
Flink源码解析(二十一) ——Checkpoint过程解析(下)
一、状态存储及快照策略说明
1、Flink用户视角下状态存储新旧版本区分
(1)、旧版本StateBackend
旧版本StateBackend分类:MemoryStateBackend、FsStateBackend、RocksDBStateBackend
旧版本StateBackend用法:
1)、单任务配置
env.setStateBackend(new FsStateBackend("hdfs://hdfsha/flink/checkpoints"));
env.setStateBackend(new MemoryStateBackend());
env.setStateBackend(new RocksDBStateBackend(filebackend, true));
2)、全局配置flink-conf.yaml
state.backend: filesystem
state.checkpoints.dir: hdfs://hdfsha/flink/checkpoints
注:旧版本StateBackend机制模糊了作业运行过程中状态存储、访问过程和作业checkpoint过程中状态持久化过程,新版本用CheckpointStorage强调了下Checkpoint过程,将这俩过程做了区分。
(2)、新版本StateBackend
新版本StateBackend分类:HashMapStateBackend、EmbeddedRocksDBStateBackend
新版本StateBackend用法:
1)、HashMapStateBackend 替代 旧版本MemoryStateBackend
env.setStateBackend(new HashMapStateBackend()); //更偏向于作业运行过程中状态存储及访问过程
env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage()); //更偏向于作业checkpoint过程中状态持久化过程
2)、HashMapStateBackend 替代 旧版本FsStateBackend
env.setStateBackend(new HashMapStateBackend()); //更偏向于作业运行过程中状态存储及访问过程
env.getCheckpointConfig().setCheckpointStorage("hdfs://checkpoints"); //更偏向于作业checkpoint过程中状态持久化过程
3)、EmbeddedRocksDBStateBackend 替代 旧版本RocksDBStateBackend
env.setStateBackend(new EmbeddedRocksDBStateBackend()); //更偏向于作业运行过程中状态存储及访问过程
env.getCheckpointConfig().setCheckpointStorage("hdfs://checkpoints"); //更偏向于作业checkpoint过程中状态持久化过程
2、Flink系统视角下状态存储
