
Flink源码解析(五)——时间、水印及窗口原理解析
一、时间类型解析
1、处理时间(Processing Time):处理时间是指数据被计算引擎处理的时间,以各个计算节点的本地时间为准。
2、事件事件(Event Time):事件时间是指数据发生的时间,通常产生于数据采集设备中,与Flink计算引擎本地时间无关。因受网络延迟、数据乱序、背压等影响,事件时间进入计算引擎往往有一定程度的数据乱序现象发生。为了计算结果的准确性,需要等待数据,但必须配合水印(Watermark)机制来触发计算动作的发生。
3、摄取时间(Ingestion Time):摄取时间是指数据流入Flink流处理系统的时间,一经读取,Flink系统就采用读取时刻作为数据的摄取时间,后续处理流程中,摄取时间保持不变。
二、水印(Watermark)解析
1、水印概念:水印本质上是一个较早的时间戳,代表数据乱序的时间错乱程度。实现上是设置一个时间间隔,用最新的事件时间或当前时间减去这个水印时间间隔得到的时间,系统就认为在这个时间之前的数据已全部收集完毕,可以触发下一步的窗口计算等动作。比如水印是10min间隔,当前时间是15:20,15:20减去10min是15:10。就代表结束时间在15:10之前的窗口可以触发窗口函数的计算了。15:10之后的数据还在水印时间间隔内,数据未收集完成,不可以触发计算。因此水印机制往往会结合窗口来实现乱序数据的处理。
2、多流Watermark获取:针对union、groupby、keyby等操作的算子会有多个上游输入边,每个输入边都有一个Watermark,算子会选取较小的Watermark水印时间戳作为当前算子的Watermark。具体选取手段如下:算子会保留3个inputWatermark1、inputWatermark2、combinedWatermark水印字段。inputWatermark1代表输入边1的当前水印,inputWatermark2代表输入边2的当前水印,combinedWatermark代表算子的当前Watermark。当输入边1输入一个最新的Watermark时,算子按公式max(min(新inputWatermark1,inputWatermark2),combinedWatermark)得到算子新结果Watermark,如果新结果Watermark大于combinedWatermark时,则更新combinedWatermark并下发新结果Watermark。当输入边2输入一个最新的Watermark时,处理规则类似。
(1)、上游输入边有新的Watermark时调用processWatermark(mark, 0)或processWatermark(mark, 1)更新inputWatermark1或inputWatermark2,并计算最新的combinedWatermark。
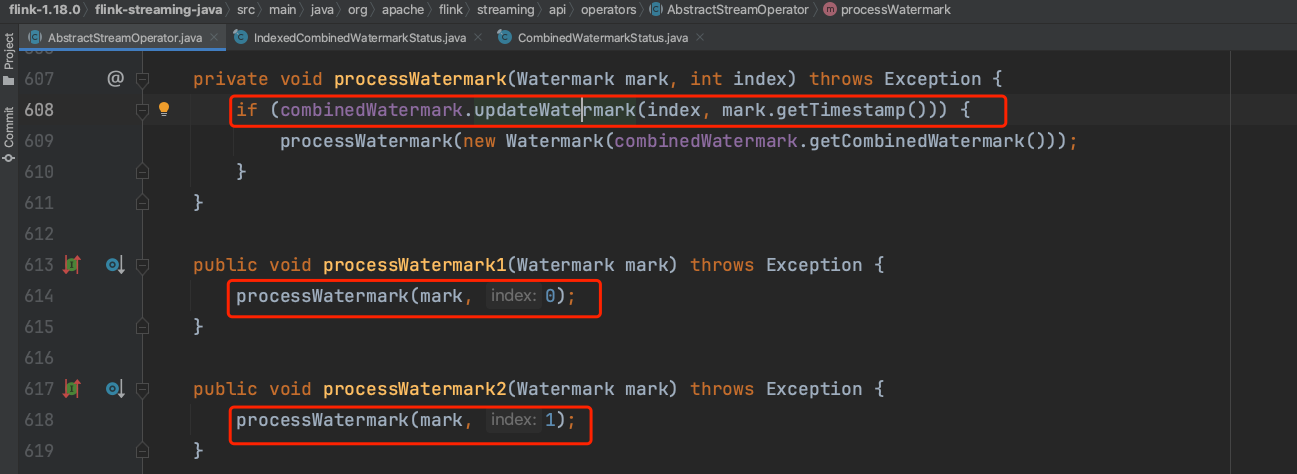
(2)、下图第65行代表更新combinedWatermark
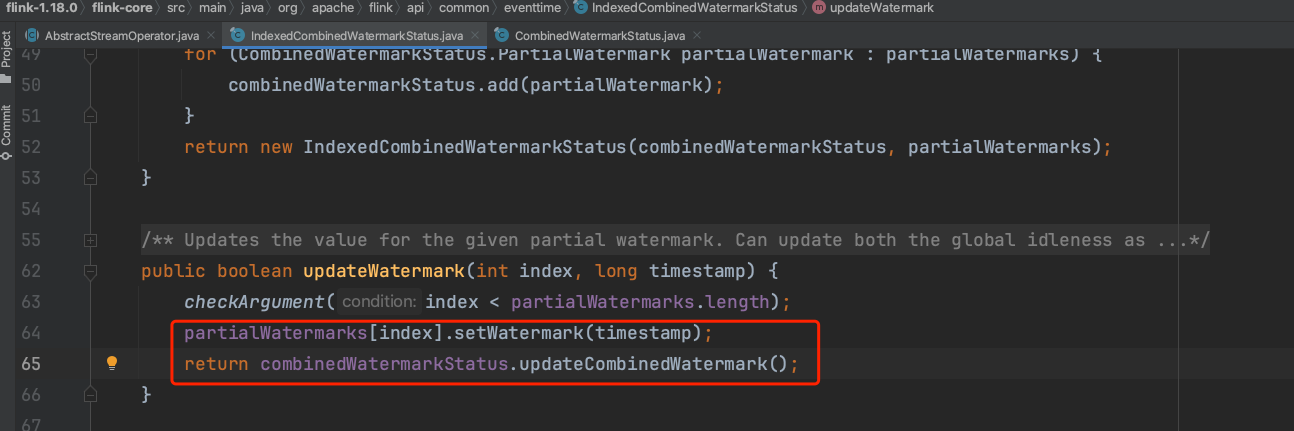
(3)、下图是用公式max(min(新inputWatermark1,inputWatermark2),combinedWatermark)计算最新combinedWatermark的过程。

