
多任务:
frok():只能在linux下执行
import os import time #在程序运行时,父进程的ID就已经生成完毕了 print('当前进程是父进程,id是:%s'%os.getpid()) ret = os.fork() #创建一个子进程 #ret的值在父进程中是子进程的ID,在子进程中则返回0 print('ret的值是%s'%ret) print('*'*50) if ret == 0: #ret值为0,是子进程 print('这是一个子进程:%s,他的父进程是:%s'%(os.getpid(),os.getppid())) time.sleep(1) #os.getpid()是返回当前进程id,os.getppid()是返回当前进程的父进程id elif ret > 0: #ret值大于0,是在父进程中 print('这是父进程:%s,子进程的值是:%s'%(os.getpid(),ret)) time.sleep(1) else: print('进程创建失败') time.sleep(1)
如果主进程退出,整个进程就直接退出了,不会因为子进程没执行完而等待子进程结束后才结束整个进程
子进程中修改的全局变量不会影响到父进程的全局变量,多进程中,数据不共享,如果想共享进程中的数据,需要进程间通信
多次fork()的结果:
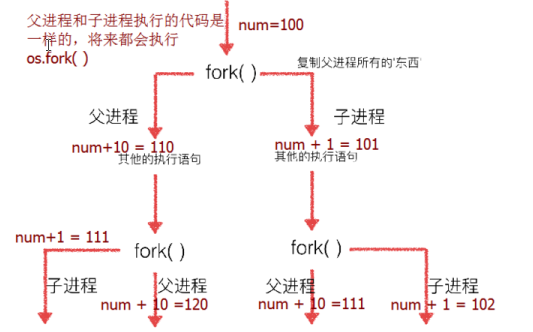
父进程,子进程执行顺序没有规律,完全看操作系统的调度代码
multiprocessing 在windows上也能用的多进程模块,他提供了一个Process类来代表一个进程对象,这样就能实现跨平台开发了
fork()创建的子进程,如果主进程退出,就所有进程退出
Process类创建的子进程,主进程退出后还会继续执行
from multiprocessing import Process import os import time #将子进程要执行的代码放入函数中 def run_proc(name): print('子进程运行中,name = %s , pid = %d...'%(name,os.getpid())) if __name__ == '__main__': print('父进程%d'%os.getpid()) #创建一个Process的实例对象,一个实例对象就是一个子进程 p = Process(target=run_proc,args=('test',)) #传入的是元组,如果只有一个值,要在结尾加逗号 #target后面放的是子进程要运行的函数 #args放的是target里函数需要的参数 print('子进程开始执行') p.start() #开始执行子进程 p.join() #等待子进程结束后才继续执行后面的函数,通常用于进程同步 print('子进程结束执行')
实例练习:
from multiprocessing import Process import os import time #将子进程要执行的代码放入函数中 def run_proc(name,age,**kwargs): for i in range(10): print('子进程运行中,name = %s,age=%d,pid = %d...'%(name,age,os.getpid())) print(kwargs) time.sleep(1) print('子进程结束') if __name__ == '__main__': p = Process(target=run_proc,args=('test',18),kwargs={'tom':'alice'}) print('子进程将要执行') p.start() time.sleep(1) p.terminate() #杀死子进程 p.join() print('父进程结束')
发现子进程就运行了一秒后就被强行结束了,结束后执行输出父进程结束,如果没有调用terminate()的话,会等到子进程循环完才结束
实例练习2:
from multiprocessing import Process import os import time def work_1(interval): print('work_1父进程(%s),当前进程(%s)'%(os.getppid(),os.getpid())) t_start = time.time() #取当前的时间戳 time.sleep(interval) t_end = time.time() print('work_1 执行时间为%.2f秒'%(t_end-t_start)) print('work_1结束') def work_2(interval): print('work_2父进程(%s),当前进程(%s)'%(os.getppid(),os.getpid())) t_start = time.time() #取当前的时间戳 time.sleep(interval) t_end = time.time() print('work_2 执行时间为%.2f秒'%(t_end-t_start)) print('work_2结束') if __name__ == '__main__': print('当前程序ID(父进程):%s'%os.getpid()) p1 = Process(target=work_1,args=(2,)) p2 = Process(target=work_2,name='dd',args=(3,)) #name参数是给进程取个进程名,没有调用的话程序会默认生成Process-x的程序名 p1.start() p2.start() print('p1.name=%s'%p1.name) print('p1.pid=%d'%p1.pid) print('p2.name=%s'%p2.name) print('p2.pid=%d'%p2.pid) print('主进程结束')
Process的run()属性:如果没有给target参数,而对这个对象使用了start()方法的话,就会执行run(),下面写一个继承Process的类,重写他的run(),查看run()的用法
