
深度学习基本概念简介
一、Linear Models' Bias
上篇学习机器学习一文中,所构造的 $y = b + wx_0$ 函数是一个linear model亦即线性模型,但是linear models有缺陷的——它过于简单了。实际应用中,我们所面临的不会只是一个简单的linear model,因此我们需要更复杂的models。

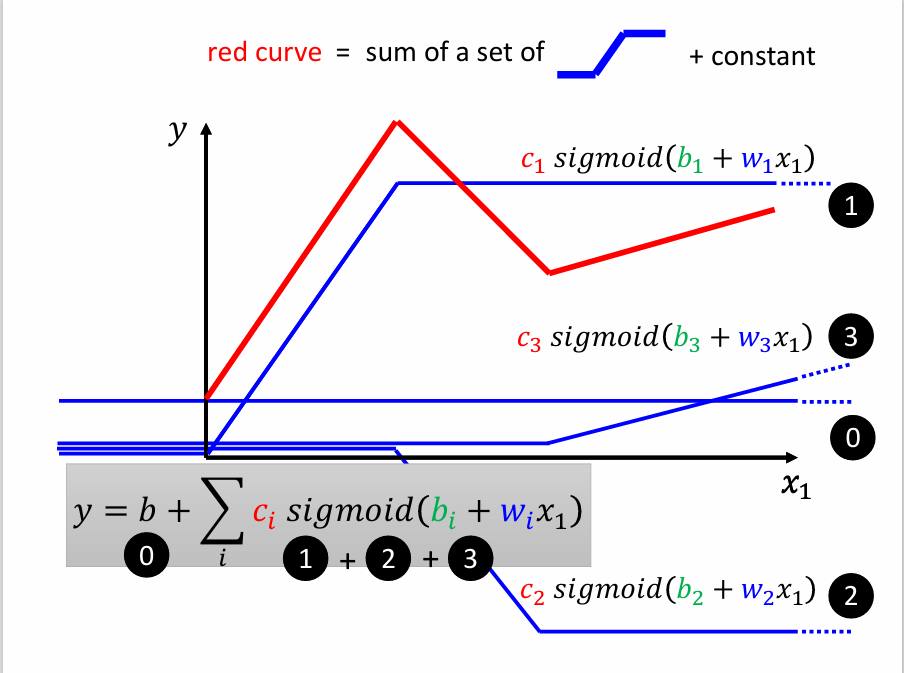
比如上图中的红色曲线,如何找到它的表达式呢?
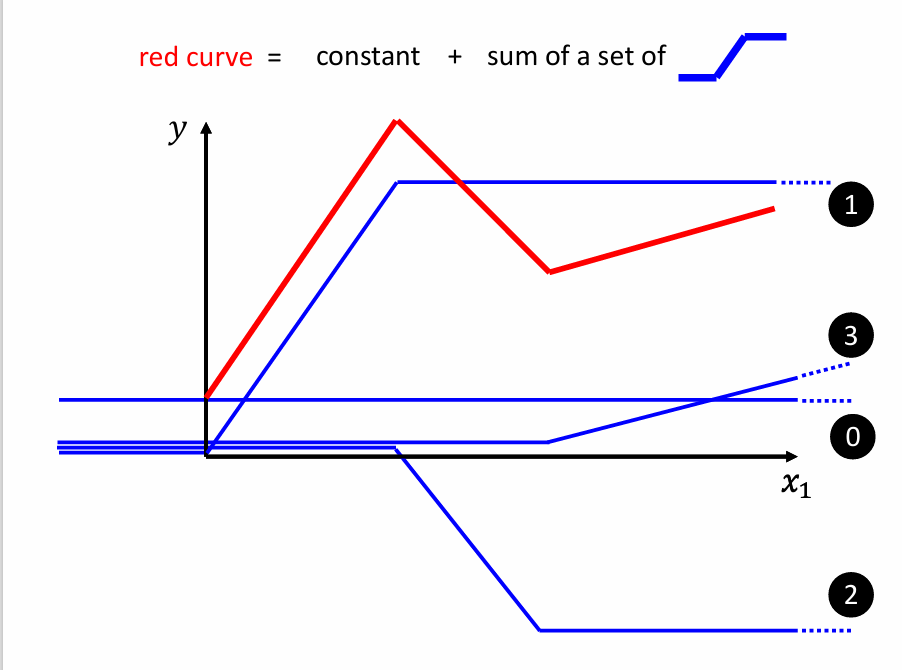
