

0.3kubeadm部署高可用kubernetes集群(Ubuntu)
kubeadm安装Kubernetes
0.部署环境&需求
kubeadm介绍
git地址:https://github.com/kubernetes/kubeadm
文档地址:https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
部署版本 kubernetes1.18
| IP | Hostname | 内核 | CPU&Memory | 系统版本 | 备注 |
|---|---|---|---|---|---|
| 192.168.121.81 | k8s-master01 | 4.15.0-76-generic | 4C&16M | 18.04 | control plane |
| 192.168.121.82 | k8s-master02 | 4.15.0-76-generic | 4C&16M | 18.04 | control plane |
| 192.168.121.83 | k8s-master03 | 4.15.0-76-generic | 4C&16M | 18.04 | control plane |
| 192.168.121.84 | k8s-node01 | 4.15.0-76-generic | 4C&16M | 18.04 | worker nodes |
| 192.168.121.85 | k8s-node02 | 4.15.0-76-generic | 4C&16M | 18.04 | worker nodes |
| 192.168.121.86 | k8s-node03 | 4.15.0-76-generic | 4C&16M | 18.04 | worker nodes |
| 192.168.121.88 | ha01 | haproxy&keepalive | |||
| 192.168.121.89 | ha02 | haproxy&keepalive | |||
| 192.168.121.80 | v1.3.5 | vip |
1.系统初始化
1.1.主机名
设置永久主机名称,然后重新登录:
hostnamectl set-hostname k8s-master01 # 将 k8s-master01 替换为当前主机名
- 设置的主机名保存在
/etc/hostname文件中;
如果 DNS 不支持解析主机名称,则需要修改每台机器的 /etc/hosts 文件,添加主机名和 IP 的对应关系:
]# cat >> /etc/hosts <<EOF
192.168.121.81 k8s-master01
192.168.121.82 k8s-master02
192.168.121.83 k8s-master03
192.168.121.84 k8s-node01
192.168.121.85 k8s-node02
192.168.121.86 k8s-node03
EOF
1.2.添加 docker 账户
在每台机器上添加 docker 账户:
useradd -m docker
1.3.无密码 ssh 登录其它节点
如果没有特殊指明,本文档的所有操作均在 k8s-master01 节点上执行,然后远程分发文件和执行命令,所以需要添加该节点到其它节点的 ssh 信任关系。
设置 k8s-master 的 root 账户可以无密码登录所有节点:
# apt-get install python2.7
# ln -s /usr/bin/python2.7 /usr/bin/python
# apt-get install git ansible -y
# ssh-keygen #生成密钥对
# apt-get install sshpass #ssh同步公钥到各k8s服务器
#分发公钥脚本:
root@k8s-master1:~# cat scp.sh
#!/bin/bash
#目标主机列表
IP="
192.168.121.81
192.168.121.82
192.168.121.83
192.168.121.84
192.168.121.85
192.168.121.86
"
for node in ${IP};do
sshpass -p 123456 ssh-copy-id ${node} -o StrictHostKeyChecking=no
if [ $? -eq 0 ];then
echo "${node} 秘钥copy完成"
else
echo "${node} 秘钥copy失败"
fi
done
1.4.更新 PATH 变量
将可执行文件目录添加到 PATH 环境变量中:
echo 'PATH=/opt/k8s/bin:$PATH' >>/root/.bashrc
source /root/.bashrc
1.5.安装依赖包
在每台机器上安装依赖包:
apt install -y conntrack ntpdate ntp ipvsadm ipset jq iptables curl sysstat libseccomp wget
1.6.关闭防火墙
在每台机器上关闭防火墙,清理防火墙规则,设置默认转发策略:
systemctl stop firewalld
systemctl disable firewalld
iptables -F && iptables -X && iptables -F -t nat && iptables -X -t nat
iptables -P FORWARD ACCEPT
1.7.关闭 swap 分区
如果开启了 swap 分区,kubelet 会启动失败(可以通过将参数 --fail-swap-on 设置为 false 来忽略 swap on),故需要在每台机器上关闭 swap 分区。同时注释 /etc/fstab 中相应的条目,防止开机自动挂载 swap 分区:
swapoff -a
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
1.9.加载内核模块
modprobe ip_vs_rr
modprobe br_netfilter
1.10.优化内核参数
cat > kubernetes.conf <<EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0 # 禁止使用 swap 空间,只有当系统 OOM 时才允许使用它
vm.overcommit_memory=1 # 不检查物理内存是否够用
vm.panic_on_oom=0 # 开启 OOM
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
cp kubernetes.conf /etc/sysctl.d/kubernetes.conf
