MySQL/mariadb知识点——查询缓存

查询的执行路径
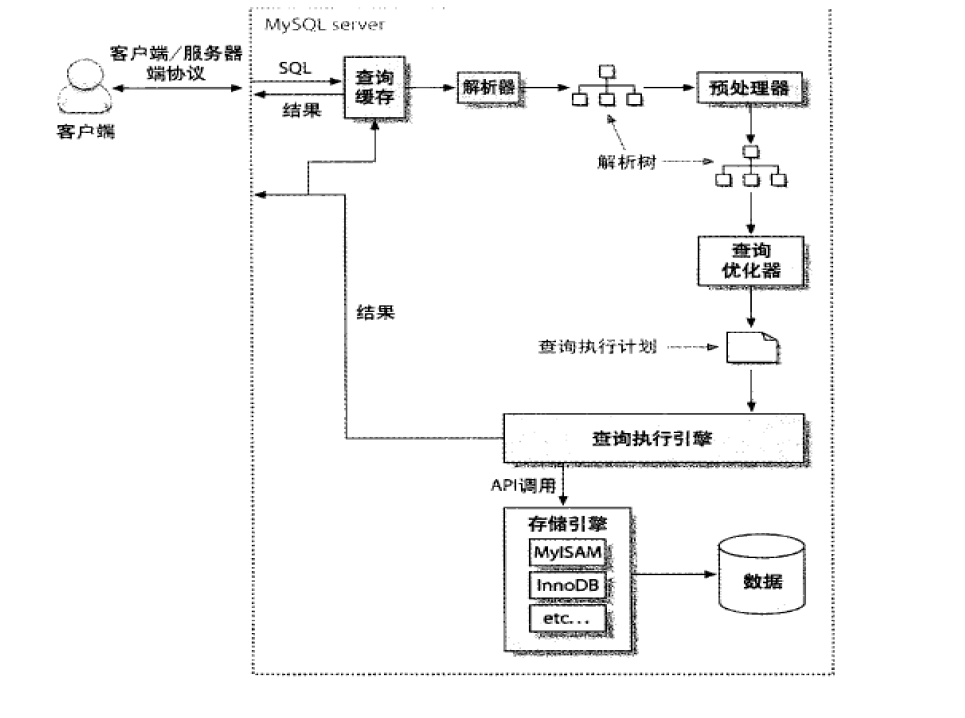
- SQL语句
- 查询缓存
- 解析器
- 解析树
- 预处理
- 查找最好的查询路径
- 查询优化SQL语句
- 执行计划
- API调用存储引擎
- 调用数据,返回结果
缓存SELECT操作或预处理查询的结果集和SQL语句,当有新的SELECT语句或预处理查询语句请求,先去查询缓存,判断是否存在可用的记录集,判断标准:与缓存的SQL语句,是否完全一样,区分大小写。
不需要对SQL语句做任何解析和执行,当然语法解析必须通过在先,直接从Query Cache中获得查询结果,提高查询性能
查询缓存的判断规则,不够智能,也即提高了查询缓存的使用门槛,降低其效率;查询缓存的使用,会增加检查和清理Query Cache中记录集的开销
查询缓存
查询缓存,及将查询结果的缓存下载;如果查询语句完全相同,则直接返回缓存中的结果;
我们可以使用如下语句,查看当前服务是否开启了查询缓存功能:
MariaDB [(none)]> SHOW VARIABLES LIKE '%query_cache%'; +------------------------------+----------+ | Variable_name | Value | +------------------------------+----------+ | have_query_cache | YES | | query_cache_limit | 1048576 | | query_cache_min_res_unit | 4096 | | query_cache_size | 33554432 | | query_cache_strip_comments | OFF | | query_cache_type | ON | | query_cache_wlock_invalidate | OFF | +------------------------------+----------+ 7 rows in set (0.10 sec)
可以看到,query_cache_type的值为ON,也就是目前已经开启了查询缓存功能;
query_cache_type的值可以设置为:ON、OFF、DEMAND,分别为已启动、已禁用和按需缓存,在文件my.cnf中设置即可;
vim /etc/my.cnf [mysqld]中添加: query_cache_type = ON
have_query_cache表示当前数据库是否支持缓存功能;值为YES
query_cache_limit表示单条查询缓存的最大值,如果查询结果超过此大小,即使指定缓存当前结果,结果也不会被缓存;默认为1M
query_cache_min_res_unit表示缓存存储于内存的最小单元,默认为4K,如果查询结果小于4K,也会占用4k内存,所以设置过大会存内存空间的浪费,设置过小,则会频繁分配内存待遇按或频发的回收
query_cache_size表示查询缓存的总大小
query_cache_wlock_invalidate表示所查询的表如果被写锁锁定,是否使用缓存返回结构
只有查询语句完全相同时,缓存才能够被命中;查询SQL语句相同,大小写不同即算不同;
MariaDB [(none)]> select * from stu; MariaDB [(none)]> SELECT * FROM stu;
MySQL在收到查询请求时,会对查询语句进行hash计算,计算出对应的hash,通过这个hash值查找是否存在对应的缓存,所以,即使查询语句的大小写不同,也会被认为是不同的查询语句;当前hash码没有命中对应的缓存,mysql则会将对应的hash值放在对应的hash表中,同时将查询结果存放在对应的缓存中,如果查询语句的hash值命中了对应缓存项,则之间从缓存中返回响应结果,如果缓存对应的表中的数据发生了变化,那么查询缓存中,所有与变化的数据表有关的缓存都将失效;
那么,我们该如何灵活使用缓存呢;可用如下方法;
在开启缓存时(query_cache_type=ON),指定对应的查询语句不使用缓存
MariaDB [(none)]> select sql_no_cache name from stu;
