
1、 java 是由四方面组成的:java编程语言、java类文件格式、java虚拟机和java应用程序接口(java API)组成。
2、 java编译环境是:java源码文件通过java编译器(Eclipse,idear)等编译成java字节码文件(.class文件)
3、 javac编译器是官方JDK中提供的前端编译器,JDK/bin 目录下的javac只是一个与平台相关的调用入口,具体的实现是在JDK/lib目录下的tools.jar
4、 javac编译器源码编译
a、解析与填充符号表过程:解析主要包括词法分析和语法分析两个过程;
b、插入式注解处理器的注解处理过程;
c、语义分析与字节码的生成过程;
javac经过第一步的解析(语法分析和语法分析),会生成用来一颗描述程序代码语法结构的抽象语法树,每个节点都代表程序代码中的一个语法结构,
包括:包、类型、修饰符、运算符、接口、返回值、甚至注解等;而后不同的编译阶段都定义不同的访问者去处理改语法树(节点)。(访问者模式)
5、解析与填充符号表:
a、解析包括:词法、语法分析
a1、词法分析是将源代码的字符流转换为标记(token)集合
标记是编程过程中最小元素,包含关键字、变量名、字面量、运算符(甚至一个".")等。
a2、语法分析是根据token序列构造抽象语法树的过程
抽象语法树是一种描绘程序代码结构的树形表达方式
语法结构(Construct)包括:包、类型、修饰符、运算符、接口、返回值、甚至注释等;
b、填充符号表
符号表是由一组符号地址和符号信息构成的表格,可以想象成哈希表中的K-V值的形势
符号表登记的信息在编译的不同阶段都要用到,如:
1) 用于语义检测和产生中间代码
2) 在目标代码生成阶段,符号表是对符号名进行地址分配的依据
6、 java整体机构
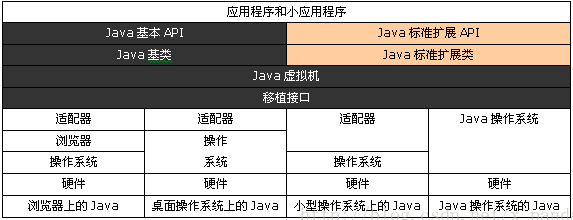
可以看出,在java平台结构中,java虚拟机(JVM)处于核心位置,是程序与底层和硬件无关的关键
JVM 下方:是移植接口
移植接口是由 适配器 和java操作系统
适配器:依赖于平台的部分,------------jvm通过移植接口在具体的平台和操作系统上实现 。
JVM 上方:java的基本类库和扩展类库以及它们的API
7、 JVM 在它的生存周期中有一个明确的任务,那就是运行java程序因此当Java程序启动的时候,就产生JVM的一个实例;
当程序运行结束的时候,该实例也跟着消失了。
8、JVM 机制
a、类装载子系统:装载具有合适名称的类或接口
b、执行引擎:负责执行包含在已装载的类或者接口的指令。
9、 JVM包含:
方法区、Java堆、java栈、本地方法栈、指令计数器与其他隐含寄存器
10、流程
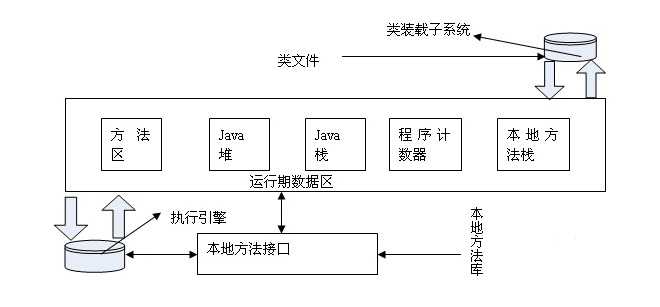
从这个结构中不难看出,class文件被jvm装载后,经过jvm的内存空间调配,最终由执行引擎完成clas文件的执行。
JVM关注:
java代码编译和执行的整个过程
JVM内存管理以及垃圾回收机制
11、java 代码编译是由java源码编译器来完成,流程如下
源代码--->(经过)词法分析器--->token流---->(经过)语法分析器
---->语法树/抽象语法树---->(经过)语义分析器------->注解抽象语法树---->字节码生成器---->JVM字码节
12、java 字节码的执行是由JVM执行引擎来完成的
13、java代码编译和执行的整个过程包含了以下三个重要的机制:
a、java源码编译机制
b、类加载机制
c、类执行机制
14、java源码编译主要经过三个过程;
a、分析和输入到符号表
