R学习(1)-基本操作
R官方网址
下载教程就不说了,很简单
用这个来设置代码路径
setwd("C:/08_CS/Project/R/Sep") #改成你的
getwd()
现在打开 R 控制台,并将工作目录设置为保存你下载的位置(或你的工作路径)。
加载 CSV 文件
本教程的数据在data文件夹里了。这是美国人口普查局美国社区调查的州级数据。它显示了不同人口统计数据的平均收入。该文件夹中有多个文件,我们需要的文件位于“data/ACS_13_5YR_S1903/ACS_13_5YR_S1903.csv”(获取方式看最下面👇)。这就是实际的数据文件,其他的是元数据。
将位置传递给 R 中的函数。
income <- read.csv("data/ACS_13_5YR_S1903/ACS_13_5YR_S1903.csv")
输入dim(income)获取新存储的数据框的维度。
该文件有 52 行和 123 列,现在存储在变量中。这会使用默认设置加载数据,R 会尝试猜测拥有的数据类型,但有时效果不佳。
例如,如果查看实际 CSV 文件 GEO.id2 的第二列,则代码的长度均为 2。但是,查看数据帧(income[,c(1,2)])的前两列时,可以看到read.csv()删除了前导零。这是因为 R 将数据列视为数字而不是字符。你可以使用参数指定它。
# Be more specific.
income <- read.csv("data/ACS_13_5YR_S1903/ACS_13_5YR_S1903.csv",
stringsAsFactors=FALSE, sep=",", colClasses=c("GEO.id2"="character"))
默认设置为FALSE
此外,分隔符(sep)显式设置为逗号以指示字段以逗号分隔。如果数据是制表符分隔的,请相应地设置值。
# Tab-delimited
income <- read.csv("data/ACS_13_5YR_S1903/ACS_13_5YR_S1903.tsv",
stringsAsFactors=FALSE, sep="\t", colClasses=c("GEO.id2"="character"))
如果有互联网连接,则可以通过 URL 加载数据。只需输入通常输入目录路径的 URL。其它都一样。
# Load from URL
income <- read.csv("http://datasets.flowingdata.com/tuts/2015/load-data/ACS_13_5YR_S1903.csv",
stringsAsFactors=FALSE, sep=",", colClasses=c("GEO.id2"="character"))
数据一览
加载数据后应该做的下一件事是确保它按预期加载。 R 提供了多种函数来查看数据的不同部分。
这个特定的数据集有 52 行和 123 列,因此调用 to 显示了相当多的信息。
输入以下内容以查看前几行。
head(income)
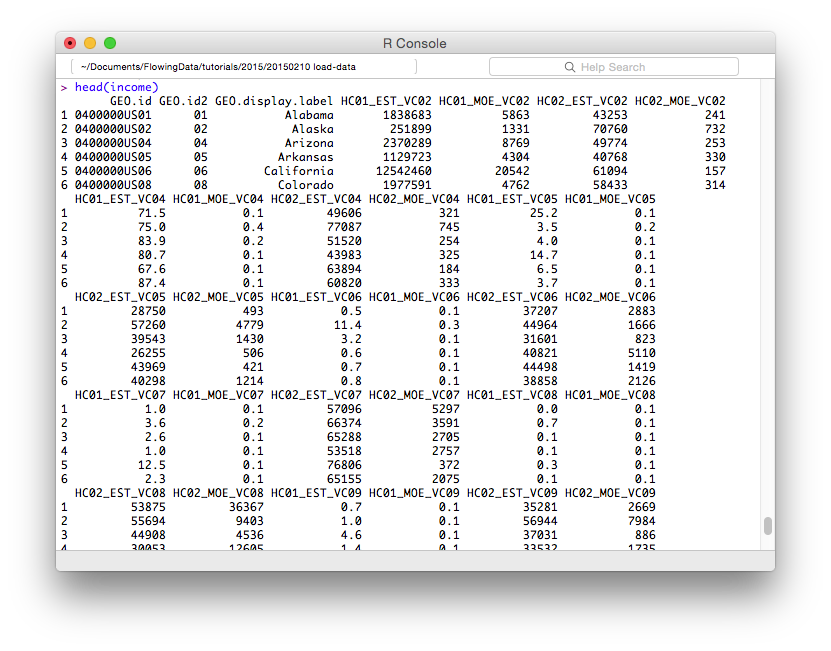
dim()函数指数据框的尺寸。
dim(income)
返回值如下,其中第一个值是行数,第二个值是列数:
[1] 52 123
查看列名称(全部 152 个)。
names(income)
并检查每一列的结构。在这种情况下,除了前两列之外的所有数字都是指示地理区域的 id。
str(income)
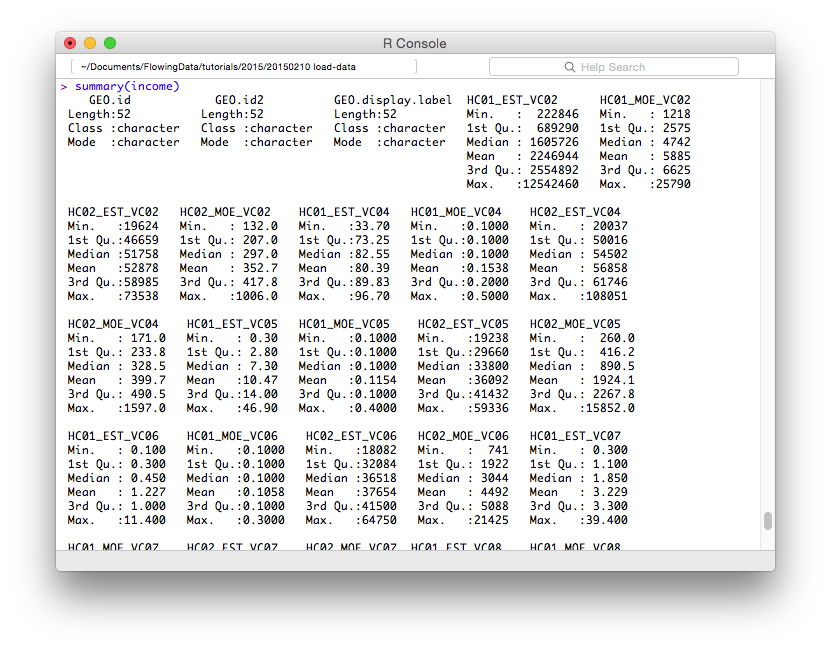
最后,要快速总结显示最小值、最大值、缺失值以及中间内容的每列,用summary() 。
# Quick summary
summary(income)
