
if __name__ == '__main__':
当.py文件被直接运行时,if __name__ == '__main__'之下的代码块将被运行;当.py文件以模块形式被导入时,if __name__ == '__main__'之下的代码块不被运行。
匿名函数(lambda函数):
a = lambda x:10+x a(5) >>>15 #############等同于############### def a(x): return 10+x
推倒式:
a = [10+i for i in range(10)] print(a) >>> [10, 11, 12, 13, 14, 15, 16, 17, 18, 19] ##################等同于################ a = [] for i in range(10): a.append(10+i) print(a) >>> [10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
推到式也能用集合和字典来做,但是不能用圆括号()来做,因为出来的是生成器而不是推到式,但是如果硬要搞'元组推到式',只能使用以下方法:
a = tuple(10+i for i in range(10))
不过毫无意义
迭代器:
lis=[1,2,3,4] it = iter(lis) # 使用Python内置的iter()方法创建迭代器对象 next(it) # 使用next()方法获取迭代器的下一个元素 1 >>> next(it) 2 >>> next(it) 3 >>> next(it) 4 >>> next(it) #当后面没有元素可以next的时候,弹出错误
迭代器(Iterator)和可迭代(Iterable)的区别:
1.凡是可作用于for循环的对象都是可迭代类型;
2.凡是可作用于next()函数的对象都是迭代器类型;
3.list、dict、str等是可迭代的但不是迭代器,因为next()函数无法调用它们。可以通过iter()函数将它们转换成迭代
器。
4.Python的for循环本质上就是通过不断调用next()函数实现的。
生成器:
有时候,序列或集合内的元素的个数非常巨大,如果全制造出来并放入内存,对计算机的压力是非常大的。比如,假
设需要获取一个10**20次方如此巨大的数据序列,把每一个数都生成出来,并放在一个内存的列表内,这是粗暴的方
式,有如此大的内存么?如果元素可以按照某种算法推算出来,需要就计算到哪个,就可以在循环的过程中不断推算
出后续的元素,而不必创建完整的元素集合,从而节省大量的空间
>>> g = (x * x for x in range(1, 4)) 可以通过next()函数获得generator的下一个返回值,这点和迭代器非常相似: >>> next(g) 1 >>> next(g) 4 >>> next(g) 9 #更多情况下使用的是以下代码而不是next() for i in g: print(i)
但是除了使用生成器推倒式还可以用yield将函数变成生成器:
#斐波那契函数 def fibonacci(n): a, b, counter = 0, 1, 0 while True: # | if counter > n: # | return # ↓ yield a #yield让该函数变成一个生成器 -----------停止 a,b = b,a+ b # | 运行 counter += 1 # | fib = fibonacci(10) # fib是一个生成器 print(type(fib)) for i in fib: print(i, end=" ")
函数在for中每次都执行到yield停止,返回yield后面的值,等到下一个循环运行的时候才从yield下的代码开始运行
类和函数:
使用函数可以重用代码,省去重复性代码的编写,提高代码的重复利用率。
函数的基本架构如下:
def func(): return 123 a = func() #此时,a的值是func函数返回的123
函数会优先调用函数里的变量,如果函数里没有变量会继续向上一级寻找变量,但是,函数里的变量无法当做全局变量使用,如果函数想调用修改全局变量,需要添加global
1 a = 10 #a是一个全局变量 2 3 def func(): 4 global a #申明使用的a是全局变量的a 5 a = 20 #给a赋值 6 7 print(a) #这时输出的a是20 8 9 def func2(): 10 a = 100 11 12 print(a) #这时输出的a还是20,因为func2赋值的a只是函数里的a,不是全局变量的a
类是用来描述具有相同属性和方法的对象的集合:
基本架构如下:
class MyClass(object): #object可写可不写,不写默认继承object def a(self): print('aaa') def b(self): print('bbb') c = MyClass() #创建一个实例对象 c.a() c.b() #此时会输出aaa和bbb
创建实例的时候会有三个动作:
1.创建类对象
2.初始化类对象
3.将类对象赋给变量变成一个实例
class cls(): def a() return 'a' obj = cls()
装饰器:
装饰器可以在不修改原有代码的情况下,为被装饰的对象增加新的功能或者附加限制条件或者帮助输出。
def outer(func): def inner(): print('aaa') func() #执行的是原来的f1函数 print('bbb') return inner @outer def f1(): #将f1函数当做outer函数的参数func,并将outer函数返回的inner函数赋给f1 print('this is f1') f1() #这里的f1执行的其实是outer返回的inner >>> aaa >>> this is f1 >>> bbb
文件读写:
python有内置的方法open()用来读写文件,一共分三步,第一步:打开文件,第二步:操作文件,第三步:关闭文件
f = open('test.txt','w') #后面的w参数是写入的意思,一共有w,a,r,b,w+,r+ 6种方法 f.write('hahahahaha') f.close() #关闭文件

如果觉得要打close麻烦,可以使用with方法:
with关键字用于Python的上下文管理器机制。为了防止诸如open这一类文件打开方法在操作过程出现异常或错误,或者
最后忘了执行close方法,文件非正常关闭等可能导致文件泄露、破坏的问题。Python提供了with这个上下文管理器机
制,保证文件会被正常关闭。在它的管理下,不需要再写close语句。
with open('test.txt','w') as f: f.write('hahahahaha')
两种代码都可以读写文件,只不过with方法运行完后会自动关闭文件
with还支持打开多个文件:
with open('test1.txt','r') as a,open('test2.txt','w') as b: str1 = a.read() a.readline() #从文件读取一行内容,并将光标移动到这行结尾,并且不能往回读,如果返回空字符串,说明到了文档结尾 li = a.readlines() #将文件所有的行一行一行加入列表中 for line in a: #和readline一样的方法 print(line,end='') b.write('this is test2') b.tell() #查看光标所在的位置 b.seek(x,y) #改变光标位置x表示偏移量,负表示往左移,正数表示往右移动,y表示开始的位置,0表示从头开始算,1表示当前位置,2表示文件结尾
面向对象编程:
面向对象编程有三大特征:封装,继承,多态
封装
封装是指将数据与具体操作的实现代码放在某个对象内部,使这些代码的实现细节不被外界发现,外界只能通过接口使用该对象,而不能通过任何形式修改对象内部实现,正是由于封装机
制,程序在使用某一对象时不需要关心该对象的数据结构细节及实现操作的方法。使用封装能隐藏对象实现细节,使代码更易维护,同时因为不能直接调用、修改对象内部的私有信息,在
一定程度上保证了系统安全性。类通过将函数和变量封装在内部,实现了比函数更高一级的封装。
class Student: classroom = '101' address = 'beijing' def __init__(self, name, age): self.name = name self.age = age def print_age(self): print('%s: %s' % (self.name, self.age))
########################
#无法直接调用类里面的变量.#
#print(classroom) #
#print(address) #
########################
继承
继承来源于现实世界,一个最简单的例子就是孩子会具有父母的一些特征,即每个孩子都会继承父亲或者母亲的某些特征,当然这只是最基本的继承关系,现实世界中还存在着更复杂的继
承。继承机制实现了代码的复用,多个类公用的代码部分可以只在一个类中提供,而其他类只需要继承这个类即可。
# 父类定义 class people: def __init__(self, name, age, weight): self.name = name self.age = age self.__weight = weight def speak(self): print("%s 说: 我 %d 岁。" % (self.name, self.age)) ############################################### # 继承示例 class student(people): def __init__(self, name, age, weight, grade): # 调用父类的实例化方法 people.__init__(self, name, age, weight) self.grade = grade # 重写父类的speak方法 def speak(self): print("%s 说: 我 %d 岁了,我在读 %d 年级" % (self.name, self.age, self.grade)) s = student('ken', 10, 30, 3) s.speak()
python3的继承机制是从左到右,深度优先,意思是如果继承多个父类,先从左边的父类开始查找,一条插到底再在下一条开始查找
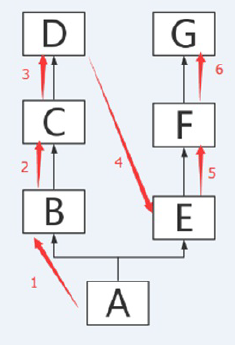
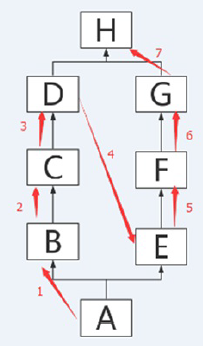
多态
class Father(): def kind(self): print('I am Father') class son1(): def kind(self): print('I am son1') class son2(): def kind(self): print('I am son2') def show_kind(c): c.kind() a = Father() #创建实例 b = son1() c = son2() show_kind(a) #在封装好的函数中调用实例内的函数kind(),实际上就是执行了Father.kind() show_kind(b) show_kind(c) ################################## 打印结果 I am Father I am son1 I am son2
私有成员:
如果不想类中的变量和方法直接被调用的话,例如:
class People: title = "人类" def __init__(self, name, age): self.name = name self.age = age def print_age(self): print('%s: %s' % (self.name, self.age)) obj = People("jack", 12) obj.age = 18 #这里可以直接通过赋值改变obj实例的age,下面需要通过方法防止这个现象发生 obj.print_age()
如果不想类的变量被直接调用修改,需要将变量变成私有成员:
class People: title = "人类" def __init__(self, name, age): self.__name = name self.__age = age def get_name(self): return self.__name def get_age(self): return self.__age def set_name(self, name): self.__name = name def set_age(self, age): self.__age = age def print_age(self): print('%s: %s' % (self.__name, self.__age))
obj = People("jack", 18) obj.__name #想直接调用__name看值,发现无法访问 ------------------------------ Traceback (most recent call last): File "F:/Python/pycharm/201705/1.py", line 68, in <module> obj.__name AttributeError: 'People' object has no attribute '__name' ------------------------------ obj.__name = 'tom' #想通过用__name直接赋值 obj.get_name() ------------------------------ jack #发现输出的还是jack,因为强行用__name只是给obj添加了个对象变量而已,并影响不了私有变量__name------------------------------ #如果想修改变量,只能通过之前写好的set_name方法才能修改 obj.set_name('tom') obj.get_name() ------------------------------ tom
