
浮点数表示 & 缓存 & 布隆过滤器
浮点数表示 & 缓存 & 布隆过滤器
- 1.计算机是如何表示小数
- 2.缓存
- 3.布隆过滤器
1.浮点数的表示
引子: 我们先看一个错误示例
public static void main(String[] args) {
System.out.println(1f == 0.999999f); // false
System.out.println(1f == 0.9999999f); // false
System.out.println(1f == 0.99999999f); // true
System.out.println(1f == 0.999999999999f); // true
}
注意: 不能使用 "==" 对浮点值进行判断
浮点数之间的等值判断,基本数据类型不能使用 "==" ,包装数据类型不能使用 equals来判断 --- 阿里巴巴Java开发手册[强制]
为什么浮点数不能使用 "==" 判断 ?
计算机是如何表示小数的?
十进制小数
\[D = \sum^{m}_{i=-n} d_{i} * 10^{i}
\]
二进制小数
\[B = \sum_{i= -n}^{m} b_{i}*2^{i}
\]
IEEE-745浮点标准
\[V = (-1)^s * M *2^E
\]
- s 符号位
- M 阶码部分
- E 尾数部分
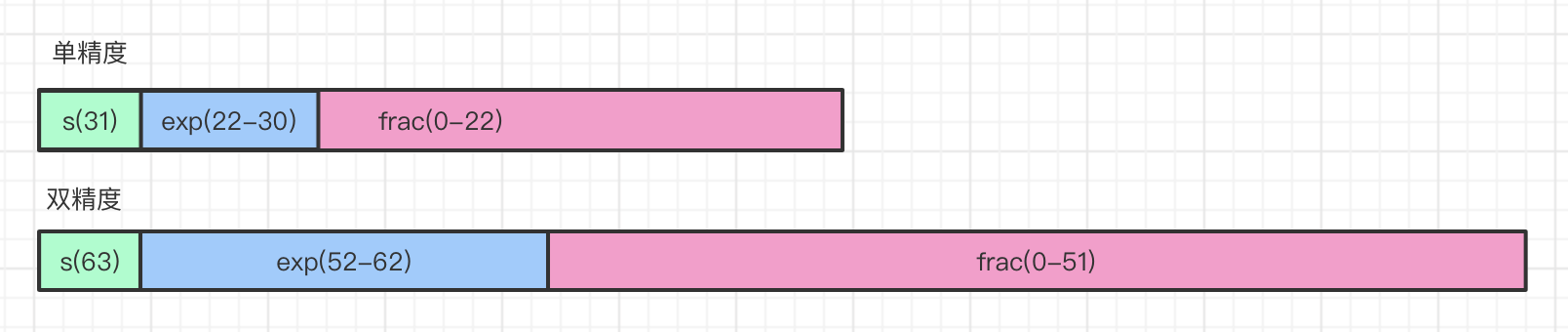
符号s: 0正,1负
