
面向对象第三单元作业
(1)JML语言理论基础,应用工具链情况
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。通过JML及其支持工具,不仅可以基于规格自动构造测试用例,并整合了SMT Solver等工具 以静态方式来检查代码实现对规格的满足情况。
几个重要部分
requires子句定义该方法的前置条件(precondition)
副作用范围限定,assignable列出这个方法能够修改的类成员属性
ensures子句定义了后置条件
表达式
原子表达式
\result:表示一个非 void 类型的方法执行所获得的结果
\old( expr )表达式:用来表示一个表达式 expr 在相应方法执行前的取值
量化表达式
比如\forall, \exists, \sum等
其他例子
\sum:返回给定范围内表达式的和,例如:(\sum int i; 0<=i && i< 5; i)得到的结果为0+1+2+3+4=10。
\max:返回给定范围内表达式的最大值。
\min:返回给定范围内表达式的最小值。
\nothing:表示一个空集,常常在副作用中使用,assignable \nothing表示这个方法没有副作用。
操作符
JML表达式中可以正常使用Java语言所定义算术操作符、逻辑预算操作符等,此外又专门定义了:
子类型关系操作符、等价关系操作符、子类型关系操作符、变量引用操作符
JML应用工具链
JML相应的工具链,可以自动识别和分析处理JML 规格。常用的有:
openjml,其使用SMT Solver来对检查程序实现是否满足所设计的规格(specification)。目前openjml封装了四个主流的solver:z3, cvc4, simplify, yices2。
JMLUnitNG,可以根据JML自动生成对应的测试样例,用于进行单元化测试。
(3)JMLUnitNG/JMLUnit
public class Demo {
public static void main(String[] args) {
add(233, 666);
}
/*@ public normal_behaviour
@ ensures \result == x + y;
*/
public static int add(int x, int y) {
return x + y;
}
}
测试步骤:
首先将jmluning.jar复制到当前目录下
1.生成文件
java -cp jmlunitng.jar Demo.java
2.编译
javac -cp jmlunitng.jar *.java
source ~/openjml.sh -rac Demo.java
3.测试
java -cp jmlunitng.jar Demo_JML_Test
测试结果如下图所示:
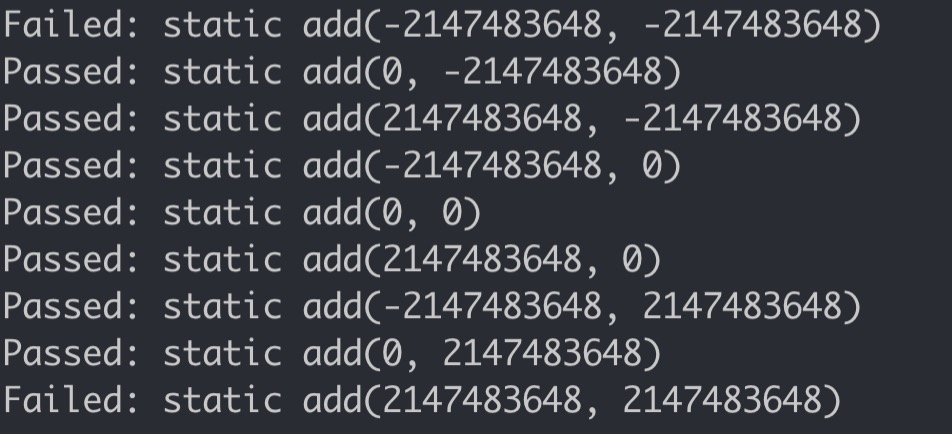
可以看到,生成的测试样例主要覆盖了边界情况(正负Integer.Max)和0,由于没有对输入进行限定,如果两个输入都是Integer.Max或者负Integer.Max,将会出现溢出情况。
(4)架构设计
第一次作业比较简单;
第二次作业
MyPath
相比第一次做了优化,MyPath内部构造了一个HashMap用来存储整个图,这样可以提升不少效率,比如containsNode可以利用HashMap的keyset进行判定;getDistinctNodeCount可以直接return HashMap的keySet的大小;
MyGraph
除了plist和pidList,构建了一个HashMap用于存储所有path组成的图结构。每次加入一个path就新增一些节点和边;每次remove一个path就删除一些边,如果某个节点没有边,那么也删除这个节点;这个图结构可以方便某些操作的进行,比如containsNode、containsEdge、getDistinctNodeCount,也方便之后的BFS搜索;
如果plist的构建没有大小关系,那么Path寻找操作是需要依次遍历的,非常麻烦,于是考虑把plist做成有序的,这样每次查找可以用二分查找。另一方面,如果plist是有序的,那么pidList不能保证有序,于是设计的时候构建了一个叫做id2Path的HashMap,存储<id,path地址>构成的键值对,应对getPathById、containsPathId、removePathById操作都可以在很快的时间内完成。
关于getShortestPathLength和isConnected,二者之行内容基本都是BFS算法,考虑到可能出现二次查询,构建了一个record用来存储之前的数据。新来查询的时候先查record,里面没有再执行BFS。另外addPath和removePath的时候需要清空record,一方面因为图结构变动的时候这些结果可能都会变,另一方面是如果不清空,维护record的成本太高。
第三次作业
MyPath
和上一次基本没有啥变化
MyRailwaySystem
第三次作业架构比较复杂,如下图所示
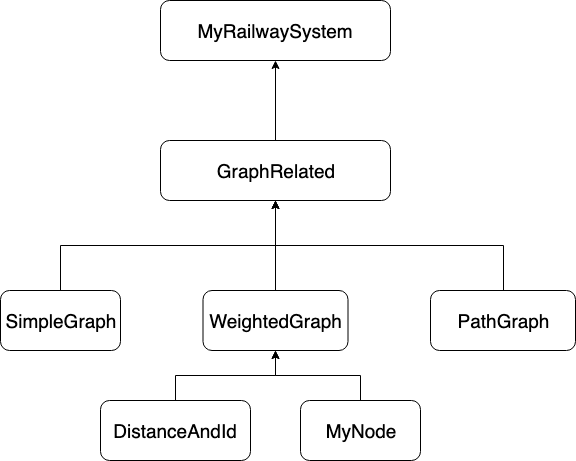
