

C# 利用WebClient抓取网页数据

内容。。。。
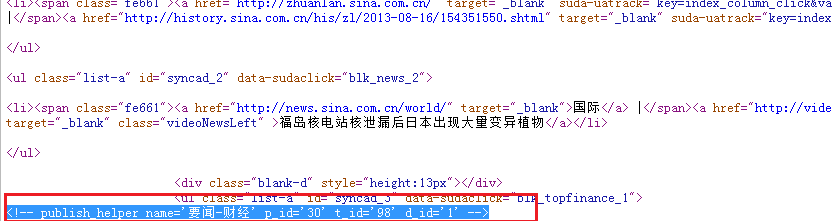
protected void Enter_Click(object sender, EventArgs e) 2 { 3 WebClient we = new WebClient(); //主要使用WebClient类 4 byte[] myDataBuffer; 5 myDataBuffer = we.DownloadData(txtURL.Text); //该方法返回的是 字节数组,所以需要定义一个byte[] 6 string download = Encoding.Default.GetString(myDataBuffer); //对下载的数据进行编码 7 8 9 //通过查询源代码,获取某两个值之间的新闻内容 10 int startIndex = download.IndexOf("<!-- publish_helper name='要闻-新闻' p_id='1' t_id='850' d_id='1' -->"); 11 int endIndex = download.IndexOf("<!-- publish_helper name='要闻-财经' p_id='30' t_id='98' d_id='1' -->"); 12 13 string temp = download.Substring(startIndex, endIndex - startIndex + 1); //截取新闻内容 14 15 lblMessage.Text = temp;//显示所截取的新闻内容 16 }
除了把下载的数据保存为文本以外,还可以保存为 文件类型 和 流 类型。

1 WebClient wc = new WebClient(); 2 wc.DownloadFile(TextBox1.Text, @"F:\test.txt"); 3 Label1.Text = "文件下载完成";
1 WebClient wc = new WebClient(); 2 Stream s = wc.OpenRead(TextBox1.Text); 3 4 StreamReader sr = new StreamReader(s); 5 Label1.Text = sr.ReadToEnd();

 浙公网安备 33010602011771号
浙公网安备 33010602011771号