阶码E: float 8bit(-128,127) double 11bit(-1023,1024)
尾数M:float 23bit double 52bit
\[V = x * 2^y
\]
根据exp的值,被编码的值可以分为三种
- 规格化的值
- 非规格化的值
- 特殊值
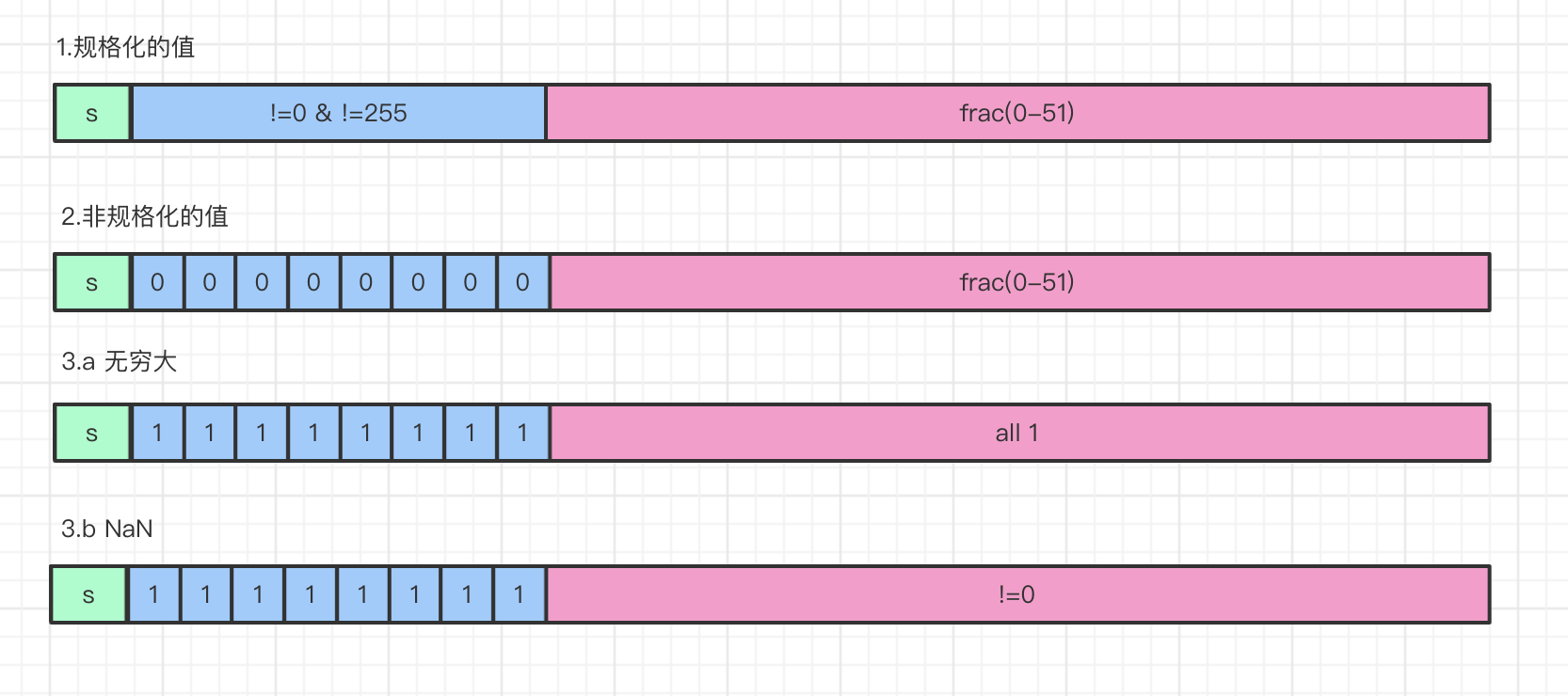
1.规格化的值
\[E = e - Bias
\]
\[M = 1+ f
\]
- e - exp表达式的值
- Bias
\[Bias = 2^{k-1} -1 ; (127,1023)
\]
- M - 调整阶码的值
\[1101.111 = 1.101111 * 2^{3}
\]
案例example
\[13.875_{10} = 1101.111_{2} = 1.101111_{2} * 2^{3}
\]
\[M = 1 +f
\]
\[f = 1011111
\]
\[e = E + Bias = 3 + 127 = 130_{10} = 10000010_{2}
\]
| 13.875 |
|---|
| Sign Exponent Mantissa |
| 0x415E0000 = 01000001 01011110 00000000 00000000 0 10000010 10111100000000000000000 |
2.非规格化的值
\[E = 1- Bias
\]
\[M = f
\]
3.特殊值
a.当exp全部为1,小数域全为0,表示无穷
