Redis基础及其相关面试题
Redis持久化
一、持久化简介
Redis 的数据 全部存储 在 内存 中,如果 突然宕机,数据就会全部丢失,因此必须有一套机制来保证 Redis 的数据不会因为故障而丢失,这种机制就是 Redis 的 持久化机制,它会将内存中的数据库状态 保存到磁盘 中。
持久化发生了什么 | 从内存到磁盘
我们来稍微考虑一下 Redis 作为一个 "内存数据库" 要做的关于持久化的事情。通常来说,从客户端发起请求开始,到服务器真实地写入磁盘,需要发生如下几件事情:

详细版 的文字描述大概就是下面这样:
- 客户端向数据库 发送写命令 (数据在客户端的内存中)
- 数据库 接收 到客户端的 写请求 (数据在服务器的内存中)
- 数据库 调用系统 API 将数据写入磁盘 (数据在内核缓冲区中)
- 操作系统将 写缓冲区 传输到 磁盘控控制器 (数据在磁盘缓存中)
- 操作系统的磁盘控制器将数据 写入实际的物理媒介 中 (数据在磁盘中)
注意: 上面的过程其实是 极度精简 的,在实际的操作系统中,缓存 和 缓冲区 会比这 多得多...
如何尽可能保证持久化的安全
如果我们故障仅仅涉及到 软件层面 (该进程被管理员终止或程序崩溃) 并且没有接触到内核,那么在 上述步骤 3 成功返回之后,我们就认为成功了。即使进程崩溃,操作系统仍然会帮助我们把数据正确地写入磁盘。
如果我们考虑 停电/ 火灾 等 更具灾难性 的事情,那么只有在完成了第 5 步之后,才是安全的。
所以我们可以总结得出数据安全最重要的阶段是:步骤三、四、五,即:
- 数据库软件调用写操作将用户空间的缓冲区转移到内核缓冲区的频率是多少?
- 内核多久从缓冲区取数据刷新到磁盘控制器?
- 磁盘控制器多久把数据写入物理媒介一次?
- 注意: 如果真的发生灾难性的事件,我们可以从上图的过程中看到,任何一步都可能被意外打断丢失,所以只能 尽可能地保证 数据的安全,这对于所有数据库来说都是一样的。
我们从 第三步 开始。Linux 系统提供了清晰、易用的用于操作文件的 POSIX file API,20 多年过去,仍然还有很多人对于这一套 API 的设计津津乐道,我想其中一个原因就是因为你光从 API 的命名就能够很清晰地知道这一套 API 的用途:
int open(const char *path, int oflag, .../*,mode_t mode */);
int close (int filedes);int remove( const char *fname );
ssize_t write(int fildes, const void *buf, size_t nbyte);
ssize_t read(int fildes, void *buf, size_t nbyte);
- 参考自:API 设计最佳实践的思考 - https://www.cnblogs.com/yuanjiangw/p/10846560.html
所以,我们有很好的可用的 API 来完成 第三步,但是对于成功返回之前,我们对系统调用花费的时间没有太多的控制权。
然后我们来说说 第四步。我们知道,除了早期对电脑特别了解那帮人 (操作系统就这帮人搞的),实际的物理硬件都不是我们能够 直接操作 的,都是通过 操作系统调用 来达到目的的。为了防止过慢的 I/O 操作拖慢整个系统的运行,操作系统层面做了很多的努力,譬如说 上述第四步 提到的 写缓冲区,并不是所有的写操作都会被立即写入磁盘,而是要先经过一个缓冲区,默认情况下,Linux 将在 30 秒 后实际提交写入。
但是很明显,30 秒 并不是 Redis 能够承受的,这意味着,如果发生故障,那么最近 30 秒内写入的所有数据都可能会丢失。幸好 PROSIX API 提供了另一个解决方案:fsync,该命令会 强制 内核将 缓冲区 写入 磁盘,但这是一个非常消耗性能的操作,每次调用都会 阻塞等待 直到设备报告 IO 完成,所以一般在生产环境的服务器中,Redis 通常是每隔 1s 左右执行一次 fsync 操作。
到目前为止,我们了解到了如何控制 第三步 和 第四步,但是对于 第五步,我们 完全无法控制。也许一些内核实现将试图告诉驱动实际提交物理介质上的数据,或者控制器可能会为了提高速度而重新排序写操作,不会尽快将数据真正写到磁盘上,而是会等待几个多毫秒。这完全是我们无法控制的。
二、Redis 中的两种持久化方式
方式一:快照
Redis 快照 是最简单的 Redis 持久性模式。当满足特定条件时,它将生成数据集的时间点快照,例如,如果先前的快照是在2分钟前创建的,并且现在已经至少有 100 次新写入,则将创建一个新的快照。此条件可以由用户配置 Redis 实例来控制,也可以在运行时修改而无需重新启动服务器。快照作为包含整个数据集的单个 .rdb 文件生成。
但我们知道,Redis 是一个 单线程 的程序,这意味着,我们不仅仅要响应用户的请求,还需要进行内存快照。而后者要求 Redis 必须进行 IO 操作,这会严重拖累服务器的性能。
还有一个重要的问题是,我们在 持久化的同时,内存数据结构 还可能在 变化,比如一个大型的 hash 字典正在持久化,结果一个请求过来把它删除了,可是这才刚持久化结束,咋办?
使用系统多进程 COW( On Write) 机制 | fork 函数
操作系统多进程 COW( On Write) 机制 拯救了我们。Redis 在持久化时会调用 glibc 的函数 fork 产生一个子进程,简单理解也就是基于当前进程 复制 了一个进程,主进程和子进程会共享内存里面的代码块和数据段:

这里多说一点,为什么 fork 成功调用后会有两个返回值呢? 因为子进程在复制时复制了父进程的堆栈段,所以两个进程都停留在了 fork 函数中 *(都在同一个地方往下继续"同时"执行)*,等待返回,所以 一次在父进程中返回子进程的 pid,另一次在子进程中返回零,系统资源不够时返回负数。 (伪代码如下)
pid = os.fork()
if pid > 0:
handle_client_request() # 父进程继续处理客户端请求
if pid == 0:
handle_snapshot_write() # 子进程处理快照写磁盘
if pid < 0:
# fork error
所以 快照持久化 可以完全交给 子进程 来处理,父进程 则继续 处理客户端请求。子进程 做数据持久化,它 不会修改现有的内存数据结构,它只是对数据结构进行遍历读取,然后序列化写到磁盘中。但是 父进程 不一样,它必须持续服务客户端请求,然后对 内存数据结构进行不间断的修改。
这个时候就会使用操作系统的 COW 机制来进行 数据段页面 的分离。数据段是由很多操作系统的页面组合而成,当父进程对其中一个页面的数据进行修改时,会将被共享的页面复 制一份分离出来,然后 对这个复制的页面进行修改。这时 子进程 相应的页面是 没有变化的,还是进程产生时那一瞬间的数据。
子进程因为数据没有变化,它能看到的内存里的数据在进程产生的一瞬间就凝固了,再也不会改变,这也是为什么 Redis 的持久化 叫「快照」的原因。接下来子进程就可以非常安心的遍历数据了进行序列化写磁盘了。
方式二:AOF
快照不是很持久。如果运行 Redis 的计算机停止运行,电源线出现故障或者您 kill -9 的实例意外发生,则写入 Redis 的最新数据将丢失。尽管这对于某些应用程序可能不是什么大问题,但有些使用案例具有充分的耐用性,在这些情况下,快照并不是可行的选择。
AOF(Append Only File - 仅追加文件) 它的工作方式非常简单:每次执行 修改内存 中数据集的写操作时,都会 记录 该操作。假设 AOF 日志记录了自 Redis 实例创建以来 所有的修改性指令序列,那么就可以通过对一个空的 Redis 实例 顺序执行所有的指令,也就是 「重放」,来恢复 Redis 当前实例的内存数据结构的状态。
为了展示 AOF 在实际中的工作方式,我们来做一个简单的实验:
./redis-server --appendonly yes # 设置一个新实例为 AOF 模式
然后我们执行一些写操作:
redis 127.0.0.1:6379> set key1 Hello
OK
redis 127.0.0.1:6379> append key1 " World!"
(integer) 12
redis 127.0.0.1:6379> del key1
(integer) 1
redis 127.0.0.1:6379> del non_existing_key
(integer) 0
前三个操作实际上修改了数据集,第四个操作没有修改,因为没有指定名称的键。这是 AOF 日志保存的文本:
$ cat appendonly.aof
*2
$6
SELECT
$1
0
*3
$3
set
$4
key1
$5
Hello
*3
$6
append
$4
key1
$7
World!
*2
$3
del
$4
key1
如您所见,最后的那一条 DEL 指令不见了,因为它没有对数据集进行任何修改。
就是这么简单。当 Redis 收到客户端修改指令后,会先进行参数校验、逻辑处理,如果没问题,就 立即 将该指令文本 存储 到 AOF 日志中,也就是说,先执行指令再将日志存盘。这一点不同于 MySQL、LevelDB、HBase 等存储引擎,如果我们先存储日志再做逻辑处理,这样就可以保证即使宕机了,我们仍然可以通过之前保存的日志恢复到之前的数据状态,但是 Redis 为什么没有这么做呢?
Emmm... 没找到特别满意的答案,引用一条来自知乎上的回答吧:
- @缘于专注 - 我甚至觉得没有什么特别的原因。仅仅是因为,由于AOF文件会比较大,为了避免写入无效指令(错误指令),必须先做指令检查?如何检查,只能先执行了。因为语法级别检查并不能保证指令的有效性,比如删除一个不存在的key。而MySQL这种是因为它本身就维护了所有的表的信息,所以可以语法检查后过滤掉大部分无效指令直接记录日志,然后再执行。
- 更多讨论参见:为什么Redis先执行指令,再记录AOF日志,而不是像其它存储引擎一样反过来呢? - https://www.zhihu.com/question/342427472
AOF 重写
Redis 在长期运行的过程中,AOF 的日志会越变越长。如果实例宕机重启,重放整个 AOF 日志会非常耗时,导致长时间 Redis 无法对外提供服务。所以需要对 AOF 日志 "瘦身"。
Redis 提供了 bgrewriteaof 指令用于对 AOF 日志进行瘦身。其 原理 就是 开辟一个子进程 对内存进行 遍历 转换成一系列 Redis 的操作指令,序列化到一个新的 AOF 日志文件 中。序列化完毕后再将操作期间发生的 增量 AOF 日志 追加到这个新的 AOF 日志文件中,追加完毕后就立即替代旧的 AOF 日志文件了,瘦身工作就完成了。
fsync
AOF 日志是以文件的形式存在的,当程序对 AOF 日志文件进行写操作时,实际上是将内容写到了内核为文件描述符分配的一个内存缓存中,然后内核会异步将脏数据刷回到磁盘的。
就像我们 上方第四步 描述的那样,我们需要借助 glibc 提供的 fsync(int fd) 函数来讲指定的文件内容 强制从内核缓存刷到磁盘。但 "强制开车" 仍然是一个很消耗资源的一个过程,需要 "节制"!通常来说,生产环境的服务器,Redis 每隔 1s 左右执行一次 fsync 操作就可以了。
Redis 同样也提供了另外两种策略,一个是 永不 fsync*,来让操作系统来决定合适同步磁盘,很不安全,另一个是 *来一个指令就 fsync 一次,非常慢。但是在生产环境基本不会使用,了解一下即可。
Redis 4.0 混合持久化

重启 Redis 时,我们很少使用 rdb 来恢复内存状态,因为会丢失大量数据。我们通常使用 AOF 日志重放,但是重放 AOF 日志性能相对 rdb 来说要慢很多,这样在 Redis 实例很大的情况下,启动需要花费很长的时间。
Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化。将 rdb 文件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是 自持久化开始到持久化结束 的这段时间发生的增量 AOF 日志,通常这部分 AOF 日志很小:
Redis面试
1. 简单介绍一下 Redis 呗!
-
简单来说 Redis 就是一个使用 C 语言开发的数据库,不过与传统数据库不同的是 Redis 的数据是存在内存中的 ,也就是它是内存数据库,所以读写速度非常快,因此 Redis 被广泛应用于缓存方向。
-
另外,Redis 除了做缓存之外,Redis 也经常用来做分布式锁,甚至是消息队列。
-
Redis 提供了多种数据类型来支持不同的业务场景。Redis 还支持事务 、持久化、Lua 脚本、多种集群方案。
-
Redis 是速度非常快的非关系型(NoSQL)内存键值数据库,可以存储键和五种不同类型的值之间的映射。
-
键的类型只能为字符串,值支持五种数据类型:字符串、列表、集合、散列表、有序集合。
-
Redis 支持很多特性,例如将内存中的数据持久化到硬盘中,使用复制来扩展读性能,使用分片来扩展写性能。
2. 分布式缓存常见的技术选型方案有哪些?
分布式缓存的话,使用的比较多的主要是 Memcached 和 Redis。不过,现在基本没有看过还有项目使用 Memcached 来做缓存,都是直接用 Redis。
Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
分布式缓存主要解决的是单机缓存的容量受服务器限制并且无法保存通用的信息。因为,本地缓存只在当前服务里有效,比如如果你部署了两个相同的服务,他们两者之间的缓存数据是无法共同的。
3. 说一下 Redis 和 Memcached 的区别和共同点
现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!不过,了解 Redis 和 Memcached 的区别和共同点,有助于我们在做相应的技术选型的时候,能够做到有理有据!
共同点 :
- 都是基于内存的数据库,一般都用来当做缓存使用。
- 都有过期策略。
- 两者的性能都非常高。
区别 :
- Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
- Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memecache 把数据全部存在内存之中。
- Redis 有灾难恢复机制。 因为可以把缓存中的数据持久化到磁盘上。
- Redis 在服务器内存使用完之后,可以将不用的数据放到磁盘上。但是,Memcached 在服务器内存使用完之后,就会直接报异常。
- Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的.
- Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。 (Redis 6.0 引入了多线程 IO )
- Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。
- Memcached过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。
相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached 来作为自己项目的分布式缓存了。
4. 缓存数据的处理流程是怎样的?
作为暖男一号,我给大家画了一个草图。

