串
串
知识框架
- 串是内容受限的线性表。
- 数组和广义表是线性结构的推广。
No.1串的定义
-
串( string):是由零个或多个任意字符组成的有限序列,如 S = "
a1 a2 ... an"(n >= 0)。 -
串名:S是串名。
-
串值:
a1 a2 ... an表中元素都是值。 -
串的长度:串中字符的个数 n。
-
空串:n=0时的串。
-
子串:串中任意多个连续的字符组成的子序列(含空串)称为该串的子串。
-
真子串:不包含(主串)自身的所有子串。
-
主串:包含子串的串。
-
字符在主串中的位置(字符位置):某个字符在串中的序号。
-
子串在主串中的位置(子串位置):子串的第一个字符在主串中的位置。
-
串相等:当且仅当两个串的长度相等并且各个对应位置上的字符都相同时,这两个串才是相等。
-
空串与空格串:
- M = "" 是空串。
- N = " " 是空格串。
-
串与线性表:
- 串是特殊的线性表,数据元素之间呈线性关系(逻辑结构相似);
- 串的数据对象限定为字符集:中文字符、英文字符、数字字符、标点字符…
- 串的基本操作,如增删改除通常以子串为操作对象。
No.2串的顺序存储结构
一、顺序串
1.定长分配实现
- 类似于线性表的顺序存储结构,用一组地址连续的存储单元存储串值的字符序列。在串的定长顺序存储结构中,为每个串变量分配一个固定长度的存储区,即定长数组。
- 串的实际长度只能小于等于
MAXLEN,超过预定义长度的串值会被舍去,称为截断。串长有两种表示方法: 一是如上述定义描述的那样,用一个额外的变量len来存放串的长度;二是在串值后面加一一个不计入串长的结束标记字符“\0”,此时的串长为隐含值。 - 在一些串的操作(如插入、联接等)中,若串值序列的长度超过上界
MAXLEN,约定用“截断”法处理,要克服这种弊端,只能不限定串长的最大长度,即采用动态分配的方式。
//头文件
#include <stdio.h>
#include <stdlib.h>
#define OK 1 //成功标识
#define ERROR 0 //失败标识
typedef int Status; //Status是函数的类型,其值是函数结果状态代码,如OK等
#define MAXLEN 255 //预定义最大串长为255
typedef struct{
char ch[MAXLEN]; //每个分量存储一个字符
int length; //串的实际长度
}SString;
2.堆式分配实现
- 堆分配存储表示仍然以一组地址连续的存储单元存放串值的字符序列,但它们的存储空间是在程序执行过程中动态分配得到的。
- 在C语言中,存在一一个称之为“堆”的自由存储区,并用
malloc()和free()函数来完成动则返回一个指向起始地址的指针,作为串的基地址,这个串由ch指针来指示;若分配失败,则返回NULL。已分配的空间可用free()释放掉。
//头文件
#include <stdio.h>
#include <stdlib.h>
#define OK 1 //成功标识
#define ERROR 0 //失败标识
typedef int Status; //Status是函数的类型,其值是函数结果状态代码,如OK等
typedef struct{
char *ch; //按串长分配存储区,ch指向串的基地址
int length; //串的长度
}HString;
No.3串的链式存储结构
一、链式串
1.块链分配实现
- 类似于线性表的链式存储结构,也可采用链表方式存储串值。由于串的特殊性(每个元素只有一个字符),在具体实现时,每个结点既可以存放一个字符, 也可以存放多个字符。每个结点称为块,整个链表称为块链结构。图(a)是结点大小为4 (即每个结点存放4个字符)的链表,最后一个结点占不满时通常用“#”补上;图(b)是结点大小为1的链表。

//头文件
#include <stdio.h>
#include <stdlib.h>
#define OK 1 //成功标识
#define ERROR 0 //失败标识
typedef int Status; //Status是函数的类型,其值是函数结果状态代码,如OK等
# define CHUNKSIZE 80 // 块的大小可自定义
typedef struct Chunk {
char ch[CHUNKSIZE];
struct Chunk *next;
}Chunk;
typedef struct {
Chunk *head, *tail; // 串的头指针与尾指针
int length; // 串的当前长度
}LString;
No.4串的模式匹配算法
- 算法目的:确定主串中所含子串(模式串)第一次出现的位置(定位)
- 算法应用:搜索引擎,拼写检查,语言翻译,数据压缩
- 算法种类:简单匹配算法:
BF算法(经典朴素,穷举);KMP算法(特点:速度快) - 主串:正文串;子串:模式
一、BF算法(Brute-Force)
- 算法思路就是从主串的每一个字符位置开始依次与子串的字符进行比较
- 匹配失败:主串开始 i= 1;子串开始 j = 1;失败后主串回溯 i = i - j + 2;子串回溯 j = 1
- 匹配成功:返回主串当前的 i - 子串长度
- 平均算法时间复杂度O(N*M):N为主串长度M为子串长度
- 子串的定位操作通常称为串的模式匹配,它求的是子串(常称模式串)在主串中的位置。这里采用定长顺序存储结构,给出一种不依赖于其他串操作的暴力匹配算法。