sysctl -p /etc/sysctl.d/kubernetes.conf
- 必须关闭 tcp_tw_recycle,否则和 NAT 冲突,会导致服务不通;
- 关闭 IPV6,防止触发 docker BUG;
1.11.设置系统时区
# 调整系统 TimeZone
]# timedatectl set-timezone Asia/Shanghai
# 将当前的 UTC 时间写入硬件时钟
]# timedatectl set-local-rtc 0
### 重启依赖于系统时间的服务
]# systemctl restart rsyslog
]# systemctl restart crond
1.14.文件最大数
]# cat>/etc/security/limits.d/kubernetes.conf<<EOF
* soft nproc 131072
* hard nproc 131072
* soft nofile 131072
* hard nofile 131072
root soft nproc 131072
root hard nproc 131072
root soft nofile 131072
root hard nofile 131072
EOF
1.15.关闭swap
vim /etc/default/grub
#找到GRUB_CMDLINE_LINUX=配置项,并追加
cgroup_enable=memory swapaccount=1
注意
如果GRUB_CMDLINE_LINUX=内有内容,切记不可删除,只需在后面追加cgroup_enable=memory swapaccount=1并用空格和前面的内容分隔开。<br>
#配置如下
GRUB_CMDLINE_LINUX="net.ifnames=0 console=tty0 console=ttyS0,115200n8 cgroup_enable=memory swapaccount=1"
#保存,升级grub
sudo update-grub
2.部署准备
2.1.部署haproxy&keepalived
k8s-master节点都执行本部分操作。
安装keepalived&haproxy
]# apt install -y keepalived haproxy
#注意查看是否有如下参数
]# echo 'net.ipv4.ip_nonlocal_bind = 1'>>/etc/sysctl.conf
]# sysctl -p
haproxy配置
ha01上haproxy配置:
listen k8s-api-6443
bind 192.168.121.80:6443
mode tcp
server master1 192.168.121.81 check inter 3s fall 3 rise 5
server master2 192.168.121.82 check inter 3s fall 3 rise 5
server master3 192.168.121.83 check inter 3s fall 3 rise 5
ha02上haproxy配置:
listen k8s-api-6443
bind 192.168.121.80:6443
mode tcp
server master1 192.168.121.81 check inter 3s fall 3 rise 5
server master2 192.168.121.82 check inter 3s fall 3 rise 5
server master3 192.168.121.83 check inter 3s fall 3 rise 5
keepalived配置
ha01上keepalived配置:
cp /usr/share/doc/keepalived/samples/keepalived.conf.vrrp /etc/keepalived/keepalived.conf
[root@master01 ~]# more /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id master01
}
vrrp_script chk_http_port {
script "/etc/keepalived/check_haproxy.sh"
initerval 2
weight 2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.121.80
}
}
ha02上keepalived配置:
cp /usr/share/doc/keepalived/samples/keepalived.conf.vrrp /etc/keepalived/keepalived.conf
[root@master02 ~]# more /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id master02
}
vrrp_script chk_http_port {
script "/etc/keepalived/check_haproxy.sh"
initerval 2
weight 2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 50
priority 51
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.121.80
}
}
检查脚本
#!/bin/bash
if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ]; then
systemctl start haproxy
fi
sleep 2
if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ]; then
systemctl stop keepalived
fi
启动keepalived
所有k8s-mster节点启动keepalived服务并设置开机启动
]# service keepalived start
]# systemctl enable keepalived
VIP查看
]# ip a
确保vip在master01上;否则在初始化安装会无法连接api-server
2.2.部署Docker
每台机器上安装Docker。
# step 1: 安装必要的一些系统工具
sudo apt-get update
sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common
# step 2: 安装GPG证书
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