b.当exp全部为1,小数域frac不等于0,表示NaN(not a number)
2.缓存
应用缓存 ->性能优化案例:
- 操作系统
- 数据库
- 分布式缓存
- 本地缓存
缓存目的: 弥补cpu高算力和IO读写慢之间的鸿沟
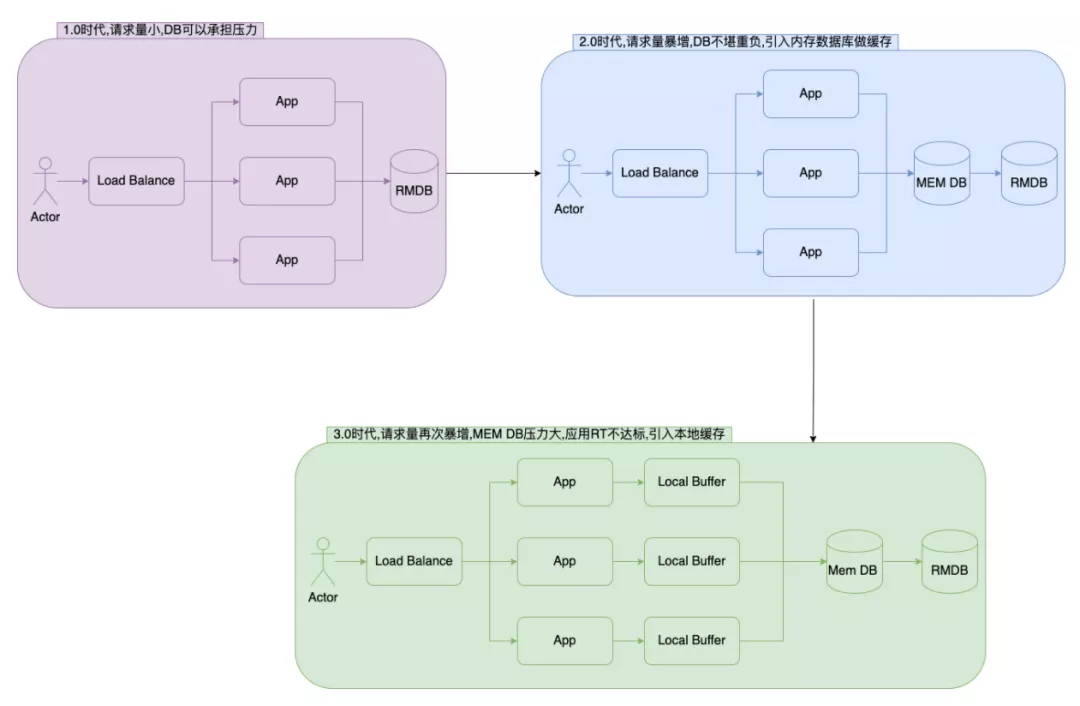
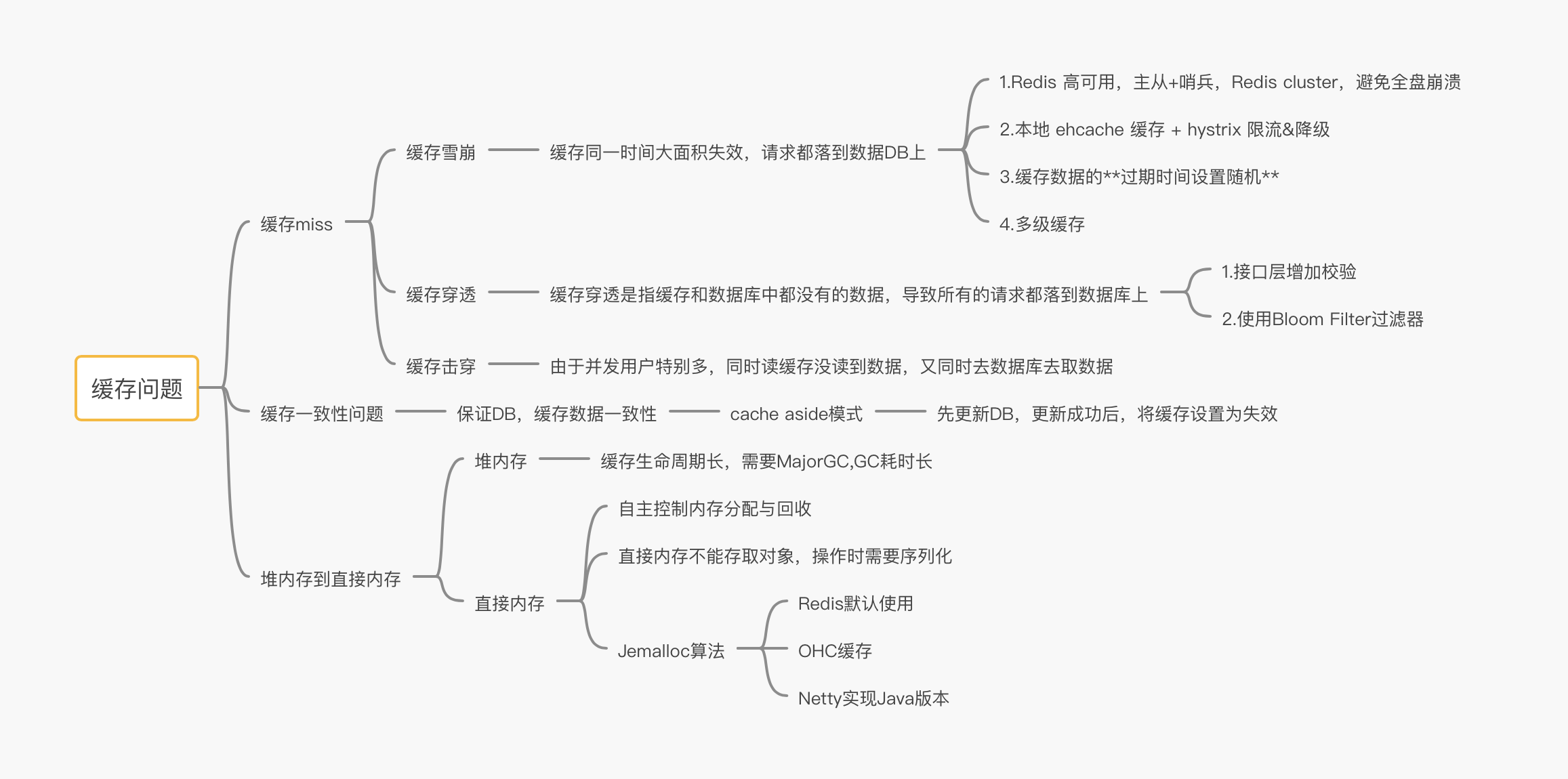
缓存
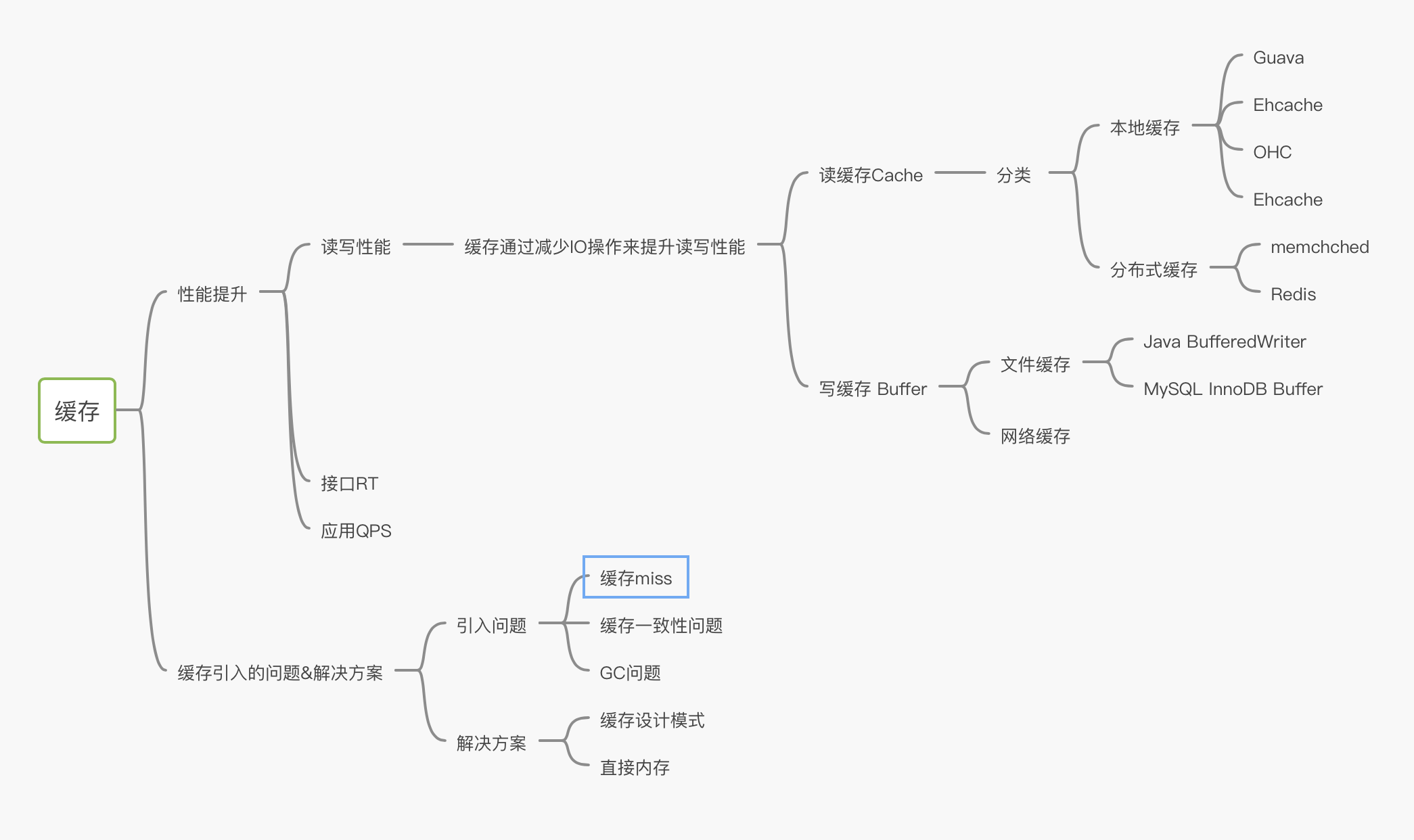
缓存问题
3.布隆过滤器
如何判断一个元素是否已经存在?
1.set集合
2.数据+hash , index = hash(xx) % table.length
3.Bloom Filter
布隆过滤器:
-
减少hash冲突,优化hash函数(多个hash实现)
-
增加数组长度
![]()
假设用100w的数据量
- 使用int数组
\[1*10^{6} * 4 (Byte) = 4*10^{6}/1024 = 4000k \]- 使用位数组
\[1*10^{6} / 8 = 125000(byte) = 127k \]
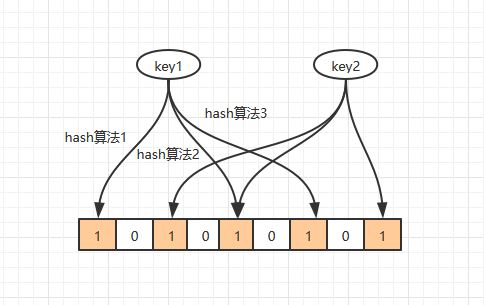
布隆过滤器的判断方法
- 布隆过滤器判定某个元素存在,其实有可能存在(hash冲突)
- 布隆过滤器判定某个元素不存在,则一定不存在
布隆过滤器的使用场景
- 判断数据在海量数据中是否存在,防止缓存穿透
- 判定某个URL是否已经处理过
