Java: 压缩PDF文档
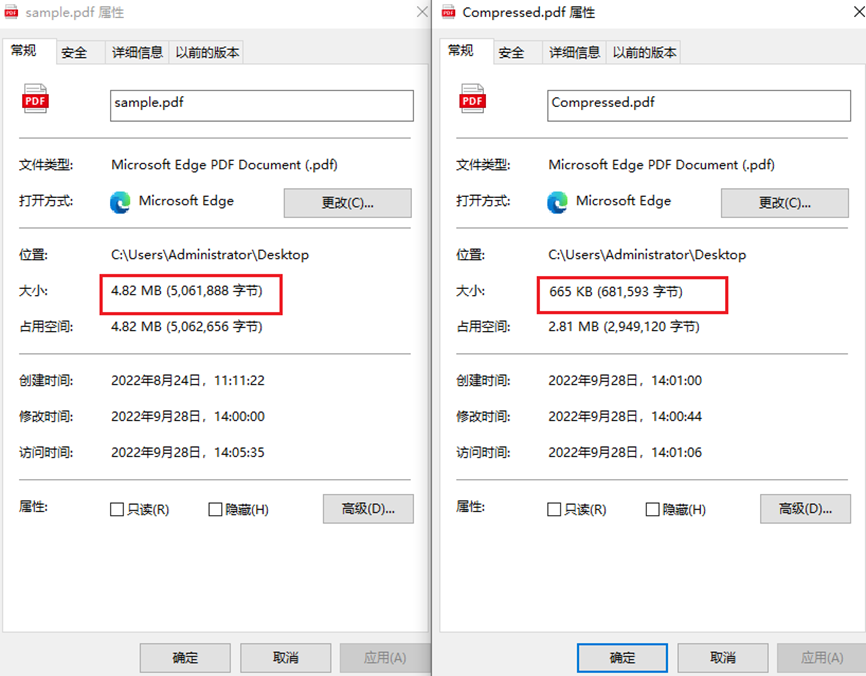
PDF文档在日常工作中应用广泛,经常用于保存公司文件,电子图书或网络资料等大篇幅内容。然而,内容过多往往也会导致PDF文件过大,不便于其保存和发送。在这种情况下,我们可以选择使用Free Spire.PDF for Java压缩PDF文件。这一方法主要通过压缩文件内的图片、不需要的注释行和空格等来压缩文件大小,以此节约储存空间,减少文件传送时间。以下是具体的操作步骤。
安装Spire.PDF.Jar
方法一:
如果您使用的是 maven,可以通过添加以下代码到项目的 pom.xml 文件中,将 JAR 文件导入到应用程序中。
<repositories>
<repository>
<id>com.e-iceblue</id>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf.free</artifactId>
<version>5.1.0</version>
</dependency>
</dependencies>
方法二:
如果您没有使用 maven,则可以从此链接下载Free Spire.PDF for Java,找到lib文件夹下的Spire.PDF.jar并进行解压;然后在IDEA中创建一个新项目,依次点击“文件”(File),“项目结构”(Project Structure),“组件”(Modules),“依赖项”(Dependencies),再点击右方绿色“+”下的第一个选项“JAR文件或路径”(JARs or Directories),找到解压后的Spire.PDF.jar 文件,点击确认,将其导入到项目中。
注意:Free Spire.PDF for Java支持10页内的PDF文档,如果PDF页数过多,可以选择使用Spire.PDF for Java。
压缩PDF文档
下面是详细操作步骤和相关代码:
- 创建PdfDocument类的对象。
- 使用PdfDocument.loadFromFile()方法加载PDF文档。
- 使用PdfDocument.getFileInfo().setIncrementalUpdate() 方法禁用增量更新。
- 使用PdfDocument.setCompressionLevel()方法将压缩级别设置为最佳,用于压缩文档中的内容。您可以从PdfCompressionLevel列举中选择其他级别。
- 遍历文档页面,并使用PdfPageBase.getImagesInfo()方法获取每个页面的图像信息集合。
- 遍历集合中的所有项目,并使用PdfBitmap.setQuality() 方法压缩特定图像的质量。
- 使用PdfPageBase.replaceImage()方法将原始图像替换为压缩图像。
- 使用PdfDocument.saveToFile()方法将文档保存到另一个PDF文档。
import com.spire.pdf.PdfCompressionLevel; import com.spire.pdf.PdfDocument; import com.spire.pdf.PdfPageBase; import com.spire.pdf.exporting.PdfImageInfo; import com.spire.pdf.graphics.PdfBitmap; public class CompressPdfDocument { public static void main(String[] args) { //创建PdfDocument类的对象 PdfDocument doc = new PdfDocument(); //加载PDF文档 doc.loadFromFile("sample.pdf"); //禁用增量更新 doc.getFileInfo().setIncrementalUpdate(false); //将压缩级别设置为最佳 doc.setCompressionLevel(PdfCompressionLevel.Best); //遍历文档页面 for (int i = 0; i < doc.getPages().getCount(); i++) { //获取指定页面 PdfPageBase page = doc.getPages().get(i); //获取每个页面的图像信息集合 PdfImageInfo[] images = page.getImagesInfo(); //遍历集合中的所有项目 if (images != null && images.length > 0) for (int j = 0; j < images.length; j++) { //获取指定图片 PdfImageInfo image = images[j]; PdfBitmap bp = new PdfBitmap(image.getImage()); //设置压缩质量 bp.setQuality(20); //将原始图像替换为压缩图像 page.replaceImage(j, bp); } //将结果文档保存至另一个PDF文档中 doc.saveToFile("Compressed.pdf"); doc.close(); } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号