
Flink源码解析(十六)——Flink Task启动过程解析
在随笔十五最后只是粗略解析到Task初始化过程中的重要信息,但并未详细查看Task构造函数内部构成过程,本篇随笔继续解析Task构造函数内部的构造事宜,继而解析StreamTask启动过程。
一、核心对象说明
1、ResultPartitionWriter:ResultPartitionWriter面向的是Buffer,在数据传输层次中处于最低层,其子类实现中包含一个BufferPool组件,提供Buffer资源。子类实现中包含一个数组结构ResultSubpartition[] subpartitions的子分区组件,用来承接上层RecordWriter对象分发下来的数据。ResultPartitionWriter类实现层级如下:ResultPartitionWriter(I) -> ResultPartition(A) -> BufferWritingResultPartition(A) -> PipelinedResultPartition(C)
2、RecordWriter:RecordWriter负责将Task处理的数据输出,其主要面向StreamRecord。RecordWriter比ResultPartitionWriter层级要高,每一个RecordWriter实例都包含一个ResultPartitionWriter子类实例。RecordWriter主要有两个子类实现,ChannelSelectorRecordWriter、BroadcastRecordWriter。子类中包含设置StreamRecord分区的分区器信息,用来决定每一个StreamRecord数据所属的低层级ResultPartitionWriter实例中subpartitions数组组件的下标元素。RecordWriterDelegate是RecordWriter类的代理类。代理零个、一个、多个RecordWriter对象。
3、Output:Output接口继承于Collector接口,Collector接口即为flatMap等api方法中Collector参数类型。Output是算子向下游传递的数据抽象,用来向下游发送StreamRecord、Watermark、LatencyMark等事件元素。其主要接口继承体系如下:Collector(I) -> Output(I) -> WatermarkGaugeExposingOutput(I) -> {BroadcastingOutputCollector(C)、ChainingOutput(C)、RecordWriterOutput(C)}。