【爬虫】第二章-基本请求库
一、urllib
使用request模拟发送请求
官方文档
https://docs.python.org/3/library/urllib.request.html#module-urllib.request
urlopen发送get请求
Urllib.request.urlopen(url,data=None[timeout,]*,cafile=None,capath=None,cadefault=None,context=None)
import urllib
from urllib import request
import cchardet
# 使用urllib分别抓取http://www.xinhuanet.com/politics/leaders/2021-07/01/c_1127615334.htm和https://www.kanunu8.com/book/3829/的源码并输出。
#加上请求头
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
url1="http://www.xinhuanet.com/politics/leaders/2021-07/01/c_1127615334.htm"
url2="https://www.kanunu8.com/book/3829/"
req1=urllib.request.Request(url1,headers=headers)
req2=urllib.request.Request(url2,headers=headers)
# urlopen(url)中可以是url地址,也可以是Request对象
res1=urllib.request.urlopen(req1)
res2=urllib.request.urlopen(req2)
#检查网页编码类型
#print(cchardet.detect(res1.read()))
#print(cchardet.detect(res2.read()))
#打印源码
print(res1.read().decode("utf-8"))
print(res2.read().decode('GB18030'))
三种请求方式的区别:
第一种: urlopen直接放入url且不解码
request=urllib.request.urlopen(url)
print(request.read())
# 运行结果
b'<!DOCTYPE html><!--STATUS OK--><html><head><meta http-equiv="Content-Type" content="text/html;charset=utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="always" name="referrer"><meta name="theme-color" content="#ffffff"><meta name="description" content="\xe5\x85\xa8\xe7\x90\x83\xe9\xa2\x86\xe5\x85\x88\xe7\x9a\x84\xe4\xb8\xad\xe6\x96\x87\xe6\x90\x9c\xe7\xb
第二种:urlopen直接放入url且解码
request=urllib.request.urlopen(url)
print(request.read().decode('utf-8'))
# 运行结果
<!DOCTYPE html><!--STATUS OK--><html><head><meta http-equiv="Content-Type" content="text/html;charset=utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="always" name="referrer"><meta name="theme-color" content="#ffffff"><meta name="description" content="全球领先的中文搜索引擎、致力于让网民更便捷地获取信息,找到所求。百度超过千亿的中文网页数据库,可以瞬间找到相关的搜索结果。"><link rel="shortcut icon" href="https://www.baidu.com/favicon.ico" type="image/x-icon" /><link rel="search" type="application/opensearchdescription+xml" href="/content-search.xml" title="百度搜索" /><link rel="icon" sizes="any" mask href="https://www.baidu.com/favicon.ico"><link rel="dns-prefetch" href="//dss0.bdstatic.com"/><link rel="dns-prefetch" href="//dss1.bdstatic.com"/><link rel="dns-prefetch" href="//ss1.bdstatic.com"/><link rel="dns-prefetch" href="//sp0.baidu.com"/><link rel="dns-prefetch" href="//sp1.baidu.com"/><link rel="dns-prefetch" href="//sp2.baidu.com"/><link rel="dns-prefetch" href="//pss.bdstatic.com"/><link rel="apple-touch-icon-precomposed" href="https://psstatic.cdn.bcebos.com/video/wiseindex/aa6eef91f8b5b1a33b454c401_1660835115000.png"><title>百度一下,你就知道</title><style
第三种:请求Request对象不解码
req=urllib.request.Request("http://www.baidu.com")
rep=urllib.request.urlopen("http://www.baidu.com")
print(rep.read())
# 运行结果: 同1
第四种:请求Request对象且解码
req=urllib.request.Request("http://www.baidu.com")
rep=urllib.request.urlopen("http://www.baidu.com")