1)、Flink系统视角下更关注状态分类即OperatorState和KeyedState,在Checkpoint状态持久化过程中用DefaultOperatorStateBackend实现OperatorState持久化,用HeapKeyedStateBackend实现KeyedState持久化。Flink用户视角下状态存储StateBackend会新建DefaultOperatorStateBackend和HeapKeyedStateBackend。
2)、快照策略SnapshotStrategy,快照策略代表同一个状态存储不同的快照方法过程。
DefaultOperatorStateBackend对应的快照策略是DefaultOperatorStateBackendSnapshotStrategy
HeapKeyedStateBackend对应的快照策略是HeapSnapshotStrategy
RocksDBKeyedStateBackend对应的快照策略有2个,全量快照策略RocksNativeFullSnapshotStrategy和增量快照策略RocksIncrementalSnapshotStrategy
上篇随笔中提到OperatorSnapshotFutures包含4个异步状态数据持久化动作,新建OperatorSnapshotFinalizer对象时构造函数中会异步执行这4个不同类型的状态快照过程,但没有解析状态数据Checkpoint过程细节。本篇随笔把托管的KeyedState、OperatorState快照过程详细解析下,即着重分析HeapKeyedStateBackend和DefaultOperatorStateBackend。
二、KeyedState快照过程
Flink系统通过方法HeapKeyedStateBackend.snapshop(...)触发KeyedState快照过程核心逻辑,最终方法链调用会转入到方法SnapshotStrategyRunner.snapshot(...)中去。
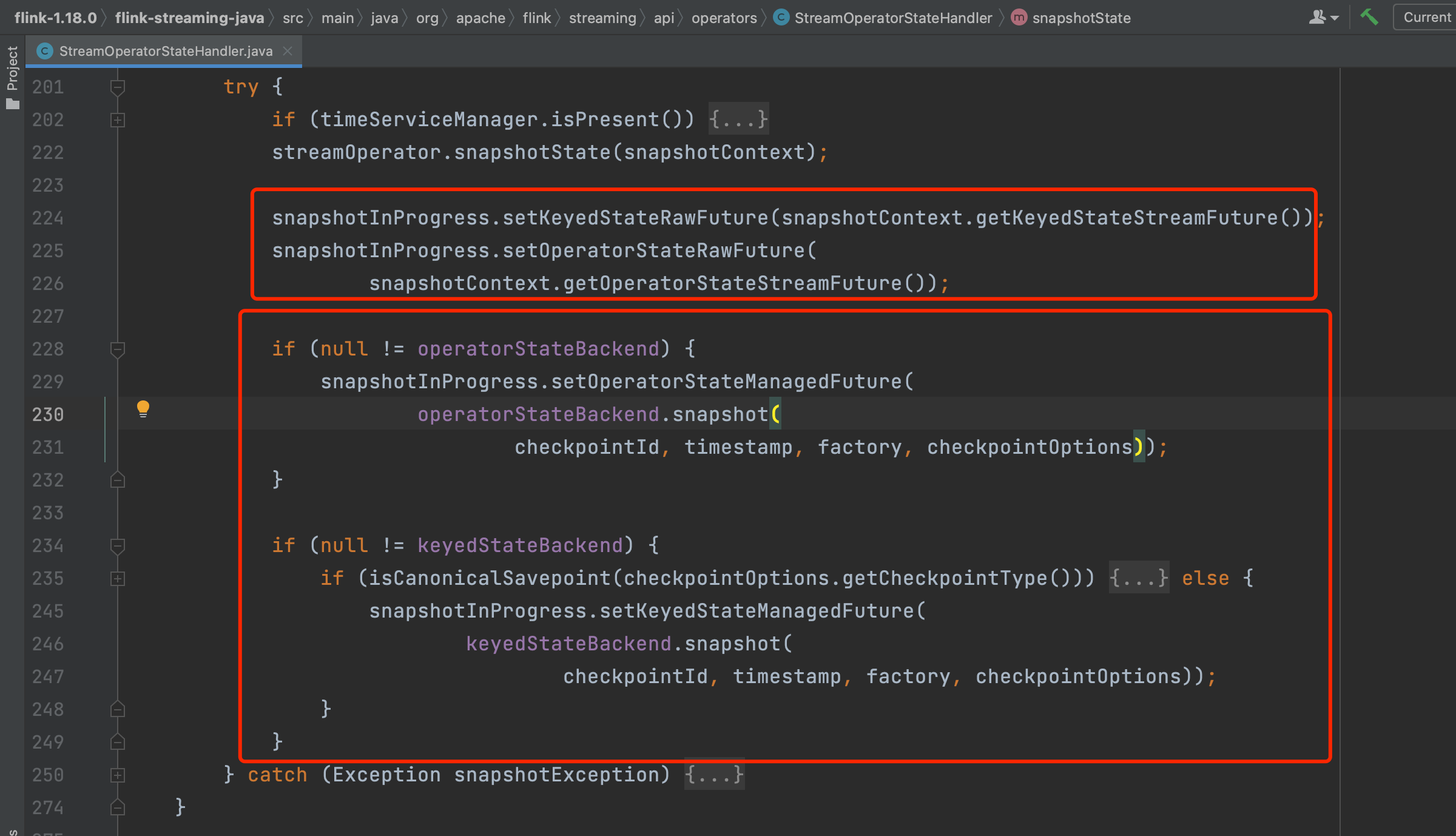
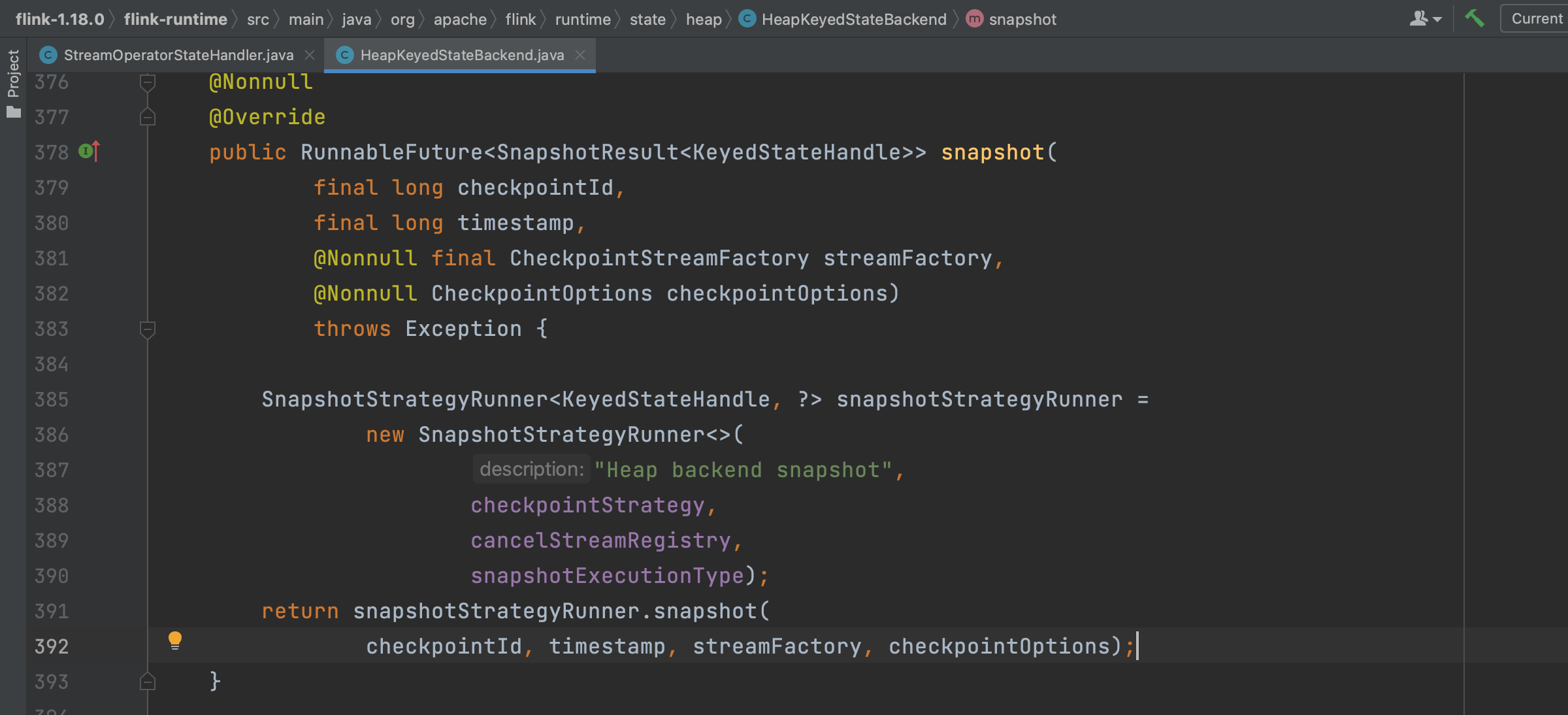
方法SnapshotStrategyRunner.snapshot(...)包含两个重要步骤,分别如下:
1、第77行:SR snapshotResources = snapshotStrategy.syncPrepareResources(checkpointId);同步拷贝状态数据的引用,而不是状态实例对象数据的拷贝。
2、第80行:snapshotStrategy.asyncSnapshot(...);方法里创建Checkpoint输出流CheckpointStateOutputStream、Checkpoint数据持久化操作。
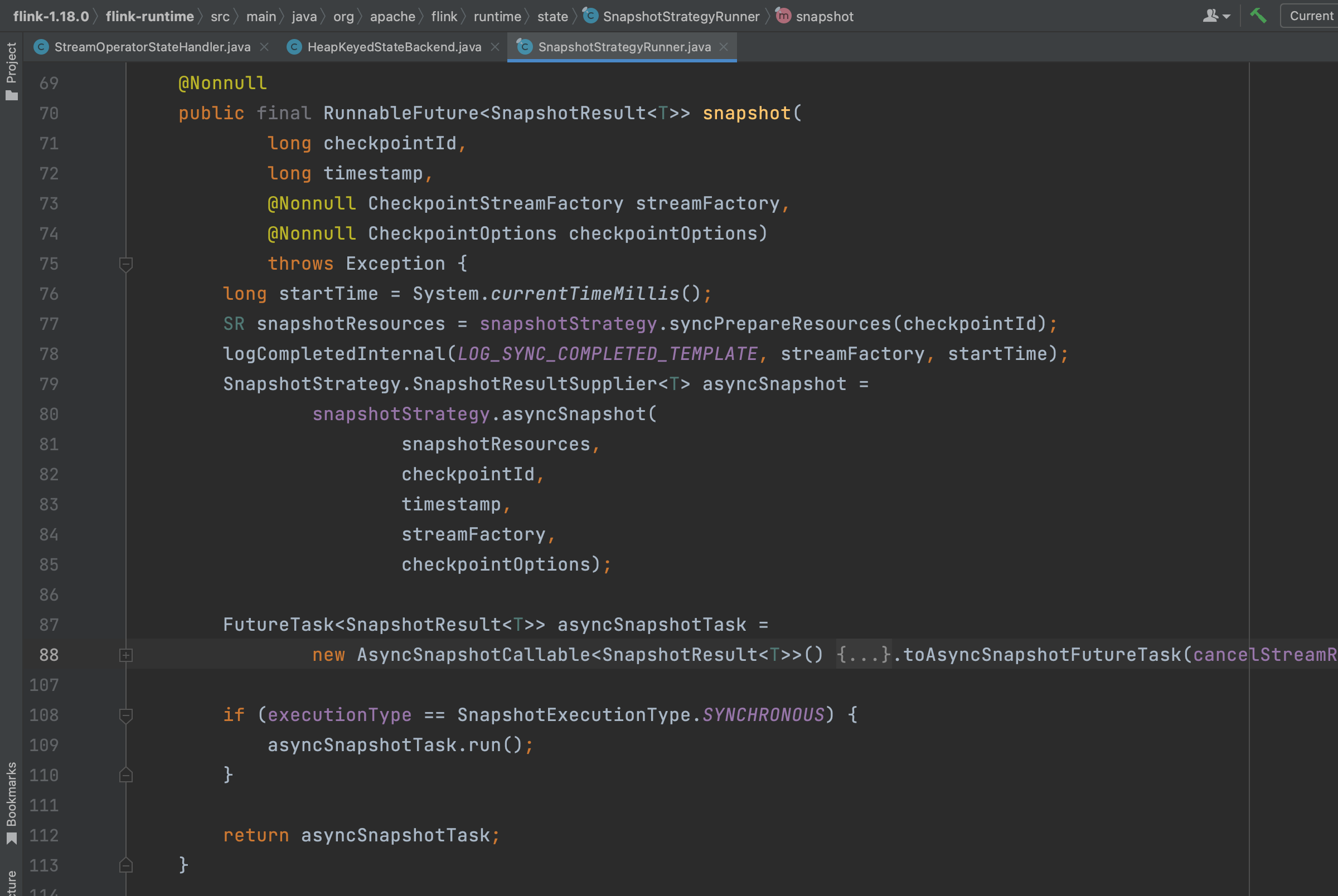
下面详细解析这两个重要步骤:
1、snapshotStrategy.syncPrepareResources(checkpointId)跳转到方法HeapSnapshotResources.create(...)里拷贝状态引用。
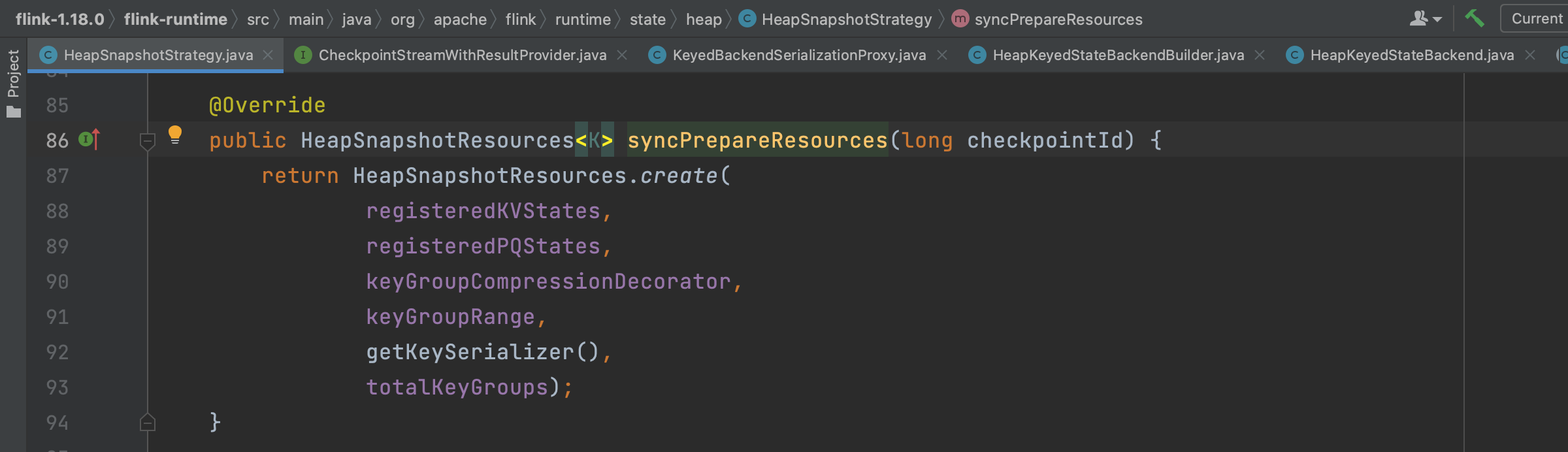