RecordWriterOutput主要负责数据跨网络的输出,ChainingOutput主要在算子链内传递数据,BroadcastingOutputCollector包含一组Output,向下游所有Task广播数据。
4、数据传递:Flink的数据传递过程主要分为三类,第一类是算子链内部算子之间的数据传递,算子链所有算子在同一个本地线程内链式调用processElements()方法。第二类是本地线程间数据传递,存在某些有上下游关系的Task被分配到同一个机器节点的TaskManager中,以LocalInputChannel为中介,利用java对象的wait()/notifyAll()机制来等待上游数据发送及上游数据具备时唤醒数据消费动作。第三类跨网络间数据传递,利用RemoteInputChannel组件以及Netty的请求响应机制来跨网络间传递数据。
5、StreamInputProcessor输入处理器:StreamInputProcessor是StreamTask中读取数据的抽象,负责完成数据的读取、处理、输出给下游的过程。在其子类实现中往往会包含StreamTaskInput、DataOutput两个重要的组件,来共同完成数据读取、处理、输出给下游动作。
6、StreamTaskInput Task输入:StreamTaskInput是StreamTask数据输入的抽象,其包含InputGate组件,InputGate用来读取上游Task的数据。
7、DataOutput Task输出:其子类实现是StreamTaskNetworkOutput,StreamTaskNetworkOutput只负责将数据交给算子来进行处理,算子处理完数据后写出数据的动作由上面的Output负责。
二、Task构造过程解析
查看Task构造函数会发现其中包含一系列重要成员变量的赋值动作,包括nameOfInvokableClass、memoryManager、ioManager、taskStateManager、partitionWriters、inputGates等。partitionWriters、inputGates分别代表Task的输出及输入操作,本节详细解析Task输入输出操作的构造过程。
1、createResultPartitionWriters(...)方法负责创建partitionWriters成员变量,由入参可知包含Task提交过程中创建的ResultPartitionDeploymentDescriptor实例信息,即Task的输出信息。
