
深入理解计算机系统(第三版)第三章重要内容摘要
3.3数据格式
| C声明 | Intel数据类型 | 汇编代码后缀 | 大小(字节) |
|---|---|---|---|
| char | 字节 | b | 1 |
| short | 字 | w | 2 |
| int | 双字 | l | 4 |
| long | 四字 | q | 8 |
| char* | 四字 | q | 8 |
| float | 单精度 | s | 4 |
| double | 双精度 | l | 8 |
3.4访问信息
x86-64包含的一组共16个存储64位值的通用目的寄存器

在后面的章节中,我们会展现很多指令,复制和生成1字节、2字节、4字节和8字节值。当这些指令以寄存器作为目标时,对于生产小于8字节结果的指令,寄存器中剩下的字节会怎么样,对此有两条规则:生成1字节和2字节数字的指令会保持剩下的字节不变;生成4字节数字的指令会把高位4个字节置为0.后面这条指令是作为IA32到x86-64的扩展的一部分而采用的。
3.4.1操作数指示符
| 类型 | 格式 | 操作数值 | 名称 |
|---|---|---|---|
| 立即数 | \(\$Imm\) | Imm | 立即数寻址 |
| 寄存器 | \(r_a\) | \(R[r_a]\) | 寄存器寻址 |
| 存储器 | \(Imm\) | \(M[Imm]\) | 绝对寻址 |
| 存储器 | \((r_a)\) | \(M[R[r_a]]\) | 间接寻址 |
| 存储器 | \(Imm(r_b)\) | \(M[Imm+R[r_b]]\) | (基址+偏移量)寻址 |
| 存储器 | \((r_b,r_i)\) | \(M[R[r_b]+R[r_i]]\) | 变址寻址 |
| 存储器 | \(Imm(r_b,r_i)\) | \(M[Imm+R[r_b]+R[r_i]]\) | 变址寻址 |
| 存储器 | \((,r_i,s)\) | \(M[R[r_i]\cdot s]\) | 比例变址寻址 |
| 存储器 | \(Imm(,r_i,s)\) | \(M[Imm+R[r_i]\cdot s]\) | 比例变址寻址 |
| 存储器 | \((r_b,r_i,s)\) | \(M[R[r_b]+R[r_i]\cdot s]\) | 比例变址寻址 |
| 存储器 | \(Imm(r_b,r_i,s)\) | \(M[Imm+R[r_b]+R[r_i]\cdot s]\) | 比例变址寻址 |
3.4.2数据传送指令
| 指令 | 效果 | 描述 |
|---|---|---|
| MOV S, D | \(D\leftarrow S\) | 传送 |
| movb | 传送字节 | |
| movw | 传送字 | |
| movl | 传送双节 | |
| movq | 传送四节 | |
| movabsq I, R | \(R\leftarrow I\) | 传送绝对的四节 |
下面的MOV指令示例给出了源和目的类型的五种可能的组合。记住,第一个是源操作数,第二个是目的操作数:
| 指令 | 效果 | 描述 |
|---|---|---|
| MOV S, R | \(R\leftarrow 零扩展(S)\) | 以零扩展进行传送 |
| movzbw | 将做了零扩展的字节传送到字 | |
| movzbl | 将做了零扩展的字节传送到双字 | |
| movzwl | 将做了零扩展的字传送到双字 | |
| movzbq | 将做了零扩展的字节传送到四字 | |
| movzwq | 将做了零扩展的字传送到四字 |
3.4.4压入和弹出数据栈
最后两个数据传送操作可以将数据压入程序栈中,以及从程序栈中弹出数据,如图所示。正如我们所看到的,栈在处理过程中调用中起到至关重要的作用。栈是一种数据结构,可以添加或者删除值,不过要遵循“后进先出”的原则。通过push操作把数据压入栈中,通过pop操作删除数据;它具有一个属性:弹出的值永远是最近被压入而且仍然在栈中的值。栈可以实现为一个数组,总是从数组的一段插入和删除元素。这一段被称为栈顶。在x86-64中,程序栈存放在内存中某个区域。栈向下增长,这样一来,栈顶元素的地址是所有栈中元素地址中最低的。栈指针%rsp保存着栈顶元素的地址。
| 指令 | 效果 | 描述 |
|---|---|---|
| push S | $$R[%rsp]\leftarrow R[%rsq]-8;$$ $$M[R[%rsp]]\leftarrow S$$ | 将四字压入栈 |
| popq D | $$D\leftarrow M[R[%rsp]];$$ $$R[%rsp]\leftarrow R[%rsp]+8$$ | 将四字弹出栈 |
pushq指令的功能是把数据压入到栈上,而popq指令是弹出数据。这些指令都只有一个操作数——压入的数据源和弹出的数据目的。
3.5算数和逻辑操作