from multiprocessing import Process import os import time #定义一个类,继承Process类,继承并重写这个类 class Sub_Process(Process): def __init__(self,interval): #因为Process本身也有__init__方法,现在等于重写了这个方法 #这样会带来一个问题,初始化的时候只初始化了自己的__init__没有初始化Process的__init__ #不能使用从这个类继承的方法和属性,所以要把子类的__init__传给Process.__init__的方法,完成这些初始化 Process.__init__(self) self.interval = interval #重写Process的run方法 def run(self): print('子进程%s开始执行,父进程为%s'%(os.getpid(),os.getppid())) time_start = time.time() time.sleep(self.interval) time_stop = time.time() print('子进程执行结束,耗时%.2f秒'%(time_stop-time_start)) if __name__ == '__main__': time_start = time.time() p1 = Sub_Process(2) #对一个没有写target属性的Process执行start方法,就会执行run方法 p1.start() p1.join() time_stop = time.time() print('父进程执行结束,耗时%.2f秒' % (time_stop - time_start))
Pool进程池:
from multiprocessing import Pool import os import time import random def worker(msg): print(msg,'子进程%s开始执行,父进程为%s' % (os.getpid(), os.getppid())) time_start = time.time() #取当前的时间戳 time.sleep(random.random()*2) time_stop = time.time() print('子进程执行结束,耗时%.2f秒' % (time_stop - time_start)) if __name__ == '__main__': po = Pool(3) #定义一个进程池,最大进程为3,立刻创建3个进程 print('start') for msg in range(5): #等进程池的一个进程执行完毕后,加入一个进程,直到运行了5个进程 po.apply_async(worker,(msg,)) #使用非阻塞方式执行worker #po.apply(worker,(msg,)) #使用阻塞的方式执行worker po.close()#关闭进程池 po.join() print('end')
进程池适合在服务器环境下使用,有用户访问直接调用进程池创建进程
Queue消息队列:
from multiprocessing import Queue #消息队列,先进先出 q = Queue(3) q.put('1') q.put('2') q.put('3') print(q.full()) #查看队列是否满了 print(q.qsize()) #查看队列消息数量 q.get() q.get() q.get() -------------------------------------------- True '1' '2' '3'
from multiprocessing import Process,Queue import time,random def write(q): for value in ['a','b','c']: print('put %s to queue'%value) q.put(value) time.sleep(random.random()) def read(q): while True: if not q.empty(): value = q.get() print('get %s from queue'%value) time.sleep((random.random())) else: break if __name__ == '__main__': q = Queue() pw = Process(target=write,args=(q,)) pr = Process(target=read,args=(q,)) pw.start() pr.start() pw.join() pr.join()
进程池中使用Queue:
#进程池中的queue from multiprocessing import Pool,Managerimport time,random def write(q): for value in ['a','b','c']: print('put %s to queue'%value) q.put(value) time.sleep(random.random()) def read(q): print('read start') for each in range(q.qsize()): #qsize函数能查看queue中信息的数量 print('get %s from queue' % q.get()) if __name__ == '__main__': q = Manager().Queue() pool = Pool() #创建个无上限的进程池 pool.apply(write,(q,)) pool.apply(read,(q,)) pool.close() pool.join()
通过进程池和Queue复制文件夹中的文件:
from multiprocessing import Pool, Manager # Manager有管理Queue import os ######################### 子进程拷贝,主进程读取 ##################### def copyFile(filename, source_fold, destin_fold, queue): # print(filename) f_read = open(source_fold + '\\' + filename, 'rb') file_content = f_read.read() f_write = open(destin_fold + '\\' + filename, 'wb') f_write.write(file_content) f_read.close() f_write.close() queue.put(filename) # 将复制好的文件名加入到到queue里 def main(): os.chdir('D:\\python') source_fold = 'source_dir' # 复制的文件夹 destin_fold = 'destin_dir' # 粘贴的文件夹 if