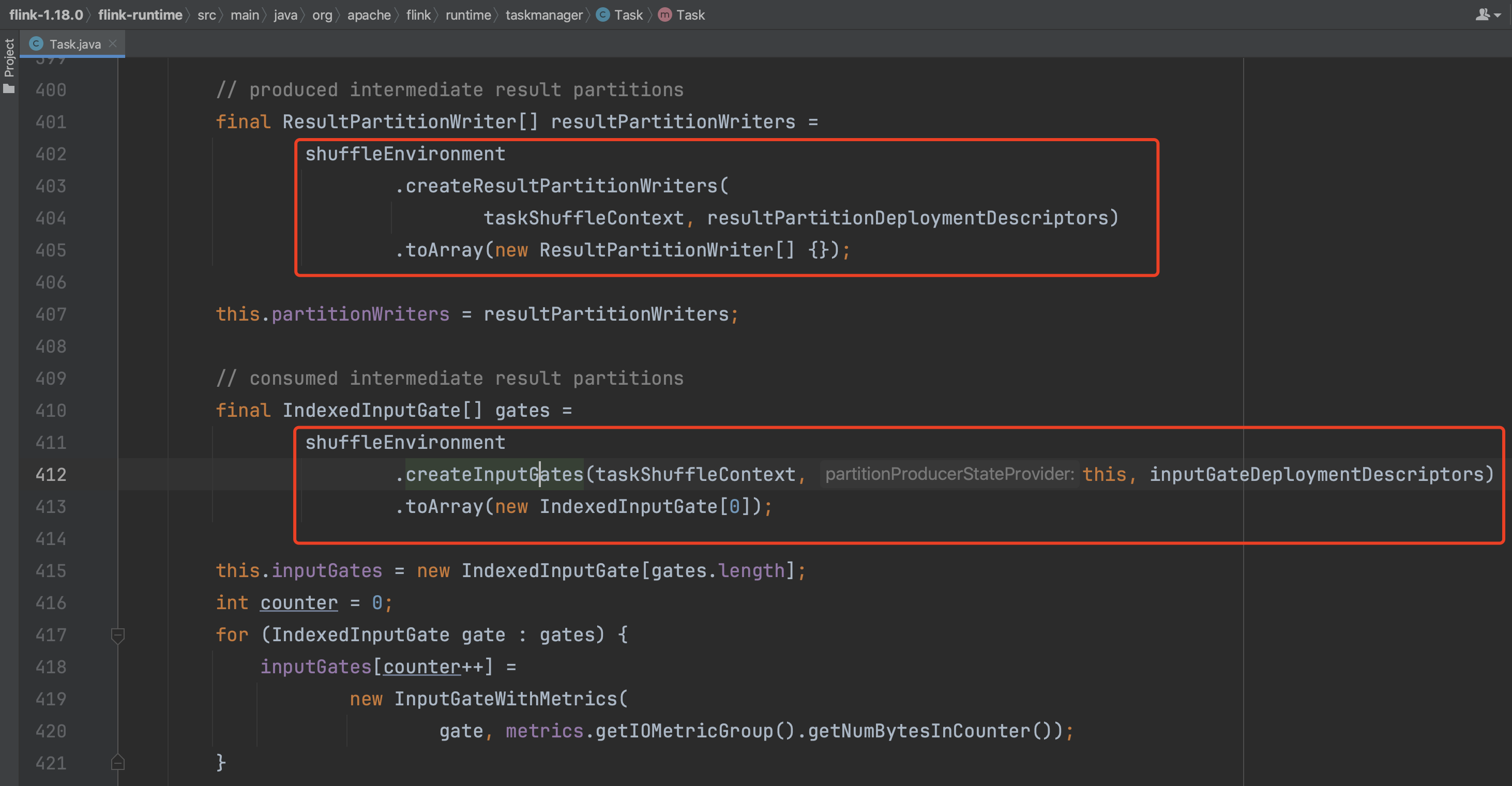
进入createResultPartitionWriters(...)方法中可知会遍历Task的ResultPartition列表,ResultPartition列表长度即下游有多少个算子(注意,是不同算子的实例,不是同一个算子的不同算子实例)消费该Task的数据。

进入到工厂类ResultPartitionFactory中开始创建ResultPartition信息,由类继承关系可知抽象类ResultPartition继承于ResultPartitionWriter接口。根据不同算子节点的分区信息,desc.getNumberOfSubpartitions()方法会返回下游一个ExecutionJobVertex中有多少个ExecutionVertex实例消费该Task实例的数据。ResultPartition列表长度代表下游有多少个算子消费该Task数据,desc.getNumberOfSubpartitions()代表下游同一个算子有多少个算子实例消费该Task数据。
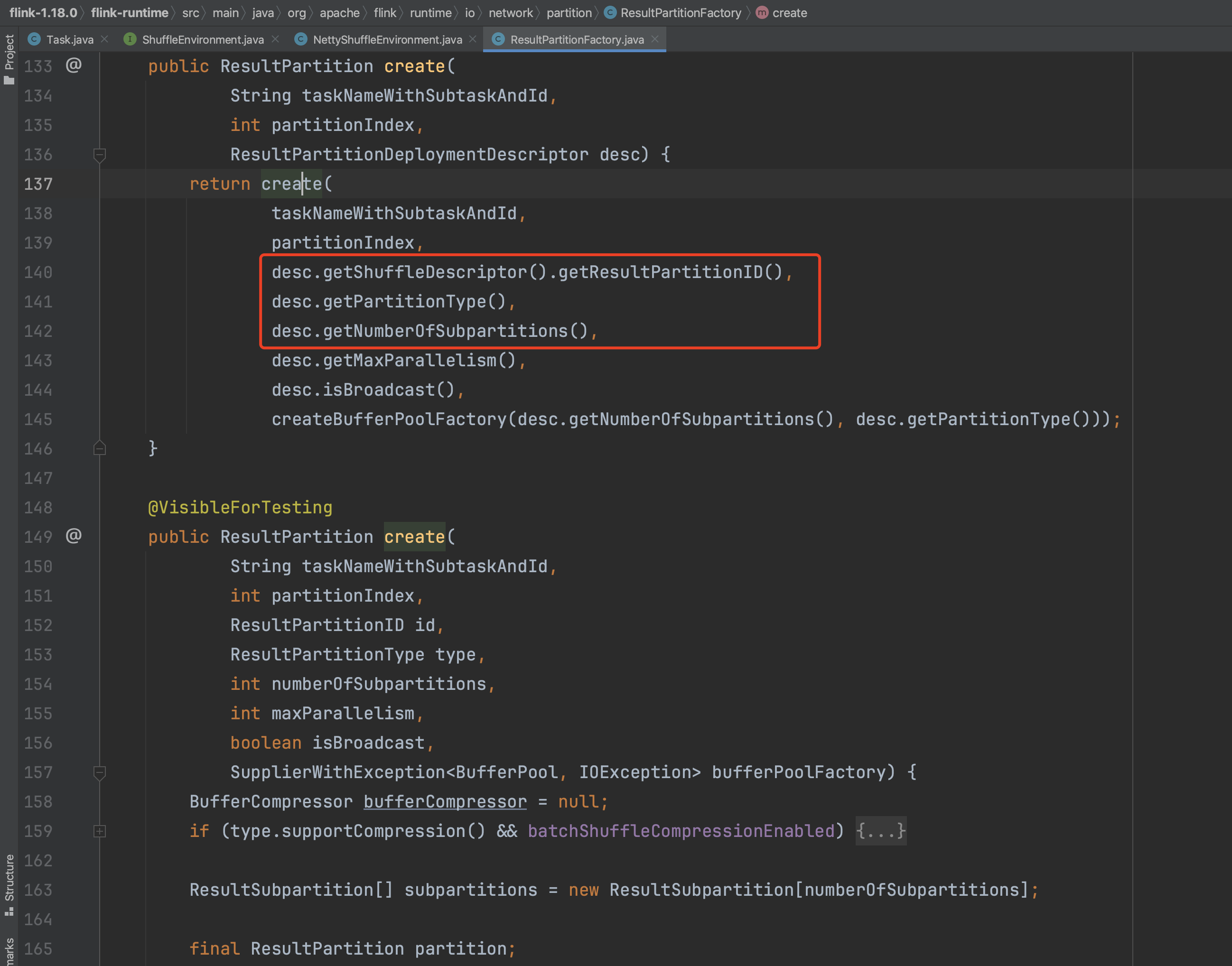
首先创建隶属于该Task的ResultPartition实例,根据numberOfSubpartitions参数,遍历生成ResultSubpartitions数组成员。ResultSubpartitions数组是ResultPartition实例的成员变量。
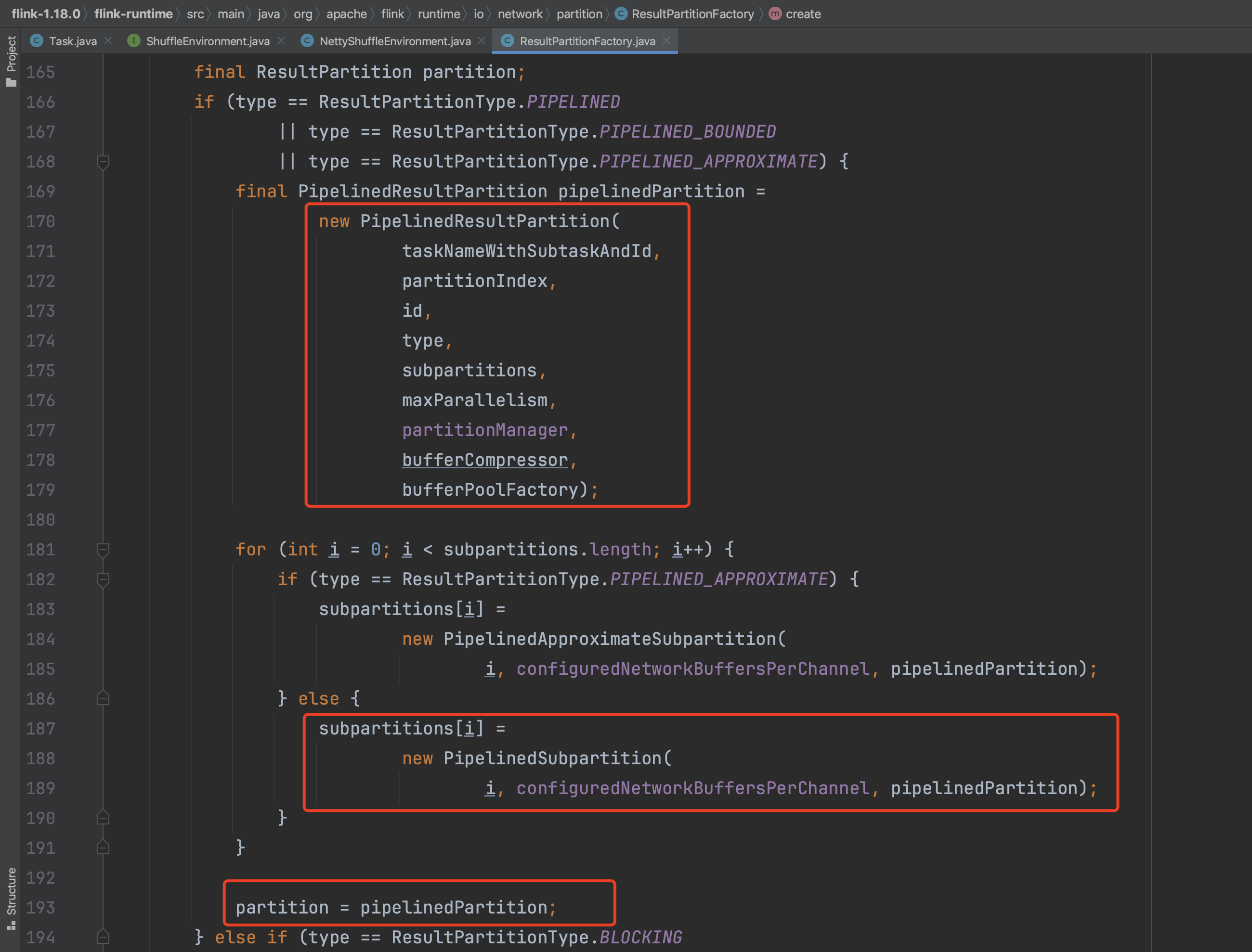
以上即为Task实例partitionWriters成员生成过程,接下来解析inputGates成员生成过程。
2、createInputGates(...)方法为inputGates的生成入口,入参包含Task提交过程中创建的InputGateDeploymentDescriptor实例信息即Task的输入信息。InputGateDeploymentDescriptor个数代表该Task消费上游多少个算子数据。遍历InputGateDeploymentDescriptor个数开始创建一个个InputGate实例信息。
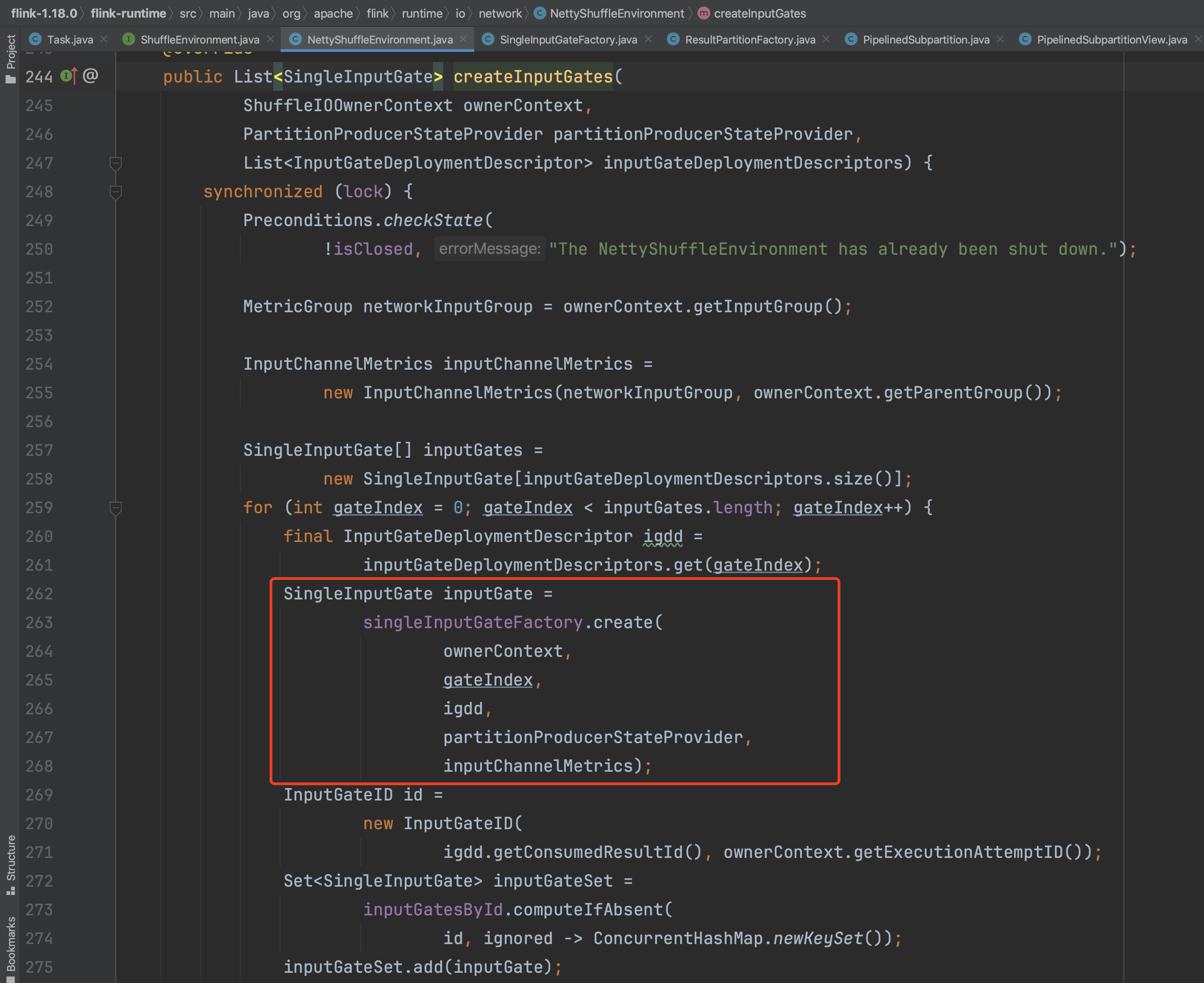