图3-10列出了x86-64的一些整数和逻辑操作。大多数操作都分成了指令类,这些指令类有各种带不同大小操作数的变种(只有leaq没有其他大小的变种)。例如,指令类ADD由四条加法指令组成:addb、addw、addl和addq,分别是字节加法、字加法、双字加法和四字加法。事实上,给出的每个指令类都有对这四种不同大小数据的指令。
3.5.1加载有效地址
加载有效地址(load effectie address)指令leaq实际上是movq指令的变形。它的指令形式是从内存读数据到寄存器,但实际上它根本就没有引入内存。它的第一个操作数看上去是一个内存引用,但该指令并不是从指定的位置读入数据,而是将有效地址写入到目的操作数。我们用C语言的地址操作符&S说明这个计算。这条指令可以为后面的内存引用产生指针。另外,它还可以简洁地描述普通地算术操作。例如,如果寄存器%rdx地值为x,那么指令leaq 7(%rdx,%rdx,4),%rax 将设置寄存器%rax地值为5x+7.编译器经常发现leaq地一些灵活用法,根本就与有效地址计算无关。目的操作数必须是一个寄存器。
leaq指令能执行加法和有限形式的乘法
3.5.2一元和二元操作
第二组中的操作时一元操作,只有一个操作数,既是源又是目的。
第三组是二元操作,其中,第二个操作数既是源又是目的。
3.5.3移位操作
最后一组是移位操作,先给出移位量,然后第二项给出的是要移位的数。可以进行算数和逻辑右移。移位量可以是一个立即数,或者放在单字节寄存器%cl中。(这些指令很特别,因为只允许以这个特定的寄存器作为操作数。)原则上来说,1个字节的移位量使得移位量的编码范围可以达到\(2^8-1=255\)。x86-64中,移位操作对\(\omega\)位长的数据值进行操作,移位量是由%cl寄存器的低\(m\)位决定的,这里\(2^m=\omega\)。高位会被忽略。所以,例如当寄存器%cl的十六进制值位0xFF时,指令salb会移7位,salw会移15位,sall会移31位,而salq会移63位。
3.5.5特殊的算数操作
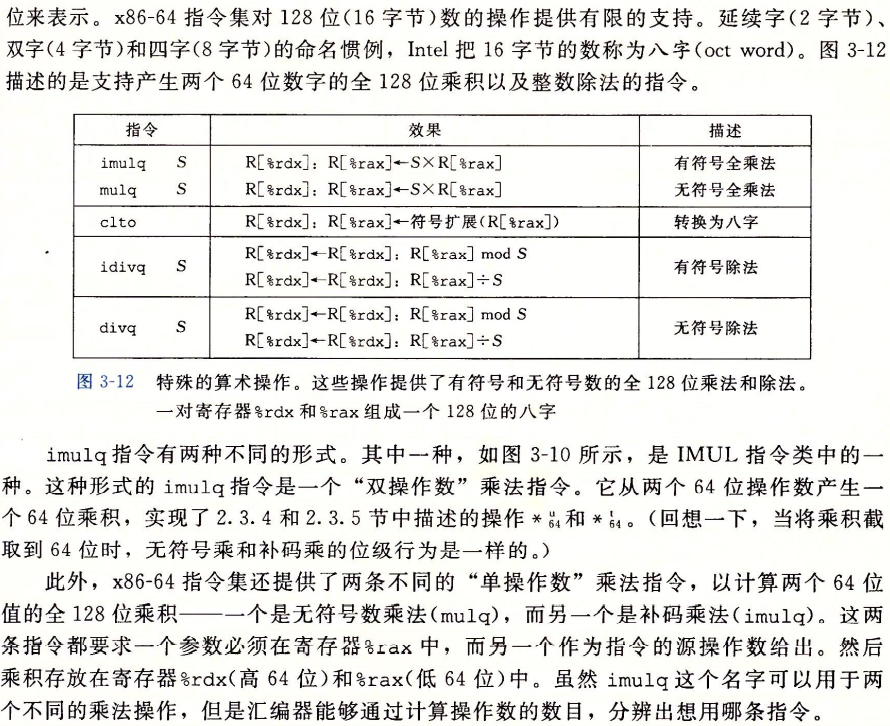