# Step 3: 写入软件源信息
sudo add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
# Step 4: 更新并安装Docker-CE
sudo apt-get -y update
sudo apt-get -y install docker-ce
# 安装指定版本的Docker-CE:
# Step 1: 查找Docker-CE的版本:
# apt-cache madison docker-ce
# docker-ce | 17.03.1~ce-0~ubuntu-xenial | https://mirrors.aliyun.com/docker-ce/linux/ubuntu xenial/stable amd64 Packages
# docker-ce | 17.03.0~ce-0~ubuntu-xenial | https://mirrors.aliyun.com/docker-ce/linux/ubuntu xenial/stable amd64 Packages
# Step 2: 安装指定版本的Docker-CE: (VERSION例如上面的17.03.1~ce-0~ubuntu-xenial)
# sudo apt-get -y install docker-ce=[VERSION]
镜像下载加速:
]# curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://f1361db2.m.daocloud.io
设置cgroup驱动,推荐systemd:
mkdir -p /etc/docker
cat > /etc/docker/daemon.json <<EOF
{
"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn","http://f1361db2.m.daocloud.io"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {"max-size": "100m"},
"storage-driver": "overlay2",
"data-root":"/docker"
}
EOF
systemctl enable docker
systemctl start docker
修改cgroupdriver是为了消除告警:
[WARNING IsDockerSystemdCheck]: detected “cgroupfs” as the Docker cgroup driver. The recommended driver is “systemd”. Please follow the guide at https://kubernetes.io/docs/setup/cri/
启动&验证
systemctl enable --now docker
docker --version
Docker version 18.09.9, build 039a7df9ba
2.3.部署管理工具kubeadm
在所有节点操作
apt-get update && apt-get install -y apt-transport-https
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
echo "deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main" > /etc/apt/sources.list.d/kubernetes.list
apt-get update
master节点
apt install kubeadm=1.18.9-00 kubelet=1.18.9-00 kubectl=1.18.9-00
apt-mark hold kubelet kubeadm kubectl
sudo systemctl daemon-reload
sudo systemctl enable kubelet && systemctl restart kubelet
node节点
apt install kubeadm=1.18.9-00 kubelet=1.18.9-00 -y
apt-mark hold kubelet kubeadm
sudo systemctl daemon-reload
sudo systemctl enable kubelet && systemctl restart kubelet
编辑配置文件
vim /var/lib/kubelet/kubeadm-flags.env
KUBELET_KUBEADM_ARGS="--network-plugin=cni --pod-infra-container-image=k8s.gcr.io/pause:3.2 --resolv-conf=/run/systemd/resolve/resolv.conf"
命令补全
#设置kubectl补全
apt install -y bash-completion
kubectl completion bash > /etc/bash_completion.d/kubectl
source /etc/bash_completion.d/kubectl
echo "source /etc/bash_completion.d/kubectl" >> /etc/profile
#设置kubeadm命令补全
mkdir /data/scripts -p
kubeadm completion bash > /etc/bash_completion.d/kubeadm
source /etc/bash_completion.d/kubeadm
chmod +x /etc/bash_completion.d/kubeadm
echo "source /etc/bash_completion.d/kubeadm" >> /etc/profile
下载镜像
镜像下载的脚本
Kubernetes几乎所有的安装组件和Docker镜像都放在goolge自己的网站上,直接访问可能会有网络问题,这里的解决办法是从阿里云镜像仓库下载镜像,拉取到本地以后改回默认的镜像tag。本文通过运行image.sh脚本方式拉取镜像。
#查看所需下载镜像列表
kubeadm config images list --kubernetes-version v1.18.9
W0131 12:13:12.391533 35517 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
k8s.gcr.io/kube-apiserver:v1.18.9
k8s.gcr.io/kube-controller-manager:v1.18.9