也可在按需使用缓存时(query_cache_type=DEMAND),,之地==指定对应的查询语句使用缓存
MariaDB [(none)]> select sql_cache name from stu;
查看缓存使用情况
MariaDB [(none)]> SHOW status LIKE 'qcache%'; +-------------------------+----------+ | Variable_name | Value | +-------------------------+----------+ | Qcache_free_blocks | 1 | | Qcache_free_memory | 33536824 | | Qcache_hits | 0 | | Qcache_inserts | 0 | | Qcache_lowmem_prunes | 0 | | Qcache_not_cached | 27 | | Qcache_queries_in_cache | 0 | | Qcache_total_blocks | 1 | +-------------------------+----------+ 8 rows in set (0.33 sec)
其中各个参数的意义如下:
Qcache_free_blocks:缓存中相邻内存块的个数。数目大说明可能有碎片。FLUSH QUERY CACHE会对缓存中的碎片进行整理,从而得到一个空闲块。
Qcache_free_memory:缓存中的空闲内存。
Qcache_hits:每次查询在缓存中命中时就增大
Qcache_inserts:每次插入一个查询时就增大。命中次数除以插入次数就是不中比率。
Qcache_lowmem_prunes:缓存出现内存不足并且必须要进行清理以便为更多查询提供空间的次数。这个数字最好长时间来看;如果这个 数字在不断增长,就表示可能碎片非常严重,或者内存很少。(上面的 free_blocks和free_memory可以告诉您属于哪种情况)
Qcache_not_cached:不适合进行缓存的查询的数量,通常是由于这些查询不是 SELECT 语句或者用了now()之类的函数。
Qcache_queries_in_cache:当前缓存的查询(和响应)的数量。
Qcache_total_blocks:缓存中块的数量。
通过上述统计信息的数值,以及缓存设置相关值,计算出查询缓存的相关指标,从而判断查询缓存是否对我们有一定帮助;一切以实际生产为准
查询缓存的碎片率 = ( Qcache_free_blocks / Qcache_total_blocks ) * 100%
查询缓存利用率 = ( query_cache_size - Qcache_free_memory ) / query_cache_size * 100%
由上述两个公式可以推断出;如果Qcache_free_memory缓存中块的数量越大,则碎片率越高,可以尝试适当调小query_cache_min_res_unit值,或及时清理缓存碎片。
清理缓存碎片:
MariaDB [(none)]> FLUSH QUERY CACHE
如果想要清除查询缓存中已经存在的缓存,可用使用
从查询缓存中移除所有查询结果的缓存
MariaDB [(none)]> RESET QUERY CACHE;
如果查询缓存利用率太低,则表示query_cache_size设置过大,可适当调小,如果缓存利用率非常
高,同时Qcache_lowmem_prunes的值较大,则表示query_cache_size设置略小。
如果在调整query_cache_min_res_unit值时不确定调整为多大;可以参考如下公式
( query_cache_size - Qcache_free_memory ) / Qcache_queries_in_cache
查询缓存命中率 = ( Qcache_hits / Com_select ) * 100%
其中Com_select表示查询语句的执行次数(此描述并不准确;应是Qcache_hits + Qcache_inserts),可用如下语句获得查询语句执行次数
show status like "Com_select%";
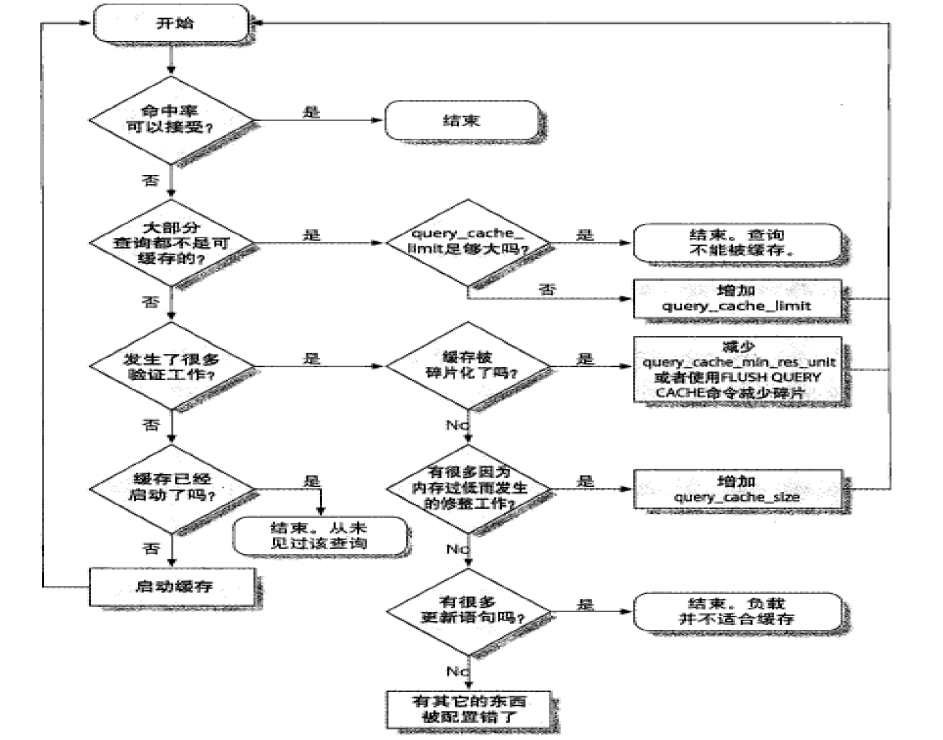
优化查询缓存