print(rep.read().decode('utf-8'))
# 运行结果: 同2
urlopen发送post请求
加上data参数可实现post请求,使用bytes()将数据转换为字节流编码,由于该方法第一个参数需要str类型,因此需要使用urlencode()方法将参数字典转换为字符串,第二个参数指定编码格式
import urllib.parse
import urllib.request
data=bytes(urllib.parse.urlencode({'word':'hello'}),encoding='utf8')
# b'word=hello'
response=urllib.request.urlopen('http://httpbin.org/post',data=data)
print(response.read())
转换为字节流另一种写法:
data_parse=urllib.parse.urlencode({'world':'hello'})
data_b=data_parse.encode('utf-8')
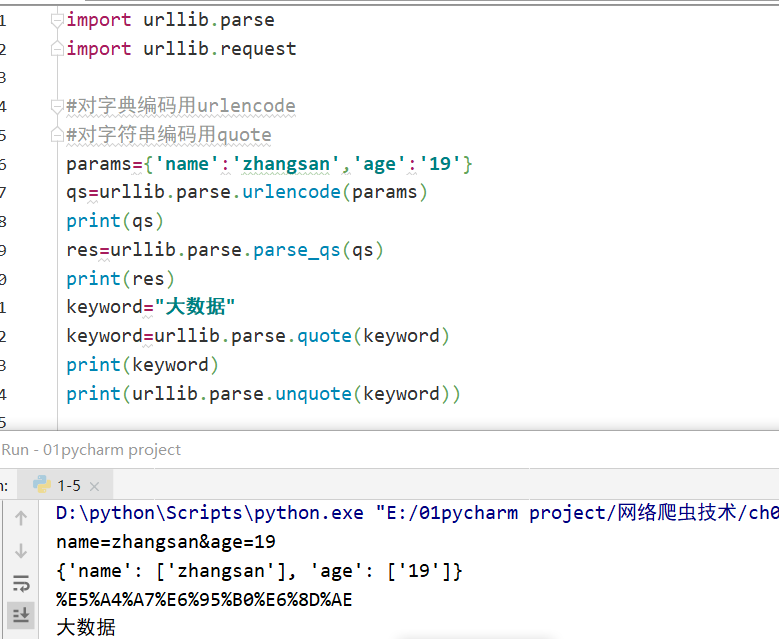
parse
介绍
- 用于处理URL,如拆分、解析、合并等,常用函数为等
编码与解码
- 编码与解码(urlencode序列化、parse_qs反序列化、quote编码、unquote解码),常用于post访问网页时需提交数据,这时可以用parse将字典或字符串转换为字节流编码
Handler处理器
- 一些Handler处理器:用于处理登陆验证、cookie、代理设置等,如urlopen相当于Opener
- 官方文档:https://docs.python.org/3/library/urllib.request.html#urllib.request.BaseHandler
1)登录验证
网页弹出需要输入用户名密码的提示框时,可使用HTTPBasicAuthHandler
from urllib.request import HTTPPasswordMgrWithDefaultRealm, HTTPBasicAuthHandler, build_opener
from urllib.error import URLError
username = username
password ='password'
url = 'http: //localhost:sooo/'
p = HTTPPasswordMgrWi thDefaultRealm()
p.add_password(None,url,username,password)
auth_handler = HTTPBasicAuthHandler(p)
opener = build_opener(auth_handler)
try:
result = opener.open(url)
html = result.read().decode('utf 8')
print(html)
except URLError as e:
print(e.reason)
2)ProxyHandler代理设置
from urllib.error import URLError
from urllib.request import ProxyHandler,build opener
proxy_handler = ProxyHandler({
'http':'http://127.0.0.1:9743',
'https':'https://127.0.0.1:9743'
})
opener = build_opener(proxy_handler)
try:
response = opener.open ('https://www.baidu.com')
print(response.read().decode ('utf-8'))
except URLError as e:
print(e.reason)
3)CookieJar/HTTPCookieProcessor获取、保存和读取Cookie
import http.cookiejar,urllib.request
# 声明一个cookieJar对象
cookie=http.cookiejar.CookieJar()
handler=urllib.request.HTTPCookieProcessor(cookie)
opener=urllib.request.build_opener(handler)
response=opener.open('http://www.baidu.com')
for item in cookie:
print(item.name+"="+item.value)
#将cookie输出成文件格式
cookie.save(ignore_discard=True,ignore_expires=True)
# 运行结果
BAIDUID=57A09ECF30B476A6A85EFB2165C219FE:FG=1
BAIDUID_BFESS=57A09ECF30B476A6A85EFB2165C219FE:FG=1
BIDUPSID=57A09ECF30B476A6A85EFB2165C219FE
H_PS_PSSID=40080_40369_40379_40416_40445_40300_40464_40458_40505_40500_40514_40397_60043_60029_60035_60048_40511_60094
PSTM=1712247775
cookie保存结果为
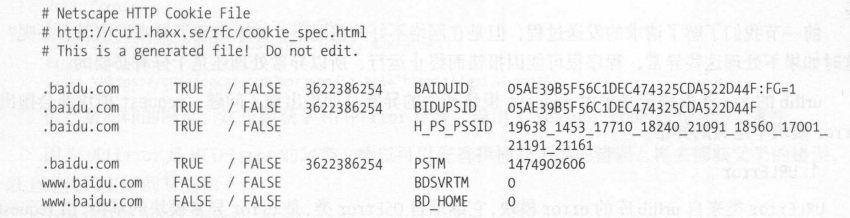
将会保存为MozillaCookieJar格式的cookie,LWPCookieJar 同样可以读取和保存 Cookies ,但是保存的格式和 MozillaCookieJar 不一样,它会保存成 libwww-perl(LWP)格式的 Cookies 文件
若要保存为LWP格式的cookie,可以在声明cookieJar时改为:
cookie =http.cookiejar.LWPCookieJar(filename)
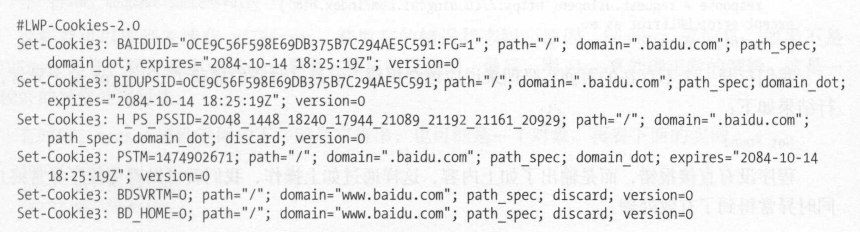
从本地txt文件中读取cookie:
cookie = http.cookiejar.LWPCookieJar()
cookie.load('cookies.txt',ignore discard=True, ignore_expires=True)
qs:还有没有其他方式获取cookie?
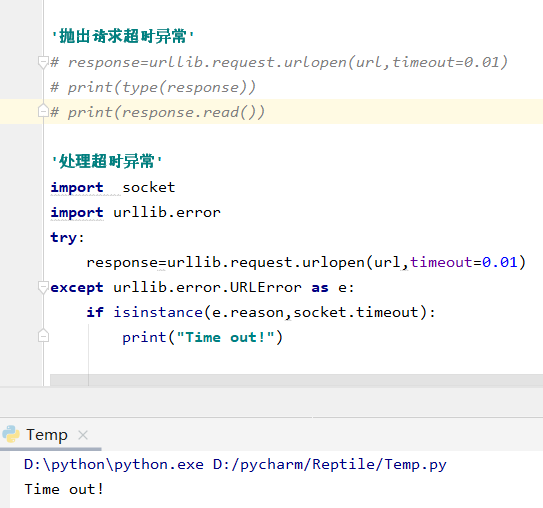
error
- URLError 属性reason可以返回错误原因