可以通过许多条蓝色的函数相加得到红色曲线的函数。所有的Piecewise Linear Curves都可以用一组类似的“蓝色函数 + 常数”来表达出来,即使是曲线也可以,如下图:
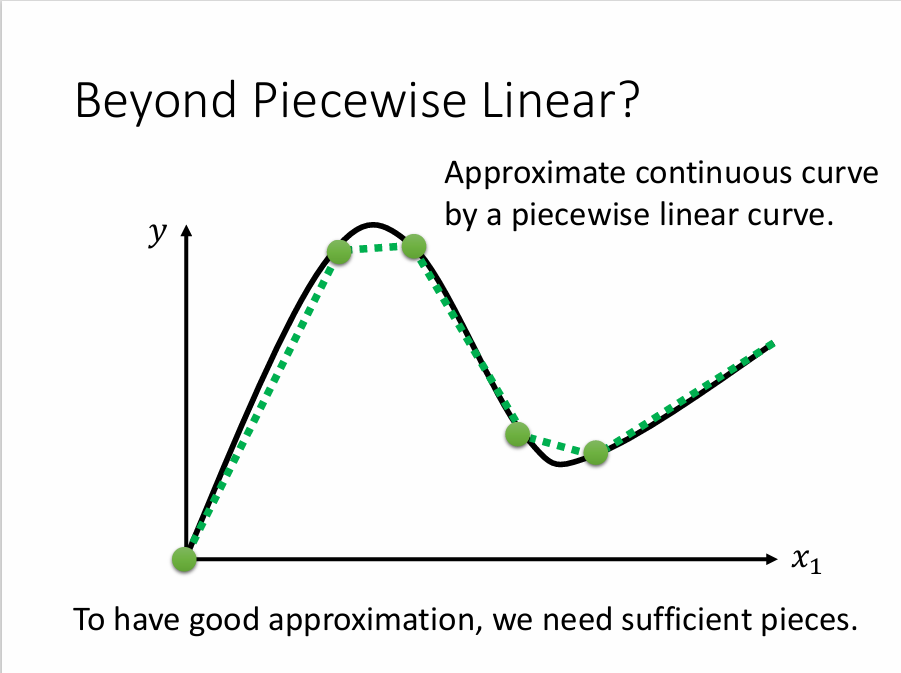
二、如何找“蓝色函数”?
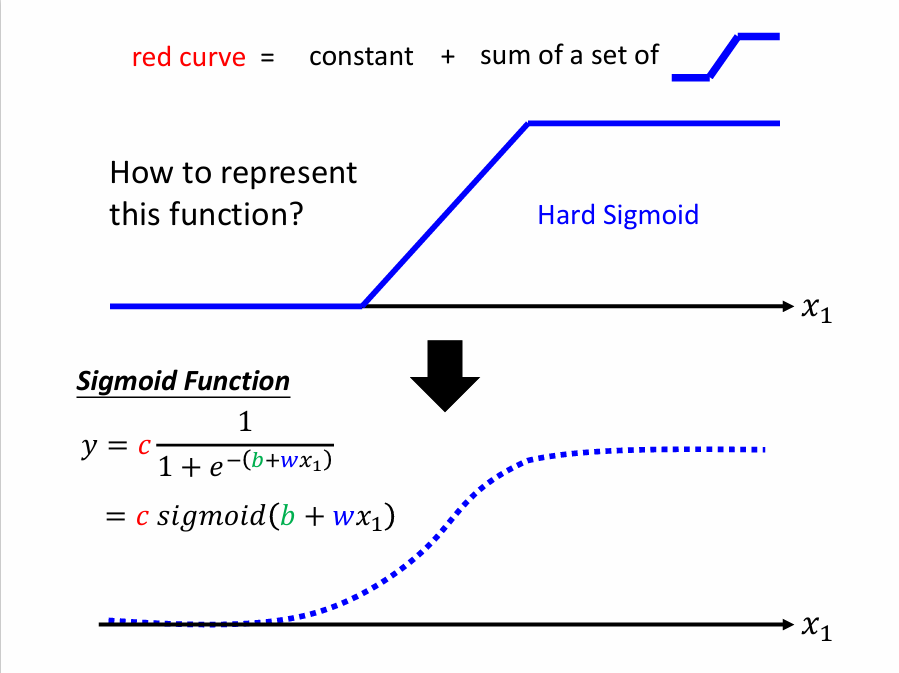
Sigmoid Function
$y = c\frac{1}{1 + e ^ {-(b + wx_1)}} = c*sigmoid(b + wx_1)$
其函数图像如下表示:
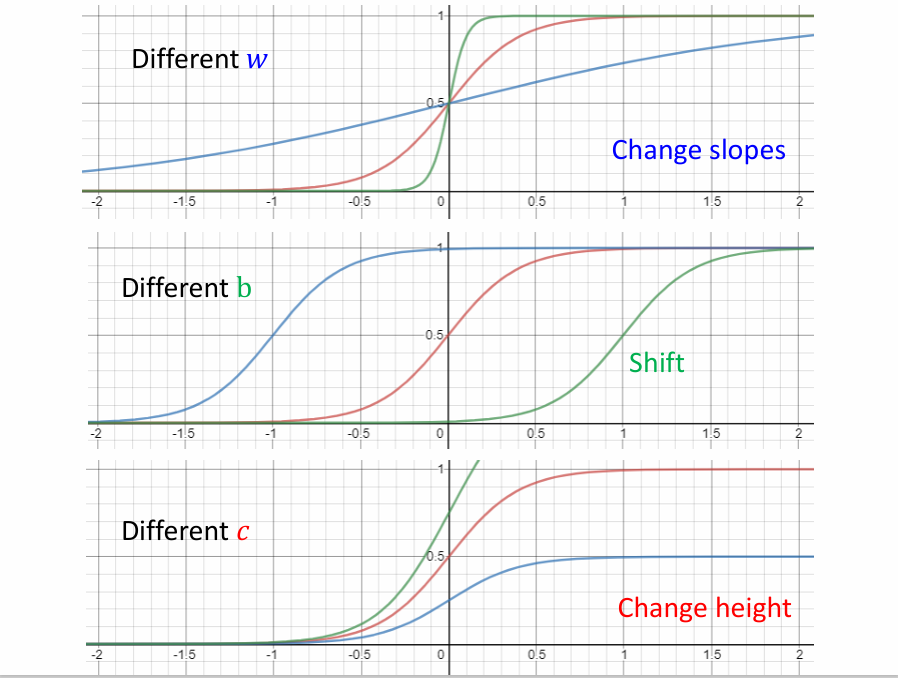
我们可以对sigmoid函数中的参数做调整,得到不同形状的sigmoid函数,来逼近蓝色函数。
改变w可以改变sigmoid函数的斜率;改变b可以左右移动其位置;改变c可以改变其高度,如下图:
所以不同的常数c,截距b和斜率w就会得到不同的sigmoid函数,然后将它们加起来就能够逼近目标函数,即
三、深度学习里的三个步骤
仿照前面ML里的三个步骤,我们也可以将其完全套在DL中
1. Function with unkonwn parameters
不同于ML里我们定义的简单的linear model,通过上面的分析我们可以得到一个全新的model——拥有更多features的model!