k8s.gcr.io/kube-scheduler:v1.18.9
k8s.gcr.io/kube-proxy:v1.18.9
k8s.gcr.io/pause:3.2
k8s.gcr.io/etcd:3.4.3-0
k8s.gcr.io/coredns:1.6.7
#提前准备镜像
more image.sh
#!/bin/bash
url=registry.aliyuncs.com/google_containers
version=v1.18.9
images=(`kubeadm config images list --kubernetes-version=$version|awk -F '/' '{print $2}'`)
for imagename in ${images[@]} ; do
docker pull $url/$imagename
docker tag $url/$imagename k8s.gcr.io/$imagename
docker rmi -f $url/$imagename
done
url为阿里云镜像仓库地址,version为安装的kubernetes版本。
下载镜像
运行脚本image.sh,下载指定版本的镜像
]# chmod +x image.sh
]# ./image.sh
]# docker images
3.初始化Master&Node
命令初始化
单节点master初始化
kubeadm init --apiserver-advertise-address=192.168.121.81 \
--apiserver-bind-port=6443 \
--kubernetes-version=v1.18.9 \
--pod-network-cidr=10.244.0.0/16 \
--image-repository=registry.aliyuncs.com/google_containers \
--ignore-preflight-errors=swap
高可用master初始化
kubeadm init --apiserver-advertise-address=192.168.121.81 \
--control-plane-endpoint=192.168.121.88 \
--apiserver-bind-port=6443 \
--kubernetes-version=v1.18.9 \
--pod-network-cidr=10.244.0.0/16 \
--image-repository=registry.aliyuncs.com/google_containers \
--ignore-preflight-errors=swap
配置初始化文件
#查看初始化配置文件;并在此基础上修改
kubeadm config print init-defaults
参考配置
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 48h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 106.3.146.200
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: kubeadm-master1
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
#vip地址
controlPlaneEndpoint: 106.3.146.197
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.18.0
networking:
dnsDomain: cluster.local
#注意与flannel保持一直
podSubnet: 10.244.0.0/16
serviceSubnet: 192.168.0.0/20
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs #启动ipvs mode;默认iptables mode
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: "rr"
strictARP: false
syncPeriod: 15s
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
failSwapOn: true
3.2.master初始化
检查文件是否错误,忽略warning,错误的话会抛出error
]# kubeadm init --config /root/initconfig.yaml --dry-run
进行初始化
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 192.168.121.80:6443 --token k6erho.mvlpk16k4gif5qix \
--discovery-token-ca-cert-hash sha256:d74fe5173f3c8499900c77f2694c2e8e72a83eaa38e1c3f0a3a9460b9139c1ca \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.121.80:6443 --token k6erho.mvlpk16k4gif5qix \
--discovery-token-ca-cert-hash sha256:d74fe5173f3c8499900c77f2694c2e8e72a83eaa38e1c3f0a3a9460b9139c1ca
复制kubectl的kubeconfig,kubectl的kubeconfig路径默认是~/.kube/config
]# mkdir -p $HOME/.kube
]# sudo cp /etc/kubernetes/admin.conf $HOME/.kube/config
]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
init的yaml信息实际上会存在集群的configmap里,我们可以随时查看,该yaml在其他node和master join的时候会使用到
kubectl -n kube-system get cm kubeadm-config -o yaml
加载环境变量
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source .bash_profile
配置其余k8s-master
#添加master节点
#生成证书key
kubeadm init phase upload-certs --upload-certs
......