b、注解处理
c、语义分析和生成class文件
模式是:访问者模式
生成的class文件组成:
a、结构信息:包含class文件格式版本号以及各部分的数量和大小信息
b、元数据:对应的java源码中声明与常量的信息.包含类/继承的超类/实现的接口的声明信息、域与方法声明信息和常量池
c、方法信息:对应的java源码中语句和表达式对应的信息。包含字节码、异常处理器表、求值栈与局部变量区大小、求值栈的类型记录、调试符号信息
15、类加载机制:
JVM的类加载是通过classLoader以及其子类来完成的
这块有写的博客
16、类执行机制
JVM是基于堆栈的虚拟机
JVM为每个新创建的线程分配一个堆栈(也就是对于一个程序来说,它的运行是通过对堆栈的操作来完成的)
堆栈以帧为单位保存线程的状态
JVM对堆栈只进行两种操作:以帧为单位的压栈和出栈操作
JVM执行class字节码,线程创建后,都会产生程序计数器(PC)和栈(Stack)
PC:存放下一条要执行的指令在方法内的偏移量。
Stack:栈中存放一个个栈帧,每个栈帧对应每个方法的每次调用,而栈帧又是由局部变量区和操作数栈两部分组成。
局部变量区:存放方法中的局部变量和参数。
操作数栈:存放执行方法过程中产生的中间结果。
17、堆内存(heap)
new创建的对象的内存都会在堆中分配
存储的全部是对象,每个对象都包含一个与之对应的class信息。(class的目的是得到操作指令)
jvm只有一个heap区,被所有线程共享,不存放基本类型和对象引用,只存放对象本身。
堆的优劣势:堆的优势是可以动态的分配内存大小,生存期也不必事先告诉编译器,java的垃圾收集器会自动收取这些不在使用的数
18、栈内存(stack)
每个线程包含一个stack区,只保存基本数据类型的对象和自定义对象的引用(不是对象),对象都存放在heap区 ------生命周期和线程相同,一个线程对应一个java栈
每个栈中的数据(数据类型和对象引用)都是私有的,其他栈不能访问。
栈分为3部分:基本类型变量区、执行环境上下文、操作指令区(存放操作指令)
栈的优势劣势:存取速度比堆要快,仅次于直接位于CPU的寄存器,但必须确定的是存在stack中的数据大小与生存期必须是确定
的,缺乏灵活性。单个stack的数据可以共享。
stack:是一个先进后出的数据结构,通常保存方法中的参数,局部变量。
在java中,所有基本类型和引用类型都在stack中储存,栈中数据的生存空间一般在当前scopes内
java栈空间不足了,程勋会抛出StackOverflowError异常,例如递归
19、方法区:
又叫静态区,跟堆一样,被所有的线程共享,方法区包含所有的class和static变量
方法区中包含的都是程序中永远的唯一元素。
20、PC寄存器:
类已经被加载了,实例对象、方法、静态变量都去了自己应该去的地方,那么问题来了,程序该怎么执行,那个方法先执行,那个方法后执行,
这些指令执行的顺序就是PC寄存器在管理,它的作用就是控制程序的执行顺序。
执行引擎当然就是根据PC寄存器的指令顺序,依次执行程序指令。
21、HelloWorld
java代码---->java字节码(class文件)---->java HelloWorld ----->加载配置(根据系统版本,寻求jvm.cfg文件)
---->根据配置找到jvm.dll(jvm.dll文件则是jvm的主要实现)-------->初始化jvm,获取JNI接口(JNI接口是java本地接口,通过JNI接口才能装载class文件,它还常用于和操作
系统、硬件的交互)----->找到并执行main方法。