简单来说就是:
- 如果用户请求的数据在缓存中就直接返回。
- 缓存中不存在的话就看数据库中是否存在。
- 数据库中存在的话就更新缓存中的数据。
- 数据库中不存在的话就返回空数据。
5. 为什么要用 Redis/为什么要用缓存?
简单,来说使用缓存主要是为了提升用户体验以及应对更多的用户。
下面我们主要从“高性能”和“高并发”这两点来看待这个问题。

高性能 :
对照上面 👆 我画的图。我们设想这样的场景:
假如用户第一次访问数据库中的某些数据的话,这个过程是比较慢,毕竟是从硬盘中读取的。但是,如果说,用户访问的数据属于高频数据并且不会经常改变的话,那么我们就可以很放心地将该用户访问的数据存在缓存中。
这样有什么好处呢? 那就是保证用户下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。
不过,要保持数据库和缓存中的数据的一致性。 如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
高并发:
一般像 MySQL 这类的数据库的 QPS 大概都在 1w 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 10w+,甚至最高能达到 30w+(就单机 redis 的情况,redis 集群的话会更高)。
QPS(Query Per Second):服务器每秒可以执行的查询次数;
所以,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高的系统整体的并发。
6. Redis 常见数据类型以及使用场景分析
| 数据类型 | 可以存储的值 | 操作 |
|---|---|---|
| STRING | 字符串、整数或者浮点数 | 对整个字符串或者字符串的其中一部分执行操作 对整数和浮点数执行自增或者自减操作 |
| LIST | 列表 | 从两端压入或者弹出元素 对单个或者多个元素进行修剪, 只保留一个范围内的元素 |
| SET | 无序集合 | 添加、获取、移除单个元素 检查一个元素是否存在于集合中 计算交集、并集、差集 从集合里面随机获取元素 |
| HASH | 包含键值对的无序散列表 | 添加、获取、移除单个键值对 获取所有键值对 检查某个键是否存在 |
| ZSET | 有序集合 | 添加、获取、删除元素 根据分值范围或者成员来获取元素 计算一个键的排名 |
6.1. string
- 介绍 :string 数据结构是简单的 key-value 类型。虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 简单动态字符串(simple dynamic string,SDS)。相比于 C 的原生字符串,Redis 的 SDS 不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)(C 字符串为 O(N)),除此之外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
- 常用命令:
set,get,strlen,exists,dect,incr,setex等等。 - 应用场景 :一般常用在需要计数的场景,比如用户的访问次数、热点文章的点赞转发数量等等。
下面我们简单看看它的使用!
普通字符串的基本操作:
127.0.0.1:6379> set key value #设置 key-value 类型的值
OK
127.0.0.1:6379> get key # 根据 key 获得对应的 value
"value"
127.0.0.1:6379> exists key # 判断某个 key 是否存在
(integer) 1
127.0.0.1:6379> strlen key # 返回 key 所储存的字符串值的长度。
(integer) 5
127.0.0.1:6379> del key # 删除某个 key 对应的值
(integer) 1
127.0.0.1:6379> get key
(nil)
批量设置 :
127.0.0.1:6379> mest key1 value1 key2 value2 # 批量设置 key-value 类型的值
OK
127.0.0.1:6379> mget key1 key2 # 批量获取多个 key 对应的 value
1) "value1"
2) "value2"
计数器(字符串的内容为整数的时候可以使用):
127.0.0.1:6379> set number 1
OK
127.0.0.1:6379> incr number # 将 key 中储存的数字值增一
(integer) 2
127.0.0.1:6379> get number
"2"
127.0.0.1:6379> decr number # 将 key 中储存的数字值减一
(integer) 1
127.0.0.1:6379> get number
"1"
过期:
127.0.0.1:6379> expire key 60 # 数据在 60s 后过期
(integer) 1
127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
OK
127.0.0.1:6379> ttl key # 查看数据还有多久过期
(integer) 56
6.2. list
- 介绍 :list 即是 链表。链表是一种非常常见的数据结构,特点是易于数据元素的插入和删除并且且可以灵活调整链表长度,但是链表的随机访问困难。许多高级编程语言都内置了链表的实现比如 Java 中的 LinkedList,但是 C 语言并没有实现链表,所以 Redis 实现了自己的链表数据结构。Redis 的 list 的实现为一个 双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
- 常用命令:
rpush,lpop,lpush,rpop,lrange、llen等。 - 应用场景: 发布与订阅或者说消息队列、慢查询。
下面我们简单看看它的使用!
通过 rpush/lpop 实现队列:
127.0.0.1:6379> rpush myList value1 # 向 list 的头部(右边)添加元素
(integer) 1
127.0.0.1:6379> rpush myList value2 value3 # 向list的头部(最右边)添加多个元素
(integer) 3
127.0.0.1:6379> lpop myList # 将 list的尾部(最左边)元素取出
"value1"
127.0.0.1:6379> lrange myList 0 1 # 查看对应下标的list列表, 0 为 start,1为 end
1) "value2"
2) "value3"
127.0.0.1:6379> lrange myList 0 -1 # 查看列表中的所有元素,-1表示倒数第一
1) "value2"
2) "value3"
通过 rpush/rpop 实现栈:
127.0.0.1:6379> rpush myList2 value1 value2 value3
(integer) 3
127.0.0.1:6379> rpop myList2 # 将 list的头部(最右边)元素取出
"value3"
我专门花了一个图方便小伙伴们来理解:

通过 lrange 查看对应下标范围的列表元素:
127.0.0.1:6379> rpush myList value1 value2 value3
(integer) 3
127.0.0.1:6379> lrange myList 0 1 # 查看对应下标的list列表, 0 为 start,1为 end
1) "value1"
2) "value2"
127.0.0.1:6379> lrange myList 0 -1 # 查看列表中的所有元素,-1表示倒数第一
1) "value1"
2) "value2"
3) "value3"
通过 lrange 命令,你可以基于 list 实现分页查询,性能非常高!
通过 llen 查看链表长度:
127.0.0.1:6379> llen myList
(integer) 3
6.3. hash
- 介绍 :hash 类似于 JDK1.8 前的 HashMap,内部实现也差不多(数组 + 链表)。不过,Redis 的 hash 做了更多优化。另外,hash 是一个 string 类型的 field 和 value 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值。 比如我们可以 hash 数据结构来存储用户信息,商品信息等等。
- 常用命令:
hset,hmset,hexists,hget,hgetall,hkeys,hvals等。 - 应用场景: 系统中对象数据的存储。
下面我们简单看看它的使用!
127.0.0.1:6379> hset userInfoKey name "guide" description "dev" age "24"
OK
127.0.0.1:6379> hexists userInfoKey name # 查看 key 对应的 value中指定的字段是否存在。
(integer) 1
127.0.0.1:6379> hget userInfoKey name # 获取存储在哈希表中指定字段的值。
"guide"
127.0.0.1:6379> hget userInfoKey age
"24"
127.0.0.1:6379> hgetall userInfoKey # 获取在哈希表中指定 key 的所有字段和值
1) "name"
2) "guide"
3) "description"
4) "dev"
5) "age"
6) "24"
127.0.0.1:6379> hkeys userInfoKey # 获取 key 列表
1) "name"
2) "description"
3) "age"
127.0.0.1:6379> hvals userInfoKey # 获取 value 列表
1) "guide"
2) "dev"
3) "24"
127.0.0.1:6379> hset userInfoKey name "GuideGeGe" # 修改某个字段对应的值
127.0.0.1:6379> hget userInfoKey name
"GuideGeGe"
6.4. set
- 介绍 : set 类似于 Java 中的
HashSet。Redis 中的 set 类型是一种无序集合,集合中的元素没有先后顺序。当你需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且 set 提供了判断某个成员是否在一个 set 集合内的重要接口,这个也是 list 所不能提供的。可以基于 set 轻易实现交集、并集、差集的操作。比如:你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。 - 常用命令:
sadd,spop,smembers,sismember,scard,sinterstore,sunion等。 - 应用场景: 需要存放的数据不能重复以及需要获取多个数据源交集和并集等场景
下面我们简单看看它的使用!
127.0.0.1:6379> sadd mySet value1 value2 # 添加元素进去
(integer) 2
127.0.0.1:6379> sadd mySet value1 # 不允许有重复元素
(integer) 0
127.0.0.1:6379> smembers mySet # 查看 set 中所有的元素
1) "value1"
2) "value2"
127.0.0.1:6379> scard mySet # 查看 set 的长度
(integer) 2
127.0.0.1:6379> sismember mySet value1 # 检查某个元素是否存在set 中,只能接收单个元素
(integer) 1
127.0.0.1:6379> sadd mySet2 value2 value3
(integer) 2
127.0.0.1:6379> sinterstore mySet3 mySet mySet2 # 获取 mySet 和 mySet2 的交集并存放在 mySet3 中
(integer) 1
127.0.0.1:6379> smembers mySet3
1) "value2"
6.5. sorted set(zset)
- 介绍: 和 set 相比,sorted set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。有点像是 Java 中 HashMap 和 TreeSet 的结合体。
- 常用命令:
zadd,zcard,zscore,zrange,zrevrange,zrem等。 - 应用场景: 需要对数据根据某个权重进行排序的场景。比如在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息。
127.0.0.1:6379> zadd myZset 3.0 value1 # 添加元素到 sorted set 中 3.0 为权重
(integer) 1
127.0.0.1:6379> zadd myZset 2.0 value2 1.0 value3 # 一次添加多个元素
(integer) 2
127.0.0.1:6379> zcard myZset # 查看 sorted set 中的元素数量
(integer) 3
127.0.0.1:6379> zscore myZset value1 # 查看某个 value 的权重
"3"
127.0.0.1:6379> zrange myZset 0 -1 # 顺序输出某个范围区间的元素,0 -1 表示输出所有元素
1) "value3"
2) "value2"
3) "value1"
127.0.0.1:6379> zrange myZset 0 1 # 顺序输出某个范围区间的元素,0 为 start 1 为 stop
1) "value3"
2) "value2"
127.0.0.1:6379> zrevrange myZset 0 1 # 逆序输出某个范围区间的元素,0 为 start 1 为 stop
1) "value1"
2) "value2"
7. Redis 单线程模型详解
Redis 基于 Reactor 模式来设计开发了自己的一套高效的事件处理模型 (Netty 的线程模型也基于 Reactor 模式,Reactor 模式不愧是高性能 IO 的基石),这套事件处理模型对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器(file event handler)是单线程方式运行的,所以我们一般都说 Redis 是单线程模型。
既然是单线程,那怎么监听大量的客户端连接呢?
Redis 通过IO 多路复用程序 来监听来自客户端的大量连接(或者说是监听多个 socket),它会将感兴趣的事件及类型(读、写)注册到内核中并监听每个事件是否发生。
这样的好处非常明显: I/O 多路复用技术的使用让 Redis 不需要额外创建多余的线程来监听客户端的大量连接,降低了资源的消耗(和 NIO 中的 Selector 组件很像)。
另外, Redis 服务器是一个事件驱动程序,服务器需要处理两类事件: 1. 文件事件; 2. 时间事件。
时间事件不需要多花时间了解,我们接触最多的还是 文件事件(客户端进行读取写入等操作,涉及一系列网络通信)。
《Redis 设计与实现》有一段话是如是介绍文件事件的,我觉得写得挺不错。
Redis 基于 Reactor 模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler)。文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字,并根据 套接字目前执行的任务来为套接字关联不同的事件处理器。
当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关 闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
虽然文件事件处理器以单线程方式运行,但通过使用 I/O 多路复用程序来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与 Redis 服务器中其他同样以单线程方式运行的模块进行对接,这保持了 Redis 内部单线程设计的简单性。
可以看出,文件事件处理器(file event handler)主要是包含 4 个部分:
- 多个 socket(客户端连接)
- IO 多路复用程序(支持多个客户端连接的关键)
- 文件事件分派器(将 socket 关联到相应的事件处理器)
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)

《Redis设计与实现:12章》
8. Redis 没有使用多线程?为什么不使用多线程?
虽然说 Redis 是单线程模型,但是, 实际上,Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。

不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主处理之外的其他线程来“异步处理”。
大体上来说,Redis 6.0 之前主要还是单线程处理。
那,Redis6.0 之前 为什么不使用多线程?
我觉得主要原因有下面 3 个:
- 单线程编程容易并且更容易维护;
- Redis 的性能瓶颈不再是 CPU ,主要在内存和网络;
- 多线程就会存在死锁、线程上下文切换等问题,甚至会影响性能。
9. Redis6.0 之后为何引入了多线程?
Redis6.0 引入多线程主要是为了提高网络 IO 读写性能,因为这个算是 Redis 中的一个性能瓶颈(Redis 的瓶颈主要受限于内存和网络)。
虽然,Redis6.0 引入了多线程,但是 Redis 的多线程只是在网络数据的读写这类耗时操作上使用了, 执行命令仍然是单线程顺序执行。因此,你也不需要担心线程安全问题。
Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要修改 redis 配置文件 redis.conf :
io-threads-do-reads yes
开启多线程后,还需要设置线程数,否则是不生效的。同样需要修改 redis 配置文件 redis.conf :
io-threads 4 #官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程
推荐阅读:
10. Redis 给缓存数据设置过期时间有啥用?
一般情况下,我们设置保存的缓存数据的时候都会设置一个过期时间。为什么呢?
因为内存是有限的,如果缓存中的所有数据都是一直保存的话,分分钟直接Out of memory。
Redis 自带了给缓存数据设置过期时间的功能,比如:
127.0.0.1:6379> exp key 60 # 数据在 60s 后过期
(integer) 1
127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
OK
127.0.0.1:6379> ttl key # 查看数据还有多久过期
(integer) 56
注意:**Redis中除了字符串类型有自己独有设置过期时间的命令 setex 外,其他方法都需要依靠 expire 命令来设置过期时间 。另外, persist 命令可以移除一个键的过期时间: **
过期时间除了有助于缓解内存的消耗,还有什么其他用么?
很多时候,我们的业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在1分钟内有效,用户登录的 token 可能只在 1 天内有效。
如果使用传统的数据库来处理的话,一般都是自己判断过期,这样更麻烦并且性能要差很多。
11. Redis是如何判断数据是否过期的呢?
Redis 通过一个叫做过期字典(可以看作是hash表)来保存数据过期的时间。过期字典的键指向Redis数据库中的某个key(键),过期字典的值是一个long long类型的整数,这个整数保存了key所指向的数据库键的过期时间(毫秒精度的UNIX时间戳)。