robotparser
- 用于识别网站robots.txt文件
urllib.robotparser.RobotFileParser(url=’ ’)
urlretrieve
import urllib
from urllib import request
url="https://www.fjbu.edu.cn/xxgcx/files/video/2021/%E7%AC%AC1%E7%BB%84_%E5%9E%83%E5%9C%BE%E5%88%86%E7%B1%BB%EF%BC%8C%E4%BB%8E%E6%AD%A4%E5%88%BB%E5%81%9A%E8%B5%B7.mp4"
path="E:/第1组_垃圾分类,从此刻做起.mp4"
urllib.request.urlretrieve(url,path)
print("下载成功")
二、requests
text返回字符串对象,content返回bytes对象,使用pdf文件、音频、图像等使用content
官方文档
https://requests.readthedocs.io/en/latest/
实现各种请求方法
import requests
r=requests.post('http://httpbim.org/post')
r=requests.put('http://httpbim.org/put')
r=requests.delete('http://httpbim.org/delete')
r=requests.head('http://httpbim.org/head')
r=requests.options('http://httpbim.org/options')
抓取HTML网页
抓取二进制数据
1)抓取github的站点图标
import requests
r=requests.get("http://github.com/favicon.ico")
with open('favicon.ico','wb') as f:
f.write(r.content)
2)使用工作流抓取pdf报告
import requests
url="https://www.fjbu.edu.cn/19zt/pdf/web/01.pdf"
#设置工作流 放置立即开始下载 避免文件过大导致内存不足
req=requests.get(url,stream=True)
with open('十九大报告.pdf','wb') as file:
file.write(req.content)
print("下载成功")
req.close()
文件上传
import requests
files={'file':open('favicon.ico','rb')}
r=requests.post('http://httpbin.org/post',files=files)
print(r.text)
操作Cookies
获取cookie
req=requests.get(url)
cookies=req.cookies
for k,v in cookies.items():
print(key+'='+value)
在header中添加cookie
使用RequestsCookieJar添加cookie

会话维持
当直接使用post()和get()请求网页时,相当于用两个浏览器打开页面。
假设第一次使用post()登录某个网站,第二次想用get获取成功登陆后的个人信息,但实际上相当于打开了两个浏览器,两个网站存在不相关的session。
因此,想要维持同一个会话,且不想每次都设置cookies,就要实现打开新的选项卡而不是新的浏览器。
demo中先请求了http://httpbin.org/cookies/set/number/123456,随后请求了http://httpbin.org/cookies
import requests
s=requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456')
r=s.get('http://httpbin.org/cookies')
print(r.text)
代理设置
使用proxies参数设置HTTP代理
proxies={
"http":'http://101.101.0:3128'
}
request.get('http://www.baidu.com',proxies=proxies)
若代理需要使用HTTP Basic Auth,则语法为http://user:password@host:port
proxies={
"http":'http://user:psw@101.101.0:3128'
}
request.get('http://www.baidu.com',proxies=proxies)
使用socks+proxies设置SOCKS代理
pip install request[socks]
import requests
proxies={
"http":'http://user:psw@101.101.0:3128'
}
request.get('http://www.baidu.com',proxies=proxies)
登录验证
官方文档:https://requests-oauthlib.readthedocs.io/en/latest/
遇到网页弹窗需要输入用户名密码时
import requests
from requests.auth import HTTPBasciAuth
r=reuests.get('http://localhost:5000',auth=HTTPBasicAuth('username','password'))
print(r.status_code)
简化为:
import requests
r=reuests.get('http://localhost:5000',auth=('username','password'))
print(r.status_code)
三、项目实战
1)抓取https://www.kanunu8.com/book3/电子书
使用requests库和正则表达式抓取在https://www.kanunu8.com/book3/任选的一本电子书
import requests
import re
import os
header = {
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
def main(base_url,book_name):
os.makedirs(book_name,exist_ok=True)
#请求网页
req=requests.get(base_url,headers=header)
