LeetCode-139. 单词拆分
题目来源
题目详情
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。
注意: 不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"]
输出: true
解释: 返回 true 因为 "leetcode" 可以由 "leet" 和 "code" 拼接成。
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"]
输出: true
解释: 返回 true 因为 "applepenapple" 可以由 "apple" "pen" "apple" 拼接成。
注意,你可以重复使用字典中的单词。
示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"]
输出: false
提示:
1 <= s.length <= 3001 <= wordDict.length <= 10001 <= wordDict[i].length <= 20s和wordDict[i]仅有小写英文字母组成wordDict中的所有字符串 互不相同
题解分析
解法一:动态规划
- 定义 \(\textit{dp}[i]\) 表示字符串 s 前 i 个字符组成的字符串 s[0..i-1] 是否能被空格拆分成若干个字典中出现的单词。从前往后计算考虑转移方程,每次转移的时候我们需要枚举包含位置 i-1 的最后一个单词,看它是否出现在字典中以及除去这部分的字符串是否合法即可。
- 公式化来说,我们需要枚举 s[0..i-1] 中的分割点 j ,看 s[0..j-1] 组成的字符串 s1(默认 j = 0 时 s1 为空串)和 s[j..i-1] 组成的字符串 s2 是否都合法,如果两个字符串均合法,那么按照定义 s1 和 s2 拼接成的字符串也同样合法。由于计算到 \(\textit{dp}[i]\) 时我们已经计算出了 \(\textit{dp}[0..i-1]\) 的值,因此字符串 s1 是否合法可以直接由 dp[j] 得知,剩下的我们只需要看 s2 是否合法即可,因此我们可以得出如下转移方程:
\[\textit{dp}[i]=\textit{dp}[j]\ \&\&\ \textit{check}(s[j..i-1])
\]
- 其中 \(\textit{check}(s[j..i-1])\) 表示子串 \(s[j..i-1]\) 是否出现在字典中。
class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
// dp[i]表示s的前i个字符即0 - i-1的字符是否可以由字典中的字符串组成
// dp[i] = dp[j] && check(j, i-1);// check(j, i)用于判断(j - i-1)的子串是否出现在字典中
Set<String> set = new HashSet<>(wordDict);
int n = s.length();
boolean[] dp = new boolean[n + 1];
dp[0] = true;
for(int i=1; i<=n; i++){
for(int j=0; j<i; j++){
dp[i] = dp[j] && set.contains(s.substring(j, i));