3.6控制
3.6.1条件码
CF:进位标志(carry-over)。最近的操作使最高位产生了进位。可用来检查无符号操作的溢出。
ZF:零标志(zero)。最近的操作得出的结果为0.
SF:符号标志(symbol)。最近的操作得到的结果为负数。
OF:溢出标志(over-flow)。最近的操作导致一个补码溢出——正溢出或负溢出。

3.6.2访问条件码
e:equal,n:not,s:symbol,g:great:l:less,a:above,b:below


3.6.3跳转指令


指令rep和repz有什么用
本节开始地汇编代码地第8行包含指令组合rep;ret。它们在反汇编代码中(本节第6行)对应于repz retq。可以推测出repz是rep地同义名,而retq是ret地同义名。查阅Intel和AMD有关rep的文档,我们发现它通常用来实现重复的字符串操作[3,51]。在这用它似乎很不合适。这个问题的答案可以在AMD给编译器编写者的指导意见书中找到。他们建议用rep后面跟ret的组合来避免使ret、指令成为条件跳转指令的目标。如果没有rep指令,当分支不跳转时,jg指令(汇编代码的第7行)会继续到ret指令。根据AMD的说法,当ret指令通过跳转指令到达时,处理器不能正确预测ret指令的目的。这里的rep指令就是作为一种空操作,因此作为跳转目的插入它,除了能使代码在AMD上运行得更快之外,不会改变代码的其他行为。在本书后面其他代码再遇到rep或repz时,我们可以很放心地无视它们。
3.6.5用条件控制来实现条件分支

