开源的文档解析转md测评
Docling
https://github.com/DS4SD/docling
环境安装
直接使用文档中的
pip install docling
无法使用,因为torch和nvidia过高,与当前服务器版本不匹配,最好是低于当前服务器版本比较保险

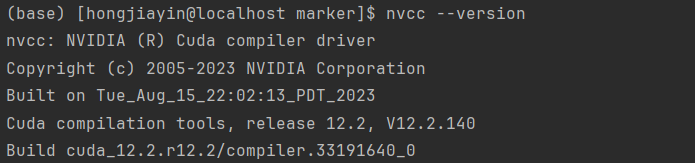
python第三方库中nvidia开头的版本需要小于12.2,如果使用12.4无法使用
安装步骤:
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install docling --no-deps
再根据提示缺少的库手动安装即可
测试
- 测试用例1
from docling.document_converter import DocumentConverter
import time
start = time.time()
source = "https://arxiv.org/pdf/2408.09869" # document per local path or URL
converter = DocumentConverter()
result = converter.convert(source)
print(result.document.export_to_markdown()) # output: "## Docling Technical Report[...]"
end = time.time()
print(end - start)
测试官网提供的demo,9页pdf耗时169s

pdf中的log不显示,只是显示
- 测试用例2
改成输入中文ppf转pdf的文件,29页的pdf耗时290s,文字基本能识别出来,但会出现部分识别错误
Marker
https://github.com/VikParuchuri/marker?tab=readme-ov-file
环境安装
poetry install
pip install marker-pdf
测试
- 测试用例1
from marker.convert import convert_single_pdf