os.path.exists(destin_fold): # os.chdir(destin_fold) for name in os.listdir(destin_fold): os.remove(name) print('删除%s结束' % name) # if not os.path.exists(destin_fold): #查看文件夹中是否存在这个文件/文件夹 else: file_name = os.listdir(source_fold) # 获取source所有文件名,返回个列表 os.mkdir(destin_fold) count = len(file_name) print(file_name) print('*' * 50) pool = Pool(5) #创建一个数量为5的进程池 queue = Manager().Queue() #创建一个信息队列 for name in file_name: pool.apply_async(copyFile, args=(name, source_fold, destin_fold, queue)) num = 0 while num < count: print(queue.get())#取出复制好的文件名 num += 1 copyRate = num / count print('copy的进度是:%0.2f%%' % (copyRate * 100), end='') pool.close() pool.join() # print(os.listdir(destin_fold)) if __name__ == '__main__': main()
线程:
一个程序至少有一个进程,一个进程最少有一个线程
线程不能独立执行,必须存在于进程中
import time import threading def saysorry(i): print('sorry'+str(i)) time.sleep(1) for i in range(5): t = threading.Thread(target=saysorry,args=(i,)) #创建一个线程对象 t.start()
主线程会等待所有的子线程结束后才结束
import time import threading def sing(): for i in range(3): print('sing'+str(i)) time.sleep(1) def dance(): for i in range(3): print('dance'+str(i)) time.sleep(1) if __name__ == '__main__': print('start%s'%time.ctime()) t1 = threading.Thread(target=sing) t2 = threading.Thread(target=dance) t1.start() t2.start() #time.sleep(5) print('end%s'%time.ctime()) ---------------------------------------------------- startTue Jul 31 10:55:37 2018 sing0 dance0 endTue Jul 31 10:55:37 2018 dance1 sing1 dance2 sing2
线程之间数据共享:
import threading import time g_num = 100 def work1(): global g_num for i in range(3): g_num += 1 print('in work1,g_num is',g_num) def work2(): global g_num print('in work2,g_num is', g_num) print('创建线程前,g_num is',g_num) t1 = threading.Thread(target=work1) t1.start() time.sleep(1) t2 = threading.Thread(target=work2) t2.start() ---------------------------------------------- 创建线程前,g_num is 100 in work1,g_num is 103 in work2,g_num is 103
import threading import time g_num = [11,22,33] def work1(g_num): #global g_num #for i in range(3): # g_num += 1 g_num.append(44) print('in work1,g_num is',g_num) def work2(g_num): #global g_num print('in work2,g_num is', g_num) print('创建线程前,g_num is',g_num) t1 = threading.Thread(target=work1,args=(g_num,)) t1.start() time.sleep(1) t2 = threading.Thread(target=work2,args=(g_num,)) t2.start() ---------------------------------------------------------- 创建线程前,g_num is [11, 22, 33] in work1,g_num is [11, 22, 33, 44] in work2,g_num is [11, 22, 33, 44]
线程的缺点:
执行次数太多的话,线程1可能还没执行完,就被线程2获得了CPU的使用权,然后线程2还没执行完,又被线程1抢走了使用权,导致运行的结果达不到预期结果
import time import threading g_num = 0 def work1(): global g_num for i in range(1000000): g_num+=1 print('in work1 g_num is',g_num) def work2(): global g_num for i in range(1000000): g_num += 1 print('in work2 g_num is', g_num) t1 = threading.Thread(target=work1) t1.start() #t1.join() t2 = threading.Thread(target=work2) t2.start() #t1.join() #加了join又没了线程同时运行的效果 print('最终结果 is',g_num) ----------------------------------- 最终结果 is 137646 in work1 g_num is 1074389 in work2 g_num is 1206789 #没得到理想中的结果2000000
