
软工作业2:个人项目——论文查重程序
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade21-34 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade21-34/homework/13023 |
| 这个作业的目标 | 学习并使用PSP模型进行个人开发流程管理,通过项目进一步加深理解和增加实战经验。 |
作业github链接:https://github.com/Glowww-s/Glowww-s/tree/main/3121005262
1 PSP表格
PSP是卡耐基梅隆大学(CMU)的专家们针对软件工程师所提出的一套模型,用于管理个人开发流程。
本次项目的PSP表格如下:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 20 | 15 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 60 |
| · Design Spec | · 生成设计文档 | 60 | 80 |
| · Design Review | · 设计复审 | 30 | 15 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 25 |
| · Design | · 具体设计 | 60 | 47 |
| · Coding | · 具体编码 | 360 | 450 |
| · Code Review | · 代码复审 | 120 | 130 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 60 | 48 |
| · Size Measurement | · 计算工作量 | 30 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 10 |
| · 合计 | 940 | 1070 |
2 需求分析
2.1 命令行参数
程序通过命令行形式运行使用,共需要设定三个命令行参数,依次分别是论文原文的文件的绝对路径、抄袭版论文的文件的绝对路径、输出的答案文件的绝对路径。
2.2 查重算法
需要使用python3或Java或c++语言设计一个论文查重算法:
- 输入:两个文本文件的文本内容。
- 输出:文件2相对文件1的重复率。
2.3 文件输入输出
- 从参数1、2指定路径读取文本文件。
- 将算法计算得到结果输出到参数3指定输出文件。
3 项目设计
3.1 文件结构
- README.md:即本文件,用于说明项目的实施流程、需求分析、设计、测试等内容。
- source:python模块源代码文件夹。
- hit_stopwords.txt:哈工大停用词表。
- keywords.py:分词提取模块文件,用于对文本进行去停用词和分词。
- frequency.py: 统计词频模块文件,用于根据提取词统计文件词频。
- merge.py:合并文档向量模块文件,生成各文件合并后的文档向量。
- similar.py:计算相似度模块文件,计算文档向量间的余弦相似度作为重复率结果。
- tests:测试用例。
- outputs:默认输出结果文件的文件夹。
- result0.txt:默认参数结果文件。
- reports:分析报告文件夹。
- result_analysis.html:程序性能分析可视化展示。
- main.py:主文件,程序运行入口,用于处理IO和调用关系。
- test_main.py:单元测试代码。
- .coverage:单元测试覆盖率数据。
- requirements.txt:程序运行环境所依赖的python软件包列表。
3.2 功能结构
本项目最终需要完成一个论文查重算法的命令行程序,经设计将功能拆分成四个小功能模块实现。
3.2.1 分词提取模块
利用python的第三方库jieba对中文进行拆解分词,再通过网络检索得到的哈工大停用词表对分词结果进行预处理,最终提取其关键词。
该模块共包含五个关键函数,分别是detect_language函数、word_cut函数、get_stopword_list函数、clean_stopword函数、extract_keywords函数,其作用及大致实现如下:
- detect_language函数【输入字符串,输出None】:通过调用langdetect的detect对象对字符串的语言进行检测判断,若检测出非中文字符串则中断程序,输出错误信息并退出。
- word_cut函数【输入字符串,输出字符串列表】:通过调用jieba库的lcut方法对输入字符串进行切割,使用的是默认全切割模式,在保证正确率的前提下,兼顾执行速度。
- get_stopword_list函数【输入停用词文件路径,输出字符串列表】:通过打开指定的停用词表文件,使用列表生成器读取文件内容到一个字符串列表。
- clean_stopword函数【输入两个字符串列表(待处理列表、停用词列表),输出一个字符串列表(处理结果)】。