过期字典是存储在redisDb这个结构里的:
typedef struct redisDb {
...
dict *dict; //数据库键空间,保存着数据库中所有键值对
dict *expires // 过期字典,保存着键的过期时间
...
} redisDb;
12. 过期的数据的删除策略了解么?
如果假设你设置了一批 key 只能存活 1 分钟,那么 1 分钟后,Redis 是怎么对这批 key 进行删除的呢?
常用的过期数据的删除策略就两个(重要!自己造缓存轮子的时候需要格外考虑的东西):
- 惰性删除 :只会在取出key的时候才对数据进行过期检查。这样对CPU最友好,但是可能会造成太多过期 key 没有被删除。
- 定期删除 : 每隔一段时间抽取一批 key 执行删除过期key操作。并且,Redis 底层会并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
定期删除对内存更加友好,惰性删除对CPU更加友好。两者各有千秋,所以Redis 采用的是 定期删除+惰性/懒汉式删除 。
但是,仅仅通过给 key 设置过期时间还是有问题的。因为还是可能存在定期删除和惰性删除漏掉了很多过期 key 的情况。这样就导致大量过期 key 堆积在内存里,然后就Out of memory了。
怎么解决这个问题呢?答案就是: Redis 内存淘汰机制。
13. Redis 内存淘汰机制了解么?
相关问题:MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证 Redis 中的数据都是热点数据?
可以设置内存最大使用量,当内存使用量超出时,会施行数据淘汰策略。
Redis 具体有 6 种淘汰策略:
| 策略 | 描述 |
|---|---|
| volatile-lru | 从已设置过期时间的数据集中挑选最近最少使用的数据淘汰 |
| volatile-ttl | 从已设置过期时间的数据集中挑选将要过期的数据淘汰 |
| volatile-random | 从已设置过期时间的数据集中任意选择数据淘汰 |
| allkeys-lru | 从所有数据集中挑选最近最少使用的数据淘汰 |
| allkeys-random | 从所有数据集中任意选择数据进行淘汰 |
| noeviction | 禁止驱逐数据 |
作为内存数据库,出于对性能和内存消耗的考虑,Redis 的淘汰算法实际实现上并非针对所有 key,而是抽样一小部分并且从中选出被淘汰的 key。
使用 Redis 缓存数据时,为了提高缓存命中率,需要保证缓存数据都是热点数据。可以将内存最大使用量设置为热点数据占用的内存量,然后启用 allkeys-lru 淘汰策略,将最近最少使用的数据淘汰。
4.0 版本后增加以下两种:
- volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
- allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key
14. Redis 持久化机制(怎么保证 Redis 挂掉之后再重启数据可以进行恢复)
很多时候我们需要持久化数据也就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了防止系统故障而将数据备份到一个远程位置。
Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持两种不同的持久化操作。Redis 的一种持久化方式叫快照(snapshotting,RDB),另一种方式是只追加文件(append-only file, AOF)。这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
快照(snapshotting)持久化(RDB)
Redis 可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis 创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis 主从结构,主要用来提高 Redis 性能),还可以将快照留在原地以便重启服务器的时候使用。
快照持久化是 Redis 默认采用的持久化方式,在 Redis.conf 配置文件中默认有此下配置:
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
AOF(append-only file)持久化
与快照持久化相比,AOF 持久化 的实时性更好,因此已成为主流的持久化方案。
appendonly yes
开启 AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入硬盘中的 AOF 文件。AOF 文件的保存位置和 RDB 文件的位置相同,都是通过 dir 参数设置的,默认的文件名是 appendonly.aof。
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式,它们分别是:
appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
appendfsync no #让操作系统决定何时进行同步
为了兼顾数据和写入性能,用户可以考虑 appendfsync everysec 选项 ,让 Redis 每秒同步一次 AOF 文件,Redis 性能几乎没受到任何影响。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis 还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
相关 issue :783:Redis 的 AOF 方式
拓展:Redis 4.0 对于持久化机制的优化
Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 aof-use-rdb-preamble 开启)。
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
补充内容:AOF 重写
AOF 重写可以产生一个新的 AOF 文件,这个新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。
AOF 重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有 AOF 文件进行任何读入、分析或者写入操作。
在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新旧两个 AOF 文件所保存的数据库状态一致。最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作
15. Redis 事务
Redis 可以通过 MULTI,EXEC,DISCARD 和 WATCH 等命令来实现事务(transaction)功能。
> MULTI
OK
> INCR foo
QUEUED
> INCR bar
QUEUED
> EXEC
1) (integer) 1
2) (integer) 1
使用 MULTI命令后可以输入多个命令。Redis不会立即执行这些命令,而是将它们放到队列,当调用了EXEC命令将执行所有命令。
Redis官网相关介绍 https://redis.io/topics/transactions 如下:

但是,Redis 的事务和我们平时理解的关系型数据库的事务不同。我们知道事务具有四大特性: 1. 原子性,2. 隔离性,3. 持久性,4. 一致性。
- 原子性(Atomicity): 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- 隔离性(Isolation): 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
- 持久性(Durability): 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
- 一致性(Consistency): 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
Redis 是不支持 roll back 的,因而不满足原子性的(而且不满足持久性)。
Redis官网也解释了自己为啥不支持回滚。简单来说就是Redis开发者们觉得没必要支持回滚,这样更简单便捷并且性能更好。Redis开发者觉得即使命令执行错误也应该在开发过程中就被发现而不是生产过程中。

你可以将Redis中的事务就理解为 :Redis事务提供了一种将多个命令请求打包的功能。然后,再按顺序执行打包的所有命令,并且不会被中途打断。
相关issue :issue452: 关于 Redis 事务不满足原子性的问题 ,推荐阅读:https://zhuanlan.zhihu.com/p/43897838 。
16. 缓存穿透
16.1. 什么是缓存穿透?
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
16.2. 缓存穿透情况的处理流程是怎样的?
如下图所示,用户的请求最终都要跑到数据库中查询一遍。