3、新版api设置水印和时间戳
(1)、数据源处设置水印和时间戳案例
public class DataGenerateSource extends RichParallelSourceFunction<String> {
private long timeDiDa = 1000;
private volatile boolean isRunning = true;
public DataGenerateSource(){}
public DataGenerateSource(long dida){
this.timeDiDa = dida;
}
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (isRunning){
JSONObject data = DataGenerator.generateData();
ctx.collect(data.toJSONString());
//收集时间戳
ctx.collectWithTimestamp(data.toJSONString(),Long.valueOf(String.valueOf(data.get("ts"))));
//收集水印
ctx.emitWatermark(new Watermark(Long.valueOf(String.valueOf(data.get("ts"))) - 60000));
Thread.sleep(timeDiDa);
}
}
@Override
public void cancel() {
isRunning = false;
}
}
(2)、非数据源DataStream设置水印和时间戳案例:
Flink 1.12版本后非数据源DataStream推荐用api:assignTimestampsAndWatermarks(WatermarkStrategy<T> watermarkStrategy)设置水印和时间戳。
DataStream ds = customSource.assignTimestampsAndWatermarks(WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(20)));
WatermarkStrategy解析:在源码中接口WatermarkStrategy继承于2个由函数式注解FunctionalInterface标注的接口WatermarkGeneratorSupplier、TimestampAssignerSupplier,分别提供createWatermarkGenerator、createTimestampAssigner方法。其中方法createTimestampAssigner已默认实现从数据源中获取时间戳的逻辑。
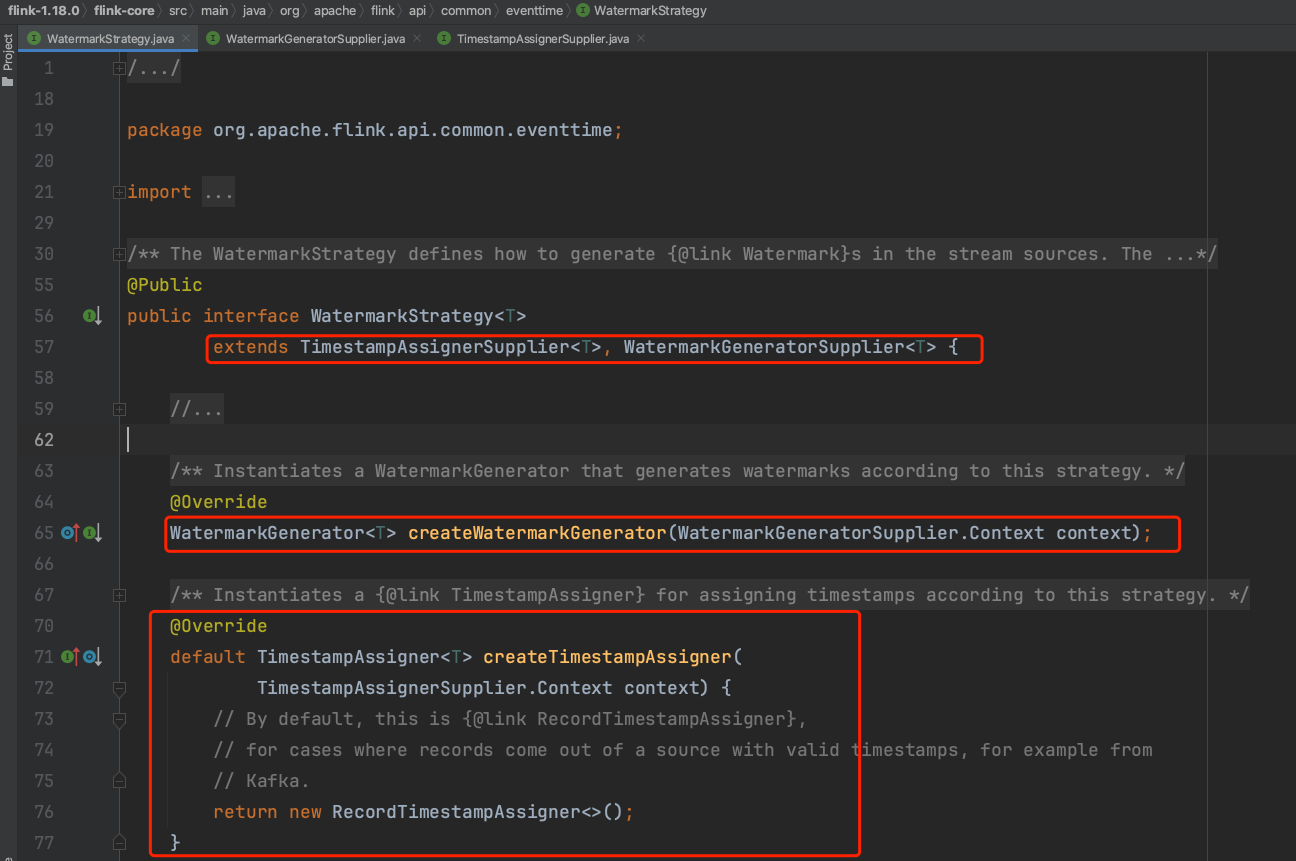
并且Flink系统在WatermarkStrategy接口提供2个生成Watermark的实现类。forMonotonousTimestamps方法生成单调递增的Watermark,forBoundedOutOfOrderness生成有界乱序Watermark
