【文本挖掘】(一)语料库、分词、词性标注、关键词提取、停用词
目录
语料库
存放语言真实使用场景、且经过加工的例句,而非脱离具体场景的标准例句。
国家语委现代汉语语料库:http://corpus.zhonghuayuwen.org
美国国家语料库:http://www.anc.org
清华大学开放中文词库:http://thuocl.thunlp.org
NLPIR-ICTCLAS汉语分词系统:http://ictclas.nlpir.org
中文分词
基于规则的中文分词:最大匹配法
最大匹配法方法简单,速度快,分词效果可以满足基本需求,但严重依赖词典,无法很好处理分词歧义和未登录词。
正向最大匹配法
对句子从左到右选择词典中最长的词条进行匹配。
统计分词词典,确定词典中最长词条的长度m
从左到右取待切分语句的m个字符作为匹配字典,查找词典,若匹配成功,则作为一个切分后的词语,否则去掉待匹配衣
#定义匹配词典
dictA=['南京市','南京市长','长江大桥','大桥']
# 确定词典中最长词条的字符m
maxDictA=max([ len(word) for word in dictA])
sentence="南京市长江大桥"
def cutA(sentence):
result=[]
sentenceLen=len(sentence)
n=0
while n<sentenceLen:
matched=0
# i倒序
for i in range(maxDictA,0,-1):
piece=sentence[n:n+i]
if piece in dictA:
result.append(piece)
matched=1
n=n+i
break
if not matched:
n+=1
print(result)
南京市长
江大桥
大桥
['南京市长', '大桥']
逆向最大匹配法
对句子从右到左选择词典中最长的词条进行匹配。
准确性优于正向匹配法
def cutB(sentence):
result=[]
sentenceLen=len(sentenct)
while sentenceLen>0:
matched=0
for i in range(maxDictA,0,-1):
piece=sentence[sentenctLen-i:sentenceLen]
if piece in dictA:
result.append(piece)
sentenctLen-=i
matched=1
break
if matched==0:
sentenctLen=-1
双向最大匹配法
当两种匹配算法切分的词汇结果相同,取任一结果;
当两种匹配算法切分的词汇结果不同,分别统计两种词汇切分结果切分的词语的个数,取数目小的作为切分结果;
当两种匹配算法切分的词汇结果不同,且切割后的词语的数目相同,选择逆向匹配算法作为切分结果;
分词
jieba
jieba分词利用前缀词典切分句子,得到所有的切分可能,根据切分位置,构造一个有向无环图;通过动态规划算法,得到最大概率的路径,作为切分结果。
jieba也可以用于关键词提取、词性标准等。
import jieba
str="利用前缀词典切分句子,得到所有的切分可能。"
'''分词'''
print(" ".join(jieba.cut(str)))
print(" ".join(jieba.lcut(str)))
print(" ".join(jieba.cut(str,cut_all=True)))
print(" ".join(jieba.cut_for_search(str)))
print(" ".join(jieba.lcut_for_search(str)))
'修改词典'
jieba.add_word('前缀词典')
print(" ".join(jieba.cut(str)))
'自定义词典'
# 词典文件要求:一词占一行 使用空格符 UTF-8编码
# 格式 词 词频(可省略) 词性(可省略)
jieba.load_userdict()
利用 前缀 词典 切分 句子 , 得到 所有 的 切分 可能 。
利用 前缀 词典 切分 句子 , 得到 所有 的 切分 可能 。
利用 前缀 词典 切分 分句 句子 , 得到 所有 的 切分 可能 。
利用 前缀 词典 切分 句子 , 得到 所有 的 切分 可能 。
利用 前缀 词典 切分 句子 , 得到 所有 的 切分 可能 。
利用 前缀词典 切分 句子 , 得到 所有 的 切分 可能 。
HMM模型 Hidden Markov Model
jieba.cut(str,HMM=False)
对于未登录词,jieba使用了基于汉字成词的HMM模型,采用Viterbi(动态规划)算法推导:
使用四个隐藏状态: 单字成词、词组的开头、词组的中间、词组的截尾。通过标注好的分词训练集,可以得到HMM的各个参数,再使用Viterbi算法解释测试集,得到分词结果。
词性标注
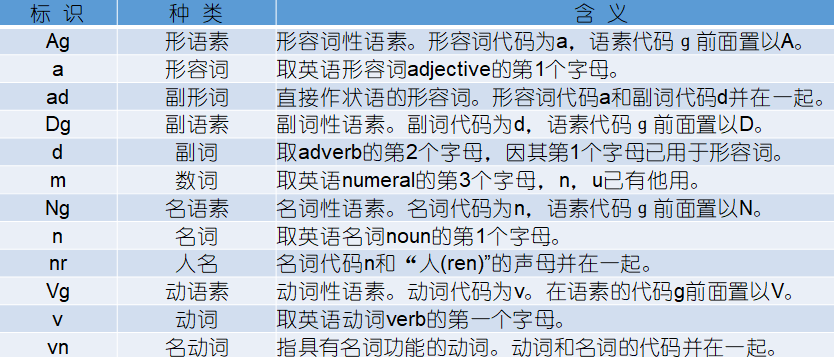
- 使用jieba.posseg.cut()实现词性标注,该标注采用北大计算所词性标注集和ICTCLAS兼容的标记法。
import jieba.posseg as psg
str="我来到赣州中学"
seg=psg.cut(str)
# 打印词性标注结果
for ele in seg:
print(ele)
# 直接输出为list
psg.lcut(str)
- 使用jieba.enable_paddle()的paddle模式
jjieba.enalbe_paddle()
words=psg.cut(str,use_paddle=True)
for w,f in words:
print('%s %s'%(w,f))
- 使用jieba.tokenize() 获取词语在原文的位置
res=jieba.tokenize(str)
for tk in result:
print("word: %s\t\t start:%d\t\t end:%d"%(tk[0],tk[1],tk[2]))
停用词
常见停用词词库:哈工大停用词词库、四川大学机器学习智能实验室停用词库、百度停用词表
停用词种类
- 超高频常用词:基本不携带有效信息,如:的、地、得
- 虚词:如介词、连词等(只、条、件;当、从、同)
- 视情况而定的停用词,如呵呵、emoji等
过滤方法
- 创建停用词表txt文件
- 创建停用词列表
- 使用jieba.extract_tags去除
关键词提取
TF-IDF
import jieba.analyse
str='"共商国是"不是"共商国事","国是"指国家大计,为国家政策方针等重大决策,多用于书面书,语境庄重、严肃;"国事"是指具体指称。"共商国是"一词中的"是"不能用"事"代替。'
# topK:返回几个TF/IDF权重最大的关键词,默认为20
# withWeight:是否一并返回关键词权重,默认False
allowPOS:仅包括指定词性的词
keywords=jieba.analyse.extract_tags(sentence,topK=20,withWeight=True,allowPOS=('n','nr','ns'))
for item in keywords:
print(item[0],item[1])
TextRank
keywords=jieba.analyse.textrank(sentenct,topK=10,withWeight=True,allowPOS=('ns','n','vn','v'))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号