机器学习之归一化和标准化
因为归一化和标准化在数据分析和处理中都属于数据与预处理。因此,其API都在 sklearn.preprocessing中
1、归一化
作用:将数据映射到到某个区域内,默认是0到1之间。
API: sklearn.preprocessing.MinMaxScaler

feature_range(0,1)表示将数据映射到0到1之间,也可以指定映射到2到3或者其他的区间。
数学原理:

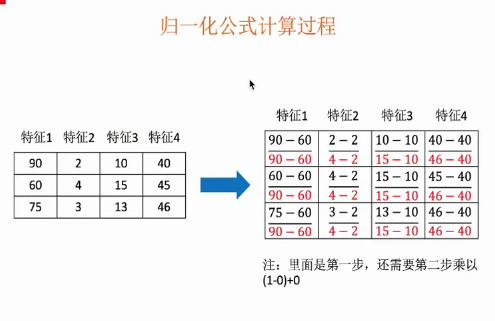
理论乏味,来个例子:
左边的数组是我们的数据,右边的数组是计算的X′。第二步再乘以(1-0)+0即可。
结果:

上代码:
1 from sklearn.preprocessing import MinMaxScaler 2 3 def mm(): 4 ''' 5 g 6 归一化处理 7 :return: 8 ''' 9 mm = MinMaxScaler() 10 data = mm.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]]) 11 print(data) 12 if __name__ == '__main__': 13 mm()
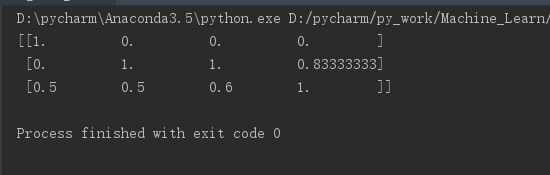
但是呢,归一化有一个缺点:那就是特别受到异常值的影响,其鲁棒性较差,因为从数学原理角度可以看出其公式中只用到了最大值最小值。
所以,这个时候就需要推出标准化。
2、标准化
因为标准化中使用了平均值和标准差这两个数学指标,而均值和标准差是不容易受到异常值影响的,因此标准化更加稳定。
API:sklearn.preprocessing.StandardScaler

数学原理:

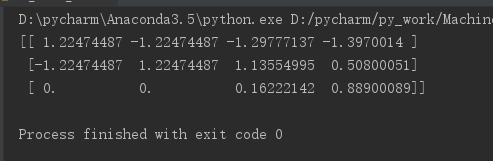
上代码:
1 from sklearn.preprocessing import StandardScaler 2 3 def Stand(): 4 ''' 5 标准化缩放 6 :return: 7 ''' 8 std = StandardScaler() 9 data = std.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]]) 10 print(data) 11 if __name__ == '__main__': 12 Stand()
--------------------成功,肯定是需要一点一滴积累的--------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号