
Flink源码解析(二十) ——Checkpoint过程解析(上)
一、Flink系统Checkpoint机制简述
1、Checkpoint机制是Flink流式应用容错的保证。Flink系统通过周期性触发Checkpoint动作通知流作业中各个算子将自身的状态数据持久化存储下来。当作业重新运行时选择以往成功的Checkpoint快照数据来恢复各个算子停止前的状态数据,读取新的数据继续执行作业逻辑,避免数据丢失、重复。
2、Flink Checkpoint机制的四种不同程度的可靠性保证:
(1)、最多一次(At-Most-Once):数据最多处理一次,不会重复处理,但可能会丢失。Flink不开启Checkpoint机制时就是最多一次数据处理保证。
(2)、最少一次(At-Least-Once):数据可能会重复处理,但不会丢失。Flink作业开启Checkpoint机制但不进行Barrier对齐时就是最少一次数据处理保证。
(3)、引擎内严格一次(Exactly-Once):数据不重复、不丢失。当Flink作业开启Checkpoint机制并且进行Barrier对齐时就能达到引擎内严格一次的数据处理保证。如果数据源支持断点读取,如Kafka通过从特定位点读取数据功能,则Flink能支持从数据源到引擎处理完毕,再写出到外部存储之前的过程中的严格一次。
(4)、端到端严格一次:从数据读取、引擎处理再到写入外部存储的整个过程,数据不重复、不丢失。端到端严格一次需要数据源支持断点读取、外部存储支持事务机制,能够进行回滚操作。Flink系统通过两阶段提交协议提供框架级别的支持端到端严格一次语义。即TwoPhaseCommitSinkFunction类实现体系。
3、检查点执行过程简述:
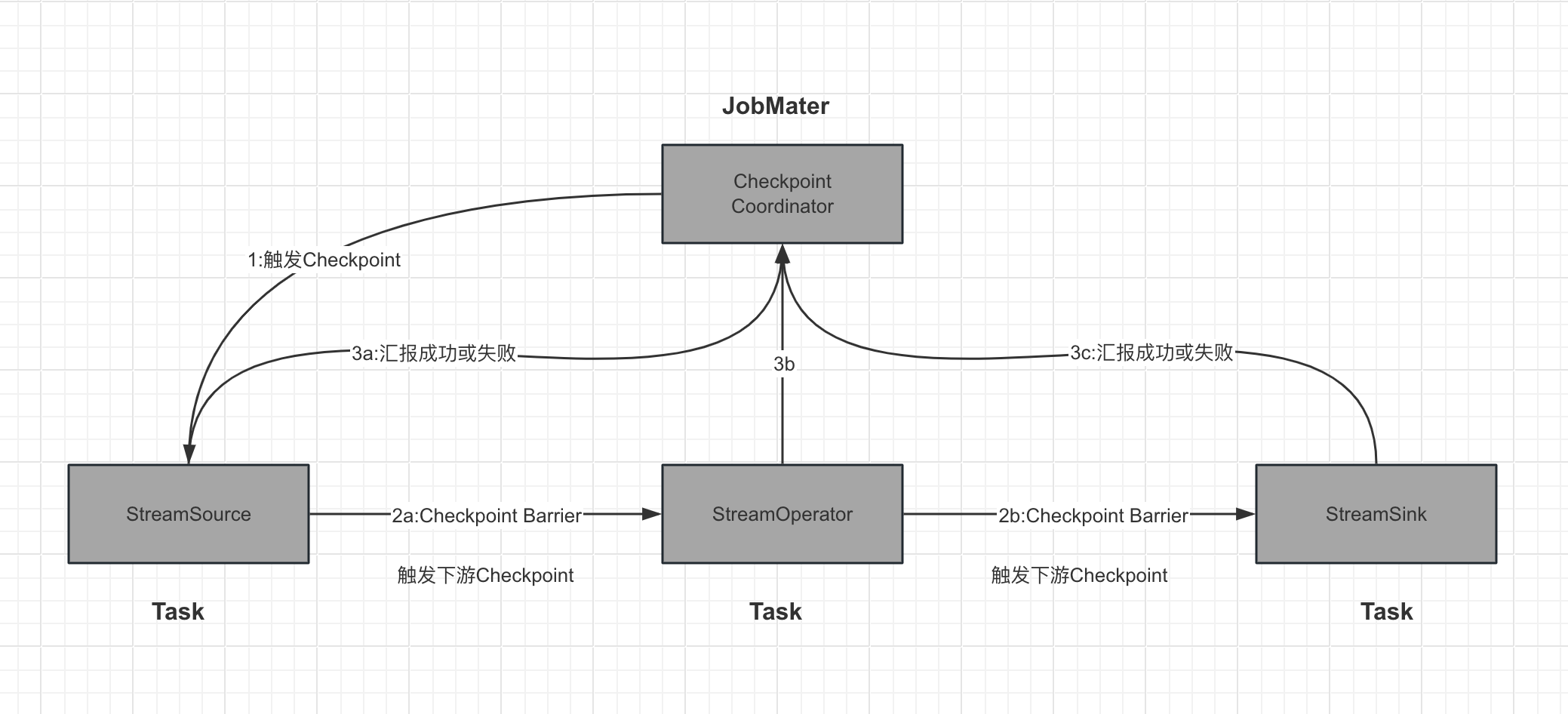
(1)、JobMaster触发Checkpoint
JobMaster开始调度作业时会为作业提供一个CheckpointCoordinator组件,该组件周期性通知Source Task产生CheckpointBarrier事件,注入数据流中,混合数据事件被下游算子截获并触发Checkpoint行为。
(2)、TaskExecutor执行Checkpoint
JobMaster通过TaskManagerGateway触发TaskManager的检查点行为,TaskManager则转交给Task执行。
(3)、Task上报Checkpoint完成
当一个算子完成状态持久化后会向JobMaster发送Checkpoint完成消息。
(4)、JobMaster确认Checkpoint
JobMaster通过调度器ScheduerNG组件通知算子Checkpoint完成事件后的commit动作。
二、Flink系统Checkpoint执行过程
随笔九介绍ExecutionGraph生成时提到当isCheckpointingEnabled(jobGraph);为true时会设置ExecutionGraph的Checkpoint信息。本篇随笔就从此处开始讲解Flink系统Checkpoint执行过程。
1、JobMaster触发Checkpoint
(1)、首先讲解下Checkpoint初始化过程,CheckpointCoordinatorConfiguration包含了Checkpoint执行间隔、执行超时、两次Checkpoint之间最小停顿时长、最大并发Checkpoint次数等Checkpoint执行配置信息。

enableCheckpoint(...)方法主要作用是创建CheckpointCoordinator组件,深挖isCheckpointingEnabled(...)方法会发现不管Flink作业有没有设置checkpoint,都会执行enableCheckpoint(...)方法,都会新建创建CheckpointCoordinator组件。

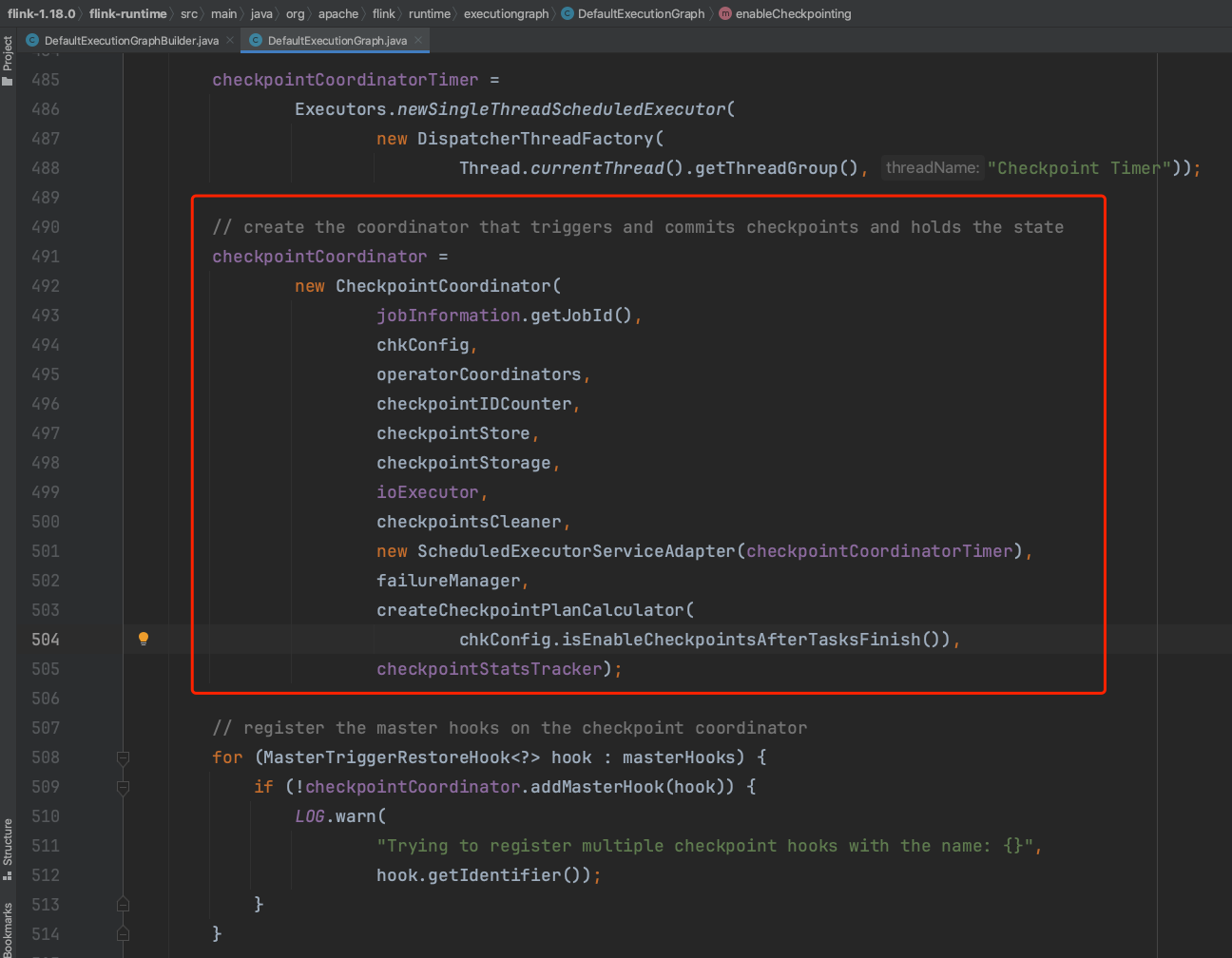
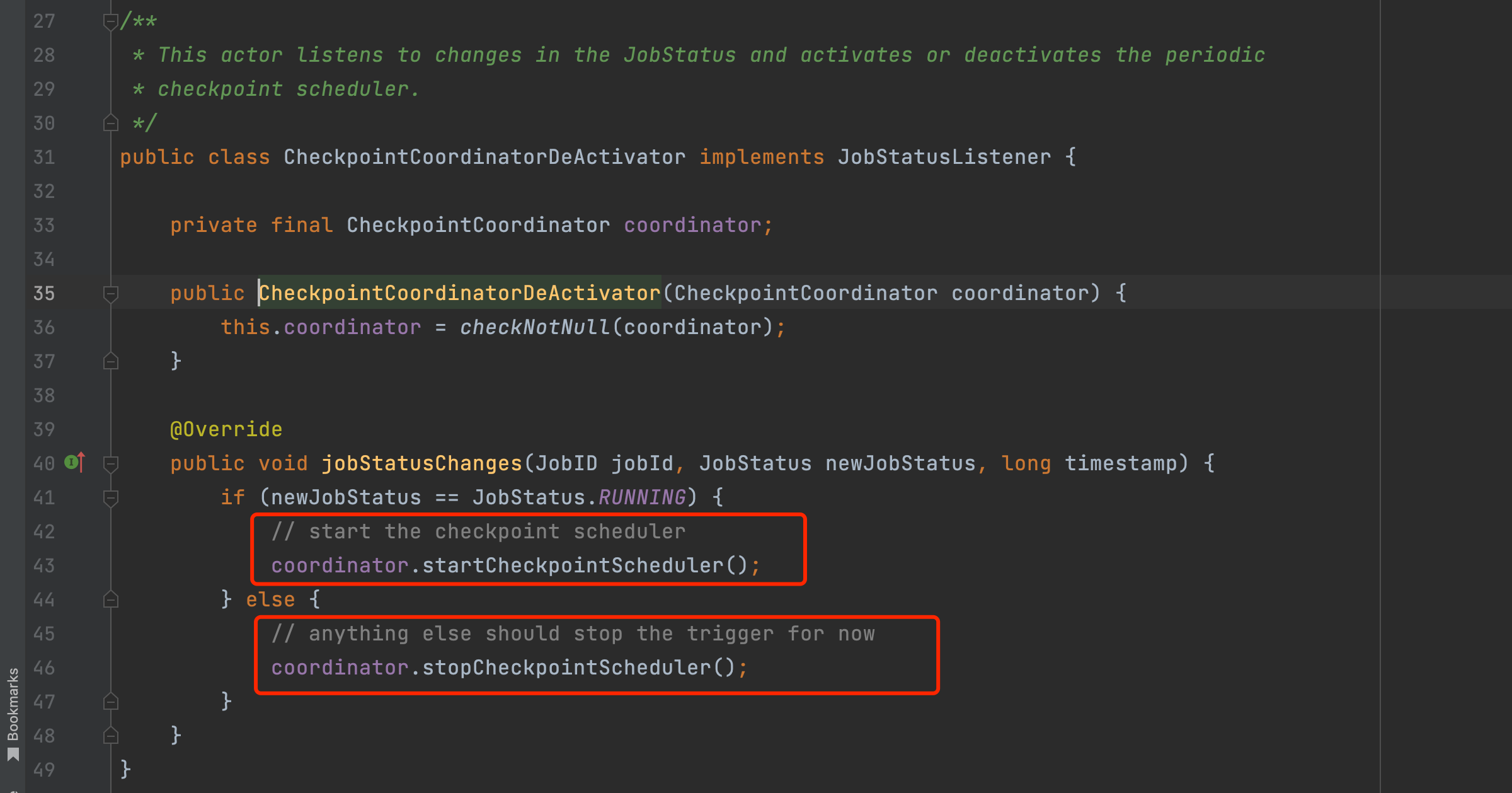
在组件CheckpointCoordinator创建完成后,如果Flink作业配置了周期性Checkpoint行为,则组件CheckpointCoordinator为Flink作业添加一个CheckpointCoordinatorDeActivator监听器,该监听器负责启动和停止Checkpoint动作。
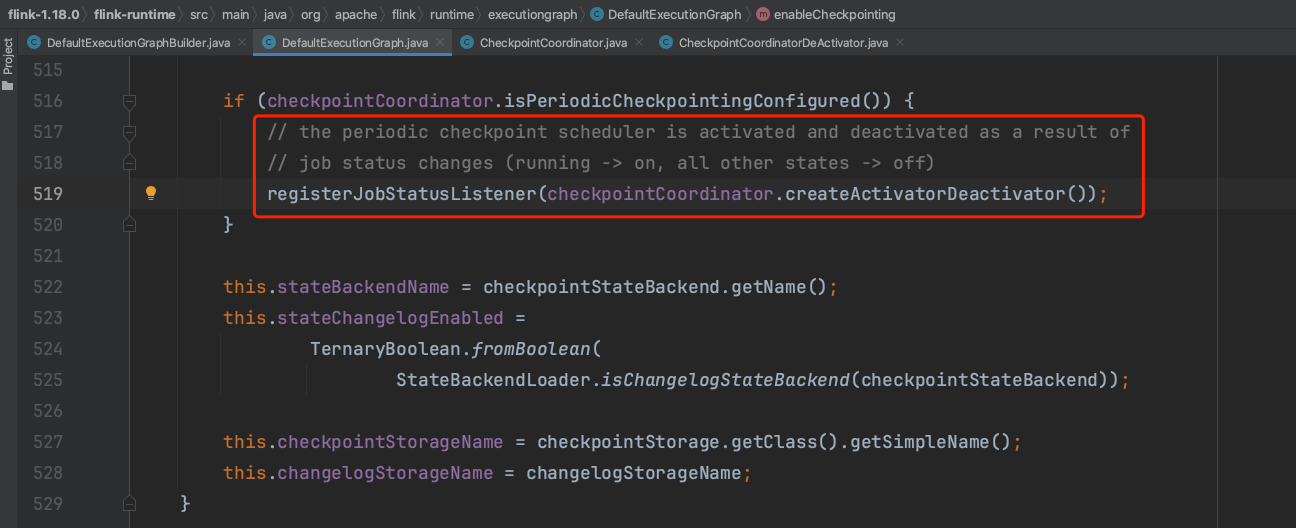
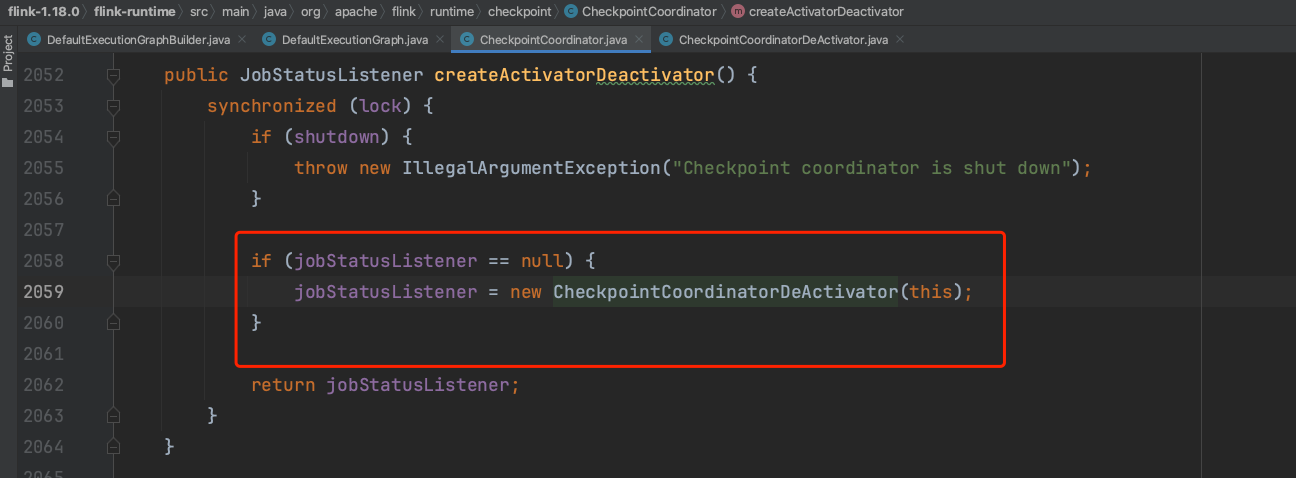
监听器CheckpointCoordinatorDeActivator监听Flink作业的运行状态,如果作业处于运行状态时则周期性触发Checkpoint动作,其他状态则停止Checkpoint动作。
以上是初始化操作,下面解析触发调度操作。
(2)、Checkpoint触发过程。
当Flink作业开始调度时,系统将Flink作业状态设置为RUNNING状态。由上一小节可知,Flink作业处于RUNNING状态时组件CheckpointCoordinatorDeActivator会触发Checkpoint调度开始动作。
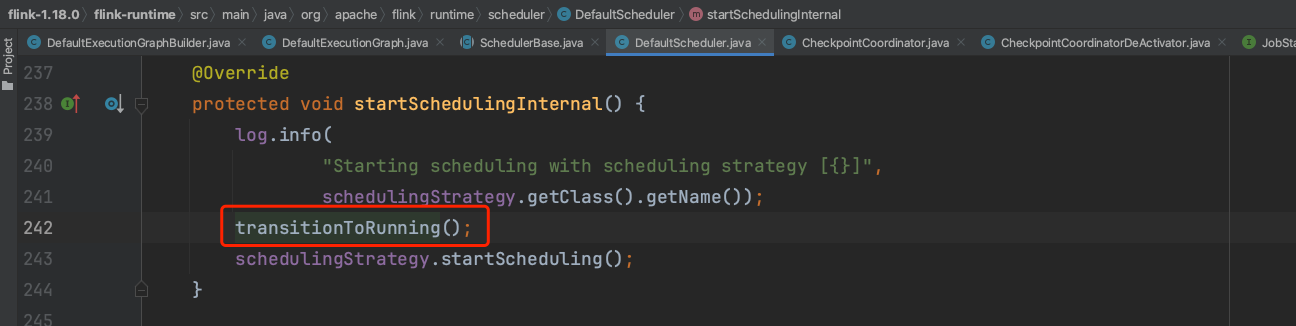

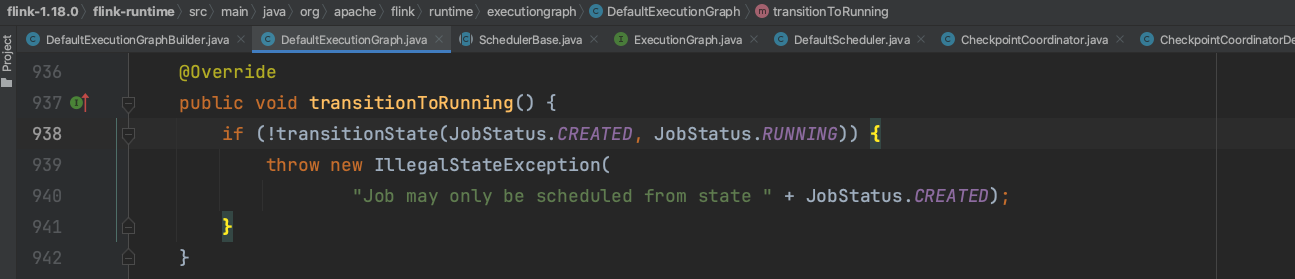
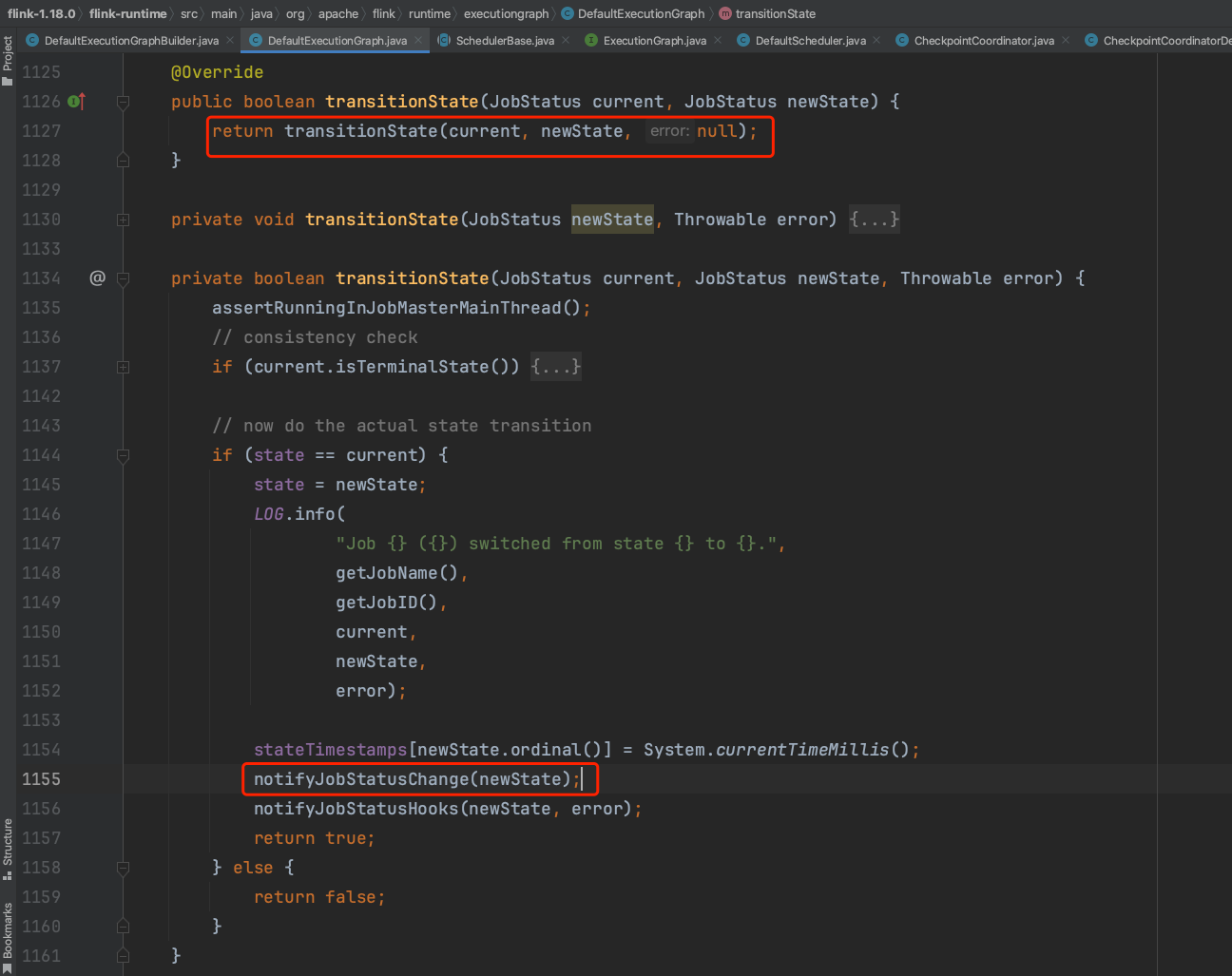
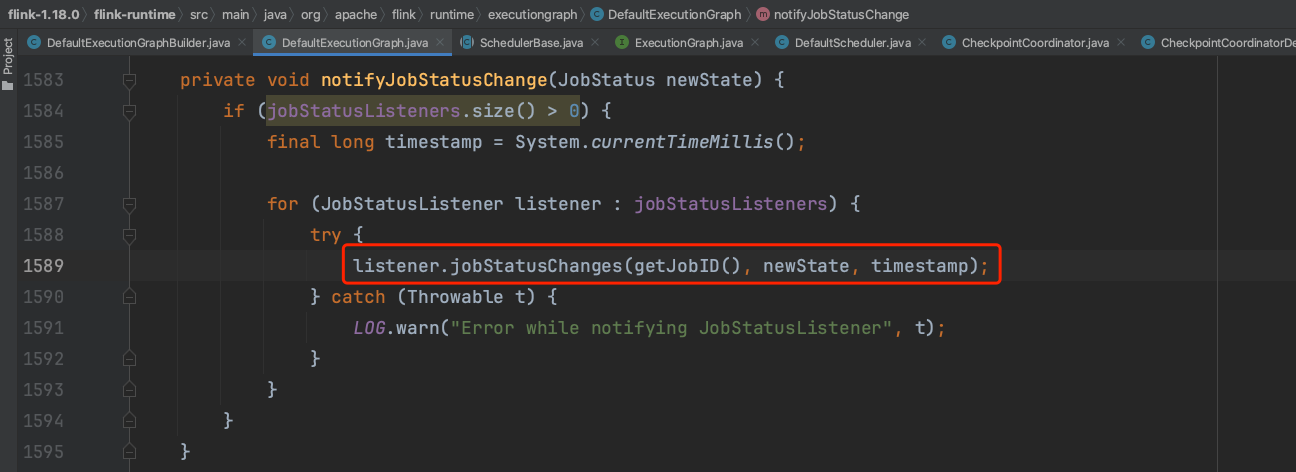
组件CheckpointCoordinatorDeActivator触发Checkpoint调度开始动作。