jvm.cfg:jvm的配置文件,位置 D:\Java\jdk1.7.0_80\jre\lib\amd64\jvm.cfg,通过jvm.cfg找到对应的jvm.dll文件
jvm.dll:jvm虚拟机的主要实现。位置: D:\Java\jdk1.7.0_80\jre\bin\server\jvm.dll
JNI接口:java本地接口。JVM怎么从硬盘上找到这个文件并装载到JVM里呢,就是通过JNI接口(它还常用于java与操作系统、硬件交互),找到class文件后并装载进
JVM,然后找到main方法,最后执行
22、JVM配置参数分为三类参数:
a、跟踪参数
b、堆分配参数
c、栈分配参数
23、垃圾回收器的算法:
a、stop the world :执行某一个垃圾回收器算法的时候,JVM为了垃圾回收,会暂停java应用程序,等垃圾回收完成后,再继续运行。尽可能的减少stop the world的时间,就是我们优化jvm的主要目标。
b、引数算法:各个对象的引用个数,为0清楚
c、标记清除:标记可达不可达(存活/不存活),从GC Root遍历他们,清除不可达的内存
d、标记压缩:标记清除的算法上添加压缩
e、复制算法:把内存一分为二,只使用其中的一份,垃圾回收的时候,将正在使用的存活的复制到另一份空白的内存中,最后将正在使用的内存空间对象清除,完成垃圾回收。
24、垃圾回收器:
java堆内存结构包括:新生代和老年代,其中新生代由一个eden(伊甸区)和两个幸运区(s0 和 s1两个区)组成。两个幸运区是完全对称的,没有任何差别,也可以称作
from区和to区
a、串行回收器:单线程,新生代复制算法,老年代标记压缩算法。串行收集器是最古老最稳定的收集器
b、并行回收器:多线程回收器
b1、ParNew回收器:这个回收器只针对新生代进行并发回收,老年代依然使用串行回收。回收算法依然和串行回收一样,新生代使用复制算法,老年代使用标记压缩算法
b2、Parallel回收器:依然是并行回收器,但这种回收器有两种配置,一种类似于ParNEW:新生代使用并行回收、老年代使用串行回收。它与ParNew的不同在于它在
设计目标上更重视吞吐量,可以认为在相同的条件下它比ParNew更优
Parallel回收器另外一种配置则不同于ParNew,对于新生代和老年代均适应并行回收
c、CMS回收器:并发、标记、清除
程序与垃圾回收器同步执行。
步骤大致为:应用程序线程-->初始标记-->并发标记-->重新标记--->并发清理
CMS的优点,减少了程序的停顿时间,让回收程序和应用线程可以并发执行。
CMS的缺点,回收不彻底,频繁的回收将影响程序的吞吐量
d、GI回收器
jdk1.7以后推出的回收器,试图取代CMS回收器
将堆空间画为多个相互独立的区块,第一时间处理垃圾最多的区块。
G1相对CMS回收器来说优点在于:
d1、因为划分了很多区块,回收时减小了内存碎片的产生;
d2、G1适用于新生代和老年代,而CMS只适用于老年代。
25、GC的相关指令
-XX:+UseSerialGC:在新生代和老年代使用串行收集器
-XX:+UseParNewGC:在新生代使用并行收集器
-XX:+UseParallelGC :新生代使用并行回收收集器,更加关注吞吐量
-XX:+UseParallelOldGC:老年代使用并行回收收集器
-XX:ParallelGCThreads:设置用于垃圾回收的线程数
-XX:+UseConcMarkSweepGC:新生代使用并行收集器,老年代使用CMS+串行收集器
-XX:ParallelCMSThreads:设定CMS的线程数量
-XX:+UseG1GC:启用G1垃圾回收器
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号