需要解决这种问题,需要用到Lock互斥锁:
from threading import Thread,Lock from time import sleep class Task1(Thread): def run(self): while True: if lock1.acquire(): #判断线程有没有上锁,如果没有上锁,则返回True并上锁, print('task1') #如果已上锁,则返回false跳过 sleep(0.5) lock2.release() #释放lock2的锁,解锁后lock2才能运行 class Task2(Thread): def run(self): while True: if lock2.acquire(): print('Task2') sleep(0.5) lock3.release() class Task3(Thread): def run(self): while True: if lock3.acquire(): print('Task3') sleep(0.5) lock1.release() lock1 = Lock() #Lock创建的锁默认没有'锁上' lock2 = Lock() lock2.acquire() #给lock上锁 lock3 = Lock() lock3.acquire() t1 = Task1() t2 = Task2() t3 = Task3() t1.start() t2.start() t3.start()
import threading import time g_num = 0 def work1(): global g_num for i in range(1000000): if lock1.acquire(): g_num += 1 lock2.release() print('in work1 g_num',g_num) def work2(): global g_num for i in range(1000000): if lock2.acquire(True): #默认是True,表示阻塞,如果这个锁在上锁之前已经被锁,就会在这等待到锁结束才继续执行 g_num += 1 # lock1.release() print('in work2 g_num',g_num) lock1 = threading.Lock() lock2 = threading.Lock() lock2.acquire() #上锁 t1 = threading.Thread(target=work1) t2 = threading.Thread(target=work2) t1.start() t2.start() ------------------------------------------------------------ in work1 g_num 1999999 in work2 g_num 2000000
锁的好处:
确保某段代码只能由一个线程重头到尾完美执行
锁的坏处:
阻止了多线程代码的并发执行,包含锁的某段代码实际上只能以单进程执行,效率下降
由于可以存在多个锁,不同线程有不同的锁,并试图获取对方的锁时,容易造成死锁
生产者和消费者模式:
生产者和消费者模式是透过一个容器来解决生产者和消费者的强耦合问题,两个线程不直接通讯,而是通过阻塞队列来进行通讯,所以生产者生产完数据后不用等待消费者处理,直接丢给消息队列,消费者直接从消息队列里获取数据,消息队列相当于一个缓冲区,平衡了两个线程的处理能力。
import threading import time from queue import Queue class shengchanzhe(threading.Thread): def run(self): global queue count = 0 while True: if queue.qsize() < 1000: for i in range(100): #添加100个值到queue队列 count += 1 msg = '生产产品'+str(count) queue.put(msg) print(msg) time.sleep(0.5) class xiaofeizhe(threading.Thread): def run(self): global queue while True: if queue.qsize()>100: #如果队列数量大于100,就取出里面的消息 for i in range(3): msg = self.name+'消费了'+queue.get() print(msg) time.sleep(0.5) if __name__ == '__main__': queue = Queue() for i in range(500): queue.put('初始产品'+str(i)) for i in range(2): #创建2个线程 p = shengchanzhe() p.start() for i in range(5): #创建5个线程 c = xiaofeizhe() c.start()
异步:
from multiprocessing import Pool import time import os def test1(): print('进程池中的进程 pid=%d,父进程id=%d'%(os.getpid(),os.getppid())) for i in range(3): print(i) time.sleep(1) return 'good' def test2(args): print('callback func pid=%d'%os.getpid()) print('callback func args=%s'%args) if __name__ == '__main__': pool = Pool(3) pool.apply_async(func=test1,callback=test2) #运行完test1后将test1()当做test2的函数运行 time.sleep(5) #如果test1没返回值,test2的args值是None print('主进程-pid=%d'%os.getpid())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号