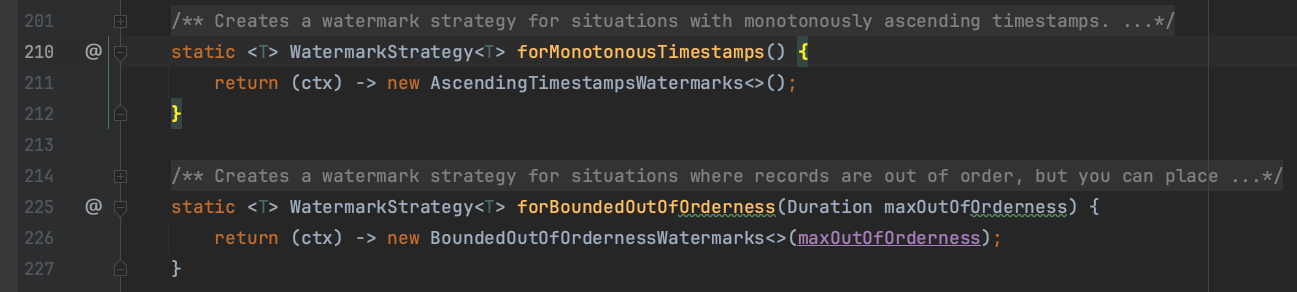
注:上图211行、226行代码形式是借助函数式接口注解功能实现接口WatermarkStrategy的createWatermarkGenerator方法。
三、窗口解析
在批处理场景下,数据已经按天、周、月等某个时间间隔分批次存储及处理了。但在流处理场景下数据源源不断地流入,没有始末。因此在流数据处理中经常需要明确一个时间窗口,在该时间窗口维度下进行数据聚合处理等操作。在Flink系统实现中有三种窗口分类:计数窗口、时间窗口、会话窗口。其中计数窗口可以细分为滚动计数窗口、滑动计数窗口,时间窗口可以细分为滚动时间窗口、滑动时间窗口。
1、窗口程序的基本结构
Keyed Windows类型
stream
.keyBy(...) <- 仅 keyed 窗口需要
.window(...) <- 必填项:"WindowAssigner"
[.trigger(...)] <- 可选项:"trigger" (省略则使用默认 trigger)
[.evictor(...)] <- 可选项:"evictor" (省略则不使用 evictor)
[.allowedLateness(...)] <- 可选项:"lateness" (省略则为 0)
[.sideOutputLateData(...)] <- 可选项:"output tag" (省略则不对迟到数据使用 side output)
.reduce/aggregate/apply/process() <- 必填项:"function"
[.getSideOutput(...)] <- 可选项:"output tag"
Non-Keyed Windows类型
stream
.windowAll(...) <- 必填项:"WindowAssigner"
[.trigger(...)] <- 可选项:"trigger" (else default trigger)
[.evictor(...)] <- 可选项:"evictor" (else no evictor)
[.allowedLateness(...)] <- 可选项:"lateness" (else zero)
[.sideOutputLateData(...)] <- 可选项:"output tag" (else no side output for late data)
.reduce/aggregate/apply/process() <- 必填项:"function"
[.getSideOutput(...)] <- 可选项:"output tag"
在窗口算子的使用过程中WindowAssigner和function两步是必备操作,根据实际业务需要trigger、evictor、allowedLateness、sideOutputLateData、getSideOutput是可选操作。根据时间类型及窗口类型不同划分组合来看,WindowAssigner有以下几种常见的实现类:GlobalWindows、ProcessingTimeSessionWindows、EventTimeSessionWindows、TumblingProcessingTimeWindows、TumblingEventTimeWindows、SlidingProcessingTimeWindows、SlidingEventTimeWindows。后面会详细分析窗口程序基本结构的源码实现过程。
