
线性代数:
矩阵:
矩阵有三种类型:
1、向量 1*n(1行n列) 或者n*1(n行1列)
![]()
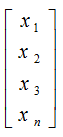
2、标量 1*1(1行1列)
3、普通矩阵 m行n列
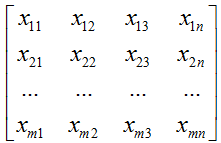
矩阵的加减法,直接用A,B同位置的数加减就行,不过两个矩阵的形态要相同
矩阵的乘法,A x B ,A的列数一定要和B的行数相等,例如:
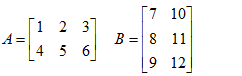 如图,A有3列,B有3行,所以两个矩阵可以相乘
如图,A有3列,B有3行,所以两个矩阵可以相乘
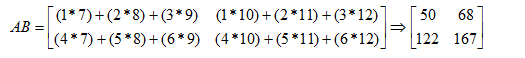
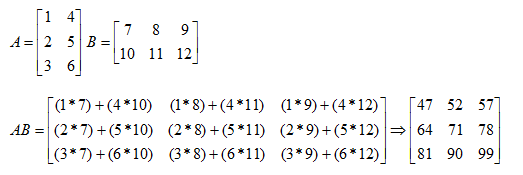
矩阵的常用转置算法:
(AT)T = A (A+B)T =AT+BT (λA)T = λAT (AB)T = BTAT
T是转置的意思,如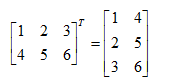
行列式:
行列式是NXN行的方阵,且行长度等于列长度
 行列式用的是竖线而不是中括号[ ]
行列式用的是竖线而不是中括号[ ]
行列式的结果用代数余子式进行计算:
代数余子式是将 A行列 * (-1)行+列 * A行列 的余子式
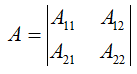 A11的余子式为去除A11所在的行和列,代数余子式为↓
A11的余子式为去除A11所在的行和列,代数余子式为↓
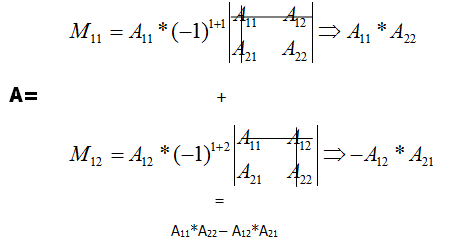

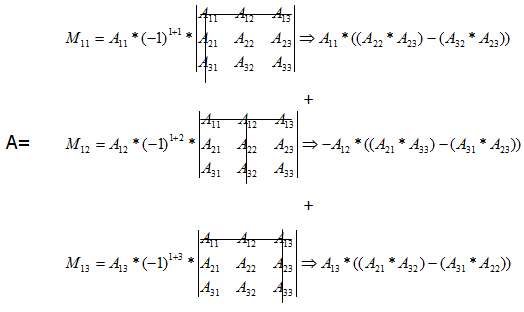
cmd → jupyter notebook
import import numpy as np arr1 = np.array([[1,2,3][4,5,6]]) #创建一个数组 arr1.shape #查看维度 arr1.T #将数组或者矩阵转置 matrix_1 = np.mat([1,2,3]) #创建一个矩阵 arr_zero = np.zeros((i,j)) #创建一个i行j列的全0数组 arr_ones = np.ones((i,j)) #创建一个i行j列的全1数组 arr_range = np.arange(10) arr_range ------------------------------ array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) arr_range.reshape(i,j) #将数组转成i行j列数组,但是数值总数要一样才行 arr_random = np.random.random((2,2)) arr_range = np.arange(12).reshape(3,4) arr_range --------------------------------------------- array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) arr_range.sum(axis=1) #axis 0是按列求和,1是按行求和 -------------------------- array([[ 0, 1, 3, 6], [ 4, 9, 15, 22], [ 8, 17, 27, 38]], dtype=int32) a.ravel() #将a数组变成一维数组后输出,但是a本身不变 a.transpose() #和T一样也是转置 a = np.random.randint(2,6,(3,4)) #创建一个3行4列,数值2-5(左闭右开) b=np.random.randint(1,4,(3,4)) a,b --------------------------------------------- (array([[2, 4, 5, 4], [5, 3, 2, 5], [3, 2, 2, 5]]), array([[3, 1, 2, 2], [1, 1, 1, 1], [1, 1, 1, 3]])) np.vstack((a,b)) #垂直合并 --------------------------------- array([[2, 4, 5, 4], [5, 3, 2, 5], [3, 2, 2, 5], [3, 1, 2, 2], [1, 1, 1, 1], [1, 1, 1, 3]]) np.hstack((a,b)) #水平合并 --------------------------------- array([[2, 4, 5, 4, 3, 1, 2, 