为什么直接调用__name修改不了,因为类通过方法将__name转变成私有变量_People__name所以通过__name肯定修改不了,如果想强行修改,只能通过_People__name
obj = People('jack',18) obj._People__name = 'tom' obj._People__age = '20' obj.get_name() obj.get_age() ---------------------------------- tom 20
限制实例变量:
class Foo(): __slots__ = ('name','age') #限制创建实例后只能用这两个变量 pass obj = Foo() #obj只能调用name和age obj.name = 'tom' obj.age = 18 obj.sex = ‘man’ #会报错
property装饰器:
class man(): def __init__(self,name): self.__name = name @property def name(self): return self.__name() @age.setter def name(self,newname): self.__name = newname @name.deleter def name(self): print('已删除') obj = man('Tom') n = obj.name #获取值,调用的是第一个name函数 obj.name = 'Sam' #给name重新赋值,调用的是第二个被装饰的name函数 del obj.name #不会真的删除,但是会输出已删除三个字,因为本来的删除函数被重新定义了,调用的删除函数变成了第三个被装饰的name函数
还有一种方法是:
class man(): def __init__(self,name): self.__name = name def get_name(self): return self.__name() def set_name(self,newname): self.__name = newname def del_name(self): print('已删除') #直接调用内置的property函数 name = property(get_name,set_name,del_name) ############################################################## # property()函数的参数: # # 第一个参数是方法名,调用 实例.属性 时自动执行的方法 # # 第二个参数是方法名,调用 实例.属性 = XXX时自动执行的方法 # # 第三个参数是方法名,调用 del 实例.属性 时自动执行的方法 # # 第四个参数是字符串,调用 实例.属性.__doc__时的描述信息。 # ##############################################################
reflect反射 和 动态导入另一个py文件的函数:
########## 这是py1.py 文件 在/etc/x文件夹 ######### def dog(): print('this is dog') def cat(): print("this is cat") ########## 这是py2.py文件,在/etc文件夹############ # import py1 #这样import是绝对不行的,因为不在同一个文件夹中 # import x.py1 #这样又觉得太麻烦了,而且不知道x文件夹是否真的有py1 def run(): inp = input('请输入要调用的模块文件').strip() modules,func = inp.split('/') obj = __import__('x.'+modules,fromlist=True) #fromlist不写的话只会识别到x.的.之前的内容 #(x.py1) #(dog or cat) if hasattr(obj,func): #查看obj里是否有func模块 func = getattr(obj,func) #getattr函数是查找obj里是否有和 func字符串相同的函数名,有的话将他返回,并赋值给新的func func() else: print('404') run() ---------------------------------------------------------------------- 输入py1/cat 这时候会用import魔法函数自动导入x.py1然后调用cat #如果这里的import函数没有写fromlist的话,就只会在x文件夹里查找有没有cat,那肯定会返回404 再在x.py1里查看是否有cat模块,没有就会弹出404 有的话,调用x.py1跟cat字符串 ”长相“ 一样的 cat函数 ---------------------------------------------------------------------- this is cat
try语句:
try: print(1/2) except: #如果会报错则输出except print('except') else: #如果没有报错则在输出完1/2后输出else print("else") finally: #不管有没有报错都会执行完上面的语句后输出finally print("finally") ------------------------------------------- 0.5 else
finally ######################################### try: print(1/0) #除不了0,会执行except except: print('exc') else: print('else') finally: print('finally') ------------------------------ exc finally
小例子:在函数中用了try如果有finally的话,一定会返回finally的值:
def test(): try: return 123 except: return 456 else: return 789 finally: return 111 a = test() print(a) ---------------------------------------------- 111

 浙公网安备 33010602011771号
浙公网安备 33010602011771号