2、以Keyed Windows类型为例分析源码实现过程:
(1)、客户端新建WindowOperator、OneInputTransformation、DataStream过程解析。Flink1.18版本KeyedStream类timeWindow(...)方法已标记为不推荐状态,可直接使用window方法。使用方式如下:
keyedStream.window(SlidingProcessingTimeWindows.of(Time.of(1, MINUTES), Time.of(10, SECONDS));

(2)、入参一个具体的WindowAssigner实例,调用完方法window(...)后,实际上是生成一个WindowStream流。它重要成员变量包含如下:
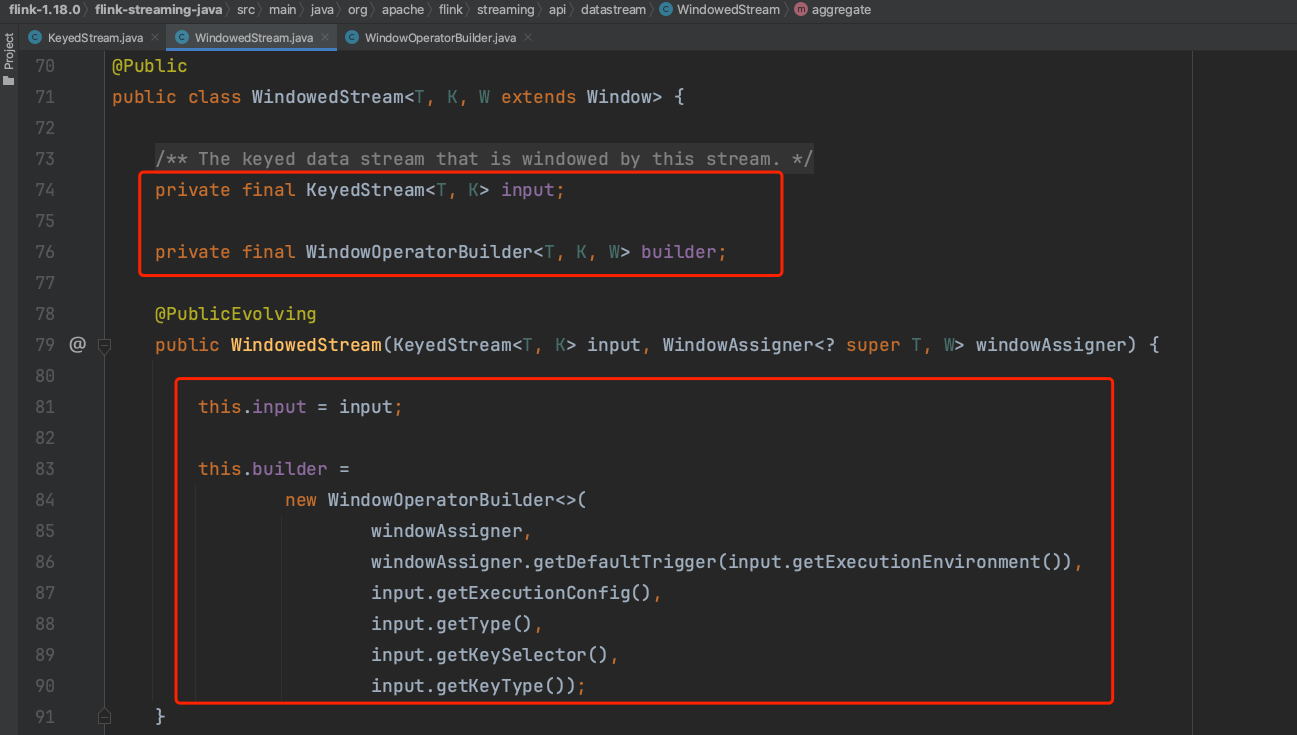
private final KeyedStream<T, K> input; private final WindowOperatorBuilder<T, K, W> builder;
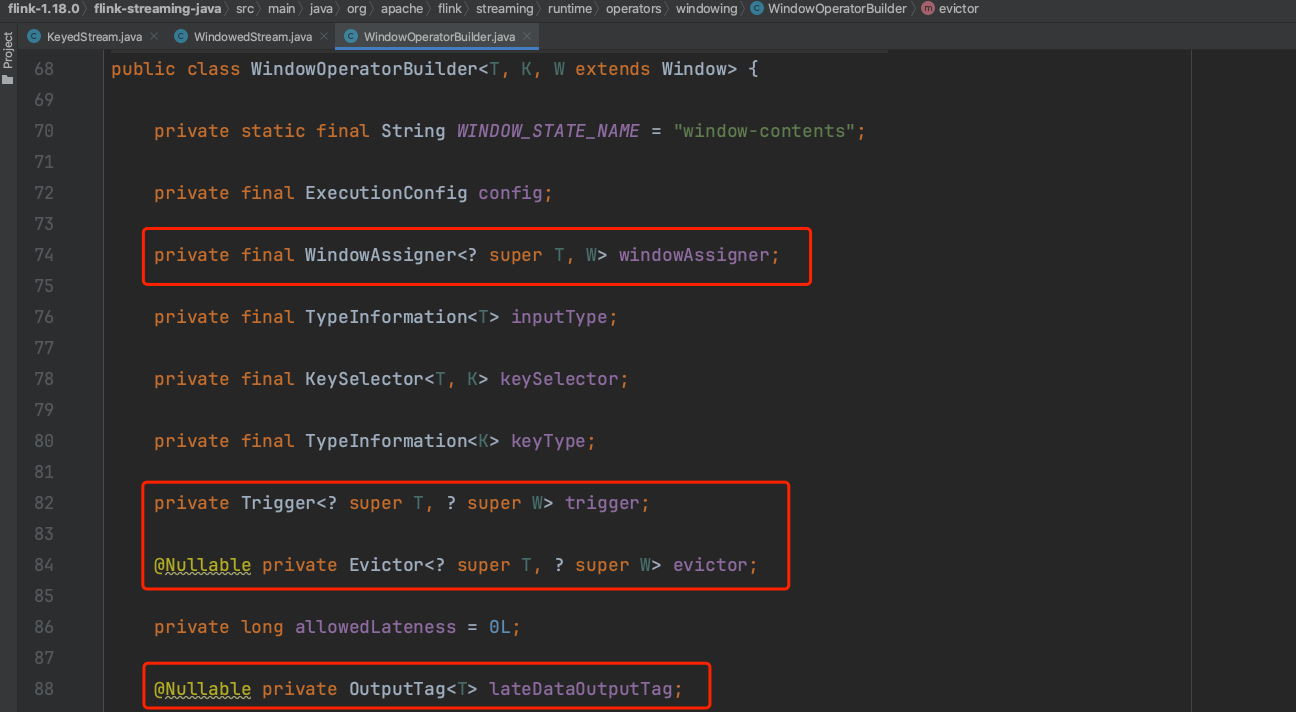
用WindowAssigner构建一个WindowOperatorBuilder实例。
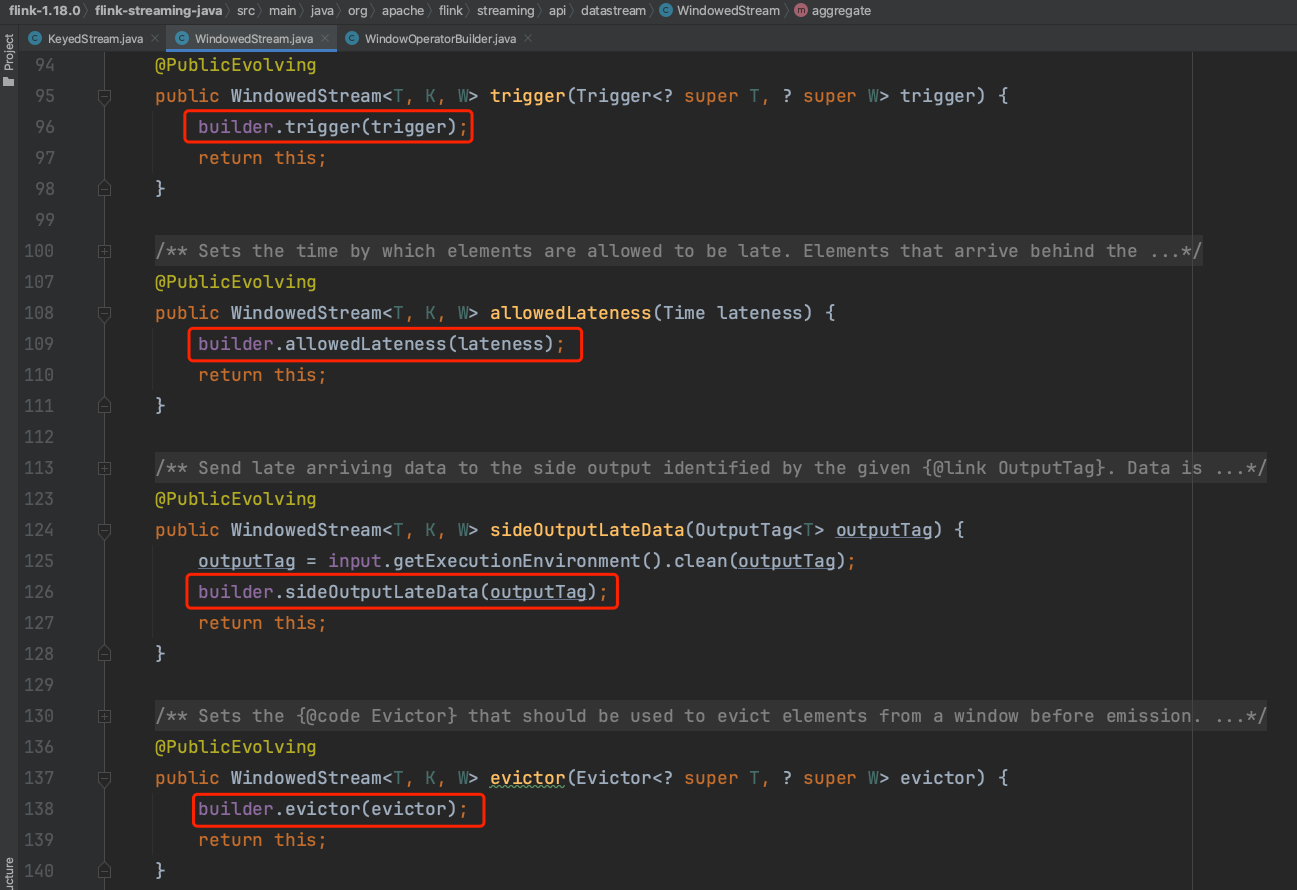
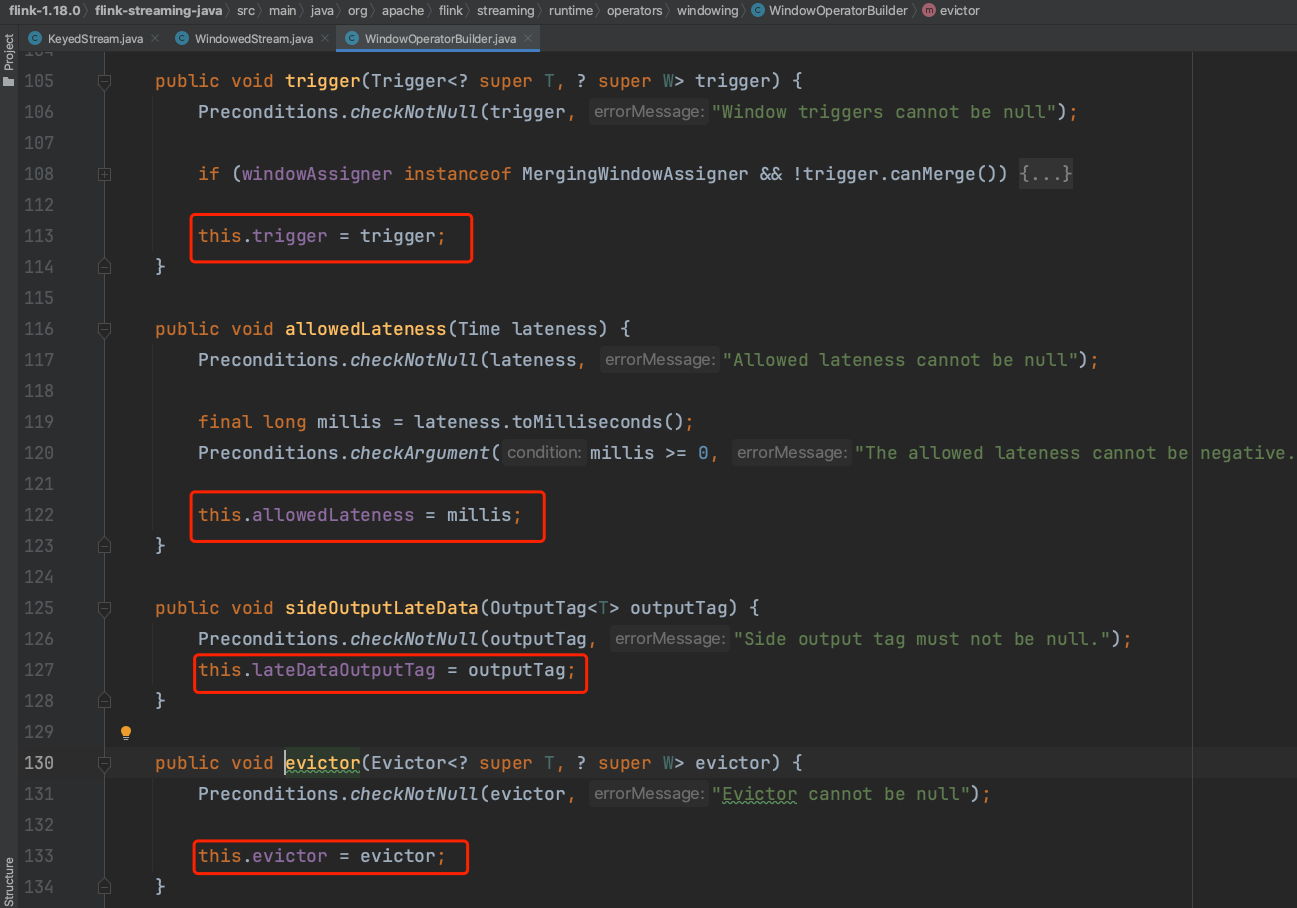
(3)、在窗口程序的基本结构中,方法trigger(...)、evictor(...)、allowedLateness(...)、sideOutputLateData(...)调用目的是设置WindowOperatorBuilder的成员变量。
(4)、以聚合方法为例,aggregate(...)调用需要一个聚合UDF函数入参。
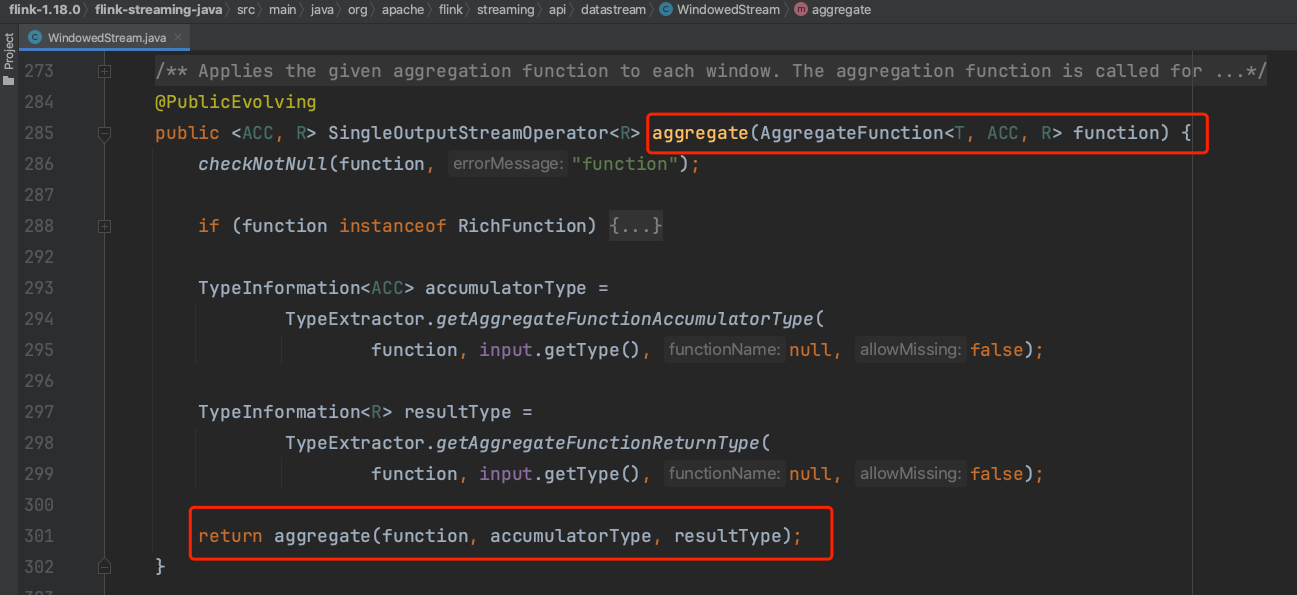
(5)、如下图所示,Flink系统会自动生成一个WindowFunction类的子类PassThroughWindowFunction实例作为window算子的UDF函数。
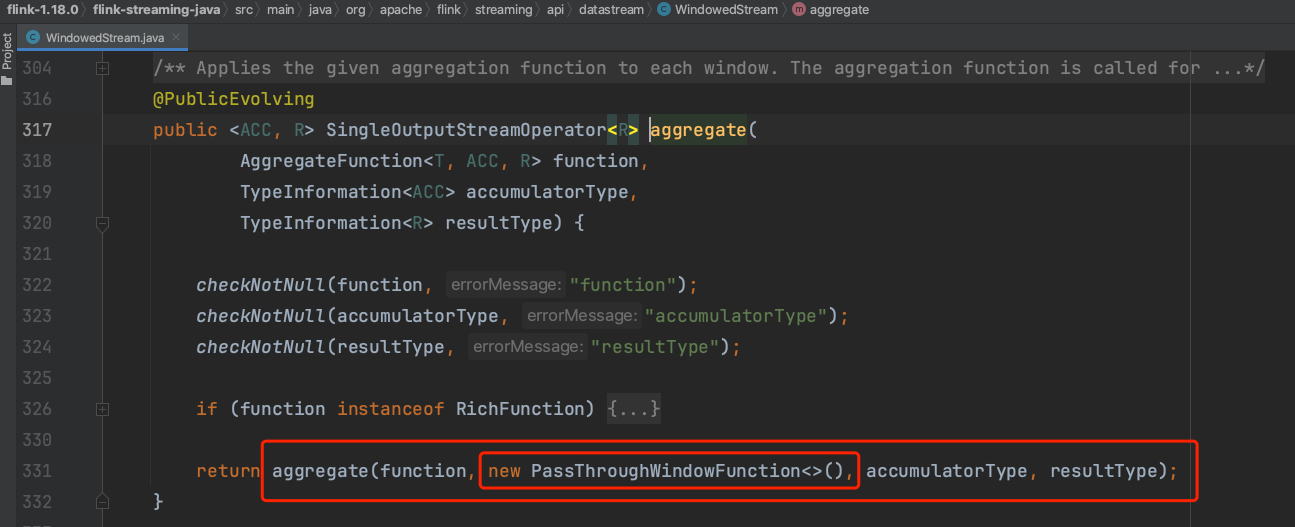
(6)、用户传入的aggregateFunction最后被设置到状态实例中,而不是直接设置到WindowOperator中。具体可参考RocksDBAggregatingState、HeapAggregatingState实现类,说明aggregate方法真正聚合的动作在中间状态的操作过程中触发。WindowOperatorBuilder使用2个UDF函数创建出一个具体WindowOperator实例。
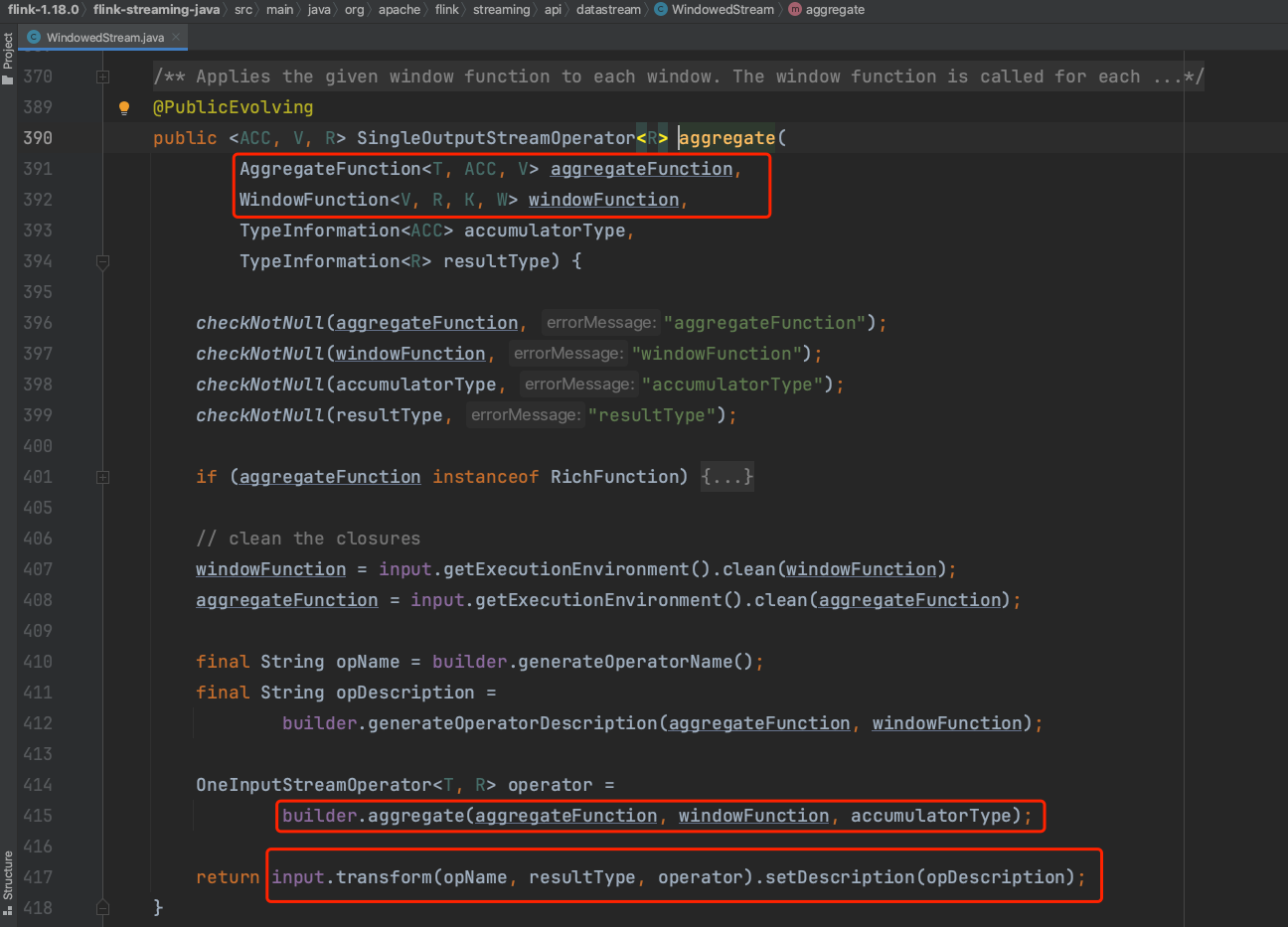
(7)、如下为比较熟悉的创建Transformation的过程。
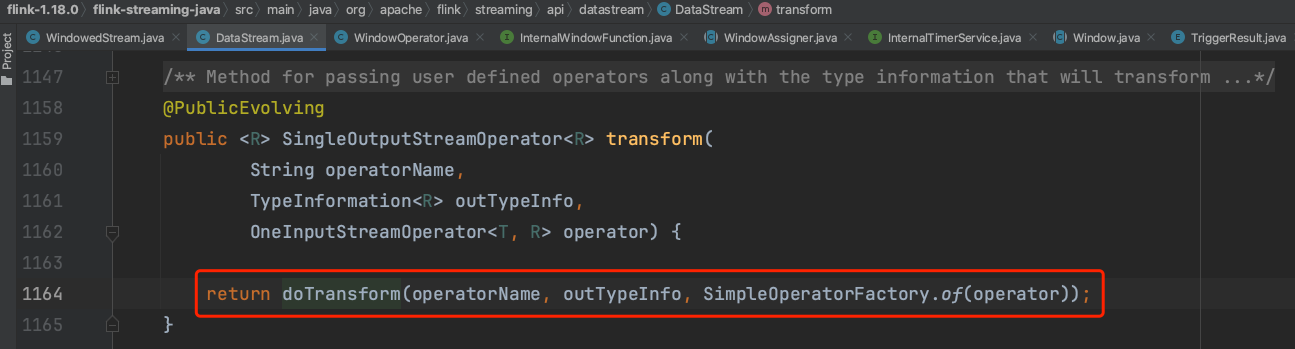
(8)、生成单输入OneInputTransformation、DataStream,并将resultTransform放入env中的转换列表中。

