熵相关
1 信息量
1.1 简介
- 信息量(也可以叫信息熵)是表示一个事件所包含信息大小的度量(也可以理解为一个事件从不确定到确定的度量)。
1.2 公式
\[f(x) = -log(x) \tag{1}
\]
1.3 由来
- 怎样算信息量高?是通过这个信息我们听没听过来衡量,还是告诉我们内容的多少来衡量?
- 如果说“马云购买了一架飞机”,这句话如果我们没有听过的话,确实给我们带来了一定的信息量,但是信息量一定是相对较小的。但是如果换一句话说“马云买不起一辆自行车”,这句话明显相对上面一句话所带来的信息量就大很多了。
- 再举个例子,假如世界杯比赛中,总共有八支队伍,不考虑其他因素,就简单的认为他们夺冠的概率都是一样的,那么阿根廷夺冠的概率就是\(\frac{1}{8}\)
![20221018120154]()
- 但是此时我告诉你说,“阿根廷是比赛冠军”,那么阿根廷夺冠的概率一下就从1/8变到了100%,这样信息量是不是就非常大了,同理,我告诉你“阿根廷能进决赛”并且“阿根廷赢得了决赛”,这两者之间的信息量应该与“阿根廷是比赛冠军”一样的。以八强为起点的话,阿根廷进决赛的概率为1/4,以决赛为起点,阿根廷赢得决赛的概率为1/2。于是我们可以得到阿根廷进决赛的信息量如下所示:
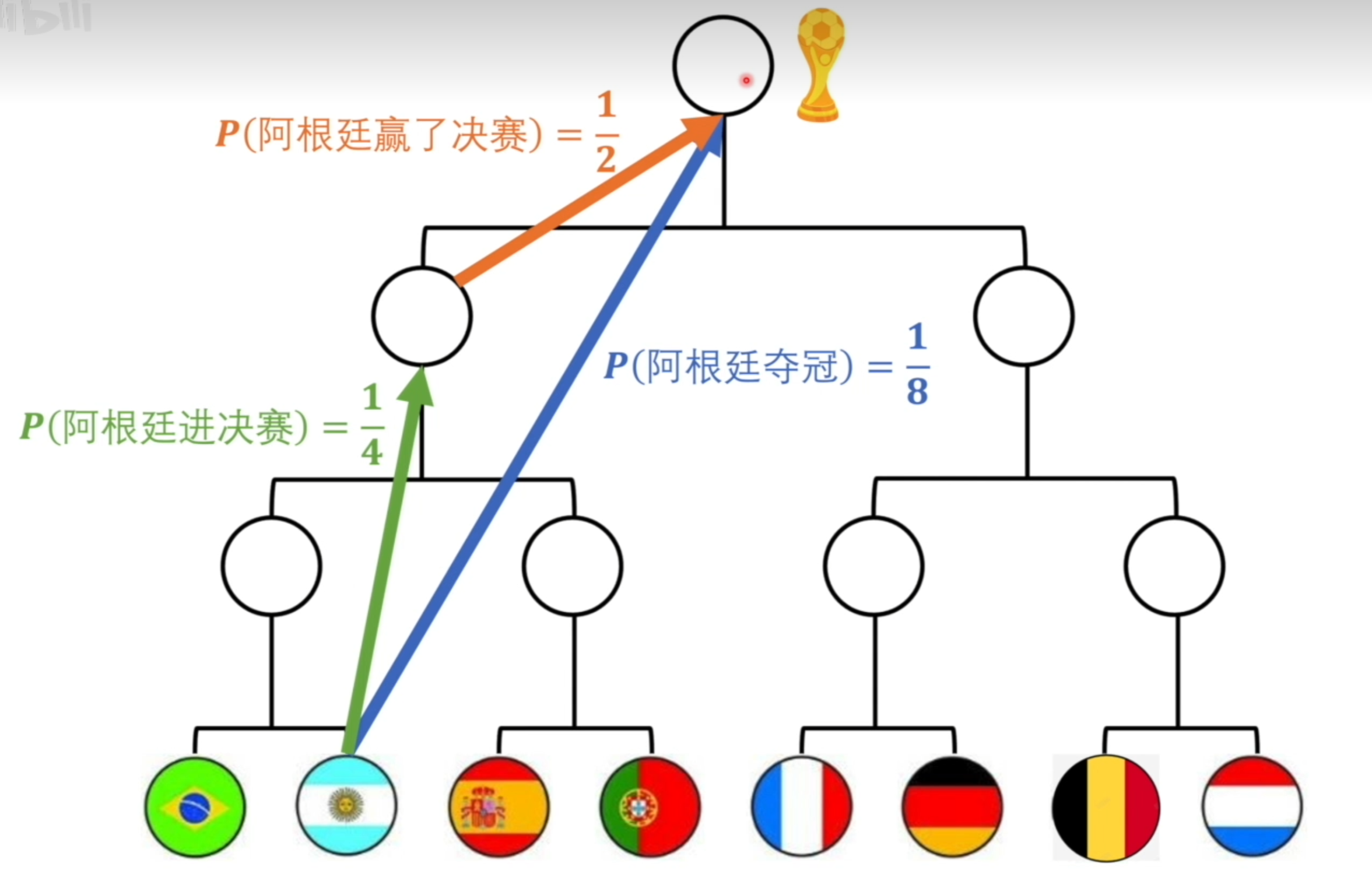
\[f(P(\frac{1}{8})) = f(P(\frac{1}{4})) + f(P(\frac{1}{2})) \tag{2}
\]
因为上述公式的1/8等均为概率,于是从概率的公式出发,两个事件同时发生的概率为两个事件发生概率的乘积:
\[P(\frac{1}{8}) = P(\frac{1}{4}) \times P(\frac{1}{2}) \tag{3}
\]
而将(3)等式右侧的内容替换(2)等式左侧,也就推演出了(4)式
\[f(x_1x_2) = f(x_1) + f(x_2) \tag{4}
\]
通过(4)我们很容易想到一个可以将乘法转换为加法的公式,即对数函数\(\log(x)\)
\[\log(x_1x_2) = \log(x_1) + \log(x_2) \tag{5}
\]
- 此时我们再思考一个问题,是得到最终信息量之前的概率值越小从而信息量越大,还是概率值越大从而信息量越大呢?
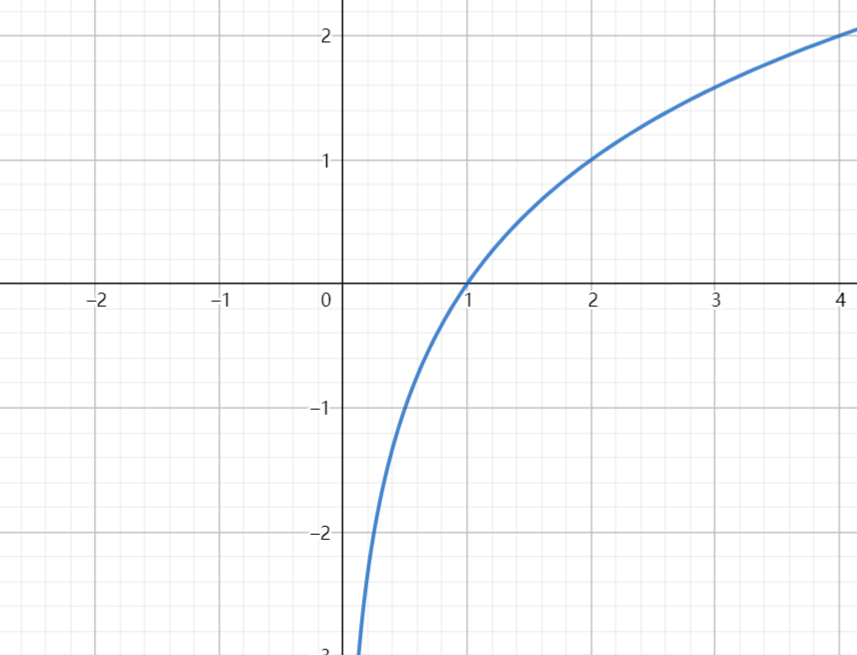
举个例子,拿中国足球来说,在不确定最终结果的情况下,中国足球获得世界杯的概率大还是阿根廷获得世界杯的概率大,很明显是阿根廷(没有侮辱中国足球的意思),也就是说中国相较于阿根廷而言获得世界杯的概率很小,这个时候如果我告诉你,中国足球获得了世界杯,这里的信息量是不是就比告诉你阿根廷获得了世界杯的信息量大很多了。于是我们从常理可以判断出,得到最终信息量之前的概率值越小从而信息量越大。 - 而对数函数则是一个增函数,随着变量\(x\)的增大而增大,如下图所示:
![20221018133946]()
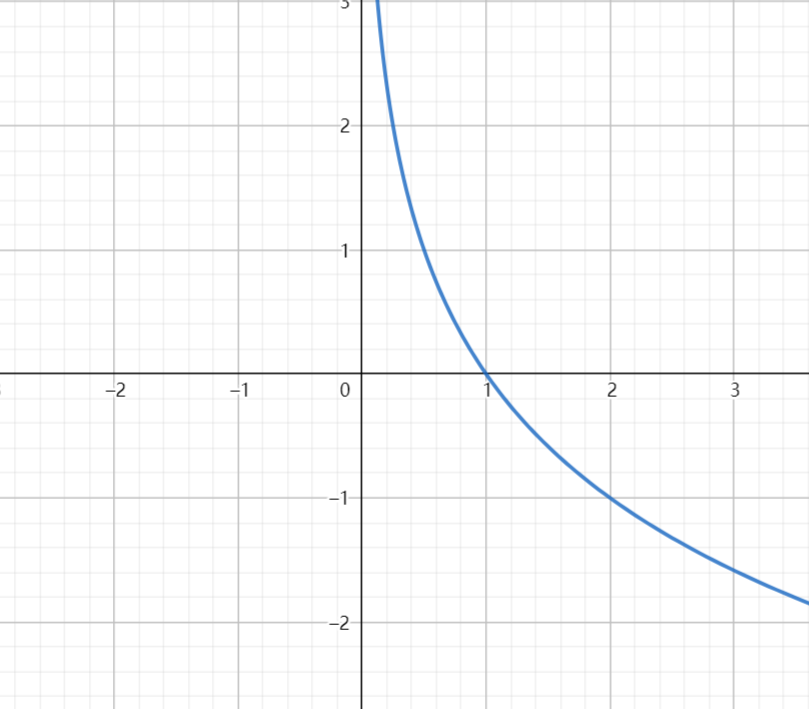
这与我们刚刚的结论相反,于是我们需要在对数函数前面加个负号来取反,从而使得\(x\)越小,最后的值越大
![20221018134122]()
- 至此,我们就得出了信息量的公式,至于底数是几,这个不重要,取最常见的\(2\)、\(e\)等都行,看你最后想以什么为单位而决定,例如我想以比特作为单位,那么我就取2为底。
