【文本挖掘】(三)文本表示
文本表示的概念
- 核心:将字符串以计算机形式进行表示出来,如向量化。
- 分类
- 离散/向量表示:词袋模型(独热编码、TF-IDF、N-gram)
- 分布式表示:词嵌入word embedding,包括word2vec、Glove、ELMO、GPT、BERT等。
- 基于矩阵:基于降维表示和基于聚类表示
- 基于神经网络:CBOW、Skip-gram、NNLM、C&W
文本预处理
文本预处理的一般过程:
(1)对输入的文本进行删除开始、结尾以及段与段之间的空格等操作。
(2)识别换行符号,对文本进行分段,并用分段标记标识段落。
(3)识别断句符号,如“。”、“!”、“?”、“;”等,并用断句符号标记句子。
(4)对断句出来的句子用分词算法进行分词,并进行词性标注。
(5)处理完成之后,采用一定的策略对之前得到的词汇进行特征词选取。
(6)设置特征词汇的权重。
(7)形成文本的向量空间模型。

向量空间模型VSM: vector space model
权重计算
- 布尔权重
- 词频权重
- TF-IDF
向量相似度量
向量内积
- 普通形式
\[Sim(D_i,D_j)=\sum^n_k=1({t_ik}\times{t_jk})
\]
- 归一化形式
\[Sim(D_i,D_j)=cos\theta=\frac{\sum^n_k=1({t_ik}\times{t_jk})}{
\sqrt{
\sum^n_{k=1}{t_{ik}}
}
\times
\sqrt{
\sum^n_{k=1}{t_{jk}}
}
}
\]
向量间的距离
- 绝对值距离
- 欧几里得距离
- 切比雪夫距离
代码案例
案例1 计算文档Di=(0.2,0.4,0.11,0.06)和Dj=(0.14,0.21,0.026,0.34)的余弦相似度。
- 使用内积函数dot()和范式函数linalg.norm()
import numpy as np
di=[0.2,0.4,0.11,0.06]
dj=[0.14,0.21,0.026,0.34]
dist1=np.dot(Di,Dj)/np.linalg.norm(Di)*np.linalg.norm(Dj)
- 使用scipy
from scipy import spatial
dist1=1-spatial.distance.cosine(Di,Dj)
- 使用sklearn
dfrom sklarn.metrics.pairwise import cosine_similarity
dist1=cosine_similar(Di.reshape(1,-1),Dj.reshape(1,-1))
案例2 计算两个句子的相似度
D1='我喜欢看电视,不喜欢看电影'
D2='我不喜欢看电视,也不喜欢看电影'
# 分词
split1=[ word for word in jieba.cut(D1) if word not in [',','。']]
split1=[ word for word in jieba.cut(D2) if word not in [',','。']]
# 列出所有的词
wordset=set(split1).union(split2)
# 统计词频
def computeTF(wordSet,split):
tf=dict.fromkeys(wordSet,0)
for word in split:
tf[word]+=1
return tf
tf1=computeTF(wordSet,split1)
tf2=computeTF(wordSet,split2)
# 词频向量
s1=list(tf1.values())
s2=list(tf2.values())
#计算余弦相似性
dist1=np.dot(s1,s2)/(np.linalg.norm(s1)*np.linalg.norm(s2))
文本表示方法
离散/向量表示
TF-IDF
\[词频(Term Frequency)=\frac{某个词在文章出现总次数}{文章的总词数}=\frac{某个词在文章出现总次数}{该训练文本出现最多次的词数}
\]
\[逆文档频率(Inverse Document Frequency)=\log\frac{总样本数}{包含该词的文档数+1},其中,+1为了避免分母为0。
\]
词袋模型Big of Words