CheckpointCoordinatorCheckpointCoordinator.startCheckpointScheduler()方法中周期性执行Runnable实现类ScheduledTrigger()逻辑。



triggerCheckpoint(...)方法中创建并选择可执行的CheckpointTriggerRequest实例,交由方法startTriggeringCheckpoint(...)处理。判断CheckpointTriggerRequest实例可执行的条件有多个,主要包括判断最大并行Checkpoint数量、两次Checkpoint最小间隔、当前状态、是否强制执行等。可参考chooseRequestToExecute(...)方法。
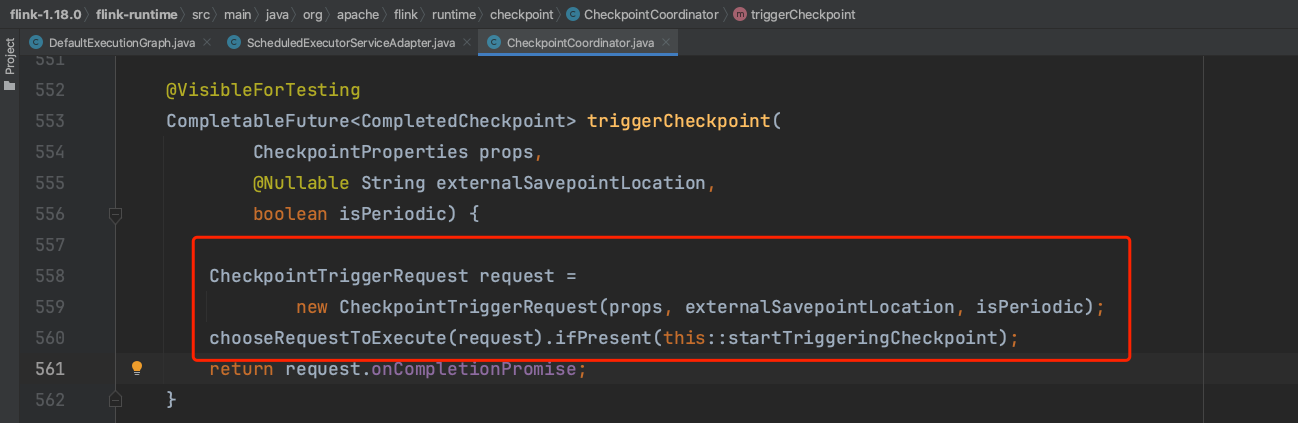
当满足Checkpoint执行条件后,进入startTriggeringCheckpoint(...)方法执行,该方法主要包含以下主要步骤
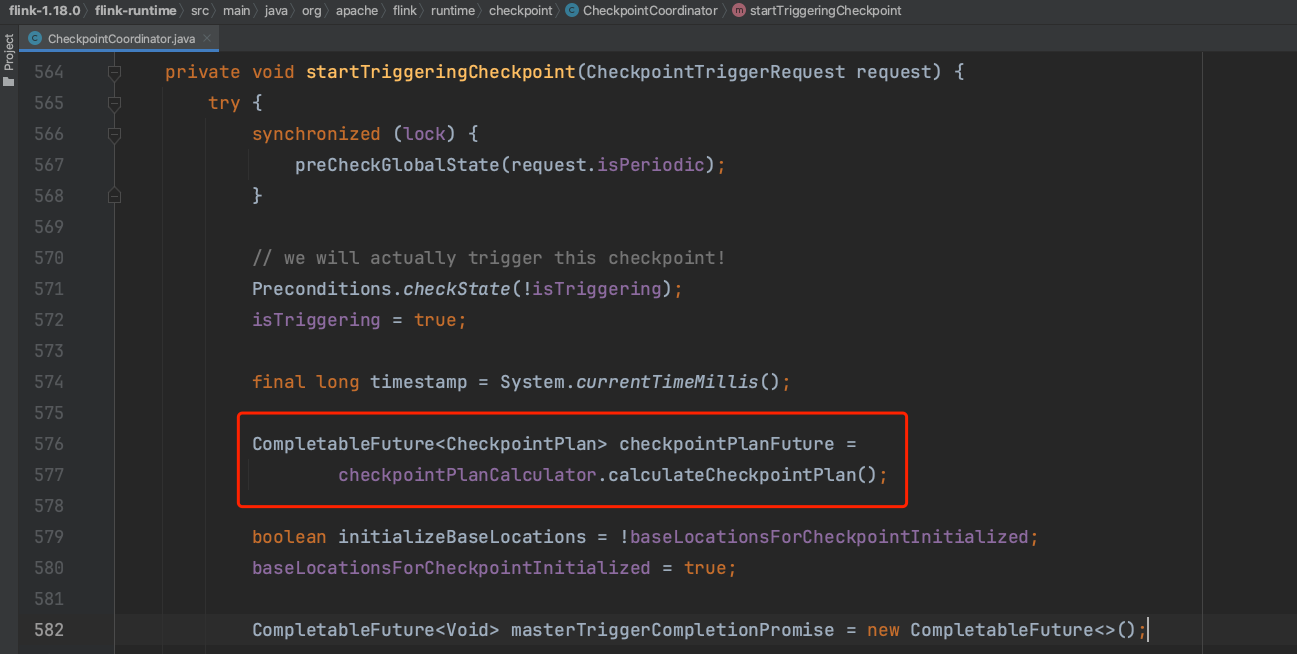
1)、计算Checkpoint执行计划,判断要产生CheckpointBarrier事件的Task即所有的Source Task,要等待及提交Checkpoint完成消息的Task,通常是Flink作业所有的Task。
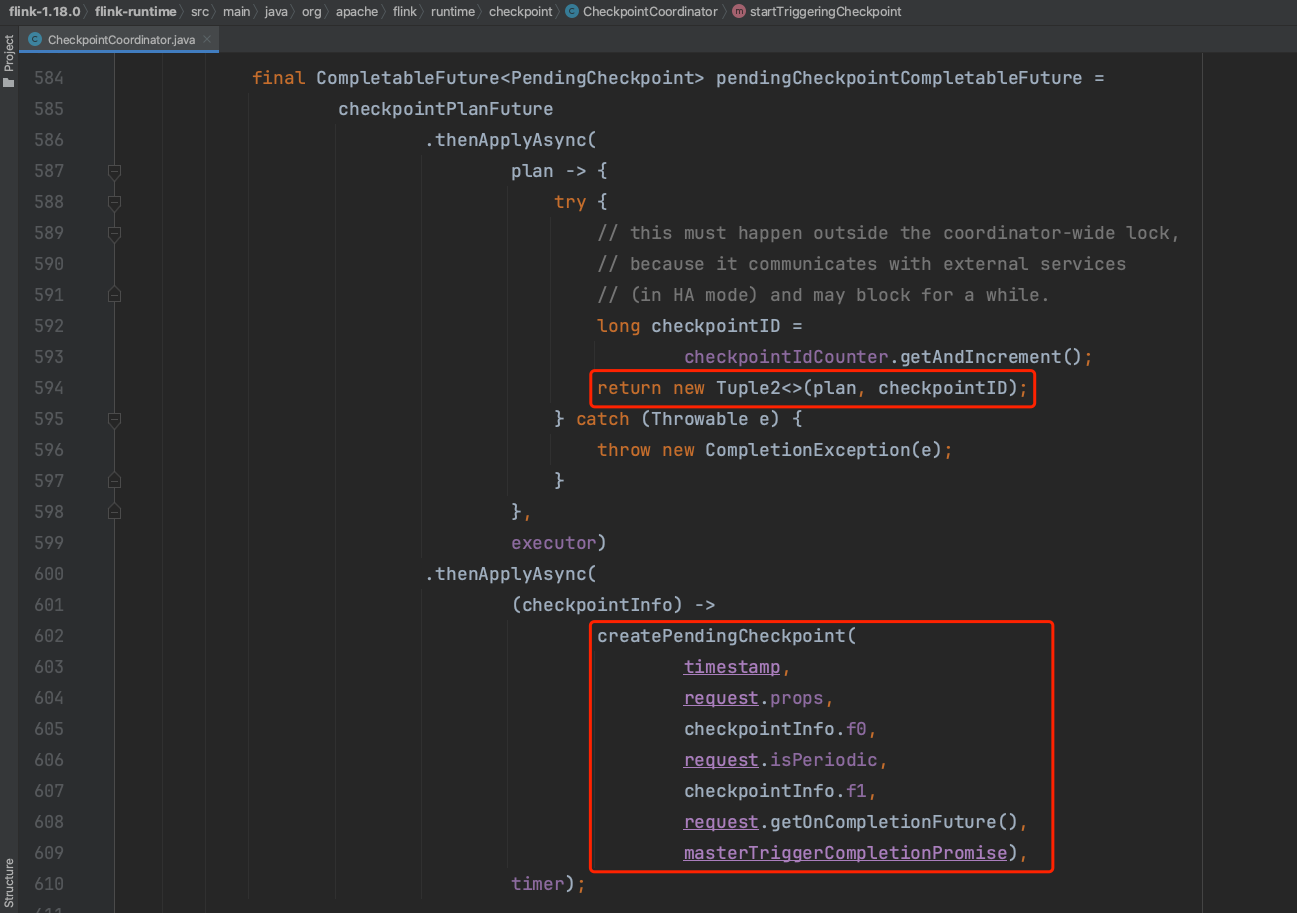
2)、为每一个Checkpoint执行计划生成从0自增的CheckpointID,并创建PendingCheckpoint实例。
3)、创建Checkpoint状态数据的存储目录。OperatorCoordinator本身不直接参与Checkpoint的生成和持久化,但它可能会参与状态的管理和协调(例如,确保所有相关的状态更新都被正确处理等。
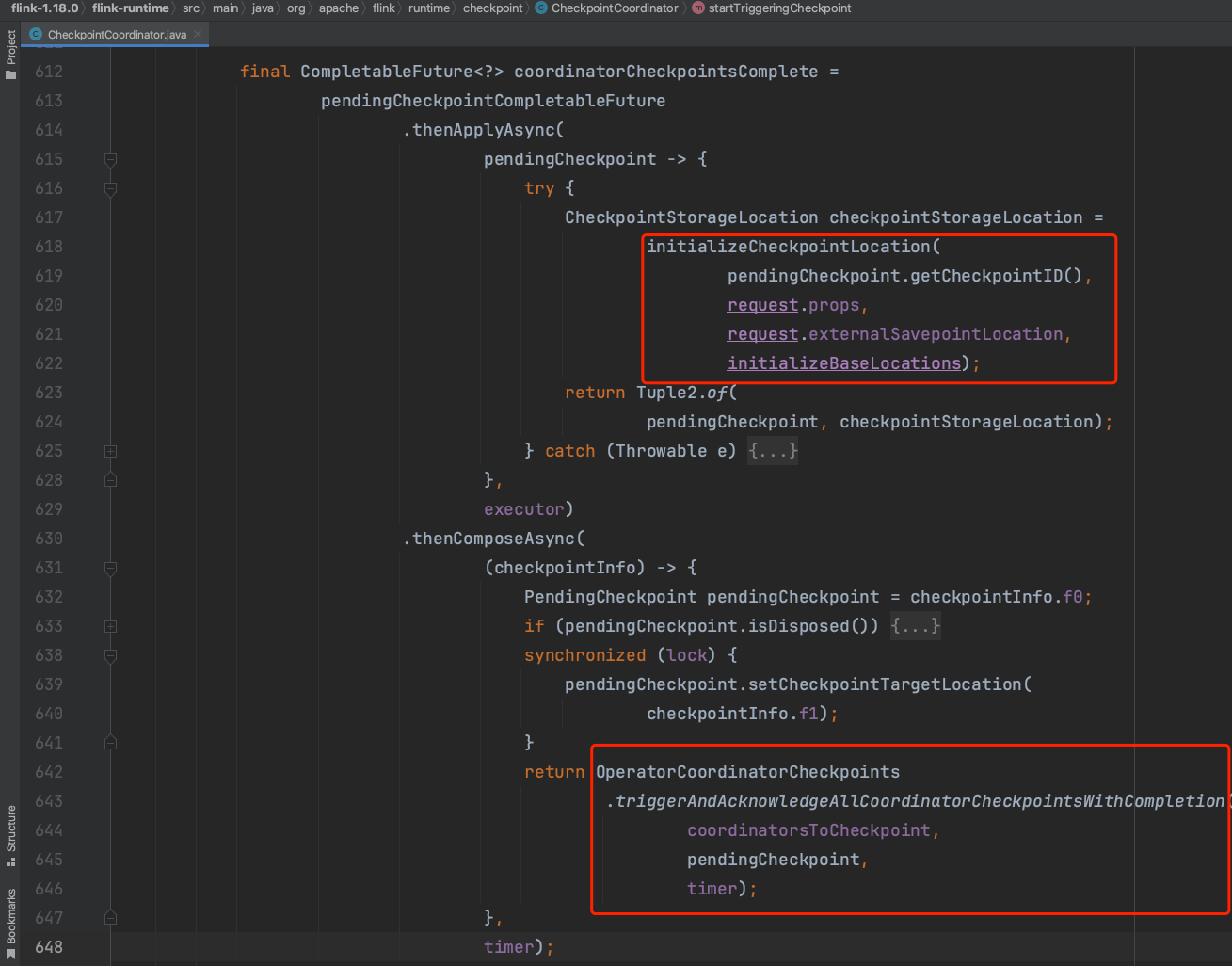

4)、triggerCheckpointRequest(...)方法遍历每个Source Task,产生CheckpointBarrier消息。
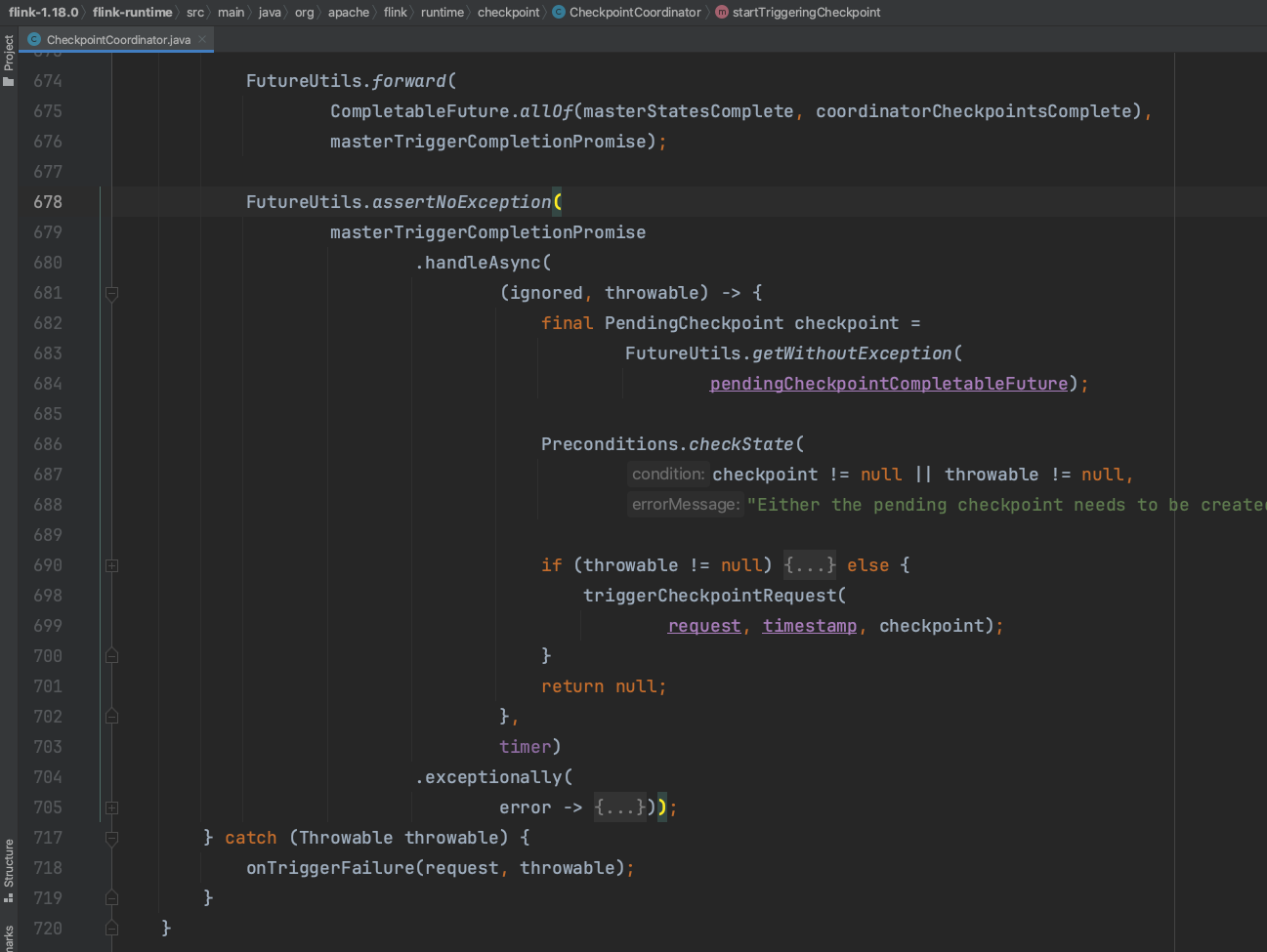
以上是方法startTriggeringCheckpoint(...)4个主要步骤,下面详细解析每个步骤。
下图可知方法calculateCheckpointPlan()先检查所有Task是否都已完成初始化动作,接着构造Checkpoint执行计划。
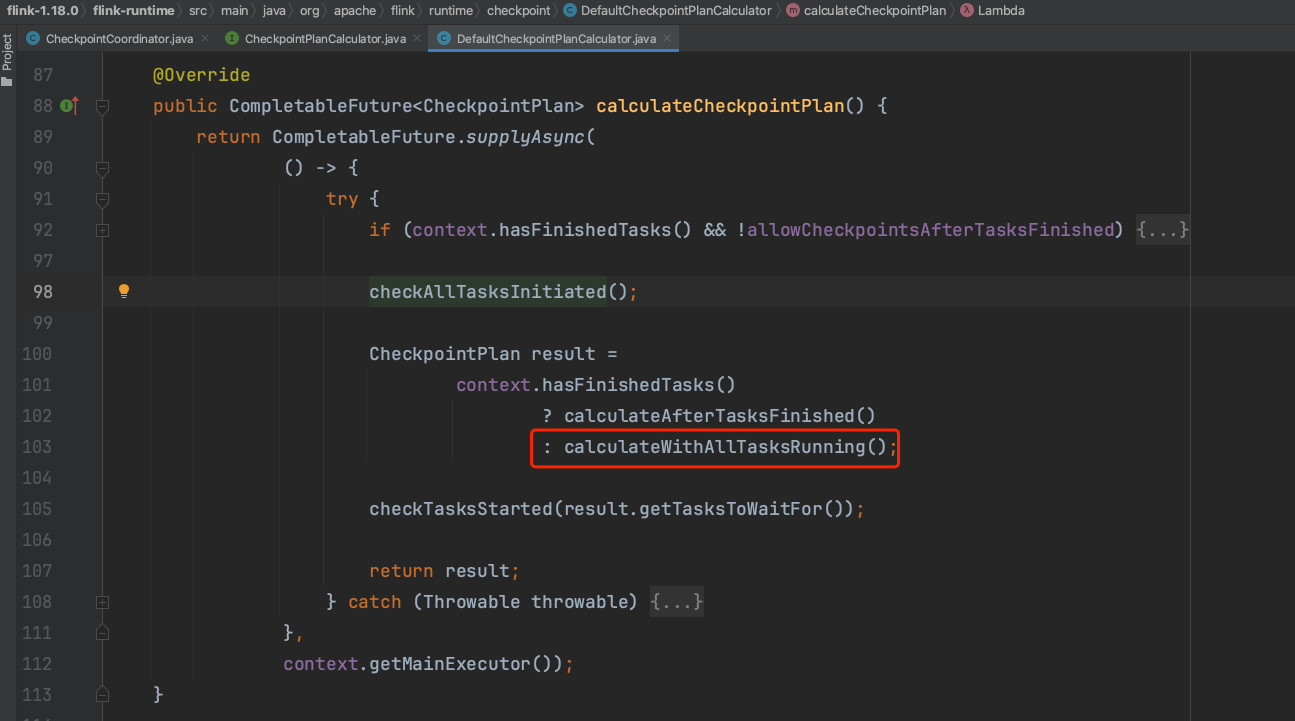
Checkpoint执行计划中tasksToTrigger集合代表要产生CheckpointBarrier消息的Task,即所有的Source Task。tasksToWaitFor集合代表需要等待确认Checkpoint成功完成的Task集合,一般是所有的Task。tasksToCommitTo集合代表需要提交Checkpoint消息的集合,一般也是所有的Task。

createPendingCheckpoint(...)方法负责创建PendingCheckpoint实例,代表JobMaster端Pending状态的Checkpoint,处于等待Checkpoint执行完成的状态。包含Checkpoint时间、CheckpointID、执行计划等。为每一个PendingCheckpoint注册一个超时取消器,执行超时后及时取消Checkpoint。


triggerCheckpointRequest(...)方法遍历tasksToWaitFor集合,触发Execution.triggerCheckpoint(...)方法执行。每个Source Task都要产生CheckpointBarrier消息。

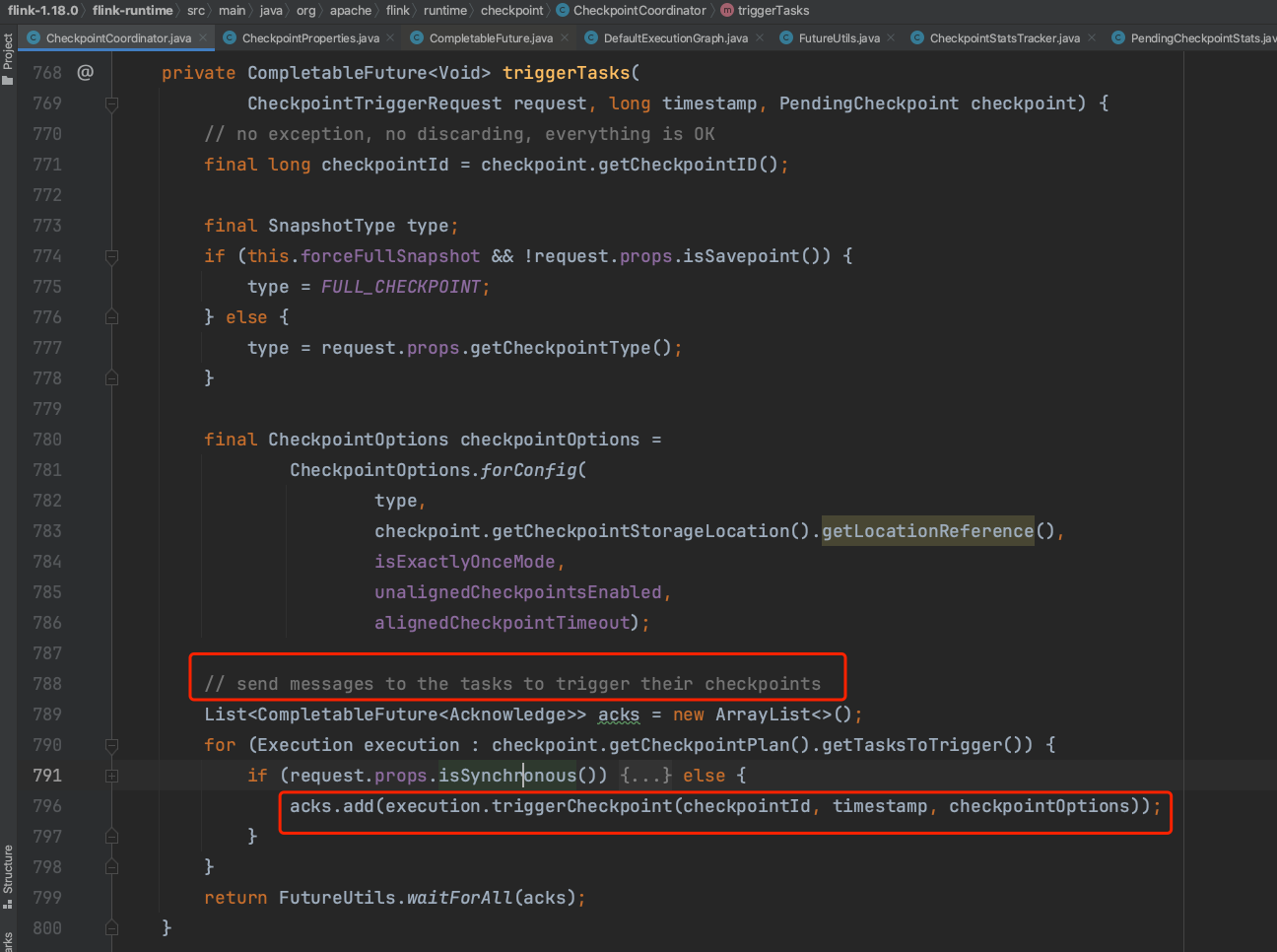
每个Execution里都持有一个RpcTaskManagerGateway远程过程调用入口,通过此RPC组件远程调用TaskExecutor.triggerCheckpoint(...)方法来执行Task上的Checkpoint操作。
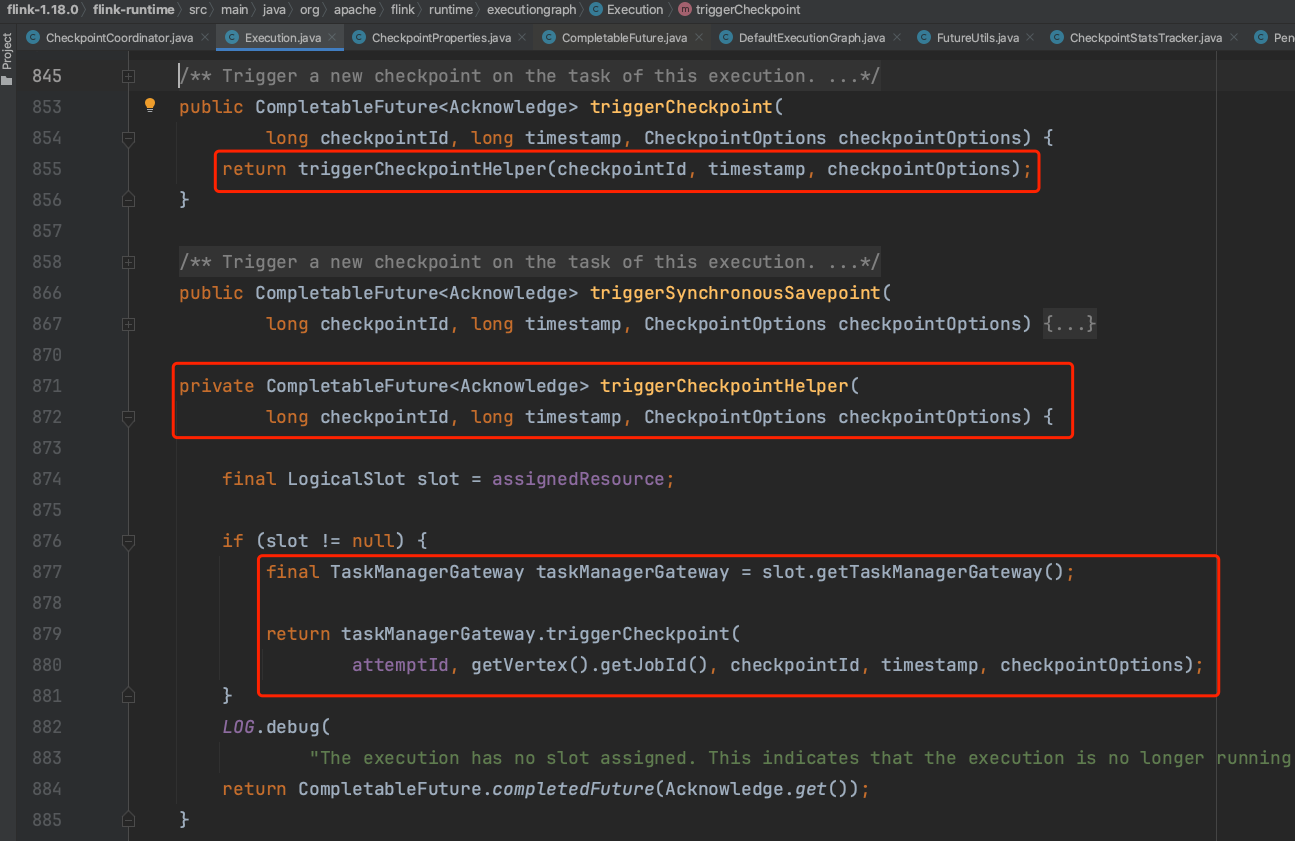