3.6.6用条件传送来实现条件分支




3.6.7循环
1.do-while循环

2.while循环


3.for循环


3.6.8switch语句

3.7过程

3.7.1运行时栈
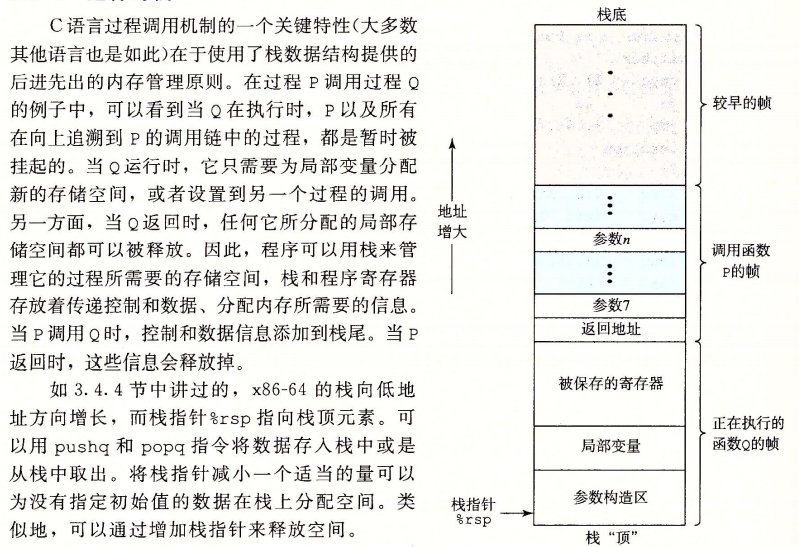
3.7.2控制转移

3.7.3数据传送


3.7.4栈上的局部存储

3.7.5寄存器中的局部存储空间

3.7.6递归过程

3.8数组分配和访问
3.8.1基本原则



3.8.2指针运算

3.8.3嵌套的数组



3.8.4定长数组

3.8.5变长数组



3.9异质的数据结构
3.9.1结构

3.9.2联合

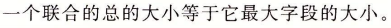


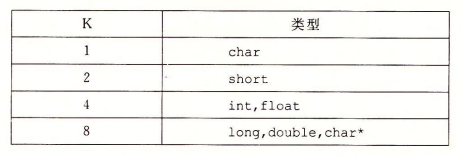
3.9.3数据对齐



3.10在机器级程序中将控制与数据结合起来
3.10.1理解指针






3.10.2应用:使用GDB调试器

3.10.3内存越界引用和缓冲区溢出




3.10.4对抗缓冲区溢出攻击
1.栈随机化
为了在系统中插入攻击代码,攻击者既要插入代码,也要插入指向这段代码的指针,这个指针也是攻击字符串地一部分。产生这个指针需要知道这个字符串放置地栈地址。在过去,程序的栈地址非常容易预测。对于所有运行同样程序和操作系统版本的系统来说,在不同的机器之间,栈地位置是相当固定的。因此,如果攻击者可以确定一个常见的Web服务器所使用的栈空间,就可以设计一个在许多机器上都能实施的攻击。以传染病来打个比方,许多系统都容易受到同一种病毒的攻击,这种现象被称为安全单一化(security monocultrue)
栈随机化的思想使得栈的位置在程序每次运行时都有变化。因此,即使许多机器都运行同样的代码,它们的栈地址都是不同的。实现的方式是:在程序开始时,在栈上分配一段0~n字节之间的随机大小的空间,例如,使用分配函数alloca在栈上分配指定字节数量的空间。程序不使用这个空间,但是它会导致程序每次执行时后续的栈位置发生了变化,分配的范围n必须足够大,才能获得足够多的栈地址变化,但是又要足够小,不至于浪费程序太多的空间。
在Linux系统中,栈随机化已经变成了标准行为。它是更大的一类技术中的一种,这类技术被称为地址空间布局随机化(Address-Space Layout Randomization),或者简称ASLR。采用ASLR,每次运行时程序的不同部分,包括程序代码、库代码、栈、全局变量和堆数据,都会被加载到内存的不同区域。这就意味着在一台机器上运行一程序,与在其他机器上运行同样的程序,它们的地址映射大相径庭。这样才能够对抗一些形式的攻击。
12.栈破坏检测
计算机的第二道防线是能够检测到何时栈已经被破坏。我们在echo函数示例(图3-40)中看到,破坏通常发生在当超越局部缓冲区的边界时。在C语言中,没有可靠的方法来防止对数组的越界写。但是,我们能够在发生了越界写的时候,在造成任何有害结果之前,尝试检测到它。
最近的GCC版本在产生的代码中加入了一种栈保护者(stark protector)机制,来检测缓冲区越界。其思想是在栈帧中任何局部缓冲区与站状态之间存储一个特殊的金丝雀(cannary)值,如图所示。这个金丝雀值,也称为哨兵值(guard value),是在程序每次运行时随机产生的,因此,攻击者没有简单的办法能够知道它是什么。在恢复寄存器状态和从函数返回之前,程序检查这个金丝雀值是否被该函数的某个操作或者该函数调用的某个函数的某个操作改变了。如果是的,那么程序异常中止。



3.10.5支持变长栈帧


3.11浮点代码


AVX512和AVX2相比
1、寄存器变化(与AVX2相比,不仅寄存器的宽度从256位增加到512位,而且寄存器的数量也增加了一倍,达到32)
2、比AVX2提供高达8倍的性能提升,由于并行处理了16条消息
3.11.1浮点传送和转换操作
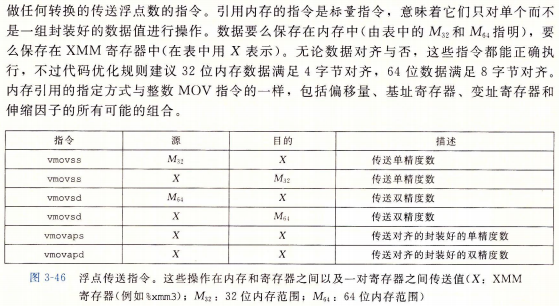