SingleInputGate实例包含一个重要的成员变量BufferPoolFactory,它负责生成InputGate的数据Buffer空间。

后去SingleInputGate的subpartitionIndexRange信息,流式作业subpartitionIndexRange范围一般都是1。接着开始创建SingleInputGate实例,赋值一系列的成员变量的初始值。调用createInputChannels(...)方法开始创建每个SingleInputGate的InputChannel数组成员。
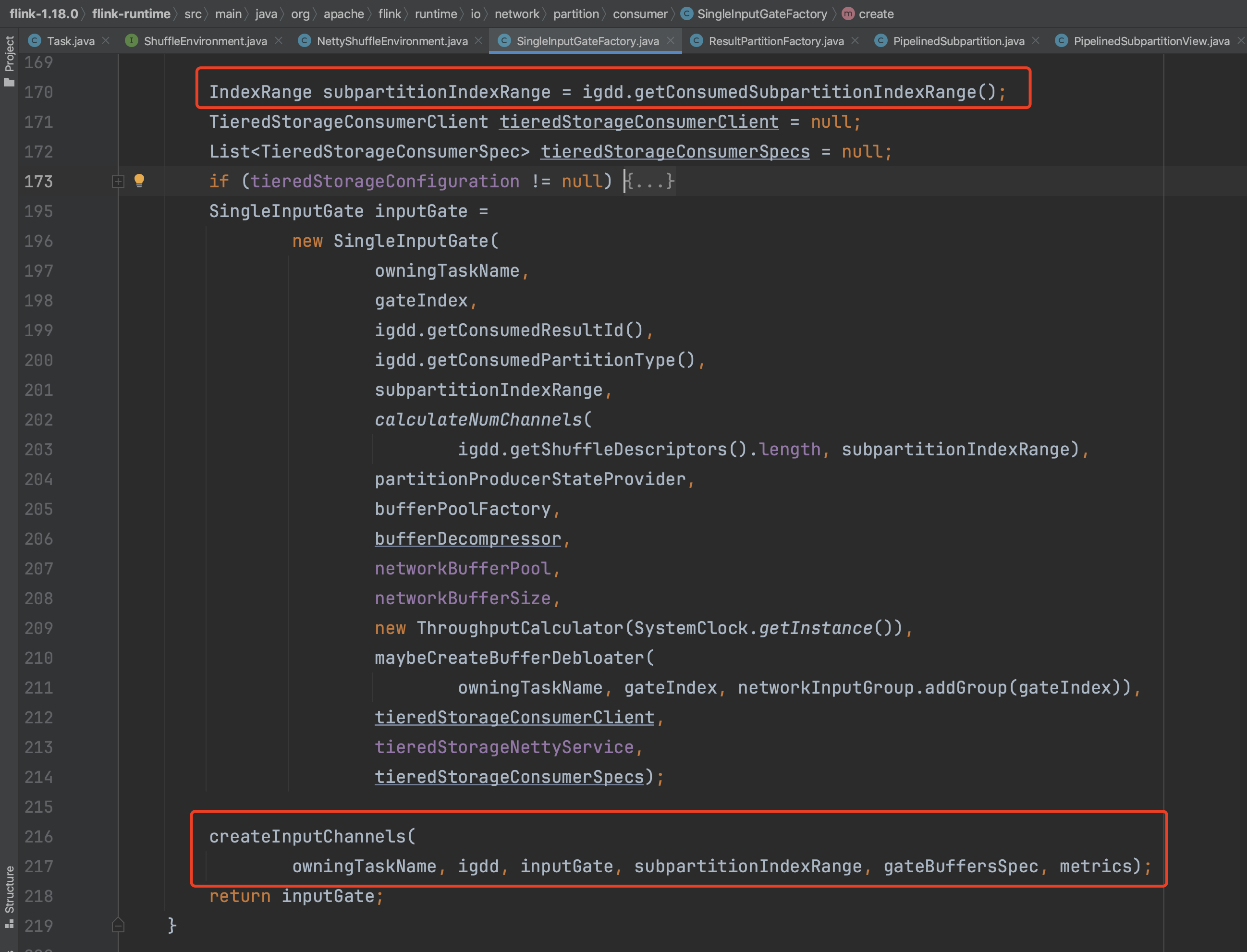
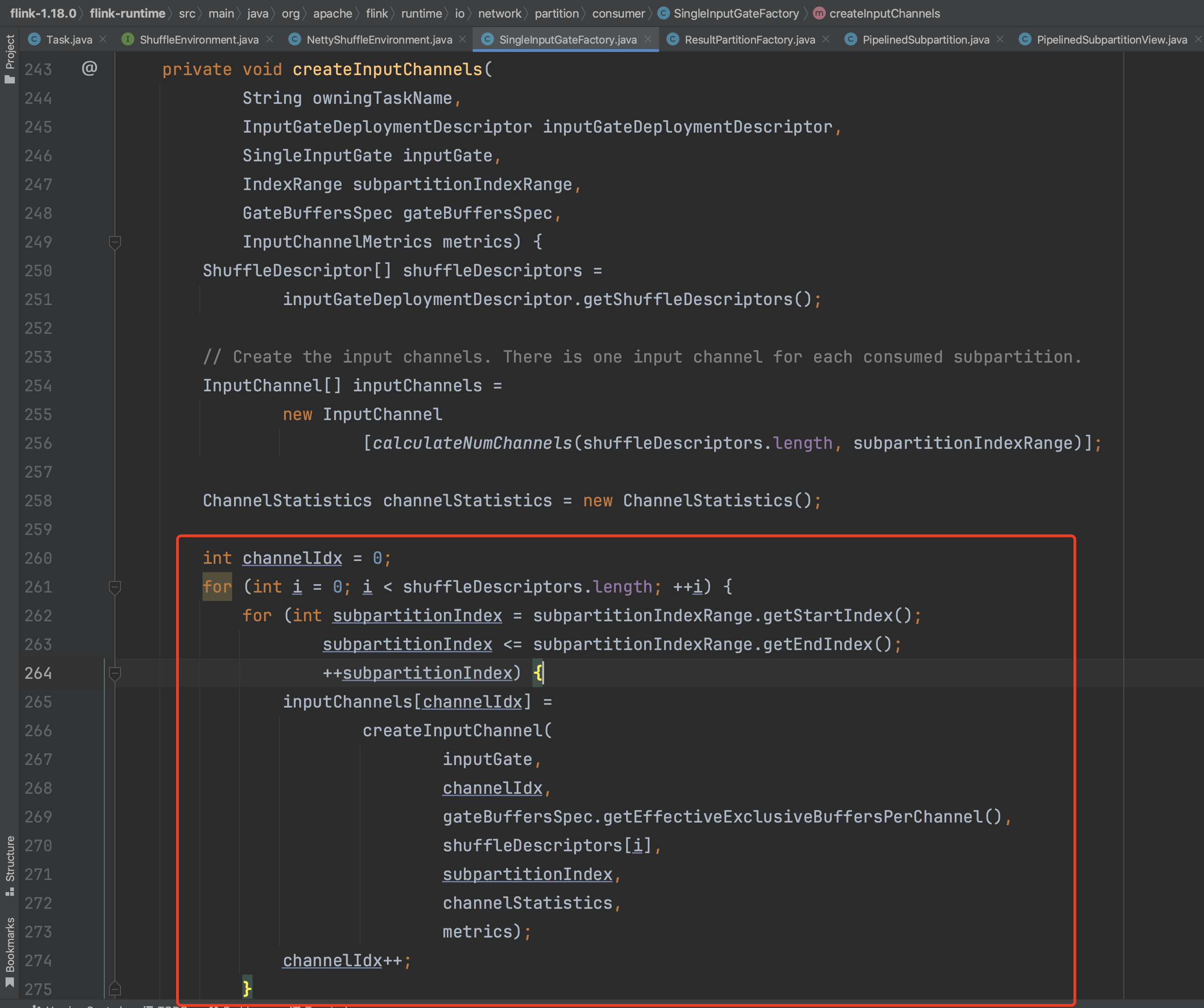
多数情况下每个算子有多个算子实例,Task会为每个上游算子的每个算子实例创建一个InputChannel通道信息。嗯,一个Task会消费上游算子的多个算子实例,通过InputChannel和每个算子实例产生关联关系。流式计算中subpartitionIndexRange范围一般都是1。
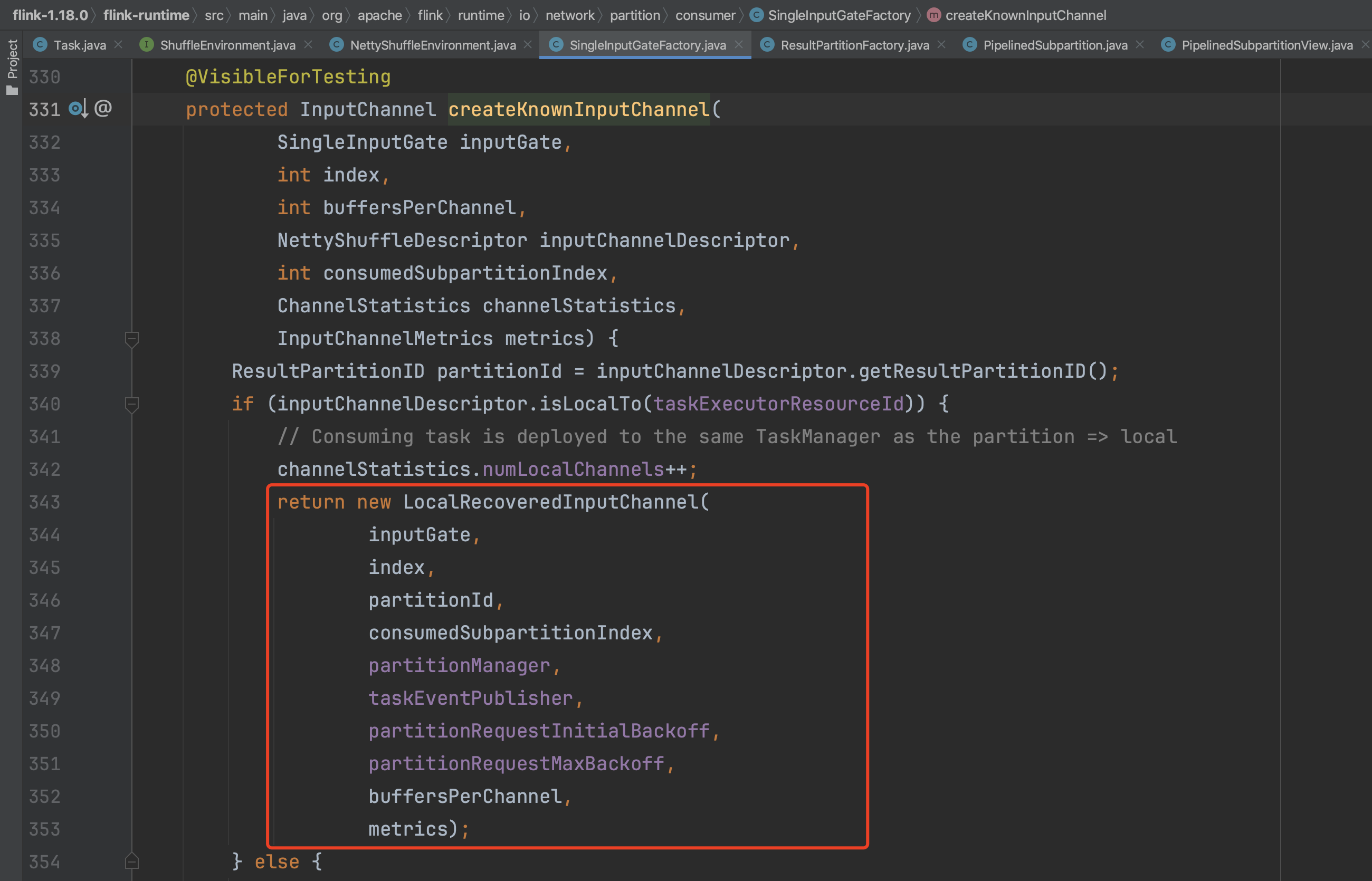
根据上下游Task实例所在的机器位置信息判断创建不同的LocalRecoveredInputChannel、RemoteRecoveredInputChannel类型实例。
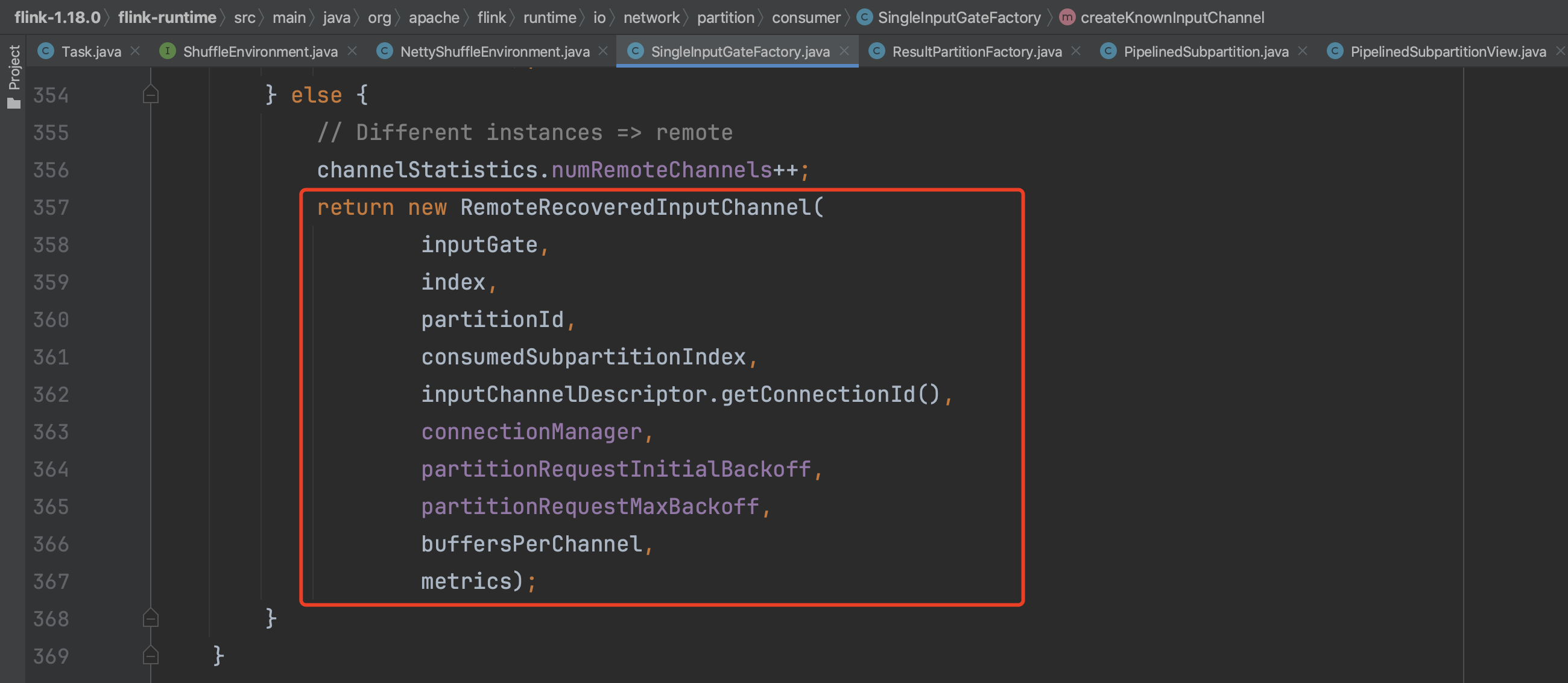
以上即为Task实例初始化过程中输入输出操作的创建过程,接下来解析StreamTask的构成过程。
三、StreamTask构造过程解析
Task类继承于Runnable接口,在创建完Task实例后,TaskExecutor.submitTask(...)就会运行Task.run()方法,开始Task的运行过程。
1、通过Task.run()方法跳转到doRun()方法,在doRun()方法里会以反射的形式新建TaskInvokable invokable的值。一般来说,StreamTask继承于TaskInvokable,此处反射创建的invokable实例就是StreamTask实例。
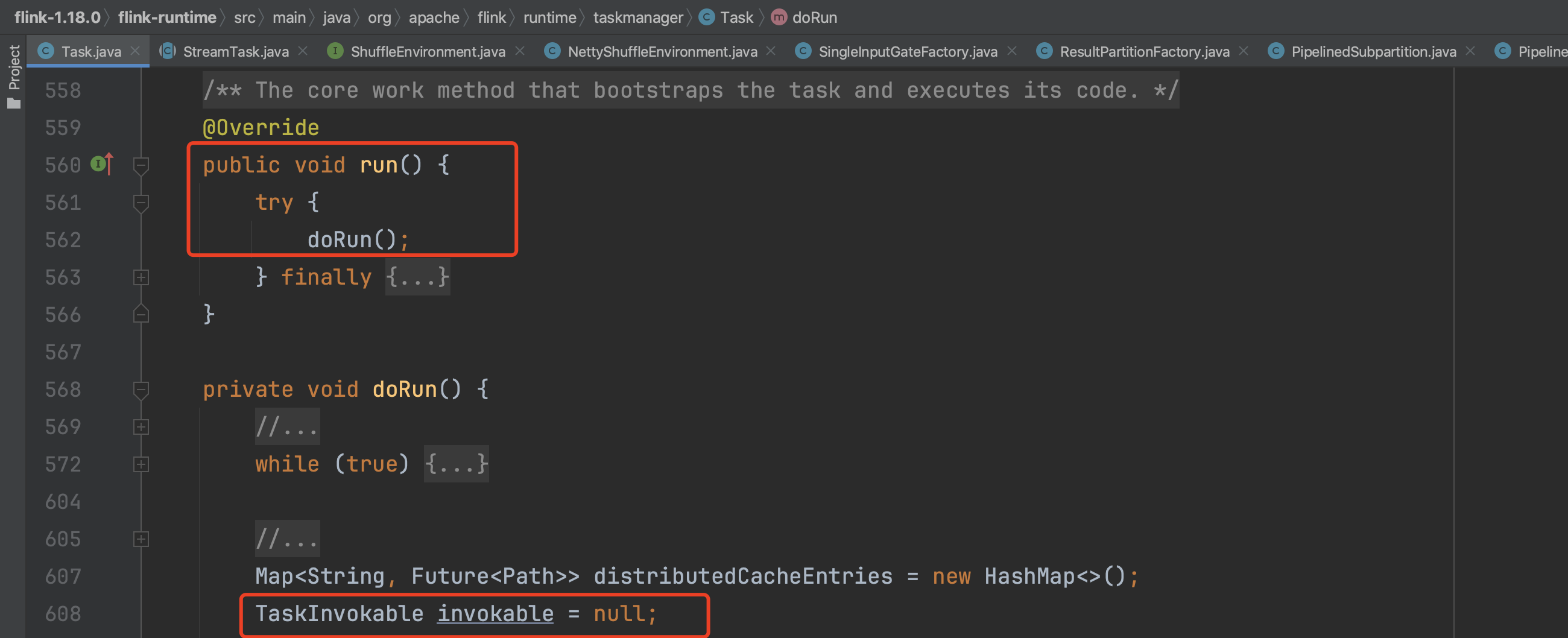
此处setupPartitionsAndGates(...)方法主要作用是设置ResultPartition和InputGate的BufferPool信息。

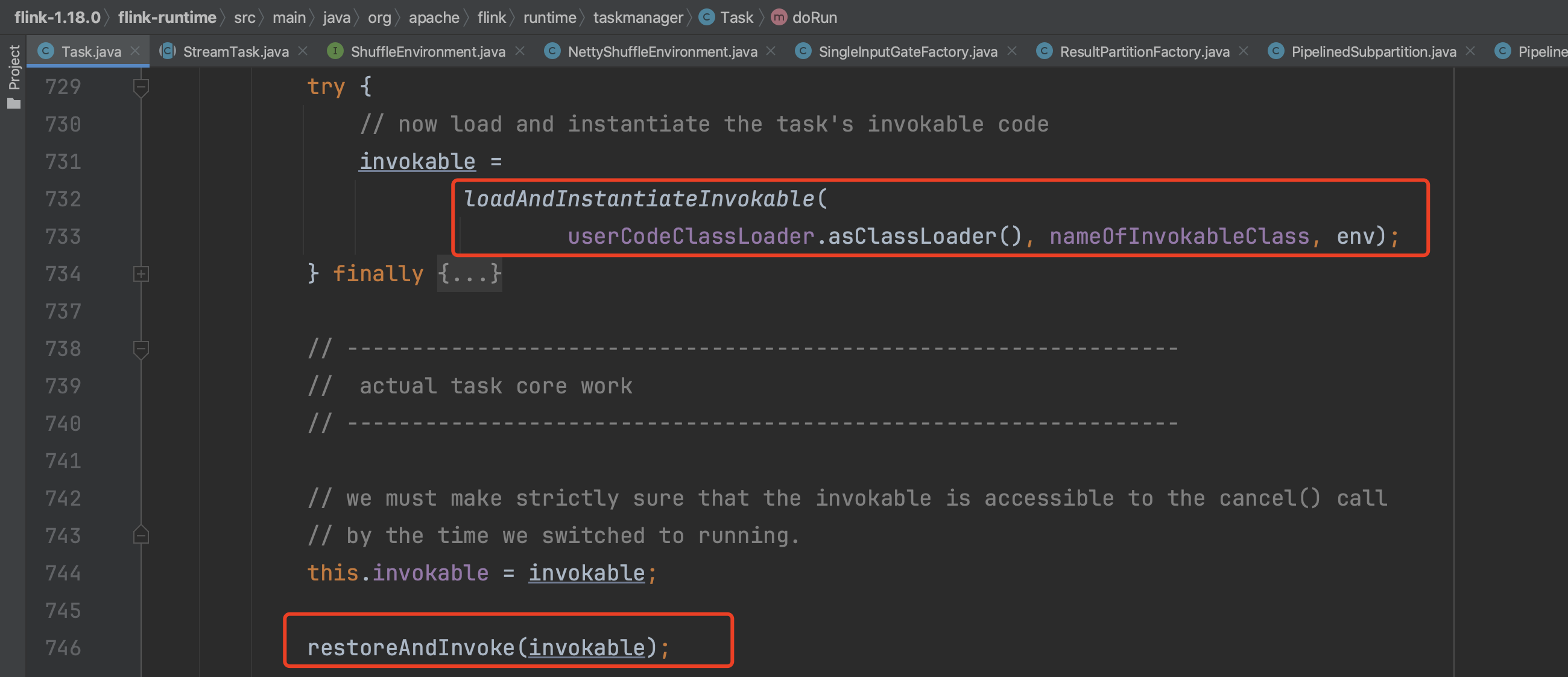