以上即为JobMaster端触发Checkpoint过程,下面继续讲解TaskExecutor上Task执行Checkpoint过程。
2、TaskExecutor执行Checkpoint
一个TaskExecutor节点一般会对应多个Task实例,需要通过ExecutionAttemptID找到特定的Task来执行Checkpoint操作,如下图所示。
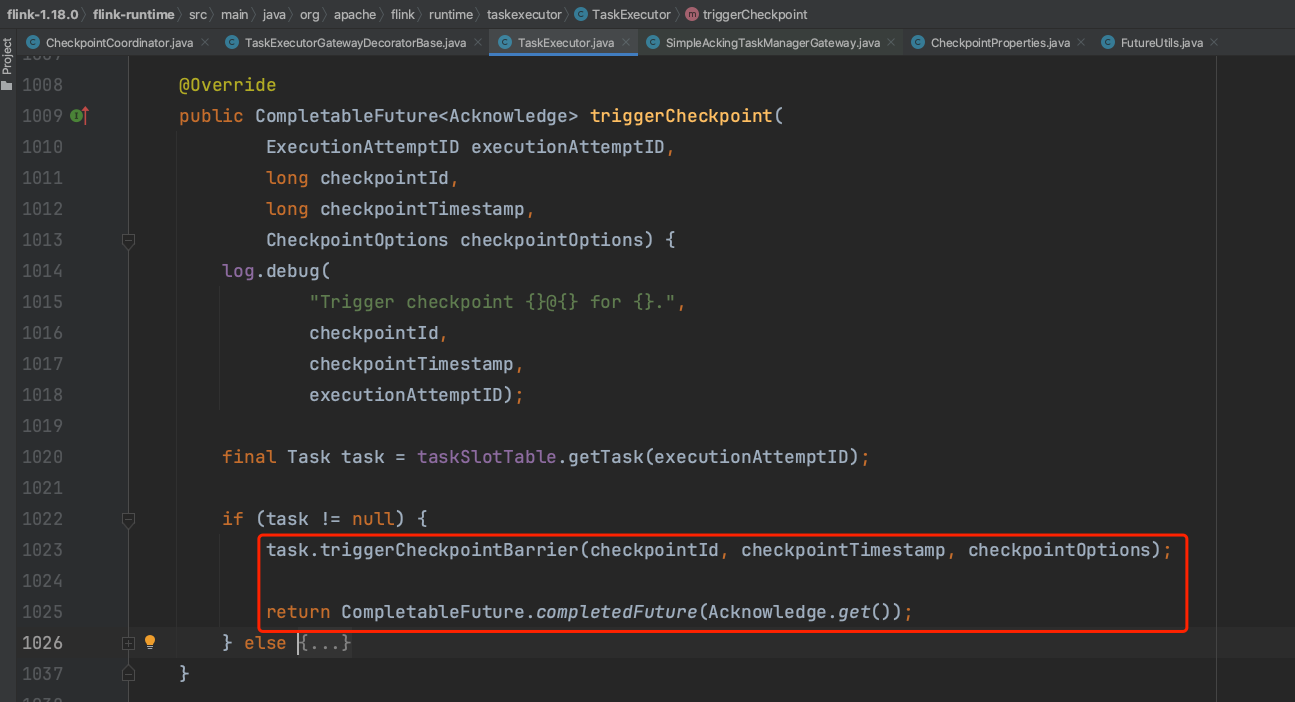
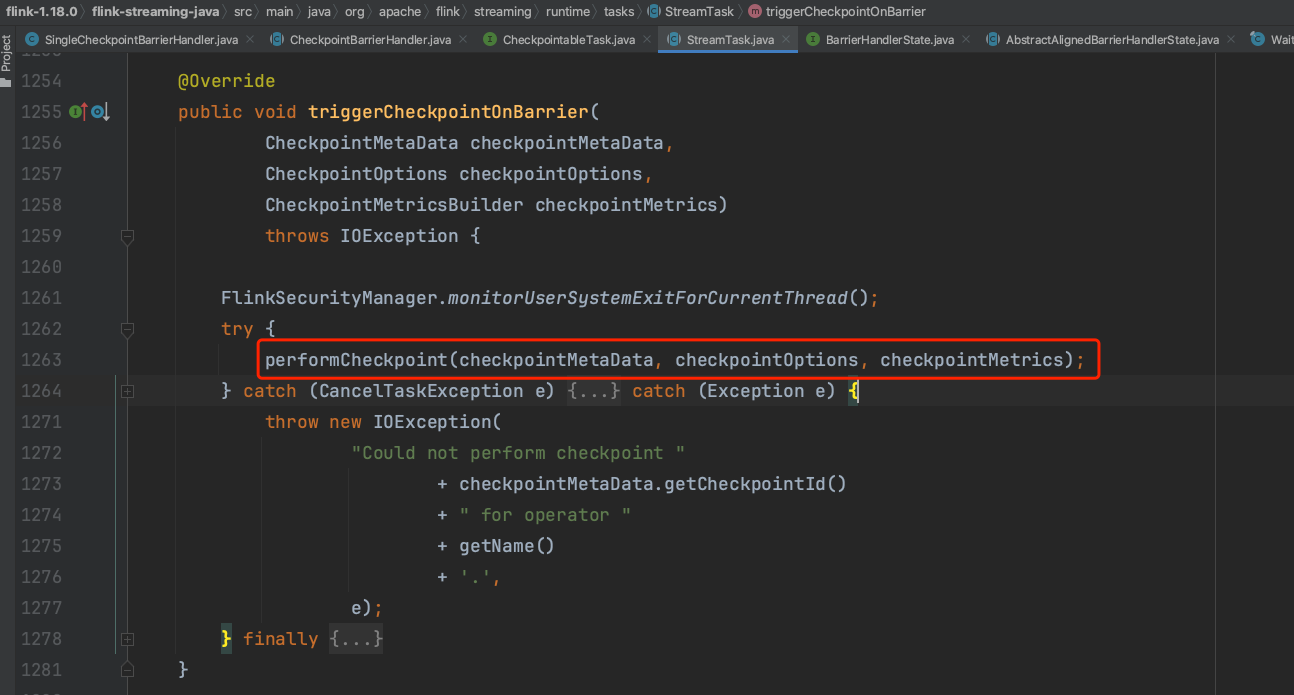
进入到Task.triggerCheckpointBarrrier(...)方法,当前Task处于RUNNING状态且TaskInvokable类型是SourceStreamTask。
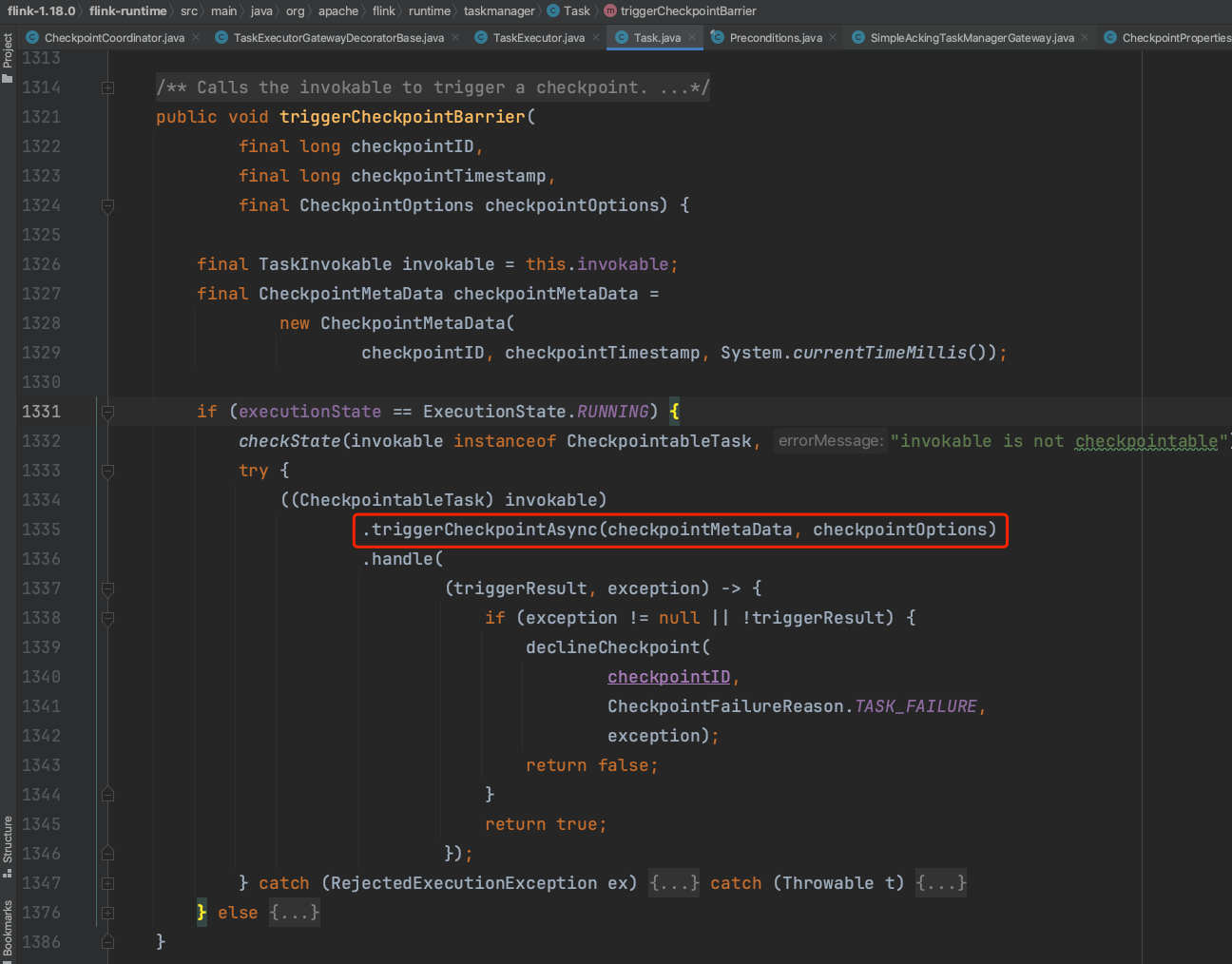
子类SourceStreamTask.triggerCheckpointAsync(...)方法会调用父类StreamTask.triggerCheckpointAsync(...)方法触发Checkpoint执行。

借助方法StreamTask.triggerCheckpointAsync(...)转入到方法StreamTask.triggerCheckpointAsyncInMailbox(...)中。
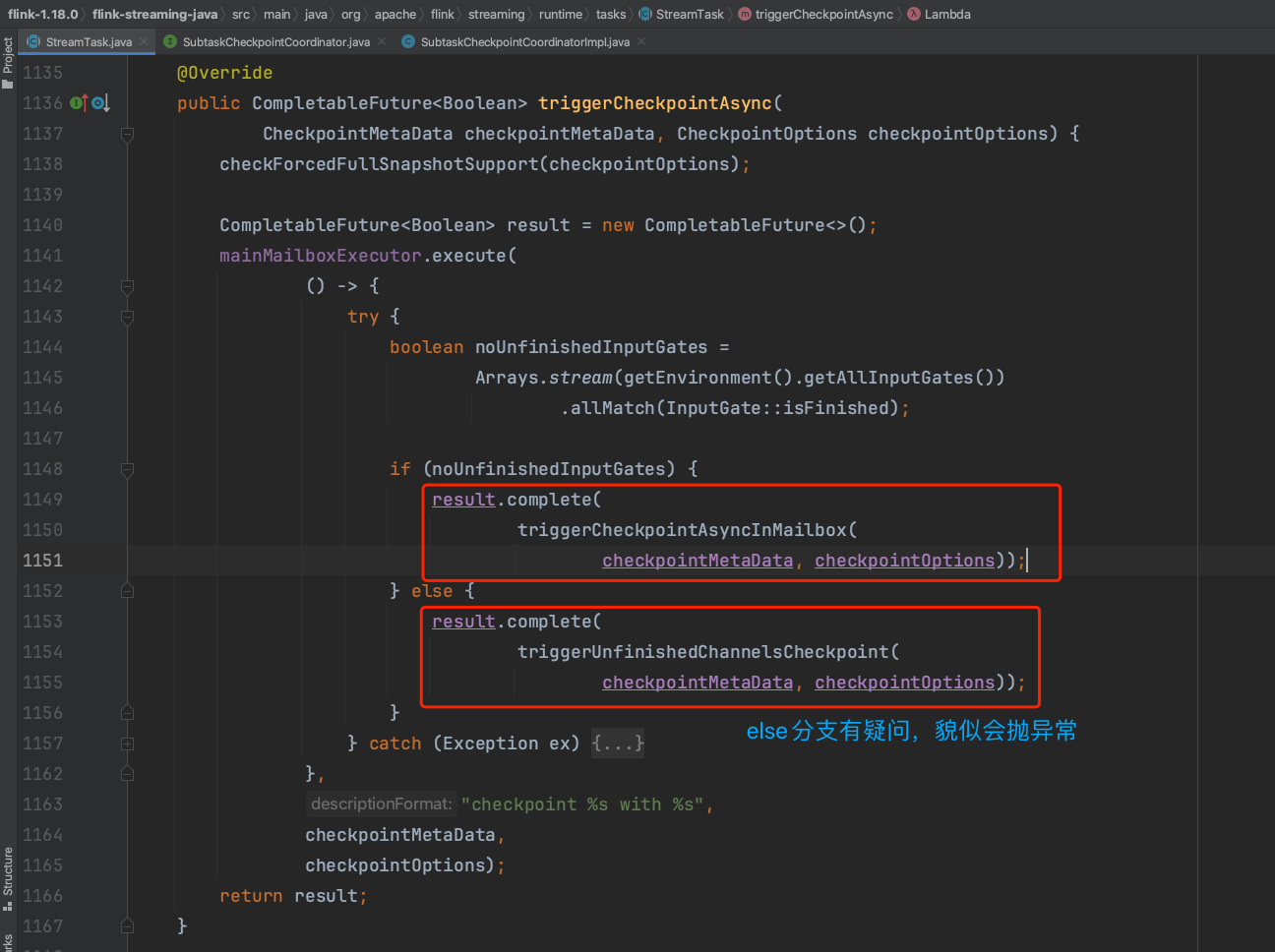
checkpoint状态数据在写入之前需要调用SubtaskCheckpointCoordinatorImpl.initInputCheckpoint(...)方法做一些初始化的动作。
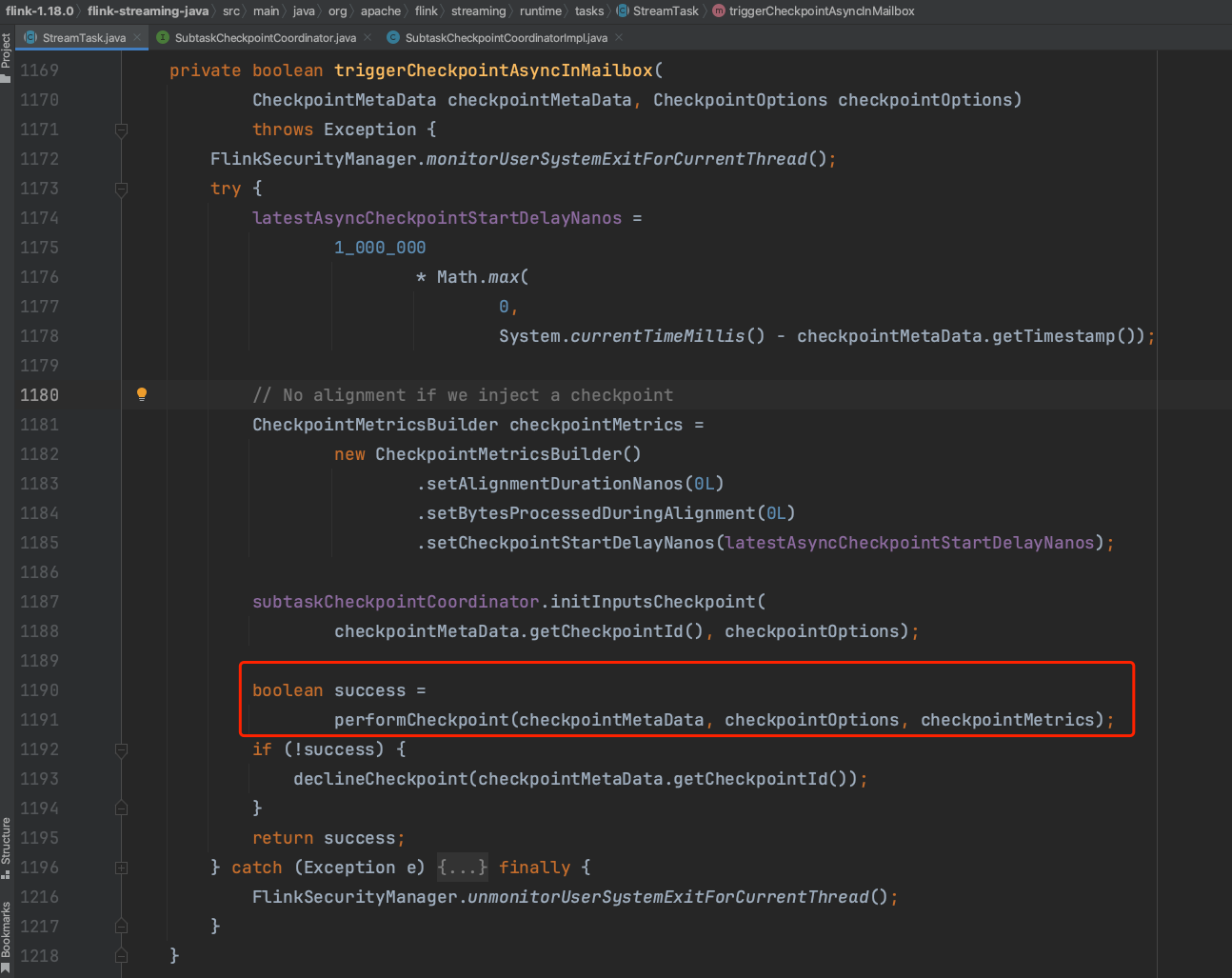
初始化动作之后StreamTask借助SubtaskCheckpointCoordinatorImpl开始执行Checkpoint操作。

在正式的Checkpoint执行过程中,主要有三个步骤:
1)、operatorChain.prepareSnapshotPreBarrier(metadata.getCheckpointId()),在Checkpoint之前算子可以做一些准备工作,该步骤在通常情况下是一个空实现,不做什么具体操作。
2)、马上向下游广播CheckpointBarrier消息,使下游Task尽快接收到CheckpointBarrier消息并开始Checkpoint操作。
3)、写入真实快照状态数据即Checkpoint操作。



prepareSnapshotPreBarrier(...),在Checkpoint之前算子可以做一些准备工作,该步骤在通常情况下是一个空实现,不做什么具体操作。
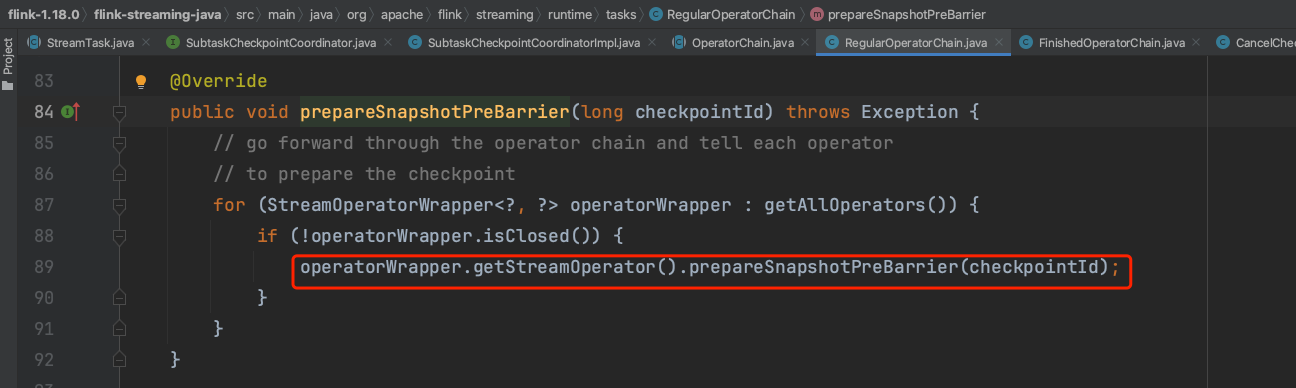

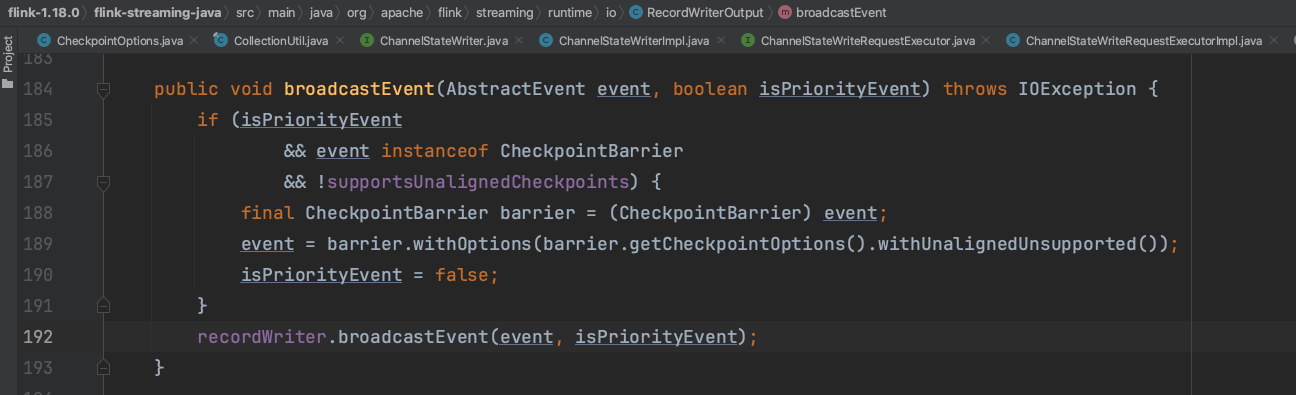
Source Task新建CheckpointBarrier消息并广播发送消息到下游Task。相邻Checkpoint之间的数据通过两次CheckpointBarrier消息去界限。