int index_BF(SString S, SString T, int pos)
{
int i = pos, j = 1;
while (i <= S.length && j <= T.length)
{
if (S.ch[i] == T.ch[j])
{ // 主串和子串依次匹配下一个字符
i++;
j++;
}
else
{ // 匹配失败,主串子串回溯重新开始下一次匹配
i = i - j + 2;
j = 1;
}
}
if (j > T.length) // 若超出了子串的范围
{
return i - T.length; // 返回匹配的第一个字符的下标
}
else
{
return 0; // 模式匹配不成功
}
}
二、KMP算法(Knuth Morris Pratt)
- 利用已经部分匹配的的结果而加快模式串的滑动速度
KMP算法的特点就是:仅仅后移模式串,比较指针不回溯。- 且主串S的指针i不回溯,可提速到O(n + m):N为主串长度M为子串长度
- 算法思路:在BF算法基础上,主串S第i个字符与子串T第j个字符不匹配,则i不回溯继续++,j与i匹配失败时,需定义next[j],记录在子串中需要重新和主串中该字符进行比较的字符的位置。
- next[j] = max{k|1<k<j,且从头开始的k-1个元素 = j前面的k-1个元素 当此集合为空时} --> P[1 ~ k-1] == P[j-k+1 ~ j-1] (分别代 表前后缀,并不包括本身)

- next[j] = 0 当 j= 1时
- next[j] = 1 其他情况
- next函数改进:
nextval函数修正值- 默认第一个
nextval的值是0,第二个字符如果和第一个字符相等,那么它的nextval的值就为0,不等就为1。之后遵循如下方法: - 找到当前要求
nextval值的字符,看它的next值下标所指向的字符是否和它相等,相等那么nextval为当前所指下标的nextval值,不相等nextval的值就为本身字符的next值。
- 默认第一个
- 在上面的简单匹配中,每趟匹配失败都是模式后移一位再从头开始比较。而某趟已匹配相等的字符序列是模式的某个前缀,这种频繁的重复比较相当于模式串在不断地进行自我比较,这就是其低效率的根源。
- 因此,可以从分析模式本身的结构着手,如果已匹配相等的前缀序列中有某个后缀正好是模式的前缀,那么就可以将模式向后滑动到与这些相等字符对齐的位置,主串i指针无须回溯,并继续从该位置开始进行比较。而模式向后滑动位数的计算仅与模式本身的结构有关,与主串无关。
1.字符串的前缀、后缀和最大公共前后缀长度
- 要了解子串的结构,首先要弄清楚几个概念:前缀、后缀和部分匹配值。前缀指除最后一个字符以外,字符串的所有头部子串;后缀指除第一个字符外,字符串的所有尾部子串;部分匹配值则为字符串的前缀和后缀的最大公共前后缀长度。下面以
ababa为例进行说明 a的前缀和后缀都为空集最大公共前后缀长度长度为0。ab的前缀为{ a },后缀为{ b } , { a } ∩ { b } = NULL,最大公共前后缀长度长度为0。aba的前缀为{ a , a b }, 后缀为{ a , b a } , { a , a b } ∩ { a , b a } = { a }, 最大公共前后缀长度长度为1abab,前缀∩后缀,{ a , a b , a b a } ∩ { b , a b , b a b } = { a b },最大公共前后缀长度长度为2。ababa,前缀∩后缀,{ a , a b , a b a , a b a b } ∩ { b , a b , b a b , b a b a } = { a , a b a }, 公共元素有两个,最大公共前后缀长度长度为3。- 故字符串
ababa的最大公共前后缀长度为00123。 - 回到最初的问题,主串为
abacabcacbab,子串为abcac。 - 利用上述方法容易写出子串
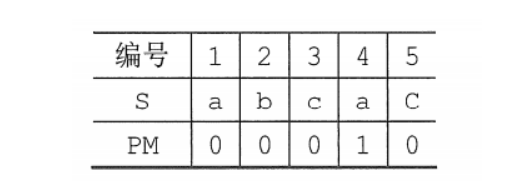
abcac的最大公共前后缀长度为00010,将最大公共前后缀长度值写成数组形式,就得到了最大公共前后缀长度(Partial match,PM)的表。
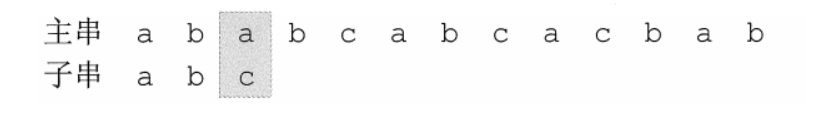
- 第一趟匹配过程:
- 发现c与a不匹配,前面的2个字
ab
是匹配的,查表可知,最后一个匹配字符b对应的部分匹配值为0,因此按照下面的公式算出子串需要向后移动的位数: - 移动位数 = 已匹配的字符数 − 对应最大公共前后缀长度
- 因为2−0=2,所以将子串向后移动2位,如下进行第二趟匹配:
- 发现c与a不匹配,前面的2个字