\[f(x) = -\log_2(x) \tag{6}
\]
2 熵
2.1 简介
- 熵是表示一个系统混乱程度的一个度量(或者是不确定性高不高),而不单单只是系统里的某一个事件了
2.2 公式
\[H(P) := E(P_f) = \sum_{i=1}^mp_i(-\log_2p_i) = -\sum_{i=1}^mp_i \cdot \log_2p_i \tag{7}
\]
2.3 由来
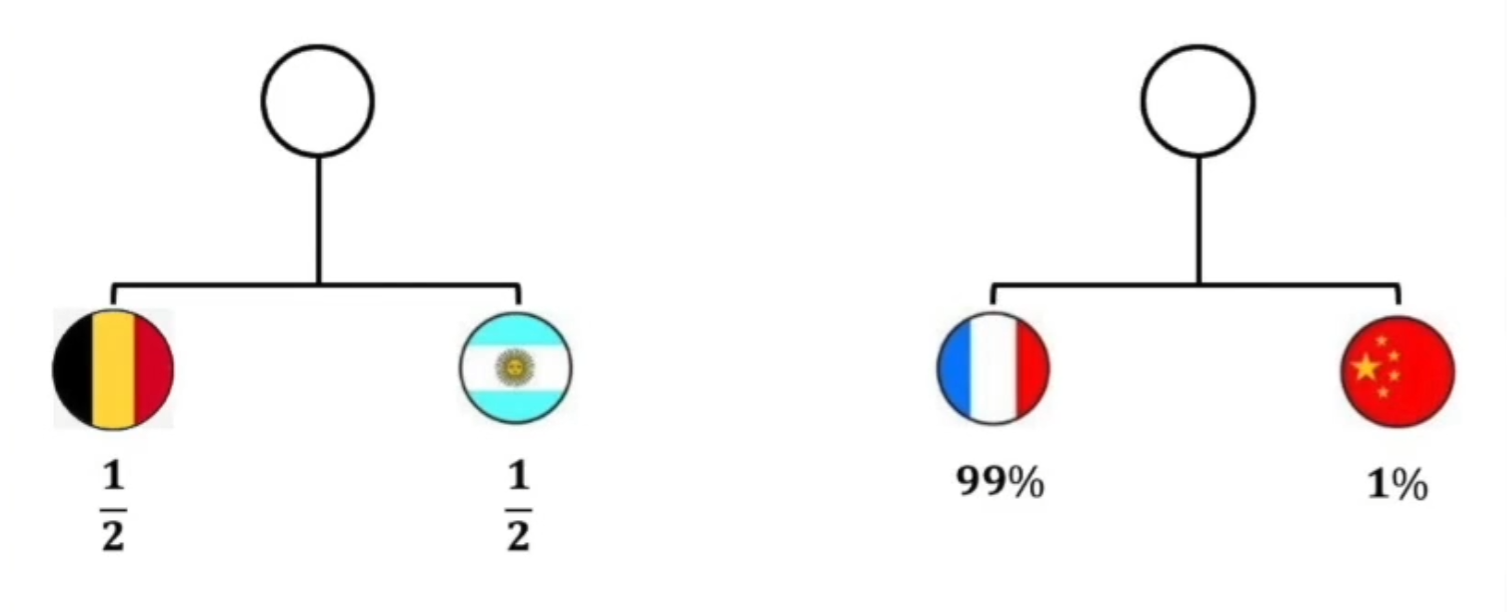
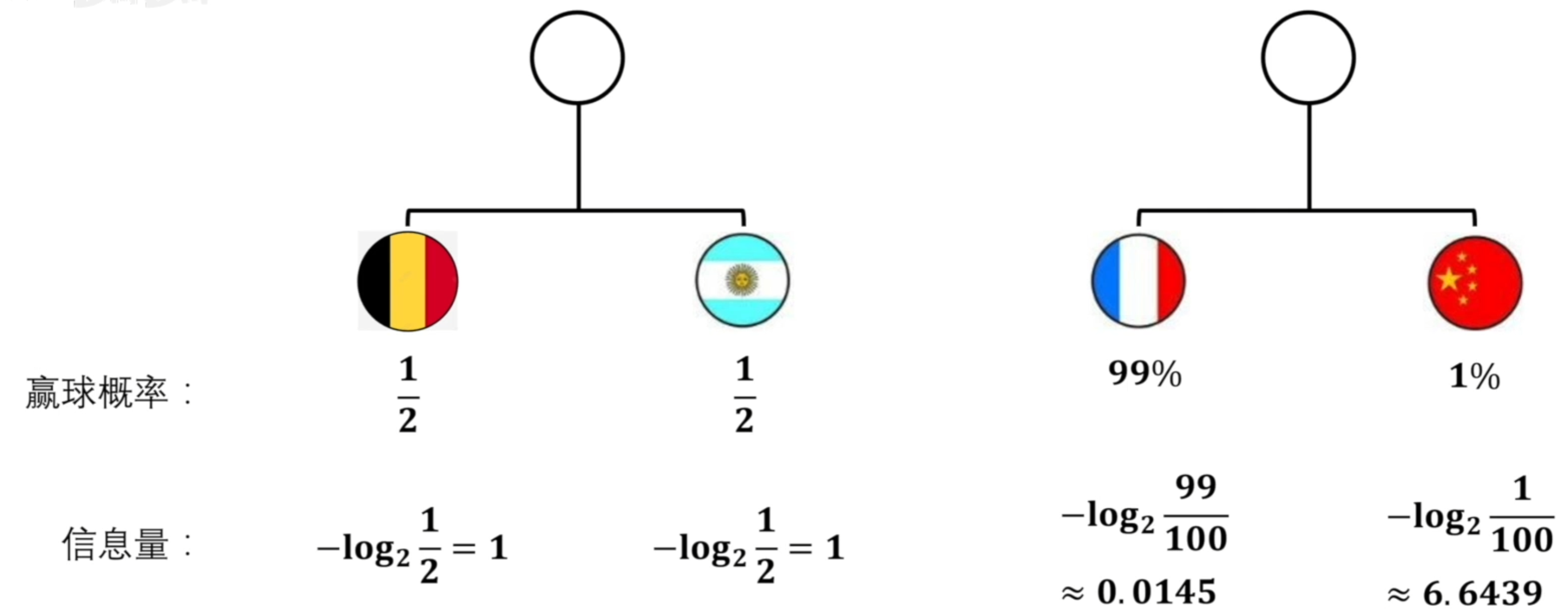
- 还是举世界杯的例子,假如有两场比赛:
![20221018135608]()
- 一个是阿根廷对比利时,他俩之间赢得概率都差不多,一半一半,还有一个是中国对法国,中国队可能就稍弱一些。把这两个比赛当成是两个系统。我们可以通过信息量计算公式来计算这两个系统队伍中获胜的信息量是多少。
![20221018140426]()
- 最终我们获得如上所示信息量,我们怎样获得这两个比赛的熵呢?如果直接使用加法将每个比赛中的所有队伍的信息量相加起来,我们可以得第一个比赛的值是2,第二个比赛的值约为6.65。很明显可以看出用这种计算方式获得的值是不符合熵的定义的,熵是描述一个系统不确定程度高不高的,按理来说第一场比赛双方都是1/2,这场比赛的不确定程度应该很高才对,而第二场比赛法国队赢球的概率是99%,这场比赛的不确定程度应该很低才对。所以我们不能简单的通过相加该系统内的所有信息量来得到该系统的熵。
