机器学习之scikit-learn库
前面讲到了,这个库适合学习,轻量级,所以先学它。
安装就不讲了,简单。不过得先安装numpy和pandas库才能安装scikit-learn库。
如果安装了anaconda得话,会自带有这个库。
----------------------------------------------------------------------------------------------------------
1、首先进行字典特征提取
作用:对字典数据进行特征值提取。
API:sklearn.feature_extraction.DictVectorizer

流程:1、实例化类 DictVectorizer()
2、调用fit_transorm方法输入数据并转换
上代码:
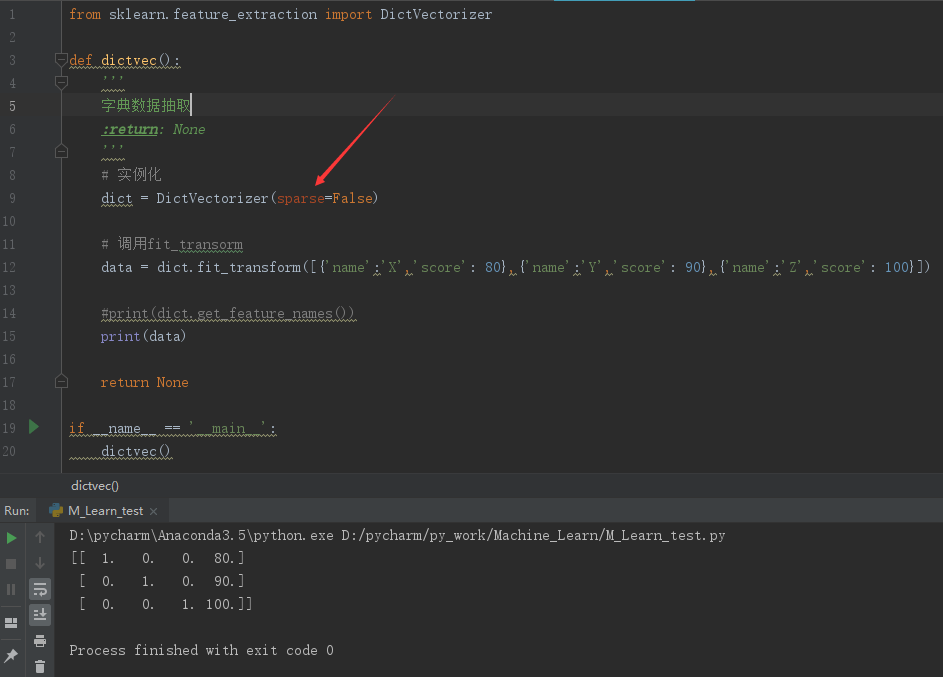
1 from sklearn.feature_extraction import DictVectorizer 2 3 def dictvec(): 4 ''' 5 字典数据抽取 6 :return: None 7 ''' 8 # 实例化 9 dict = DictVectorizer() 10 11 # 调用fit_transorm 12 data = dict.fit_transform([{'name':'X','score': 80},{'name':'Y','score': 90},{'name':'Z','score': 100}]) 13 14 print(data) 15 16 return None 17 18 if __name__ == '__main__': 19 dictvec()

可以看到输出结果是一个Sparse矩阵,前面得括号里面是坐标,后面的数字是这个坐标的值,比如:(0,0) 1.0 表示在第0行0列的值为1。
其他没有列出来的坐标如(0,1)、(0,2)等的值默认为0.
将DictVectorizer()中的sparse参数设置为False可以使得结果容易可读。
2、文本特征提取
作用:对文本数据进行提取
API:sklearn.feature_extraction.text.CountVectorizer
上代码:假设有两篇文章分别为:'life is shortm,i like Python'和'life is too long, i dislike Python'

1 from sklearn.feature_extraction.text import CountVectorizer 2 3 def countvec(): 4 ''' 5 对文本进行特征值提取 6 :return: None 7 ''' 8 # 实例化 9 cv = CountVectorizer() 10 11 # 调用fit_transorm 12 data = cv.fit_transform(['life is shortm,i like Python','life is too long, i dislike Python']) 13 14 print(data) 15 16 return None 17 18 if __name__ == '__main__': 19 countvec()
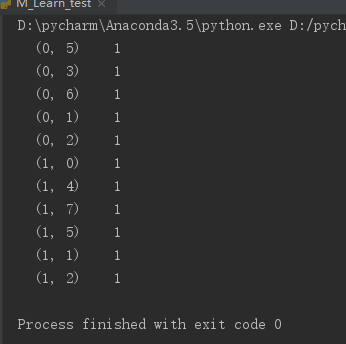
结果和字典提取是一样的,值得注意的是这里要将parse矩阵转换成比较容易读的二维矩阵的话,是在结果中调用toarray(),而不是设置sparse参数
如下图:
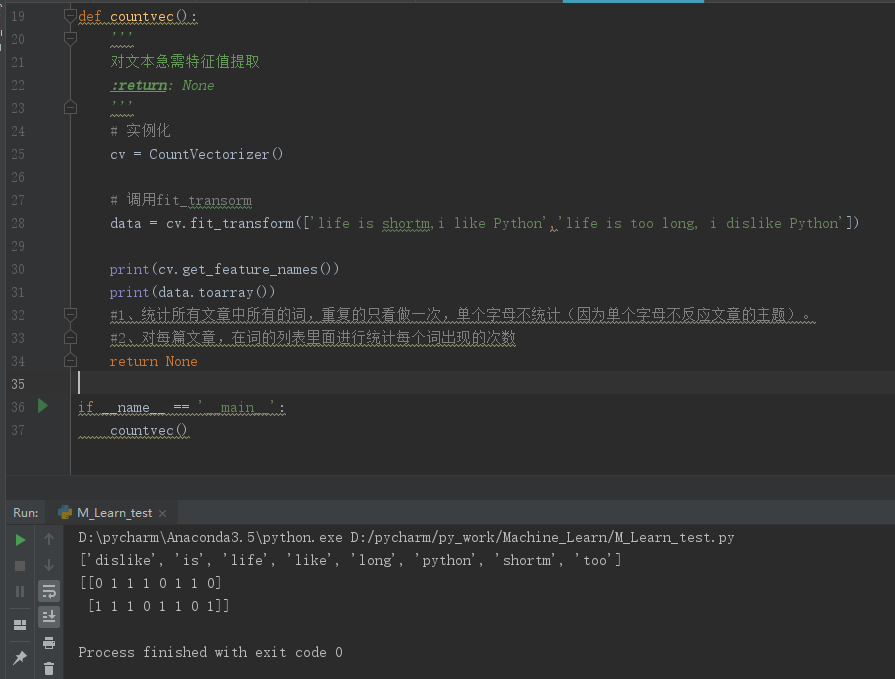
get_feature_names()返回一个列表,列表里面是提取的所有特征(本例中提取出了8个单词,单个字母不统计)。
结果中有两个列表,每个列表对应一篇文章。第一个列表中第一个0表示第一篇文章中dislike没有出现,第一个列表中第一个1表示is出现了,依次类推
--------------------成功,肯定是需要一点一滴积累的--------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号