二进制文件 .VS. 文本文件 > python

【前言】
最近用python读二进制文件,遇到一个问题:我的二进制文件里面掺杂着正常的文本,我想将里面的文本给剔除掉。解决这个问题就是写这篇文章的初衷。
一、预备知识
二进制文件和文本文件有啥区别呢?百度知道 里面有位大佬说:在定义和存取方式上二进制文件与文本文件存在区别。
1、定义上的区别
-
文本文件:文本文件是一种计算机文件,它是一种典型的顺序文件,其文件的逻辑结构又属于流式文件。简单的说,文本文件是基于字符编码的文件,常见的编码有ASCII编码,UNICODE编码等等。
-
二进制文件:是基于值编码的文件,你可以根据具体应用,指定某个值是什么意思(这样一个过程,可以看作是自定义编码)。用户一般不能直接读懂它们,只有通过相应的软件才能将其显示出来。二进制文件一般是可执行程序、图形、图像、声音等等。
-
从上面可以看出文本文件与二进制文件的区别并不是物理上的,而是逻辑上的。这两者只是在编码层次上有差异,文本文件基本上是定长编码的(也有非定长的编码如UTF-8)。而二进制文件则可看成是变长编码,因为是值编码,多少个比特代表一个值,完全由你决定。
2、存储方式上的区别
- 文本工具打开一个文件,首先读取文件物理上所对应的二进制比特流,然后按照所选择的解码方式来解释这个流,然后将解释结果显示出来。
- 一般来说,你选取的解码方式会是ASCII码形式(ASCII码的一个字符是8个比特),接下来,它8个比特8个比特地来解释这个文件流。
- 记事本无论打开什么文件都按既定的字符编码工作(如ASCII码),所以当他打开二进制文件时,出现乱码也是很必然的一件事情了,解码和译码不对应。
- 文本文件的存储与其读取基本上是个逆过程。而二进制文件的存取与文本文件的存取差不多,只是编/解码方式不同而已。
- 二进制文件就是把内存中的数据按其在内存中存储的形式原样输出到磁盘中存放,即存放的是数据的原形式。文本文件是把数据的终端形式的二进制数据输出到磁盘上存放,即存放的是数据的终端形式
3、文本文件和二进制文件的优缺点:
- 一般认为,文本文件编码基于字符定长,译码容易些;二进制文件编码是变长的,所以它灵活,存储利用率要高些,译码难一些(不同的二进制文件格式,有不同的译码方式)。
- 关于空间利用率,想想看,二进制文件甚至可以用一个比特来代表一个意思(位操作),而文本文件任何一个意思至少是一个字符。
- 在windows下,文本文件不一定是以ASCII来存贮的,因为ASCII码只能表示128的标识,你打开一个txt文档,然后另存为,有个选项是编码,可以选择存贮格式,一般来说UTF-8编码格式兼容性要好一些。而二进制用的计算机原始语言,不存在兼容性。
- 如果存储的是字符数据,无论采用文本文件还是二进制文件都是没有任何区别的。如果存储的是非字符数据,又要看我们使用的情况来决定:
-
- 1、如果是需要频繁的保存和访问数据,那么应该采取二进制文件进行存放,这样可以节省存储空间和转换时间。
-
- 2、如果需要频繁的向终端显示数据或从终端读入数据,那么应该采用文本文件进行存放,这样可以节省转换时间。
二、Python 读取
好像对于文本文件,不论是二进制方式读取还是文本方式读取,都可以;但是对于二进制文件,只可以二进制方式读取,用文本方式读取的话会报错的。
Python 读取文本文件不用多说,关键是二进制文件。
#读取文本文件
f=open('somefile.txt','r');
flist=f.readlines()
f.close()
读二进制文件,就来个压缩包吧,最近就是搞压缩包遇到问题,才想写这篇文章的。
filename=r'C:\Users\OHanlon\Documents\python\temp\ABPO00MDG_R_20191010000_01D_30S_MO.crx.gz'
fblist=fb.readlines()
l1=fblist[0] #b'HTTP/1.1 200 OK\r\n'
l15=fblist[14] #b"\xe3\xe0\x87\x91\xc..