如下图,获取只包含Environment入参类型的StreamTask构造函数,最后新建StreamTask实例。
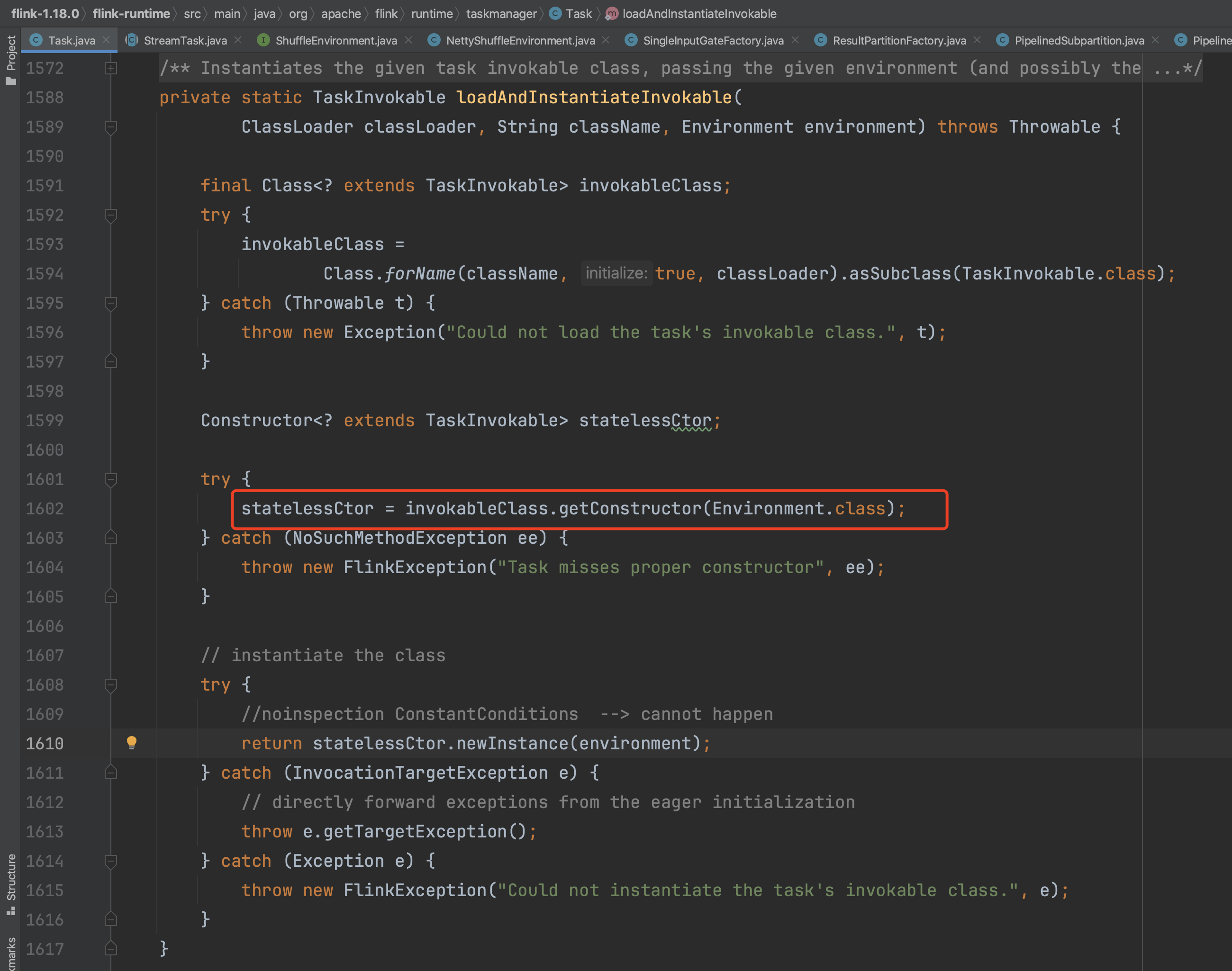
以下为只包含Environment入参类型的StreamTask构造函数的调用过程。
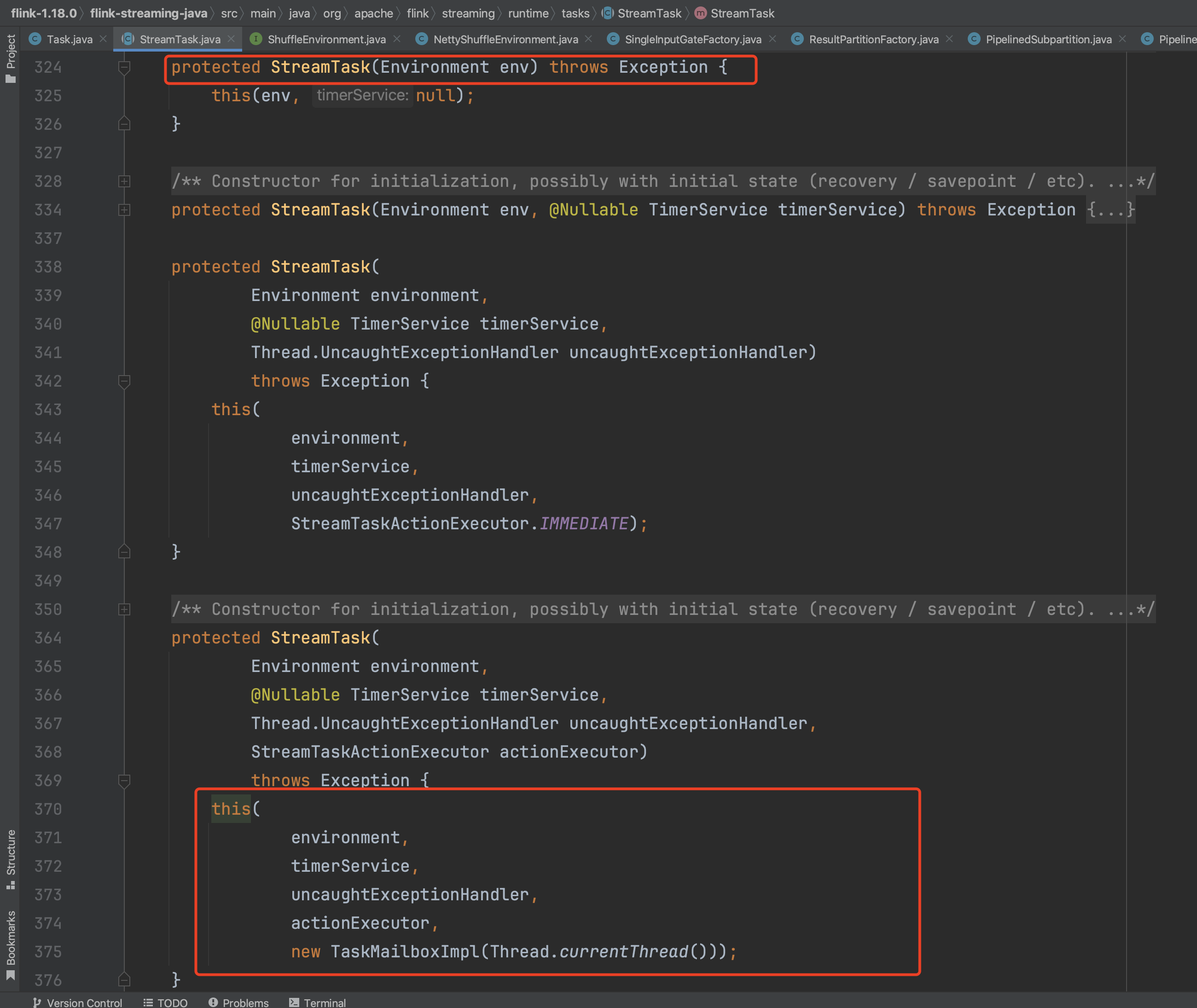
进入到下图的构造函数中,开始StreamTask初始化过程。在Flink应用执行数据处理、checkpoint执行、定时器触发等过程中可能会同时修改状态,Flink系统通过引入Mailbox线程模型来解决状态操作不一致的情况。其中MailboxProcessor负责拉取、处理Mailbox中的Mail,即checkpoint执行、定时器触发等动作,而MailboxProcessor成员变量MailboxDefaultAction mailboxDefaultAction默认动作负责DataStream上普通消息的处理,包括:处理Event、barrier、Watermark等。TaskMailboxImpl为Mailbox的实现,负责存储checkpoint执行、定时器触发等动作,MailboxExecutorImpl负责提交生成checkpoint执行、定时器触发等动作。Mailbox线程模型细节信息可以通过其他途径了解。下图在生成MailboxProcessor实例时,processInput()方法作为成员mailboxDefaultAction的值,负责常规的数据处理。下篇随笔详细解析Task读写数据的过程。
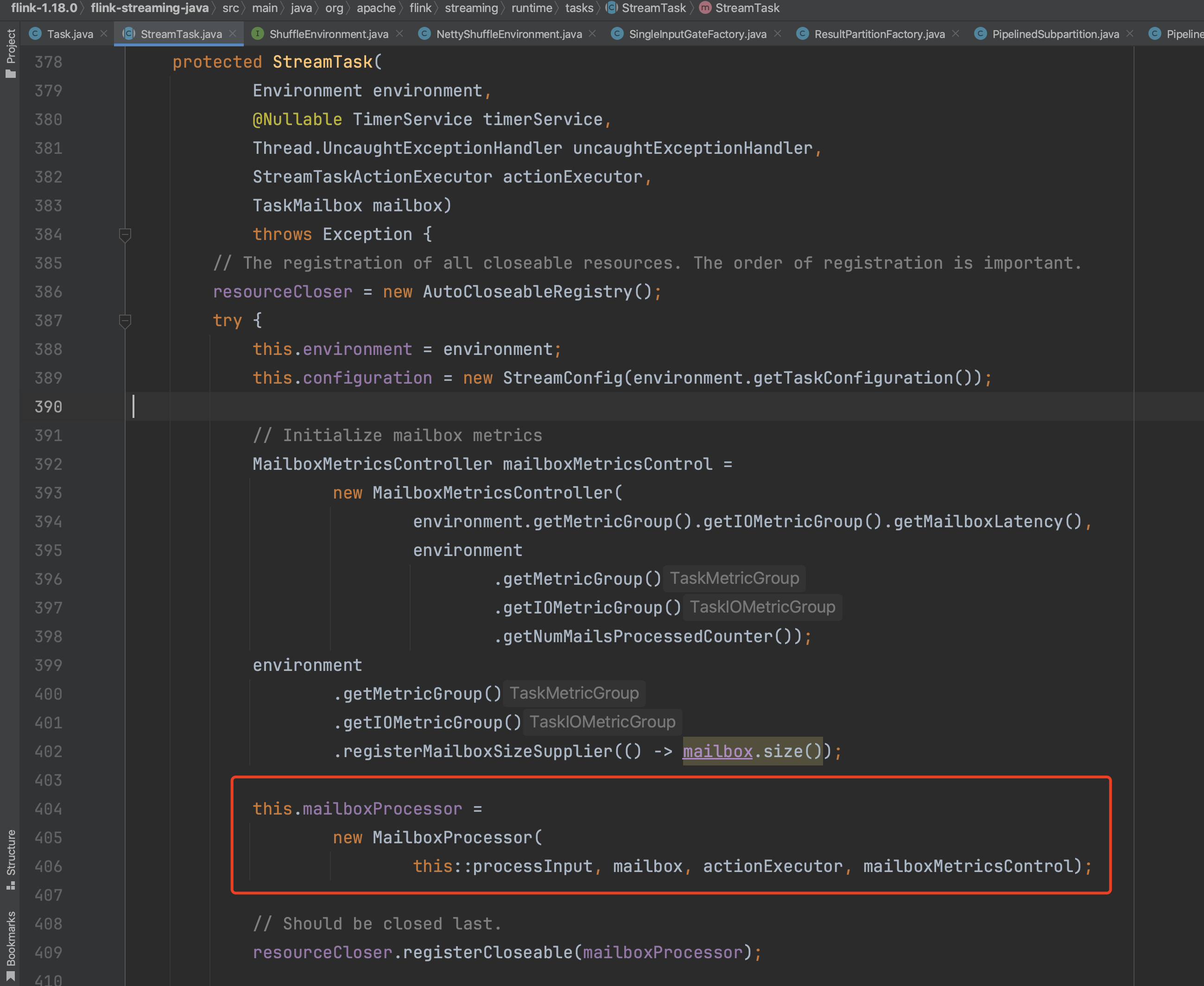
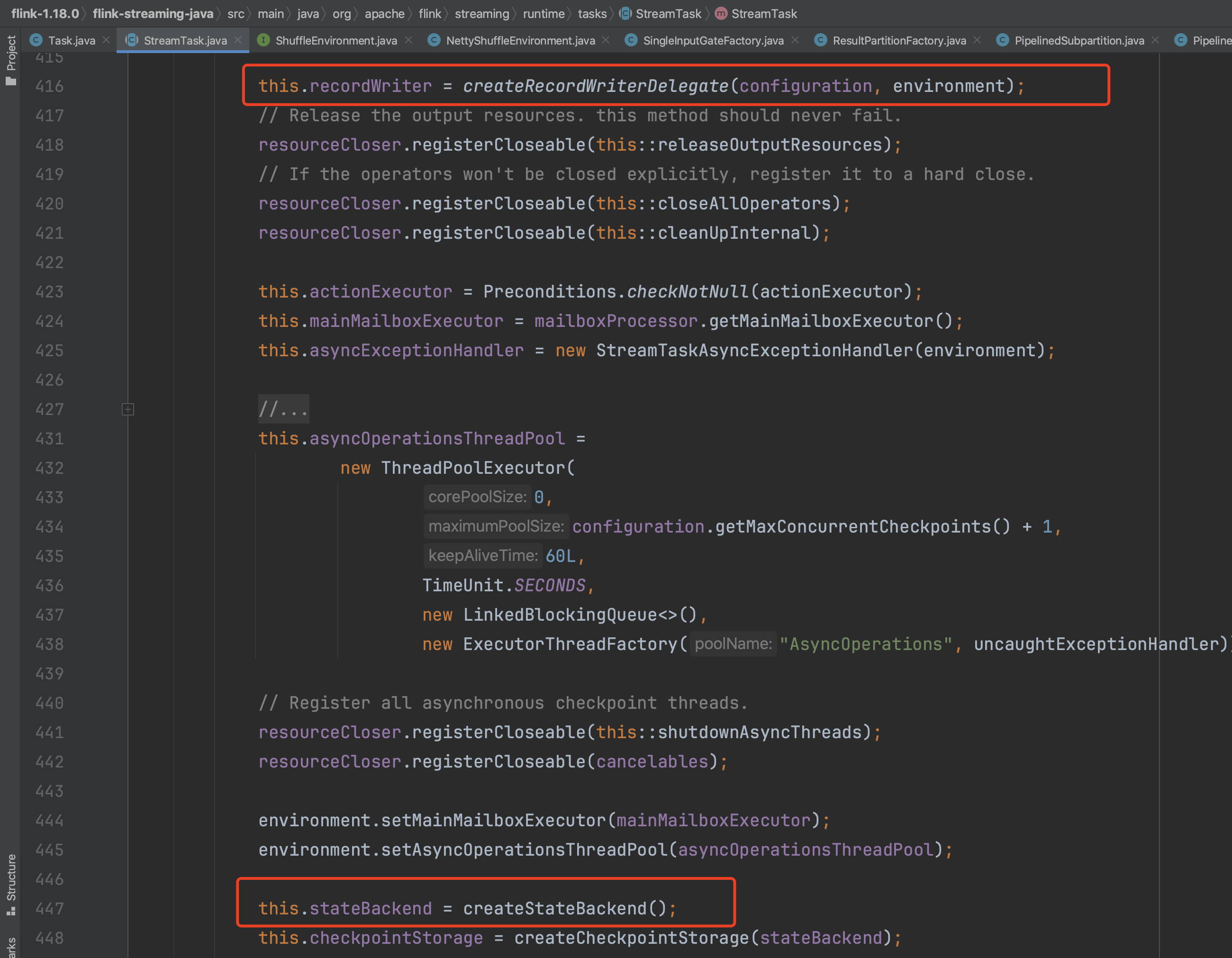
在StreamTask初始化过程中,还有两个比较重要操作,RecordWriter的创建和StateBackend的创建。其中方法createRecordWriterDelegate(...)是RecordWriter创建入口。
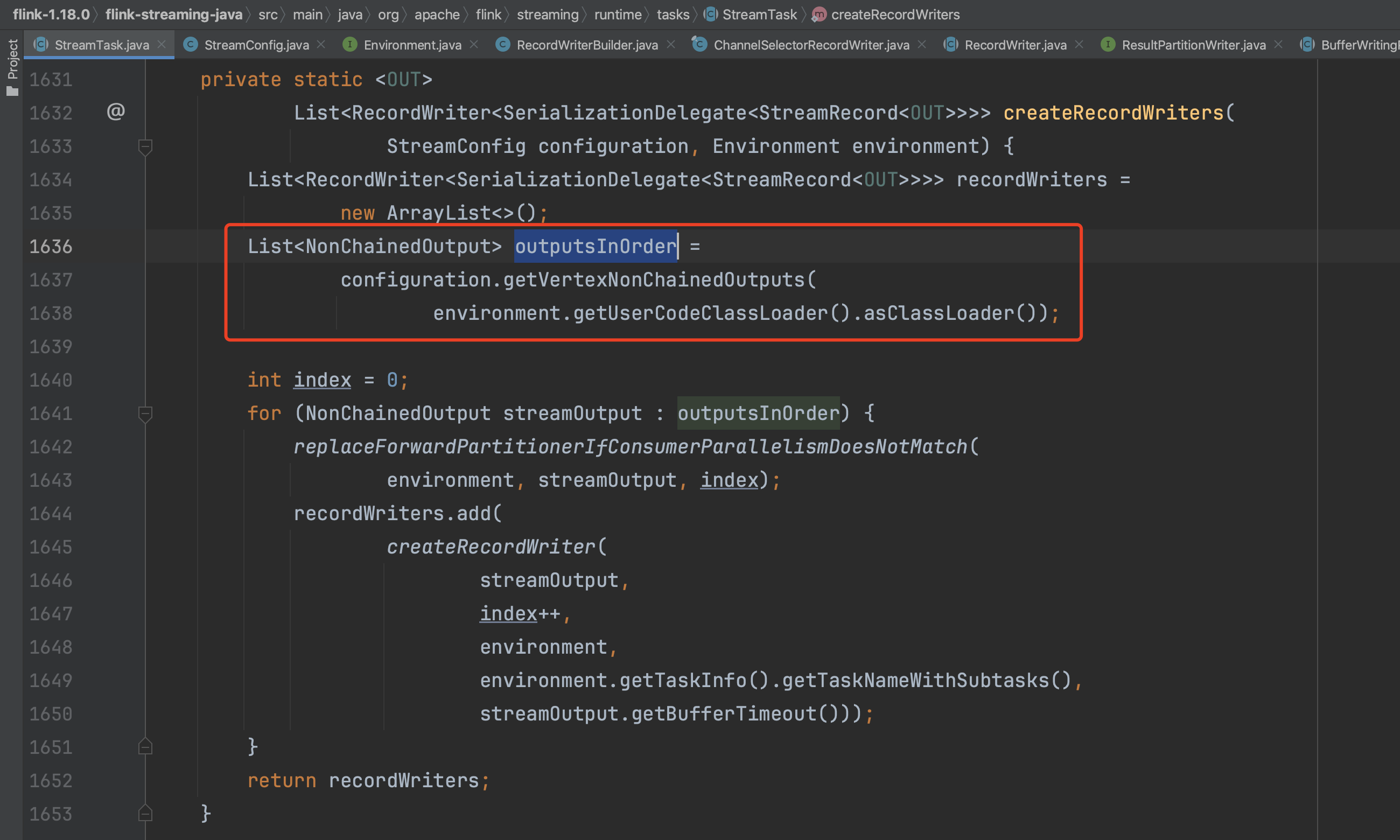
以Task配置信息、执行环境信息为入参进入到方法createRecordWriters(...)中去。

下图可知,先获取每个算子不可chain下游的出边集合,遍历该集合,根据每个不可chain下游算子的出边创建一个RecordWriter实例。
