
深入理解计算机系统(第三版)第十二章重要内容摘要
12.1基于进程的并发编程

12.1.1基于进程的并发服务器

12.1.2进程的优劣

12.2基于I/O多路复用的并发编程
I/O多路复用(I/O multiplexing)技术基本的思路就是使用select函数,要求内核挂起进程,只有在一个或多个I/O事件发生后,才将控制返回给应用程序。

#include <sys/select.h>
int select(int n, fd_set *fdset, NULL, NULL, NULL);
返回已准备好的描述符的非零的个数,若出错则为-1,
FD_ZERO(fd_set *fdset); /* Clear all bits in fdset */
FD_CLR(fd_set *fdset); /* CLear bit fd in fdset */
FD_SET(fd_set *fdset); /* Turn on bit fd in fdset*/
FD_ISSET(fd_set *fdset); /* Is bit fd in fdset on? */
处理描述符集合的宏,

12.2.1基于I/O多路复用的并发事件驱动器

12.2.2I/O多路复用技术的优劣
优点
- 事件驱动设计的一个优点是,它比基于进程的设计给了程序员更多的对程序行为的控制。
- 另一个优点是,一个基于I/O多路复用的事件驱动服务器是运行在单一进程上下文中的,因此每个逻辑流都能访问该进程的全部地址空间。这使得在流之间共享数据变得更容易。
- 一个与作为单个进程运行相关的优点是,你可以利用熟悉的调试工具,例如GDB,来调试你的并发服务器,就像对顺序进程那样。
- 最后,事件驱动设计常常比基于进程的设计要高效得多,因为它们不需要进程上下文切换来调度新的流。
缺点
1.事件驱动设计一个明显得缺点就是编码复杂。并且很不幸,随着并发粒度得减小,复杂性还会上升。(粒度是指每个逻辑流每个时间片执行得指令数量。)
2.不能充分利用多核处理器。
12.3基于线程的并发编程
线程(thread)就是运行在进程上下文中的逻辑流。
线程由内核自动调度。每个线程都有它自己的线程上下文(thread context),包括一个唯一得整数线程ID(Thread Id,TID)、栈、栈指针、程序计数器、通用目的寄存器和条件码。所有的运行在一个进程里的线程共享该进程的整个虚拟地址空间。
12.3.1线程执行模型

12.3.2Posix线程
Posix线程(Pthreads)是在C程序中处理线程的一个标准接口。它最早出现在1995年,而且在所有的Linux系统上都可用。Pthreads定义了大约60个函数,运行程序创建、杀死和回收线程,与对等线程安全地共享数据,还可以通过对等线程系统状态地变化。
12.3.3创建线程
线程通过调用pthread_create函数来创建其他线程。
#include <pthread.h>
typedef void *(func)(void *);
int pthread_create(pthread_t *tid, pthread_attr_t *attr, fun *f, void *arg);
若成功则返回0,若出错则为非零。
pthread_create函数创建了一个新的线程,并带着一个输入变量arg,在新线程的上下文中运行线程例程f。能用attr参数来改变新创建线程的默认属性。改变这些属性已超出我们学习的范围,在我们的示例中,总是用一个为NULL的attr函数来调用pthread_create函数。
当pthread_create返回时,参数tid包含新创建线程的ID。新线程可以通过调用pthread_self函数来获得它自己的线程ID。
#include<pthread.h>
pthread_t pthread_self(void);
返回调用者的线程ID。
12.3.4终止线程

12.3.5回收已终止线程的资源


12.3.6分离线程

12.3.7初始化线程

12.3.8基于线程的并发服务器
12.4多线程程序的共享变量
12.4.1线程内存模型
一组并发线程运行在一个进程的上下文中。每个线程都有它自己独立的线程上下文,包括线程ID、栈、栈指针、程序计数器、条件码和通用目的寄存器值。每个线程和其他线程一起共享进程上下文的剩余部分。这包括整个用户虚拟地址空间,它是由只读文本(代码)、读/写数据、堆以及所有的共享库代码和数据区域组成的。线程也共享相同的打开文件的集合。
从实际操作的角度来说,让一个线程去读或写另一个线程的寄存器值是不可能的。另一方面,任何线程都可以访问共享虚拟内存的任意位置。如果某个线程修改了一个内存位置,那么其他每个线程最终都能在它读这个位置时发现这个变化。因此,寄存器是从不共享的,而虚拟内存总是共享的。
12.4.2将变量映射到内存