将前面的linear表达式代入sigmoid函数:
其中:
\(j\)代表第\(j\)个feature(即第\(j\)天的点击量);\(i\)代表选择第\(i\)个sigmoid函数;\(w_{ij}\)表示在第\(i\)个sigmoid函数中\(x_j\)的权值
如图,分别代入计算就能得到:
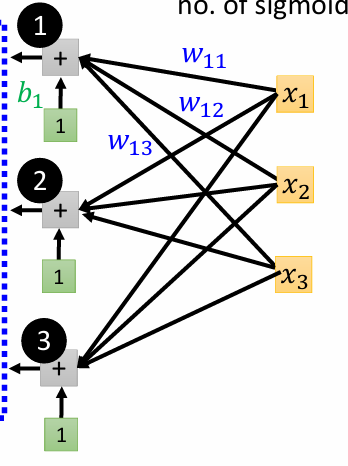
由线性代数的知识可以发现,上面的三个式子可以写作矩阵的乘法:
然后将\(r\)代入sigmoid函数,记作\(a = \sigma(r)\),乘上系数\(c\),再加上\(b\)就得到最后的\(y\),即\(y = b + c^Ta\)
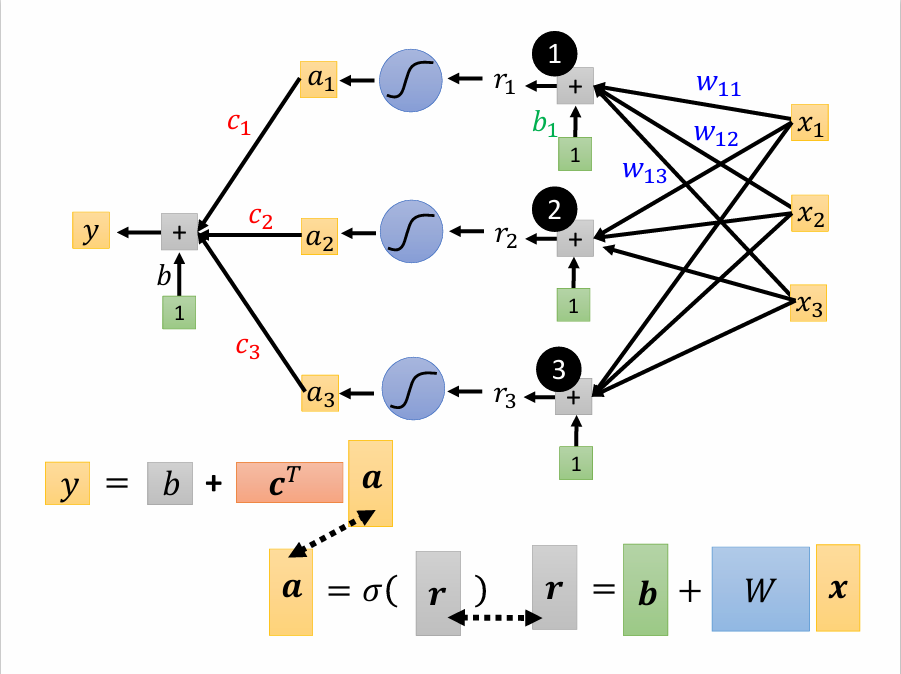
最终得到:$$y = b + c^T \sigma({\bf b} + Wx)$$(\(b\)和\(\bf b\)区别开)
将W矩阵中的行或者列取出来,与\(b\),\(\bf b\)和\(c^T\)竖着排列起来组成:
就进入了第2步找Loss函数
2. Define Loss from Training Data
Loss函数与ML一节中讲的一样,定义函数\(L(\theta)\)
先给定一组参数代入\(y = b + c^T \sigma({\bf b} + Wx)\)计算出\(y\)的值,然后将其与真实值(label) \(\widehat{y}\)比较,得到误差\(e\),最后便可得Loss函数的表达式:
进而到第3步找一个最优解的步骤
3. Optimization
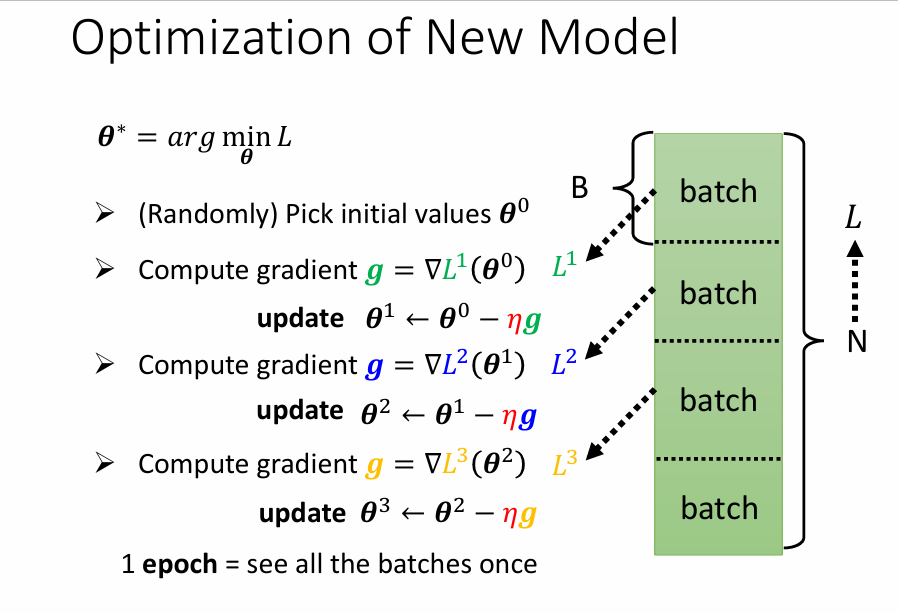
记 \(\theta^\star = arg min_{\theta}L\)
-
(Randomly)Pick initial value \(\theta^0\)