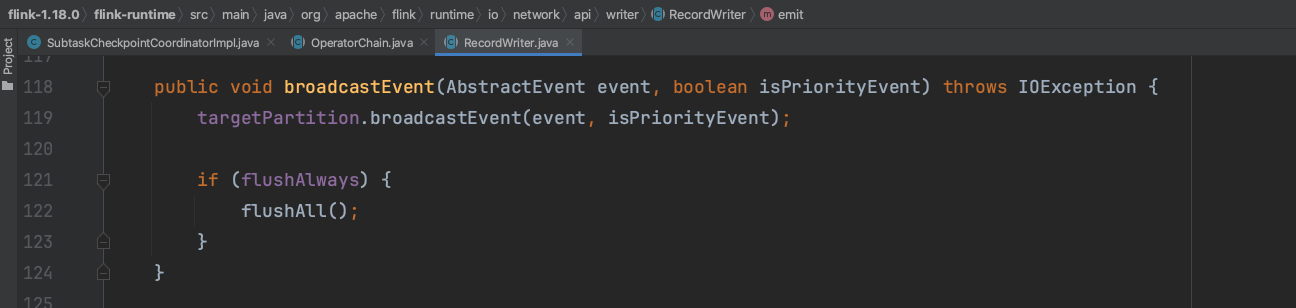
Flink系统使用随笔十七介绍的RecordWriterOutput、RecordWriter、ResultPartition、ResultSubpartition组件将CheckpointBarrier消息广播到下游Task。
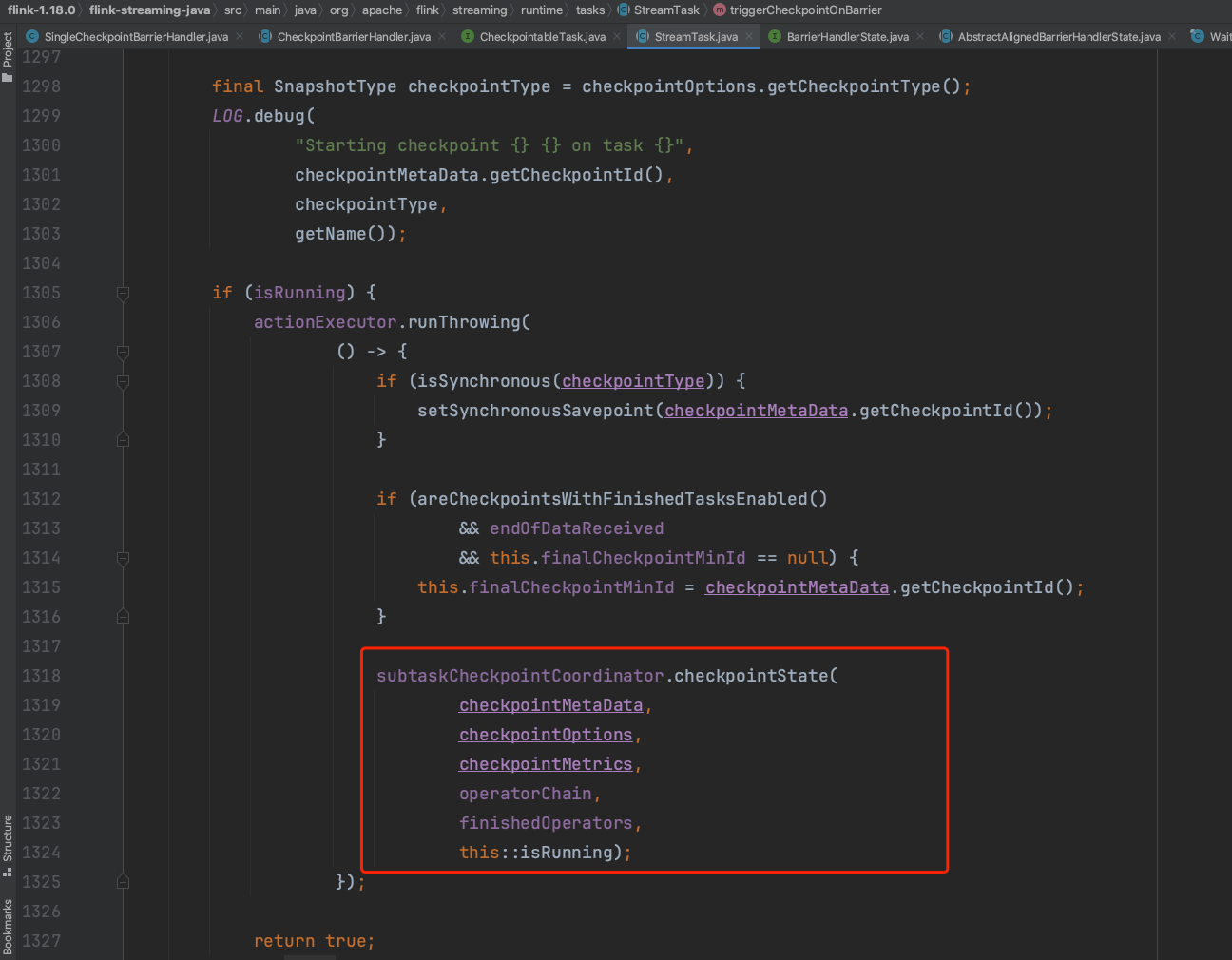
异步执行Checkpoint操作,方法takeSnapshotSync(...)负责为每个算子创建状态数据写入操作的OperatorSnapshotFutures数据结构,该数据结构包含4个具体RunnableFuture异步执行动作,分别为:托管KeyedState写入动作keyedStateManagedFuture、原始KeyedState写入动作keyedStateRawFuture、托管算子状态写入动作operatorStateManagedFuture、原始算子状态写入动作operatorStateRawFuture。这4个算子状态数据快照过程实现于RunnableFuture,具体的状态快照动作在run()方法中实现,通过get()方法可以获取执行结果SnapshotResult。
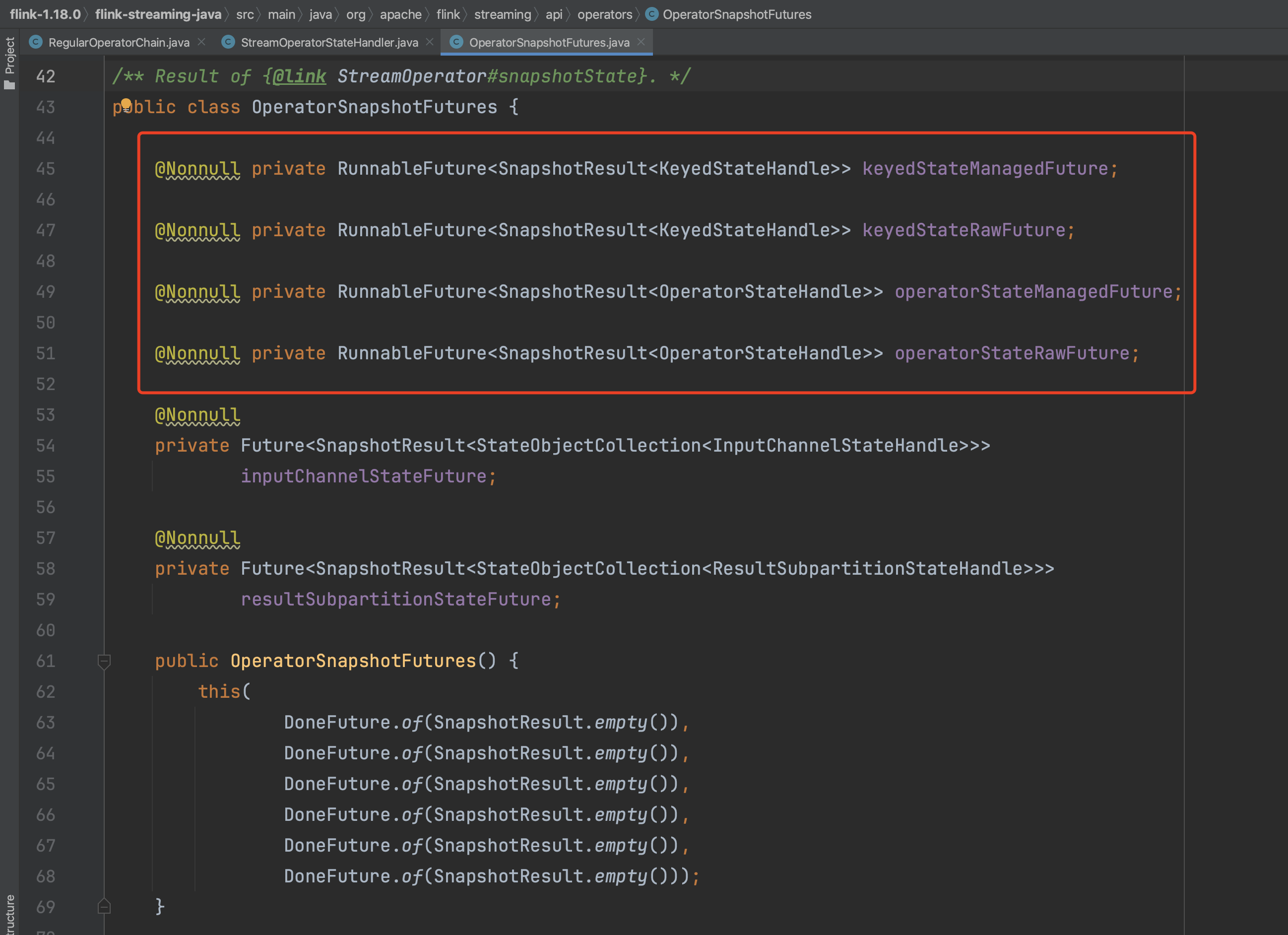
方法takeSnapshotSync(...)为每个算子创建状态数据写入操作的OperatorSnapshotFutures过程如下:
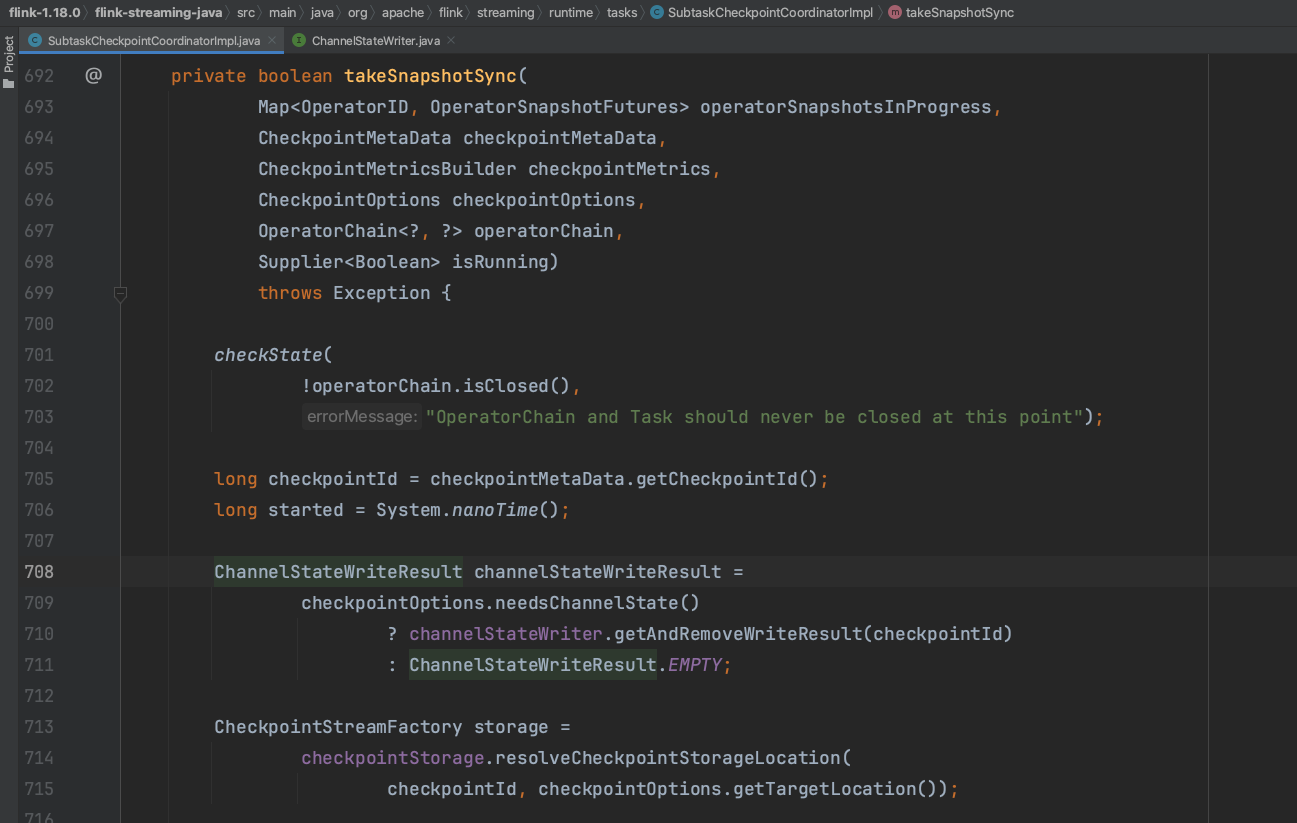
触发算子链方法snapshotState(...),依次为每个算子生成对应的OperatorSnapshotFutures结构。
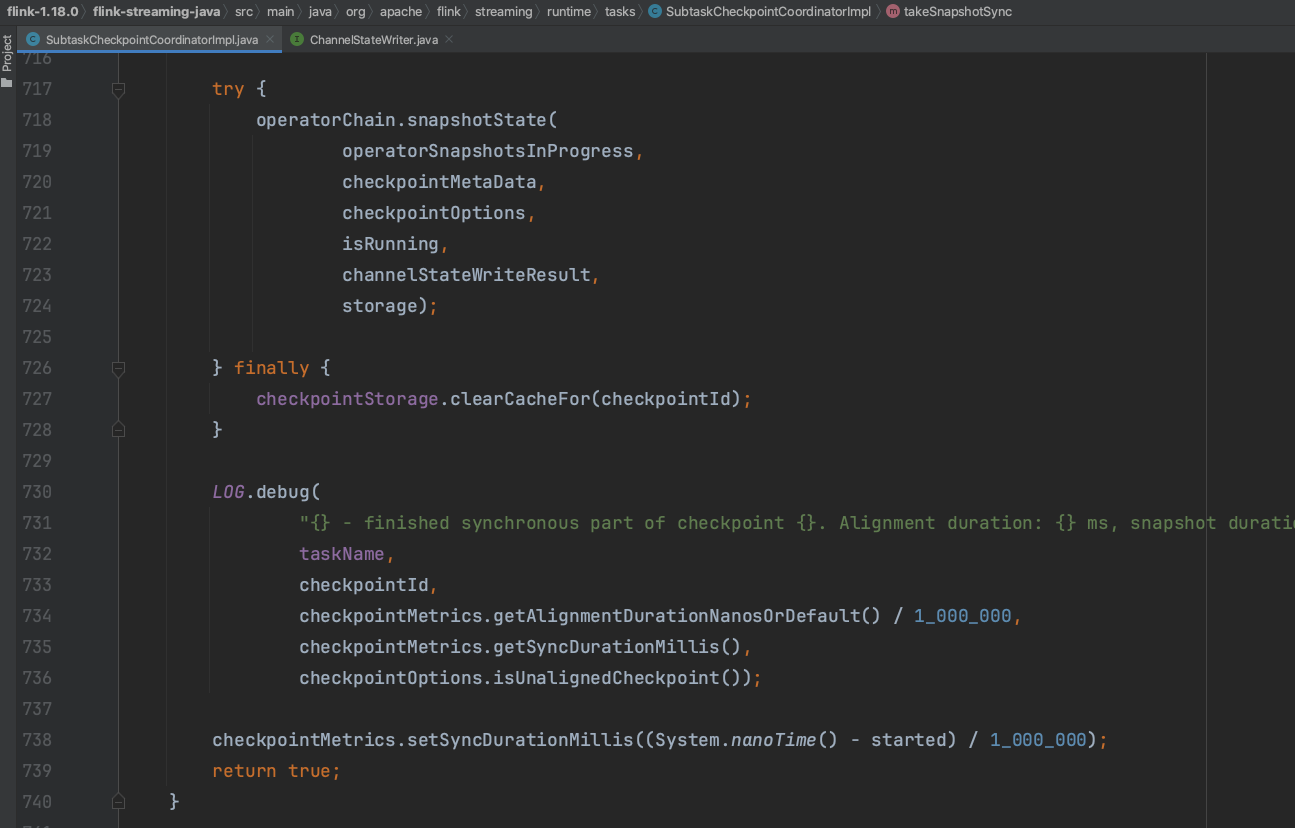
遍历算子链中的算子,为每个算子生成OperatorSnapshotFutures结构。

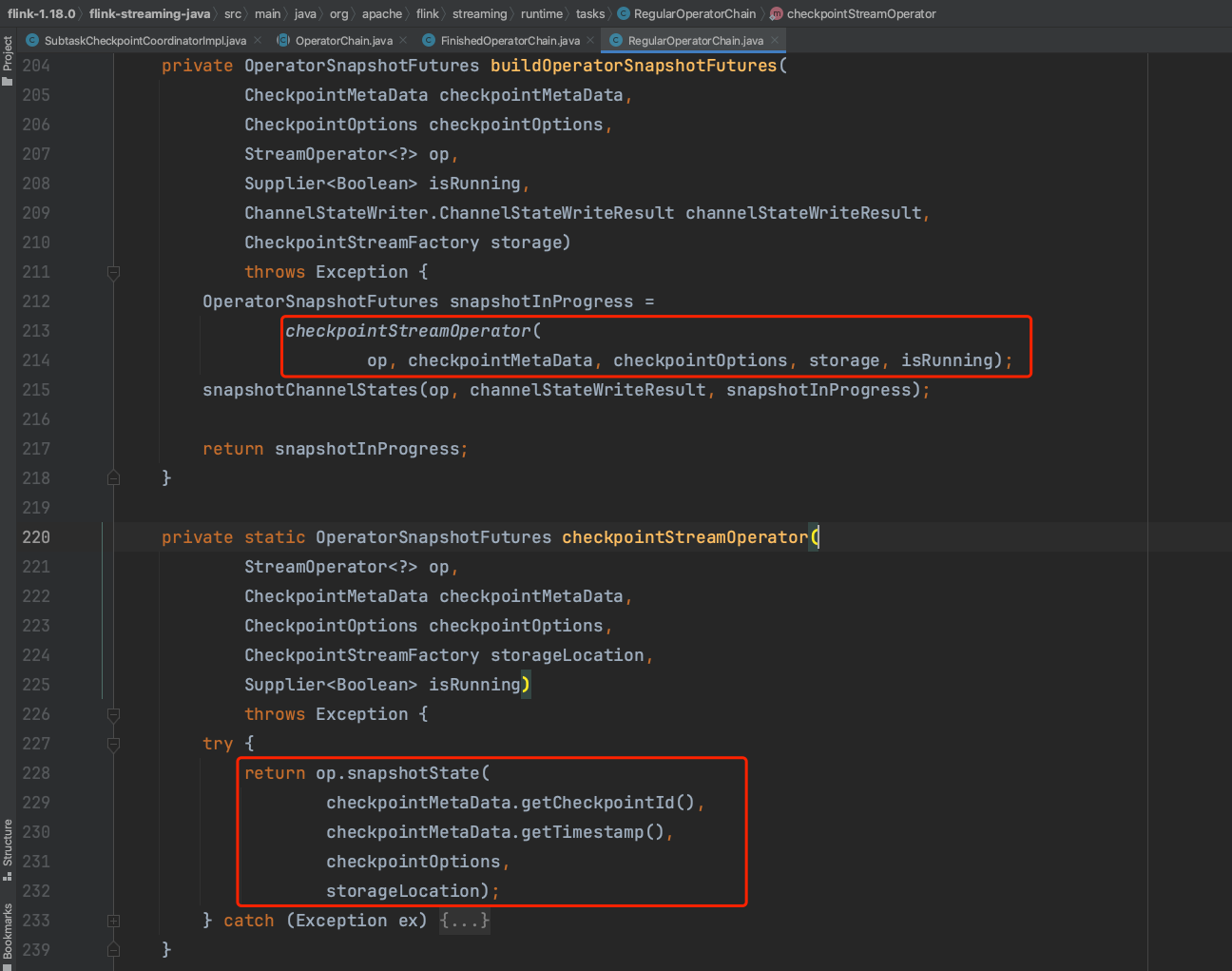
stateHandler组件代表算子简要的状态快照过程,由此生成具体类型的状态快照操作。
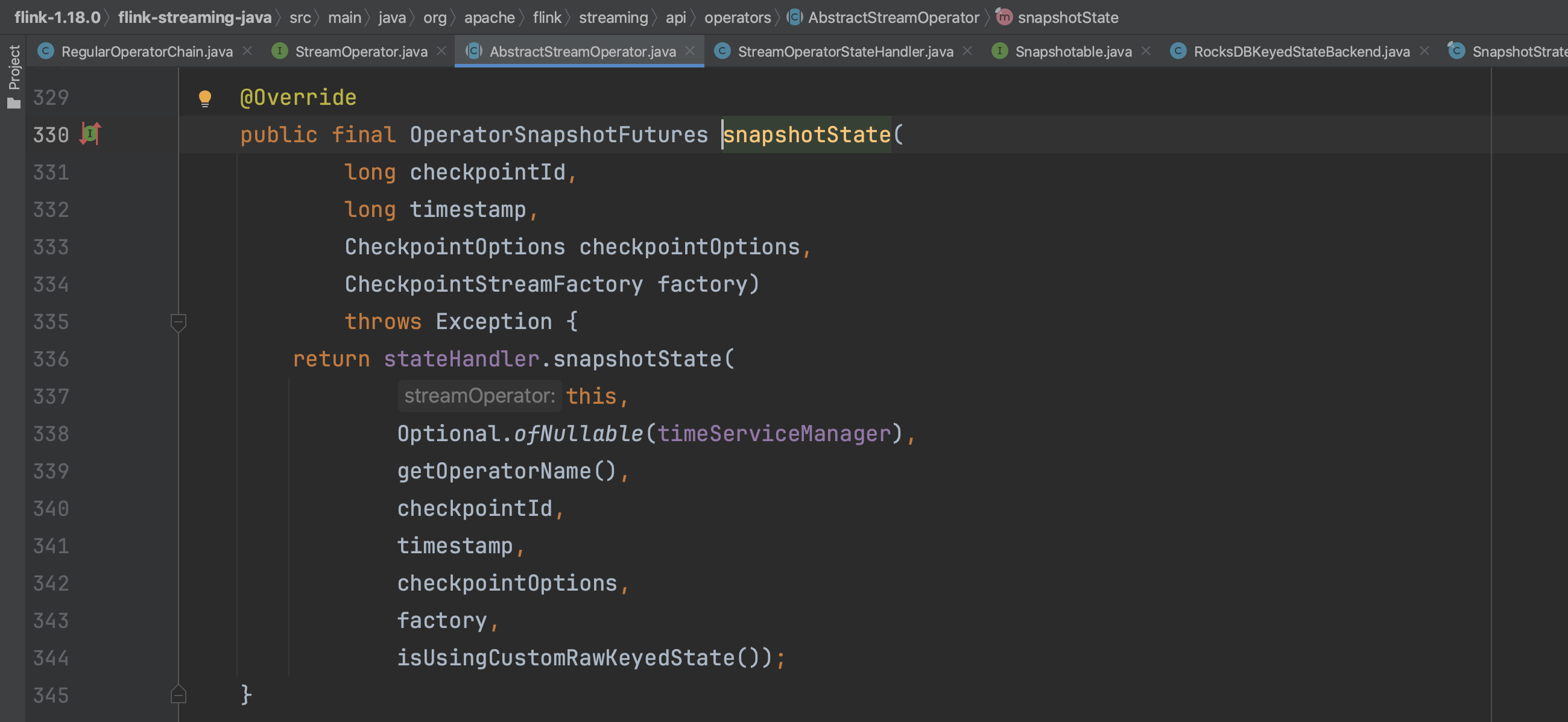
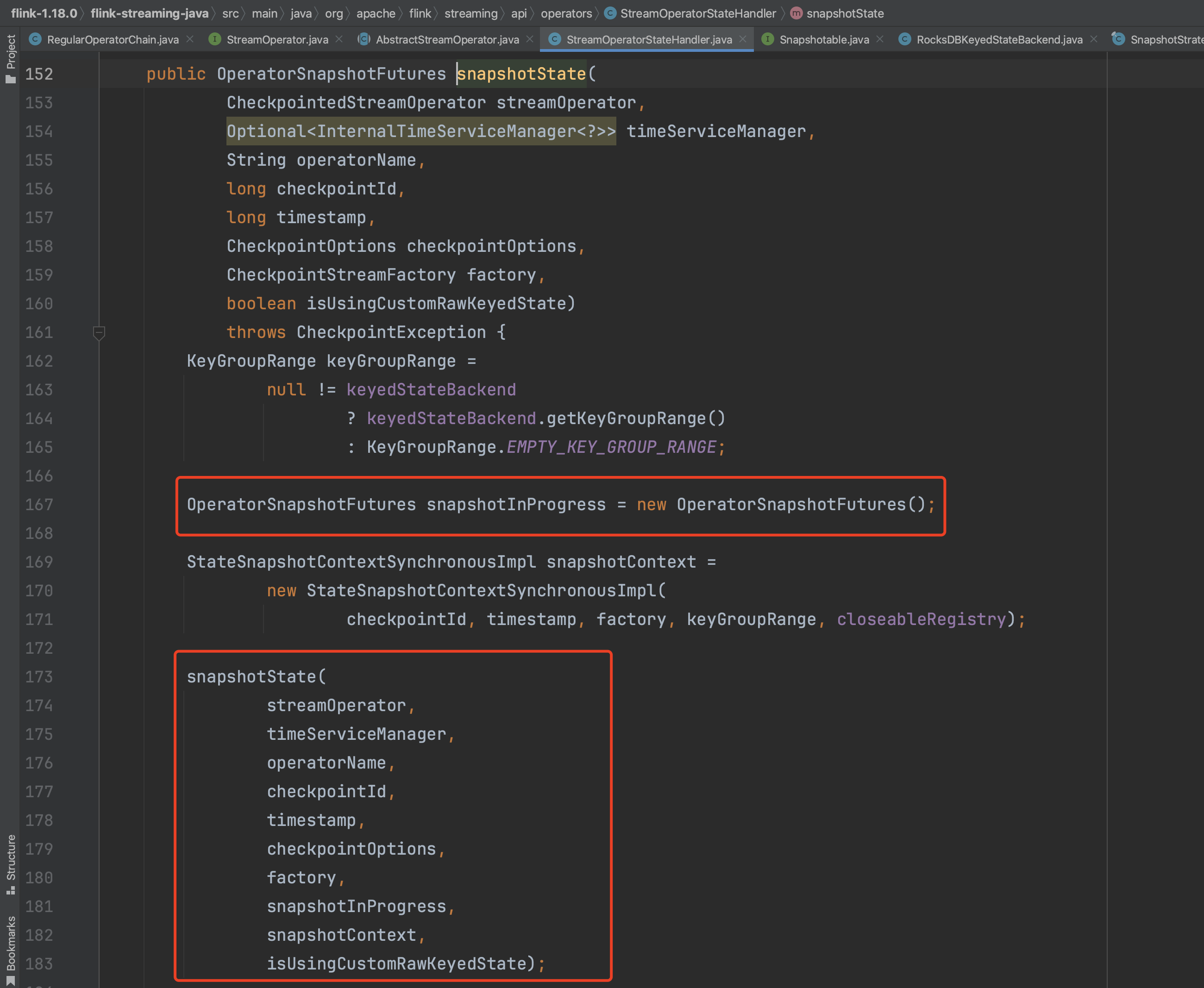
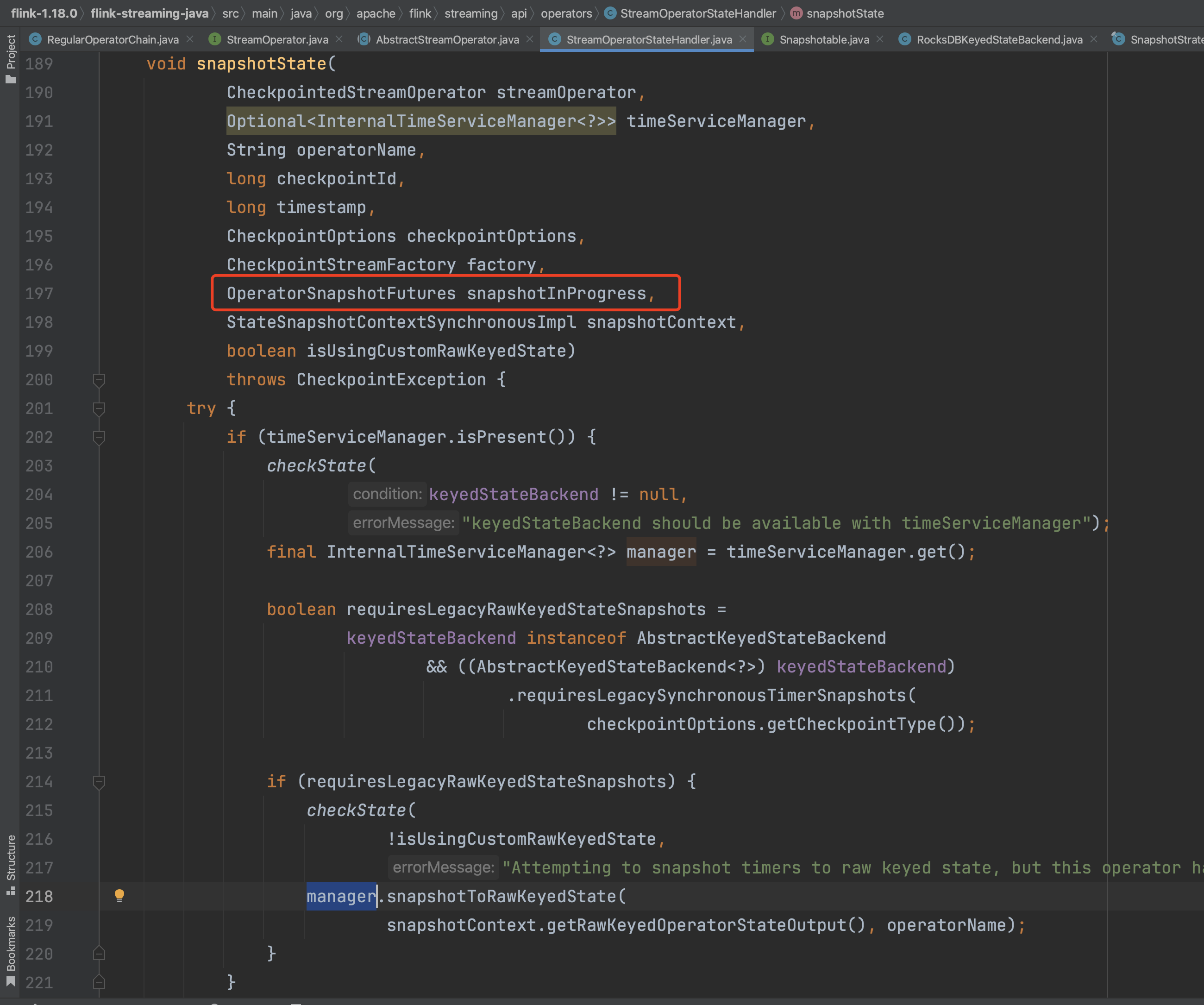
依次生成同一个算子4个不同类型状态快照过程keyedStateManagedFuture、keyedStateRawFuture、operatorStateManagedFuture、operatorStateRawFuture。
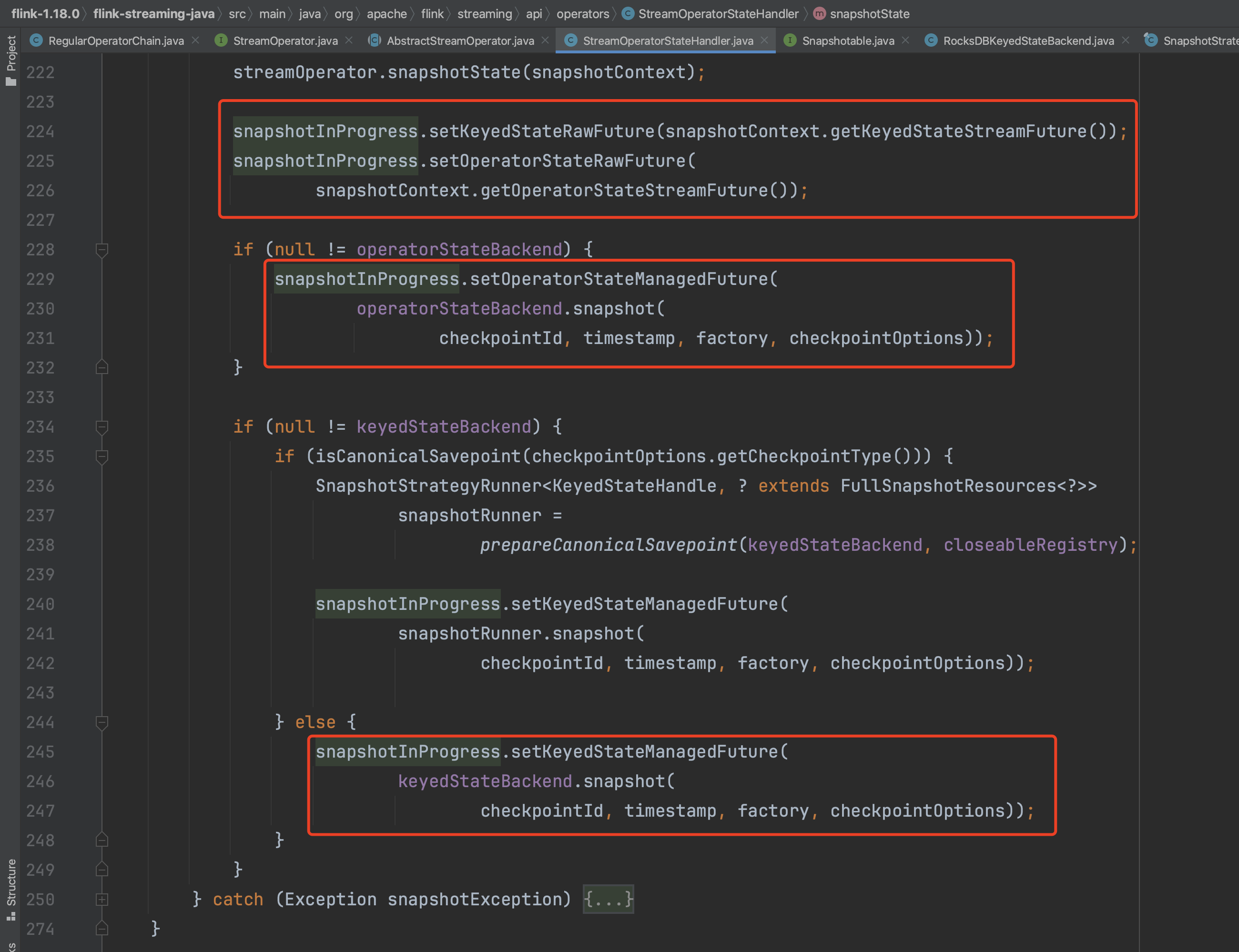
方法takeSnapshotSync(...)执行完成后,调用方法finishAndReportAsync(...)异步执行这4个不同类型的状态快照过程,执行过程如下:
新建AsyncCheckpointRunnable实例,异步执行状态快照过程。AsyncCheckpointRunnable类继承于Runnable,可被加入线程池调度,其基本逻辑在run()方法中实现。