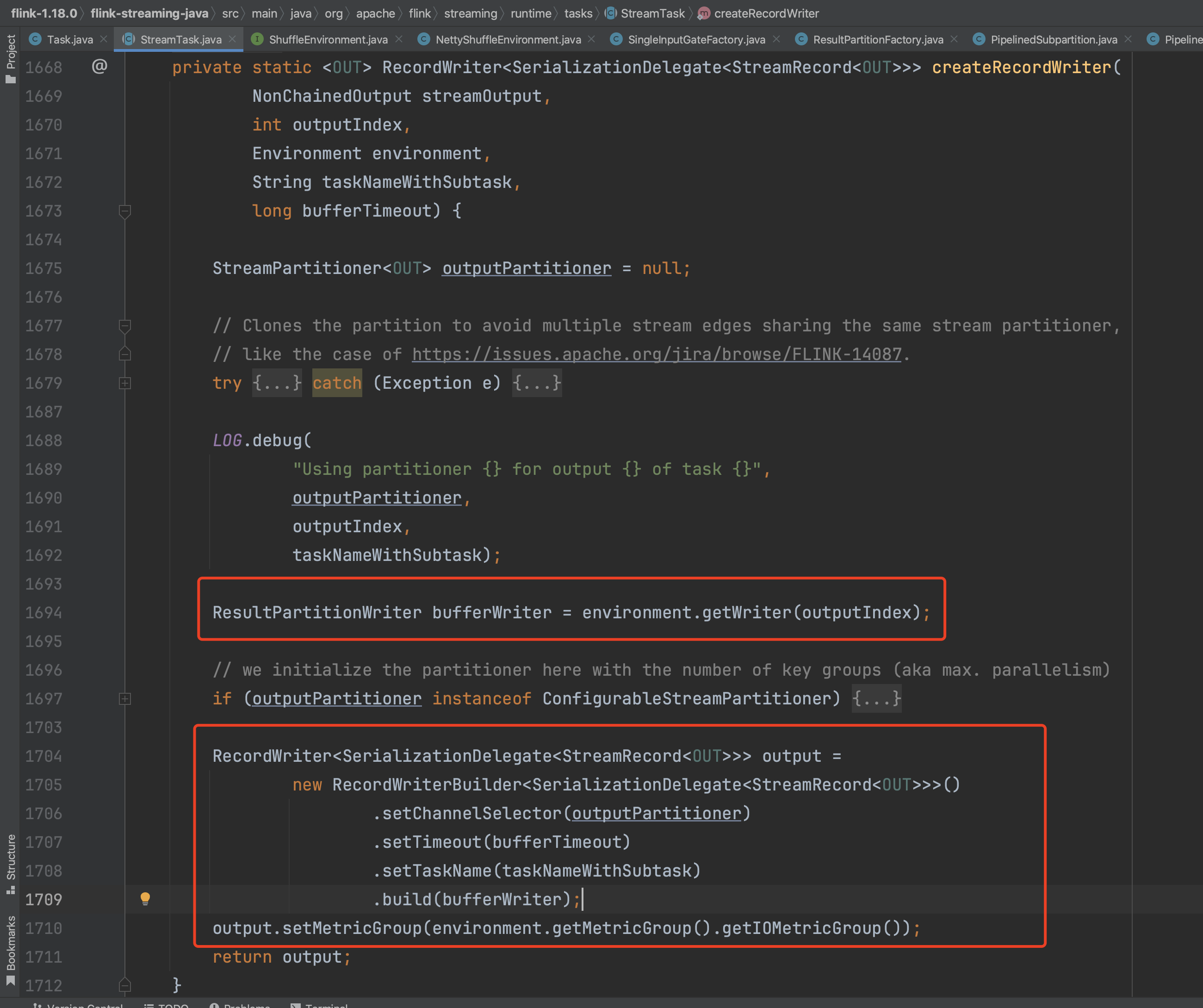
下图为创建RecordWriter实例的过程,通过出边实例获取边上的分区信息,再根据下标获取对应的ResultPartitionWriter实例,通过RecordWriterBuilder工具类创建出RecordWriter实例。以上即为RecordWriters的创建过程。
接下来继续解析StateBackend实例创建过程,入口方法即createStateBackend()。首先获取用户配置的StateBackend,配置项为:state.backend.type,创建过程实现于StateBackendLoader.loadStateBackendFromConfig(...)。利用用户配置的StateBackend信息,生成最终的系统StateBackend实例。
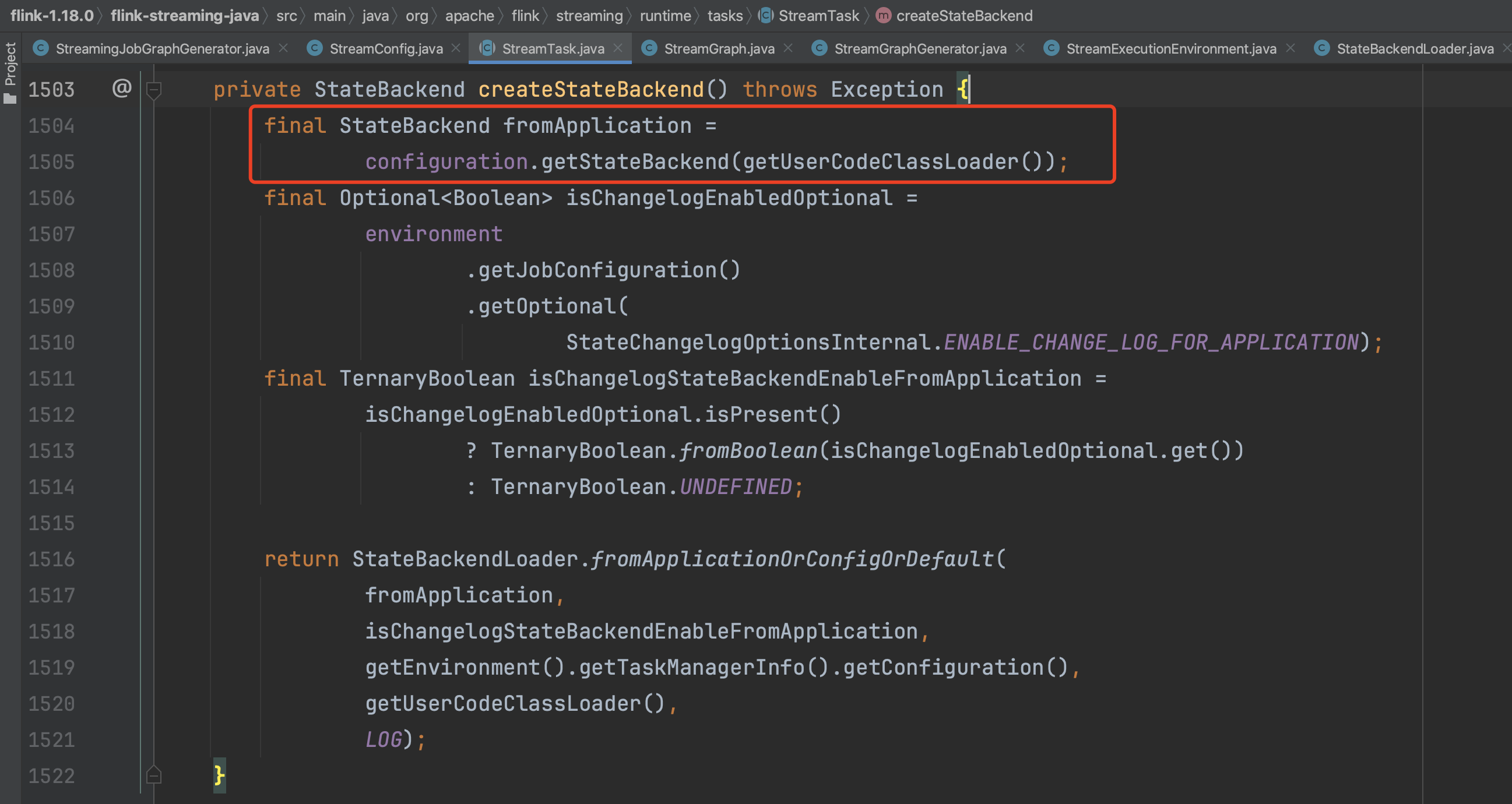
以上即为StreamTask关键构造过程解析。
四、StreamTask启动过程解析
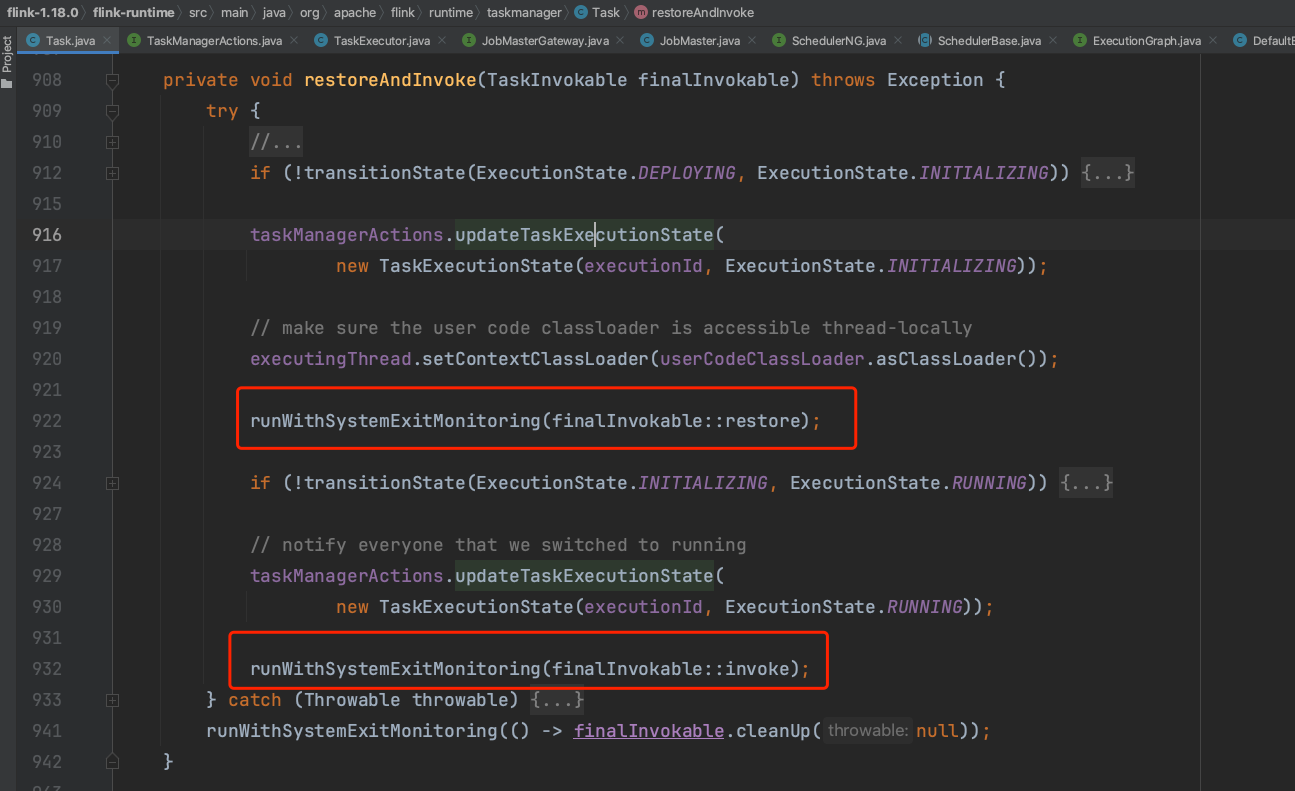
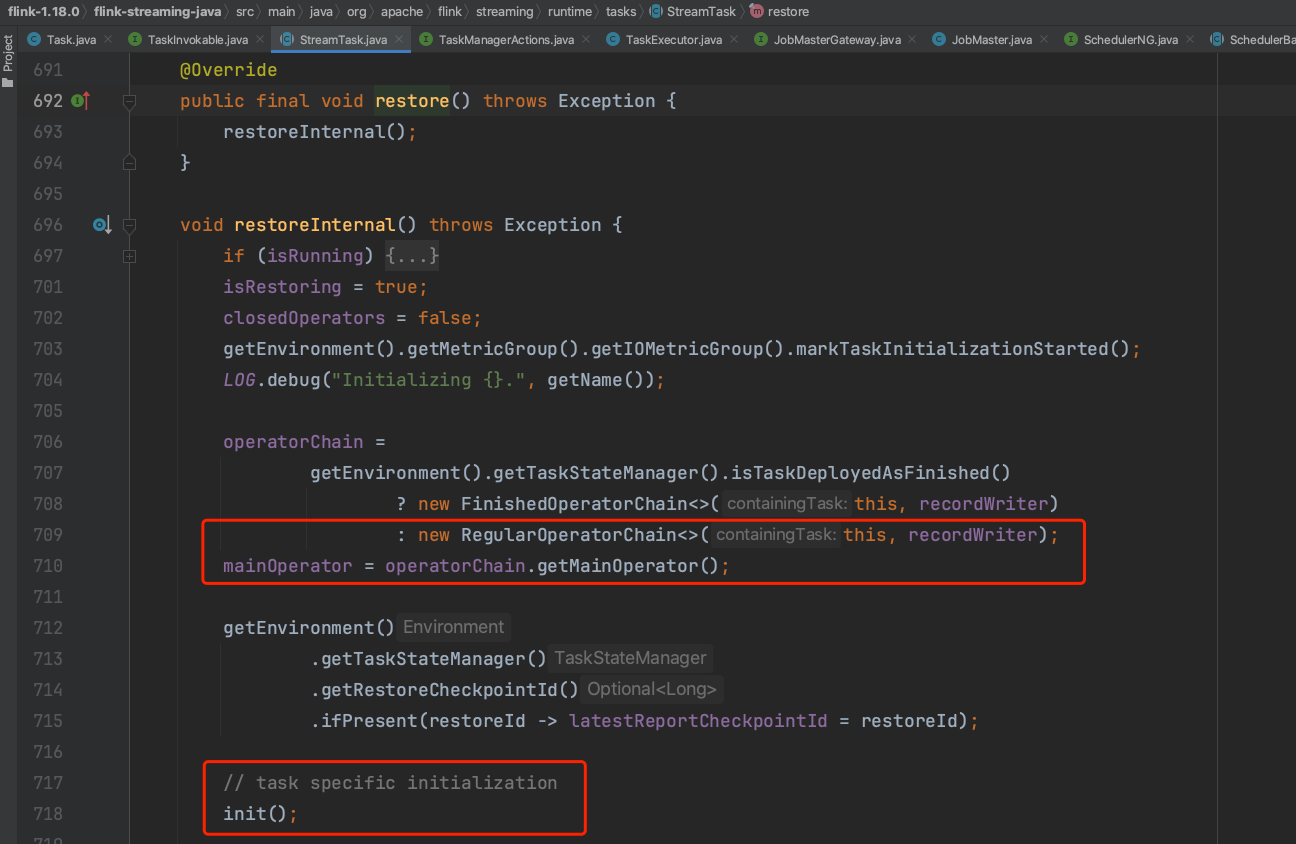
在StreamTask实例创建完后紧接着触发该实例的restore()方法,开始StreamTask启动过程的准备工作。由restore()方法跳转到restoreInternal()方法,在该方法中主要有三个重要的步骤,一是创建OperatorChain实例,二是创建StreamInputProcessor实例,流输入处理器,三是初始化算子操作。
1、创建OperatorChain实例过程。
下图可知开始创建OperatorChain实例,一般来说OperatorChain都是RegularOperatorChain类型,转入到RegularOperatorChain构造函数中。
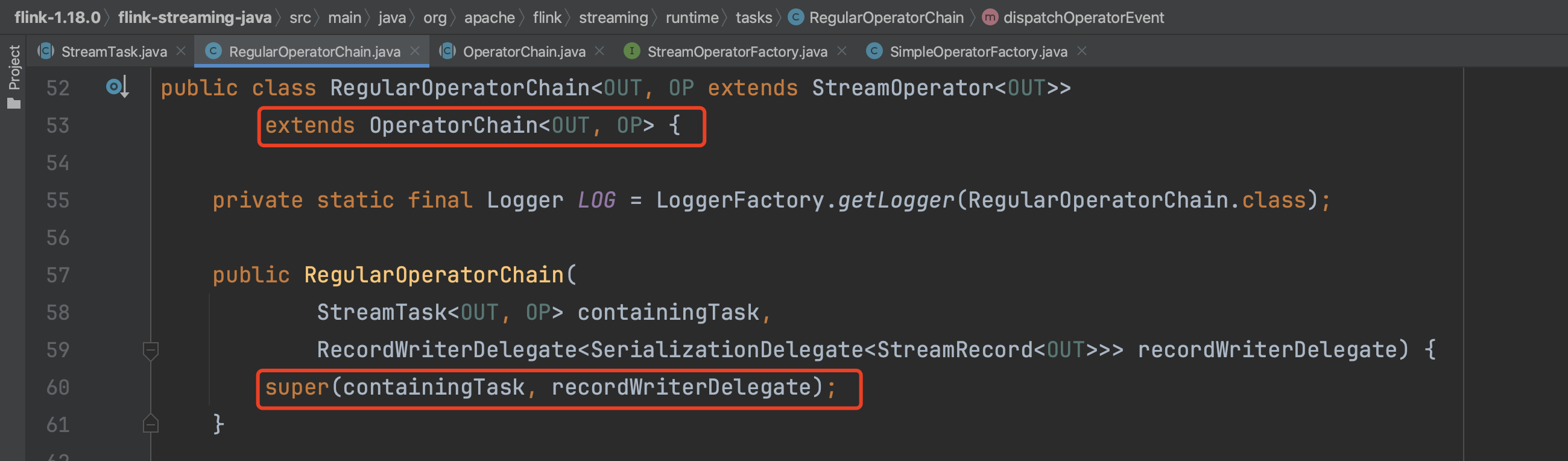
在构造函数中先获取OperatorChain重要的组件信息,如算子工厂实例、可chain的算子配置集合、不可chain的出边输出集合等。
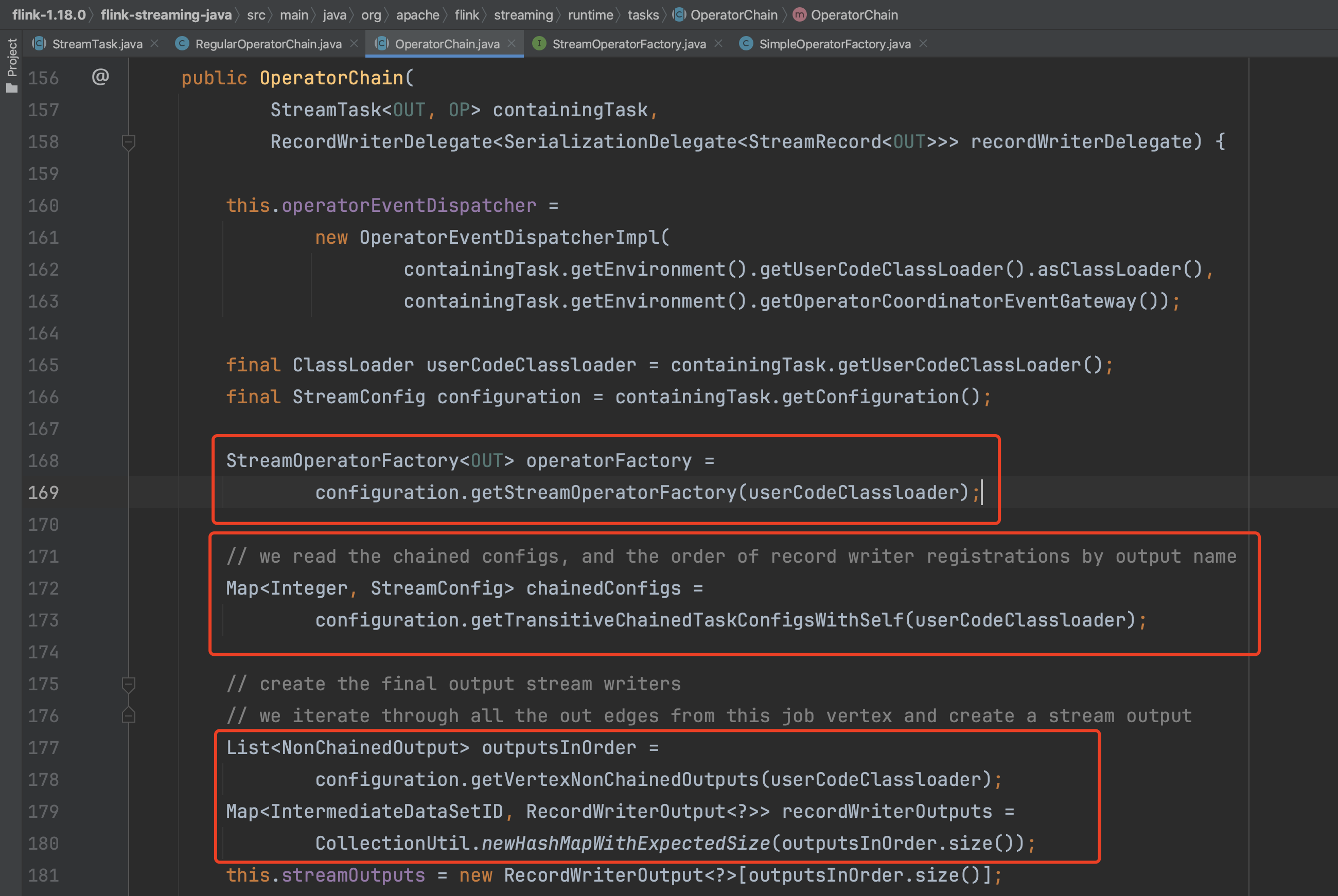
以下步骤的目的是创建整个OperatorChain不可chain出边对应RecordWriterOutput实例集合。
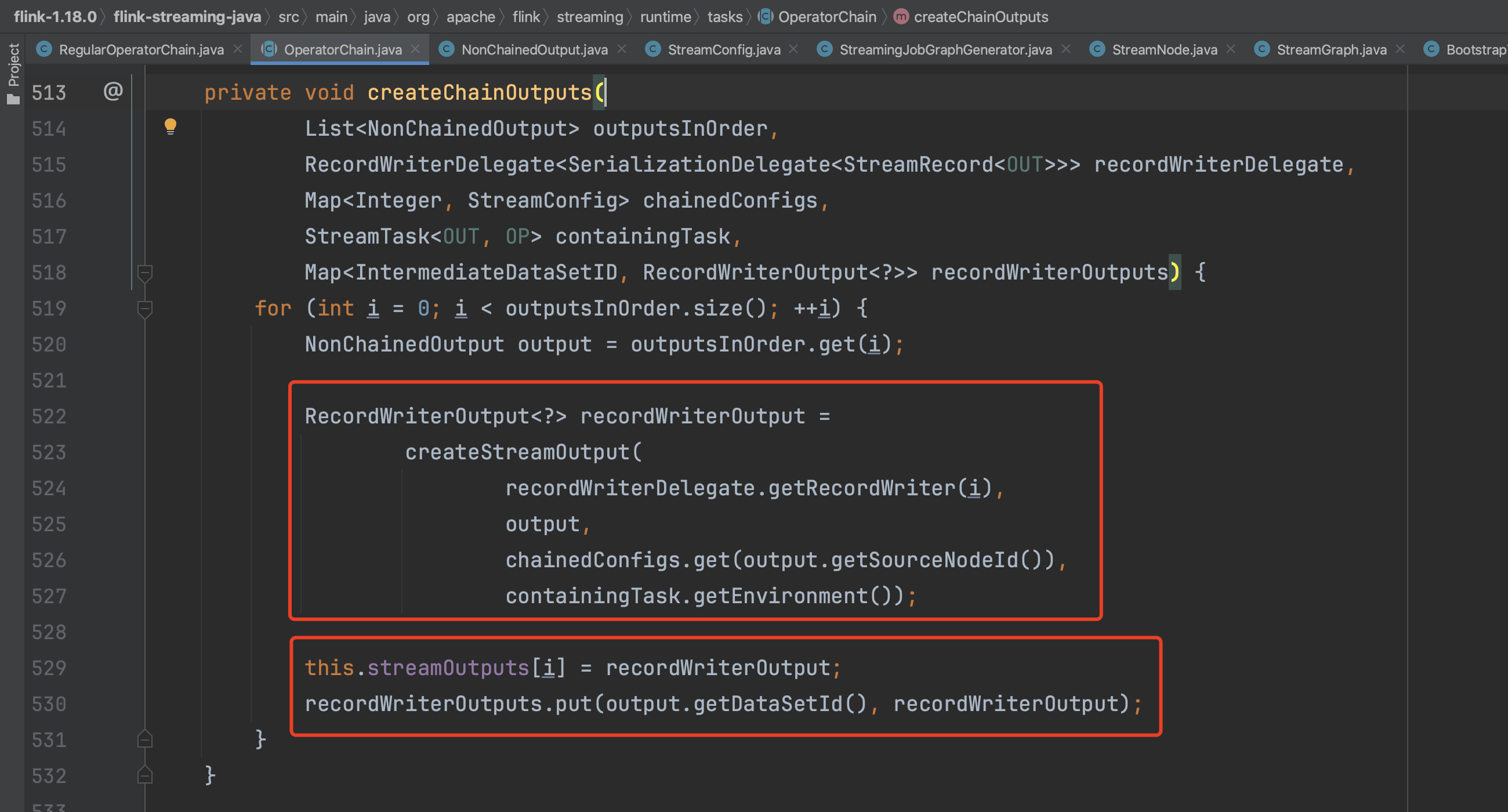