(9)、在第(6)步中Line 415处调用aggregate方法时,内部实际上是创建WindowOperator实例的过程。
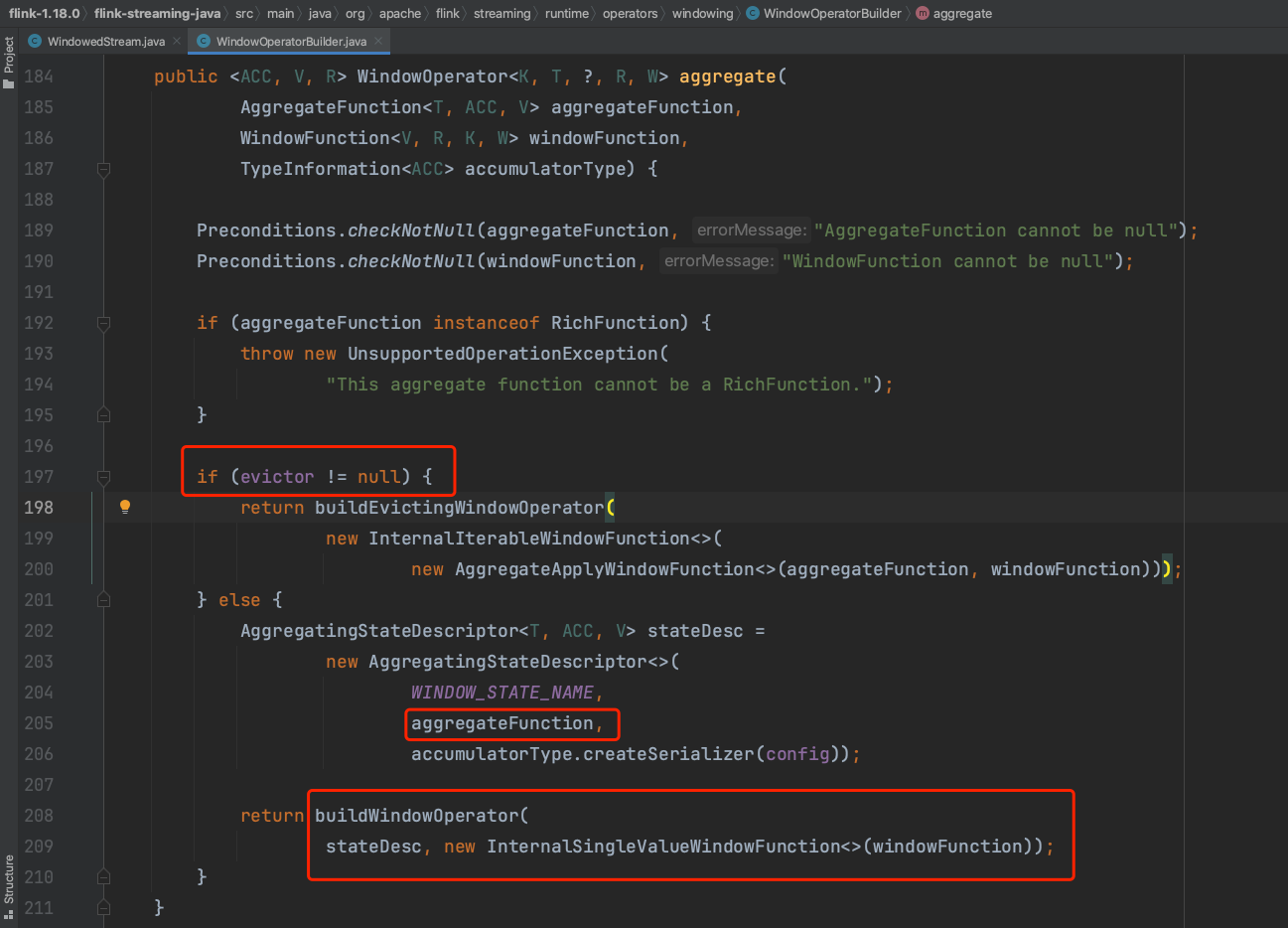
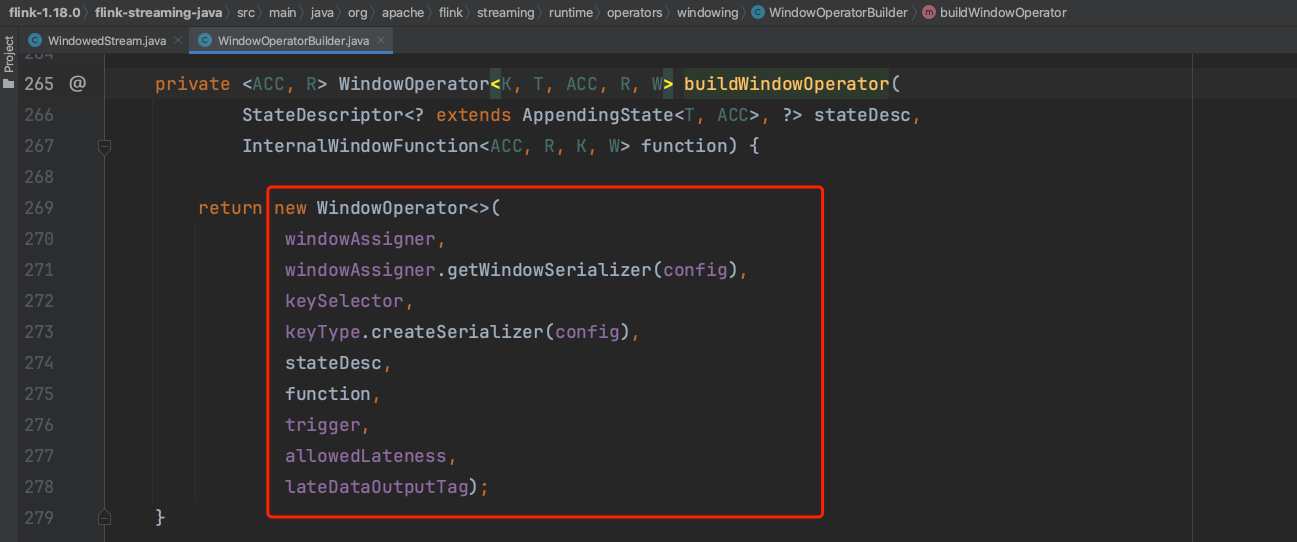
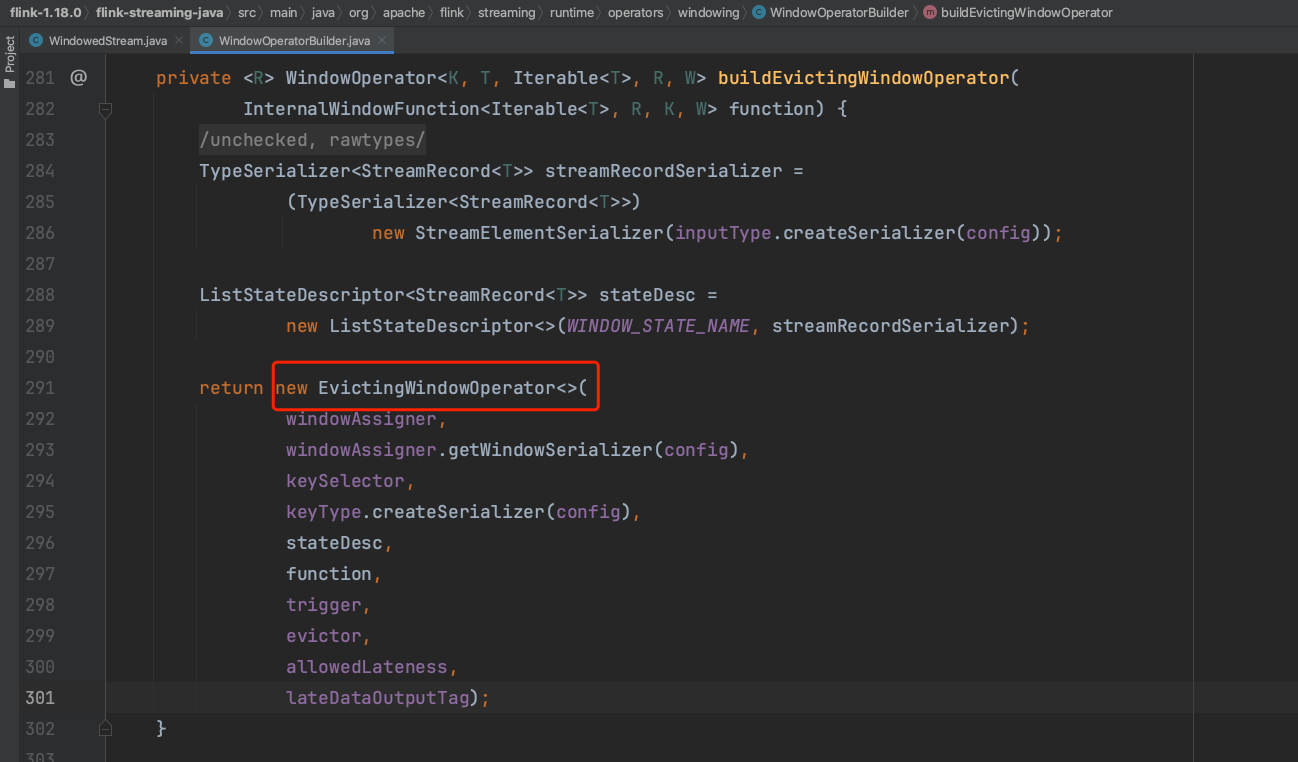
3、在运行时刻WindowAssigner、trigger、evictor、aggregate等执行过程解析
(1)、以WindowAssigner类型为SlidingProcessingTimeWindows为例,假设现在是01:56,实现一个窗口大小为1hour,滑动距离为10min的处理时间窗口分配器,则窗口分配过程如下:

调用kededStream.window(SlidingProcessingTimeWindows.of(Time.hours(1),Time.minutes(10))),给窗口过程指定窗口分配器。

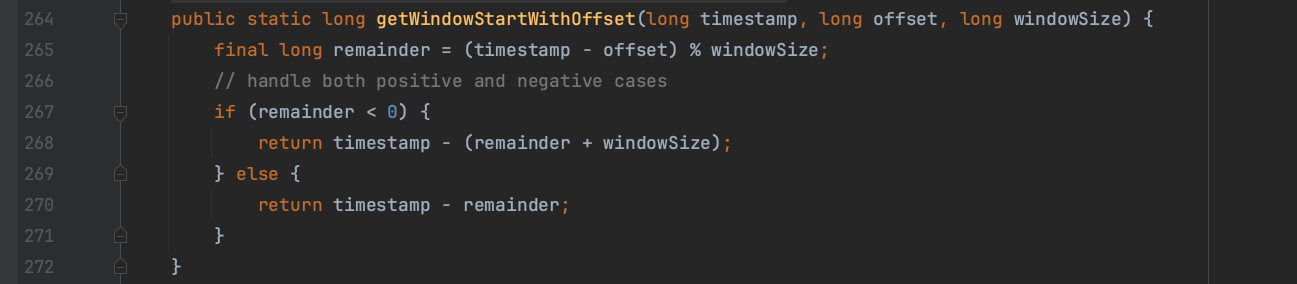
(2)、其中size为1hour,slide为10min、offset为0、下图assignWindows方法中timestamp为01:56。1hour/10min=6,容易理解同一个时间戳会分配到6个窗口中。代码TimeWindow.getWindowStartWithOffset(timestamp, offset, slide);执行过后,结果为01:50,即为6个窗口中最后一个窗口的开始时间,按slide 10min往前推,依次生成前5个窗口的开始时间。最后窗口分配器为01:56分配好6个滑动处理时间窗口。
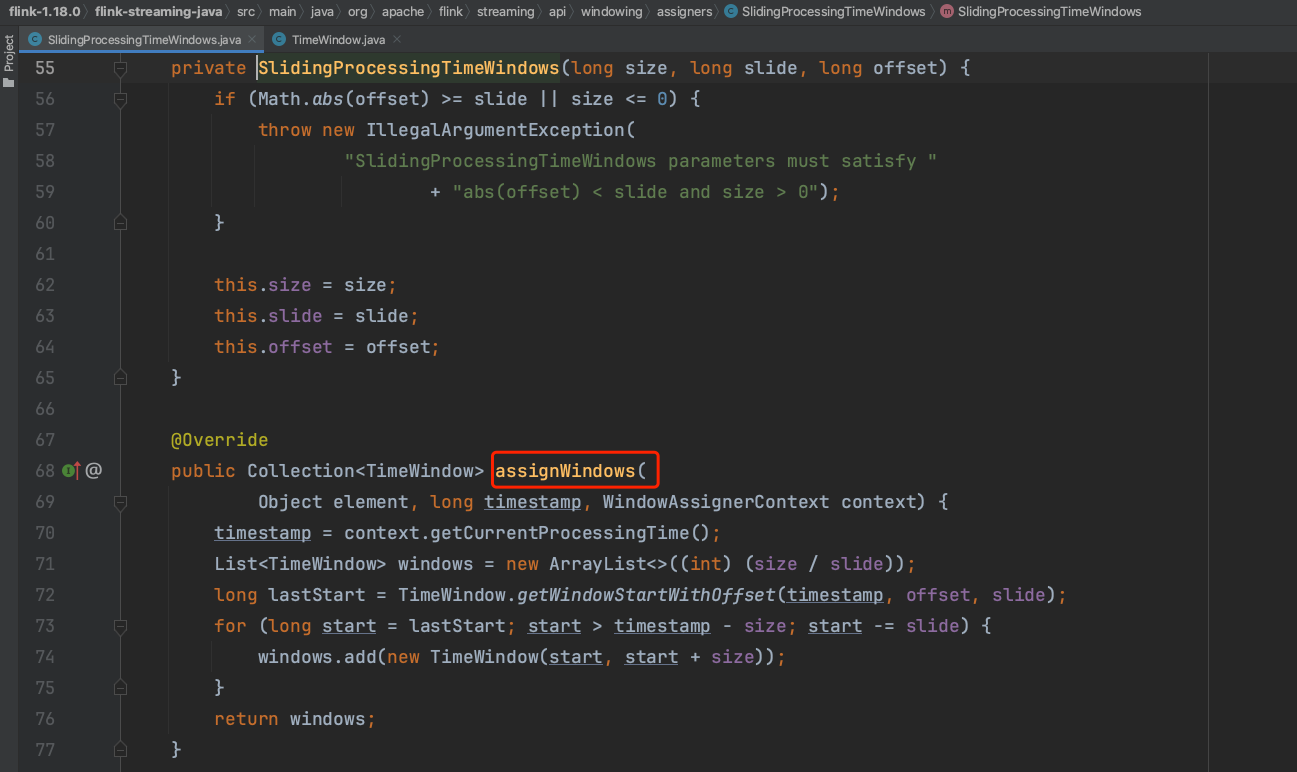
(3)、MergingWindowAssigner类型一般用在会话窗口中,此例以普通时间窗口为例接方法processElement(...)解析过程。在上一步中elementWindows有6个窗口元素。循环遍历每个窗口元素,做如下动作:
1)、isWindowLate(window)判断窗口是否延迟。
2)、windowState.add(element.getValue())更新窗口聚合状态的值。在该方法中会调用用户传入的AggregateFunction聚合逻辑。具体可参考AggregatingState类文件上的注释说明。
3)、TriggerResult triggerResult = triggerContext.onElement(element);实际上是调用窗口程序结构中trigger的逻辑。Trigger触发结果主要有Fire、Purge等4个枚举值。Fire代表会触发计算,处理窗口数据。Purge会触发清理、移除窗口和窗口中的数据。
4)、sideOutput(element)会将延迟数据放到分支流中以备后续处理。

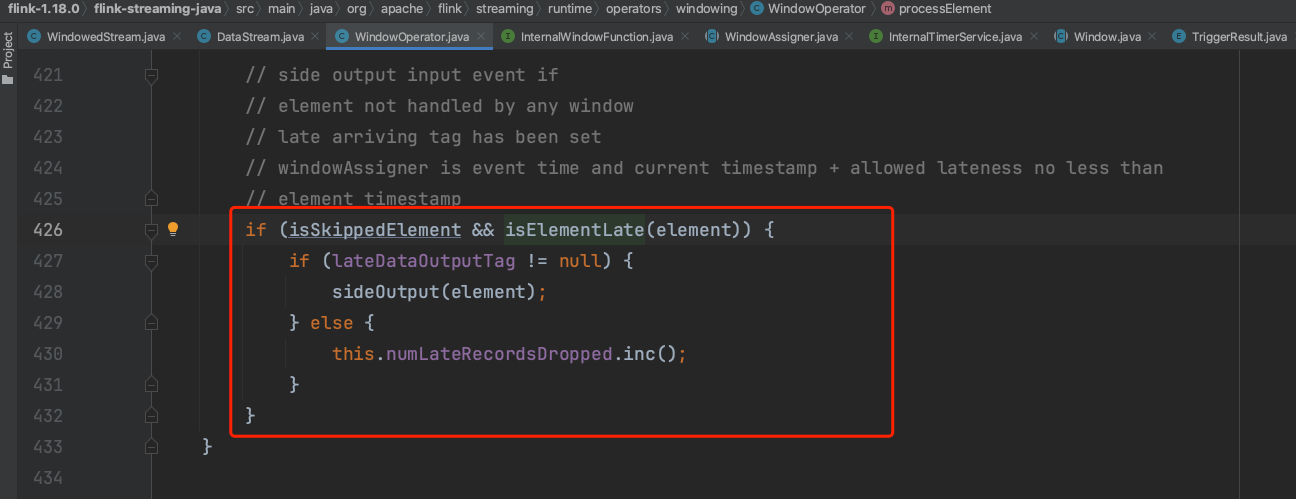

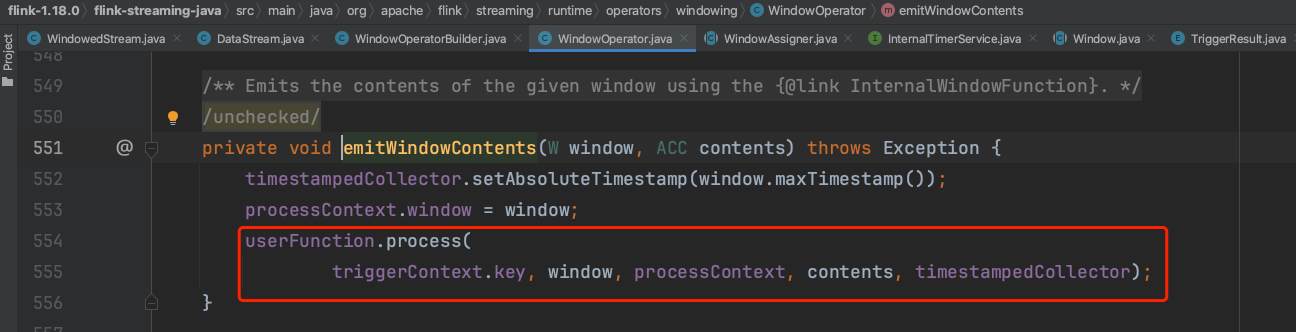