from marker.models import load_all_models
import time
start=time.time()
fpath = r"/data/develop/hjy/DocAnalysis/data/test.pdf"
model_lst = load_all_models()
full_text, images, out_meta = convert_single_pdf(fpath, model_lst)
end=time.time()
print(end-start)
print(full_text)
print(images)
print(out_meta)
转换同一份pdf,marker速度明显快于docling,且可以识别到图片并标注出来,耗时仅用62s


docling、marker对比总结
| tool_name | file | language | cost(s) | page | img |
|---|---|---|---|---|---|
| docling | https://arxiv.org/pdf/2408.09869 | en | 169 | 9 | N |
| marker | https://arxiv.org/pdf/2408.09869 | en | 62 | 9 | Y |
| docling | xx企业介绍.pdf | zh | 290 | 29 | N |
| marker | xx企业介绍.pdf | zh | 139.31 | 29 | Y |
生成速度: docling < marker
图片识别准确度: docling< marker 默认设置
经过两轮简单的测试,可以明显看出marker效果和速度都更好
问题:
- 执行以下代码还需要完善下载图片的代码,能否一次输出markdown文件或markdown文字并显示图片?
full_text, images, out_meta = convert_single_pdf(fpath, model_lst)
- 如何批量生成md
- 尝试测试其他格式文件的效果
使用命令行
marker_single /data/develop/hjy/DocAnalysis/data/test.pdf /data/develop/hjy/DocAnalysis/data/output --batch_multiplier 2 --max_pages 10