方法HeapSnapshotResources.create(...)第一个参数registeredKVStates代表Flink应用业务代码里注册的状态描述符数据表,是一个Map结构类型。key是状态描述符的名称,比方说下面一行代码注册了一个key是"pv"的ValueState类型的状态数据表,value就是状态数据表,一般来说是CopyOnWriteStateTable类型。假如一个KeyedStream流用userId字段做keyby分组,registeredKVStates的value就是同一个算子上所有userId的pv状态的数据值。
ValueStateDescriptor<Long> descriptor = new ValueStateDescriptor<>("pv",Long.class);

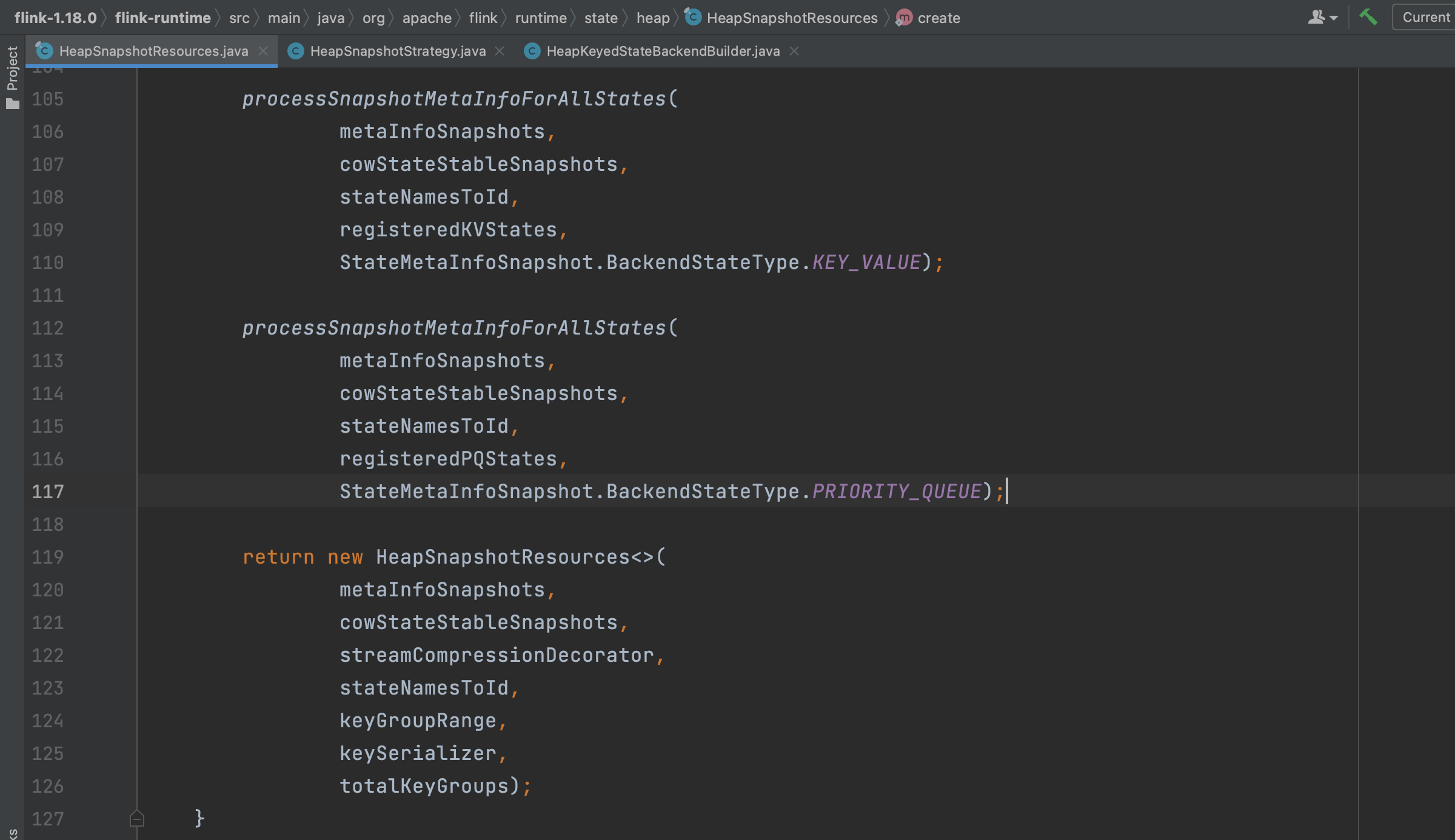
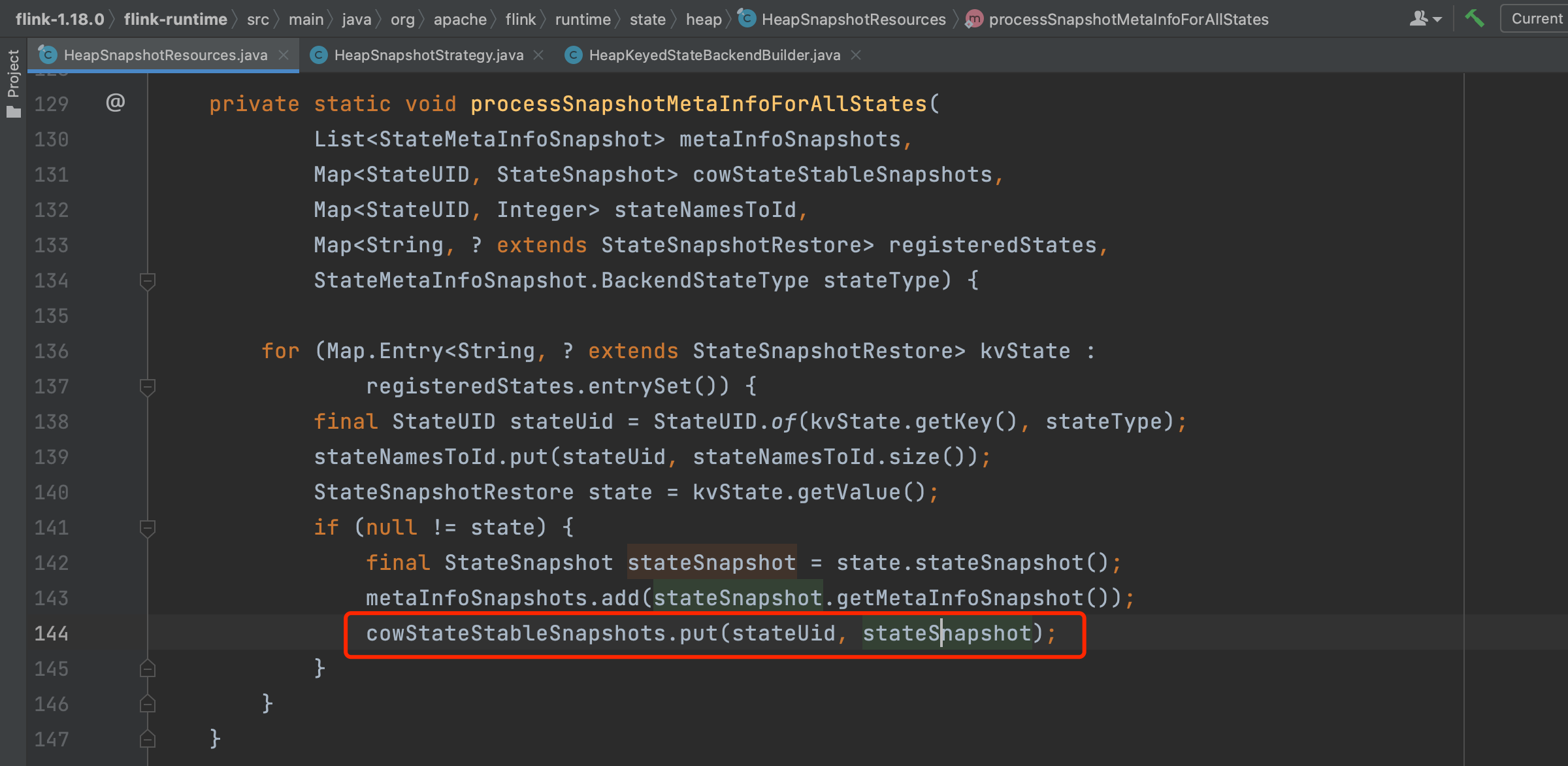
以下方法processSnapshotMetaInfoForAllStates(...)作用是拷贝状态数据的引用,而不是状态实例对象数据的拷贝。该过程执行比较快,可以同步执行。针对Flink业务代码里每一个状态描述符数据表,创建一个CopyOnWriteStateTableSnapshot快照放到cowStateStableSnapshots里。CopyOnWriteStateTableSnapshot快照的主要行为是将CopyOnWriteStateTable中的状态数据拷贝到CopyOnWriteStateTableSnapshot.stateMapSnapshots数组里。