AsyncCheckpointRunnable.run()方法包括两个步骤:步骤一方法finalizeNonFinishedSnapshots()异步执行这4个不同类型的状态快照过程,步骤二方法reportCompletedSnapshotStates(...)在Checkpoint动作完成后负责上报checkpoint信息,此步骤放到下一小节讲解。
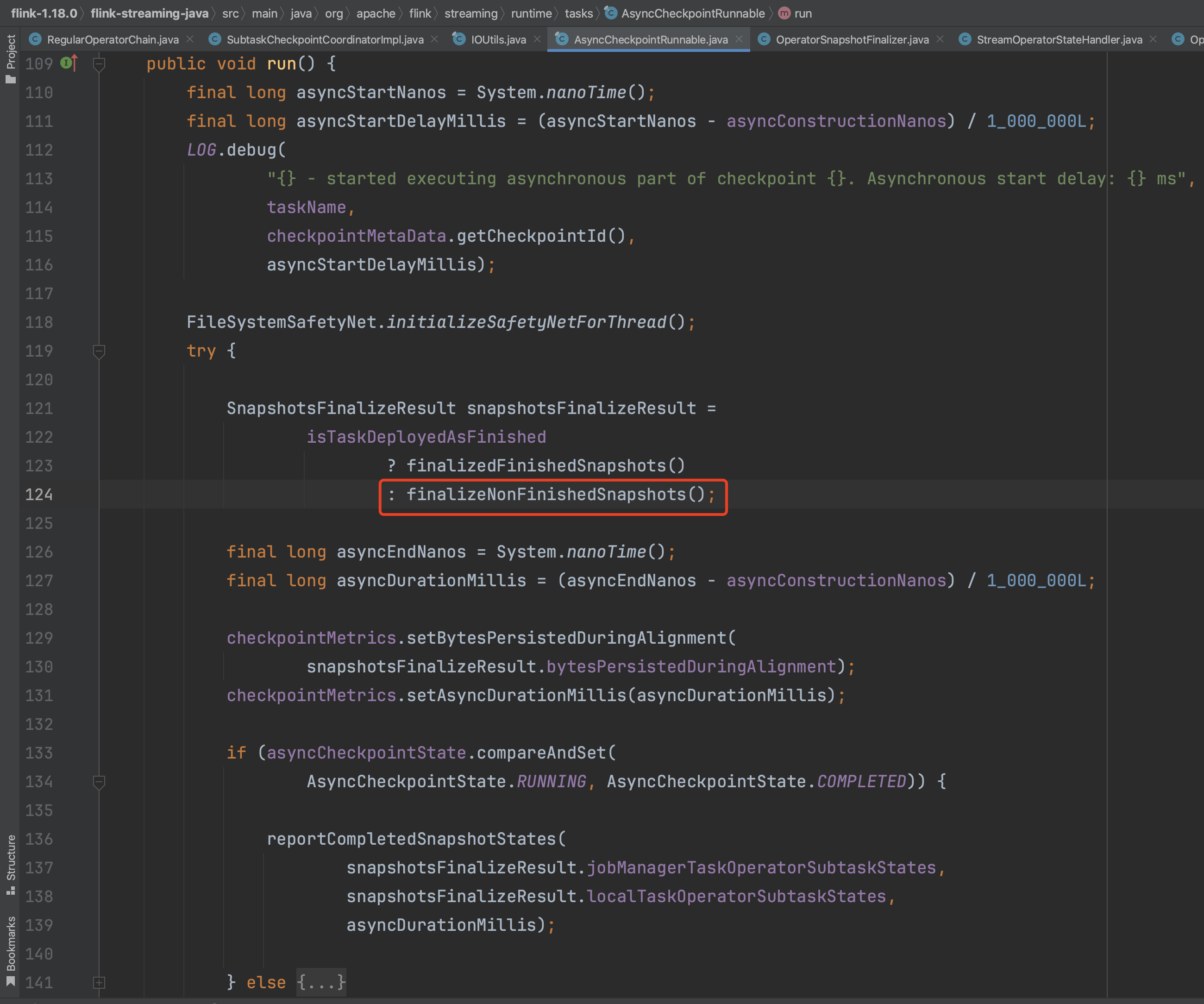
在方法finalizeNonFinishedSnapshots()中,jobManagerTaskOperatorSubtaskStates代表TaskExecutor向JobManager 确认的算子状态快照元数据信息,用于状态数据高可用。localTaskOperatorSubtaskStates代表本地TaskManager端状态快照元数据信息,主要用作Task异常时快速恢复。新建OperatorSnapshotFinalizer对象时开始异步执行这4个不同类型的状态快照过程。
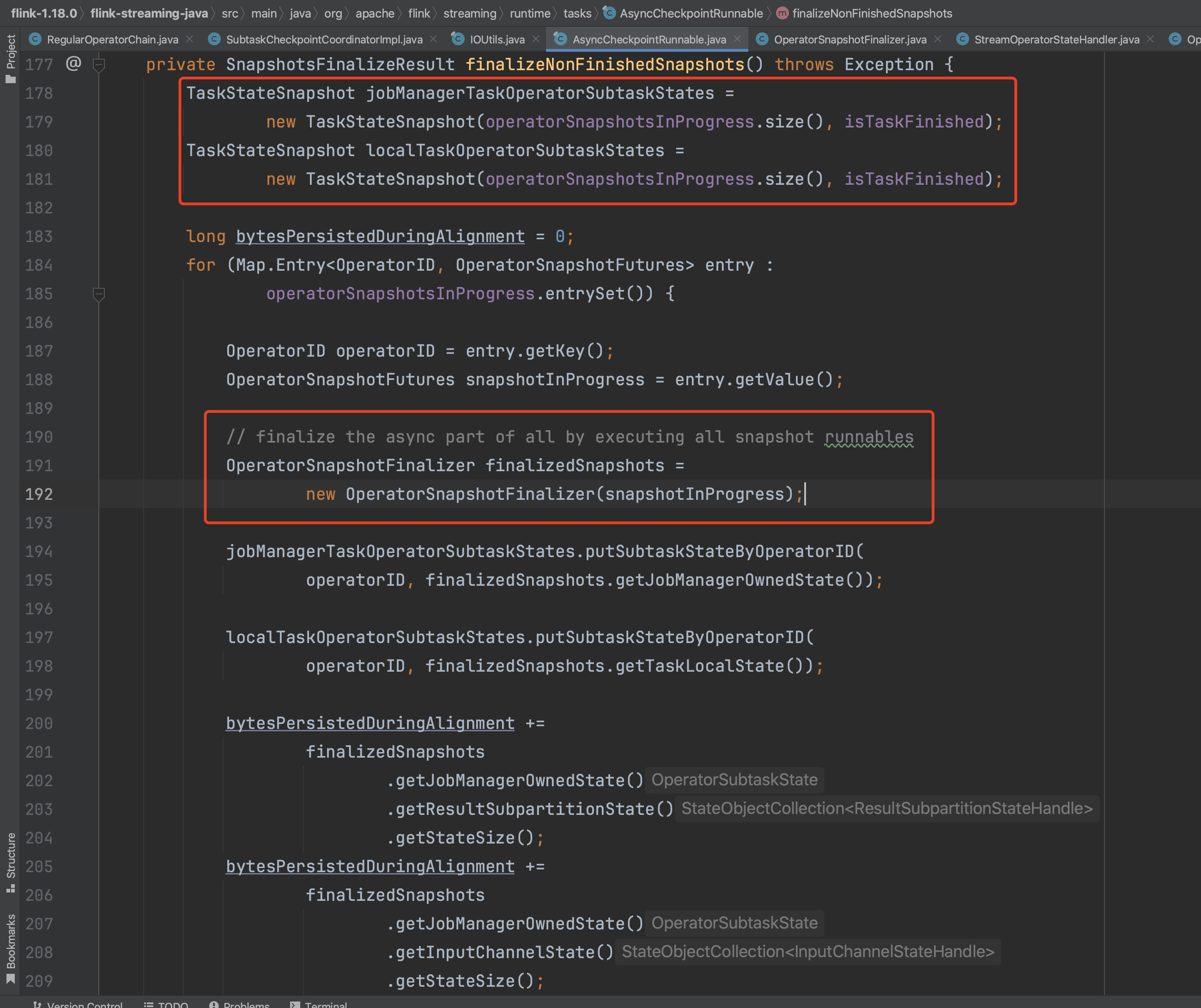
在OperatorSnapshotFinalizer构造函数中异步执行这4个不同类型的状态快照过程。状态快照执行中,比如TaskManager端将状态数据写入本地内存或远端hdfs文件系统等。


以上即为Task执行Checkpoint的过程,此篇随笔暂不分析具体的状态数据写入动作,具体的状态数据写入动作比较重需放在下一篇随笔中单独讲解。
3、Task上报checkpoint信息
Task执行完Checkpoint过程后开始上报checkpoint元数据信息。Task端方法调用链:AsyncCheckpointRunnable.reportCompletedSnapshotStates(...) -> TaskStateManagerImpl.reportTaskStateSnapshots(...) -> RpcCheckpointResponder.acknowledgeCheckpoint(...)


类JobMaster实现接口CheckpointCoordinatorGateway(RPC网关),RpcCheckpointResponder实例中持有checkpointCoordinatorGateway句柄,通过该句柄调用远程JobMaster.acknowledgeCheckpoint(...)方法,至此TaskExecutor端执行过程转入远端JobMaster执行过程。

JobMaster借助调度器组件将确认Checkpoint完成流程转入CheckpointCoordinator组件。
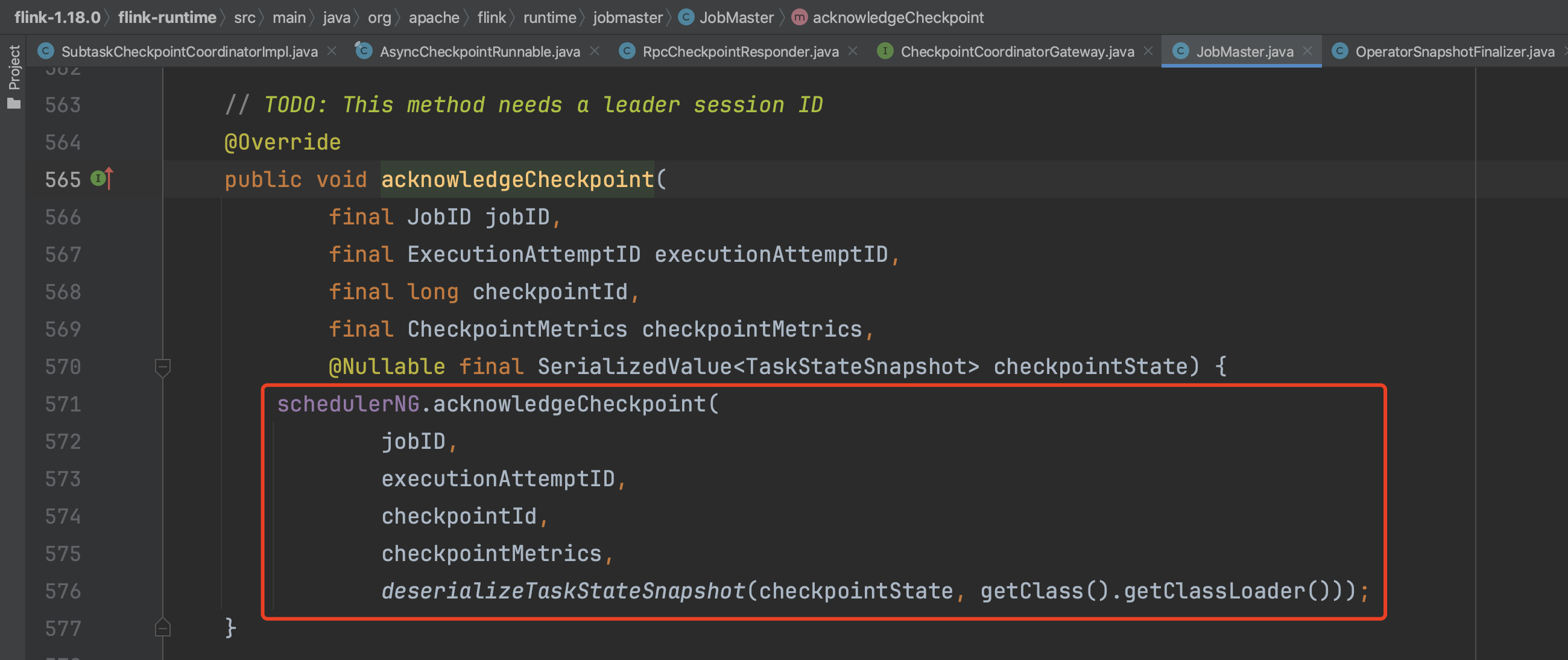
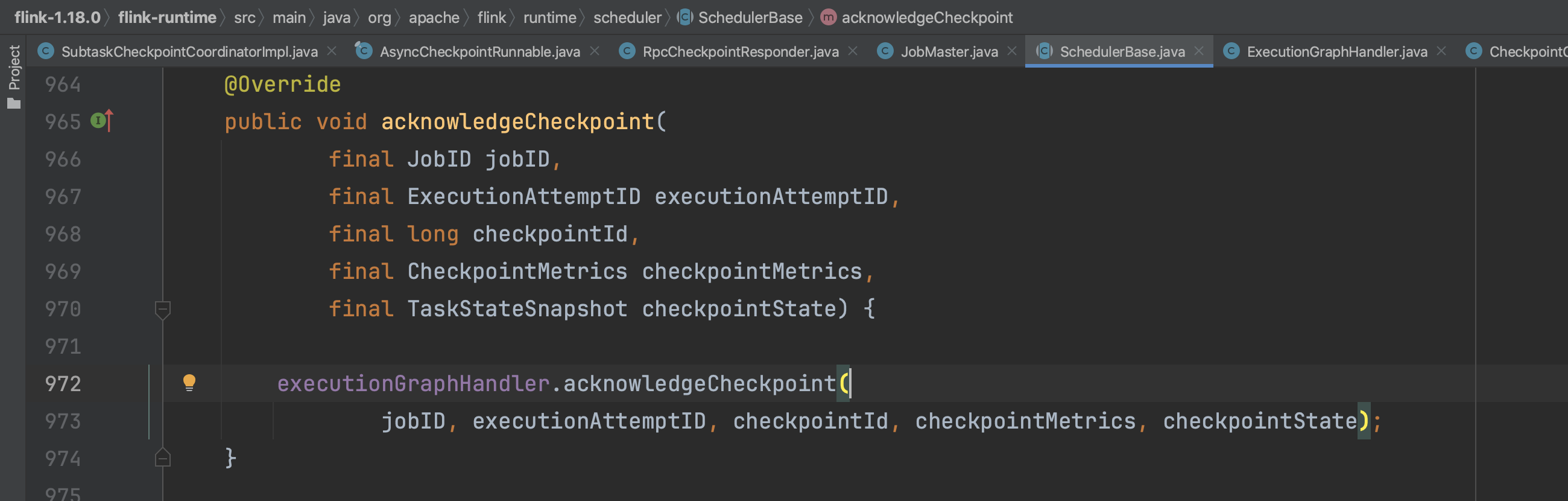
转入CheckpointCoordinator组件。
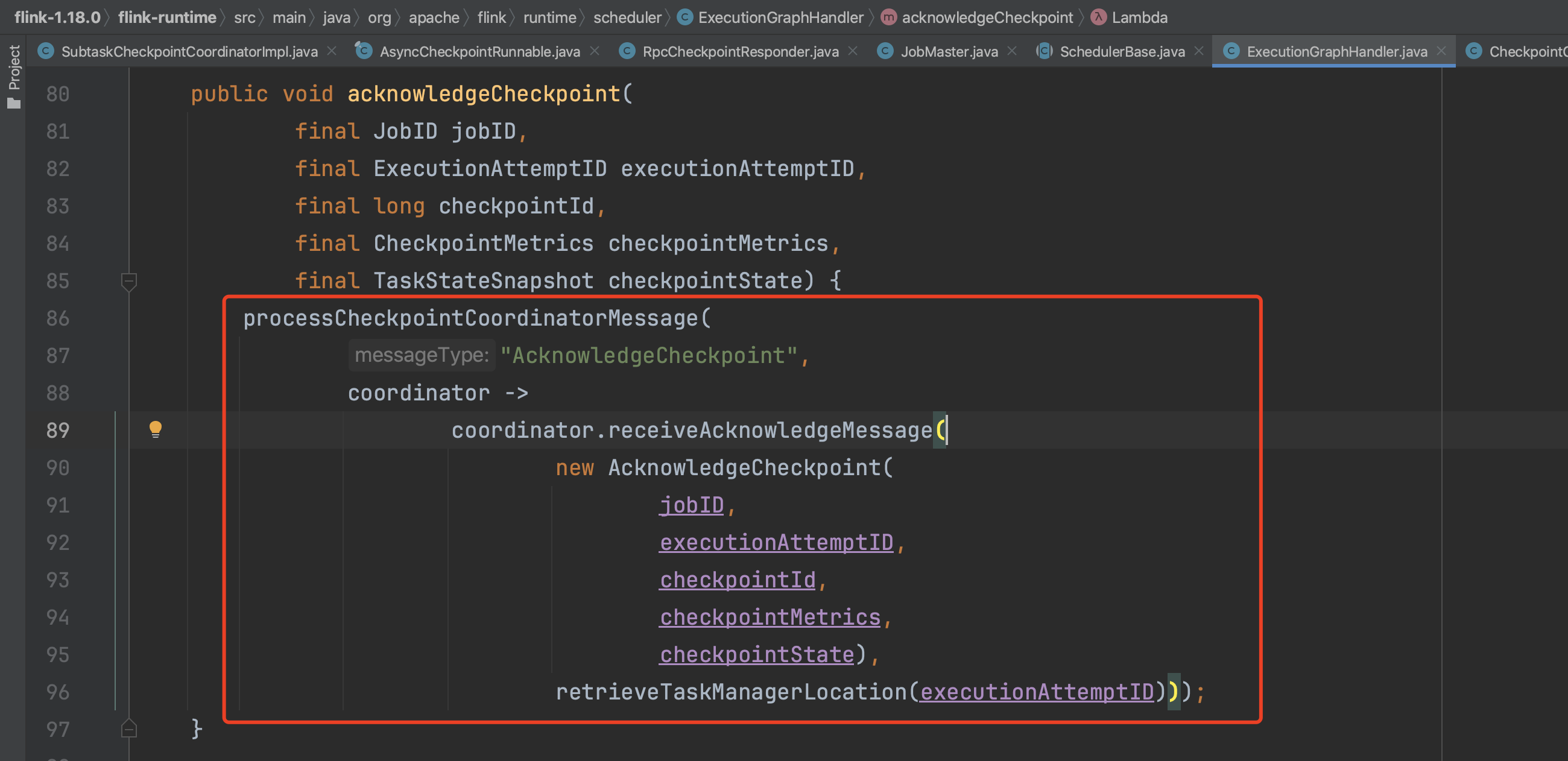
CheckpointCoordinator组件会转入到PendingCheckpoint.acknowledgeTask(...)方法。
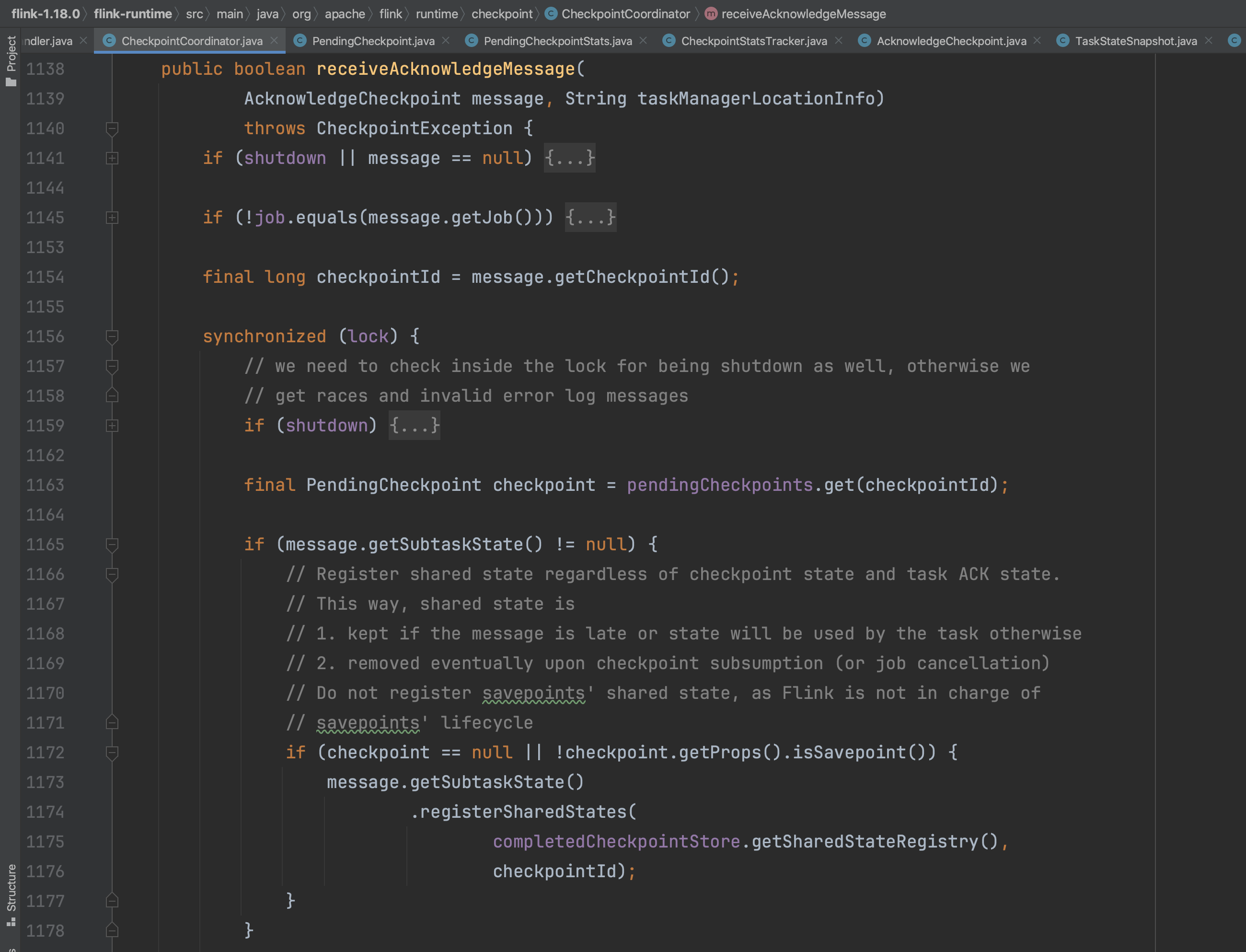
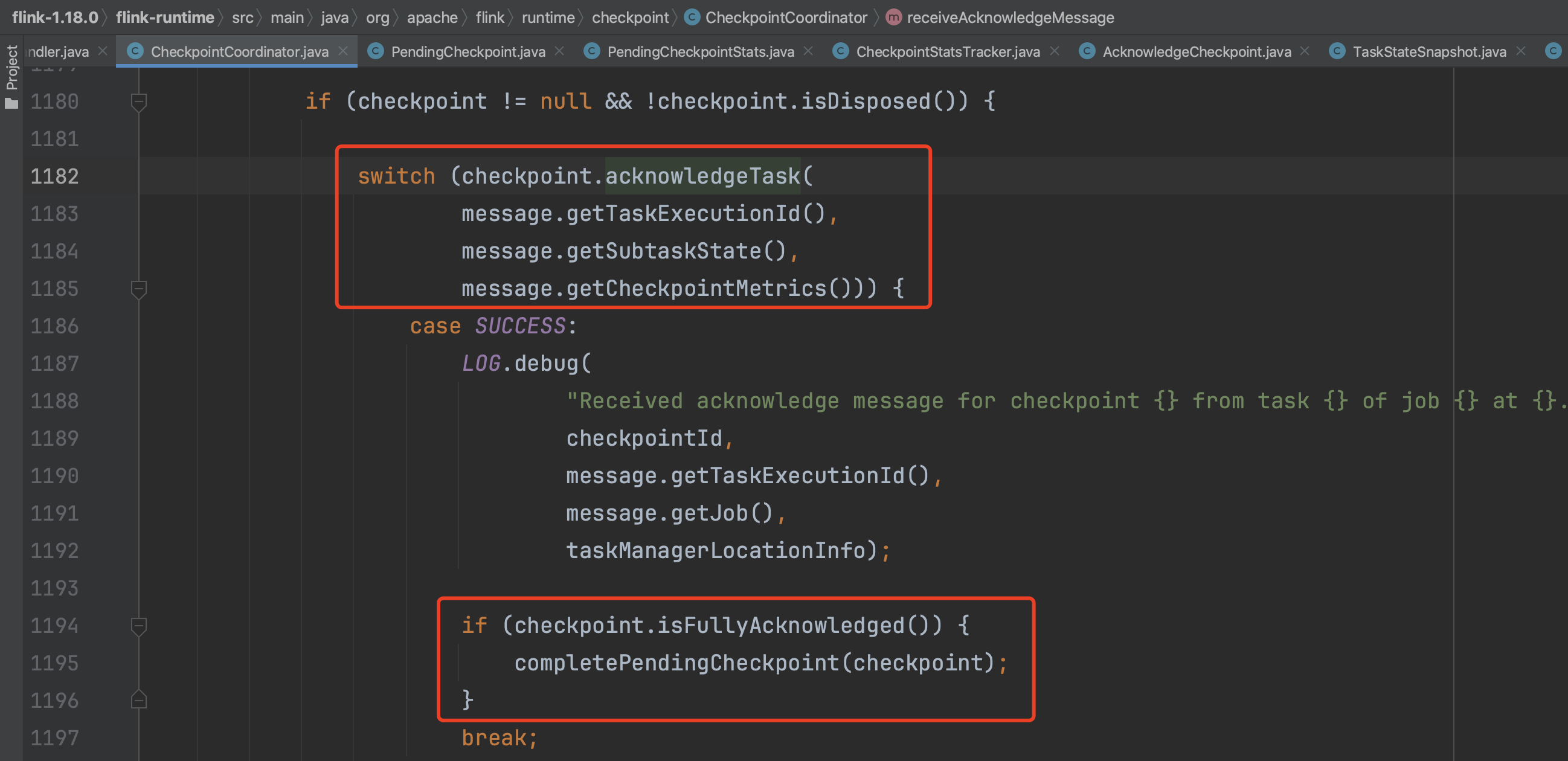
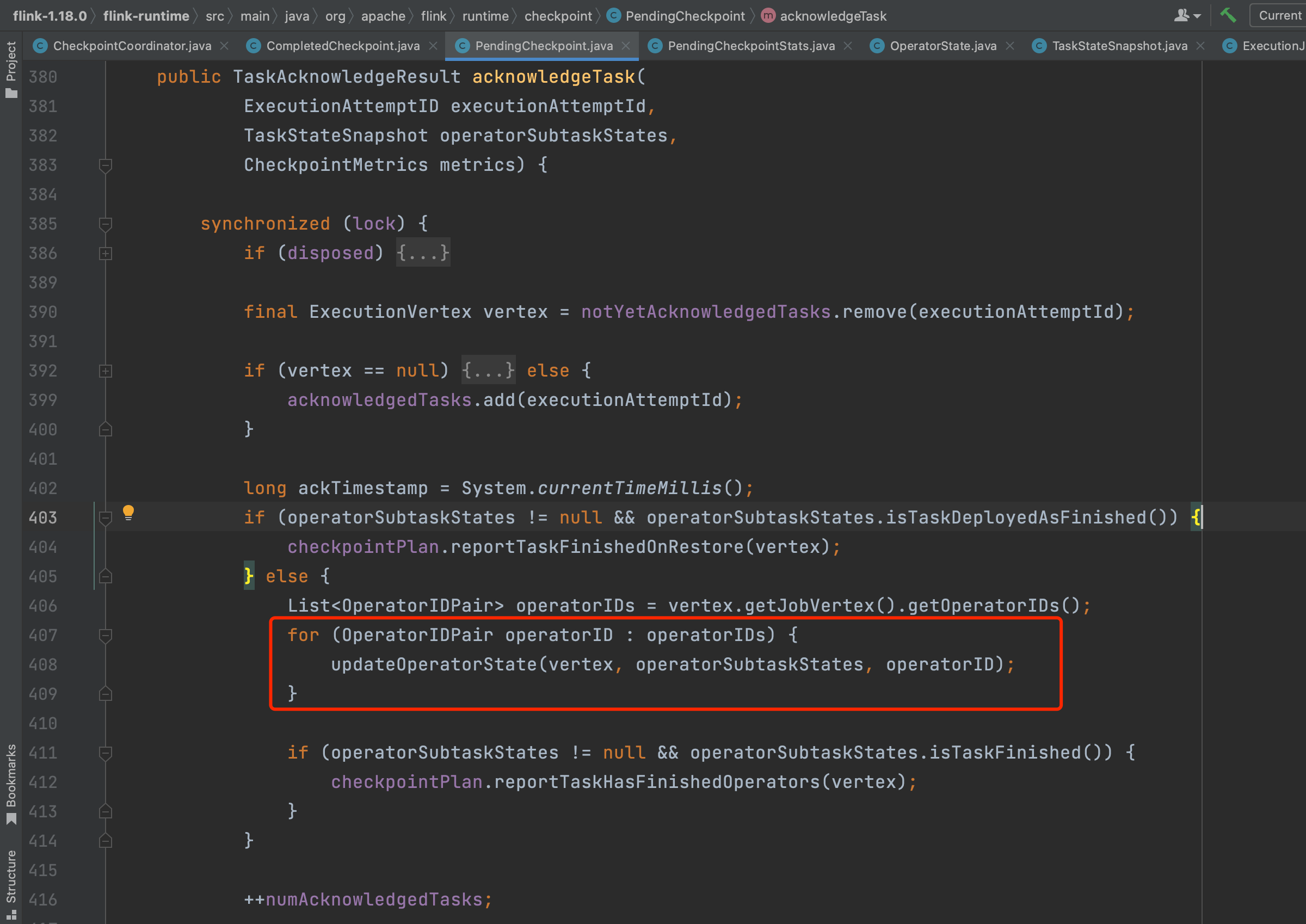
Task上报的元数据信息包括Checkpoint的路径信息、状态数据大小等。方法acknowledgeTask(...)负责将Task上报的元数据信息添加到PendingCheckpoint里。方法updateOperatorState(...)负责将Task上报的元数据信息添加到PendingCheckpoint.operatorStates成员中。
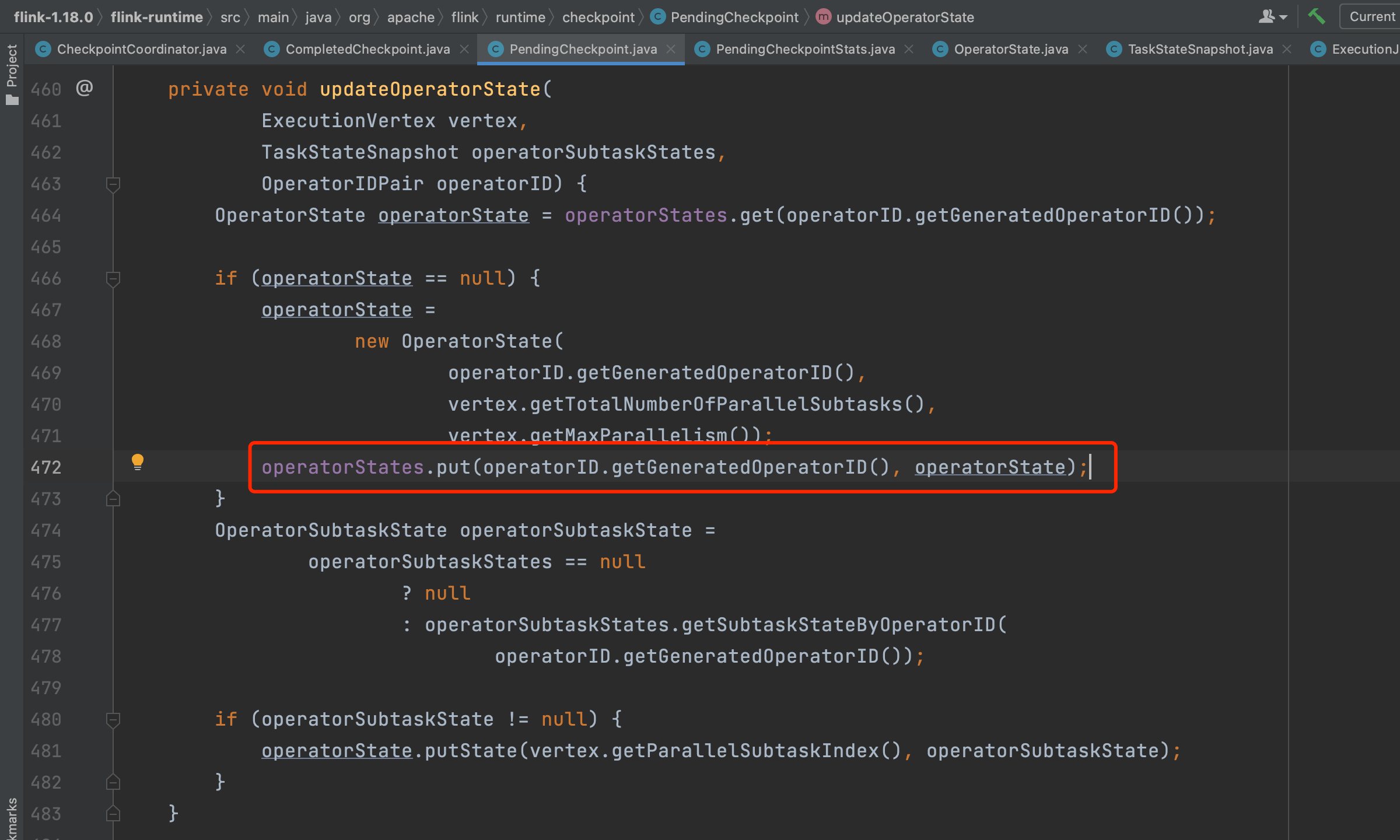
如果JobMaster接收到所有task上报的确认消息,就执行方法completePendingCheckpoint(...)。该方法主要完成以下事情:一是把pendingCheckpoint转换为CompletedCheckpoint,将元数据信息进行持久化,把CompletedCheckpoint添加到已完成的Checkpoint集合中,删除过期checkpoint数据。二是向各个算子发出RPC请求,通知该检查点已完成。