子集化
我们知道它是前七列,因为教程下载文件夹中有一个描述每一列的元数据文件。
也许我们现在只想查看总人口的收入估算。这是前七列(前两列指示区域)。以下是如何进行子集化以获得只有 7 列而不是原始 153 列的数据框。
# Just the first columns
income_total <- income[,1:7]
head(income_total)
dim(income_total)
正如预期的那样,新维度为 52 行和 7 列。
还可以使用基于值的子集。也许我们只想看上面四分位数的状态。
# Based on value
income_upper <- subset(income_total, HC02_EST_VC02 >= 58985)
使用 na.omit()删除任何字段中缺少值的行。
# Extract missing data (in thise case, returns empty)
income_without_na <- na.omit(income)
在这种情况下,可能会得到一个空数据框,因为每个州的 153 个字段中至少有一个缺失值。相反,如果你用 income_total运行该函数,只会获得相同的数据帧,因为前七列没有丢失任何值。
以下是如何使用names() 更改列名称。如果只调用names() ,该函数将返回现有的列名称,但如果为其分配一个名称向量(如下所示),将重命名。向量中名称的数量应与列的数量相同。
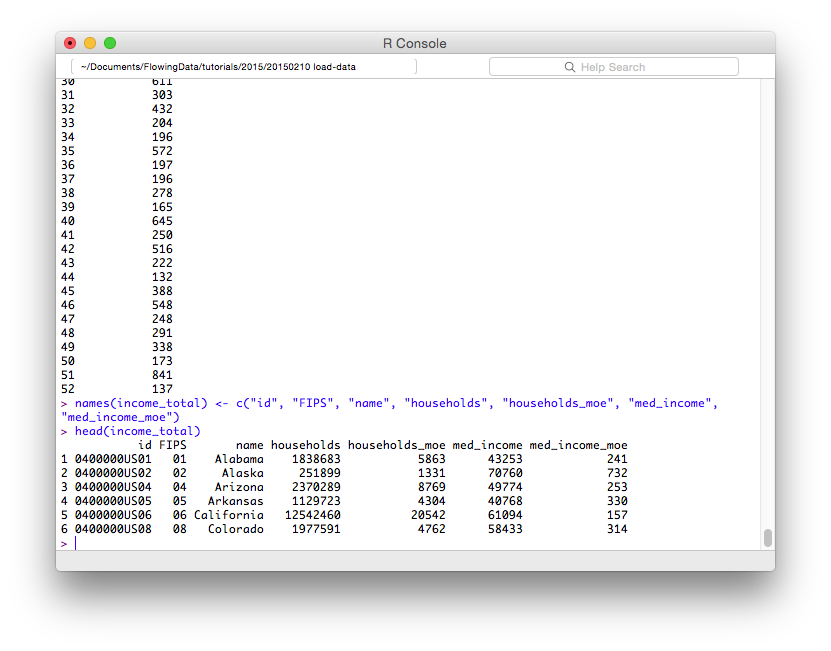
# Change column names
names(income_total) <- c("id", "FIPS", "name", "households", "households_moe", "med_income", "med_income_moe")
head(income_total)
这样更容易读
要访问特定列,可以在数据框变量后面使用sign (\(),后跟列名称。例如,如果只需要列`med_income`,输入`income_total\)med_income` 。同样,可以通过使用$指定列名称来添加列,然后提供值向量。如果列存在,则现有值将更改为新值;如果列名称不存在,则创建新列。
例如,在income_total中,有中位数和误差幅度。假如想添加一列作为最小值,另一列作为最大值。用收入中位数加上和减去误差幅度。
# New columns
income_total$med_min <- income_total$med_income - income_total$med_income_moe
income_total$med_max <- income_total$med_income + income_total$med_income_moe
New columns
想要将单位转换为千?将一列除以 1,000。
# Convert existing column
income_total$med_min <- income_total$med_min / 1000
income_total$med_max <- income_total$med_max / 1000
将向量除以单个数字时,会对该向量的每个元素执行该运算。其他基本操作相同。
与其他数据集合并
到目前为止,已经加载了一个数据集,对其进行了子集化,并将其添加到现有的数据框中。你还应该知道如何将多个数据集合并为一个。例如,假设你有 2008 年和 2013 年州一级的收入数据。
# Load two datasets
income2008 <- read.csv("data/ACS_08_3YR_S1903/ACS_08_3YR_S1903.csv",