5)、emitWindowContents方法的调用实际上是将聚合函数的处理结果状态数据输出到下游DataStream中,至此窗口数据处理完毕。此处的userFunction即为上面WindowOperator创建过程中传入的InternalSingleValueProcessWindowFunction实例。InternalSingleValueProcessWindowFunction实例中包含Flink系统提供的PassThroughWindowFunction实例。
4、时间服务
在Flink应用程序开发过程中,KeyedProcessFunction和Window中会涉及到时间的概念。在KeyedProcessFunction.processElement()方法中会用到Timer,注册Timer然后重写其onTimer()方法,在具体时间超过Timer的时间点后会触发回调onTimer()方法。此处以Window算子中涉及的时间服务为例,解析时间服务的作用过程。定时器服务的主要作用是预先设置一个时间点,等到该时间点后做一定的动作。类比于窗口就是预先设置窗口结束时间,在结束时间之前一直收集源源不断的数据,而到窗口结束时间时,调用窗口函数处理数据。
(1)、定时器服务接口InternalTimerService,主要实现类是InternalTimerServiceImpl。定时器服务实例包含4个重要的元素如:名称、命名空间、键类型K、Triggerable对象。WindowOperator实现了Triggerable接口。在WindowOperator.java中有1个定时器服务成员变量internalTimerService,该变量在open()方法中被初始化,名称是window-timers。代码参考WindowOperator.java文件中175行、216行。在InternalTimerServiceImpl实现类中有2个KeyGroupedInternalPriorityQueue优先级队列,用于维护事件时间和处理时间的定时器Timer。
(2)、定时器Timer,内部接口是InternalTimer,实现类是TimerHeapInternalTimer。窗口的触发器和定时器是紧密联系的。定时器的本质是一个预先设置的过期时间。
(3)、Trigger触发器决定了一个窗口何时能够被计算或清除,每个窗口都有一个自己的Trigger,Trigger上会有定时器,用来决定一个窗口何时能够被计算或清除。每当有元素加入该窗口或则之前注册的定时器超时,Trigger都会被调用。下面具体分析窗口触发器和定时器的联系过程。
以处理时间为例,此时Trigger实现类是ProcessingTimeTrigger。在方法WindowOperator.processElement(...)实现中,第404行TriggerResult triggerResult = triggerContext.onElement(element);实际上调用的是ProcessingTimeTrigger类的onElement()方法,如下图所示。
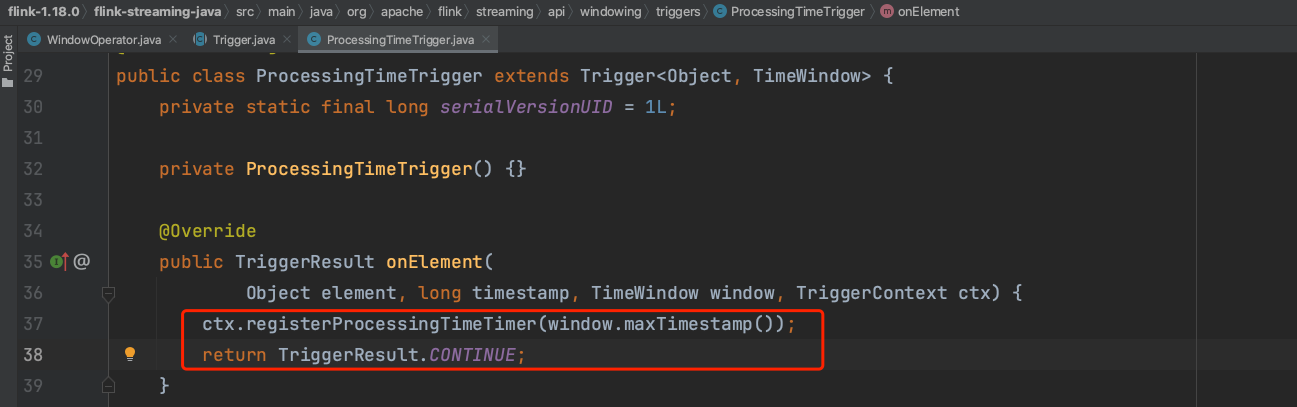
该方法中37行作用是在定时器中注册一个窗口结束时间的定时器。38行返回TriggerResult.CONTINUE;枚举值,代表继续,不做任何操作。