#上面只是一部分
type(l1) #<class 'bytes'>
type(l15) #<class 'bytes'>
上面这个文件情况是这样的:用npp打开的时候,可以看到它前面有几行是文本,然后后面是乱码。通过上面python以二进制方式读取的话,直观上看,可以很明显地区分出来文本和二进制语句。
Python2 和Python3 读取二进制文件的区别
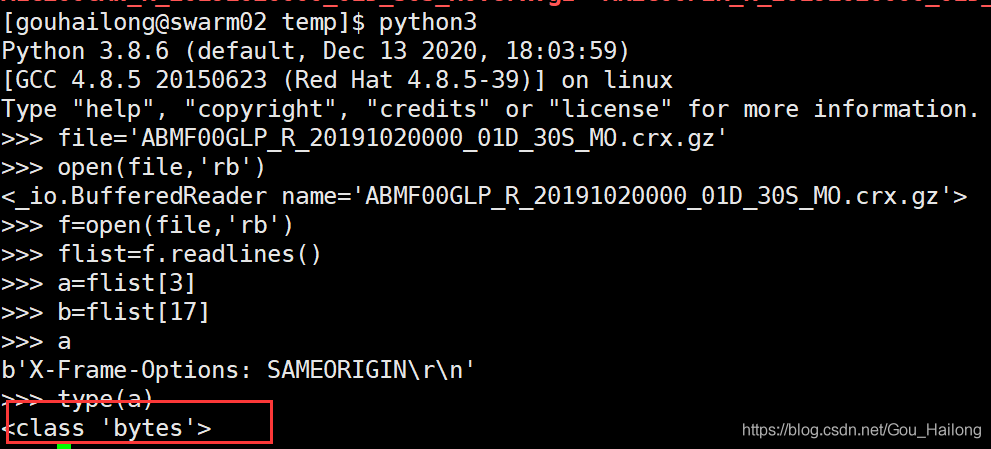
- python3:
- python2:
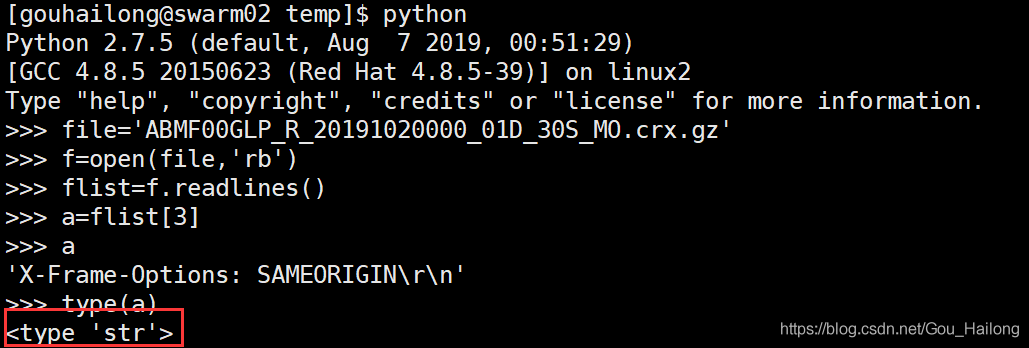
从上面可以看出来:python2 以二进制方式读文件读出来的是字符串,python3读二进制文件,读出来的是bytes。
我上面是用python3读取的,下面先考虑python3的情况。
sl1=str(l1) # "b'HTTP/1.1 200 OK\\r\\n'"
sl15=str(l15) # 'b"\\xe3\\xe0\\x87\\x91\\xc..