[upload-certs] Using certificate key:
9b663baef77427839c4b9da5ad435c701dc89e23a1e2fc2bb6ff366442a96a1c
#添加master节点
kubeadm join 192.168.121.80:6443 --token k6erho.mvlpk16k4gif5qix \
--discovery-token-ca-cert-hash sha256:d74fe5173f3c8499900c77f2694c2e8e72a83eaa38e1c3f0a3a9460b9139c1ca \
--control-plane --certificate-key 9b663baef77427839c4b9da5ad435c701dc89e23a1e2fc2bb6ff366442a96a1c
#添加node节点
kubeadm join 192.168.121.80:6443 --token k6erho.mvlpk16k4gif5qix \
--discovery-token-ca-cert-hash sha256:d74fe5173f3c8499900c77f2694c2e8e72a83eaa38e1c3f0a3a9460b9139c1ca
3.3.node初始化
在node节点执行
和master的join一样,提前准备好环境和docker,然后join的时候不需要带--control-plane
kubeadm join 192.168.121.80:6443 --token k6erho.mvlpk16k4gif5qix \
--discovery-token-ca-cert-hash sha256:d74fe5173f3c8499900c77f2694c2e8e72a83eaa38e1c3f0a3a9460b9139c1ca
3.4.初始化失败
如果初始化失败,可执行kubeadm reset后重新初始化
]# kubeadm reset
]# rm -rf $HOME/.kube/config
3.5.node节点标签
kubectl label node k8s-node01 node-role.kubernetes.io/worker=worker
4.配置etcdctl
4.1.复制出容器里的etcdctl
]# docker cp `docker ps -a | awk '/k8s_etcd/{print $1}'`:/usr/local/bin/etcdctl /usr/local/bin/etcdctl
]# cat >/etc/profile.d/etcd.sh<<'EOF'
ETCD_CERET_DIR=/etc/kubernetes/pki/etcd/
ETCD_CA_FILE=ca.crt
ETCD_KEY_FILE=healthcheck-client.key
ETCD_CERT_FILE=healthcheck-client.crt
ETCD_EP=https://192.168.121.81:2379,https://192.168.121.82:2379,https://192.168.121.83:2379
alias etcd_v3="ETCDCTL_API=3 \
etcdctl \
--cert ${ETCD_CERET_DIR}/${ETCD_CERT_FILE} \
--key ${ETCD_CERET_DIR}/${ETCD_KEY_FILE} \
--cacert ${ETCD_CERET_DIR}/${ETCD_CA_FILE} \
--endpoints $ETCD_EP"
EOF
source /etc/profile.d/etcd.sh
etcd_v3 endpoint status --write-out=table
+-----------------------------+------------------+---------+---------+-----------+-----------+------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | RAFT TERM | RAFT INDEX |
+-----------------------------+------------------+---------+---------+-----------+-----------+------------+
| https://192.168.121.81:2379 | d572bef816d9cb7e | 3.3.15 | 3.2 MB | false | 52 | 64002 |
| https://192.168.121.82:2379 | a4b42aafeef9bab3 | 3.3.15 | 3.2 MB | true | 52 | 64002 |
| https://192.168.121.83:2379 | c5d52def73f50ceb | 3.3.15 | 3.2 MB | false | 52 | 64002 |
+-----------------------------+------------------+---------+---------+-----------+-----------+------------+
etcd_v3 endpoint health --write-out=table
+-----------------------------+--------+-------------+-------+
| ENDPOINT | HEALTH | TOOK | ERROR |
+-----------------------------+--------+-------------+-------+
| https://192.168.121.82:2379 | true | 28.336842ms | |
| https://192.168.121.81:2379 | true | 29.132682ms | |
| https://192.168.121.83:2379 | true | 47.635089ms | |
+-----------------------------+--------+-------------+-------+
4.2.配置etcd备份脚本
mkdir -p /opt/etcd
cat>/opt/etcd/etcd_cron.sh<<'EOF'
#!/bin/bash
set -e
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
: ${bak_dir:=/root/} #缺省备份目录,可以修改成存在的目录
: ${cert_dir:=/etc/kubernetes/pki/etcd/}
: ${endpoints:=https://192.168.121.81:2379,https://192.168.121.82:2379,https://192.168.121.83:2379}
bak_prefix='etcd-'
cmd_suffix='date +%Y-%m-%d-%H:%M'
bak_suffix='.db'
#将规范化后的命令行参数分配至位置参数($1,$2,...)
temp=`getopt -n $0 -o c:d: -u -- "$@"`
[ $? != 0 ] && {
echo '
Examples:
# just save once
bash $0 /tmp/etcd.db
# save in contab and keep 5
bash $0 -c 5
'
exit 1
}
set -- $temp
# -c 备份保留副本数量
# -d 指定备份存放目录
while true;do
case "$1" in
-c)
[ -z "$bak_count" ] && bak_count=$2
printf -v null %d "$bak_count" &>/dev/null || \
{ echo 'the value of the -c must be number';exit 1; }
shift 2
;;
-d)
[ ! -d "$2" ] && mkdir -p $2
bak_dir=$2
shift 2
;;
*)
[[ -z "$1" || "$1" == '--' ]] && { shift;break; }
echo "Internal error!"