(4)、定时器到期后定时服务是调用具体业务逻辑如下:
在上面37行注册一个窗口结束时间的定时器代码中最终会调用定时器服务实现类InternalTimerServiceImpl的registerProcessingTimeTimer方法,该方法会调用processingTimeService成员的registerTimer方法。
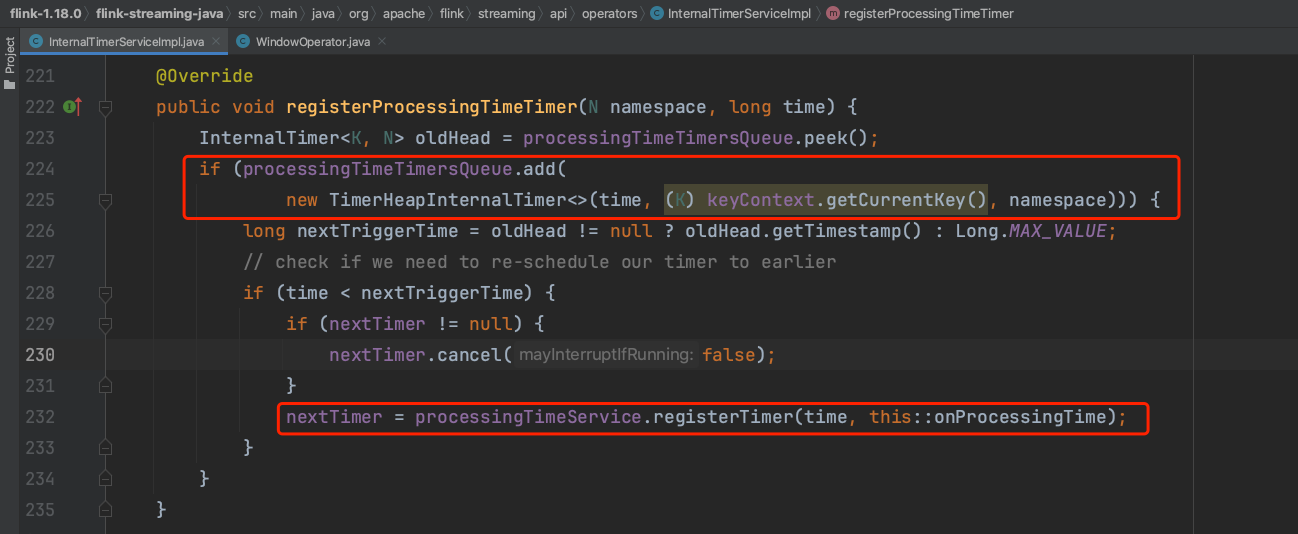
嵌套调用SystemProcessingTimeService类的registerTimer方法,最终调用timerService.schedule(wrapOnTimerCallback(callback, timestamp), delay, TimeUnit.MILLISECONDS);而此处timerService成员的类型是JUC包中的ScheduledThreadPoolExecutor。哈哈哈java的4种线程池类型之一ScheduledThreadPoolExecutor,可以周期性或指定时间执行具体的任务。
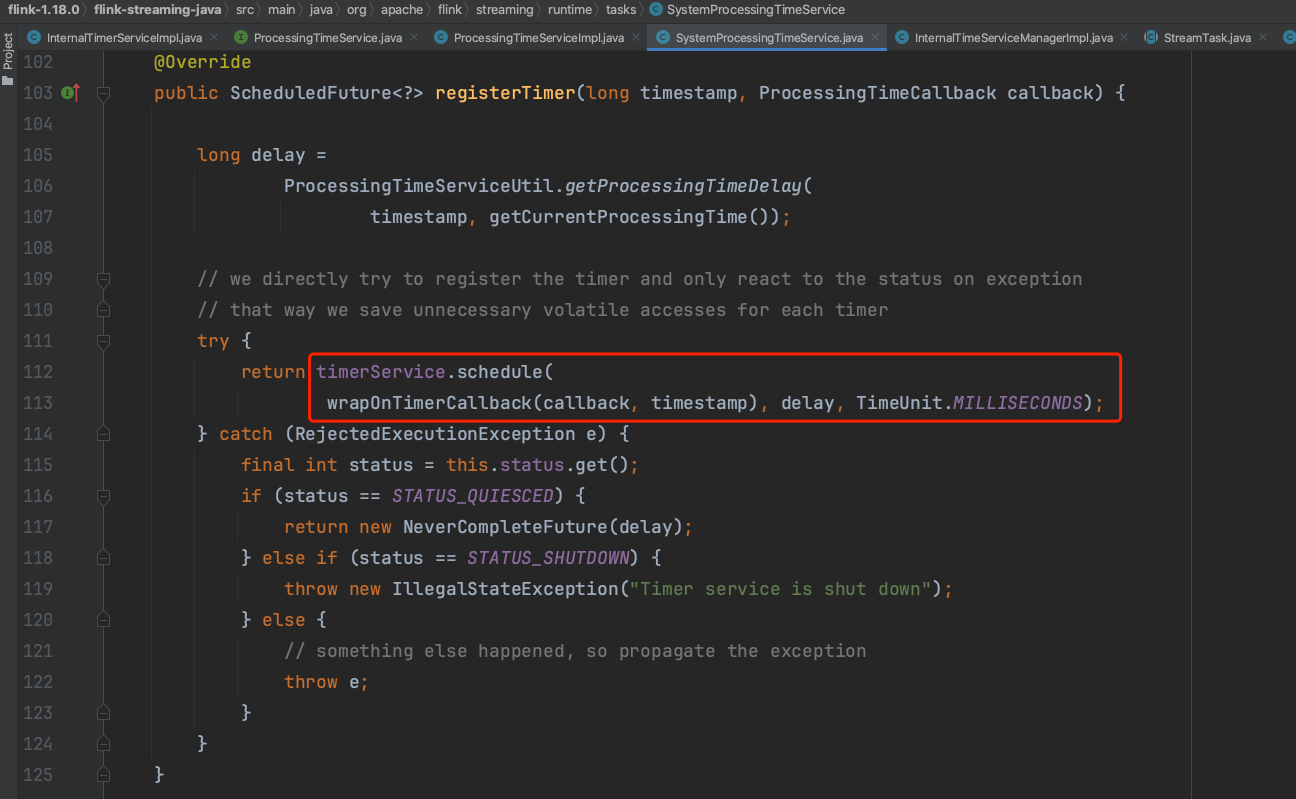
总结一下:窗口的触发器和定时器是紧密联系的。在处理时间类型的窗口中,ProcessingTimeTrigger触发器每接收一条数据,都先缓存数据并注册窗口结束时间定时器。而窗口结束时间定时器实际上作用在JUC包中ScheduledThreadPoolExecutor线程池类的schedule方法中,到时间后执行InternalTimerServiceImpl类的onProcessingTime方法,继而调用WindowOperator.java类的onProcessingTime方法,继而进行真正的数据处理构成。
四、窗口原理在coGroup、window join api的应用解析
1、coGroup api调用过程
coGroup api调用指得是方法DataStream.coGroup(...)调用过程,其底层通过窗口原理实现,基本使用流程如下:
dataStream1.coGroup(otherStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<CoGroupFunction>)
(1)、第一步DataStream实例调用coGroup()方法生成CoGroupStreams流实例。
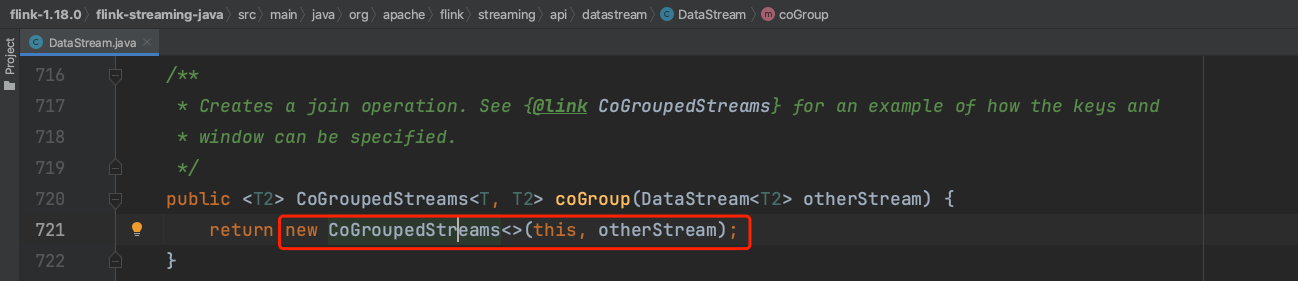
(2)、可知CoGroupStreams类似于一个包装类,包含2个输入流。当CoGroupStreams实例调用where()方法时实际上是生成一个Where类实例。
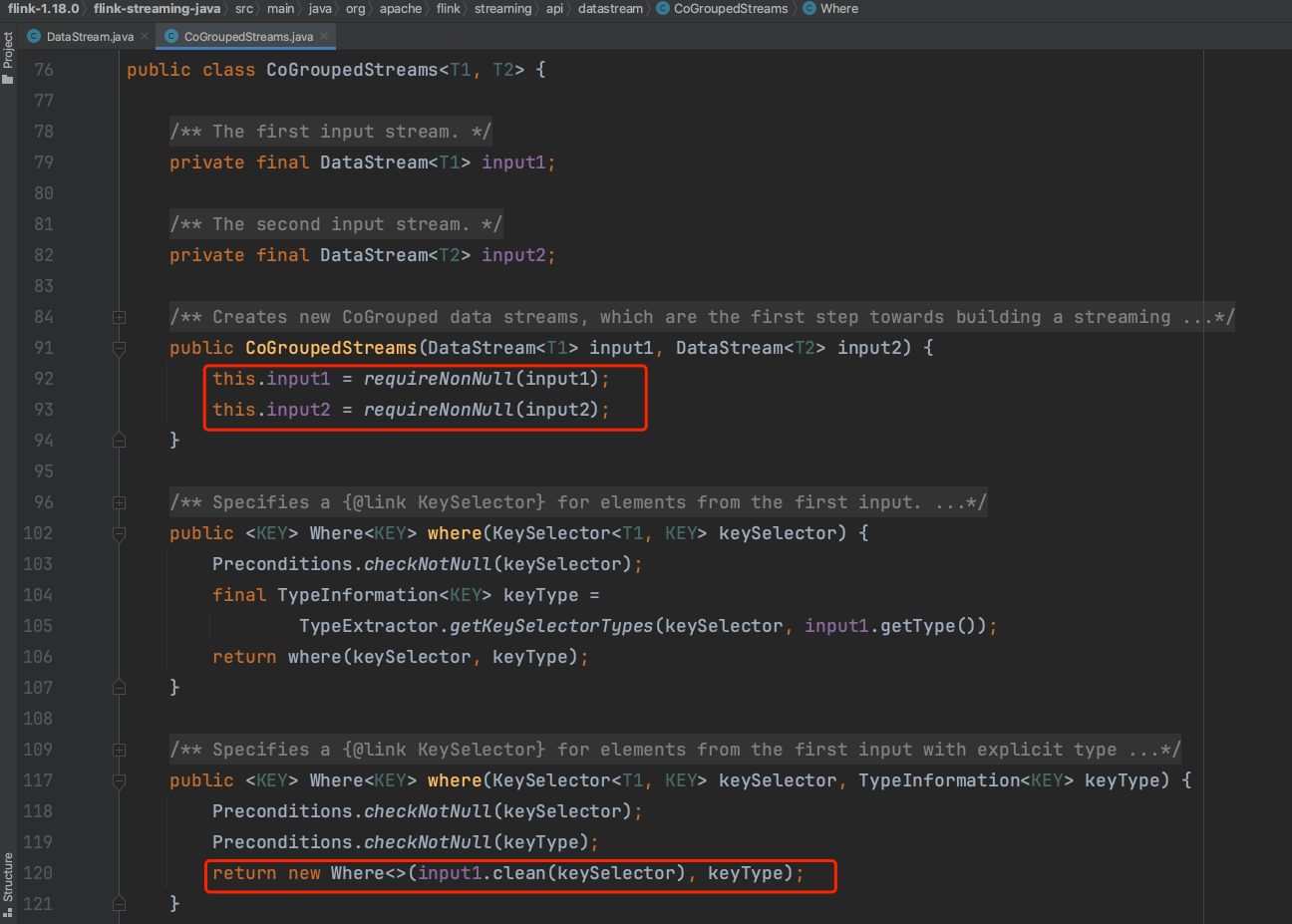
(3)、Where类也类似一个包装类,包含DataStream1的KeySelector成员。当调用equalTo()方法时生成一个EqualTo内部类实例。
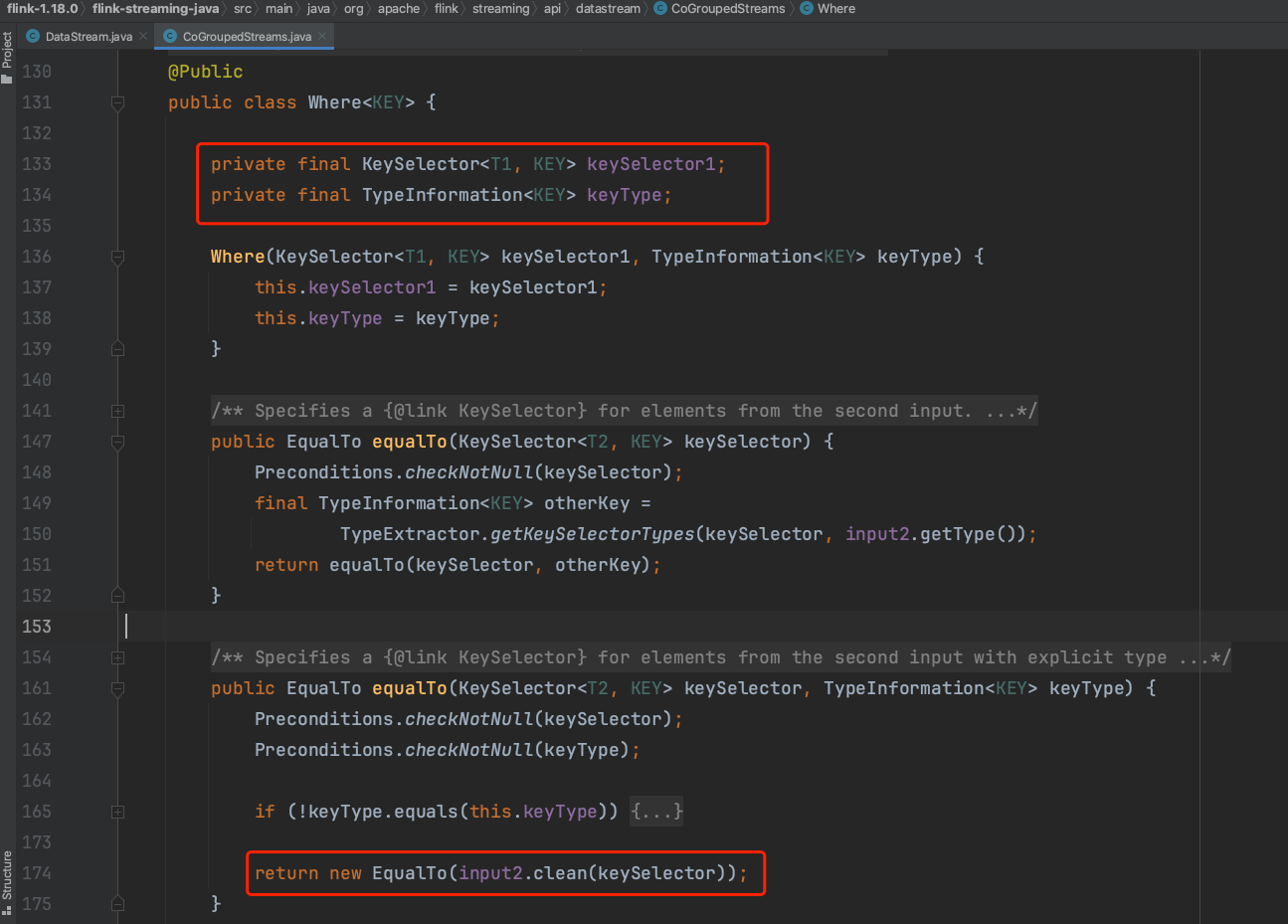
(4)、EqualTo实例调用window()方法时可知入参要求一个WindowAssigner实例并生成WithWindow实例。