12.4.3共享变量
我们说一个变量\(\nu\)是共享地,当且仅当它地一个实例被一个以上线程引用。
12.5用信号量同步线程
共享内存是十分方便的,但是它们也引入了同步错误(synchronization error)的可能性。
//
/* WARING: This code is buggy */
#include "csapp.h"
void *thread(void *vargp); /* thread routine prototype */
/* globle shared variable */
volatile long cnt = 0; /* counter */
int main(int argc, char **argv)
{
long niters;
pthread_t tid1, tid2;
/* check input argument */
if (argc != 2) {
printf("usage: %s <niters>\n", argv[0]);
exit(0);
}
niters = atoi(argv[1]);
/* create threads and wait for them to finish */
pthread_create(&tid1, NULL, thread, &niters);
pthread_create(&tid2, NULL, thread, &niters);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
/* check result */
if (cnt != (2 * niters))
printf("BOOM! cnt = %1d\n", cnt);
else
printf("OK cnt = %1d\n", cnt);
exit(0);
}
/* thread routine */
void *thread(void *vargp)
{
long i, niters = *((long *)vargp);
for (i = 0; i < niters; i++)
cnt++;
return NULL;
}
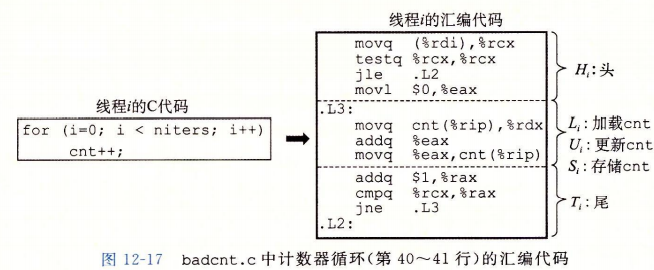


12.5.1进度图


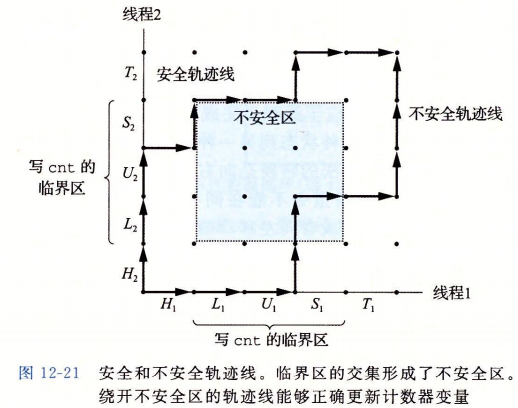
12.5.2信号量
信号量\(s\)是具有非负整数值得全局变量,只能由两种特殊得操作来处理,这两种操作称为\(P\)和\(V\):




12.5.3使用信号量实现互斥

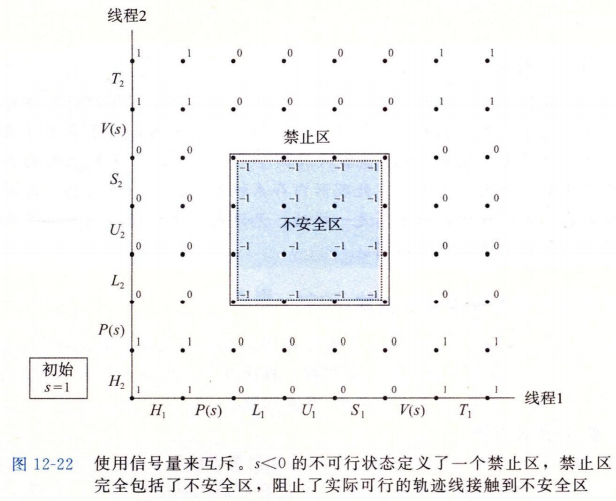
12.5.4利用信号量来调度共享资源
除了提供互斥之外,信号量的另一个重要作用是调度对共享资源的访问。在这种场景中,一个线程用信号量操作来通知另一个线程,程序状态中的某个条件已经为真了。两个经典而有用的例子是生产者-消费者和读者-写者问题。
1.生产者-消费者问题
生产者产生项目并把它们插入到一个有限的缓冲区中。消费者从缓冲区中取出这些项目,然后消费它们
2.读者-写者问题
读者-写者问题是互斥问题的一个概括。一组并发的线程要访问一个共享对象,例如一个主存中的数据结构,或者一个磁盘上的数据库。有些线程只读对象,而其他的线程只修改对象。修改对象的线程叫做写者。只读对象的线程叫做读者。写者必须拥有对对象的独占的访问,而读者可以和无限多个其他的读者共享对象。一般来说,有无限多个并发的读者和写者。
12.5.5综合:基于预线程化的并发服务器

