一幅图说明白机器学习评估指标 accuracy 与 precision 的含义
在机器学习中,accuracy(准确率)和precision(精确率)是两个常用的评估指标,用于衡量分类模型的性能。它们的含义和计算方法如下:
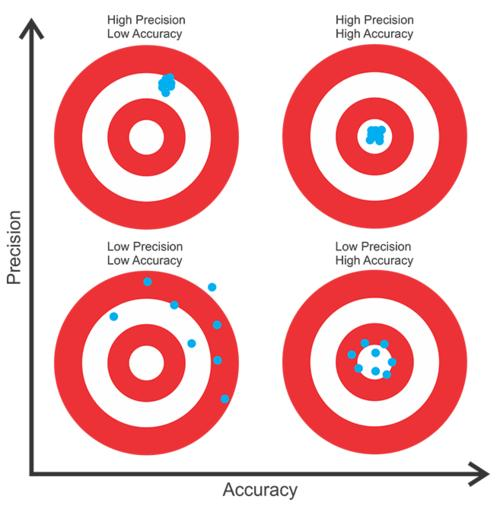
1.Accuracy(准确率)
定义:
准确率是指模型正确预测的样本数占总样本数的比例。它是衡量模型整体性能的一个直观指标。
计算公式:
其中:
• TP(True Positives):真正例,模型正确预测为正类的样本数。
• TN(True Negatives):真负例,模型正确预测为负类的样本数。
• FP(False Positives):假正例,模型错误预测为正类的样本数。
• FN(False Negatives):假负例,模型错误预测为负类的样本数。
2.Precision(精确率)
定义:
精确率是指模型预测为正类的样本中,实际为正类的比例。它关注的是模型预测为正类的样本的准确性。
计算公式:
其中:
• TP(True Positives):真正例,模型正确预测为正类的样本数。
• FP(False Positives):假正例,模型错误预测为正类的样本数。
示例
假设有一个二分类模型,对 100 个样本进行预测,结果如下:
• TP=40
• TN=30
• FP=10
• FN=20
计算准确率:
计算精确率:
详细解释
• 准确率(Accuracy):
• 优点:直观易懂,容易计算。
• 缺点:当数据类别不平衡时,准确率可能会产生误导。例如,如果一个数据集中 90%的样本都是负类,模型总是预测为负类,准确率仍然可以达到 90%,但这显然不是一个好的模型。
• 精确率(Precision):
• 优点:关注模型预测为正类的样本的准确性,适用于需要高精度的场景,如医疗诊断、金融风险评估等。
• 缺点:只关注预测为正类的样本,不考虑假负例(FN),因此在某些情况下可能会忽略模型对负类的预测性能。
选择指标
• 数据平衡:如果数据类别比较平衡,准确率是一个很好的指标。
• 数据不平衡:如果数据类别不平衡,精确率和召回率(Recall)通常更有意义。召回率(Recall)是指模型正确预测为正类的样本数占实际正类样本数的比例,计算公式为:
综合指标
• F1 分数:是精确率和召回率的调和平均数,适用于需要同时考虑精确率和召回率的场景。
本文作者:天才俱乐部
本文链接:https://www.cnblogs.com/Genius-Society/p/18673367
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。若有侵权请联系作者。



· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现