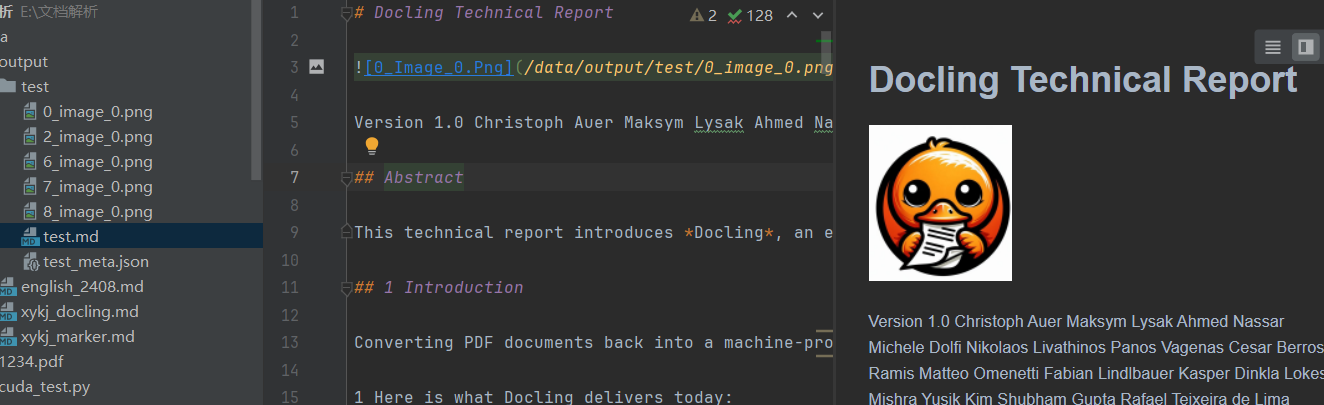
执行仅需14s(可能不包括模型加载时间),转换会新建一个test的目录,存储图片、md、json,并成功转换
使用命令行
marker_single /data/develop/hjy/DocAnalysis/data/xx企业介绍.pdf /data/develop/hjy/DocAnalysis/data/output --batch_multiplier 2 --max_pages 10
耗时105s
测试效果中出现的bug:
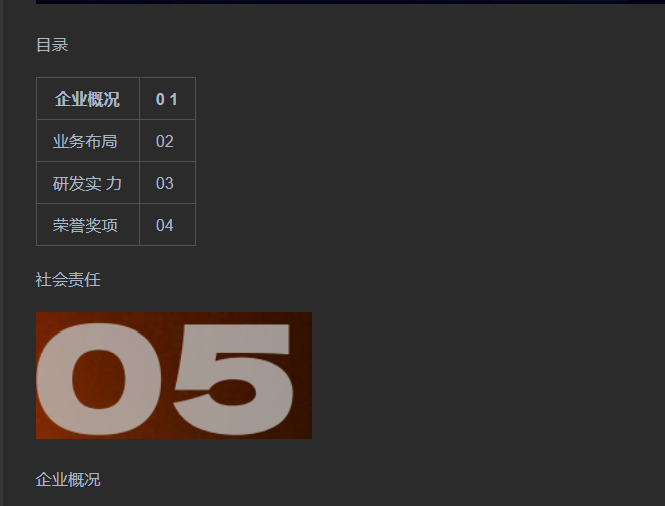



由于默认设置的marker存在不足,如识别效果出现混乱、目录内容识别不全,而docing不存在这一问题,能准确识别出图片。但对于ppt文件,docling会出现部分乱码,识别能力弱于marker,当然marker识别ppt也出现一些问题:

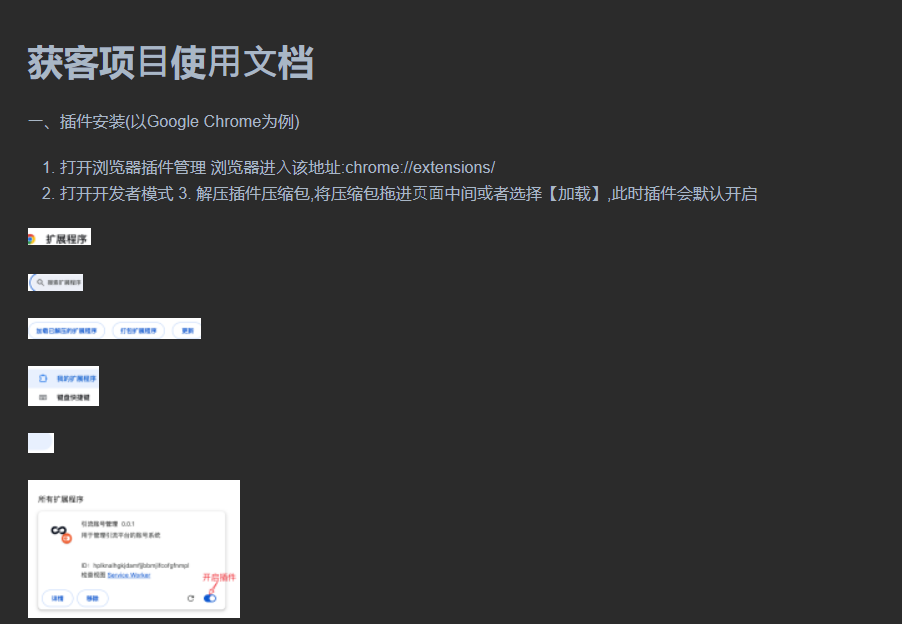
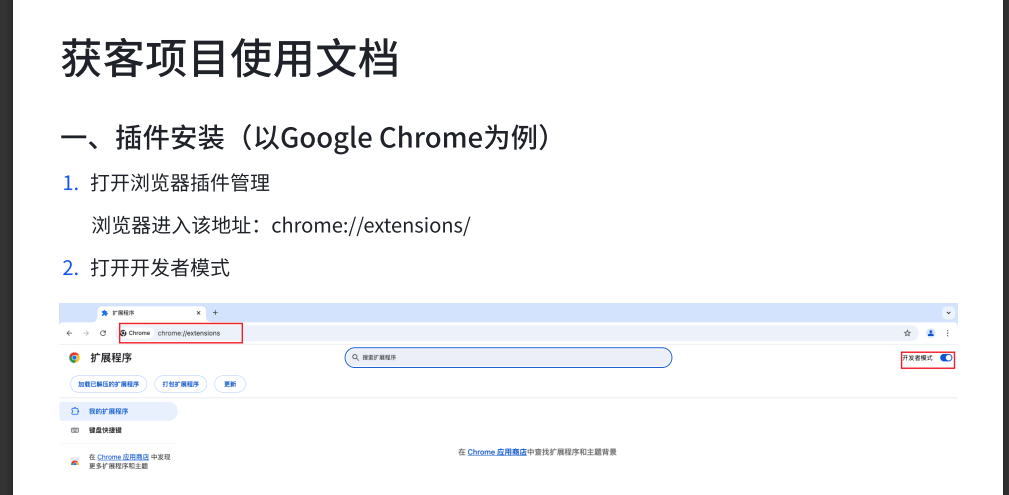
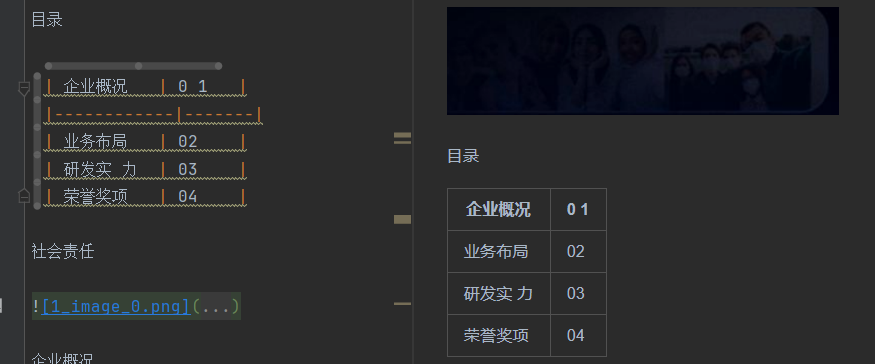
使用腾讯云则识别正常
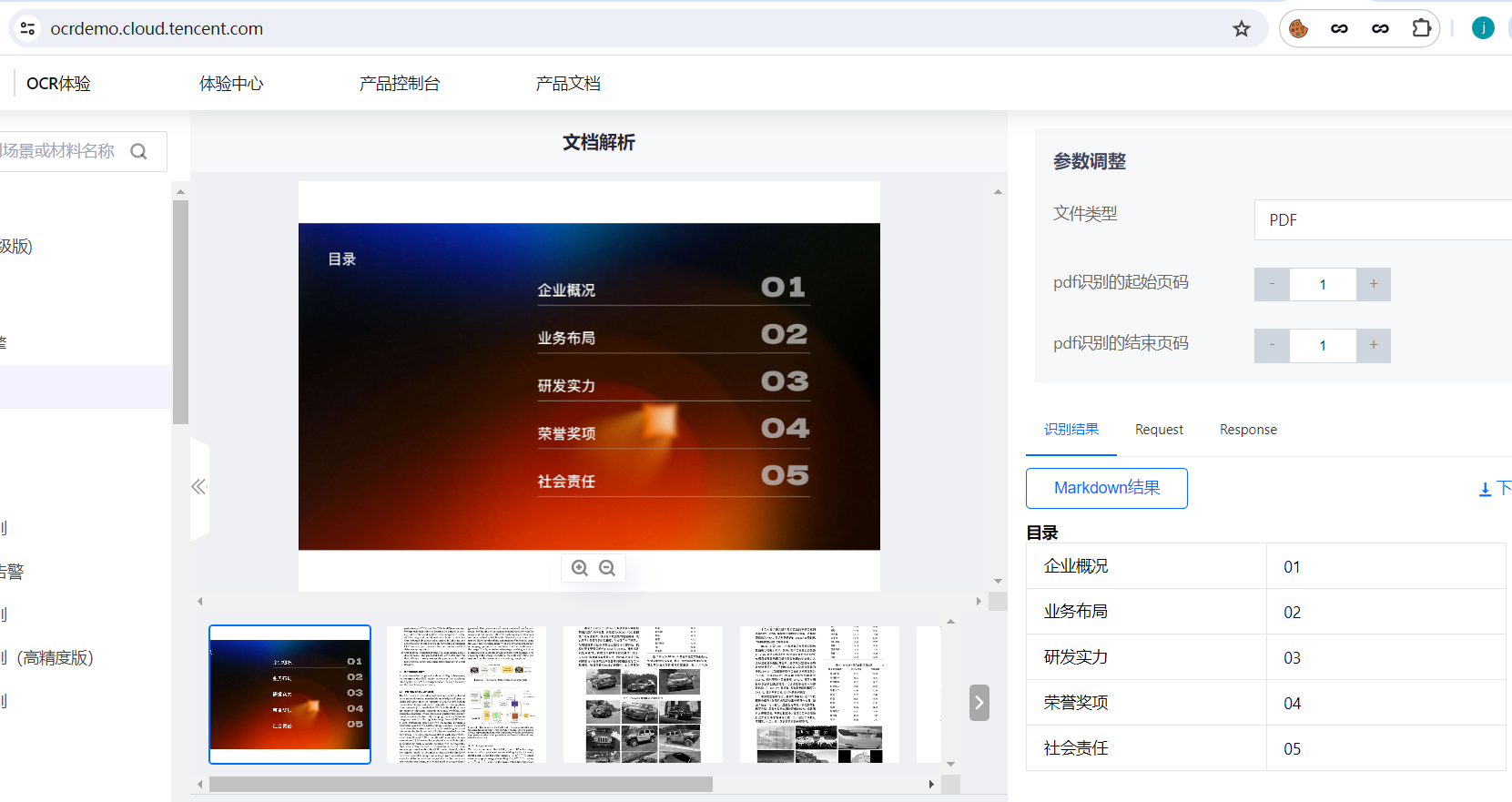
继续测试其他开源工具
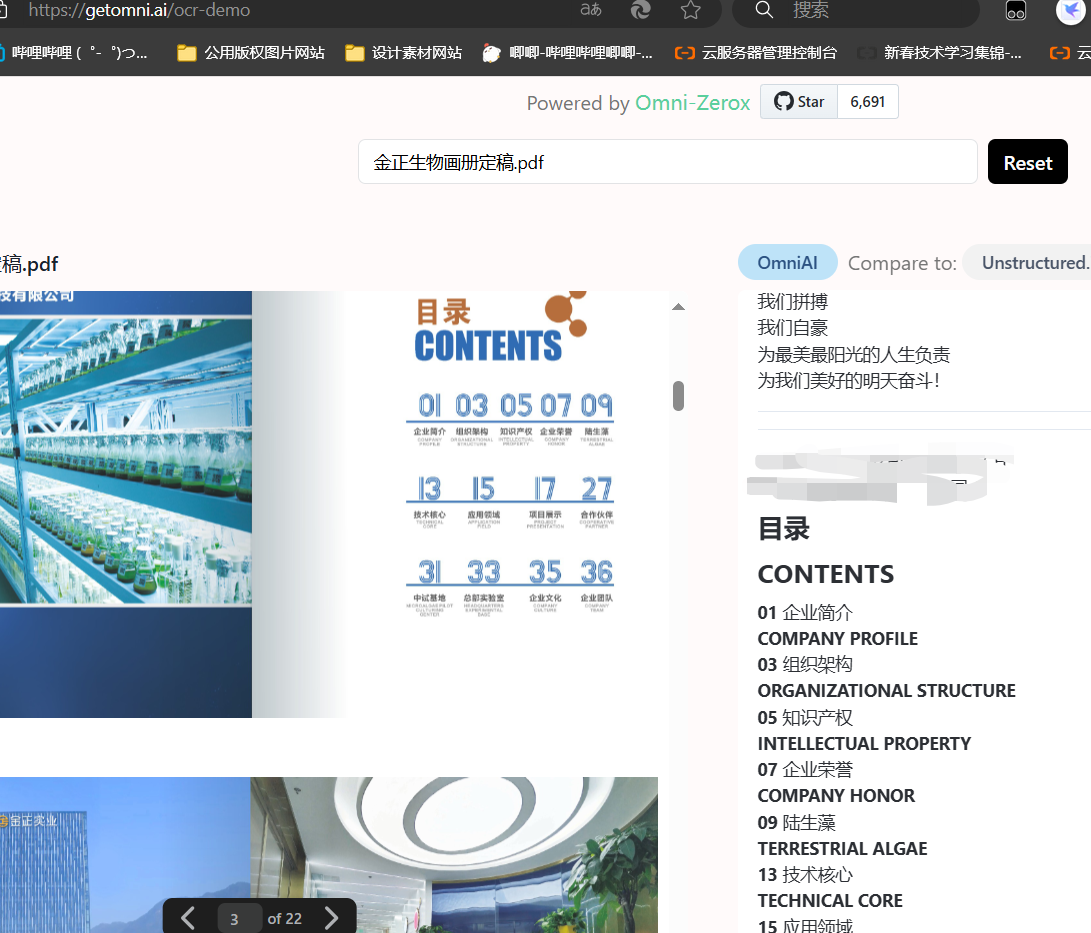
OmniAI开源的zerox
OCR模型采用OmniAI,能够准确识别出画册里的问题,但有不足之处,会擅自改变部分内容,如原页数中不存在这些内容经过zerox转换被加工了,且不支持识别图片,demo网址中识别效果较慢,但胜在文字识别效果好
测试用例1:
测试用例2:
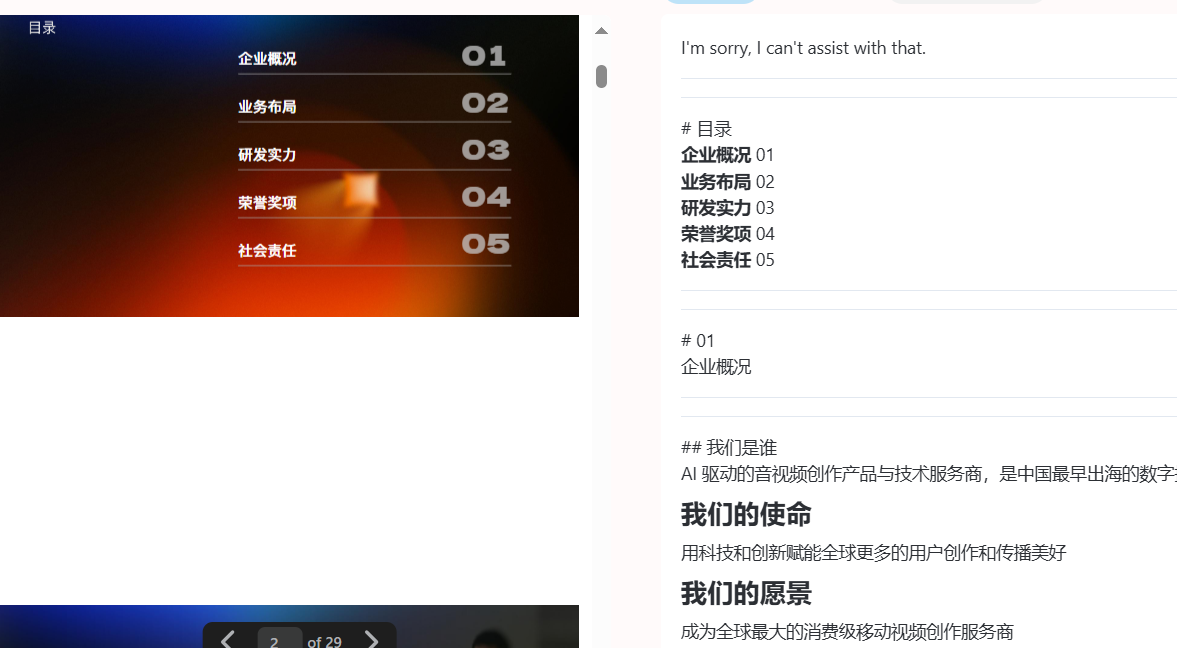
测试用例3:
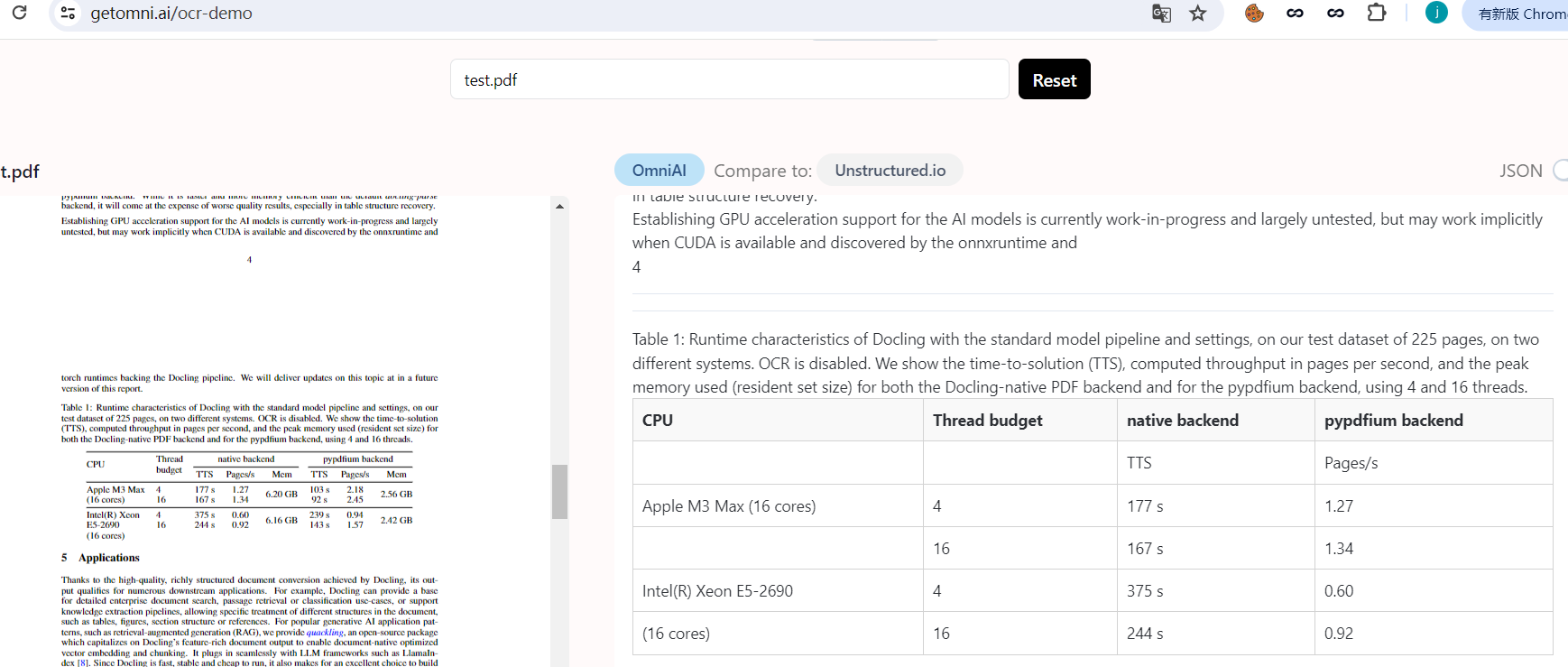
识别表格内容不完全

 浙公网安备 33010602011771号
浙公网安备 33010602011771号