
15 手写数字识别-小数据集(2)
15 手写数字识别-小数据集
15 手写数字识别-小数据集
1.手写数字数据集
- from sklearn.datasets import load_digits
- digits = load_digits()

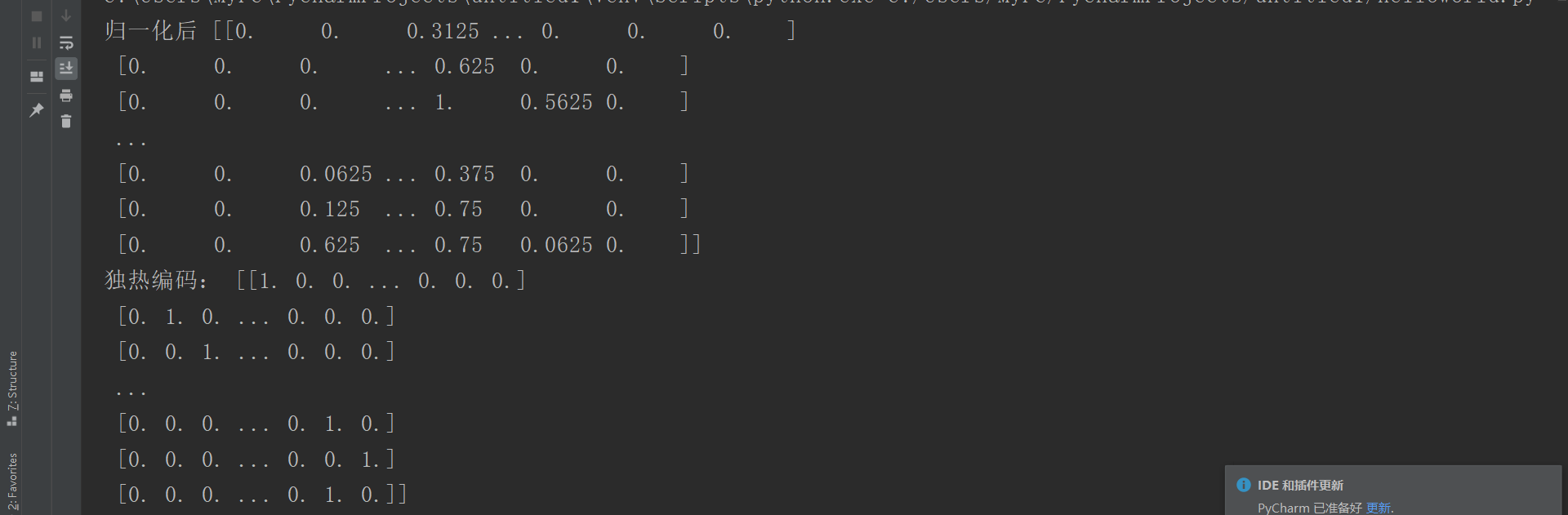
2.图片数据预处理
- x:归一化MinMaxScaler()
- y:独热编码OneHotEncoder()或to_categorical
- 训练集测试集划分
- 张量结

3.设计卷积神经网络结构
- 绘制模型结构图,并说明设计依据。
模型结构图如下:

设计依据:
(1)模型是层的堆叠,参考VGGnet模型,一条路走到黑,小卷积核,小池化核。
(2)模型使用了四层卷积,三个池化层,所以加入Dropout层来防止过拟合。


4.模型训练

def show_train_history(train_history, train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel('train')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
train_history = model.fit(x=X_train, y=y_train, validation_split=0.2, batch_size=300, epochs=10, verbose=2)
show_train_history(train_history, 'accuracy', 'val_accuracy')
show_train_history(train_history, 'loss', 'val_loss')


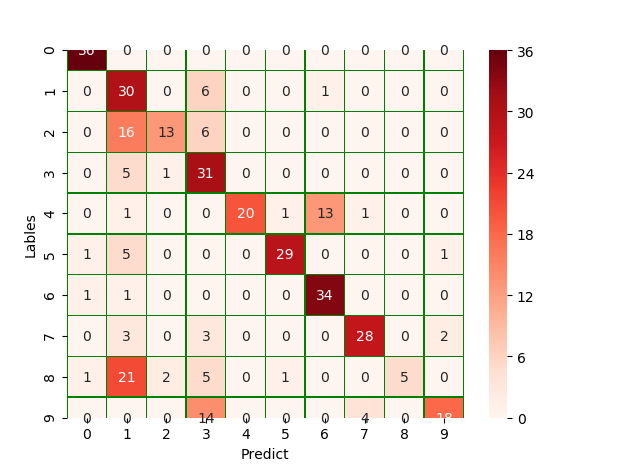
5.模型评价
- model.evaluate()
- 交叉表与交叉矩阵
- pandas.crosstab
- seaborn.heatmap
![复制代码]()
![复制代码]()
score = model.evaluate(X_test, y_test) print('score:', score) y_pred = model.predict_classes(X_test) print('y_pred:', y_pred[:10]) # 交叉表与交叉矩阵 y_test1 = np.argmax(y_test, axis=1).reshape(-1) y_true = np.array(y_test1)[0] pd.crosstab(y_true, y_pred, rownames=['true'], colnames=['predict']) # seaborn.heatmap y_test1 = y_test1.tolist()[0] a = pd.crosstab(np.array(y_test1), y_pred, rownames=['Lables'], colnames=['Predict']) df = pd.DataFrame(a) sns.heatmap(df, annot=True, cmap="Reds", linewidths=0.2, linecolor='G') plt.show()![复制代码]()
![复制代码]()
![]()
![]()

https://www.cnblogs.com/Gidupar/p/13089056.html
家里有事得帮忙 忘记了提交时间

 浙公网安备 33010602011771号
浙公网安备 33010602011771号