content=req.content.decode(req.apparent_encoding)
content = re.findall('正文(.*?)</tbody>', content, re.S)
chap_url_list=get_condition(content)[0]
chap_name_list=get_condition(content)[1]
x=0
for i in range(len(chap_name_list)):
chap_name=chap_name_list[i]
chap_url=chap_url_list[i]
chap_txt=get_txt(base_url,chap_url)
save(book_name,chap_name,chap_txt)
if chap_name=='前言':
print("前言保存成功")
x=x+1
else:
print(f"第{x}章保存成功")
x=x+1
# 获取 章节标题列表 和 章节url列表
def get_condition(content):
for item in content:
chap_url_list=re.findall('[0-9]{6}.html',item)
for item in content:
chap_name_list=re.findall('<a href="1831[0-9][0-9].html">(.+)</a></td>',item)
return chap_url_list,chap_name_list
#获取章节内容
def get_txt(base_url,chap_url):
base_url=re.search('https://www.kanunu8.com/book3/[0-9]{4}/',base_url).group(0)
url=base_url+chap_url
#请求每个章节的url
req=requests.get(url,headers=header)
chap_txt=req.content.decode('gbk')
#选取源码中的书本内容
#chap_content=re.search("<p>(.+)</p>",chap_content,re.S).group(0)
chap_txt=re.findall(r'<p>(.*?)</p>',chap_txt,re.S)[0]
#数据清洗 处理 、</br>等字符
chap_txt=chap_txt.replace(' ',"")
chap_txt=chap_txt.replace('<br />',"")
return chap_txt
#保存到当前目录
def save(book_name,chap_name,chap_txt):
chap_name=chap_name+'.txt'
with open(os.path.join(book_name,chap_name),'w',encoding='gbk') as file:
file.write(chap_txt)
if __name__ == '__main__':
base_url="https://www.kanunu8.com/book3/8259/index.html"
book_name="孽海花"
main(base_url,book_name)
2)抓取https://movie.douban.com/豆瓣电影一周口碑榜
import requests
import re
import csv
from fake_useragent import UserAgent
#re文档:
#https://docs.python.org/zh-cn/3.8/library/re.html#re.S
header = {
'user-agent': UserAgent().ie,
'cookie':'bid=gZhOMjq7Ag0; ll="118200"; __gads=ID=ee81490f4e78ee41-226c825738cf0077:T=1637495539:RT=1637495539:S=ALNI_MYAsbTf9f4zarcndONOU8V3iX3aKg; _vwo_uuid_v2=D5CD017E3233C8F72BD20AB7E8A3DE8C6|e0376aed09832ec0574b534bffe098fc; dbcl2="144119796:t9KAADz+2i4"; push_noty_num=0; push_doumail_num=0; __utmv=30149280.14411; ck=oiAV; _pk_ref.100001.4cf6=["","",1637997339,"https://www.baidu.com/link?url=-BeYMom6zanu8afK9L3VZBlLbFUbdO_SynvSZ9V8_KxMbRniAGx-WAUEh-IFvJ4g&wd=&eqid=e083a3d3000506490000000661a1db18"]; _pk_id.100001.4cf6=98c1f43971dcb9d9.1637495527.4.1637997339.1637511633.; _pk_ses.100001.4cf6=*; ap_v=0,6.0; __utma=30149280.2069033705.1637495528.1637679354.1637997340.5; __utmb=30149280.0.10.1637997340; __utmc=30149280; __utmz=30149280.1637997340.5.3.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utma=223695111.1576995638.1637495528.1637510908.1637997340.4; __utmb=223695111.0.10.1637997340; __utmc=223695111; __utmz=223695111.1637997340.4.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic'
}
def main(base_url):
source=request_url(base_url)
source = re.findall(
'<div id="billboard" class="s" data-dstat-areaid="75" data-dstat-mode="click,expose">(.+)</div>', source, re.S)
all_conditions(source)
#请求得到源码
def request_url(url):
req = requests.get(url, headers=header)