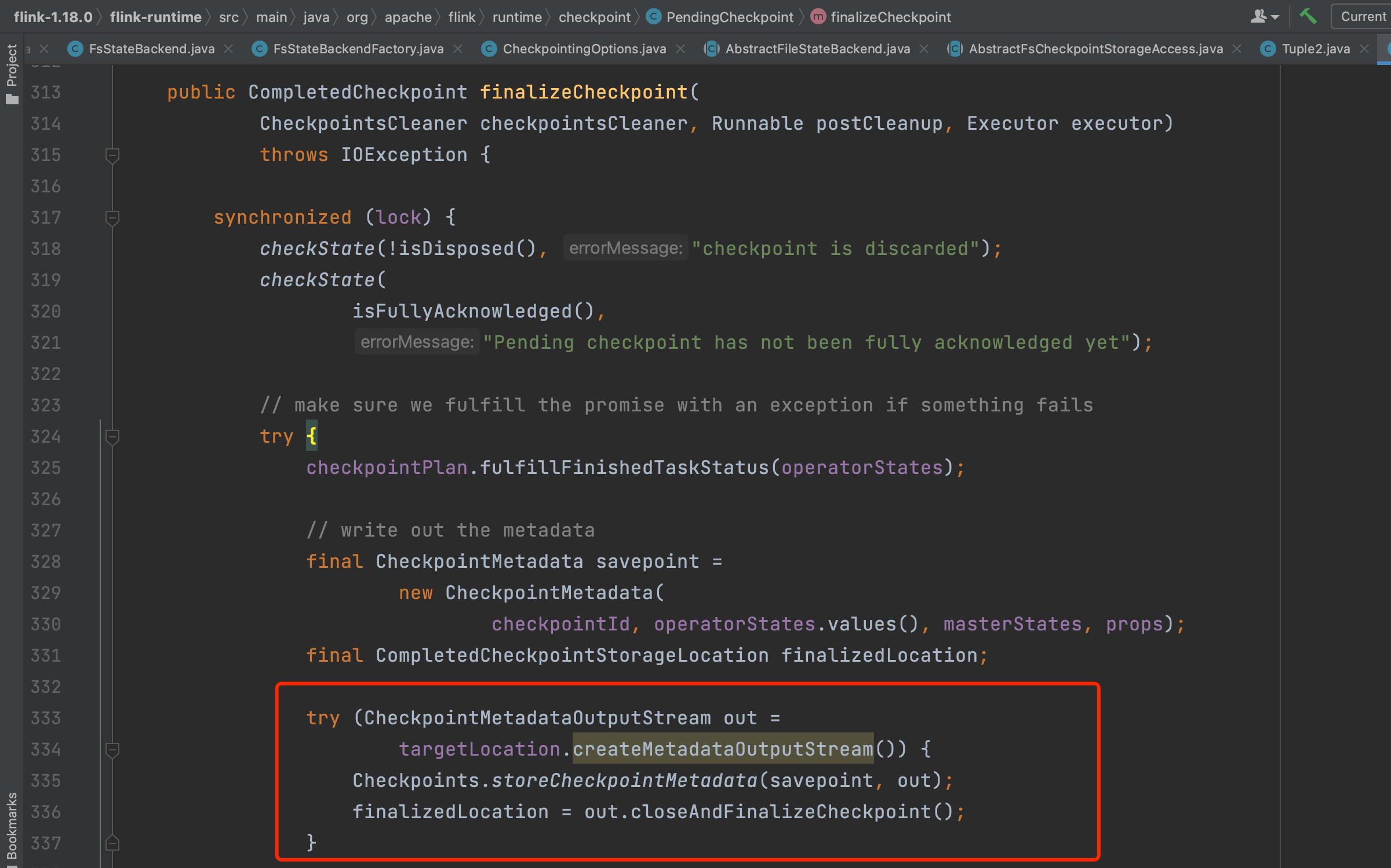
4、JobManager通知Task进行commit
方法completePendingCheckpoint(...)在收到所有Task发送的确认消息并转换成CompletedCheckpoint后,调用方法cleanupAfterCompletedCheckpoint(...)向各个算子发出RPC请求,通知该检查点已完成,即JobManager通知Task进行commit动作。
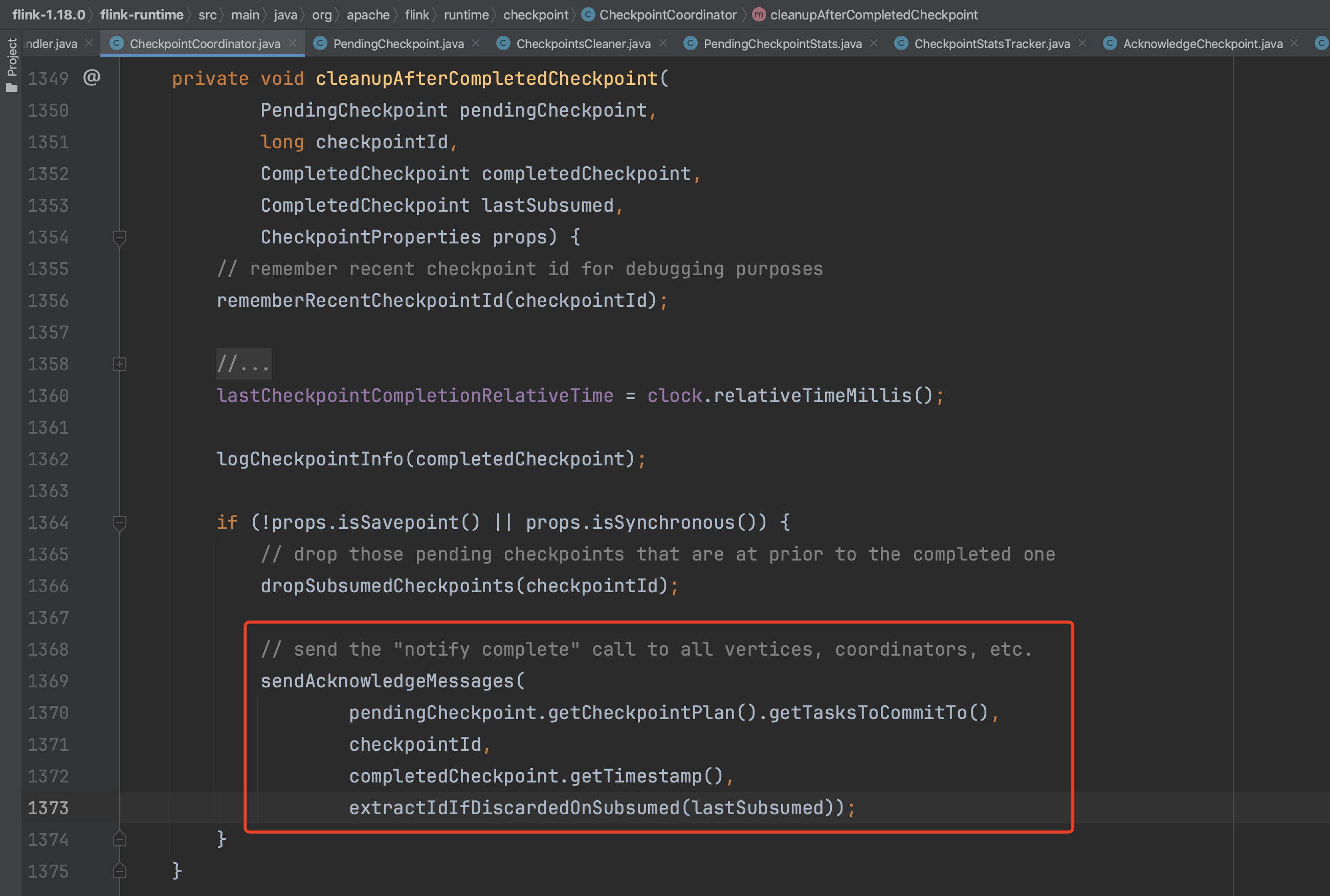
从Checkpoint执行计划中获取所有需要提交的Task集合,遍历Task集合元素,依次执行方法链Execution.notifyCheckpointOnComplete(...) -> RpcTaskManagerGateway.notifyCheckpointOnComplete(...) -> TaskExecutor.confirmCheckpoint(...)转入到远端TaskExecutor执行上来。
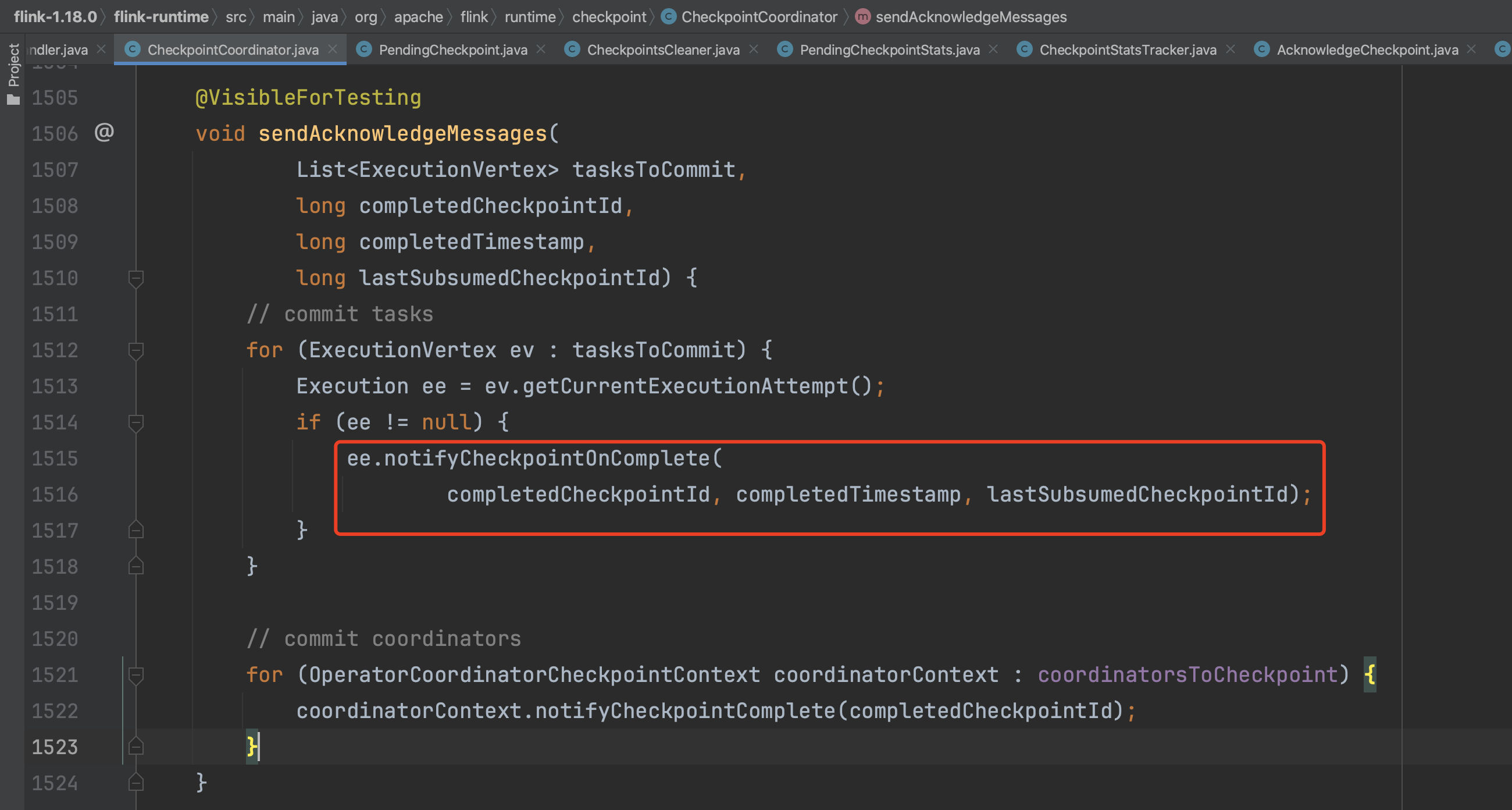
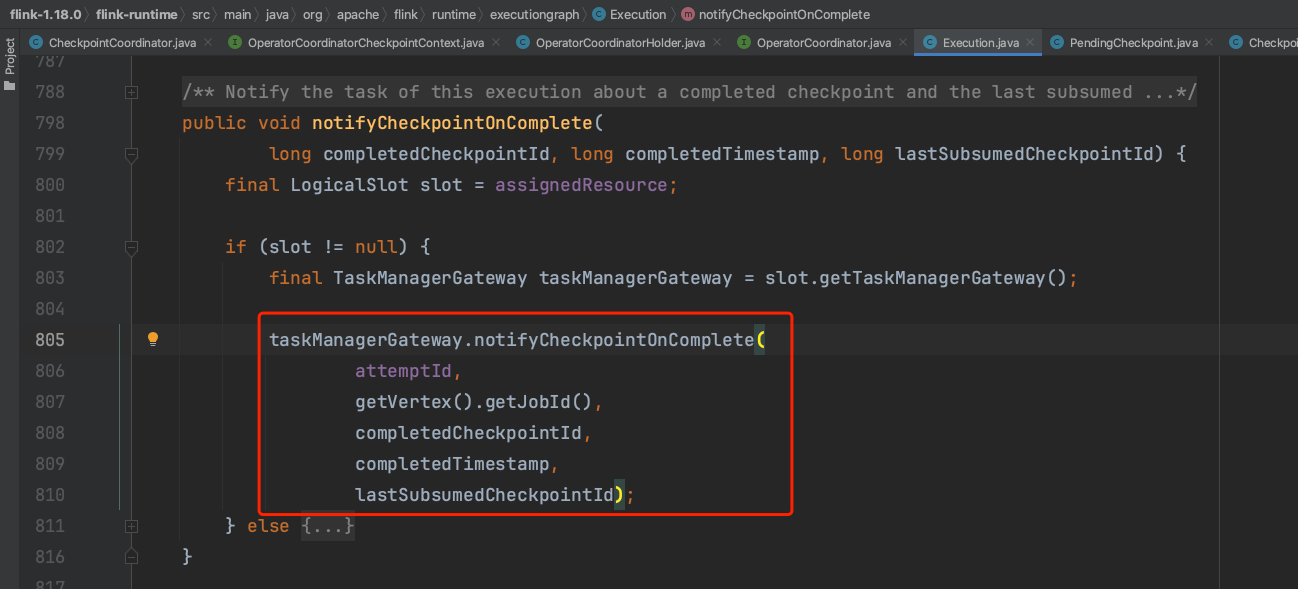