类CopyOnWriteStateTable的成员变量keyGroupedStateMaps实际类型是CopyOnWriteStateMap,CopyOnWriteStateMap牺牲部分性能和内存效率换来增量hash、写时复制的异步快照功能。
2、创建Checkpoint输出流CheckpointStateOutputStream、Checkpoint的持久化操作。
方法HeapSnapshotStrategy.asyncSnapshot(...)实现逻辑里主要包括CheckpointStateOutputStream输出流创建、Checkpoint的持久化操作等行为。
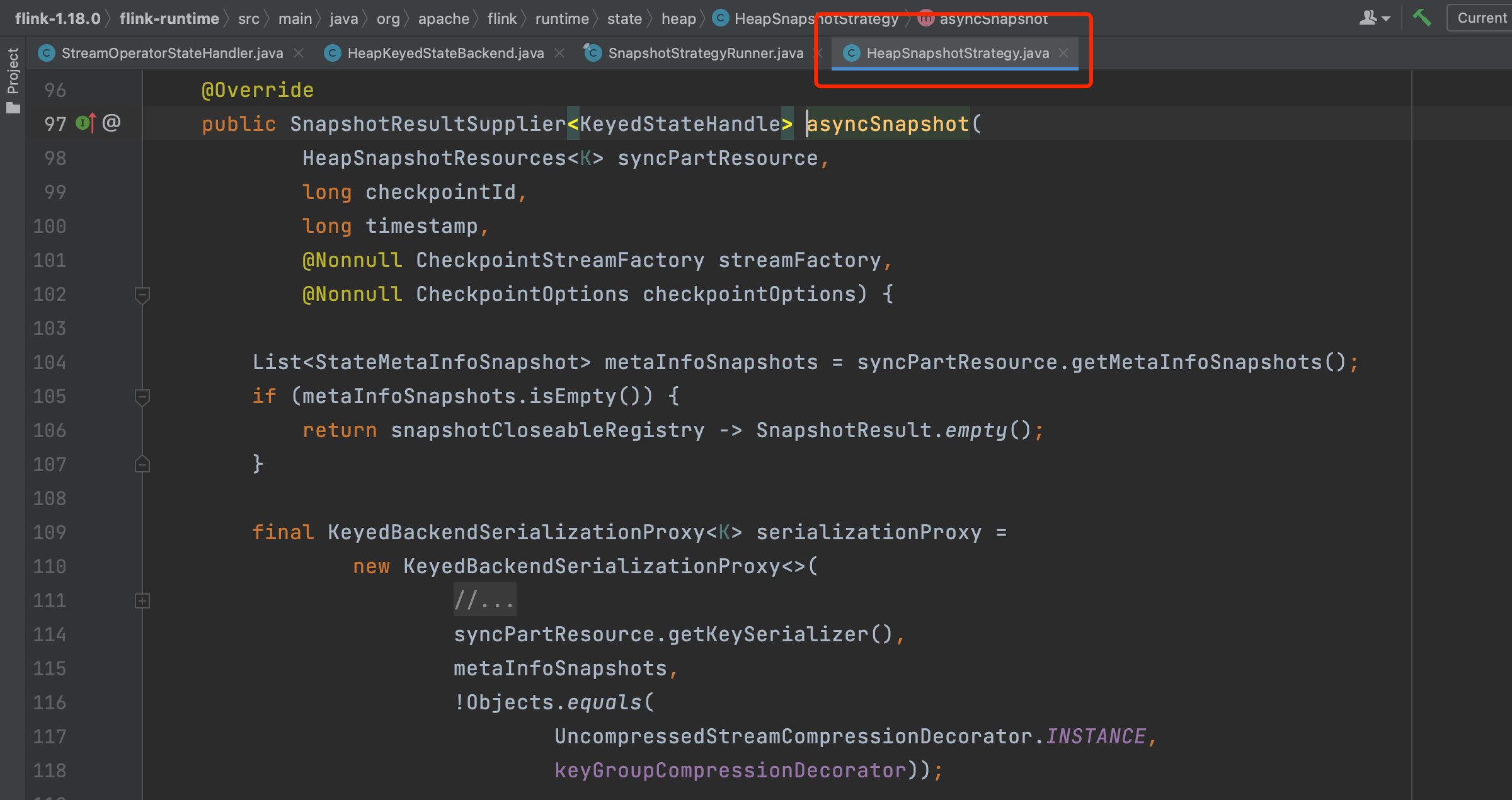
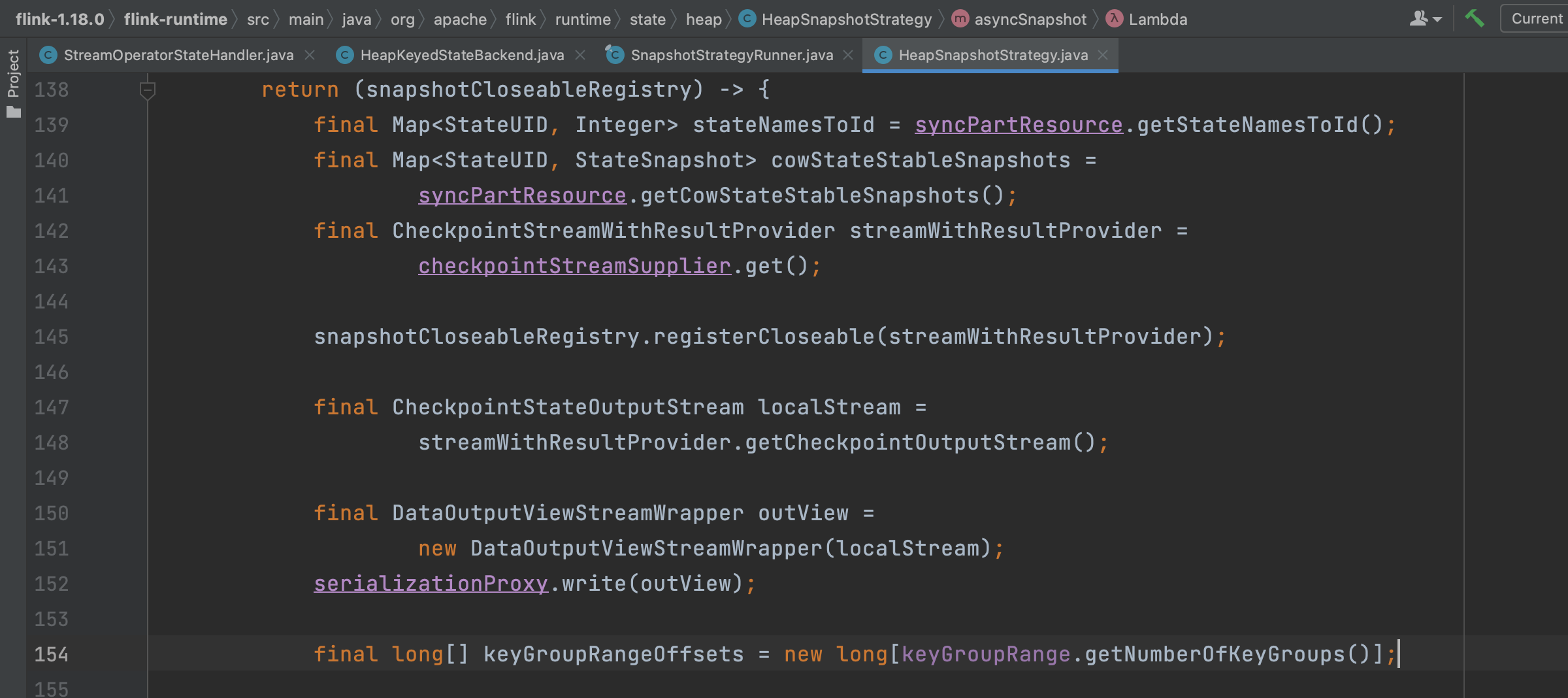
下面详细分析方法HeapSnapshotStrategy.asyncSnapshot(...)的功能。
(1)、创建Checkpoint输出流CheckpointStateOutputStream,在生产环境中一般用文件系统FsStateBackend做Checkpoint状态持久化操作,比如HDFS系统,对应的输出流类型是FsCheckpointStateOutputStream。
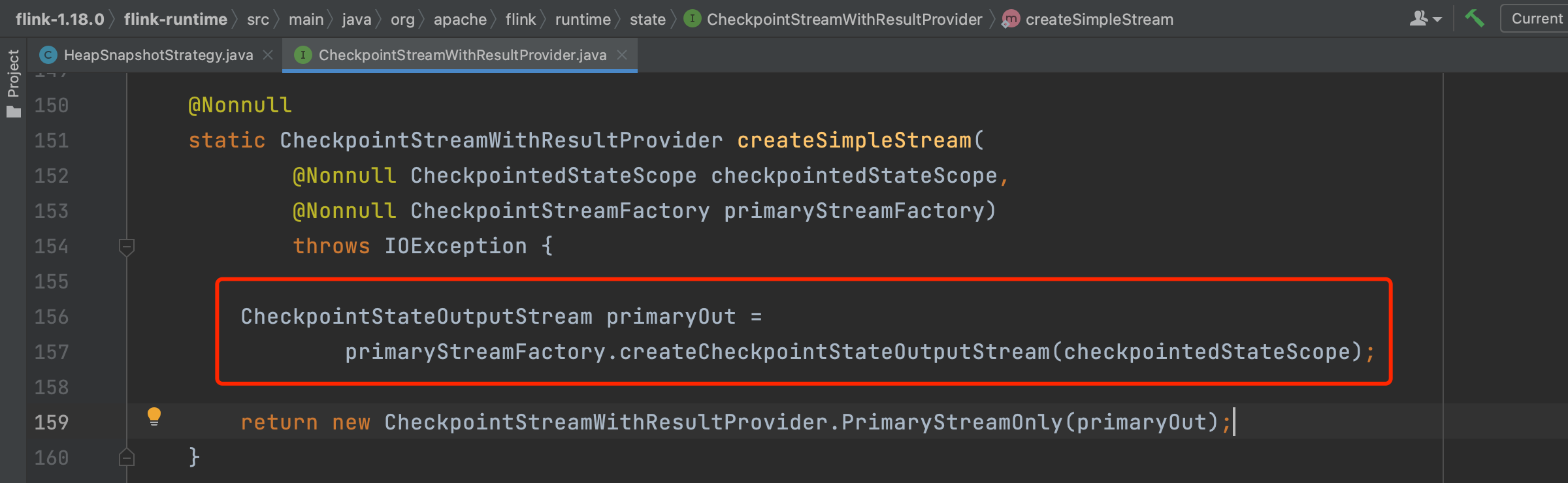
FsCheckpointStateOutputStream主要成员信息如下:
writeBuffer:状态数据写入缓冲数组byte[],数据先写到内存的缓存数组中,最后落盘,减少和文件系统的io交互。