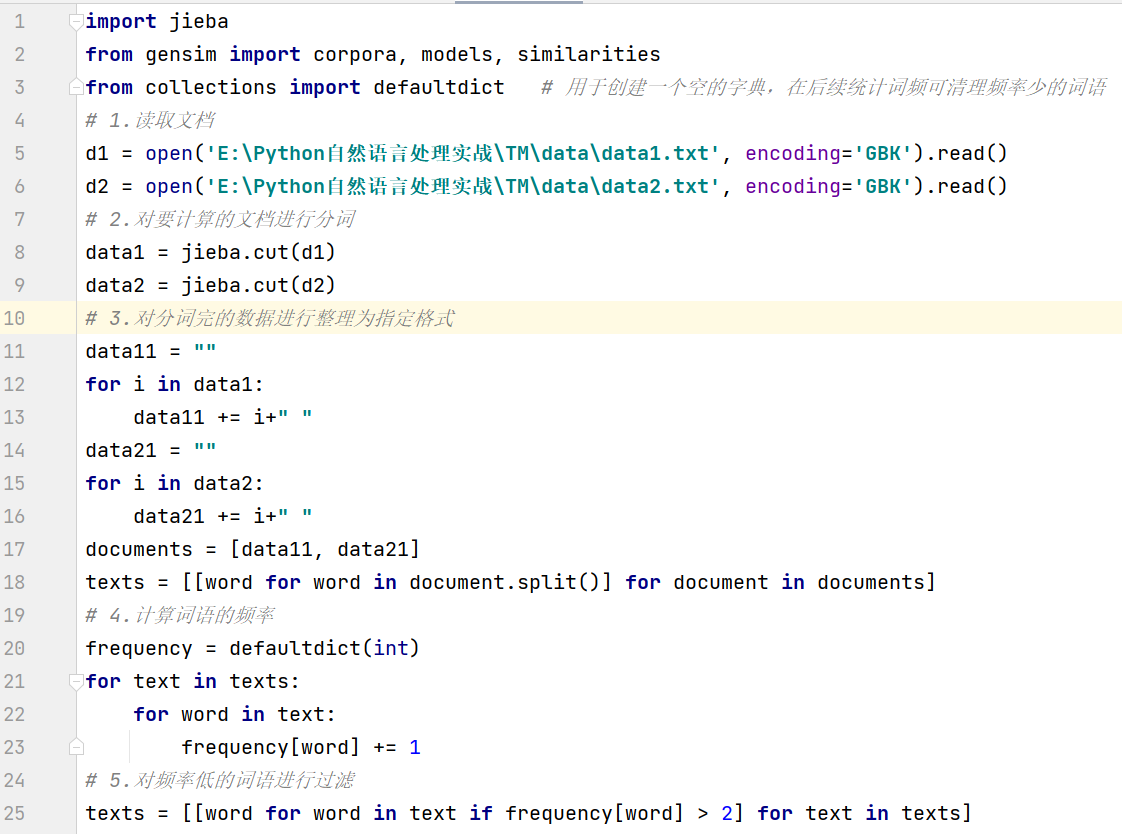
- 基于BOW计算文档相似度的gensim实现
1.建立字典
from gensim.corpora import Dictionary
import jieba
str01='大鱼吃小鱼也吃虾米,小鱼吃虾米'
text01=[ [for word in jieba.cut(str,cut_all=Ture) if word note in [",","。","大鱼吃","大鱼吃小鱼"]]]
# Dictionary类用于建立word<->id映射关系,把所有单词取一个set(),并对set中每个单词分配一个id号的map。
dict01=Dictionary(text01)
dict01.dfs # 字典{单词id,在多少文档中出现}
dict01.num_docs # 文档数目
dict01.num_nnz # 每个文件中不重复词个数的和
dict01.num_pos # 所有词的个数
dict01.token2id # 字典,{单词,对应id}
dict01.id2token() #字典,{单词id,对应的单词}
# 向字典添加词条
dict01.add_documents([['猫','爱']])
dict01.token2id.keys()
- doc2bow转换为BOW稀疏向量
# 转换为BOW稀疏向量
'''allow_update = False : 是否直接更新所用字典
return_missing = False : 是否返回新出现的(不在字典中的)词'''
print(sum(text01,[]))
dict01_cp=dict01.doc2bow(sum(text01,[]),return_missing=True)
输出结果
[(0, 2), (1, 2)],表明在文档中id为0,1的词汇各出现了2次,至于其他词汇则没有出现
return_missing = True时,输出list of (int, int), dict of (str, int)
- 转换为BOW长向量 doc2idx
# 转换为BOW长向量 doc2idx
#doc2idx( # 转换为list of token_id
# document : 用于转换的词条list
# unknown_word_index = -1 : 为不在字典中的词条准备的代码
#输出结果:按照输入list的顺序列出所出现的各词条#ID
str="小鱼吃虾米"
text=[ word for word in jieba.cut(str)]
dict01.doc2idx(text)
输出结果
[3,1,4]
- Sklearn.CountVectorizer生成文档-词条矩阵
'''
class sklearn.feature_extraction.text.CountVectorizer(
input = 'content' : {'filename', 'file', 'content'}filename为所需读入的文件列表, file则为具体的文件名称。
encoding='utf-8' : 文档编码
stop_words = None : 停用词列表,当analyzer == 'word'时才生效
min_df / max_df : float in range [0.0, 1.0] or int, default = 1 / 1.0
词频绝对值/比例的阈值,在此范围之外的将被剔除小数格式说明提供的是百分比,如0.05指的就是5%的阈值)
CountVectorizer.build_analyzer() # 返回文本预处理和分词的可调用函数
'''
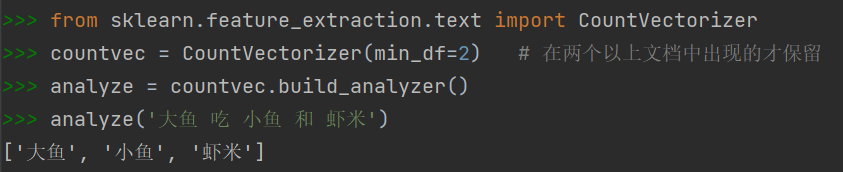


- 完整案例

分布式表示
Word2Vec
CBOW 连续词袋模型
预测未知词,等同于完形填空,如“easyai 是__ 人工智能 网站”
Skip-Gram跳字模型
预测上下文,如"_ _ 最好的 _ _"
Doc2Vec
Doc2Vec是Word2Vec的拓展。
问题思考
- BOW稀疏向量和BOW长向量的区别?
- Word2Vec和Doc2Vec的区别?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号