TaskExecutor根据RPC消息的ExecutionAttemptID标识,获取对应的Task实例进行Checkpoint commit动作。


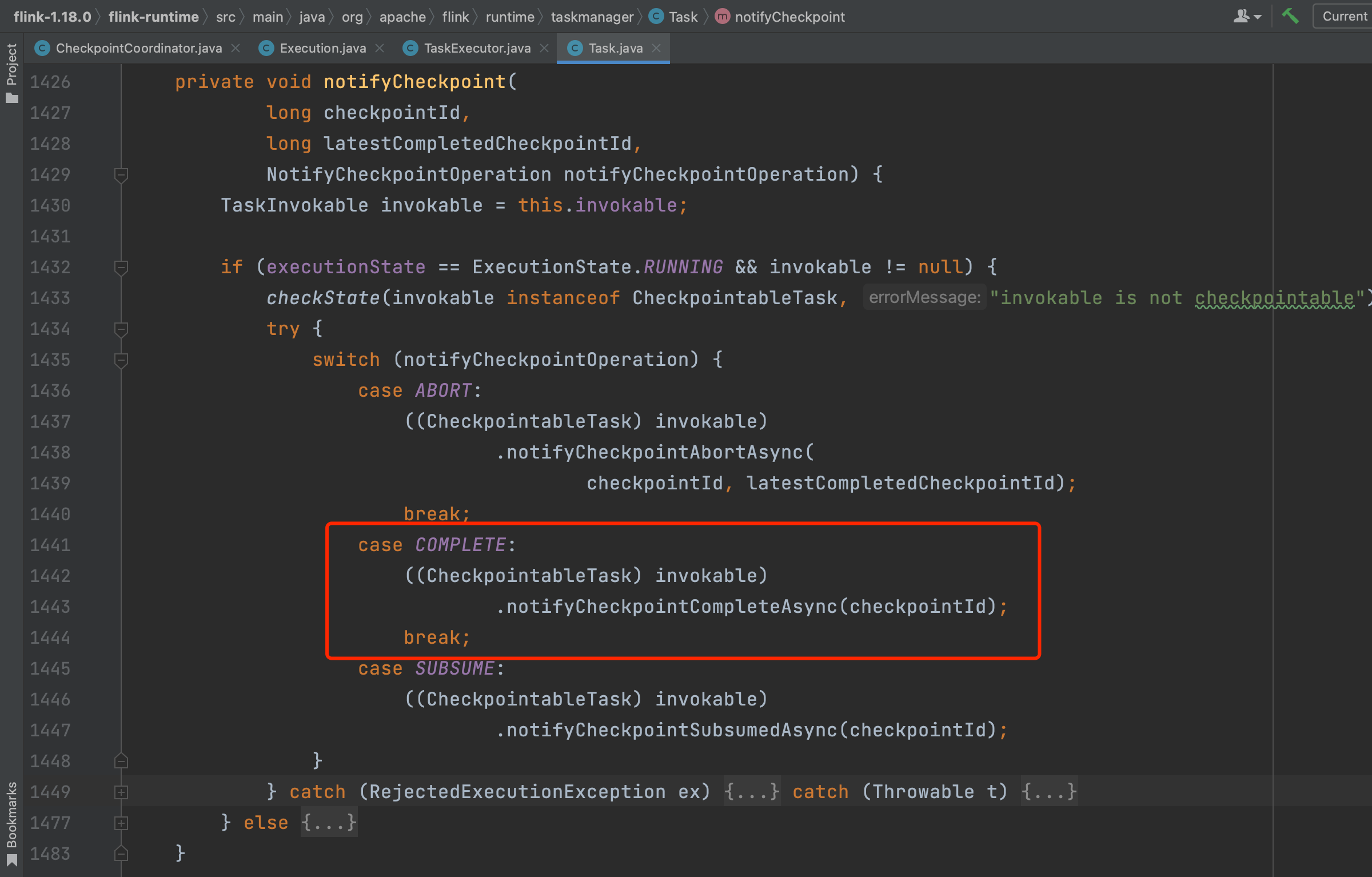
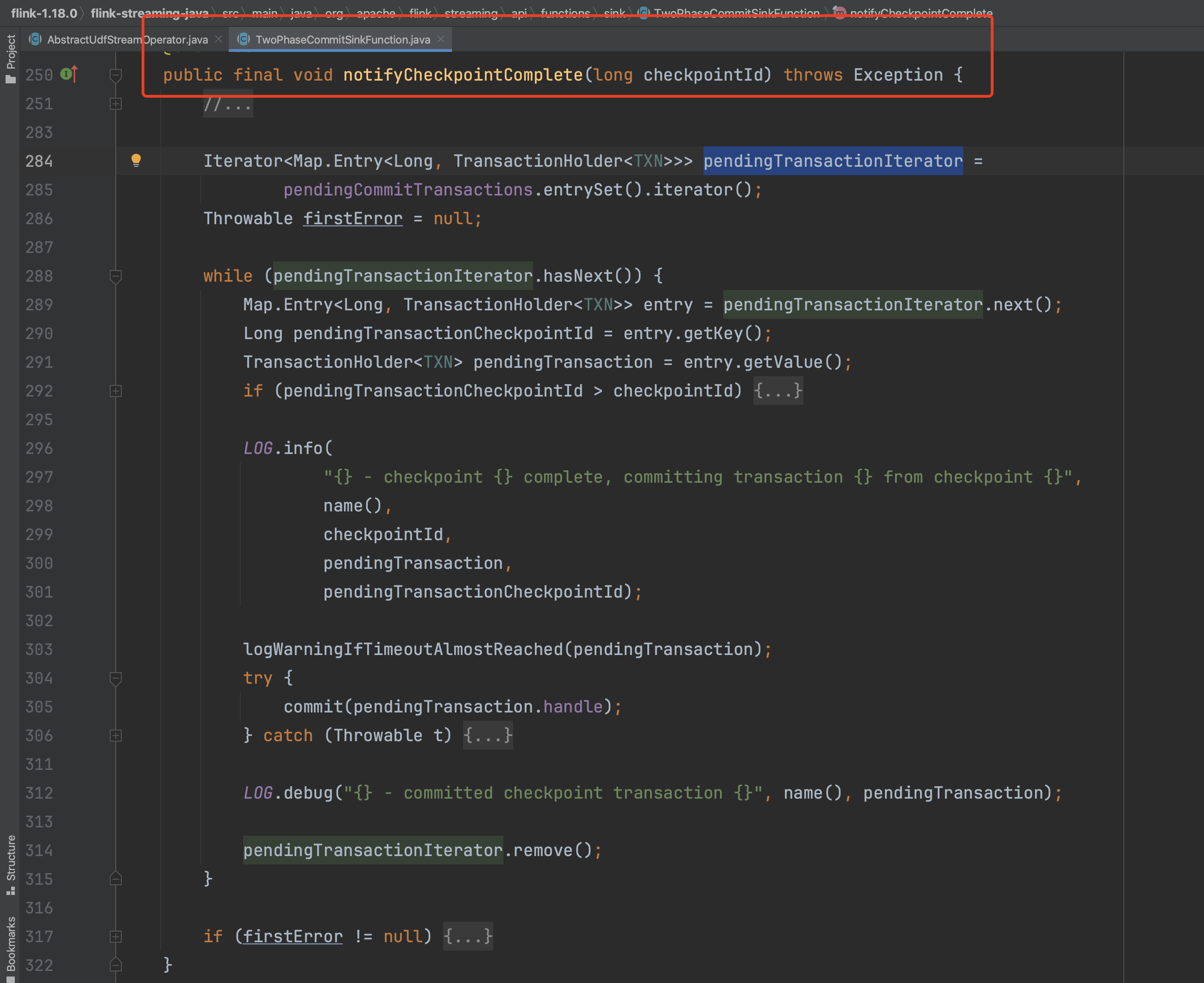
对于大部分中间算子来说,task commit操作没有太多实质性逻辑。但对于部分算子StreamSource、StreamSink如FlinkKafkaConsumerBase、FlinkKafkaProducer算子来说,实现接口CheckpointListener需要调用方法notifyCheckpointComplete(...)做一些额外逻辑处理。
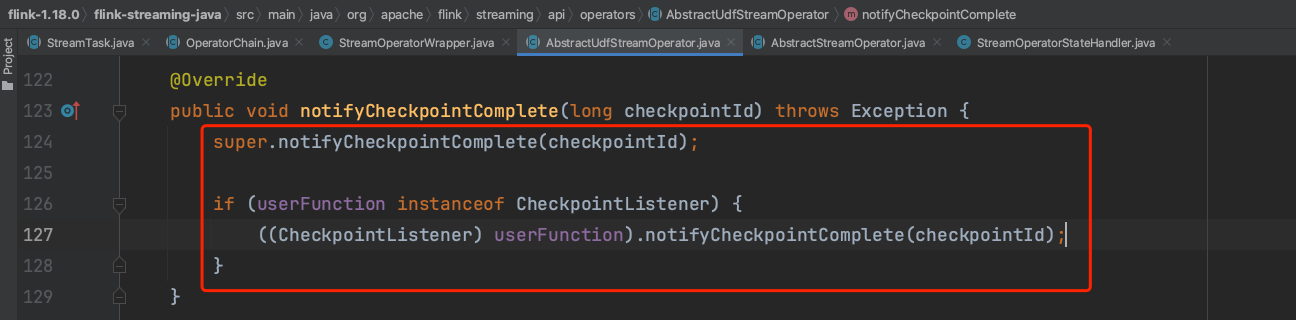
如FlinkKafkaConsumerBase来说需要向kafka server端提交消费的offset数据。
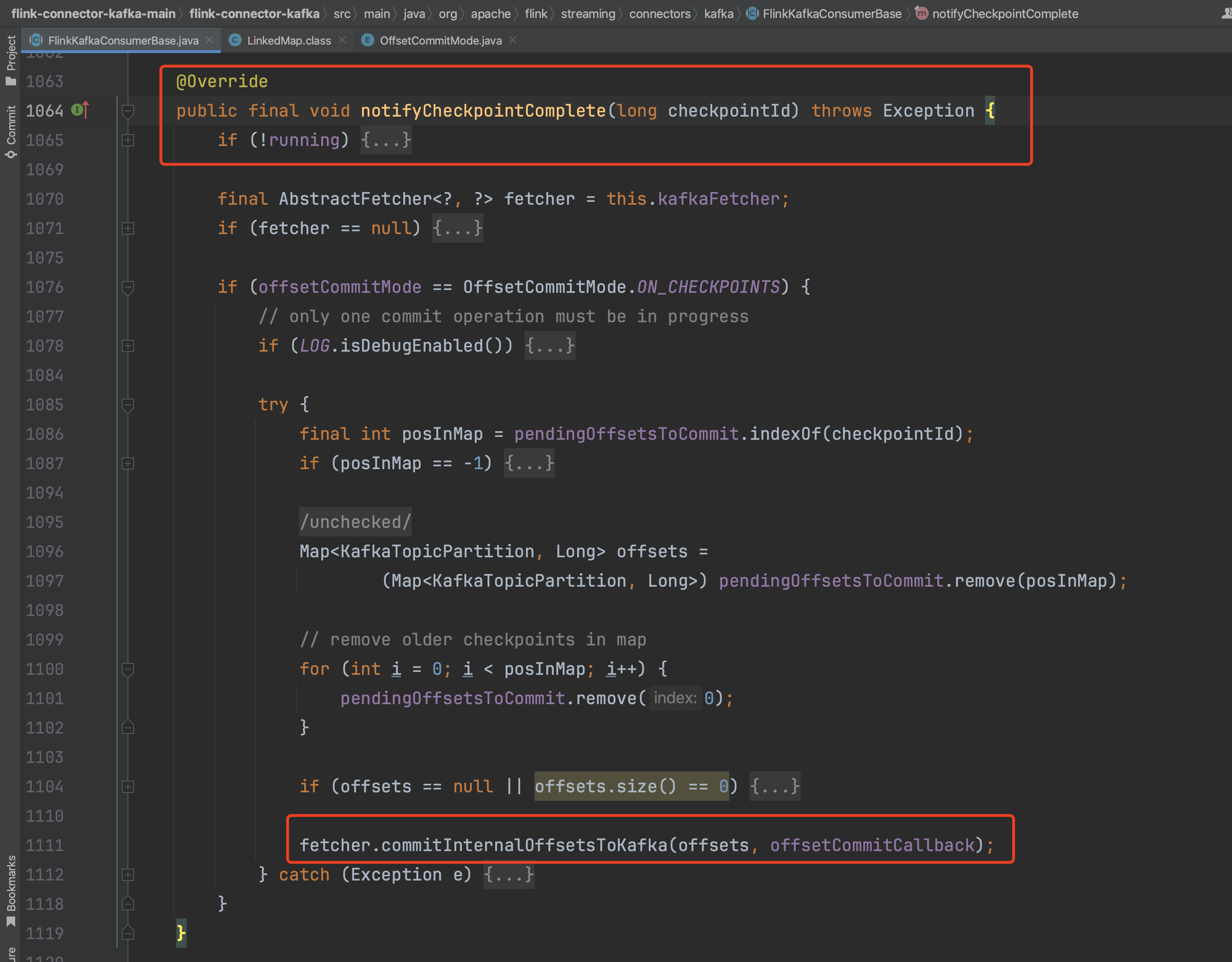
针对FlinkKafkaProducer来说,由于其实现接口TwoPhaseCommitSinkFunction且该接口继承于CheckpointListener,也需要实现方法notifyCheckpointComplete(...)做一些事务提交类的逻辑来实现flink端到端exactly-once的保证语义。
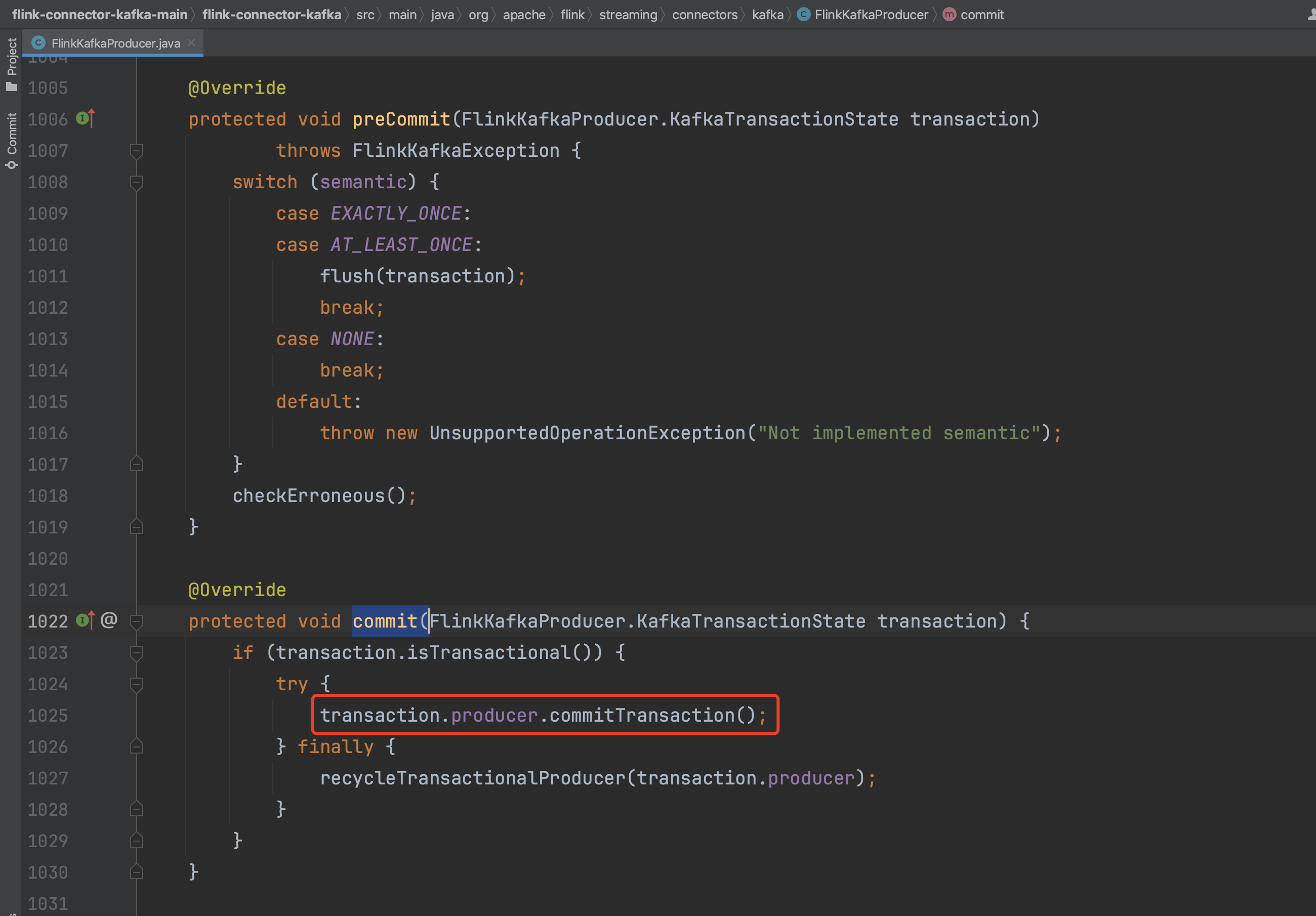
以上为数据源算子Checkpoint动作的全部过程,下面解析下非数据源算子的Checkpoint过程。
5、非DataSource Checkpoint过程
非数据源Task的Checkpoint入口和数据流中业务数据元素处理入口一样,统一由StreamTask.processInput(...)方法实现,根据从流中获取到的数据元素类型调用不同的处理逻辑。
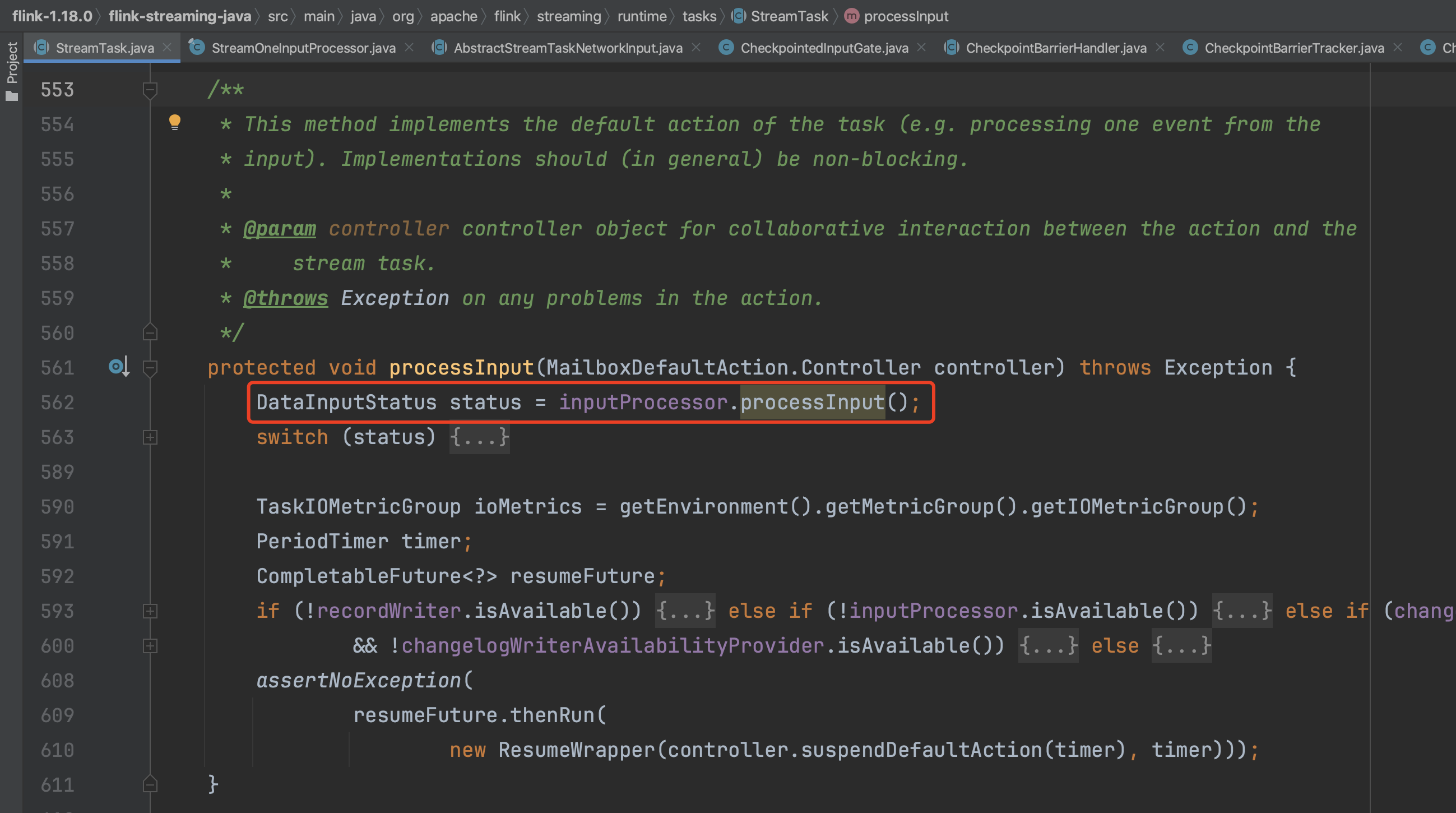
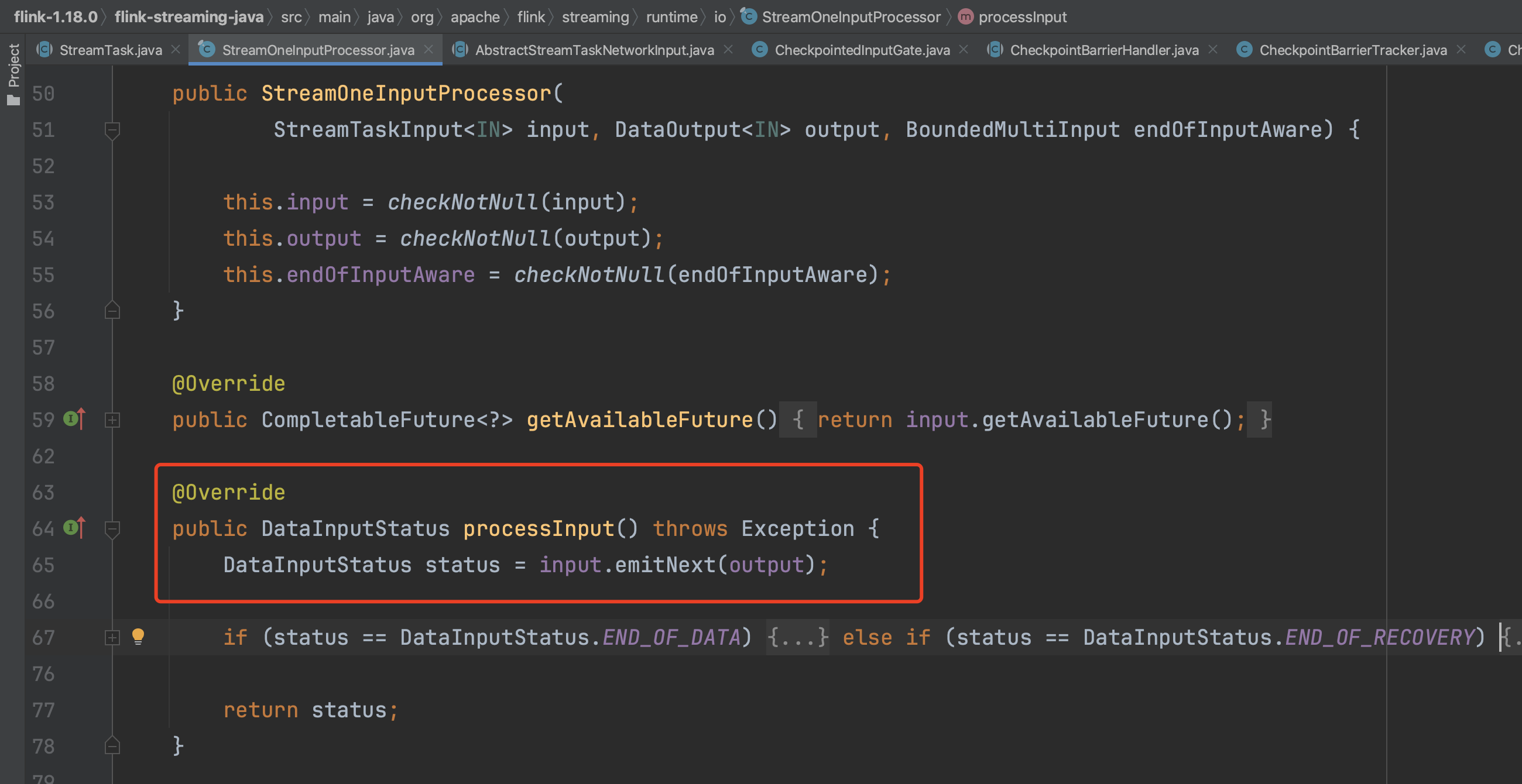
方法AbstractStreamTaskNetworkInput.emitNext(...)从数据通道中获取事件类型的数据元素交由具体的CheckpointBarrierHandler实现类处理。
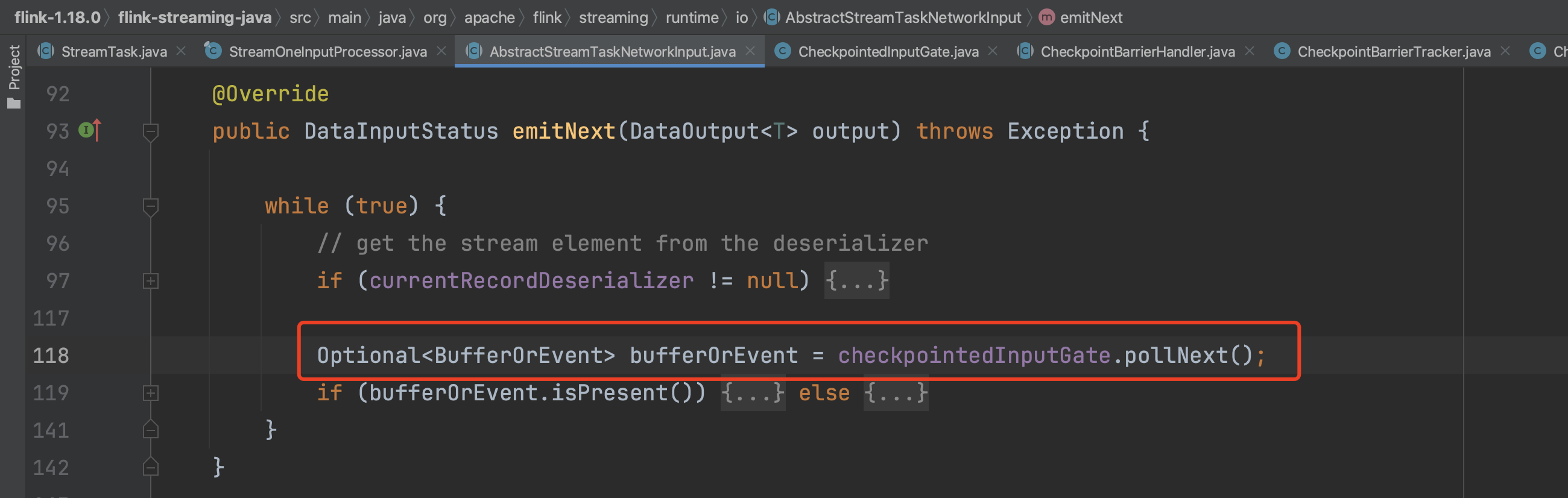
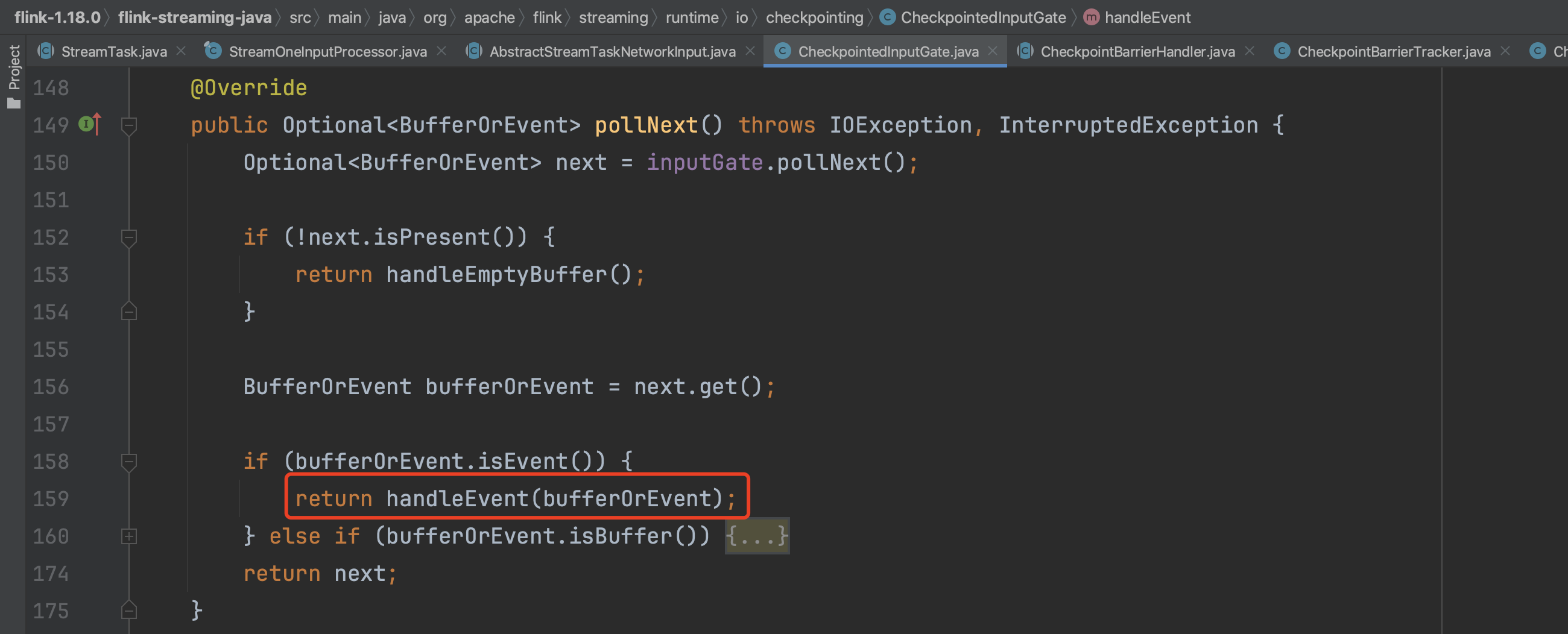
CheckpointBarrierHandler有2个实现类CheckpointBarrierTracker、SingleCheckpointBarrierHandler。根据用户配置的数据处理语义,CheckpointBarrierTracker对应AT_LEAST_ONCE语义,SingleCheckpointBarrierHandler对应EXACTLY_ONCE语义。CheckpointBarrierHandler具体实例创建过程可参考InputProcessorUtil.createCheckpointBarrierHandler(...)实现。
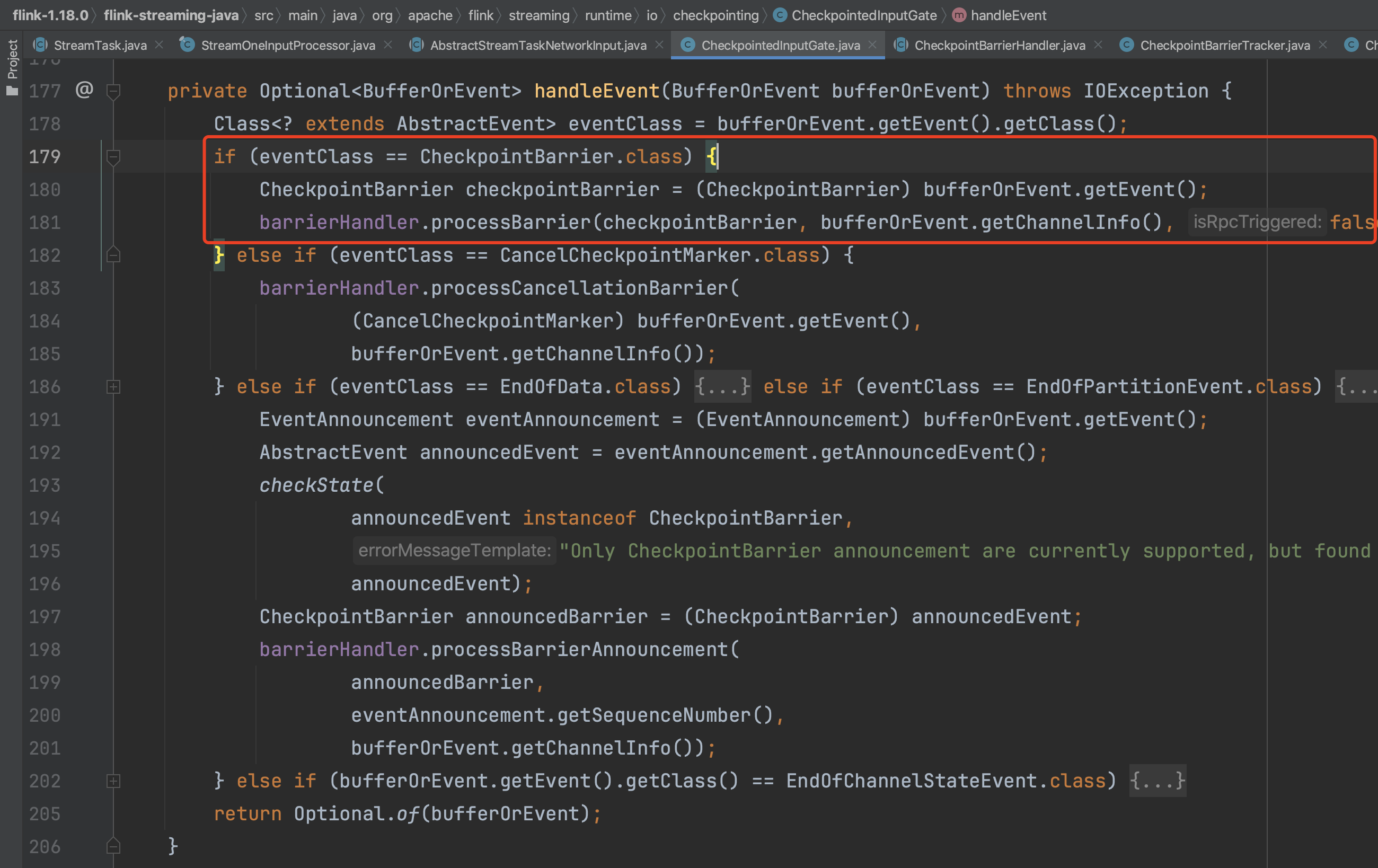
下面分别分析两种语义下CheckpointBarrierHandler Checkpoint处理过程。
(1)、EXACTLY_ONCE下Checkpoint的实现