- extract_keywords函数:【输入两个文件的字符串列表及当前脚本路径,输出处理完成的两个文件的关键词列表】:通过调用上述三个函数对两个文件进行迭代处理,得到按照语义的分词结果,同时去除停用词。
3.2.2 统计词频模块
本模块仅包含一个word_frequency函数【输入两个文件的关键词列表,输出两个文件的关键词频数字典】:利用python的第三方库collections中的Counter类统计得到个文件对应词频。
3.2.3 合并文档向量模块
本模块仅包含一个vector_merge函数【输入两个文件的关键词频数字典,输出两个文件的文档向量字典】:利用python的集合运算和字典生成式对文档向量进行处理合并。
3.2.4 计算相似度模块
本模块仅包含一个cosine_similarity函数【输入两个文件的文档向量字典,输出余弦相似度】:使用python的numpy库计算余弦相似度的方法衡量两个文档向量间的相似性,公式如下:
3.3 程序流程图

3.4 程序优点
- 逻辑简单,方便开发,易于分析调试。
4 分析测试
4.1 运行说明
Prepare:python3.11
-
根据requirements.txt文件配置好程序运行环境。
-
在3121005262文件夹路径下,命令行运行如下命令:
python main.py --text1Path [原文文件] --text2Path [抄袭版论文的文件] --resultPath [答案文件]
若运行成功,将在参数[答案文件]指定路径得到输出结果文件。
注:目前输入仅支持中文内容的txt文本文件。
4.2 测试
4.2.1 单元测试
-
部分代码:
class TestMain(unittest.TestCase): def test_word_frequency(self): """ Test word frequency module """ texts = [['这是', '这是', '测试', '文本', '1'], ['这是', '测试', '测试', '文本', '2']] results = main.word_frequency(texts) self.assertEqual(results, [{'这是': 2, '测试': 1, '文本': 1, '1': 1}, {'这是': 1, '测试': 2, '文本': 1, '2': 1}])
构造两串比较相似但有细微频数差别的短词语文本序列texts作为函数输入,将输出results与预想的频数统计字典作对别,若不等则中断,相等则通过测试。
-
覆盖率表格:
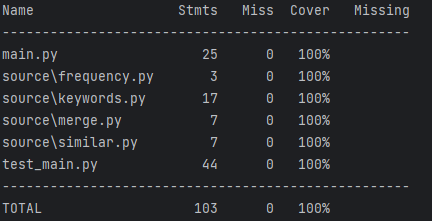
因为程序基本是线性的,且函数封装相对独立,经单元测试后最终的测试覆盖率为100%。
4.3 异常处理
-
文件路径不存在
-
测试:命令行输入
python main.py --text1Path [非法路径] --text2Path [非法路径] -
处理思路:捕获异常并输出对应异常信息,退出程序。
-
结果:输出错误信息”ERROR: 未找到指定文件,请检查参数路径是否存在。“
-
-
输入非txt文本文件
-
测试:命令行输入
python main.py --text1Path ./tests/picture.jpg --text2Path ./tests/picture.jpg -
处理思路:捕获异常并输出对应异常信息,退出程序。
-
结果:输出错误信息”ERROR: 文件编码错误,请检查输入文件是否为txt文本文件。“
-
-
输入非中文文本文件
-
测试:命令行输入
python main.py --text1Path ./tests/English.txt --text2Path ./tests/English_del.txt -
处理思路:由于使用jieba库对文本分词仅支持中文文本,但分词函数输入’utf-8‘编码的英文文本却不会报错,所以需要在输入分词前使用langdetect库对文本语言进行检测(但实际上只能大致确认语言类型)。
-
结果:输出错误信息”ERROR:输入文本语言错误,请检查输入文本是否为中文。“
-
4.4 性能分析
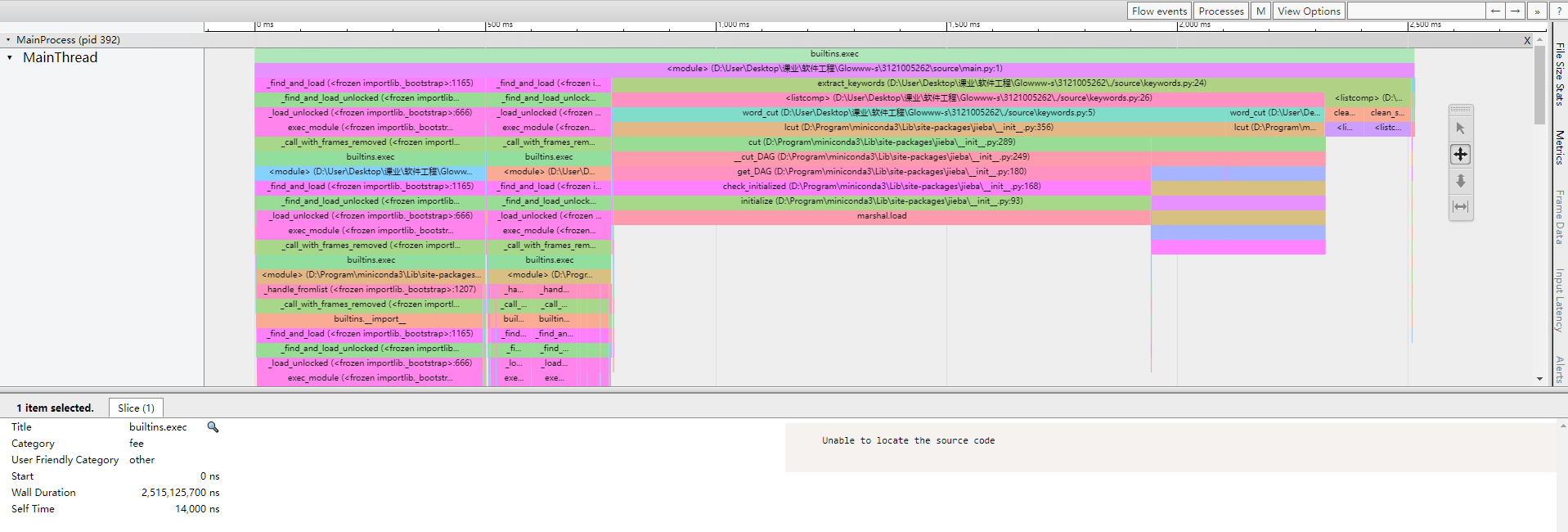
使用Viztracer性能分析工具得到上述程序性能分析报告,分析如下:
- 程序最耗时的部分是jieba库的中文分词功能(即word_cut函数),但其性能已较优,且对第三方库的实现进行优化难度较大,考虑对其余部分进行优化;
- 第二高耗时的部分是去停用词功能(即clean_stopword函数),其使用列表生成式遍历筛选的方式实现,考虑在该部分进行优化。(目前尚未找到较好的优化思路)
5 总结
- 要求内容基本完成。
- 各环节预估时间都和实际工作时间有明显偏差,之后做项目需要充分评估各环节工作量及自身能力。
- 部分环节投入不够充分,导致到了后面的环节需要重新补充完善,之后的各个环节必须确保完成度100%再进入下一环节的工作。
