基于asyncio+pyppeteer的增量式微博网页版爬虫(一)思路分析篇
项目介绍
本项目旨在利用高级搜索功能,爬取微博网页版的详细数据。而大多数爬虫以单线程为主,但单线程存在资源利用率低的不足,针对这以问题,本项目主要使用如下技术:
(1)多线程+协程技术+Redis实现增量式爬虫。实现过程中存在两个技术难点:一是使用redis数据传输时开销频繁,服务器容易崩溃;二是多线程会存在线程抢占资源的问题,这里借鉴了多窗口售票的思路解决了问题。
(2)实现爬取不同时间段的数据,包含实时数据、自定义时间段数据,并自动识别数据是否展示完全,尽可能保证数据都能爬取到。
相关技术
增量式爬虫
增量式爬虫:指在已有爬取结果的基础上,仅爬取新增的数据,并对已爬取的数据进行去重。
本项目采用两种去重,分别是URL去重和数据去重,分别采用Redis、PostGreSQL存储。
URL去重:需爬取的URL存储至Redis的set中,若当前爬取的URL已存在set中,则不更新set。
数据去重:将已爬取的数据存储在PostGreSQL数据库中,每次爬取前先从数据库读取所有已爬取数据,再与当前爬取的数据进行对比,仅爬取新增数据。
多线程
即在进程中引入多个线程实现任务并发执行,能够提高CPU的利用率,但存在资源锁的问题。
异步协程
由于计算机资源是有限的,不可能存在新的任务继续创建新的线程,这样无限创建大量线程会占用较多资源,因此,将任务调度优化从操作系统内核转移到代码片(程序)中,也就是协程。协程的上下文转换比多线程快。而进程、线程都是同步的,协程是异步的。协程具备同步的编程方式又有异步的性能
但对于计算型的操作,利用协程来回切换执行,没有任何意义,来回切换并保存状态 反倒会降低性能。