pos:writeBuffer中数据写入的当前位置。
outStream:FSDataOutputStream类型,代表Checkpoint状态持久化文件路径名,通过该流成员将状态数据写到最终文件里。
basePath:checkpoint基础路径,来源于配置项:state.backend.fs.checkpointdir
fs:HDFS文件系统
localStateThreshold:状态数据大小阈值,默认值是20KB,上限是1MB。小于该阈值的状态数据会写到ByteStreamStateHandle字节数组成员中,以减少小文件数量。大于该阈值的状态数据落入文件中。
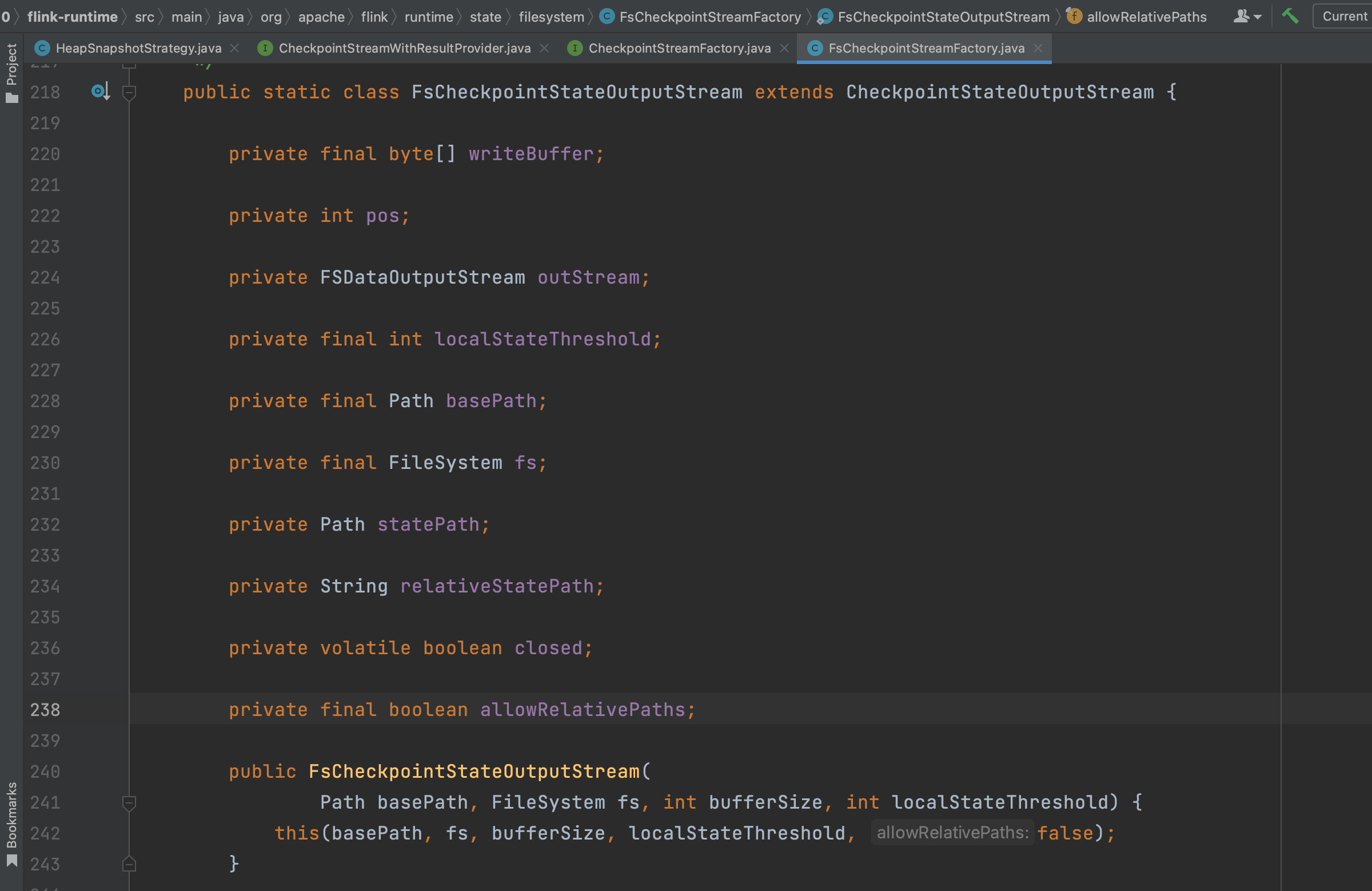
(2)、类文件HeapSnapshotStrategy第152行serializationProxy.write(outView); 利用CheckpointStateOutputStream,将状态数据的压缩格式、序列化类型、状态个数、状态名字等数据写入流中。
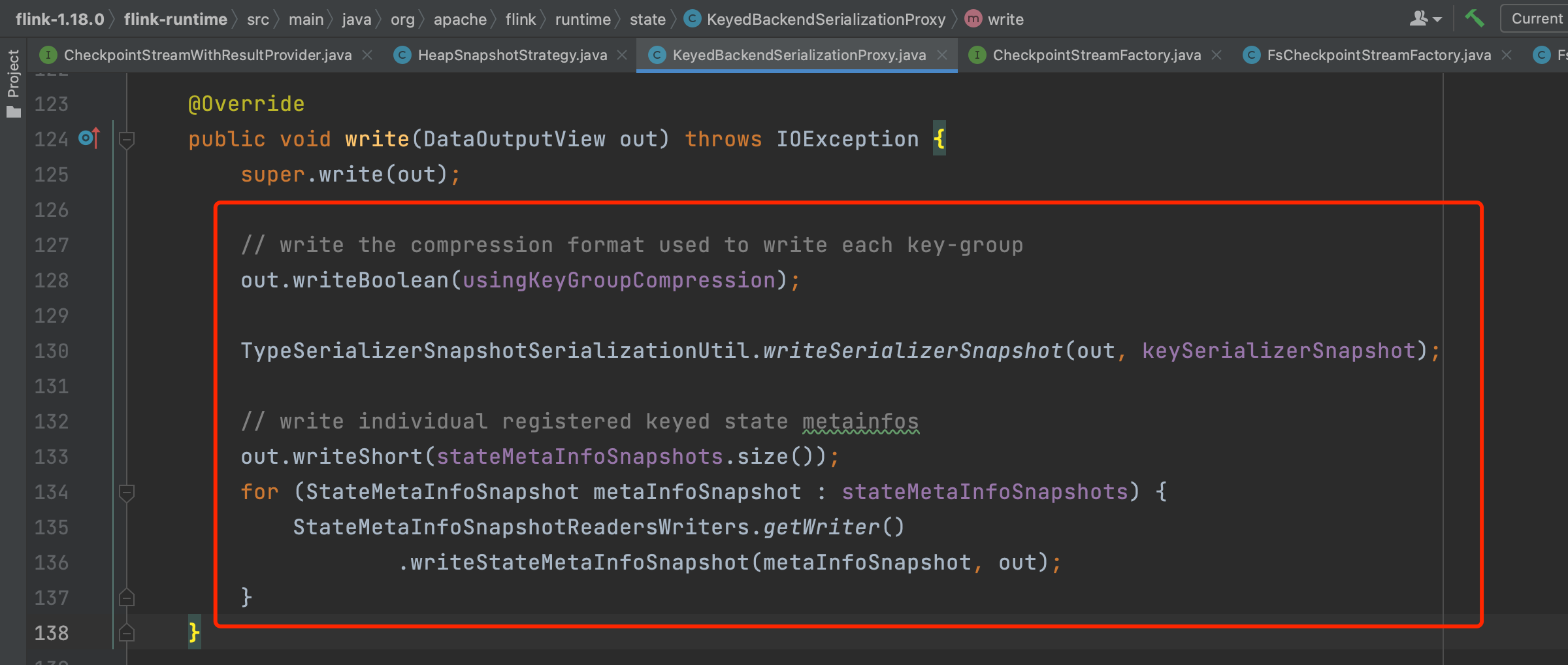
(3)、 分组状态数据写入
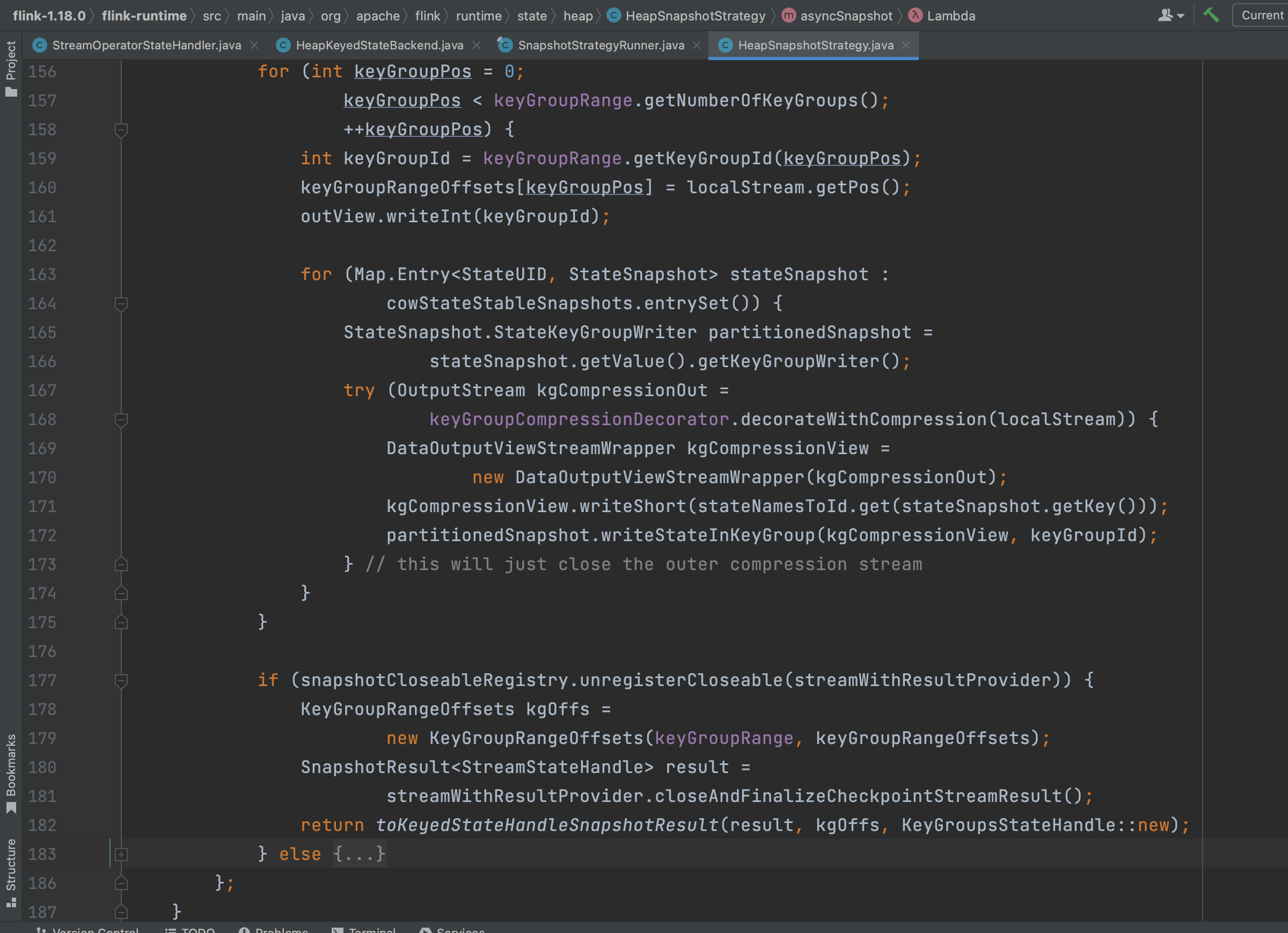
简单来说,keyBy(...)操作按key将数据分组后以近乎随机的形式分配不同的key到不同的Task节点上。实际上Flink系统将不同的key分配到不同的keyGroup上,然后将一段连续的keyGroup分配到一个特定的Task节点上,这样实现不同的key到不同的Task节点。keyGroup的数量由StreamExecutionEnvironment.maxParallelism指定。