16.3. 有哪些解决办法?
最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
1)缓存无效 key
如果缓存和数据库都查不到某个 key 的数据就写一个到 Redis 中去并设置过期时间,具体命令如下: SET key value EX 10086 。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求 key,会导致 Redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
另外,这里多说一嘴,一般情况下我们是这样设计 key 的: 表名:列名:主键名:主键值 。
如果用 Java 代码展示的话,差不多是下面这样的:
public Object getObjectInclNullById(Integer id) {
// 从缓存中获取数据
Object cacheValue = cache.get(id);
// 缓存为空
if (cacheValue == null) {
// 从数据库中获取
Object storageValue = storage.get(key);
// 缓存空对象
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(300秒)
if (storageValue == null) {
// 必须设置过期时间,否则有被攻击的风险
cache.expire(key, 60 * 5);
}
return storageValue;
}
return cacheValue;
}
2)布隆过滤器
布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。
具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
加入布隆过滤器之后的缓存处理流程图如下。

但是,需要注意的是布隆过滤器可能会存在误判的情况。总结来说就是: 布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理来说!
我们先来看一下,当一个元素加入布隆过滤器中的时候,会进行哪些操作:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
我们再来看一下,当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行哪些操作:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
然后,一定会出现这样一种情况:不同的字符串可能哈希出来的位置相同。 (可以适当增加位数组大小或者调整我们的哈希函数来降低概率)
更多关于布隆过滤器的内容可以看我的这篇原创:《不了解布隆过滤器?一文给你整的明明白白!》 ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
17. 缓存雪崩
17.1. 什么是缓存雪崩?
我发现缓存雪崩这名字起的有点意思,哈哈。
实际上,缓存雪崩描述的就是这样一个简单的场景:缓存在同一时间大面积的失效,后面的请求都直接落到了数据库上,造成数据库短时间内承受大量请求。 这就好比雪崩一样,摧枯拉朽之势,数据库的压力可想而知,可能直接就被这么多请求弄宕机了。
举个例子:系统的缓存模块出了问题比如宕机导致不可用。造成系统的所有访问,都要走数据库。
还有一种缓存雪崩的场景是:有一些被大量访问数据(热点缓存)在某一时刻大面积失效,导致对应的请求直接落到了数据库上。 这样的情况,有下面几种解决办法:
举个例子 :秒杀开始 12 个小时之前,我们统一存放了一批商品到 Redis 中,设置的缓存过期时间也是 12 个小时,那么秒杀开始的时候,这些秒杀的商品的访问直接就失效了。导致的情况就是,相应的请求直接就落到了数据库上,就像雪崩一样可怕。
17.2. 有哪些解决办法?
针对 Redis 服务不可用的情况:
- 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
- 限流,避免同时处理大量的请求。
针对热点缓存失效的情况:
- 设置不同的失效时间比如随机设置缓存的失效时间。
- 缓存永不失效。
18. 如何保证缓存和数据库数据的一致性?
细说的话可以扯很多,但是我觉得其实没太大必要(小声BB:很多解决方案我也没太弄明白)。我个人觉得引入缓存之后,如果为了短时间的不一致性问题,选择让系统设计变得更加复杂的话,完全没必要。
下面单独对 Cache Aside Pattern(旁路缓存模式) 来聊聊。
Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删除 cache 。
如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说两个解决方案:
- 缓存失效时间变短(不推荐,治标不治本) :我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
- 增加cache更新重试机制(常用): 如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将 缓存中对应的 key 删除即可。
18. Redis的主从复制
通过使用 slaveof host port 命令来让一个服务器成为另一个服务器的从服务器。
一个从服务器只能有一个主服务器,并且不支持主主复制。
#连接过程
- 主服务器创建快照文件,发送给从服务器,并在发送期间使用缓冲区记录执行的写命令。快照文件发送完毕之后,开始向从服务器发送存储在缓冲区中的写命令;
- 从服务器丢弃所有旧数据,载入主服务器发来的快照文件,之后从服务器开始接受主服务器发来的写命令;
- 主服务器每执行一次写命令,就向从服务器发送相同的写命令。
#主从链
随着负载不断上升,主服务器可能无法很快地更新所有从服务器,或者重新连接和重新同步从服务器将导致系统超载。为了解决这个问题,可以创建一个中间层来分担主服务器的复制工作。中间层的服务器是最上层服务器的从服务器,又是最下层服务器的主服务器。
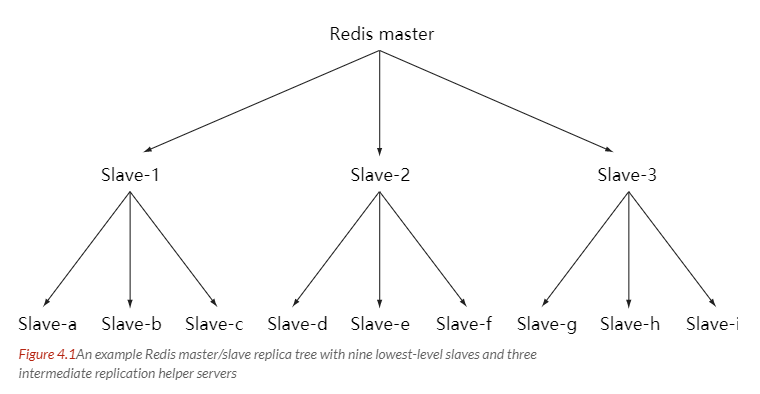
一个简单的论坛系统分析
该论坛系统功能如下:
- 可以发布文章;
- 可以对文章进行点赞;
- 在首页可以按文章的发布时间或者文章的点赞数进行排序显示。
#文章信息
文章包括标题、作者、赞数等信息,在关系型数据库中很容易构建一张表来存储这些信息,在 Redis 中可以使用 HASH 来存储每种信息以及其对应的值的映射。
Redis 没有关系型数据库中的表这一概念来将同种类型的数据存放在一起,而是使用命名空间的方式来实现这一功能。键名的前面部分存储命名空间,后面部分的内容存储 ID,通常使用 : 来进行分隔。例如下面的 HASH 的键名为 article:92617,其中 article 为命名空间,ID 为 92617。

#点赞功能
当有用户为一篇文章点赞时,除了要对该文章的 votes 字段进行加 1 操作,还必须记录该用户已经对该文章进行了点赞,防止用户点赞次数超过 1。可以建立文章的已投票用户集合来进行记录。
为了节约内存,规定一篇文章发布满一周之后,就不能再对它进行投票,而文章的已投票集合也会被删除,可以为文章的已投票集合设置一个一周的过期时间就能实现这个规定。

#对文章进行排序
为了按发布时间和点赞数进行排序,可以建立一个文章发布时间的有序集合和一个文章点赞数的有序集合。(下图中的 score 就是这里所说的点赞数;下面所示的有序集合分值并不直接是时间和点赞数,而是根据时间和点赞数间接计算出来的)