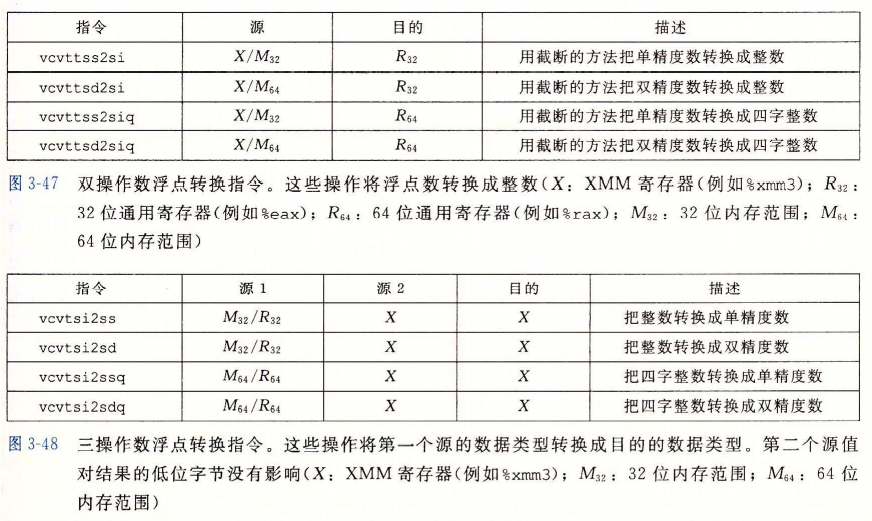
3.11.2过程中的浮点代码
- XMM寄存器 %xmm0~%xmm7最多可以传递8个浮点参数。按照参数列出的顺序使用这些寄存器。可以通过栈传递额外的浮点参数。
- 函数使用寄存器%xmm0来返回浮点值。
- 所有的XMM寄存器都是调用者保存的。被调用者可以不用保存就覆盖这些寄存器中任意一个。
当函数包含指针、整数和浮点数混合的参数时。指针和整数通过寄存器传递,而浮点数通过XMM寄存器传递。也就是说,参数到寄存器的映射取决于它们的类型和排列的顺序。下面是一些例子:
3.11.3浮点运算操作
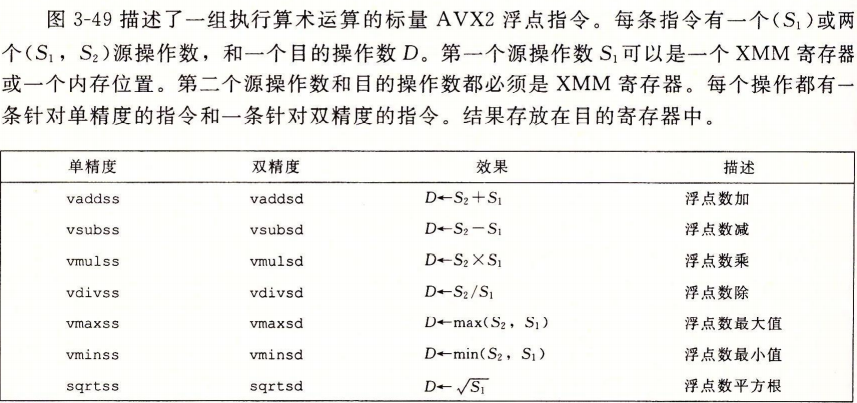
3.11.4定义和使用浮点数

3.11.5在浮点代码中使用位级操作
| 单精度 | 双精度 | 效果 | 描述 |
|---|---|---|---|
| vxorps | vorpd | \(D\leftarrow S_2\^{}S_1\) | 位级异或(EXCLUSIVE-OR) |
| vandps | andpd | \(D\leftarrow S_2\&S_1\) | 位级与(AND) |
3.11.6浮点比较操作
AVX2提供了两条用于比较浮点数值的指令:
| 指令 | 基于 | 描述 |
|---|---|---|
| ucomiss \(S_1,S_2\) | \(S_2-S_1\) | 比较单精度值 |
| ucomisd \(S_1,S_2\) | \(S_2-S_1\) | 比较双精度值 |
浮点比较值会设置三个条件码:零标志位ZF、进位标志位CF和奇偶标志位PF。对于整数操作,当最近的一次算术或逻辑运算产生的值的最低位字节是偶校验的(即这个字节中由偶数个1),那么就会设置这个标志位。不过对于浮点比较,当两个操作数中任一个是\(NaN\)时,会设置该位。根据惯例,C语言中如果有个参数为\(NaN\),就认为比较失败了,这个标志位就被用来发现这样的条件。例如,当x为\(NaN\)时,比较x==x都会得到0。
| 顺序\(S_2:S_1\) | CF | ZF | PF |
|---|---|---|---|
| 无序的 | 1 | 1 | 1 |
| \(S_2<S_1\) | 1 | 0 | 0 |
| \(S_2=S_1\) | 0 | 1 | 0 |
| \(S_2>S_1\) | 0 | 0 | 0 |
当任一操作数为\(NaN\)时,就会出现无需的情况。可以通过奇偶标志位发现这个情况。通常jp(jump on parity)指令是条件跳转,条件就是浮点比较得到一个无序的结果。除了这种情况以外,进位和零标志位的值都和对应的无符号比较一样:当两个操作数相等时,设置ZF;当\(S_2<S_1\)时,设置CF。像ja和jb这样的指令可以根据标志位的各种组合进行条件跳转。
3.11.7对浮点代码的观察结论
我们可以看到,用AVX2为浮点数上的操作产生的机器代码风格类似为整数上的操作产生的代码风格。它们都使用一组寄存器来保存和操作数据值,也都使用这些寄存器来传递函数参数。
当然,处理不同的数据类型以及对包含混合数据类型的表达式求值的规则有许多复杂之处,同事,AVX2代码包括许多比只执行整数运算的函数更加不同的指令和格式。
AVX2还有能力在封装好的数据上执行并行操作,使计算执行得更快。编译器开发者正致力于自动化从标量代码到并行代码的转换,但是目前通过并行化获得更高性能的最可靠方法是使用GCC支持的、操纵向量数据的C语言扩展。参见原书546页的网络旁注OPT:SIMD,看看可以怎么做到这样。
