
学习中遇到的问题
- 1.在编写程序的过程中,break没有理解透,也就是自己编写程序很难将break应用在程序中?
- 2.python 中的numpy在多维数组进行索引时,数字索引和切片索引?
import numpy as np
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
#Two ways of accessing the data in the middle row of the array.
#while using only slices yields an array of the same rank as the
#original array:
row_r1 = a[1, :] # Rank 1 view of the second row of a
row_r2 = a[1:2, :] # Rank 2 view of the second row of a
print(row_r1, row_r1.shape) # Prints "[5 6 7 8] (4,)"
print(row_r2, row_r2.shape) # Prints "[[5 6 7 8]] (1, 4)"
#We can make the same distinction when accessing columns of an array:
col_r1 = a[:, 1]
col_r2 = a[:, 1:2]
print(col_r1, col_r1.shape) # Prints "[ 2 6 10] (3,)"
print(col_r2, col_r2.shape) # Prints "[[ 2]
# [ 6]
# [10]] (3, 1)"
程序中可以得出的是,使用数字索引会使数组的维数降低!
import numpy as np
a = np.array([[1,2], [3, 4], [5, 6]])
#The returned array will have shape (3,) and
print(a[[0, 1, 2], [0, 1, 0]]) # Prints "[1 4 5]"
#The above example of integer array indexing is equivalent to this:
print(np.array([a[0, 0], a[1, 1], a[2, 0]])) # Prints "[1 4 5]"
-
机器学习的思想:
利用优化函数来寻找能使损失函数最小的那个参数 -
凸优化问题(convex )
涉及到矩阵,训练集,测试集的矩阵运算,以及维度方面的问题
就是程序的编写问题,也就是数据的预处理问题. -
计算梯度
数值梯度和分析梯度 numerical gradient & analytic gradient -
java编写程序的输入输出问题.一直不是很懂这个输入的程序代码.
-
机器学习中归一化的使用.当你确定在输入中不同的输入特征有不同的scales尺度规模.
-
数据预处理之PCA主成分分析(principal component analysis).
是一种常用的降维方法
矩阵的变换,矩阵变换的本质就是将向量进行一系列的拉伸,旋转,变换
矩阵高维度下变换,变换的方向是由特征向量来决定的.通过特征值分解得到的前N个特征向量,那么就对应了这个矩阵最主要的N个变化方向。我们利用这前N个变化方向,就可以近似这个矩阵(变换)。特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么.
降维,成分分析的目的:舍弃一部分信息,样本的采样密度增大;另一方面,舍弃数据可以起到降噪的效果.
协方差矩阵(covariance matrix),可以反应数据的相关结构.处理多个维度,多个特征之间的相互关系. -
白化(Whitening):PAC白化,就是将PCA变化后的维度,进行标准差归一化处理.
ZCA白化,在PCA白化的基础上,将坐标维度重新变回原来的坐标(原始的空间数据) -
数据处理常见的陷阱(common pitfall): 关于预处理的重要一点是,任何预处理统计(例如数据均值)必须仅在训练数据上计算,然后应用于验证/测试数据。 例如。 计算平均值并从整个数据集中的每个图像中减去它,然后将数据拆分为train / val / test splits将是一个错误.必须仅在训练数据上计算平均值,然后从所有分组(训练/值/测试)中相等地减去平均值。
-
批量归一化:简单的来说就是在激活层,全连接层,池化层等插入一个BN(batch normalization)
-
numpy的一个知识点:
np.random.randn()和np.random.rand()的区别
random.randn()是从一个标准正态样本分布返回样本值.
random.rand()返回属于[0,1)的随机样本值. -
关于机器学习初始化过程的一些好的建议:cs231n-lecture 6 梯度下降和参数优化 可能还是不够熟练,一些建议或者说是定义都没有看懂.
-
对机器学习训练过程的监视,通常都是用坐标的形式来进行凸显,横x-axis坐标一般都是用epoch.epoch表示在训练的过程中,每个实例被看到的次数.注意,一般情况下都是不会使用iteration迭代次数.因为在迭代次数依赖与批量次数大小的设置.