紧接着到达关键方法createOutputCollector(...)处,该方法负责创建整个OperatorChain中的算子以及算子输出。
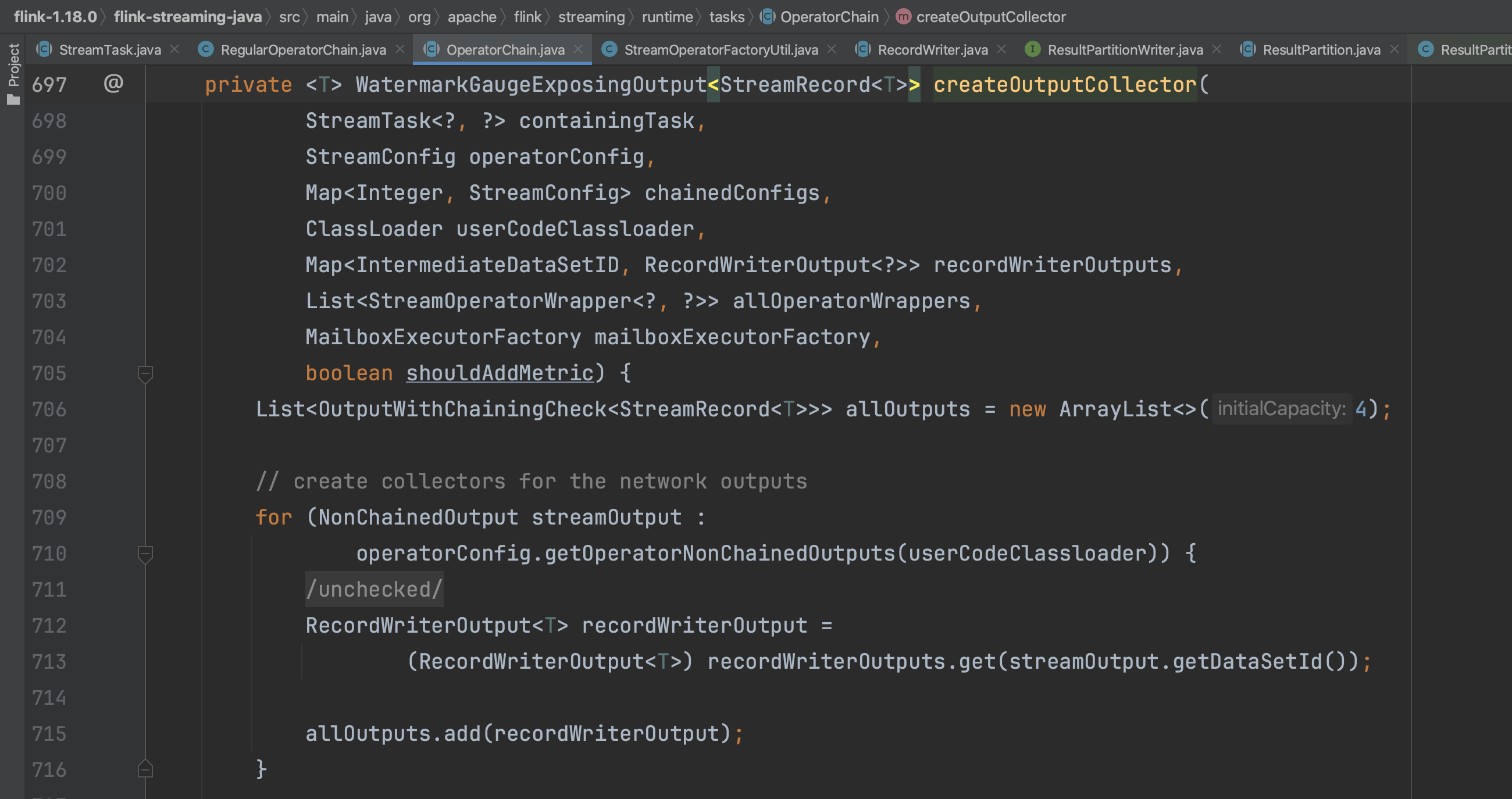
在createOutputCollector(...)中会调用createOperatorChain(...)方法,而createOperatorChain(...)会递归调用createOutputCollector(...)方法,目的是以从后往前的形式一个一个构造算子链中的算子实例。在构造算子实例的过程中,都会设置该算子的output信息,output信息包含下一个算子的引用,末尾的operator的output就是RecordWriterOutput。
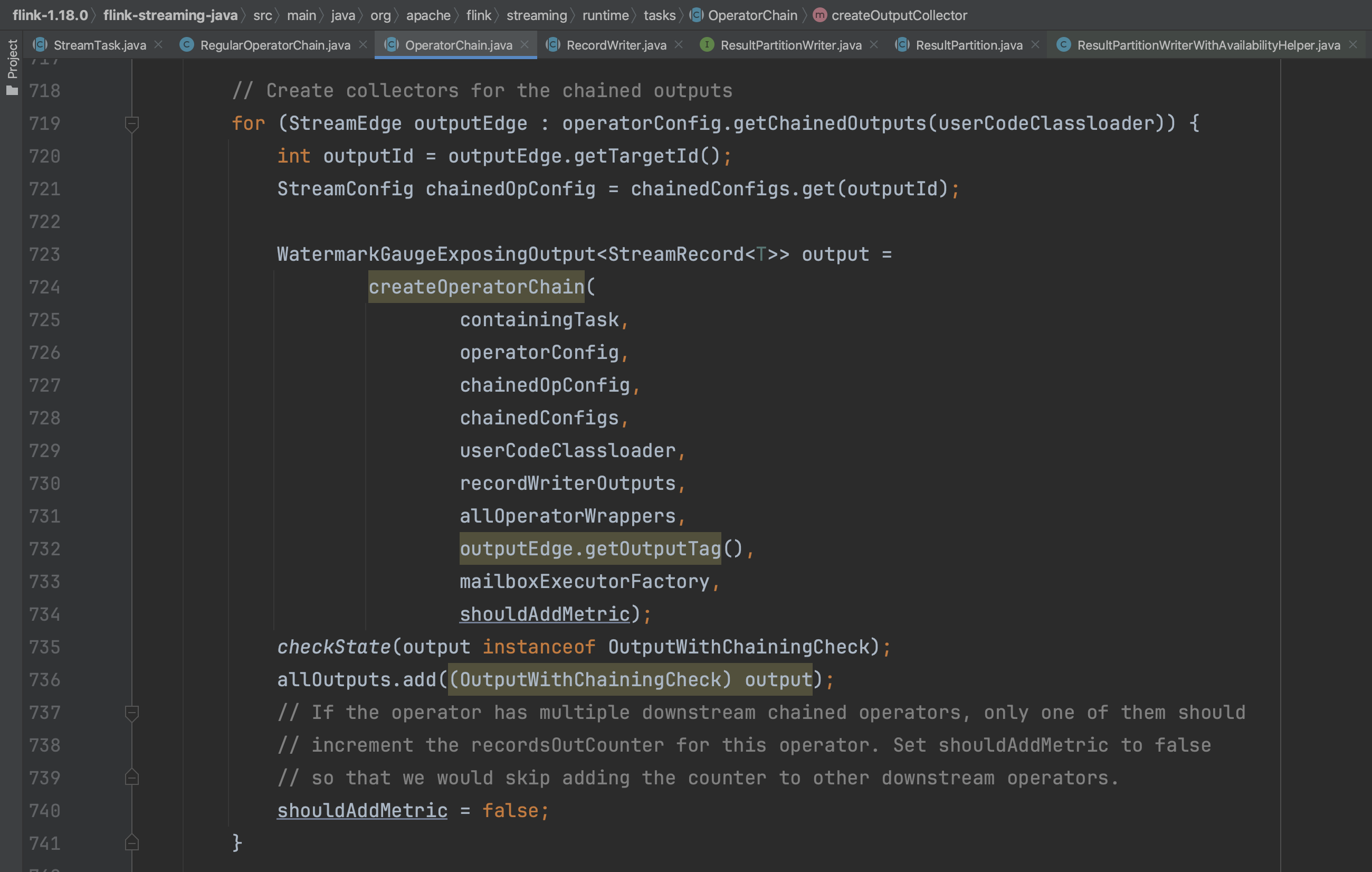
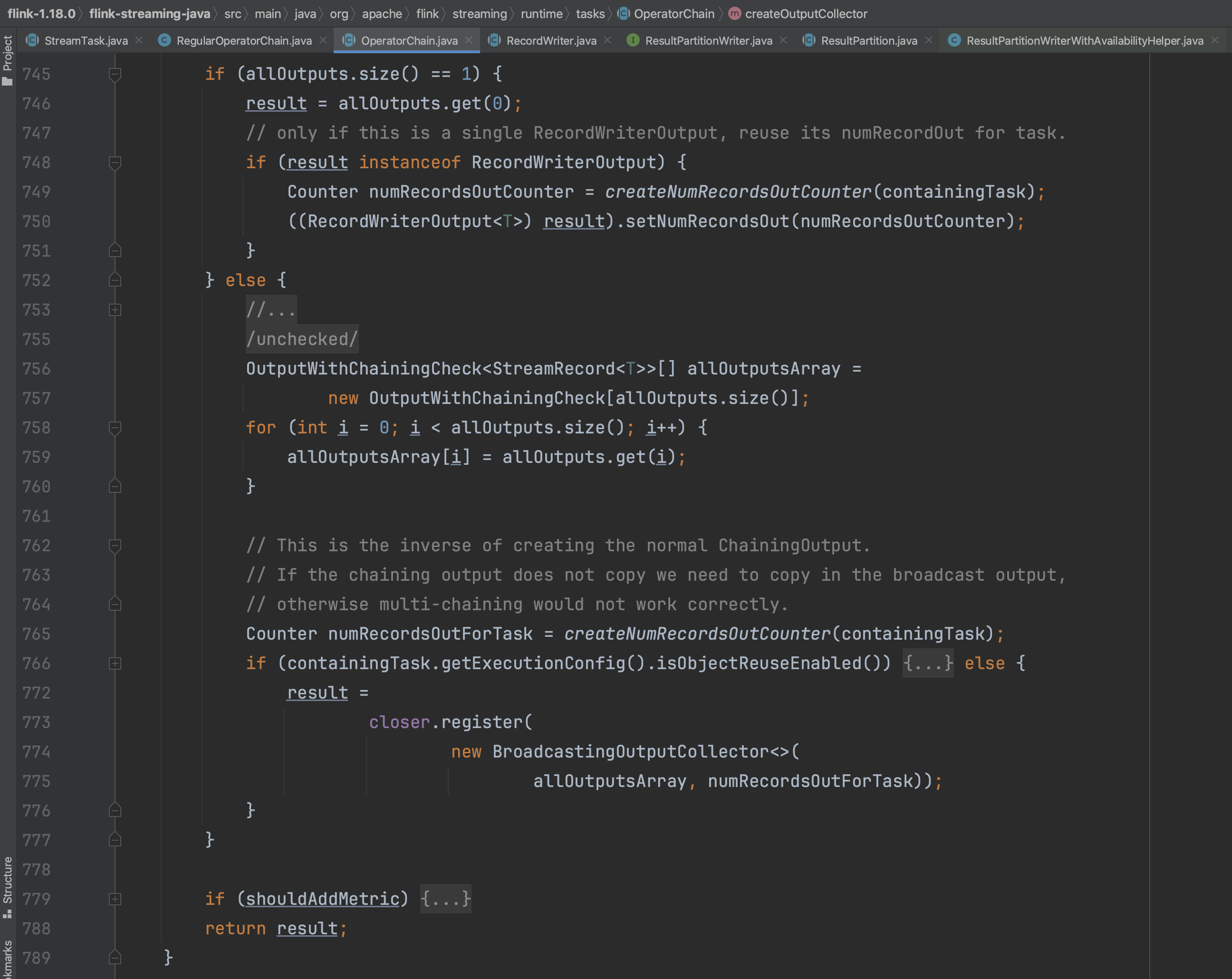
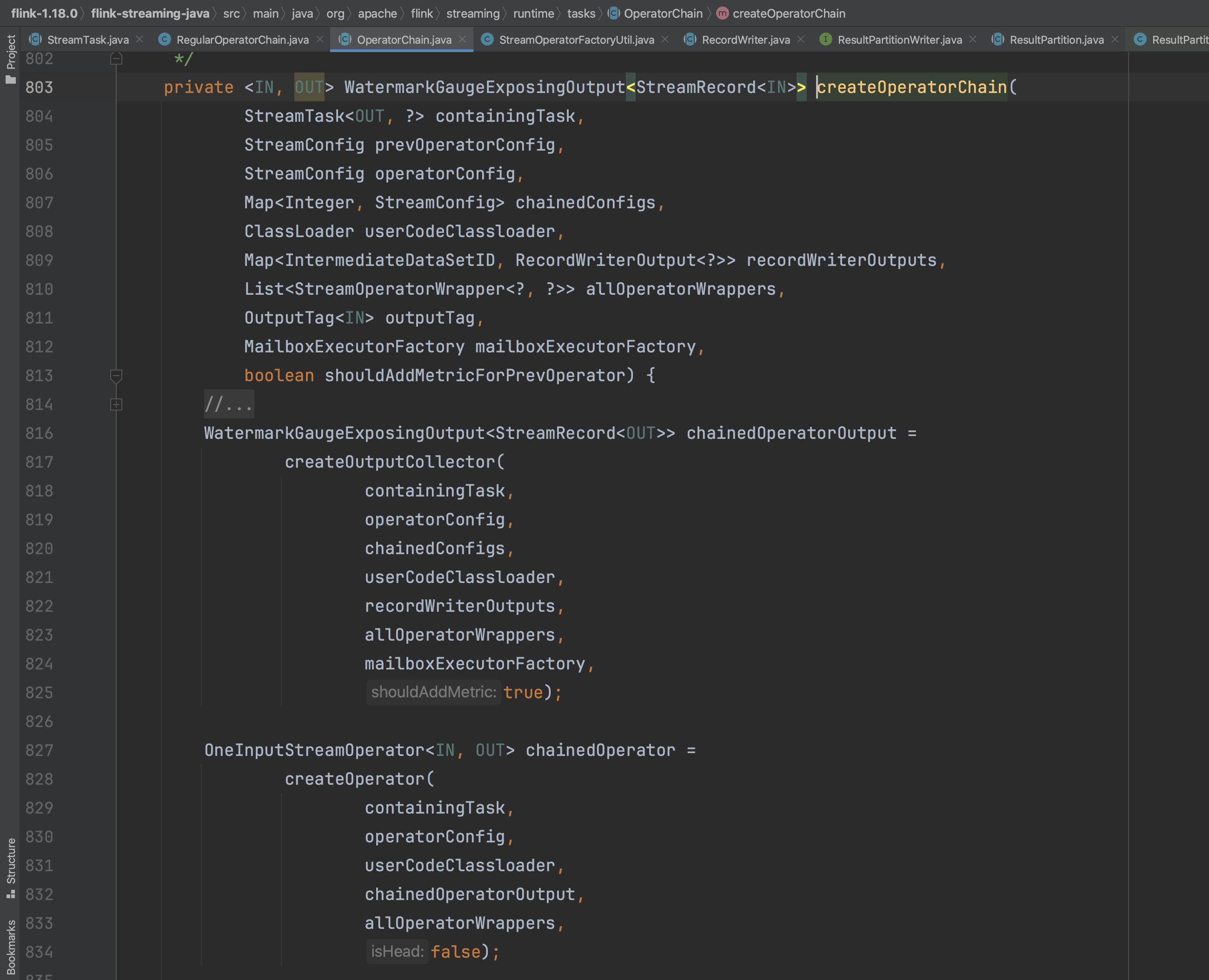
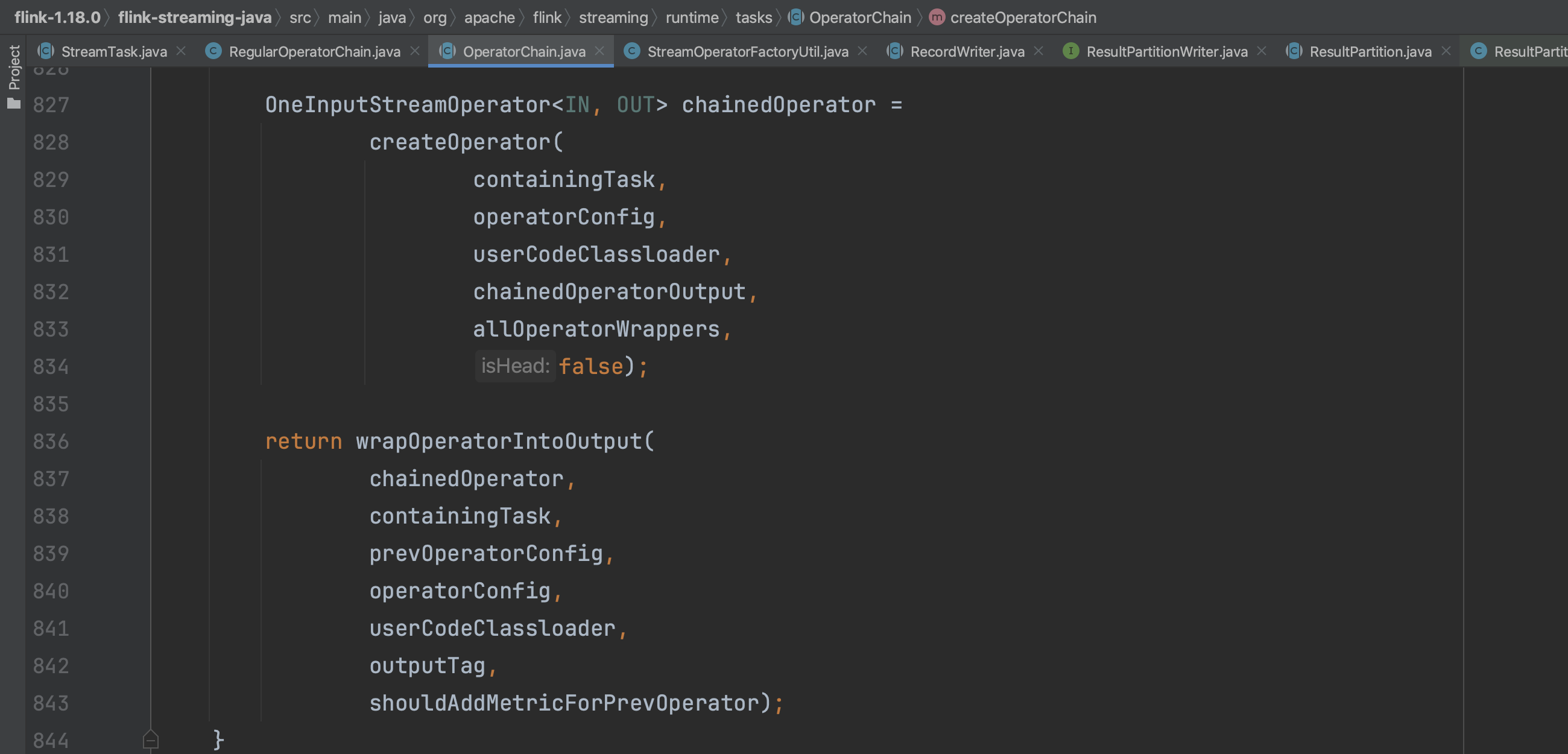
最后返回算子链的第一个output信息以及第一个mainOperatorWrapper信息。
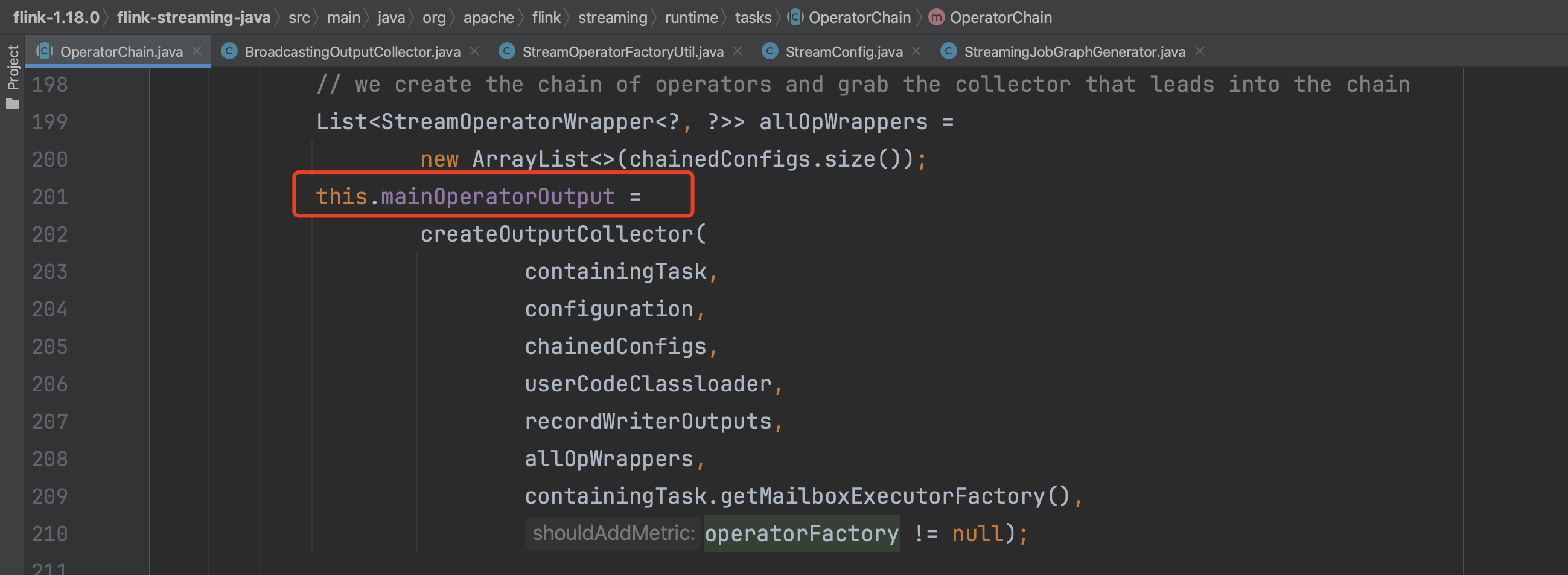
2、StreamTask的初始化过程
在OperatorChain实例创建完后,紧接着调用init()方法,该方法主要由子类实现。常见的StreamTask子类包括OneInputStreamTask和SourceStreamTask等。
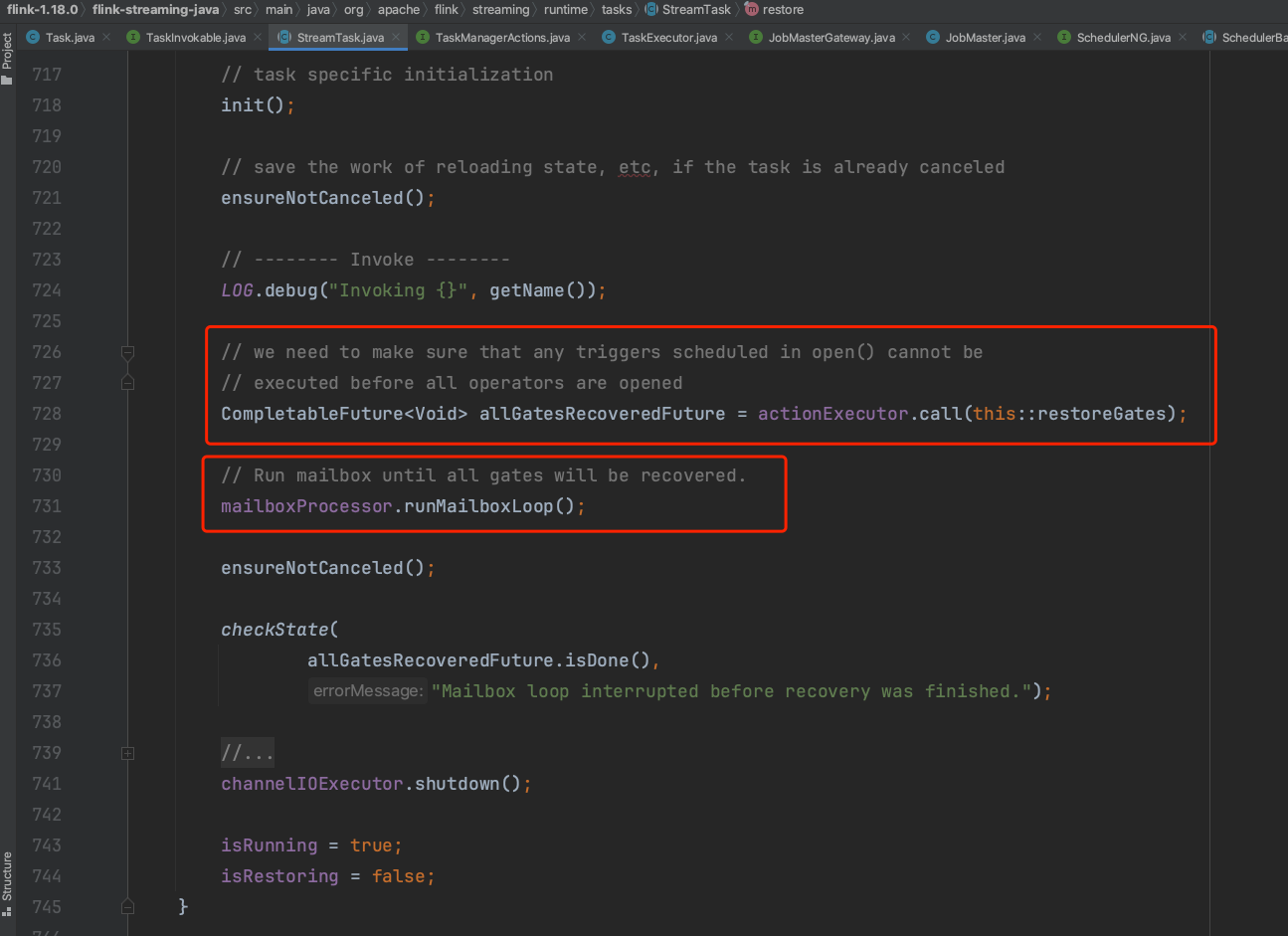
(1)、OneInputStreamTask的init()方法调用,由下图可知OneInputStreamTask子类的init()方法主要目的是创建StreamInputProcessor实例,即核心数据处理器。
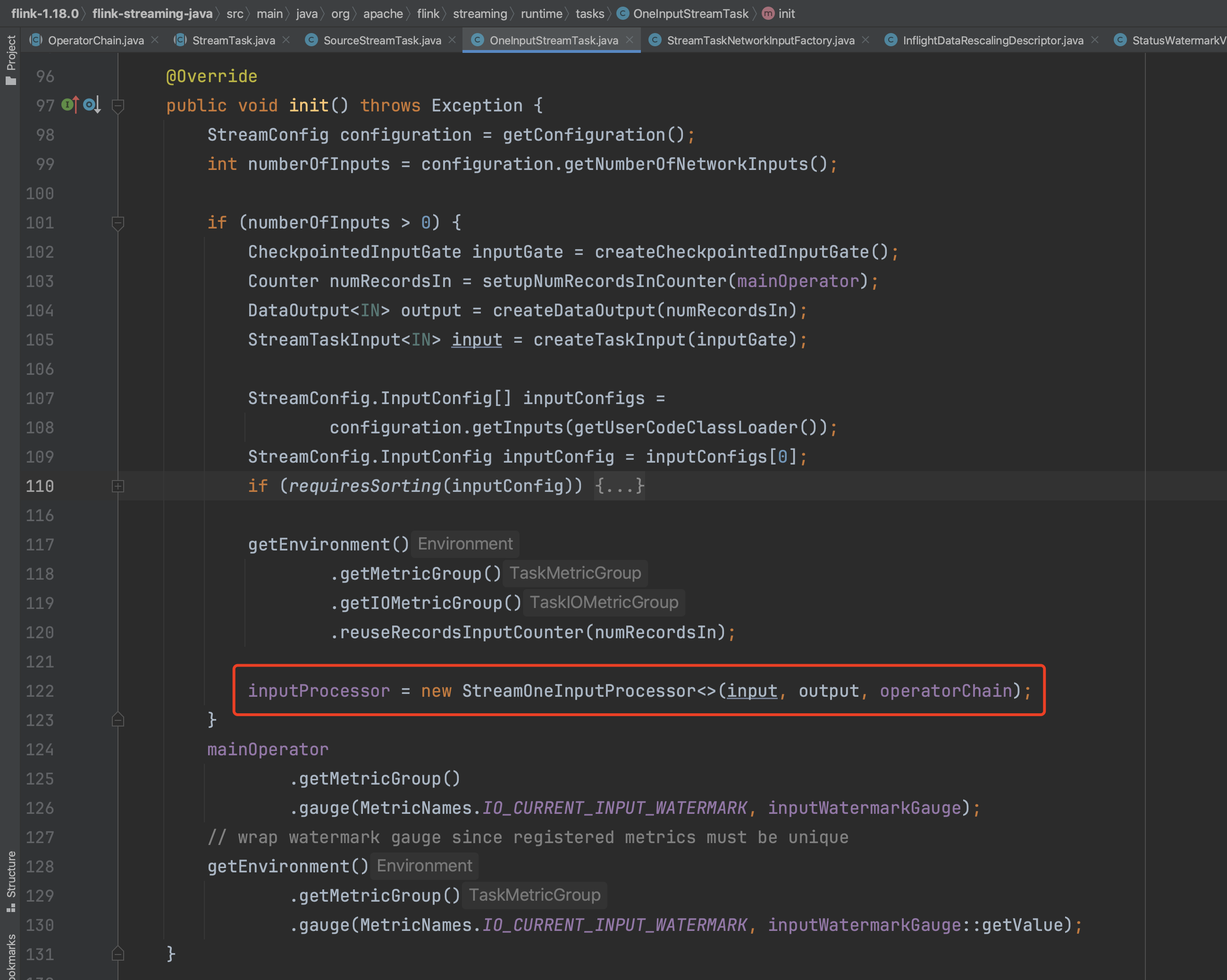
(2)、SourceStreamTask的init()方法调用,SourceStreamTask子类的init()方法没有太多实质性的操作,主要是判断SourceFunction是不是ExternallyInducedSource类型,是的话为SourceFunction设置checkpoint相关的东西等。
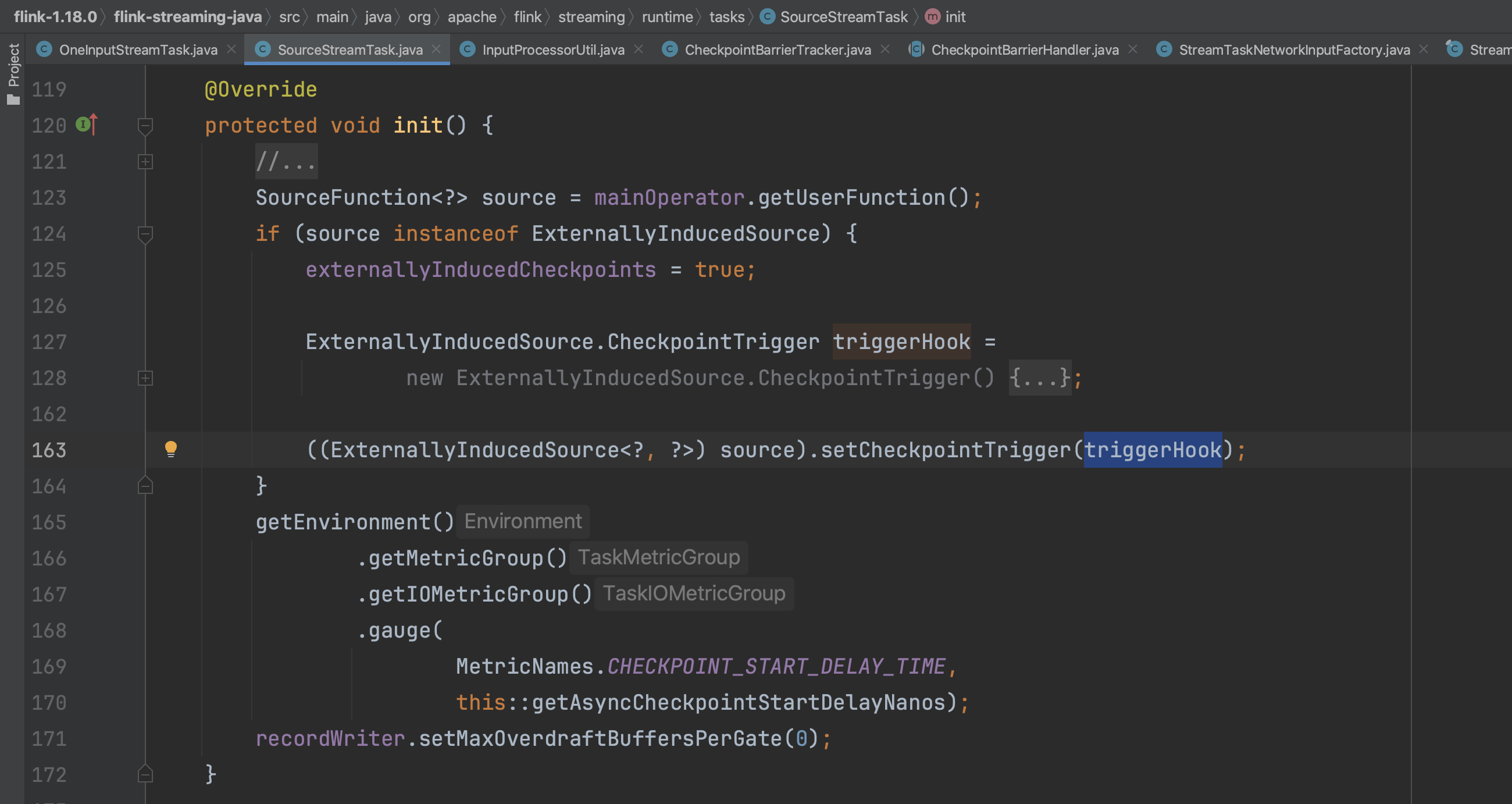