source = req.content.decode('utf-8')
return source
#主页
def all_conditions(source):
datalist=[]
for item in source:
item=re.findall("<table>(.+)</table>",item,re.S)
for i in item:
#获取主页下的排名、电影名称、子页链接
rank_list=re.findall('<td class="order">(.+)</td>',i)
href_list=re.findall('href="(.*?)">',i,re.S)
name_list=re.findall('[\u4e00-\u9fa5]+',i,re.S)
#获取子页所有信息,全部添加到列表中
for href,name,rank in zip(href_list,name_list,rank_list):
data = []
data.append(rank)
data.append(name)
data.append(href)
sub_page=get_sub_page(href)
for i in sub_page:
# print(i)
data.append(i)
datalist.append(data)
print(data)
#print("datalist\n",datalist)
#保存爬取的数据
save(datalist)
#获取子页下所有信息
def get_sub_page(href):
source=request_url(href)
score = re.search('<strong class="ll rating_num" property="v:average">(.+)</strong>', source).group(1)
con_list = re.findall('<div id="info">(.+)<br>', source, re.S)
for item in con_list:
item = re.sub('<a href="/celebrity/[\d]+/"', '', item)
item = re.sub('</span>', '', item)
#print("++++item+++",item)
#导演
actor = re.search('rel="v:directedBy">(.+)</a>', item).group(1)
# actor = [actor]
#编剧
writer = re.search("编剧: <span class='attrs'>(.+)</a><br/>", item).group(1)
writer = writer.replace("</a> / >", ",")
writer = re.sub('<a href="/(.*?)">', ',', writer).replace('</a> / ',"").replace(">","")
# writer = [writer]
#主演
star_list = re.search('rel="v:starring">(.+)</a><br/>', item).group(1)
star_list = re.sub('</a> / rel="v:starring">', ",", star_list)
if "href" in star_list:
star_list = re.sub('</a> / <a href="/(.*?)" rel="v:starring">', ',', star_list)
# star_list=[star_list]
# else:
# star_list = [star_list]
#类型
type = re.search('<span property="v:genre">(.+)<br/>', item).group(1)
type = re.findall('[\u4e00-\u9fa5]+', type)
type = ','.join(type)
#制片国家/地区
region = re.search("制片国家/地区: (.+)<br/>", item).group(1)
#语言
language = re.search("语言: (.+)<br/>", item).group(1)
#上映时间
date = re.findall('"v:initialReleaseDate" content="(.*?)">', item)
date = ','.join(date)
#片长
runtime = re.search("片长: (.+)<br/>", item).group(1)
runtime = re.findall('[\d]+[\u4e00-\u9fa5]+', runtime)
runtime = ''.join(runtime)
#又名
try:
other_name = re.search("又名: (.+)<br/>", item).group(1)
except:
other_name = ""
#IMDb
IMDb = re.search("IMDb: (.+)", item).group(1)
return score,actor,writer,star_list,type,region,language,date,runtime,other_name,IMDb
#保存为csv文件
def save(data):
with open("DoubanMovieWeekTop10.csv","w+",encoding="utf-8-sig",newline="") as f:
a=csv.writer(f)
a.writerow(["排名","电影名","详情链接","评分","导演","编剧","主演","类型","制片国家/地区","语言",
"上映时间","片场","又名","IMDb"])
a.writerows(data)
if __name__ == '__main__':
base_url = "https://movie.douban.com/"
main(base_url)
写法二:
import requests
import cchardet
import re
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36',