exit 1
;;
esac
done
function etcd_v3(){
ETCDCTL_API=3 etcdctl \
--cert $cert_dir/healthcheck-client.crt \
--key $cert_dir/healthcheck-client.key \
--cacert $cert_dir/ca.crt \
--endpoints $endpoints $@
}
etcd::cron::save(){
cd $bak_dir/
etcd_v3 snapshot save $bak_prefix$($cmd_suffix)$bak_suffix
rm_files=`ls -t $bak_prefix*$bak_suffix | tail -n +$[bak_count+1]`
if [ -n "$rm_files" ];then
rm -f $rm_files
fi
}
main(){
[ -n "$bak_count" ] && etcd::cron::save || etcd_v3 snapshot save $@
}
main $@
EOF
crontab -e添加下面内容自动保留四个备份副本
crontab -e 0 0 * * * bash /opt/etcd/etcd_cron.sh -c 4 -d /opt/etcd/ &>/dev/null
5.部署插件
5.1.网络查件
5.1.1部署flannel网络
新建flannel网络
https://github.com/coreos/flannel
]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
由于网络原因,可能会安装失败,建议更换image源,然后再执行apply
5.1.2部署Calico网络(可选)
https://github.com/projectcalico/calico
]# curl https://docs.projectcalico.org/v3.9/manifests/calico-etcd.yaml -o calico.yaml
修改yaml文件、并部署
]# sed -i -e "s@192.168.0.0/16@10.244.0.0/16@g" calico.yaml
]# kubectl apply -f calico.yaml
5.2.Web UI(Dashboard搭建)
5.2.1进行配置
下载yaml
]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0/aio/deploy/recommended.yaml
配置yaml
修改镜像地址
sed -i 's/registry.aliyuncs.com\/google_containers/g' recommended.yaml
由于默认的镜像仓库网络访问不通,故改成阿里镜像
外网访问
sed -i '/targetPort: 8443/a\ \ \ \ \ \ nodePort: 30001\n\ \ type: NodePort' recommended.yaml
配置NodePort,外部通过https://NodeIp:NodePort 访问Dashboard,此时端口为30001
或使用ingress 访问
新增管理员帐号
]# cat >> recommended.yaml << EOF
---
# ------------------- dashboard-admin ------------------- #
apiVersion: v1
kind: ServiceAccount
metadata:
name: dashboard-admin
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: dashboard-admin
subjects:
- kind: ServiceAccount
name: dashboard-admin
namespace: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
EOF
创建超级管理员的账号用于登录Dashboard
5.2.2部署访问
部署Dashboard
kubectl apply -f recommended.yaml
状态查看
kubectl get all -n kubernetes-dashboard
令牌查看
创建service account并绑定默认cluster-admin管理员集群角色:
kubectl describe secrets -n kubernetes-dashboard $(kubectl -n kubernetes-dashboard get secret | awk '/dashboard-admin/{print $1}')
使用输出的token登录Dashboard,使用火狐浏览。
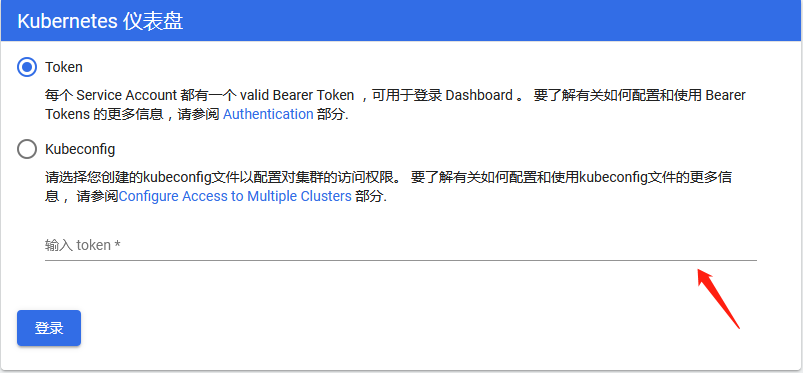
关于不能使用google
注意部署Dashboard的命名空间(之前部署默认是kube-system,新版是kubernetes-dashboard)
##1、删除默认的secret,用自签证书创建新的secret
kubectl delete secret kubernetes-dashboard-certs -n kubernetes-dashboard
kubectl create secret generic kubernetes-dashboard-certs \
--from-file=/etc/kubernetes/pki/apiserver.key --from-file=/etc/kubernetes/pki/apiserver.crt -n kubernetes-dashboard
##2、修改 dashboard.yaml 文件,在args下面增加证书两行
args:
# PLATFORM-SPECIFIC ARGS HERE
- --auto-generate-certificates
- --tls-key-file=apiserver.key
- --tls-cert-file=apiserver.crt
kubectl apply -f kubernetes-dashboard.yaml
5.3.metric-service部署
官方YAML
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/metrics-server