- 再看上图,中国队的信息量的值这么高的原因是因为中国队赢球的概率很低,所以计算出来的信息量才会高,也就是中国队赢球的不确定性就会高。但是如果法国赢了球,那就代表中国输球了,中国输了球,那就不会有这么高的信息量了。而我们刚刚在计算整个系统的熵的时候,并没有将每个队伍赢球的概率考虑上,所以说单个事件的信息量如果想贡献到整个系统,还需要乘自己赢球的比例才行。例如中国队赢球这件事对整个系统贡献的信息量为:
\[\frac{1}{100} *(-\log_2(\frac{1}{100})) \approx 0.064
\]
通过这种方法,我们可以计算出每个事件对系统的贡献量,再进行相加即可。
我们可以得到上图两个比赛的熵为
\[\text{比赛1的熵 = } \frac{1}{2}* (-\log_2(\frac{1}{2})) + \frac{1}{2} *(-\log_2(\frac{1}{2})) = 1
\]
\[\text{比赛2的熵 = } \frac{99}{100}* (-\log_2(\frac{99}{100})) + \frac{1}{100} * (-\log_2(\frac{1}{100})) \approx 0.065
\]
至此,所计算出的数值也就符合了熵的定义。
- 最终一个系统的熵的计算方法就是将该系统所有事件所发生的概率乘上该概率的信息量进行累加。
3 KL散度
3.1 简介
- KL散度是用来描述两个系统之间的概率分布的相似程度
3.2 公式
\[\begin{equation}
\begin{aligned}
&D_{KL}(P||Q)\\
&:= \sum_{i=1}^mp_i(f_Q(q_i) - f_P(p_i))\\