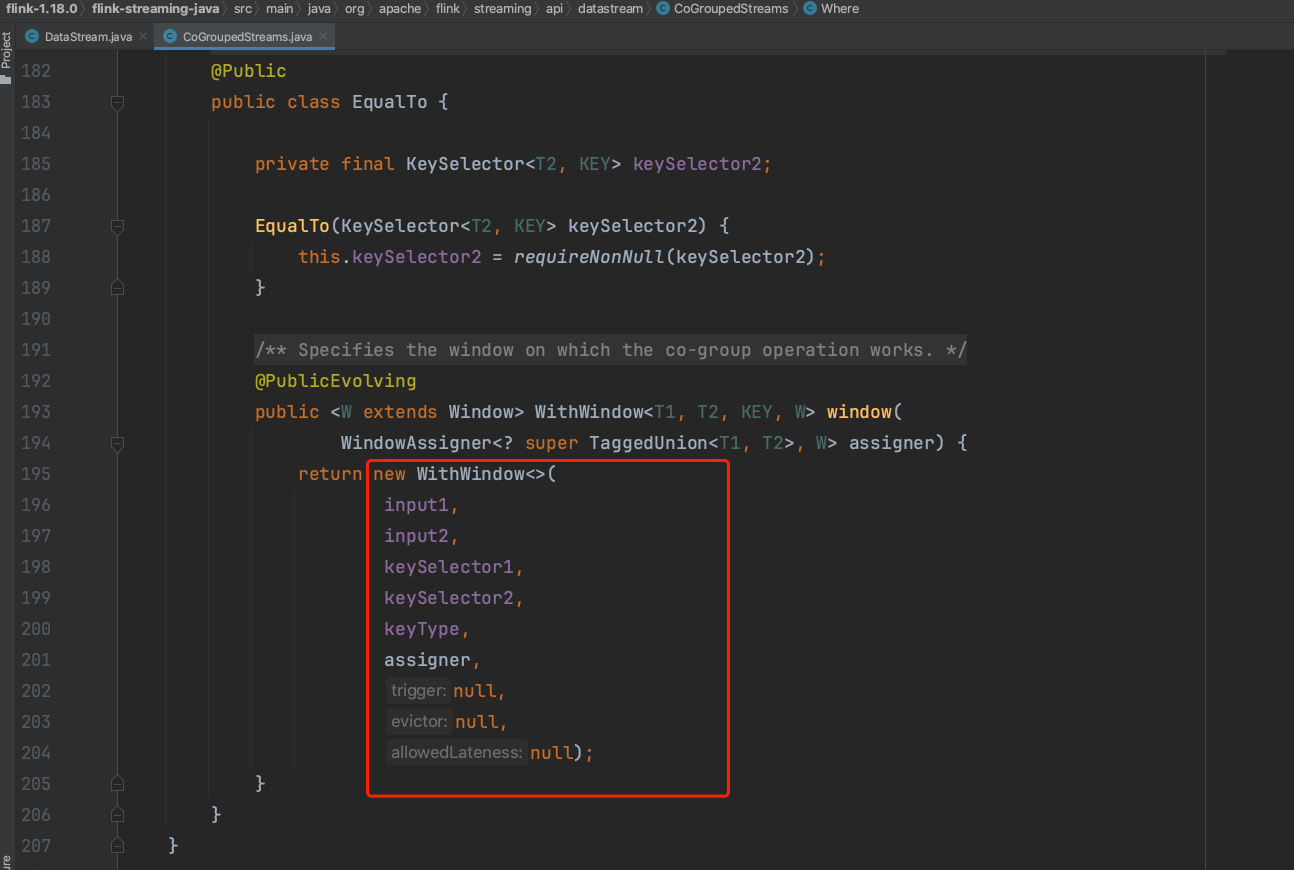
(5)、WithWindow实例最后调用apply()方法,在apply()方法实现中可知,第一步借用TaggedUnion将实例dataStream1、otherStream合并成一个普通的DataStream流。第二步生成普通的KeyedStream实例。第三步借用windowAssigner生成一个窗口流windowedStream。
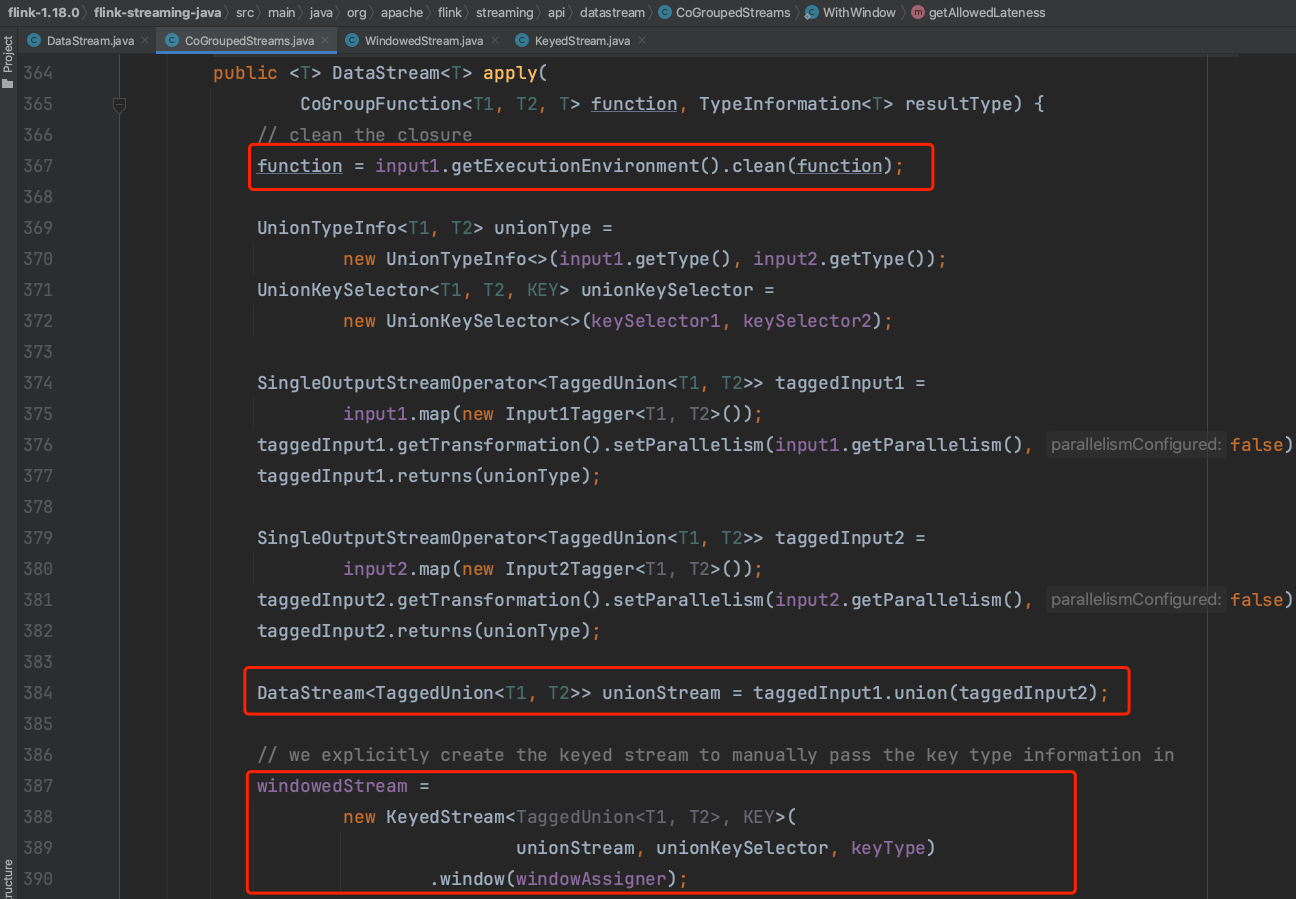
(6)、在窗口流实例windowedStream中,trigger、evictor、allowedLateness都是可选操作。最后利用窗口函数CoGroupWindowFunction将用户传入的函数逻辑包装起来,做窗口数据的处理动作。

以上可知coGroup api方法是借用窗口的原理实现其过程。
2、Window Join调用过程
Window Join调用指的是方法DataStream.join(...)调用过程,因底层是通过窗口原理实现其过程故分类为Window Join过程。其基本使用流程如下:
dataStream1.join(otherStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
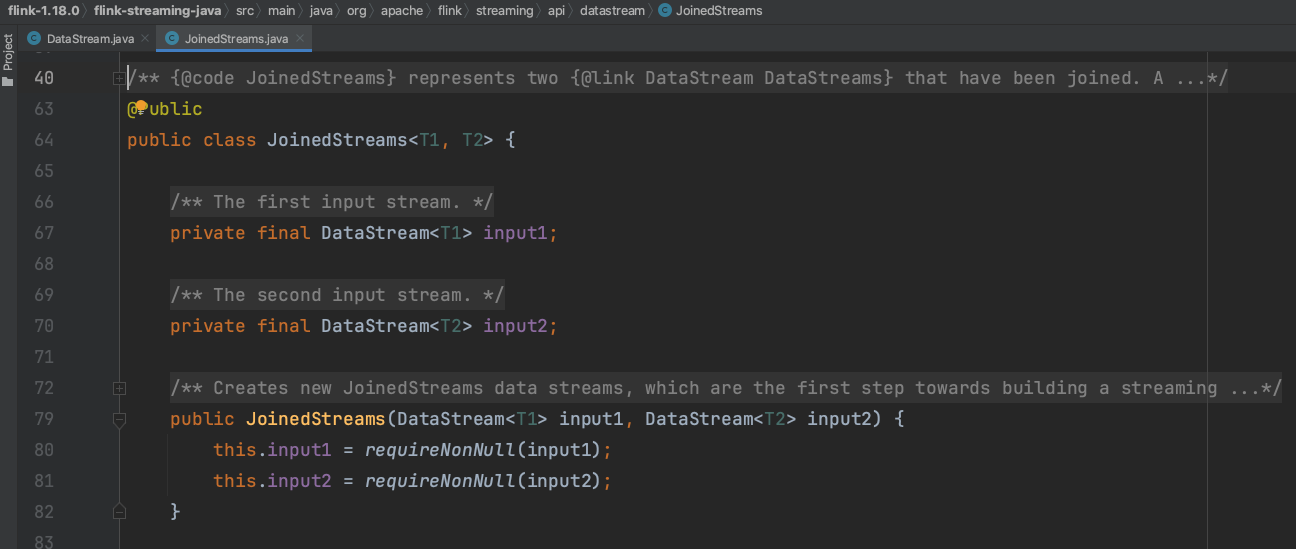
(1)、第一步DataStream实例调用join()方法生成JoinedStreams流实例。
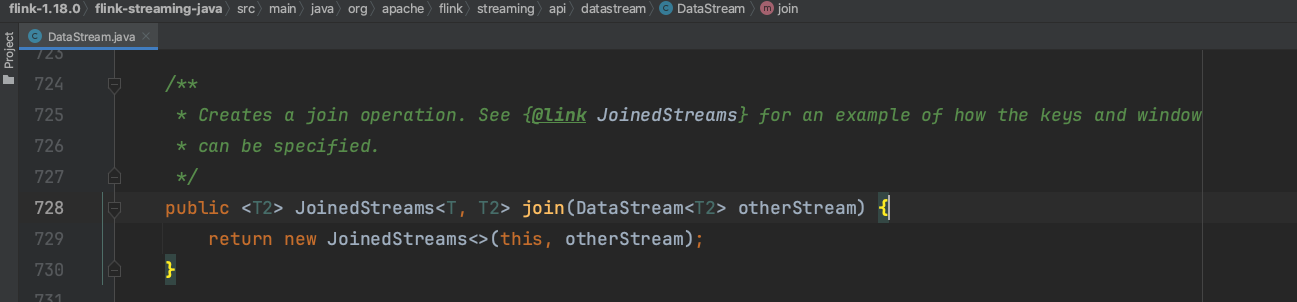
(2)、可知JoinedStreams类似于一个包装类,包含2个输入流。
(3)、当JoinedStreams实例调用where()方法时实际上是生成一个Where类实例。
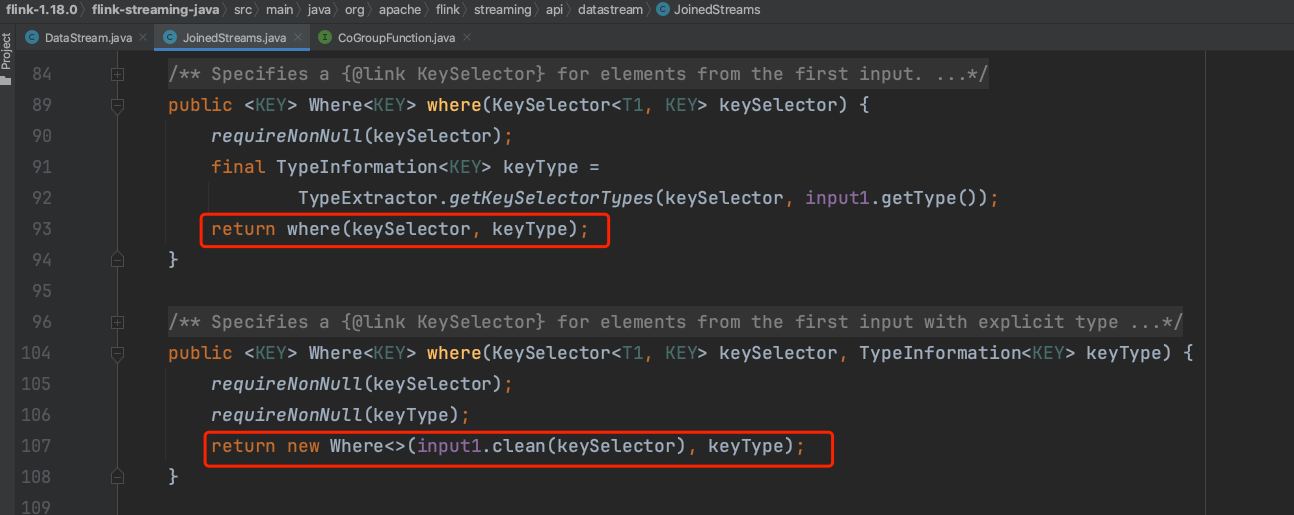
(4)、Where类也类似一个包装类,包含DataStream1的KeySelector成员。当调用equalTo()方法时生成一个EqualTo内部类实例。

(5)、EqualTo实例调用window()方法时可知入参要求一个WindowAssigner实例并生成WithWindow实例。
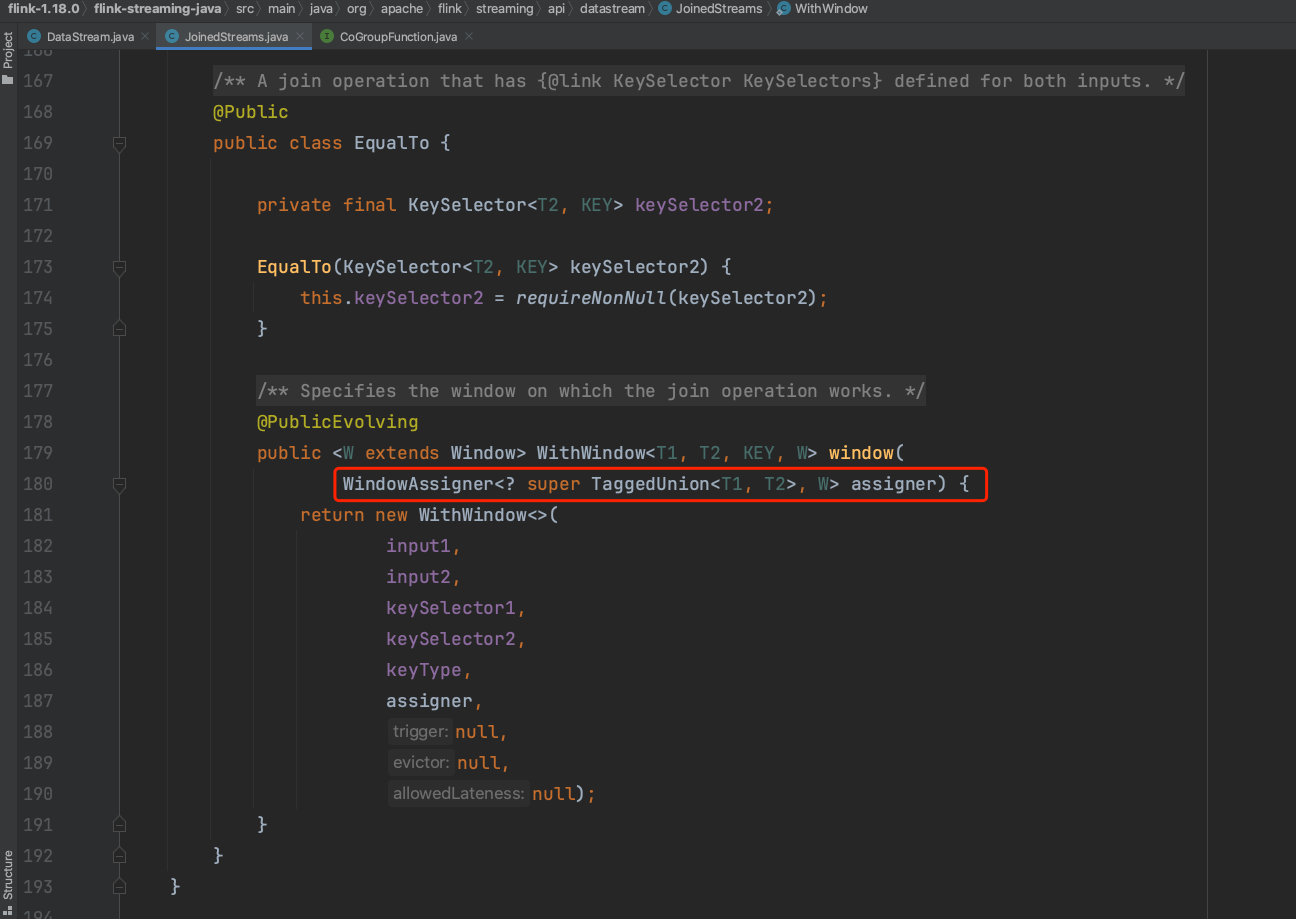
(6)、WithWindow实例调用apply()方法时,实际上是借用coGroup api实现其工作过程。
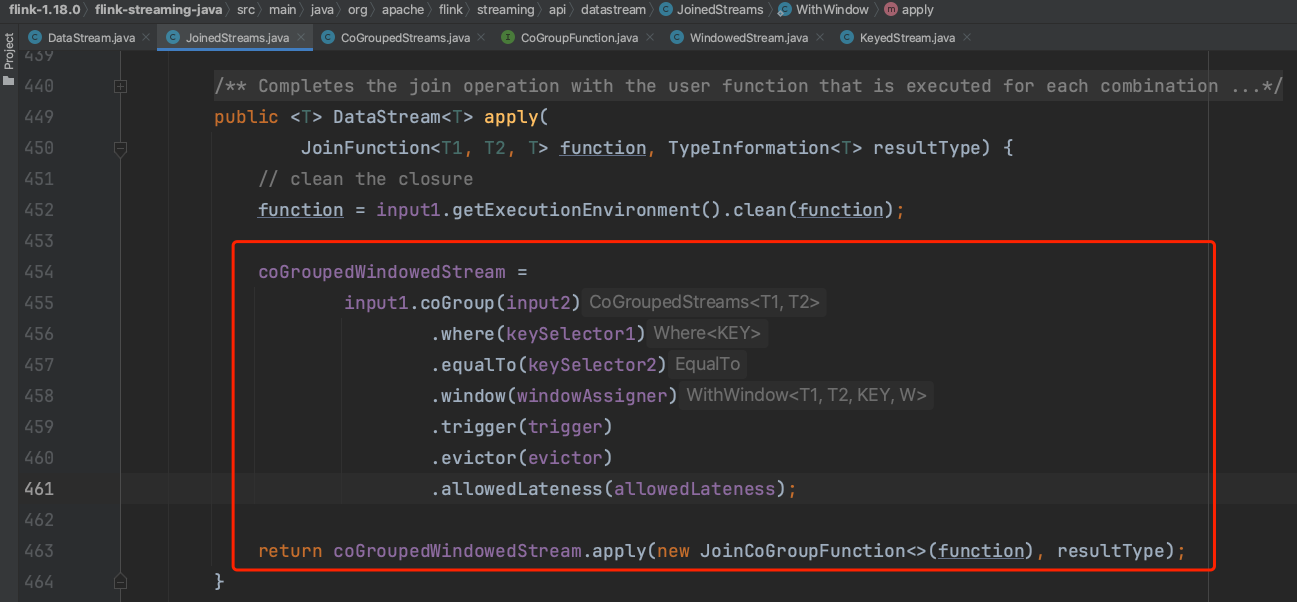
(7)、在第(6)步中Flink系统用JoinCoGroupFunction函数封装用户传入的处理逻辑。JoinCoGroupFunction的数据调用过程如下,实际上实现的是inner join的过程。如果想实现left join、right join、full join逻辑,可借用coGroup api方法,重写以下双重循环逻辑得到。
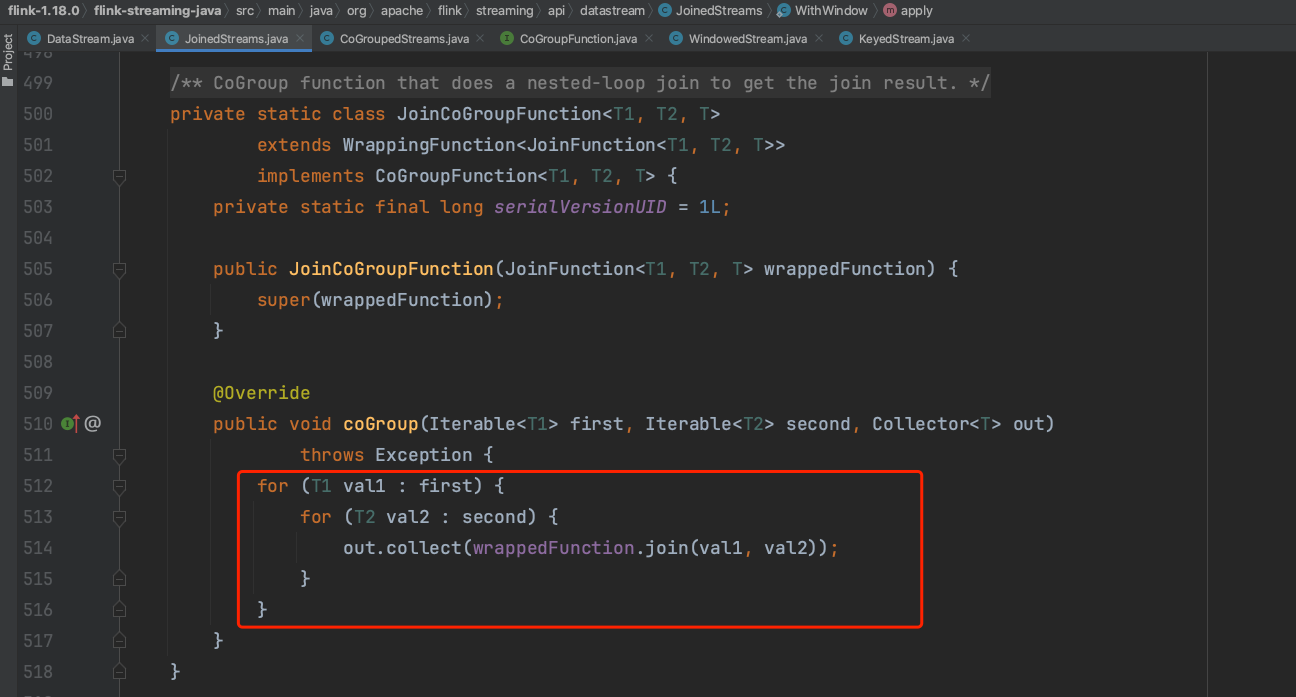
以上可知join api方法是借用窗口的原理实现其过程。通过自定义coGroup过程,可实现left join、right join、full join逻辑。