12.6使用线程提高并行性
一种避免同步地方法是让每个对等线程在一个私有变量中计算它自己地部分和,这个私有变量不与其他任何变量共享,唯一需要同步地地方是主线程必须等待所有的子线程完成。使用局部变量来消除不必要的内存引用。
刻画并行程序的性能
并行程序的加速比(speedup)通常定义为\(S_p=\frac{T_1}{T_p}\)
这里\(p\)是处理器核的数量,\(T_k\)是在\(k\)个核上的运行时间。这个公式有时被称为强扩展(strong scaling)。当\(T_1\)是程序顺序执行版本得执行时间时,\(S_p\)称为绝对加速比(absolute speedup)。当\(T_1\)是程序并行版本在一个核上的执行时间时,\(S_p\)称为相对加速比(relative speedup)。绝对加速比比相对加速比能更真实地衡量并行的好处。即使是当并行程序在一个处理器上运行时,也常常会受到同步开销地影响,而这些开销会人为地增加相对加速比的数值,因为它们增加了分子地大小。另一方面,绝对加速比比相对加速比更难以测量,因为测量绝对加速比需要程序地两种不同地版本。对于复杂的并行代码,创建一个独立的顺序版本可能不太实际,或者因为代码太复杂,或者因为源码不可得。
一种相关地测量量称为效率(efficiency),定义为$$E_p=\frac{S_p}{p}=\frac{T_1}{pT_p}$$
通常表示为范围在(0,100]之间地百分比。效率是对由于并行化造成的开销的衡量。具有高效率的程序比效率低地程序在有用的工作上花费更多地时间,在同步和通信上花费更少的时间。
12.7其他并行问题




12.7.2可重入性
有一类重要的线程安全函数,叫做可重入函数(reentrant function),其特点在于它们具有这样一种属性:当它们被多个线程调用时,不会引用任何共享数据。尽管线程安全和可重入有时会(不正确地)被用做同义词,但是它们之间还是有清晰的技术差别,值得留意。
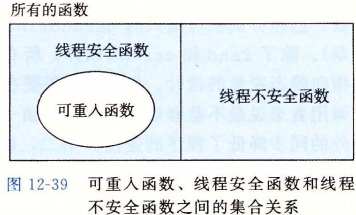

12.7.3在线程化的程序中使用已存在的库函数

12.7.4竞争
当一个程序的正确性依赖于一个线程要在另一个线程到达\(y\)点之前到达它的控制流中的\(x\)点时,就会发生竞争(race)。通常发生竞争是因为程序员假定线程将按照某种特殊的轨迹线穿过执行状态空间,而忘记了另一条准则规定:多线程的程序必须对任何可行的轨迹线都正确工作。
为了消除竞争,我们可以动态地为每个整数ID分配一个独立的块,并且传递给线程例程一个指向这个块的指针。
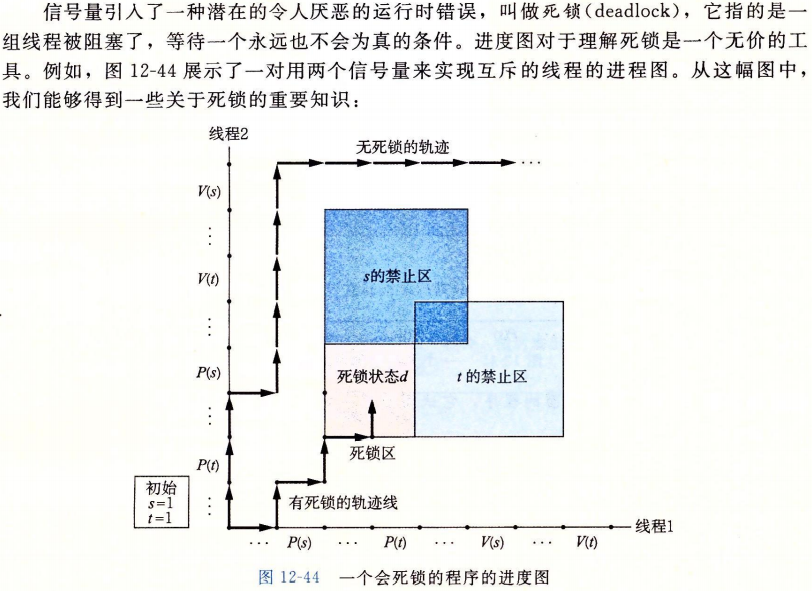
12.7.5死锁



 浙公网安备 33010602011771号
浙公网安备 33010602011771号