跳跃表
一、跳跃表简介
跳跃表(skiplist)是一种随机化的数据结构,由 William Pugh 在论文《Skip lists: a probabilistic alternative to balanced trees》中提出,是一种可以于平衡树媲美的层次化链表结构——查找、删除、添加等操作都可以在对数期望时间下完成,以下是一个典型的跳跃表例子:
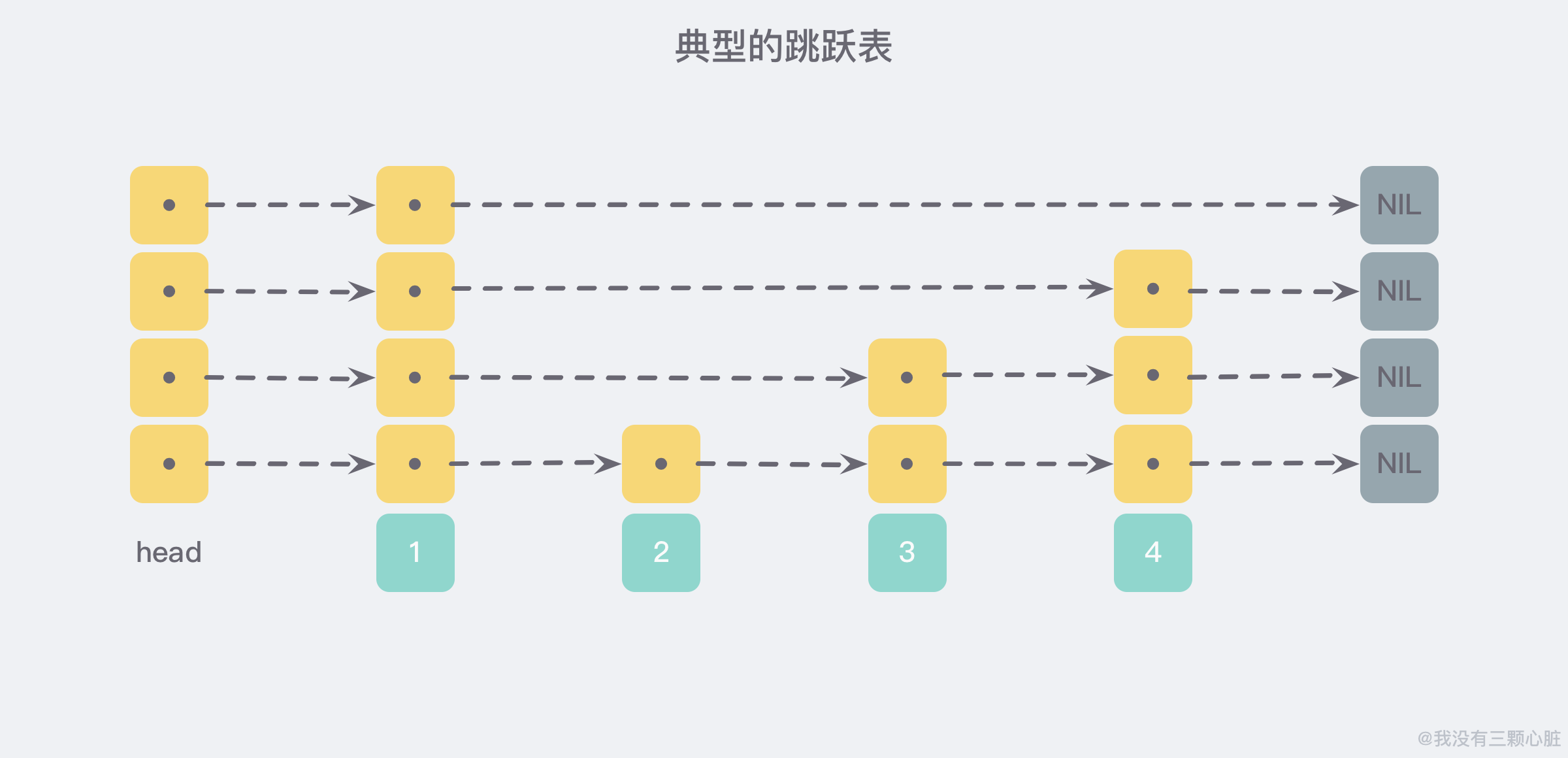
我们在上一篇中提到了 Redis 的五种基本结构中,有一个叫做 有序列表 zset 的数据结构,它类似于 Java 中的 SortedSet 和 HashMap 的结合体,一方面它是一个 set 保证了内部 value 的唯一性,另一方面又可以给每个 value 赋予一个排序的权重值 score,来达到 排序 的目的。
它的内部实现就依赖了一种叫做 「跳跃列表」 的数据结构。
为什么使用跳跃表
首先,因为 zset 要支持随机的插入和删除,所以它 不宜使用数组来实现,关于排序问题,我们也很容易就想到 红黑树/ 平衡树 这样的树形结构,为什么 Redis 不使用这样一些结构呢?
- 性能考虑: 在高并发的情况下,树形结构需要执行一些类似于 rebalance 这样的可能涉及整棵树的操作,相对来说跳跃表的变化只涉及局部 (下面详细说);
- 实现考虑: 在复杂度与红黑树相同的情况下,跳跃表实现起来更简单,看起来也更加直观;