2], [5, 3, 2, 5, 1, 1, 1, 1], [3, 2, 2, 5, 1, 1, 1, 3]]) np.diag((1,2,3,4,5)) #创建一个对角阵 --------------------------------------- array([[1, 0, 0, 0, 0], [0, 2, 0, 0, 0], [0, 0, 3, 0, 0], [0, 0, 0, 4, 0], [0, 0, 0, 0, 5]]) like = np.ones_like(a) #创建一个跟a同形状的全1数组 print(a) print(like) --------------------------------------- [[2 4 5 4] [5 3 2 5] [3 2 2 5]] [[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]] s = np.eye(n) #创建一个n*n的对角阵 a.dtype #查看数据类型 s[i,j] #取第i行第j列 b[:,j] #取所有行的第j列 print(s == 1) #判断每个值是否为1 print(s<1) #判断每个值是否小于1 arr[arr==x] = y #将数组中等于x的值替换成y a = np.array([[1,2,3],[4,5,6]]) b = np.array([[7,8,9],[10,11,12]]) print(a) print(b) -------------------------------------- [[1, 2, 3], [4, 5, 6]] [[ 7, 8, 9], [10, 11, 12]] print(a*b) #数组点乘,将同位置的数值相乘 -------------------------------------- [[ 7, 16, 27], [40, 55, 72]] with open('arr_1','wb') as f: #保存数组到文件 pickle.dump(arr_1,f) with open('arr_1','rb') as f: #从文件中读取数组 arr_11 = pickle.load(f) np.save('arr_2',arr_2) #同上 arr_3 = np.load('arr_2.npy') np.savez('multi_arr',arr_1,arr_3) #将多个数组压缩保存 arr_4 = np.load('multi_arr.npz') print(arr_4['arr_0']) #没给数组取名的话系统会自动生成名字 print(arr_4['arr_1']) np.savez('multi_arr2',a1=arr_1,a2=arr_3) arr_4 = np.load('multi_arr2.npz') print(arr_4['a1']) print(arr_4['a2'])
点乘和积乘:
点乘有两种:一种是 m*n数组 * m*n数组 或者 是 m*n数组 * 向量,向量的行数或列数要和数组相同才行
------------数组*向量↓---------------- ar1 = np.array([[1,2,3,4],[5,6,7,8]]) ar2 = np.array([[2],[4]]) print(ar1,ar2) -------------------------------------- [[1 2 3 4] [5 6 7 8]] [[2] [4]] print(ar1*ar2) #横向量也行 -------------------------------------- [[ 2, 4, 6, 8], [20, 24, 28, 32]] #################################################### -----------m*n数组 * m*n数组 ↓---------- arr3 = np.array([[1,2,3,4],[5,6,7,8]]) arr4 = np.array([[2,2,3,4],[5,6,7,8]]) print(arr3) print(arr4) ----------------------- [[1 2 3 4] [5 6 7 8]] [[2 2 3 4] [5 6 7 8]] print(arr3 * arr4) ------------------------ [[ 2 4 9 16] [25 36 49 64]]
arr_load = np.genfromtxt('filename',dtype=str,delimiter=',') #dtype是读取后的数据类型,delimiter用法和split一样

 浙公网安备 33010602011771号
浙公网安备 33010602011771号