
python采用pika库使用rabbitmq(三) --工作队列
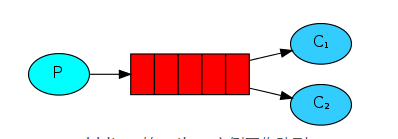
消息也可以理解为任务,消息发送者可以理解为任务分配者,消息接收者可以理解为工作者,当工作者接收到一个任务,还没完成的时候,任务分配者又发一个任务过来,那就忙不过来了,于是就需要多个工作者来共同处理这些任务,这些工作者,就称为工作队列。
RabbitMQ会默认把p发的消息依次分发给各个消费者(c),跟负载均衡差不多
先启动消息生产者,然后再分别启动3个消费者,通过生产者多发送几条消息,你会发现,这几条消息会被依次分配到各个消费者身上


1 import pika 2 import sys 3 4 credentials = pika.PlainCredentials('admin', 'passwd') 5 connection = pika.BlockingConnection(pika.ConnectionParameters( 6 'ip',credentials=credentials)) 7 channel = connection.channel() 8 9 channel.exchange_declare(exchange='logs',exchange_type='fanout') 10 11 message = ' '.join(sys.argv[1:]) or "info: Hello World!" 12 13 channel.basic_publish(exchange='logs', 14 routing_key='', 15 body=message) 16 print(" [x] Sent %r" % message) 17 connection.close()
1 import pika 2 3 credentials = pika.PlainCredentials('admin', 'passwd') 4 connection = pika.BlockingConnection(pika.ConnectionParameters( 5 'ip',credentials=credentials)) 6 channel = connection.channel() 7 8 9 channel.exchange_declare(exchange='logs', exchange_type='fanout') 10 11 result = channel.queue_declare(exclusive=True) # 不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除 12 queue_name = result.method.queue 13 14 15 channel.queue_bind(exchange='logs', queue=queue_name) 16 17 print(' [*] Waiting for logs. To exit press CTRL+C') 18 19 20 def callback(ch, method, properties, body): 21 print(" [x] %r" % body) 22 23 24 channel.basic_consume(callback, queue=queue_name,no_ack=True) 25 26 channel.start_consuming()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号