#从官方YAML文件中下载以下文件
[root@k8s-master metrics]# ll
total 24
-rw-r--r-- 1 root root 398 Mar 22 02:52 auth-delegator.yaml
-rw-r--r-- 1 root root 419 Mar 22 02:52 auth-reader.yaml
-rw-r--r-- 1 root root 393 Mar 22 02:53 metrics-apiservice.yaml
-rw-r--r-- 1 root root 2905 Mar 22 03:46 metrics-server-deployment.yaml
-rw-r--r-- 1 root root 336 Mar 22 02:53 metrics-server-service.yaml
-rw-r--r-- 1 root root 817 Mar 22 03:53 resource-reader.yaml
#修改下面这个文件的部分内容
[root@k8s-master metrics]# vim metrics-server-deployment.yaml
#在metrics-server这个容器字段里面修改command为如下:
spec:
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
containers:
- name: metrics-server
image: k8s.gcr.io/metrics-server-amd64:v0.3.1
command:
- /metrics-server
- --metric-resolution=30s
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP
#再修改metrics-server-nanny容器中的cpu和内存值,如下:
command:
- /pod_nanny
- --config-dir=/etc/config
- --cpu=100m
- --extra-cpu=0.5m
- --memory=100Mi
- --extra-memory=50Mi
- --threshold=5
- --deployment=metrics-server-v0.3.1
- --container=metrics-server
- --poll-period=300000
- --estimator=exponential
- --minClusterSize=10
#由于启动容器还需要权限获取数据,需要在resource-reader.yaml文件中增加nodes/stats
[root@k8s-master metrics]# vim resource-reader.yaml
....
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- nodes/stats
- namespaces
#部署开始
[root@k8s-master metrics]# kubectl apply -f .
[root@k8s-master metrics]# kubectl api-versions |grep metrics
metrics.k8s.io/v1beta1
#检查资源指标API的可用性
[root@k8s-master metrics]# kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes"
{"kind":"NodeMetricsList","apiVersion":"metrics.k8s.io/v1beta1","metadata":{"selfLink":"/apis/metrics.k8s.io/v1beta1/nodes"},"items":[{"metadata":{"name":"k8s-master","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-master","creationTimestamp":"2019-03-22T08:12:44Z"},"timestamp":"2019-03-22T08:12:10Z","window":"30s","usage":{"cpu":"522536968n","memory":"1198508Ki"}},{"metadata":{"name":"k8s-node01","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-node01","creationTimestamp":"2019-03-22T08:12:44Z"},"timestamp":"2019-03-22T08:12:08Z","window":"30s","usage":{"cpu":"70374658n","memory":"525544Ki"}},{"metadata":{"name":"k8s-node02","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-node02","creationTimestamp":"2019-03-22T08:12:44Z"},"timestamp":"2019-03-22T08:12:11Z","window":"30s","usage":{"cpu":"68437841n","memory":"519756Ki"}}]}
#确保Pod对象运行正常
[root@k8s-master metrics]# kubectl get pods -n kube-system |grep metrics
metrics-server-v0.3.1-5977577c75-wrcrt 2/2 Running 0 22m
以上如果内容没有做修改的话,会出现容器跑不起来一直处于CrashLoopBackOff状态,或者出现权限拒绝的问题。可以通过kubectl logs进行查看相关的日志。下面使用kubectl top命令进行查看资源信息:
[root@k8s-master metrics]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master 497m 12% 1184Mi 68%
k8s-node01 81m 8% 507Mi 58%
