快速幂、矩阵快速幂、快速乘法
快速幂
快速幂是我们经常用到的一种算法,快速幂顾名思义就是快速的幂运算。我们在很多题目中都会遇到幂运算,但是在指数很大的时候,我们如果用for或者是pow就会超时,这时候就用到了快速幂。
快速幂的原理就是,当求b^p的时候,如果p是一个奇数,那么我们就可以把它拆成(b^2)^(p/2)*b,因此每次判断一下是直接乘还是拆开就可以了。
洛谷模板链接:https://www.luogu.org/problemnew/show/P1226
下面是代码:
#include<bits/stdc++.h>
using namespace std;
long long b,p,k;
void ksm(){
long long ans=1,a=b,bb=b,pp=p;
while(p){
if(p&1) ans=ans*a%k; //判断要不要拆开
p>>=1; //p除以2
a=a*a%k;
}
printf("%lld^%lld mod %lld=%lld",bb,pp,k,ans%k);
}
int main(){
scanf("%lld%lld%lld",&b,&p,&k);
ksm();
return 0;
}
矩阵快速幂
矩阵快速幂顾名思义就是把快速幂的整数换成矩阵,要学习矩阵快速幂,就要先知道矩阵的乘法规则。矩阵的乘法规则由下图所示:
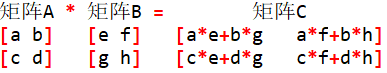
注意:两个矩阵可以做乘法的条件是矩阵A的大小是N*M,矩阵B的大小是M*K,这样的两个矩阵相乘,得到矩阵C的大小是N*K。(通俗的说就是,第一个矩阵的列数等于另一个矩阵的行数)
矩阵的乘法有几个性质是很重要的,必须记住,不要搞混:①矩阵乘法满足乘法结合律 ②矩阵乘法满足乘法分配律(包括左分配律和右分配律,左分配律是:C*(A+B)=CA+CB,右分配律是:(A+B)*C=AC+BC) ③矩阵乘法不满足乘法交换律(例:AC!=CA)。
矩阵乘法的时间复杂度是O(NMK)的,下面是矩阵乘法的代码:
for(i=1;i<=n;++i)
for(j=1;j<=m;++j)
for(l=1;l<=k;++l)
c[i][l]+=a[i][j]*b[j][l];
注意:在做矩阵乘法的时候,最好是按照我上面代码的循环顺序计算,因为如果你改变了循环顺序,速度就会变慢,如果你不相信的话可以去试一试,这是因为按照我代码的顺序,在计算一部分值之前,他的原值已经存在缓存中了,这样的话是比从内存中读取快的,而改变顺序的话,就会从内存中调用,就会变慢了。
学会了矩阵乘法,矩阵快速幂就很轻松了。因为矩阵快速幂和快速幂的区别就在于,一个是整数的次方运算,一个是矩阵的次方运算。但需要注意的是,在矩阵相乘的时候,要存在第三方数组中,这样才不会影响矩阵的值。
洛谷模板链接:https://www.luogu.org/problemnew/show/P3390
下面是AC代码:
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const int M=1000;
const ll mod = 1e9+7;
ll n,k,a[M][M],b[M][M],c[M][M];
void jz(int x){
register int i,j,l;
if(x==1){
for(i=1;i<=n;++i)
for(j=1;j<=n;++j)
for(l=1;l<=n;++l)
c[i][l]=(c[i][l]+a[i][j]*b[j][l]%mod)%mod;
for(i=1;i<=n;++i)
for(j=1;j<=n;++j)
b[i][j]=c[i][j];
memset(c,0,sizeof c);
}
else{
for(i=1;i<=n;++i)
for(j=1;j<=n;++j)
for(l=1;l<=n;++l)
c[i][l]=(c[i][l]+a[i][j]*a[j][l]%mod)%mod;
for(i=1;i<=n;++i)
for(j=1;j<=n;++j)
a[i][j]=c[i][j];
memset(c,0,sizeof c); //记住每次要清空
}
}
void ksm(){
while(k){
if(k & 1) jz(1);
k>>=1;
jz(2);
}
}
int main(){
register int i,j;
scanf("%lld",&n);
scanf("%lld",&k);
for(i=1;i<=n;++i)
for(j=1;j<=n;++j)
scanf("%lld",&a[i][j]),b[i][j]=a[i][j];
--k; //因为在上一句中,在答案中已经有了矩阵A的一次方
ksm();
for(i=1;i<=n;++i){
for(j=1;j<=n;++j)
printf("%lld ",b[i][j]);
printf("\n");
}
return 0;
}
快速乘法
快速乘法和快速幂的思想差不多,KSM是把a^p的p二进制分解,而快速乘法是把a*b的b分解,一般和KSM配套食用。当KSM%p会超范围的时候,也就是取模之前就会乘爆,就要用到快速乘法。快速乘法就是把乘法改成加法,这样一步一步的取模,就不会出现乘爆的问题了。
因为没有找到例题,这里直接附上代码:
typedef long long ll;
ll ksmul(ll x,ll y,int p){ //x*y%p
ll ans=0;
while(y){
if(y & 1) ans=(ans+y)%p;
y>>=1;
x=(x+x)%p;
}
return ans;
}

