【LeetCode每天一题】Word Break()
Given a non-empty string s and a dictionary wordDict containing a list of non-empty words, determine if s can be segmented into a space-separated sequence of one or more dictionary words.
Note:
- The same word in the dictionary may be reused multiple times in the segmentation.
- You may assume the dictionary does not contain duplicate words.
Example 1:
Input: s = "leetcode", wordDict = ["leet", "code"]
Output: true
Explanation: Return true because "leetcode" can be segmented as "leet code".
Example 2:
Input: s = "applepenapple", wordDict = ["apple", "pen"]
Output: true
Explanation: Return true because "applepenapple" can be segmented as "apple pen apple".
Note that you are allowed to reuse a dictionary word.
Example 3:
Input: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"]
Output: false
思路
在做这道题的时候比较有意思的是我想了两种方法来解决,但是两种方法都没有能ac,第一种方法大概就是我从字符串s的第一个开始遍历并申请一个tem变量来记录为被匹配的字符串,当匹配到字符串之后重新将tem设置为"",最后遍历完毕之后判断tem是否为空从而得到是否可以满足。这种思路缺陷就是我们能考虑有一种情况就是s="aaaaaaa", wordlidt=["aaaa", "aaa"],对于这个情况,她会每次都先匹配"aaa",这样导致最后还剩下一个"a"。输出False,所以不正确。
在上一种方法的特殊情况下,我想到了使用递归,大概就是从头开始遍历遍历,当遇到列表中存在的单词时,我们将s以匹配的单词去除作为参数进行递归,重新开始进行匹配。最后如果能匹配就可以得到True。但是这种解法最后因为超时也没能AC。
看了别人的答案之后发现原来还能使用动态规划来解决,大概思路就是申请一个比s字符串长1的辅助数组,初始化为False,第一个元素初始化True。最后我们设置两层循环,第一层循环就是判断辅助数组每一位是否能有列表中的单词组合成,内层循环表示从0开始到第一层循环当前遍历的位置,对每一种可能的字符串判断是否在列表中。当最后遍历完毕之后,辅助数组最后一个元素就是结果。
图解思路
![]() 解决代码
解决代码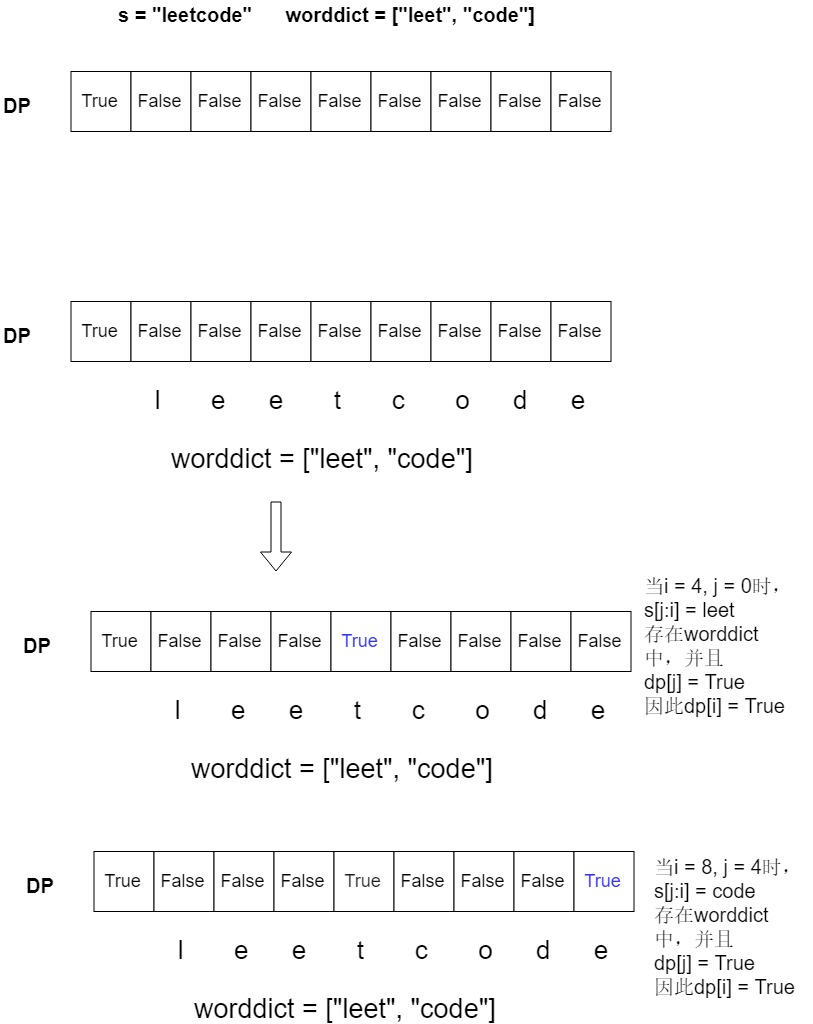
1 class Solution(object):
2 def wordBreak(self, s, wordDict):
3 """
4 :type s: str
5 :type wordDict: List[str]
6 :rtype: bool
7 """
8
9 if not s:
10 return True
11 dp = [False] *(len(s)+1) # 申请辅助数组
12 dp[0] = True # 第一个设置为True
13 for i in range(1, len(s)+1): # 外层循环
14 for j in range(i): # 内存循环
15 if dp[j] and s[j:i] in wordDict: # 判断条件
16 dp[i] = True
17 break
18 return dp[-1]
附上递归解法(s字符串过长时会超时)
1 class Solution(object):
2 def wordBreak(self, s, wordDict):
3 """
4 :type s: str
5 :type wordDict: List[str]
6 :rtype: bool
7 """
8
9 if not s:
10 return True
11 res= []
12 self.Bfs(s, wordDict, res) # 进行递归遍历
13 if not res:
14 return False
15 return True
16
17
18 def Bfs(self, s, wordDict, res):
19 if not s: # 如果s为空表示能够匹配,
20 res.append(True)
21 return
22 tem = ""
23 for i in range(len(s)): # 从头开始遍历
24 tem += s[i] # 记录未匹配的值
25 if tem in wordDict: # 当匹配到后,我们进行将s进行切割,
26 self.Bfs(s[i+1:], wordDict, res)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号