k8s-node02 63m 6% 505Mi 57%
[root@k8s-master metrics]# kubectl top pod -l k8s-app=kube-dns --containers=true -n kube-system
POD NAME CPU(cores) MEMORY(bytes)
coredns-78fcdf6894-nmcmz coredns 5m 12Mi
coredns-78fcdf6894-p5pfm coredns 5m 15Mi
5.4.helm部署
5.4.1部署Helm(2.x版本)
kubectl create serviceaccount tiller --namespace kube-system
kubectl create clusterrolebinding tiller-cluster-rule --clusterrole=cluster-admin --serviceaccount=kube-system:tiller
https://get.helm.sh/helm-v2.10.0-linux-amd64.tar.gz
#二进制包cpoy到
/usr/local/bin/
helm init --wait --service-account tiller
kubectl get pods -n kube-system |grep tiller
#安装完成后,执行helm version可以看到客户端和服务端的版本号,两个都显示表示正常安装。
helm version
5.4.2部署Helm客户端
Helm客户端下载地址:https://github.com/helm/helm/releases
解压移动到/usr/bin/目录即可。
wget https://get.helm.sh/helm-v3.0.0-linux-amd64.tar.gz
tar zxvf helm-v3.0.0-linux-amd64.tar.gz
mv linux-amd64/helm /usr/bin/
5.5.Ingress Controller部署
5.5.1yaml部署
Ingress Controller有很多实现,我们这里采用官方维护的Nginx控制器。
GitHub地址:https://github.com/kubernetes/ingress-nginx
部署文档:https😕/github.com/kubernetes/ingress-nginx/blob/master/docs/deploy/index.md
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.30.0/deploy/static/mandatory.yaml
注意事项:
- 镜像地址修改成国内的
- 使用宿主机网络:hostNetwork: true
# kubectl apply -f ingress-controller.yaml
# kubectl get pods -n ingress-nginx
NAME READY STATUS RESTARTS AGE
nginx-ingress-controller-5r4wg 1/1 Running 0 13s
nginx-ingress-controller-x7xdf 1/1 Running 0 13s
80和443端口就是接收来自外部访问集群中应用流量,转发对应的Pod上。
Kubernetes在安装部署中,需要从k8s.grc.io仓库中拉取所需镜像文件,但由于国内网络防火墙问题导致无法正常拉取。 docker.io仓库对google的容器做了镜像,可以通过下列命令下拉取相关镜像:
[root@k8s-node01 ~]# docker pull mirrorgooglecontainers/defaultbackend-amd64:1.5
1.5: Pulling from mirrorgooglecontainers/defaultbackend-amd64
9ecb1e82bb4a: Pull complete
Digest: sha256:d08e129315e2dd093abfc16283cee19eabc18ae6b7cb8c2e26cc26888c6fc56a
Status: Downloaded newer image for mirrorgooglecontainers/defaultbackend-amd64:1.5
[root@k8s-node01 ~]# docker tag mirrorgooglecontainers/defaultbackend-amd64:1.5 k8s.gcr.io/defaultbackend-amd64:1.5
[root@k8s-node01 ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
mirrorgooglecontainers/defaultbackend-amd64 1.5 b5af743e5984 34 hours ago 5.13MB
k8s.gcr.io/defaultbackend-amd64 1.5 b5af743e5984 34 hours ago 5.13MB
5.5.2helm部署
https://github.com/helm/charts/tree/master/stable/nginx-ingress
#仓库pull后,内容很多,找到nginx-ingress
#安装的时候以下指令这样
helm install stable/nginx-ingress --set controller.hostNetwork=true,controller.kind=DaemonSet
优化ingress timeout
kubectl edit ingress antiddos-op-service
添加:
annotations:
nginx.ingress.kubernetes.io/proxy-connect-timeout: "600"
nginx.ingress.kubernetes.io/proxy-read-timeout: "600"
nginx.ingress.kubernetes.io/proxy-send-timeout: "600"
#进入pod查看
kubectl exec -it triangular-rattlesnake-nginx-ingress-controller-nrrp8 bash