- 第二趟匹配过程:
- 发现c与b不匹配,前面4个字符
abca
是匹配的,最后一个匹配字符a对应的部分匹配值为1,4−1 = 3,将子串向后移动3位,如下进行第三趟匹配:
- 发现c与b不匹配,前面4个字符

- 第三趟匹配过程:
- 子串全部比较完成,匹配成功。整个匹配过程中,主串始终没有回退,故
KMP算法可以在O ( n + m )的时间数量级上完成串的模式匹配操作,大大提高了匹配效率。
- 子串全部比较完成,匹配成功。整个匹配过程中,主串始终没有回退,故
2.对算法的改进方法
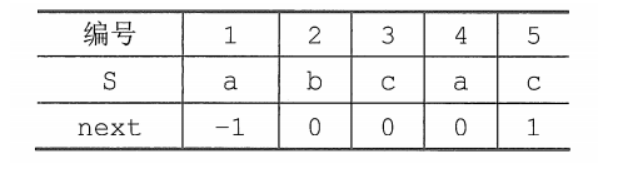
- 使用部分匹配值时,每当匹配失败,就去找它前一个元素的部分匹配值,这样使用起来有些不方便,所以将PM表右移一位,这样哪个元素匹配失败,直接看它自己的部分匹配值即可。将上例中字符串
abac的PM表右移一位,就得到了next数组:
- 有时为了使公式更加简洁、计算简单,将next数组整体+1。因此,next数组就变成:

- 最终得到子串指针变化公式j = next[j]。
- next[j]的含义是:在子串的第j个字符与主串发生失配时,则跳到子串的next[j]位置重新与主串当前位置进行比较。
- 通过分析,可以知道,除第一个字符外,模式串中其余的字符对应的next数组的值等于其最大公共前后缀长度加上1
- next[j] = 最大公共前后缀长度+1
- 科学的推导得出以下公式:
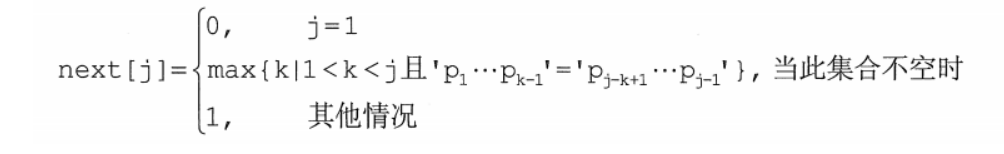
// 计算next函数值 --> 常用
void get_next(String T, int *next)
{// 求模式串T的next函数值并将其存入数组next中
int i = 1, j = 0;
next[1] = 0;
while (i < T.length){
if(j==0 || T.ch[i]==T.ch[j]){ //ch[i]表示后缀的单个字符,ch[j]表示前缀的单个字符
++i; ++j;
next[i] = j; //若pi = pj, 则next[j+1] = next[j] + 1
}else{
j = next[j]; //否则令j = next[j],j值回溯,循环继续
}
}
}
int Index_KMP(String S, String T)
{// 利用模式串T的next函数求T在主串S中第pos个字符之后的位置
int i=1, j=1;
int next[255]; //定义next数组
get_next(T, next); //得到next数组
while(i<=S.length && j<=T.length){
if(j==0 || S.ch[i] == T.ch[j]){ //字符相等则继续
++i; ++j;
}else{
j = next[j]; //模式串向右移动,i不变
}
}
if(j>T.length){
return i-T.length; //匹配成功
}else{
return 0;
}
}
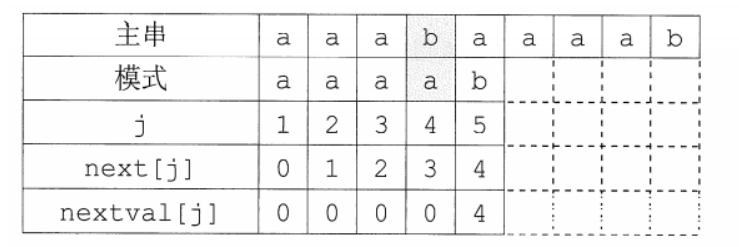
3.KMP算法的进一步优化
- 前面定义的next数组在某些情况下尚有缺陷,还可以进一步优化。如图所示,模式
aaaab
在和主串aaabaaaaab进行匹配时:
// 计算next修正值 --> 不常用
void get_nextval(SString T, int *nextval)
{// 求模式串T的next函数值并将其存入数组nextval中
int i = 1, j = 0;
nextval[1] = 0;
while (i < T.length){
if(j==0 || T.ch[i]==T.ch[j]){ //ch[i]表示后缀的单个字符,ch[j]表示前缀的单个字符
++i; ++j;
if(T.ch[i] != T.ch[j]){ //若当前字符与前缀字符不同
nextval[i] = j; //则当前的j为nextval在i位置的值
}else{
//如果与前缀字符相同
//则将前缀字符的nextval值给nextval在i位置上的值
nextval[i] = nextval[j];
}
}else{
j = nextval[j]; //否则令j = next[j],j值回溯,循环继续
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号