MyRailwaySystem是要求实现的类别,其中所有涉及的图操作都被分离出去,分离出去的结构是一个二级结构,GraphRelated负责协调下面各个部分,作为承上启下的接口,MyRailwaySystem接收一个指令,GraphRelated判定该由谁负责,然后派给那个class,并收集结果,返回给MyRailwaySystem。底层分设三个class,分别是SimpleGraph,WeightedGraph,PathGraph;DistanceAndId和MyNode都是用于辅助WeightedGraph的类别,因为时间比较紧所以起的名字有点糙。
SimpleGraph
这个图结构是专门用来处理getShortestPathLength的,和第二次作业中的图结构一样,使用BFS算法搜索。
一点小改进是查询历史的存储,第二次作业中仅仅保存了fromNodeId至toNodeId的最短路径数据,中间计算结果并没有保留。事实上,从fromNodeId到toNodeId路上经过的点,每两组点在这条路径上的距离都是二者在图中的距离,记录这些信息的成本比较低,于是做了优化。其他的成本略高,纠结了一会就没做记录。
此外,SimpleGraph其实可以看成下面要介绍的WeightedGraph的一个特例,如果重新设计结构,可以把他俩合并。
PathGraph
PathGraph的提出是为了简化"最小换乘次数"的查找,PathGraph内部包含两个HashMap:
【1】pathIntersection,key是PathId,用于记录和当前Path相交的所有Path
【2】nodeOnPaths,key是NodeId,用于记录当前节点所在的所有Path的PathId
查找"最小换乘次数",首先从【2】中找到fromNode都在哪条路上,然后依次找toNode是否也在,如果不在,就访问【1】,把与自己相交且之前没访问过的Path加入队列。
同样的,这里也设置了历史记录功能;
WeightedGraph
(1)节点唯一表示法:注意到真实地铁中的换乘,从一条线路换到另一条线路往往也是要走一段距离的,因此不妨将不同线路上的同一个Node看成不同的节点,然后为Id不同的节点制定一套权重方案,为Id相同但是不在一条线上的节点制定一套方案。
为了区分Id相同,线路不同的点,我的设计是将所有的节点用字符串表示,字符串内容为:
$$PathId.toString() + "."+NodeId.toString()$$
这个将作为HashMap图结构的Key
(2)MyNode:接着介绍一下 MyNode类,可以看成邻接表的表头,类内部包含一个字符串name,记录此节点按照上述命名法得到的名字;且包含两个HashMap:uplEdges和transEdges,分别记录和自己相邻的边的两种权重:不满意度与票价,HashMap的Key是MyNode类型(相当于key就是指针),这样直接通过边信息就可以访问到另一个MyNode节点。顺便需要重写hashCode和equals方法,直接对name操作就可以搞定。
(3)查询:WeightedGraph内部包含一个HashMap<String, MyNode>,存储着名字和相应MyNode之间的联系。查询的时候,首先通过PathGraph得到fromNode都在哪些路上,从而构造出所有可能的name字符串,将对应的MyNode设置成距离src为0,运行迪杰斯特拉算法,如果查询不满意度就用uplEdges,否则用transEdges。这里也设置了历史记录功能,选了性价比比较高的记录原则,就是把所有找到最短路的点都和src建立联系。
(5)Bug分析
第一次作业问题出在算法效率上,写代码的时候没有主要到时间要求,导致了部分样例运行超时;
第二次作业问题出在getShortestPathLength函数fromNodeId和toNodeId相等情况的处理上。实现的时候对相等情况的处理写在了containsNode判定前面,导致即便fromNodeId和toNodeId不存在但是相等,就会返回0;
第三次作业没有bug;
(6)心得与体会
JML是一个很有用的工具,规格写清楚了,只要代码按照规格来,就不会有问题。不同协作者之间不需要完全理解程序架构的细节,只需要实现满足规格的规定即可。不过规格的写作会是一个难点,有时候一个函数的规格需要很多行才能表述清楚,容易出现错误。第十一次作业展示的通过将部分功能分散到另一个函数,然后在规格中调用函数来简化规格的做法比较巧妙。
写代码架构设计很重要,需要写代码前规划好哪些方法需要哪些类型的数据结构来实现,这些数据结构之间有怎样的联系(比如构建其中一个需要另一个),他们是否相互独立还是可以进行合并,等等。有的时候一开始很难直接想的很全面,不过如果大体框架想好了,后面的改动也不算很大。此外,将各个部分独立到各自的文件中可以显著提升代码整洁程度,提升准确率,后期微调的时候可以专注于一个文件,不至于太混乱。如果合并工作处理的好,不至于出现多个数据结构/类的操作相同的情况,这样可以避免微调的时候需要重复修改多个地方,提升效率降低错误率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号