&= \sum_{i=1}^mp_i((-\log_2q_i) - (-\log_2p_i))\\
&= \sum_{i=1}^mp_i(-\log_2q_i) - \sum_{i=1}^mp_i(-\log_2p_i)\\
&= H(P,Q) - H(P)
\end{aligned}
\end{equation}
\tag{8}
\]
3.3 由来
- KL散度是用来比较两个概率系统之间相似度的,所以最直观的比较方法就是比较两个系统之间的信息量了,也就是(8)式中的第一行内容,若\(f_Q(q_i) - f_P(p_i)\)为0,则表示P和Q是完全相等的。同理,若不等于0,则表示P和Q之间是有差别的。直观上理解就是,如果Q想要达到和P一样的分布的话,就得看它们之间相差多少信息量。
- 将(8)式第一行展开,最终我们就得到了(9)式:
\[\sum_{i=1}^mp_i(-\log_2q_i) - \sum_{i=1}^mp_i(-\log_2p_i) \tag{9}
\]
可以将(9)分成两个部分(10)、(11)
\[\sum_{i=1}^mp_i(-\log_2q_i) \tag{10}
\]
\[\sum_{i=1}^mp_i(-\log_2p_i) \tag{11}
\]
可以看出,(11)就是P系统的熵,若我们把P当作基准(也就是确定了P,求Q和P有多相似,也就是(8)中的\(D_{KL}(P||Q)\)。P在前,则是求Q与P多相似;Q在前,就是求P与Q多相似),则该值对于我们整个公式而言是不会变的。所以我们如果想看Q是否像P,就得看(10)式了,而(10)就是P的交叉熵。