stringsAsFactors=FALSE, sep=",", colClasses=c("GEO.id2"="character"))
income2013 <- read.csv("data/ACS_13_5YR_S1903/ACS_13_5YR_S1903.csv",
stringsAsFactors=FALSE, sep=",", colClasses=c("GEO.id2"="character"))
让我们分别获取 2008 年和 2013 年的三列:州 ID、总人口收入中位数以及误差幅度。
# Subset
income2008p <- income2008[,c("GEO.id2", "HC02_EST_VC02", "HC02_MOE_VC02")]
income2013p <- income2013[,c("GEO.id2", "HC02_EST_VC02", "HC02_MOE_VC02")]
最好对估计列使用不同的名称。对于 id,它实际上是 FIPS(联邦信息处理标准)代码,我们在两个数据集中使其相同。
# Rename headers
names(income2008p) <- c("FIPS", "med2008", "moe2008")
names(income2013p) <- c("FIPS", "med2013", "moe2013")
下面是合并前两个数据框的概览:
> head(income2008p)
FIPS med2008 moe2008
1 01 42131 275
2 02 66293 1129
3 04 51124 309
4 05 39127 349
5 06 61154 173
6 08 56574 345
> head(income2013p)
FIPS med2013 moe2013
1 01 43253 241
2 02 70760 732
3 04 49774 253
4 05 40768 330
5 06 61094 157
6 08 58433 314
现在使用merge() 将其组合在一起。
# Combine
income0813 <- merge(income2008p, income2013p, by="FIPS")
我们可以将上面的行 income2008p和 income2013p读取为合并并按 FIPS 列并将其存储在income0813 .这是获得的五列数据框:
> head(income0813)
FIPS med2008 moe2008 med2013 moe2013
1 01 42131 275 43253 241
2 02 66293 1129 70760 732
3 04 51124 309 49774 253
4 05 39127 349 40768 330
5 06 61154 173 61094 157
6 08 56574 345 58433 314
将数据保存为文件
最后,将数据框保存为 CSV 文件,以便在不同的程序中使用。使用函数write.table() .指定数据框、文件目标和分隔符。默认情况下使用行名称,但我通常将其设置为 false。
write.table(income_total, "data/income-totals.csv",
row.names=FALSE, sep=",")
回顾一下:
- 首先解压缩文件加载数据
- 子集数据框
- 编辑数据以使其更易于管理
- 合并多个数据集
这些是 R 中的基本操作。
代码及数据
链接:https://pan.quark.cn/s/9e965dd0c470


 浙公网安备 33010602011771号
浙公网安备 33010602011771号