-
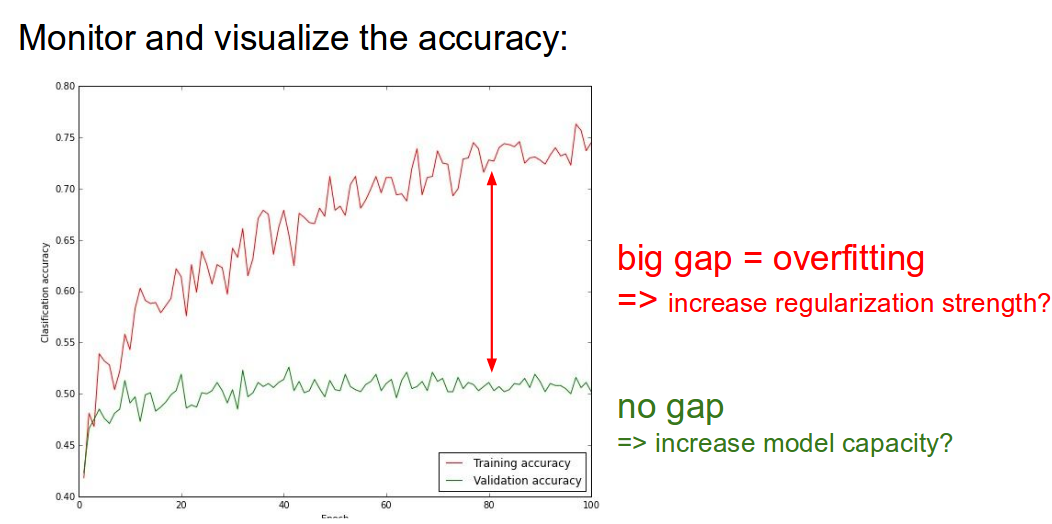
过拟合的判断:
训练集和正确率和验证集的正确率差别很大,这就表明了出现了过拟合.一般采取的方法是:regularization,dropout and collect more data.
如果训练集和验证集的两者之间契合的非常好,这也不是一个好现象,需要采用更大的模型,更多的参数.
![train&val accuracy]()
-
学习率的设置learning_rate一般设置在[1e-3 ,1e-5]之间.通过实际的测试检验得来的数据.
-
梯度优化,也叫梯度下降法.是将目标函数不断减小的策略.
基本的原理就是利用taylor函数的简化版来实现.$$f(x+\Delta x)=f(x)+\Delta x\bigtriangledown f(x)$$
实现自变量往目标函数减小的方向变化$$x+=\Delta x. 其中 \Delta x=-\gamma \bigtriangledown f(x)$$ -
关于CNN的转移学习.就利用已知大量的数据集将卷积神经网络训练好,直接将神经网络中的卷积层,池化层都不变.对于全连接层对新数据集进行重新的训练.
-
**Big question **有一个很大的问题,无论是在numpy 还是pytorch中,矩阵的运算问题.代码中都是没有考虑矩阵的shape,直接运算两个矩阵.这是个内置的运算问题吗?在进行运算时会主动将矩阵进行转置?
-
pytorch 反向传播中,使用grad.zero_()来进行实现循环来保证 权重值的更新.
-
关于概率论矩估计的一点知识点:\((x,y)\)二维随机变量,\(E(X_{k})\)称之为\(X\)的k阶原点矩.\(E([X-E(X)]^{2})\)称为\(X\)的k阶中心矩.其实也就是方差\(D(X)\).协方差\(cov(X,Y)\)是\(X,Y\)的二阶混合中心矩.
-
深度学习框架的选择:
PyTorch is my personal favorite. Clean API, dynamic graphs make it very easy to develop and debug. Can build model in PyTorch then export to Caffe2 with ONNX for production / mobile
TensorFlow is a safe bet for most projects. Not perfect but has huge community, wide usage. Can use same framework for research and production. Probably use a high-level framework. Only choice if you want to run on TPUs.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号