gradient \(g = \begin{bmatrix} \dfrac{\partial L}{\partial \theta_1}|_{\theta = \theta^0} \\ \dfrac{\partial L}{\partial \theta_2}|_{\theta = \theta^0} \\ . \\ . \\ . \end{bmatrix}\)
可以记作:\(g =\nabla L(\theta^0)\)(就是梯度符号) -
Compute gradient again and again
\(g =\nabla L(\theta^0)\) \(\theta^1 \leftarrow \theta^0 - \eta g\)
\(g =\nabla L(\theta^1)\) \(\theta^2 \leftarrow \theta^1 - \eta g\)
\(g =\nabla L(\theta^2)\) \(\theta^3 \leftarrow \theta^2 - \eta g\)
还有另一种计算方式,将整个L中的数据分成N个batch(批),每批数据中有B个数据,与上面的方法略有差异,每次update时,是依次从每个batch里取出数据来update,当把所有的batch更新过一遍,叫1个epoch(时期)
四、从sigmoid到ReLU
ReLU(Rectified Linear Unit)是另一种 Activation Function(激活函数),前面提到的分段Sigmoid(Hard-Sigmoid)函数的表达式可能会很难写出来,但是其可以看作是2个ReLU函数相加,ReLU函数的表达式如下: $$c*max(0, b + wx_1)$$
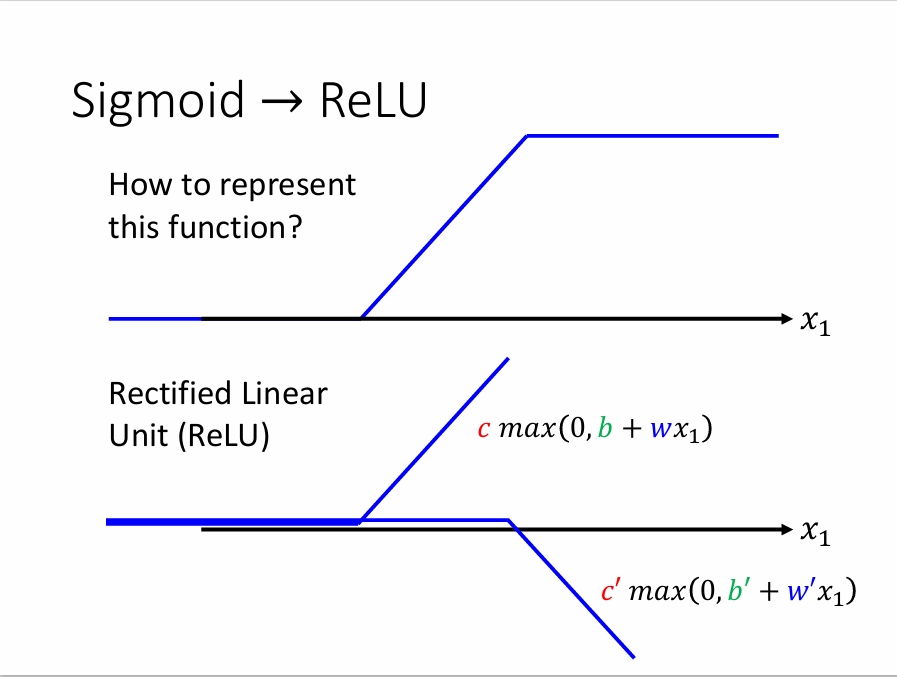
如此,我们前面y的表达式就可以变成:
注意换成ReLU函数后,\(i\)变为原来的2倍,因为2个ReLU函数才能合成一个Sigmoid函数
五、到底为什么叫Deep Learning ?