将bytes 转化成 str ;这样就很容易看出来区别了:

好,上面已经解决了python3 的问题:r'\x' in str(xx) 返回 true 就是二进制语句,返回false就是正常的文本语句。那么对于python2 怎么解决呢?(实际上我的问题已经得以解决,但是处于好奇,多尝试一下嘛)
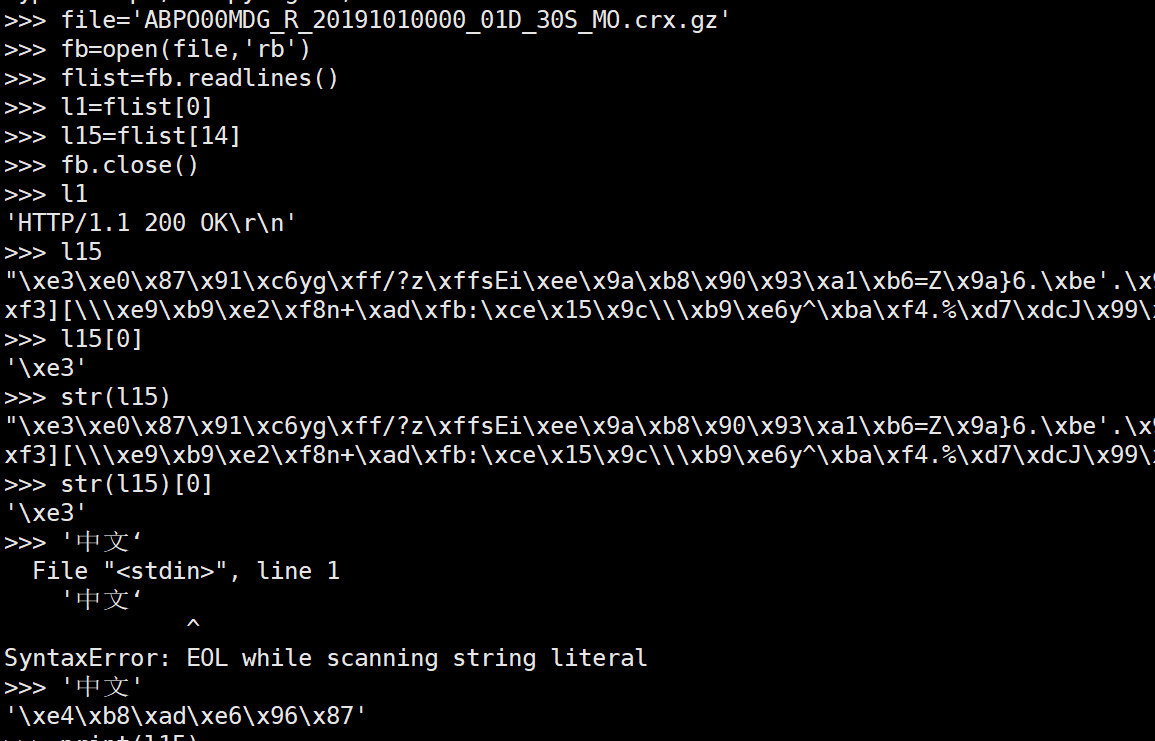
先切换到 16 进制视图看下文件:

注:这个文件,前13行是文本。
发现并没有好的标志,做了初步尝试:
然后在网上搜了搜,发现有篇文章:
文章中的小函数如下(注意,是Python2):
#Check if a string is text or binary
'''If the string contains control or more than 30% of the characters in the string are 1, then it is binary data'''
import string
text = ''.join(map(chr,range(32,127))) + '\r\n\t\b'
_null_trans = string.maketrans('','')
def istext(s,text = text,threshold = 0.30):
if '\0' in s:
return False
if not s:
return True
t = s.translate(_null_trans,text) #delete char in text for s
return len(t)/(len(s) * 1.0) <= threshold
进行测试:
file='ABPO00MDG_R_20191010000_01D_30S_MO.crx.gz'
fb=open(file,'rb')
flist=fb.readlines()
l1=flist[0]
l15=flist[14]
fb.close()
import test; print test.istext(l1); print test.istext(l15)

perfect!
至此,在python2 和python3 中都已完美解决我遇到的问题!
三、Python 中 str 和 bytes 的相互转换
>>> str='ohanlon'
>>> bstr=str.encode('utf-8')
>>> bstr
b'ohanlon'
>>> str1=bstr.decode('utf-8')
>>> str1
'ohanlon'
>>> del str #得把str删了,不然下面那行会将str认为是变量str,这样就执行不了。
>>> str(bstr)
"b'ohanlon'"
>>> repr(bstr)
"b'ohanlon'"
【文章总结】
bstr=str.encode('utf-8')str转bytesstr1=bstr.decode('utf-8')bytes转str- python3与python2的区别:python2支持
print xx和print(xx),而python3 只支持后者。python3 以二进制形式读文件出来的是bytes,而python2以二进制形式读文件读出来的是str。 - 为解决消除二进制文件中的文本信息,在python3中的解决方案是
r'\x' in str(xx)返回 true 就是二进制语句,返回false就是正常的文本语句;在python2 中的解决方案是加个小函数,istext(xx)返回 false 就是二进制语句,返回true就是正常的文本语句。
python2中的小函数如下:
#Check if a string is text or binary
'''If the string contains control or more than 30% of the characters in the string are 1, then it is binary data'''
import string
text = ''.join(map(chr,range(32,127))) + '\r\n\t\b'
_null_trans = string.maketrans('','')
def istext(s,text = text,threshold = 0.30):
if '\0' in s:
return False
if not s:
return True
t = s.translate(_null_trans,text) #delete char in text for s
return len(t)/(len(s) * 1.0) <= threshold
