OO前三次作业总结
主要分析了前两次作业,第三次作业做到一半不知道后面应该如何处理表达式,因为对“递归下降”和“树”的概念不太理解
一.程序结构分析
第一次作业复杂度分析:

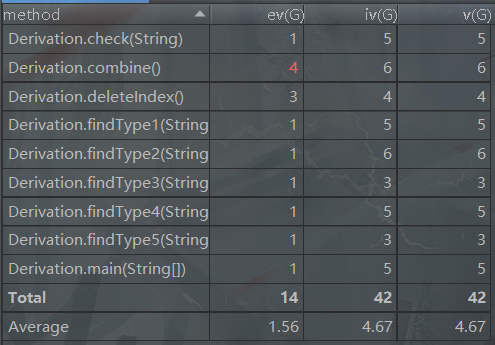
能够看出,方法结构化程度不好,类的平均循环复杂度及总复杂度有些高(因为设计不够好,只有一个类),方法规模一般且数量较少(第一次比较简单),省略了类图
最大的缺点:一个类,难以维护,扩展性不强
优点:面向过程,好写
第二次作业复杂度分析:
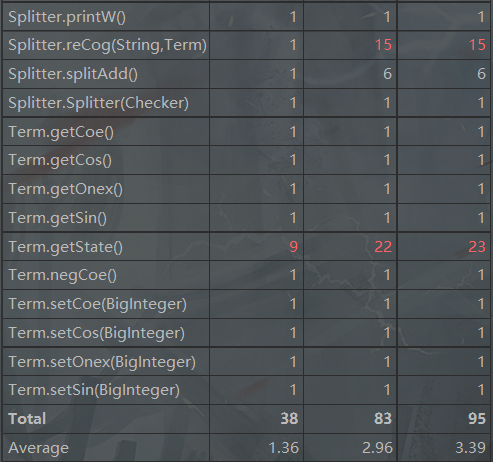
![]()
只截取了标红的部分,能看出Term.getState()和Splitter.reCog()方法结构化程度差,耦合度高,原因是自己的设计中计算和判断格式的方法比较笨,同一方法要使用多次,没有想到用Hashmap,可以直接以各个因子的index作为索引,从而提高效率。也因此导致Output和Splitter模块循环复杂度较高。
类图如下:
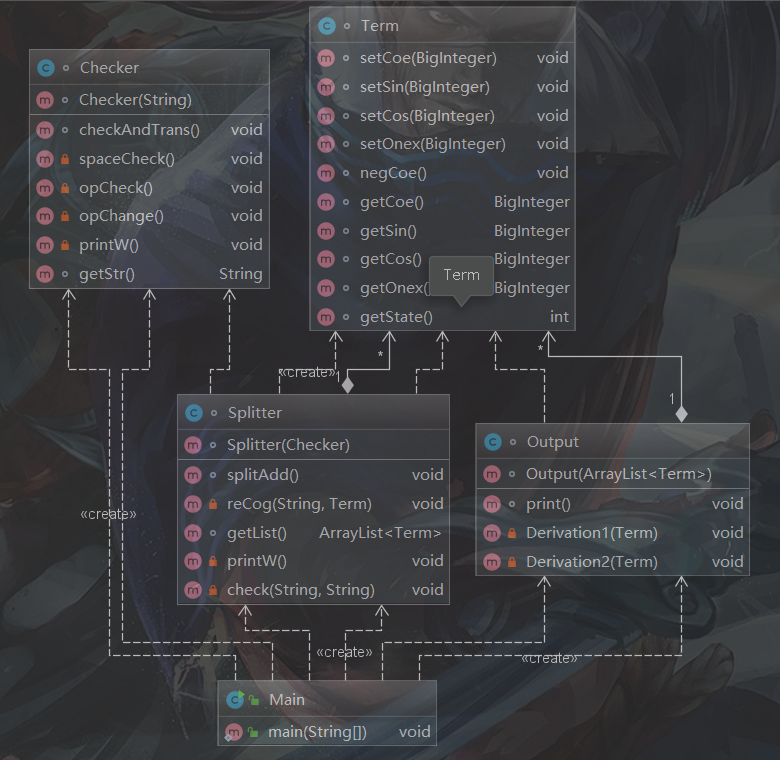
似乎有了一点点点点点点OO的思想,但是各个类的关系好像还不太明确,仍需改进,但比第一次有了一点进步,可扩展性提高了一点点点点点点点。方法个数有了提升,部分方法规模有点大,但总体还行,且较好地分布在各个类中
二.关于程序bug的分析
第一次作业:简单的x、x^num、num相加减,并且求导
测试结果:中强测全部通过,互测中被hack11次,最终合并为了3个同质bug
不足:第一次正式作业,不像寒假的A+B问题,难度和要求都有所提升(不可以一main到底)。但当时对Java的类,方法等概念不是太清楚,因此整个程序只有一个类,而且所有的方法都是private static,等于用C面向过程地写了一遍,不是特别面向对象。同时,一个正则表达式平均有两三行,也没掌握正则表达式正确的用法
bug分析:首先,第一个bug是因为不细心,本来应该删去的一行代码“m = r.matcher(str)”(类似这样)忘记删去,导致对于含有多个重复项的表达式,如-x-x-x-x-x-x,所有-x只会被计算一次,得到-1。同时也发现了对于matcher中的find()方法,如果不对matcher进行更新,无论对字符串做什么样的改变,find方法始终作用于之前的字符串
剩余的bug是因正则表达式匹配出错的。如我的正则表达式会匹配到+ + 1这种项,并认为这是正确的项,实际上根据指导书这是错误的,因此修复bug时主要针对正则表达式进行了更改。
另外,我起初的想法是:提取出所有正确的项(正确的项用空串替换),剩余串为空,则表达式正确,否则就是错误的。随之产生了一个问题,类似+++1+1这种项,会先匹配到++1,认为他是正确的,替换后又产生了一个++1,,又认为他是正确的。因此,认为表达式正确。
综上,产生的bug大部分在输入格式处理上,实际计算的bug并不算太多(这次计算比较简单),以及自己的粗心。
用正则表达式直接匹配每一项确实不是一个明智的方法,这样写出来的正则不仅长而且复杂,容易出错,也可能爆栈。对于爆栈的原因,也上网查了一些资料,同时也有同学在讨论课上指出,这是由于正则表达式匹配时的回溯。这次没有爆栈是因为项都比较简单,不是太复杂。
第二次作业:在第一次作业基础上加入sin(x)和cos(x),可以带幂,并且求导
测试结果:中测通过,强测和互测共10个bug,合并修复为两个同质bug,两个bug都在Splitter类中
bug分析:第一个bug,又是因为没细心,忘记除了负项,导致表达式中只要含有负项就会输出WRONG FORMAT!
另一个bug源于方法问题,是关于split()函数的使用。这一次的思想是通过预处理,用" + "先切割表达式,得到每个乘积表达项,他们都可以表示为kxasin(x)bcos(x)c,然后再用" * "切割,得到每个因子,这一段一开始是这么写的:
for (String ret1 : strSpl.split("\\+")) { if (!ret1.equals("")) { Term term = new Term(); for (String ret2 : ret1.split("\\*")) { reCog(ret2, term); }
所以,像2+,sin(x)*这样的表达式,我都会认为是正确的。在网上搜索了一下,发现split()方法在传递参数时,还有一个limit参数,就是最多可以得到的字符串数组个数,一个特殊的情况是limit = -1,此时split()方法会对字符串彻底进行切割,若最后n位均为切割符,仍会继续切割,举个例子(源于CSDN):
String line = "a b c ";
String [] tmp = line.split(" ");
System.out.println(tmp.length+"------");
for(int i=0;i<tmp.length;i++){
System.out.println(i+"="+tmp[i]);
}
String [] items = line.split(" ",-1);
System.out.println(items.length+"========");
for(int i=0;i<items.length;i++){
System.out.println(i+"="+items[i]);
}
结果:
4------
0=a
1=b
2=
3=c
==========
0=a
1=b
2=
3=c
4=
5=
6=
7=
8=
9=
10=
11=
12=
随后对split()方法的使用进行了更改,修复了这一bug
三.如何发现别人的bug?
1.对拍是一种不错的办法,很省力,把脏活都交给电脑去做。但是如同学们在研讨课指出,对拍可能产生许多同质bug,但也会针对一些临界值给出测试,有利有弊。
2.通过看代码,理解设计者的思路,发现细节错误,如几次作业的“正则表达式”,一旦发现问题,很容易找出bug
3.手动输入一些特殊的数据,如一些极特殊的情况,或是自己都没想到的情况
我采用的是第二三种方式,因为比较懒,不想写对拍不想看代码我认为第一种找bug的方式有些太暴力,对拍什么的硬找bug还是自己完成比较好(总有人会对拍,不如自己先拍)······对于第二种方式,有时别人的代码比较复杂或者看不太懂的时候,我就直接用第三种方式,一般都能找出一两个bug。不过我的测试样例一般都是自己突然想到的,没有较好地结合被测程序的代码设计结构
四.三次作业对比分析
做前几次作业时,在努力给自己灌输OO的思想,尽量地把代码写的面向对象。因为并没有实际参与过一些大型工程,所以对一些必要的复杂的结构性设计还不太理解。
第一次作业没有任何结构,等于用C写了一遍,没什么扩展性,于是第二次作业需要重构。
第二次作业中,把整个具体过程分为了输入检查处理,分割,得到项,求导输出,因此有了四个类(除了main,但对于这四个类的划分还有些问题)。
第三次作业,保留了第二次作业输入检查处理及项的类,因为求导部分不适应这次作业,分割的方法也不适用。可以看出,因为对类有了一些划分,各类的功能比较明确,代码可扩展性稍微高了一点,不用完全重构。但仍没有用到接口,继承等有Java特色的东西,还需要慢慢体会并了解他们的作用。另外,这次对函数,各种因子建立了类,对括号的处理也单独成类。但遗憾的是,括号处理完后,不太会对多层嵌套的递归下降处理,也不知道有什么别的方法,后一半不知道怎么写······
以后会继续努力,继续体会OO的思想,减少面向过程编程的想法,尽力做好每次作业

 浙公网安备 33010602011771号
浙公网安备 33010602011771号