上面的例子里我们只套了一层激活函数就得到了y的表达式,但是人们发现套的层数多一些预测的效果就会更好一些,所以不妨多套几层:
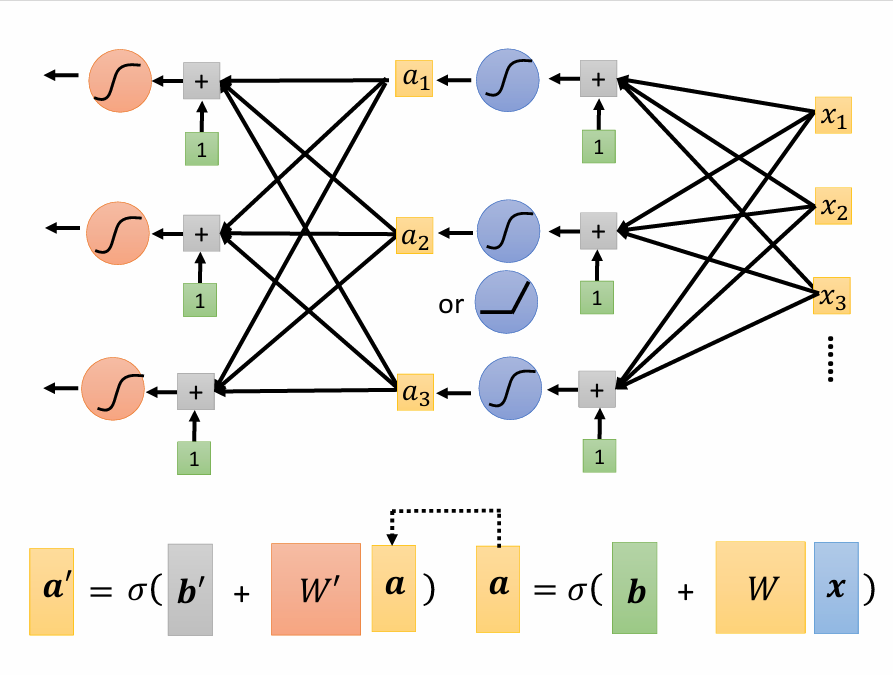
其中我们用到的sigmoid或ReLU函数叫neuron(神经元),许多neuron套起来就叫neural network(神经网络)。后来人们又给它们取了新的名字,每一排的neuron叫作hidden layer(隐含层),有许多层layer所以叫作Deep Learning
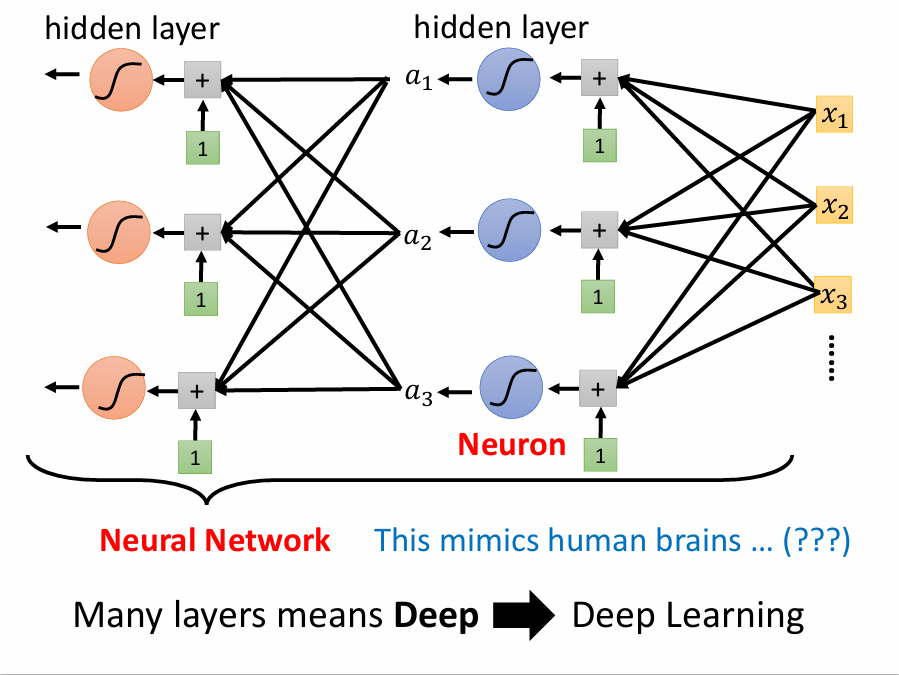
但是层数越多不见得预测效果会越好,在课堂实例中,虽然随着层数的增加,在训练数据上的效果越来越好,但是在预测数据上误差出现了增大,这便是overfitting(过拟合)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号