'Cookie': 'bid=Wt9rGb6VTcE; douban-fav-remind=1; __gads=ID=b0b9fc62ad8fd36e-2277b1a4d0ca0007:T=1629037033:RT=1629037033:S=ALNI_MZcQI-zVIz4SDF1JEWl3bohLM8JKA; viewed="35571443"; gr_user_id=b4003e18-ed65-42a8-b2aa-c2eee8128f95; ll="118200"; __utmz=30149280.1633773615.6.6.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmz=223695111.1633773615.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _vwo_uuid_v2=DAAC4D9D6B82F69AC1F055078D065C751|92efe72a313f1fd9c1647ee1c083fa7d; __utmc=30149280; __utmc=223695111; ap_v=0,6.0; __utma=30149280.1433569655.1629037036.1634220097.1634222012.15; __utmb=30149280.0.10.1634222012; __utma=223695111.1215803576.1633773615.1634220097.1634222012.10; __utmb=223695111.0.10.1634222012; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1634222012%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3Dwyyw1hAEPCDkeCOiS0lMWDx6tRJnw2gELr3aZop7fzDRrduYHXftRKiI4PbeclDL%26wd%3D%26eqid%3Db60e5a81000182b7000000066161682b%22%5D; _pk_id.100001.4cf6=f75b65b3de20f07e.1633773614.10.1634222012.1634220097.; _pk_ses.100001.4cf6=*; dbcl2="146463518:ozVFabF9880"'
}
def get_movie_list():
resp = requests.get('https://movie.douban.com', headers=header)
resp.encoding = cchardet.detect(resp.content)['encoding']
movie_list_section = re.search(r'<div class="billboard-bd">(.*?)<div id="dale_movie_home_bottom_right"', resp.text, re.S).group(1)
movie_list = re.findall(r'<tr>.*?href="(.*?)">(.*?)</a>', movie_list_section, re.S)
return movie_list
def get_movie_info(movie_url_name):
resp = requests.get(movie_url_name[0], headers=header)
resp.encoding = cchardet.detect(resp.content)['encoding']
movie_info_section = re.search(r'<div id="info">(.*?)</div>', resp.text, re.S).group(1)
director = '/'.join(re.findall(r'href=.*?v:directedBy">(.*?)</a>', movie_info_section, re.S))
screenwriter_section = re.search(r"编剧.*?'attrs'>(.*?)</span>", movie_info_section, re.S).group(1)
screenwriter = '/'.join(re.findall(r'href=.*?>(.*?)</a>', screenwriter_section, re.S))
actor = '/'.join(re.findall(r'href=.*?v:starring">(.*?)</a>', movie_info_section, re.S))
movie_type = re.search(r'property="v:genre">(.*?)</span>', movie_info_section, re.S).group(1)
district = re.search(r'制片国家/地区:</span>(.*?)<br/>', movie_info_section, re.S).group(1)
language = re.search(r'语言:</span>(.*?)<br/>', movie_info_section, re.S).group(1)
initial_release_date = '/'.join(re.findall(r'v:initialReleaseDate.*?>(.*?)</span>', movie_info_section, re.S))
runtime = re.search(r'v:runtime.*?>(.*?)</span>', movie_info_section, re.S).group(1)
movie_detail = {'片名': movie_url_name[1], '导演': director, '编剧': screenwriter, '演员': actor, '类型': movie_type, '制片国家/地区': district,
'语言': language, '上映日期': initial_release_date, '片长': runtime}
return movie_detail
if __name__ == '__main__':
mv_lst = get_movie_list()
movie_detail_list = []
for movie in mv_lst:
movie_detail = get_movie_info(movie)
movie_detail_list.append(movie_detail)
for movie in movie_detail_list:
for key, value in movie.items():
print(f'{key}:{value}')
print()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号