布隆过滤器的实现
package src.bloomFilter;
import java.util.BitSet;
/**
* @Author deng shuo
* @Date 6/12/21 10:07
* @Version 1.0
*/
public class MyBloomFilter {
private static final int DEFAULT_SIZE = 2 << 24;
private static int[] SEEDS = new int[]{3,13,46};
private static BitSet bits = new BitSet(DEFAULT_SIZE);
private SimpleHash[] func = new SimpleHash[SEEDS.length];
public MyBloomFilter(){
for(int i = 0;i< SEEDS.length;i++){
func[i] = new SimpleHash(DEFAULT_SIZE,SEEDS[i]);
}
}
public void add(Object value){
for(SimpleHash f: func){
bits.set(f.hash(value),true);
}
}
public boolean contains(Object value){
boolean res = true;
for(SimpleHash f:func){
res = bits.get(f.hash(value));
if(!res){
return false;
}
}
return true;
}
public static class SimpleHash{
private int cap;
private int seed;
public SimpleHash(int cap ,int seed){
this.cap = cap;
this.seed = seed;
}
public int hash(Object value){
int h;
return (value == null) ? 0:
Math.abs(seed*(cap -1) & (h=value.hashCode())^(h>>>16));
}
}
}
Guava工具库实现布隆过滤器
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>27.0.1-jre</version>
</dependency>
// 创建布隆过滤器对象,最多元素数量为10000,期望误报概率为0.01
BloomFilter<Integer> filter = BloomFilter.create(
Funnels.integerFunnel(), 10000, 0.01);
不要用狭隘的眼光看待不了解的事物,自己没有涉及到的领域不要急于否定.
每天学习一点,努力过好平凡的生活.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号