- 现在我们知道(11)是P的熵,而熵是一定大于0的(因为熵是一个系统内所有事件信息量的加权求和,而信息量再少也就只是没有罢了,也就是0),而(10)交叉熵也是一种描述信息量的数值,所以也不可能小于0。且由吉布斯不等式中证明,(10)是一定大于等于(11)的。
- 于是我们可以得出结论:当P和Q相同时,则(9)为0;当P和Q不相同时,则(10)大于(11)。
- 既然如此,如果我们想让Q和P非常接近,我们只需要最小化(10)式即。
4 交叉熵在神经网络中的应用
- 综上所述,我们知道如果想让一个概率分布去相似于另一个概率分布,我们可以最小化交叉熵来达成。
- 而在神经网络中,我们一般想让模型的预测值接近真实值。这正好就类似于刚刚所说的让一个概率分布去相似于另一个概率分布。于是此时的P是我们真实值的系统,Q是我们预测值的概率系统,通过利用交叉熵原理来最小化真实值于预测值之间的差距,从而使得模型能够接近预测真实值的输出。
- 例如我们有一个二分类的任务,让模型来预测一堆图片究竟是不是猫,此时利用以上所有知识可得:
\[H(Y, X) = x\log(y) \tag{12}
\]
\[H(Y, X) = (1 - x) \log(1 - y) \tag{13}
\]
- (12)公式中的\(x\)表示模型预测是猫的概率,\(y\)为是猫概率的真实值。到了(13)则\(1 - x\)表示模型预测不是猫的概率,\(1 - y\)则是不是猫概率的真实值。将(12)、(13)相加起来,就得到了最终的损失函数公式:
\[H(P,Q) = x\log(y) + (1 - x)\log(1 - y) \tag{14}
\]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号