3、Operator的初始化过程,在调用完上面的init()方法后,接着调用restoreGates()方法,在该方法中有一步重要的操作就是初始化算子链中的各个算子。
调用算子链实例的initializeStateAndOpenOperators(...)方法。
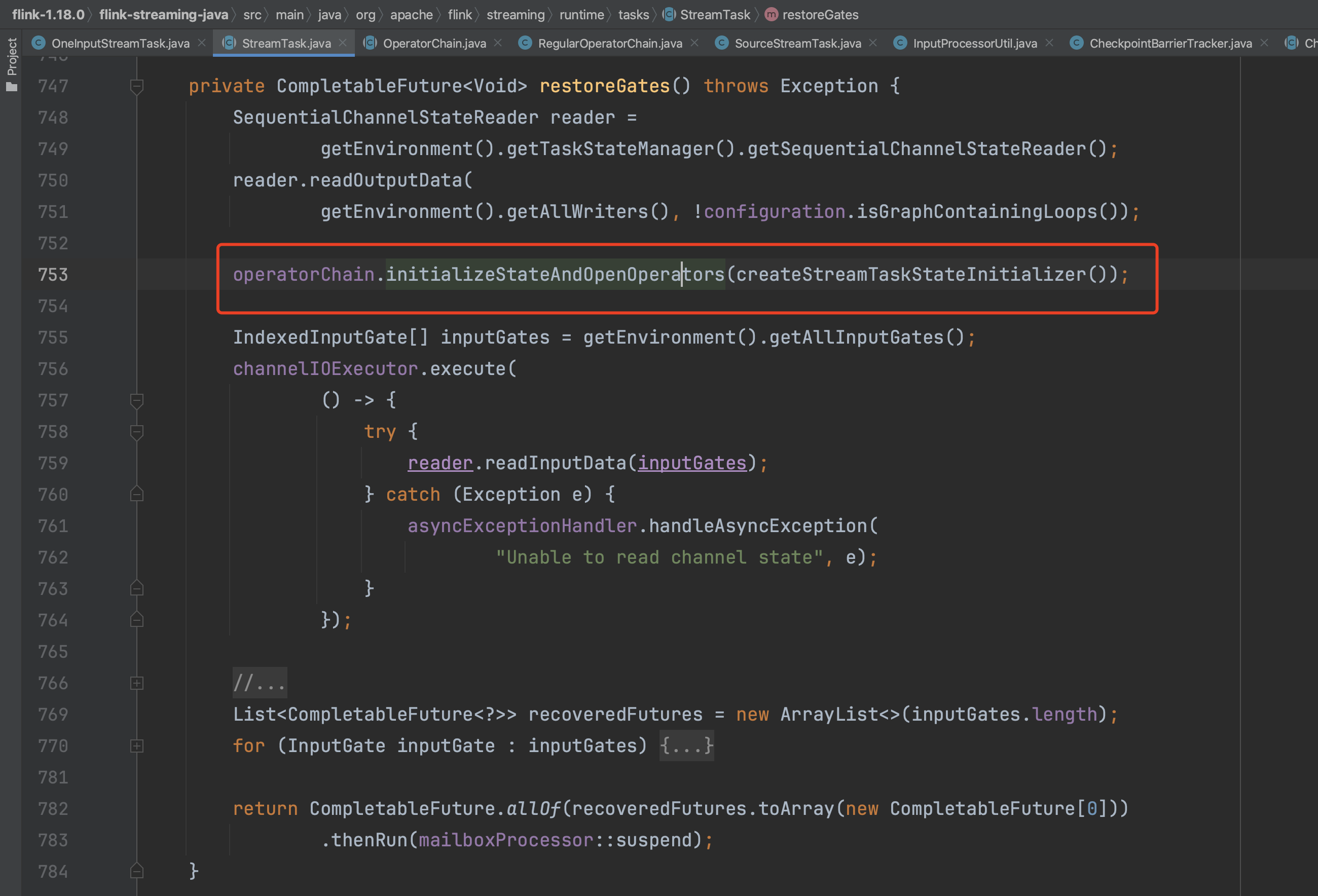
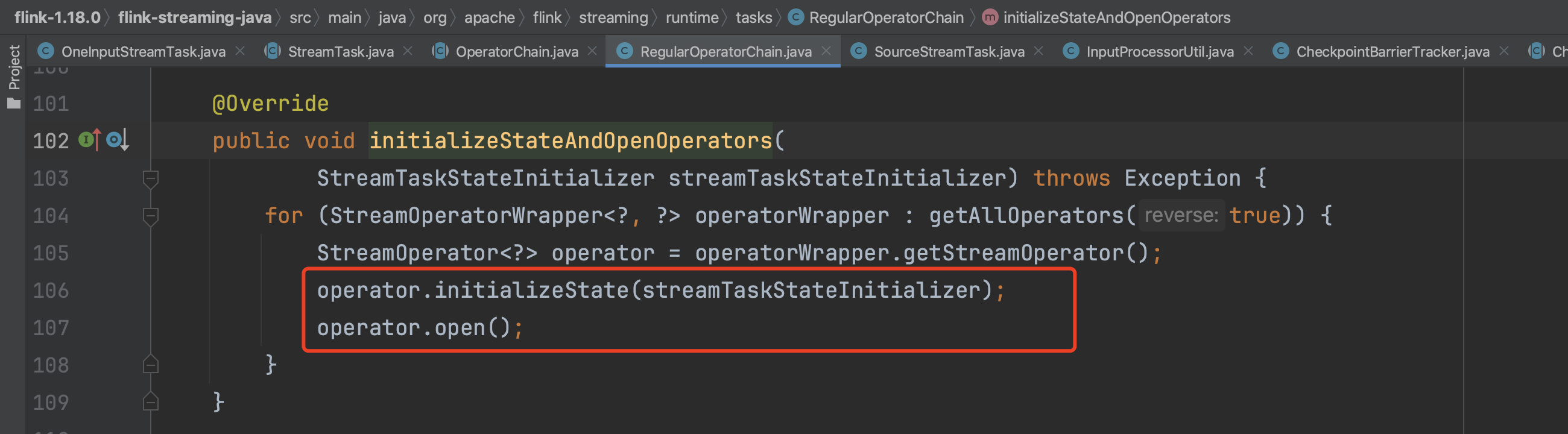
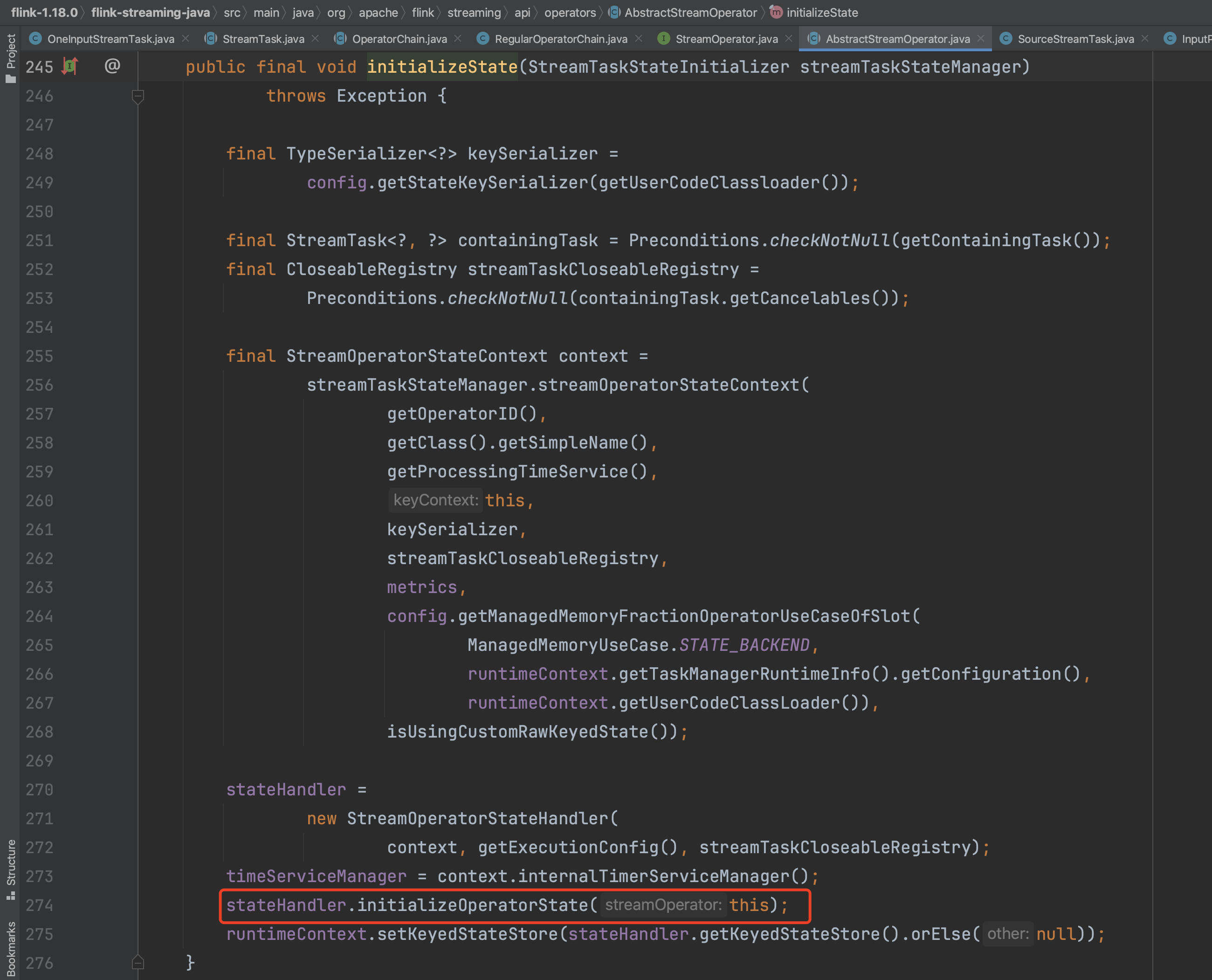
initializeState(...)方法中主要负责初始化Operator成员变量operatorStateBackend、keyedStateBackend以及keyedStateStore等。
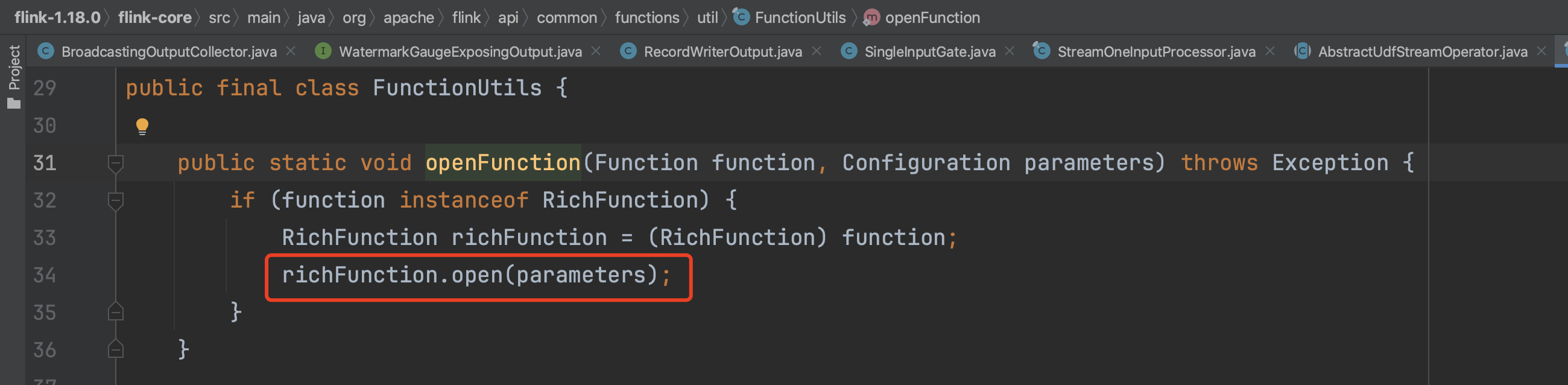
其次是调用每个Operator的open()方法,继而调用UDF函数中open()方法。

以上即为StreamTask的启动过程前的准备过程。
五、Task读数据概述
在调用完子类的init()方法后,开始触发mailboxProcessor.runMailboxLoop();代码行的执行,由方法runMailboxLoop()可知,其主要作用是触发mailboxDefaultAction默认动作的执行,即StreamTask.processInput(...)方法的执行。
1、子类OneInputStreamTask的processInput(...)方法执行,由于子类OneInputStreamTask未重写父类的processInput(...)方法,直接复用StreamTask.processInput(...)方法,可知子类实例直接调用核心数据处理器inputProcessor.processInput()方法来进行数据的处理。
2、子类SourceStreamTask.processInput(...)方法执行如下:
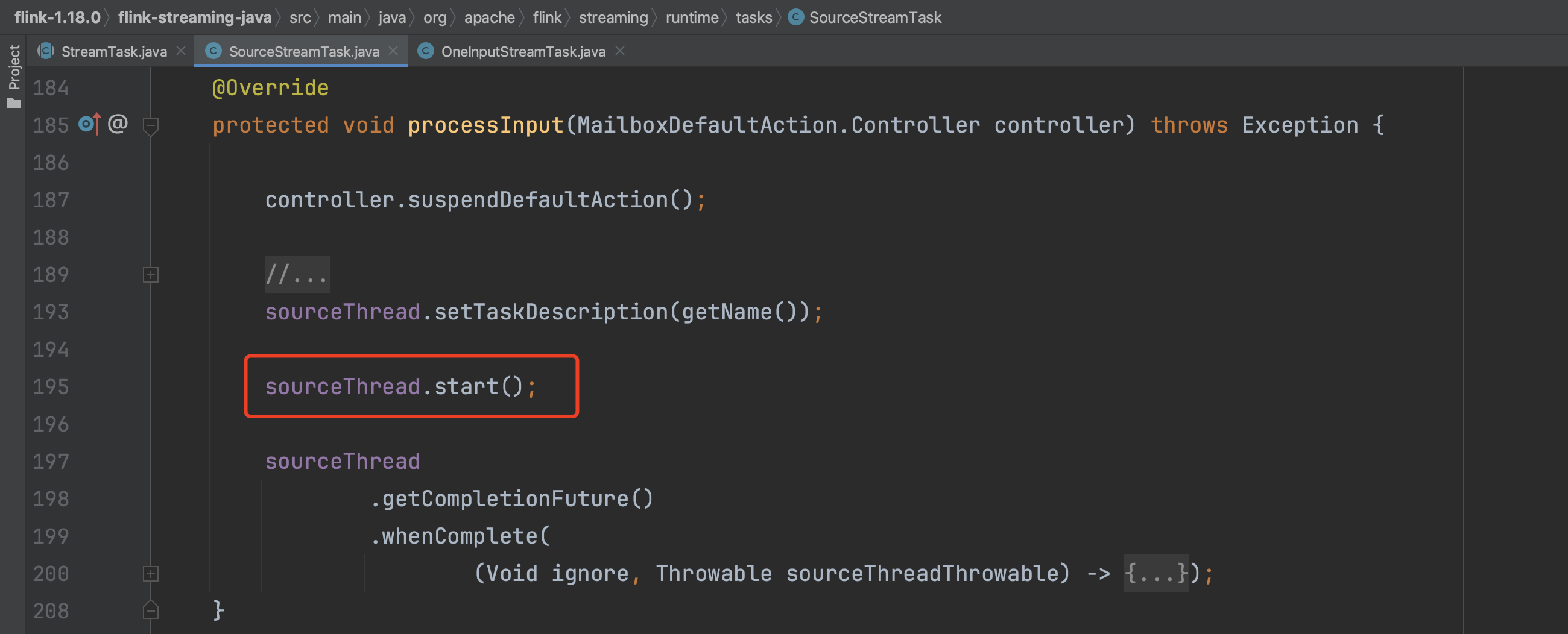
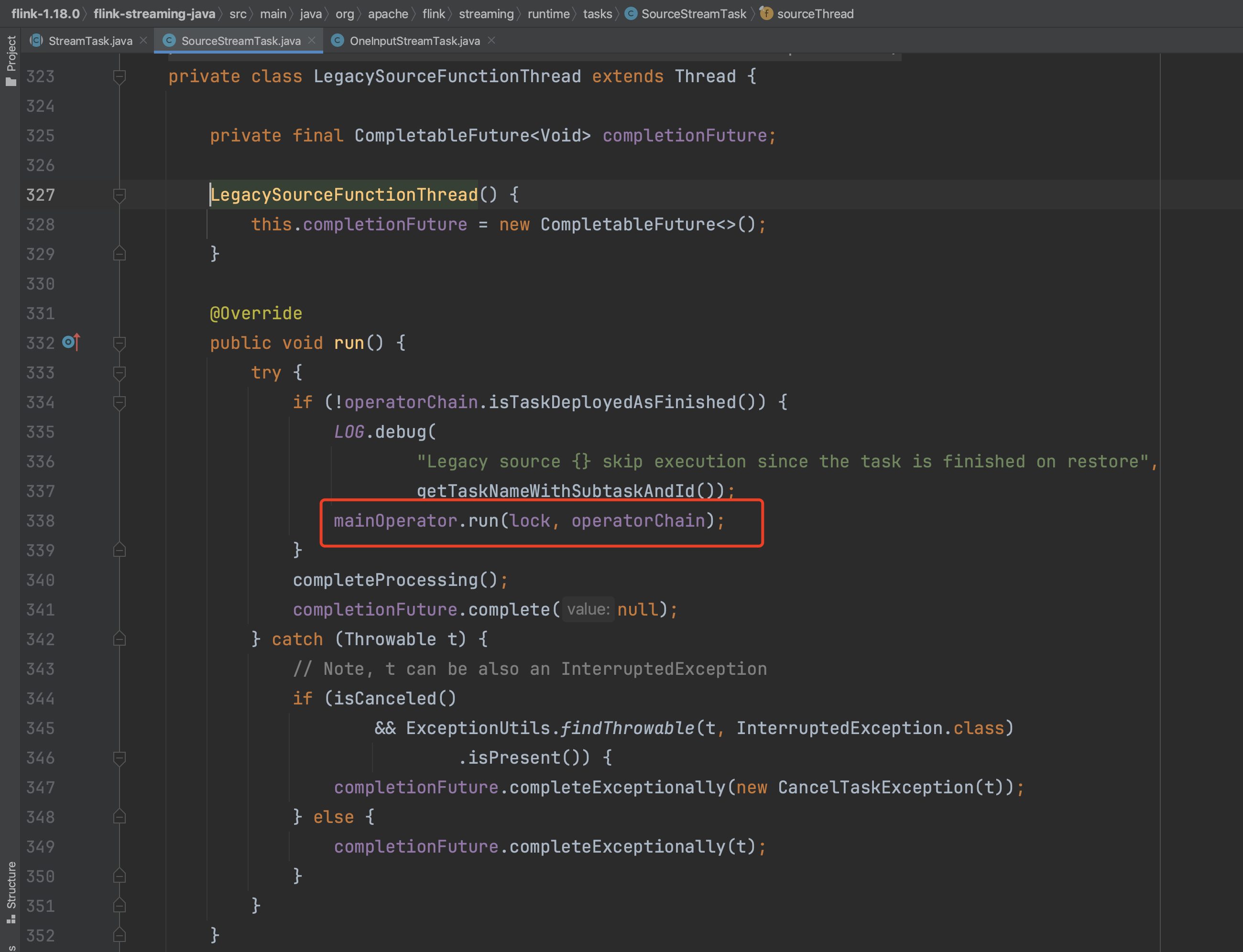

新建完SourceFunction函数的上下文环境变量后,开启数据源的读数据过程。
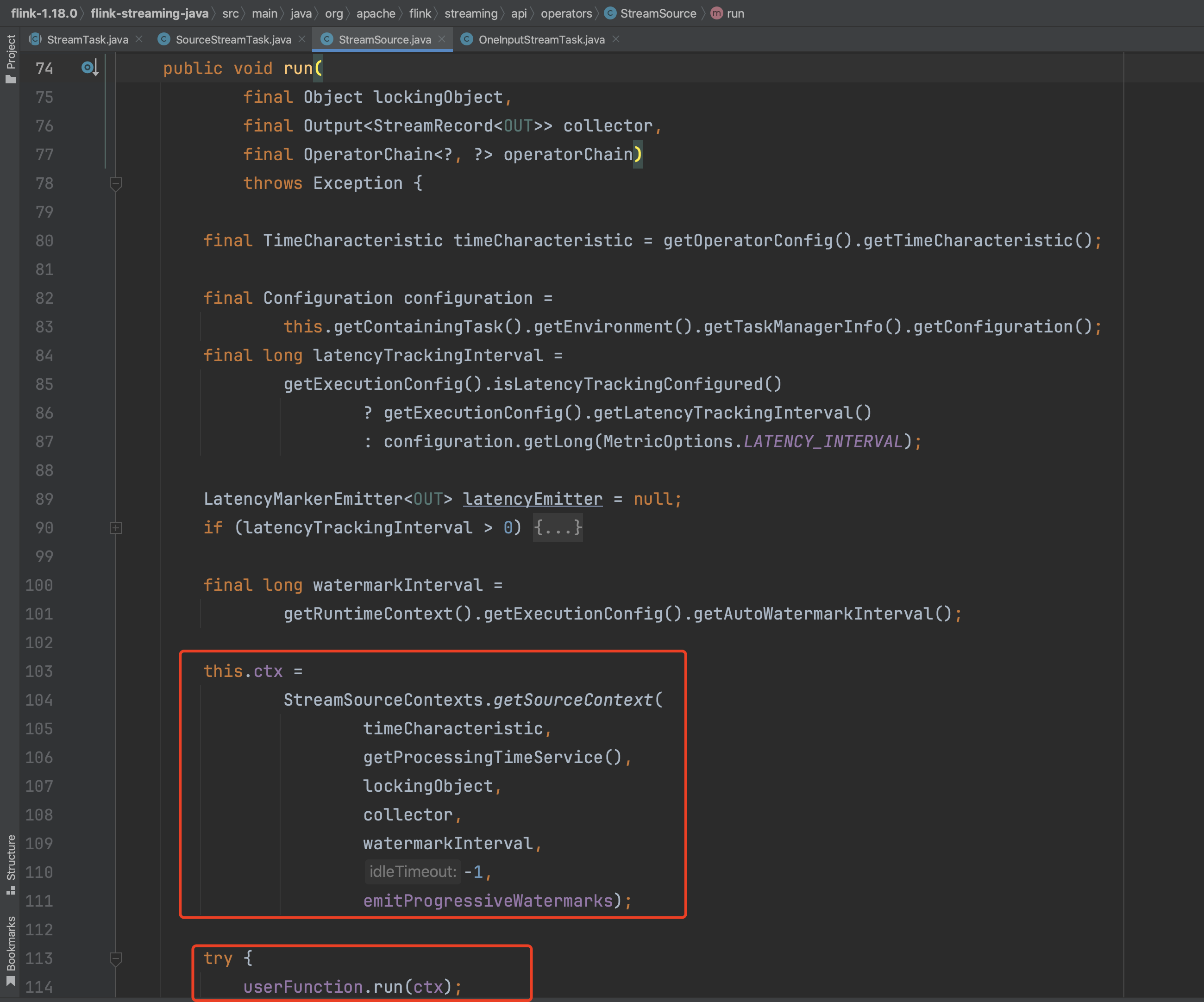
以上为概要的Task读取数据的过程,后面随笔会继续解析Task读写数据的过程。