执行方法SingleCheckpointBarrierHandler.processBarrier(...),进入到EXACTLY_ONCE语义下的Barrier处理。
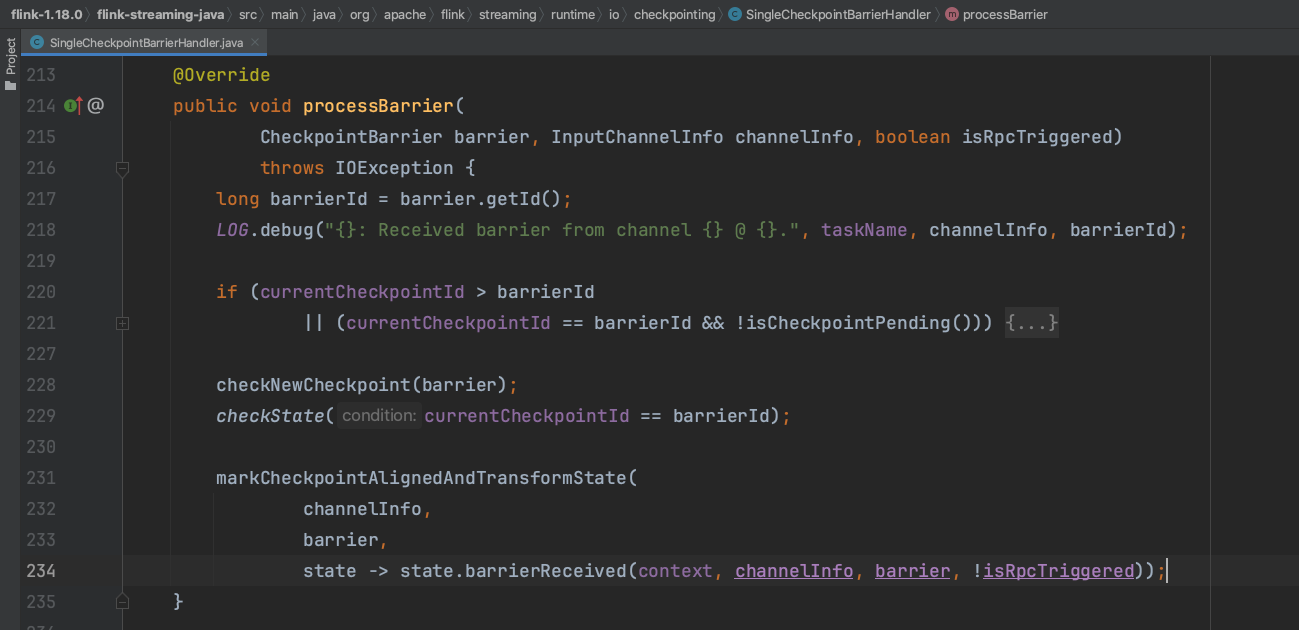
alignedChannels集合代表当前收到CheckpointBarrier消息的上游channel集合,targetChannelCount代表Task需要接收CheckpointBarrier消息的所有channel数量。当收到第一个channel发送的CheckpointBarrier消息时,Task开始进行barrier对齐,并将该channel设置为阻塞状态。当收到中间channel的CheckpointBarrier消息时只将channel设置为阻塞状态。当收到最后一个channel发送的CheckpointBarrier消息时开始触发Checkpoint逻辑处理,并取消所有阻塞的channel状态开始处理阻塞期间添加的缓存数据。
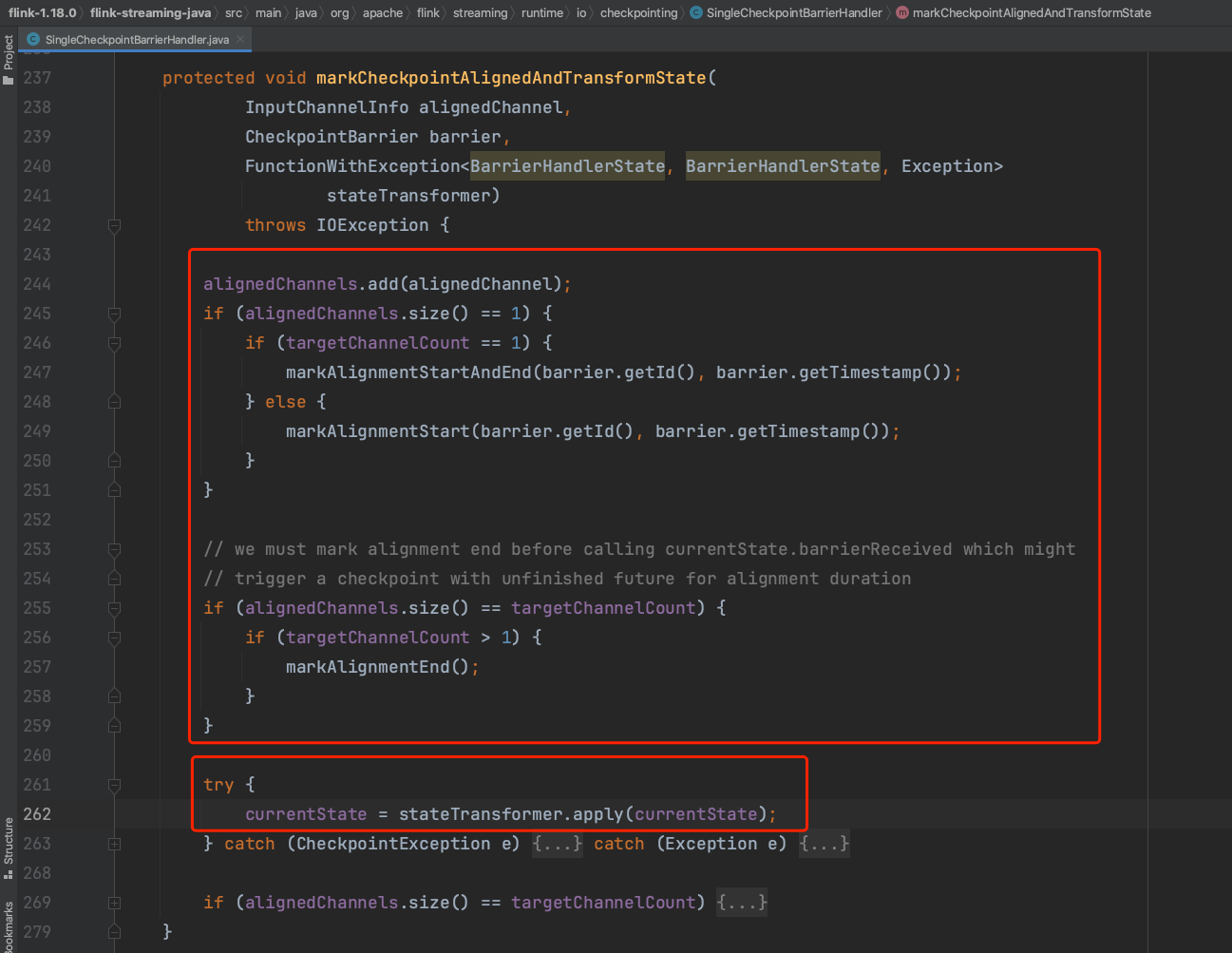
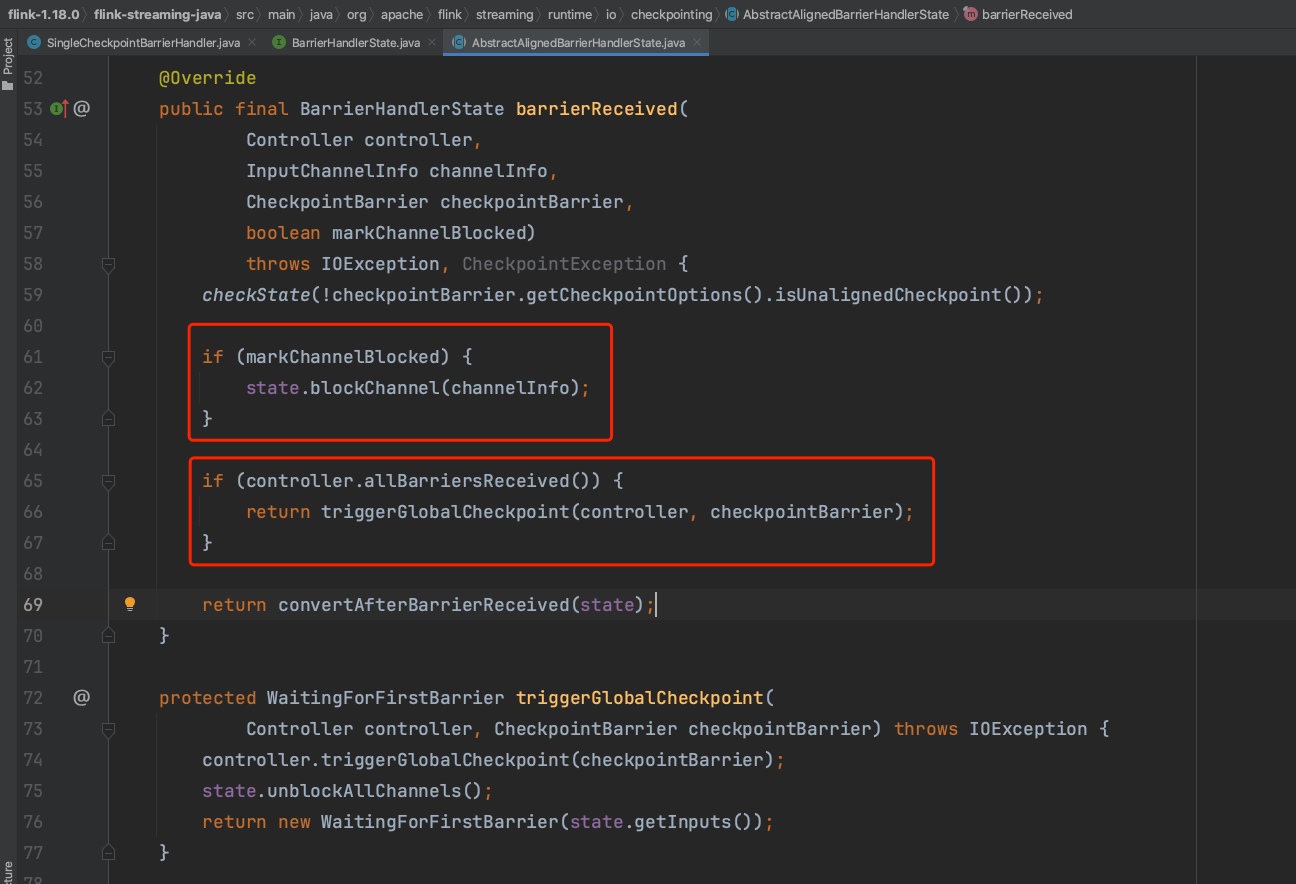
上图第262行代码即下图中barrierReceived(...)方法处理,在收到所有channel发送的CheckpointBarrier消息之前只阻塞channel,当收到所有channel发送的屏障消息时开始触发方法triggerGlobalCheckpoint(...)执行,Task端开始执行Checkpoint过程。
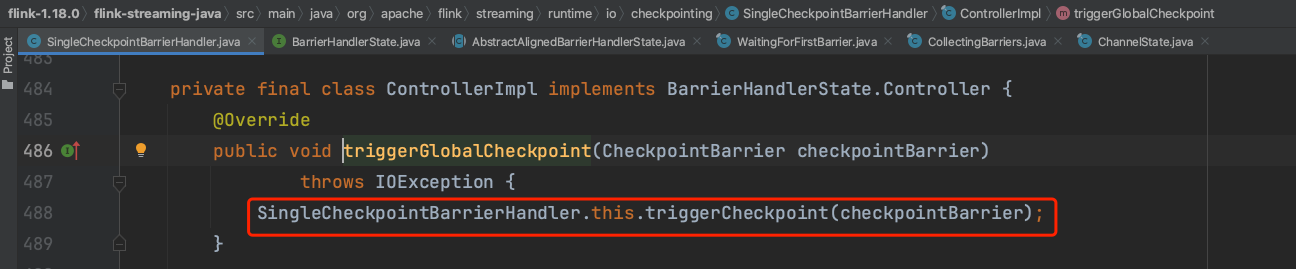
通过方法链调用SingleCheckpointBarrierHandler.triggerCheckpoint(...) -> CheckpointBarrierHandler.notifyCheckpoint(...)过程,转入到StreamTask的Checkpoint执行流程中去。
接下来的Checkpoint处理过程就和数据源Task Checkpoint处理过程保持一致,可参考上面介绍复习以下过程。
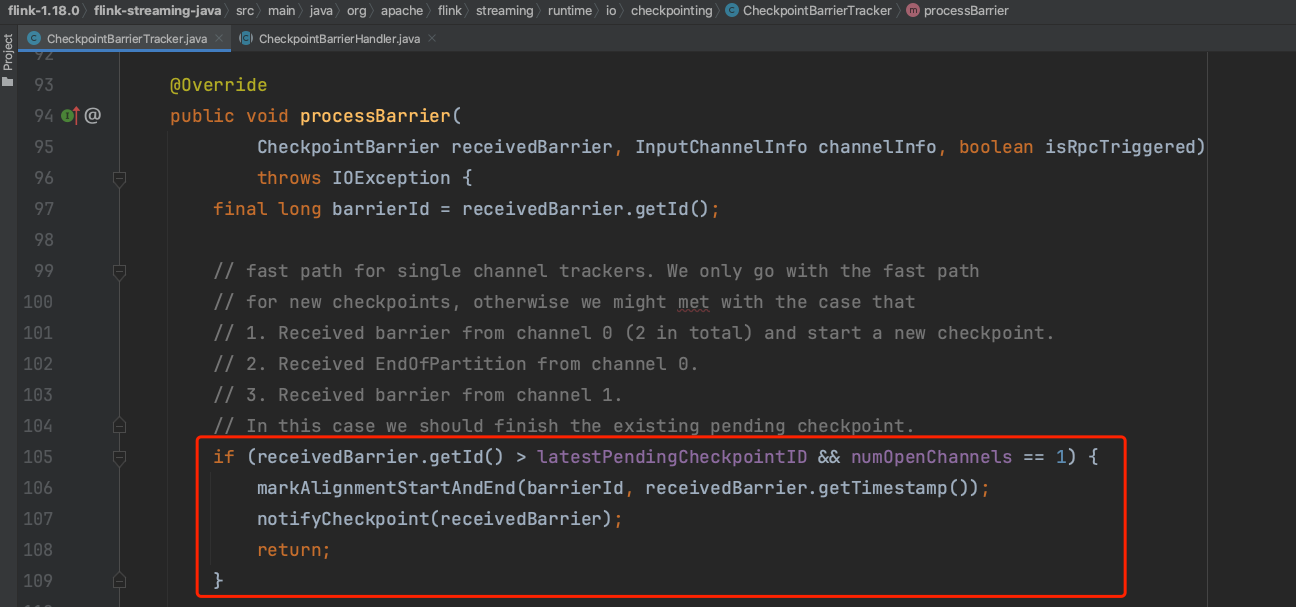
(2)、AT_LEAST_ONCE下的checkpoint实现
执行方法CheckpointBarrierTracker.processBarrier(...),进入到AT_LEAST_ONCE语义下的Barrier处理。
1)、当Task只有一个上游channel时,收到CheckpointBarrier消息时即刻触发方法notifyCheckpoint(...)执行Checkpoint过程。
2)、当Task有多个channe时,如果收到第一个channel发送的CheckpointBarrier消息,则更新下当前的CheckpointID信息。如果是收到中间channel发送的CheckpointBarrier消息时,几乎什么也不做。如果收到最后一个channel发送的CheckpointBarrier时,则开始触发Checkpoint执行过程。
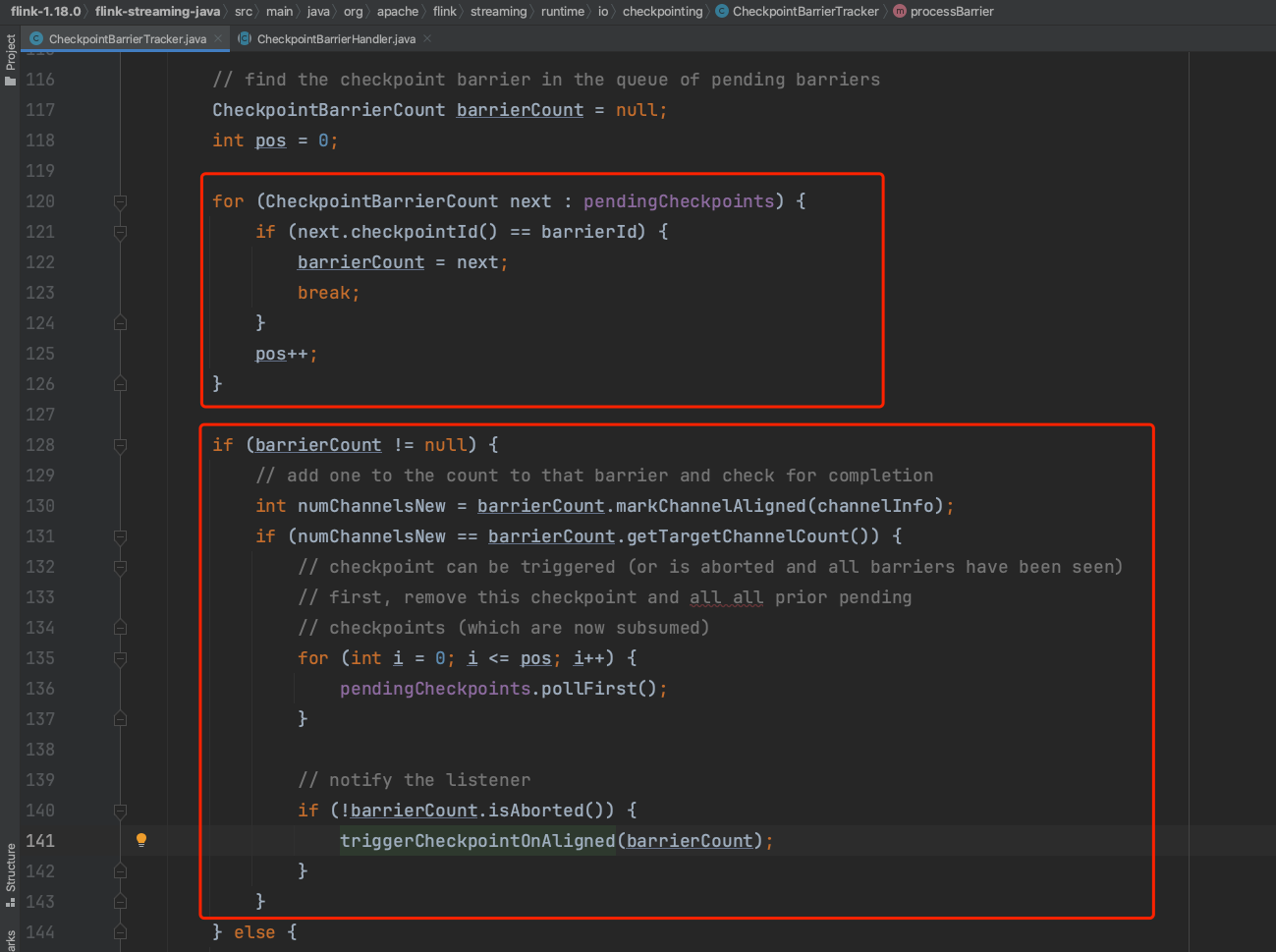

接下来的Checkpoint处理过程就和数据源Task Checkpoint处理过程保持一致,可参考上面介绍复习以下过程。
以上即为JobManager端和Taskmanager端执行Checkpoint过程,本篇随笔并未具体的分析状态数据存储过程,该过程放到下篇随笔分析。