if(dp[i]){
break;
}
}
}
return dp[n];
}
}
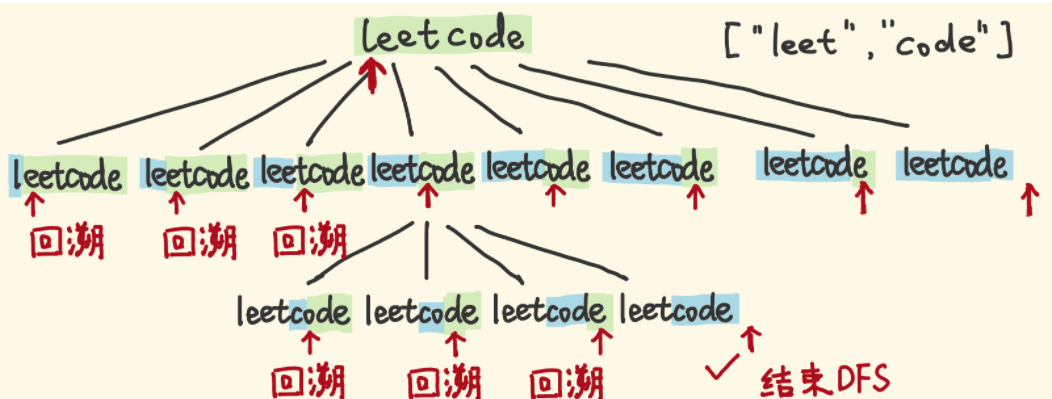
解法二:DFS
- 我们可以使用递归的方法来思考这道问题。
- "leetcode"能否 break,可以拆分为:
- "l"是否是单词表的单词、剩余子串能否 break。
- "le"是否是单词表的单词、剩余子串能否 break。
- "lee"...以此类推
- 用 DFS 回溯,考察所有的拆分可能,指针从左往右扫描:
- 如果指针的左侧部分是单词,则对剩余子串递归考察。
- 如果指针的左侧部分不是单词,不用看了,回溯,考察别的分支。
class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
Set<String> set = new HashSet<>(wordDict);
return canBreak(s, 0, set);
}
private boolean canBreak(String s, int start, Set<String> set){
int n = s.length();
if(start >= n){
return true;
}
for(int end=start + 1; end<=n; end++){
if(set.contains(s.substring(start, end)) && canBreak(s, end, set)){
return true;
}
}
return false;
}
}
解法三:DFS优化
- 上述的解法二会遇到一个问题,那就是重复计算,有很多分支被重复计算了,如下图所示:
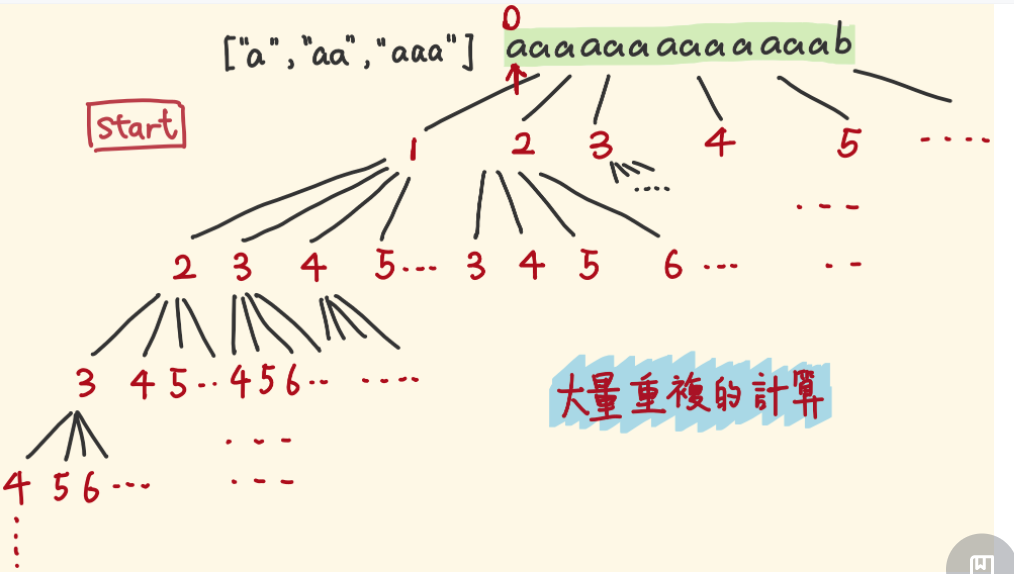
- 解决方法就是使用一个HashMap来记录以某个元素为分界的情况是否符合条件。以此,可以过滤一些已经遍历过的情况。
class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
Set<String> set = new HashSet<>(wordDict);
Map<Integer, Boolean> flag = new HashMap<>();
return canBreak(s, 0, set, flag);
}
private boolean canBreak(String s, int start, Set<String> set, Map<Integer, Boolean> flag){
int n = s.length();
if(start >= n){
return true;
}
if(flag.containsKey(start)){
return flag.get(start);
}
for(int end=start + 1; end<=n; end++){
if(set.contains(s.substring(start, end)) && canBreak(s, end, set, flag)){
flag.put(start, true);
return true;
}
}
flag.put(start, false);
return false;
}
}
结果展示
Either Excellent or Rusty

 浙公网安备 33010602011771号
浙公网安备 33010602011771号