IO型的操作,利用协程在IO等待时间就去切换执行其他任务,当IO操作结束后再自动回调,那么就会大大节省资源并提供性能,从而实现异步编程(不等待任务结束就可以去执行其他代码),而爬虫正属于IO密集型任务。
实现思路
站点分析
不同架构的站点分析见https://www.cnblogs.com/Gimm/p/18190005
考虑API采集数量有限,请求次数有限,移动端数据较少,而网页端具有高级搜索功能,虽然限制最大页数为50页,但可以细化时间粒度采集更多数据。
由于采集转发类型的博文会存在重复数据,故仅考虑采集原创博文。
根据高级搜索功能的所有参数,这里定义自定义参数有:关键词、时间,固定参数:类型=原创,包含=全部
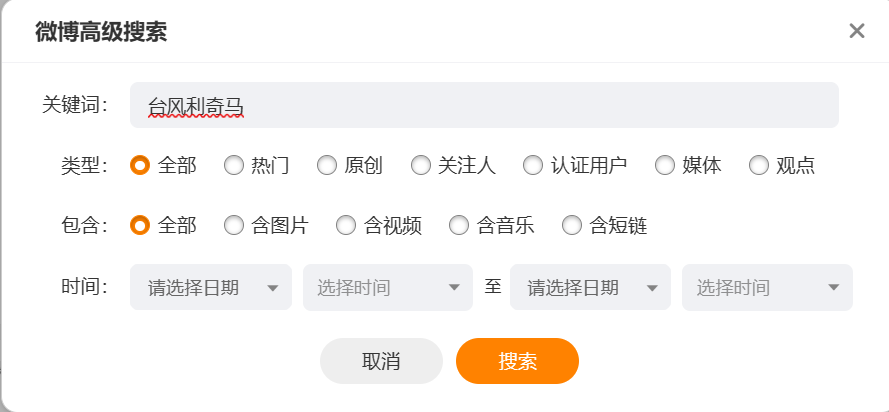
构造一级页面URL
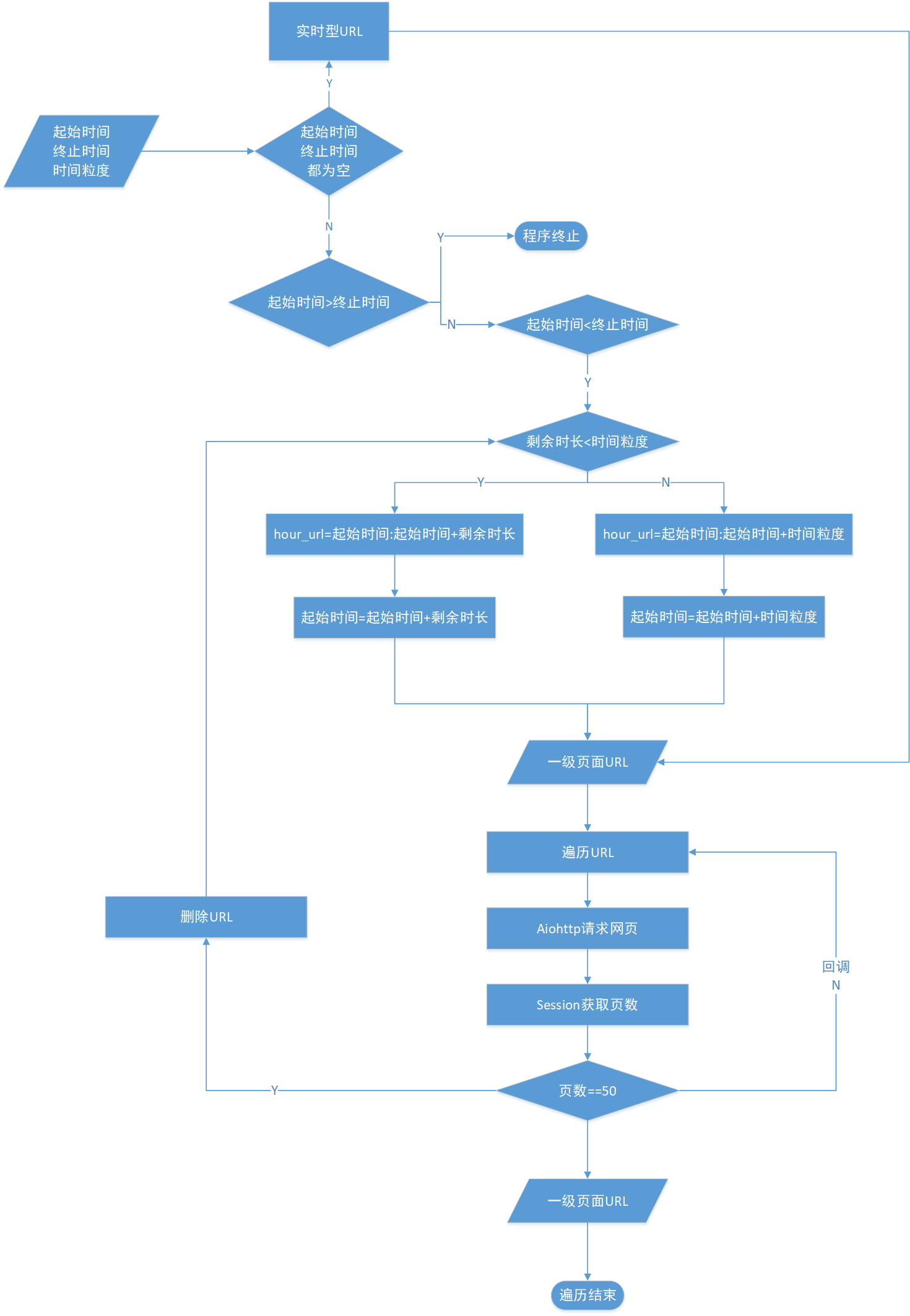
实现流程
-
获取用户列表节点
1.1 在一级页面获取用户列表节点

-
遍历用户列表节点
2.1 遍历一级页面的用户列表节点,获取用户名、发布时间、发布日期、发布内容、图片、视频、评论、转发数、点赞数、评论数
2.2 获取mid,构建文章链接和个人主页链接
其中文章链接由mid+base62转码的mid组成


-
获取微博长文
对于微博长文,需要点击“展开”按钮才能显示完全。

-
获取微博表情

-
获取定位文本
部分博文存在定位信息,可直接获取;

对于没有定位信息的博文,见步骤6,跳转到文章链接中,获取“发布于xx”的位置文本。 -
进入文章链接
获取发布于、关注、粉丝、ip


 浙公网安备 33010602011771号
浙公网安备 33010602011771号