下图keyGroupRange指的就是一段连续的keyGroup,keyGroupRangeOffsets数组记录的是每个状态数据分组在状态文件里的位置。在将keyGroupId和状态id写入文件中后,接着写入分组后的状态数据。
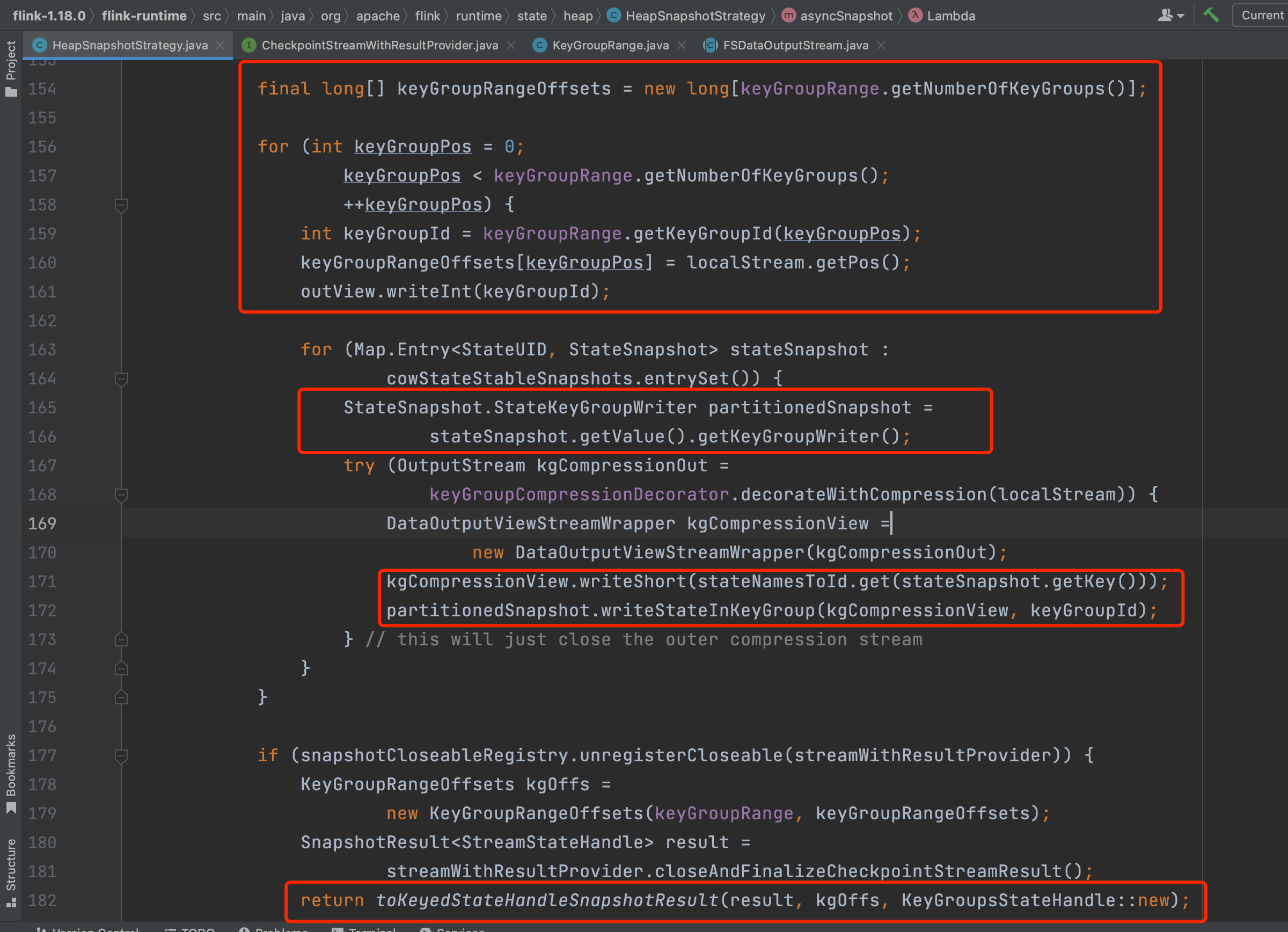
分组状态数据的写入。
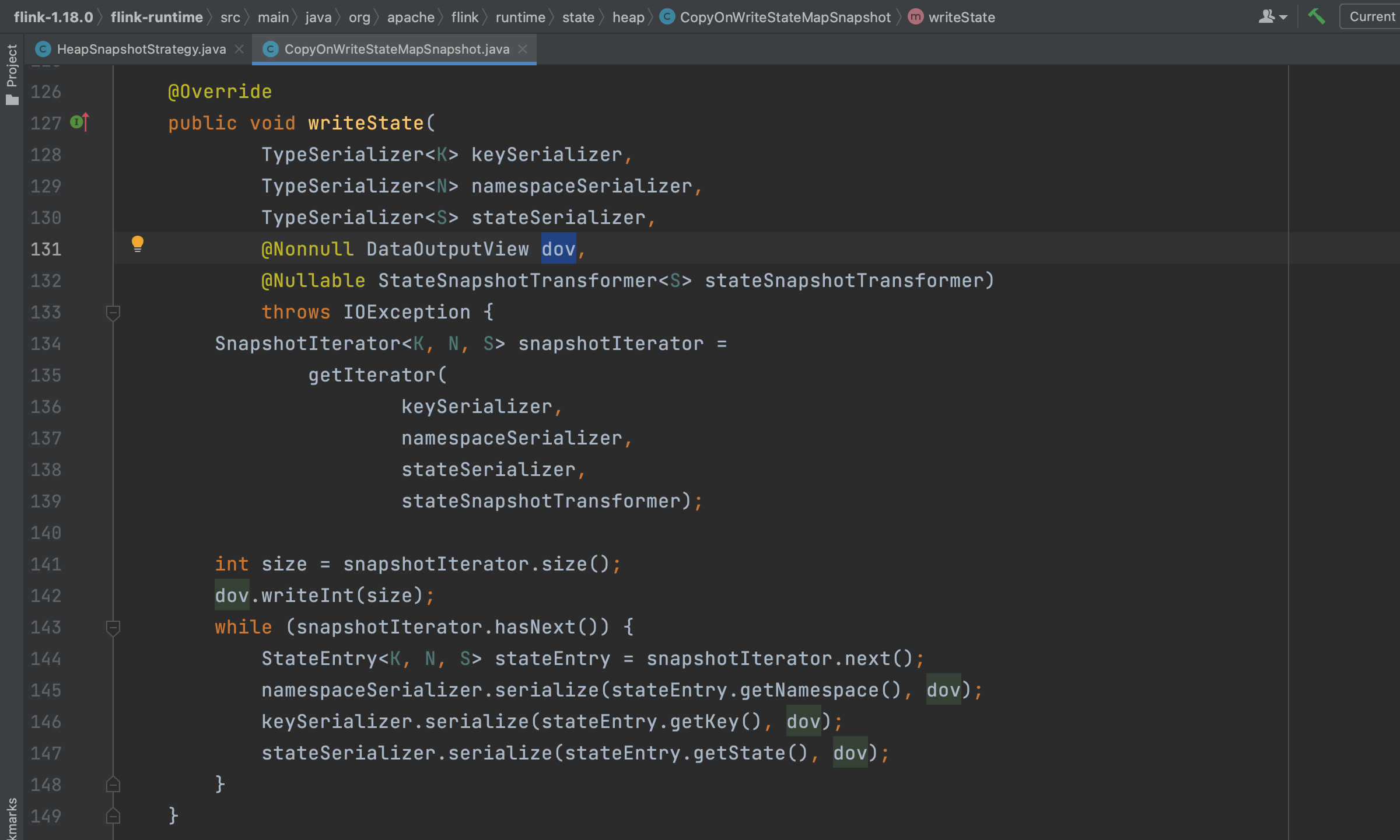
(4)、Checkpoint元数据返回
Flink系统将所有分组状态数据写完后紧接着收集Checkpoint元数据信息并返回。收集的信息主要有:
1)、keyGroupRangeOffsets,包含每个keyGoup的状态数据在状态文件中的存储位置。
2)、文件大小及文件名称等信息。该元数据信息通过SnapshotResult<StreamStateHandle> result = streamWithResultProvider.closeAndFinalizeCheckpointStreamResult();调用返回。
三、OperatorState快照过程
OperatorState快照过程和KeyedState快照过程基本类似,但比KeyedState快照过程简单。后续会完善OperatorState快照实现过程。
遗留问题:Flink1.18.0版本,KeyedState快照过程中一个Task上多个key数据对应一个连续keyGroup的keyGroupRange,key是怎么对应到分组范围内具体的keyGroup的。