基于以上的一些考虑,Redis 基于 William Pugh 的论文做出一些改进后采用了 跳跃表 这样的结构。
本质是解决查找问题
我们先来看一个普通的链表结构:
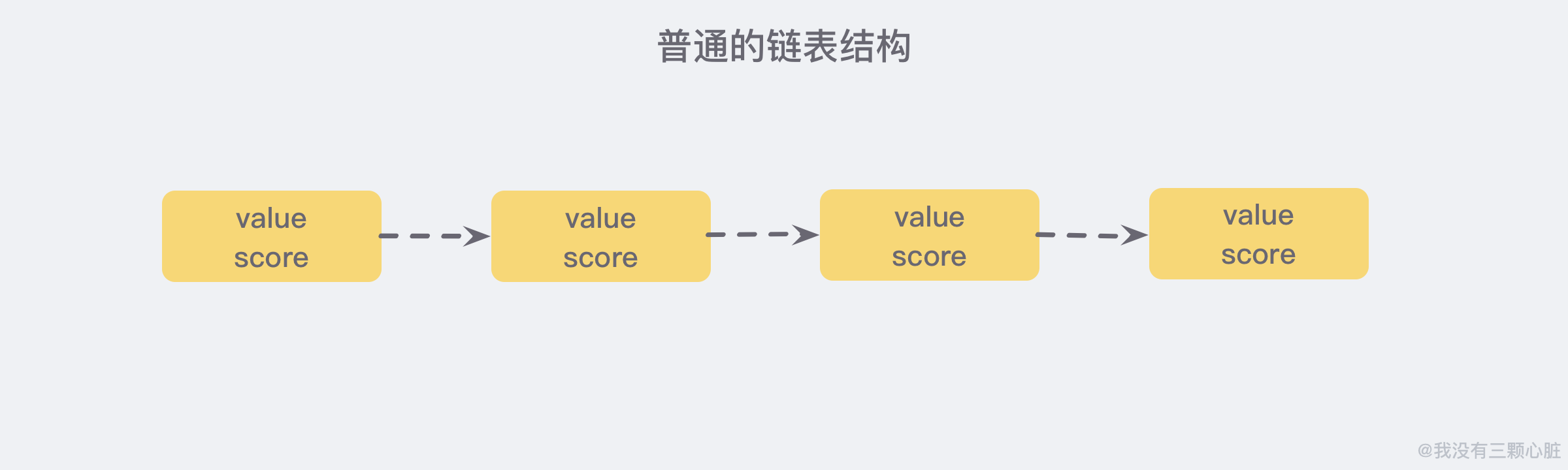
我们需要这个链表按照 score 值进行排序,这也就意味着,当我们需要添加新的元素时,我们需要定位到插入点,这样才可以继续保证链表是有序的,通常我们会使用 二分查找法,但二分查找是有序数组的,链表没办法进行位置定位,我们除了遍历整个找到第一个比给定数据大的节点为止 (时间复杂度 O(n)) 似乎没有更好的办法。
但假如我们每相邻两个节点之间就增加一个指针,让指针指向下一个节点,如下图:
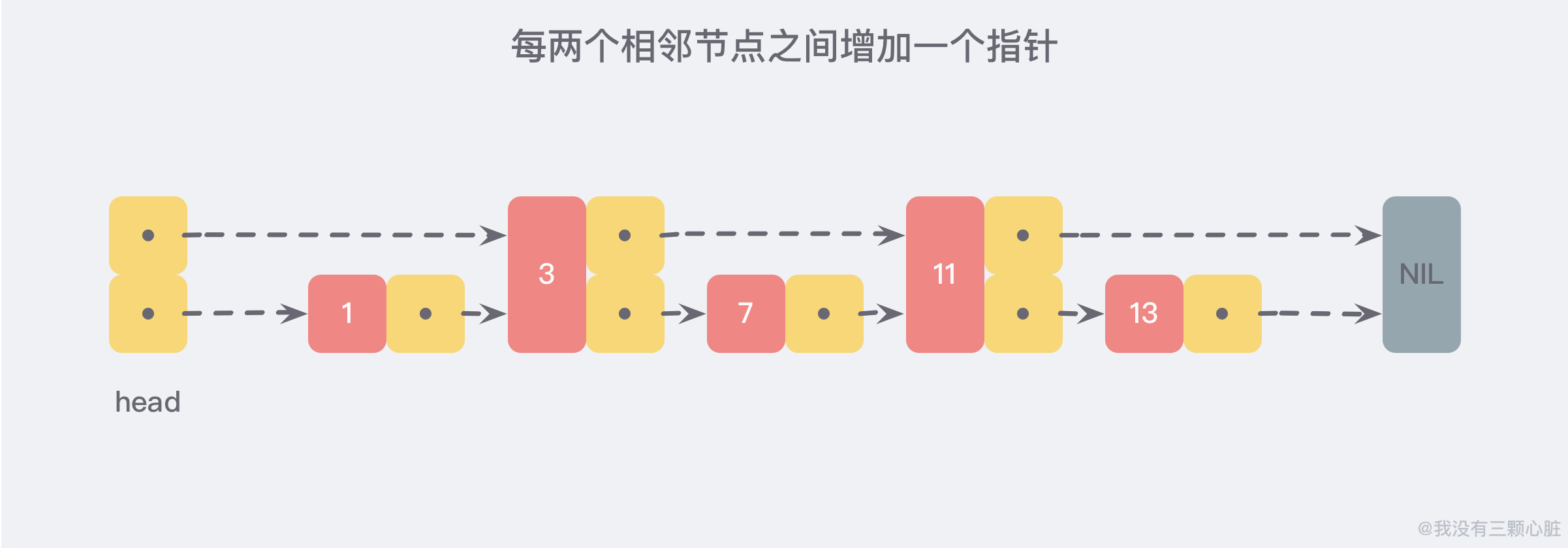
这样所有新增的指针连成了一个新的链表,但它包含的数据却只有原来的一半 (图中的为 3,11)。
现在假设我们想要查找数据时,可以根据这条新的链表查找,如果碰到比待查找数据大的节点时,再回到原来的链表中进行查找,比如,我们想要查找 7,查找的路径则是沿着下图中标注出的红色指针所指向的方向进行的:
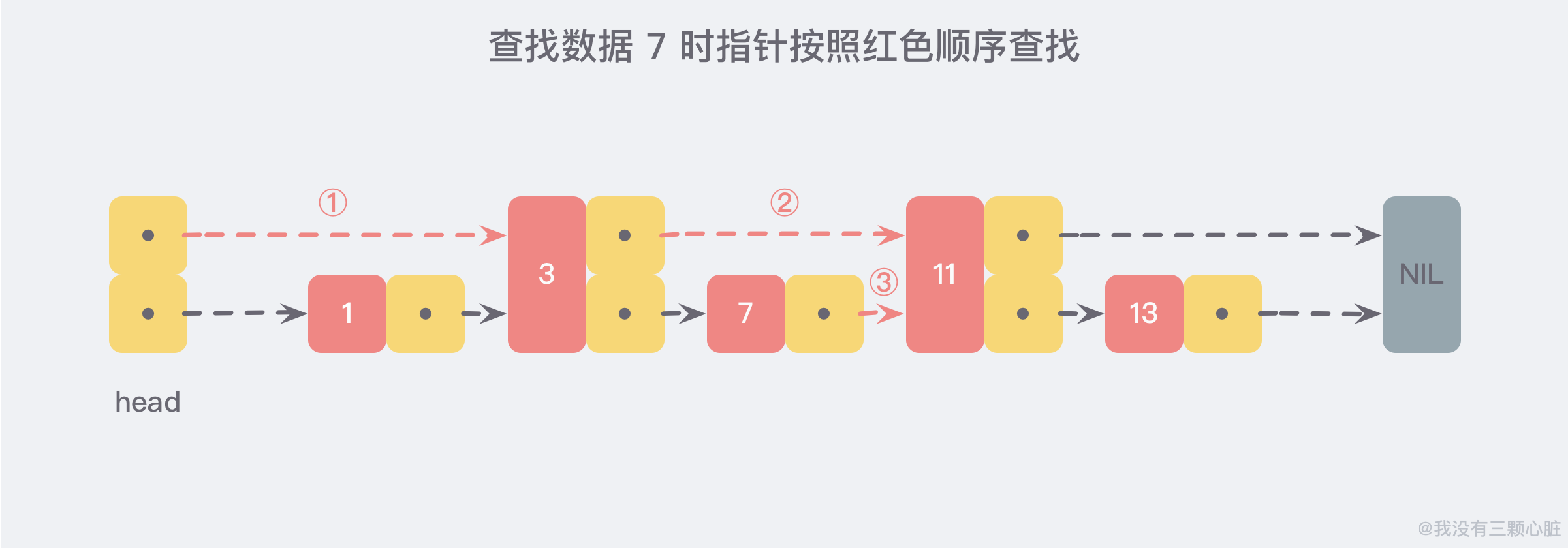
这是一个略微极端的例子,但我们仍然可以看到,通过新增加的指针查找,我们不再需要与链表上的每一个节点逐一进行比较,这样改进之后需要比较的节点数大概只有原来的一半。
利用同样的方式,我们可以在新产生的链表上,继续为每两个相邻的节点增加一个指针,从而产生第三层链表:
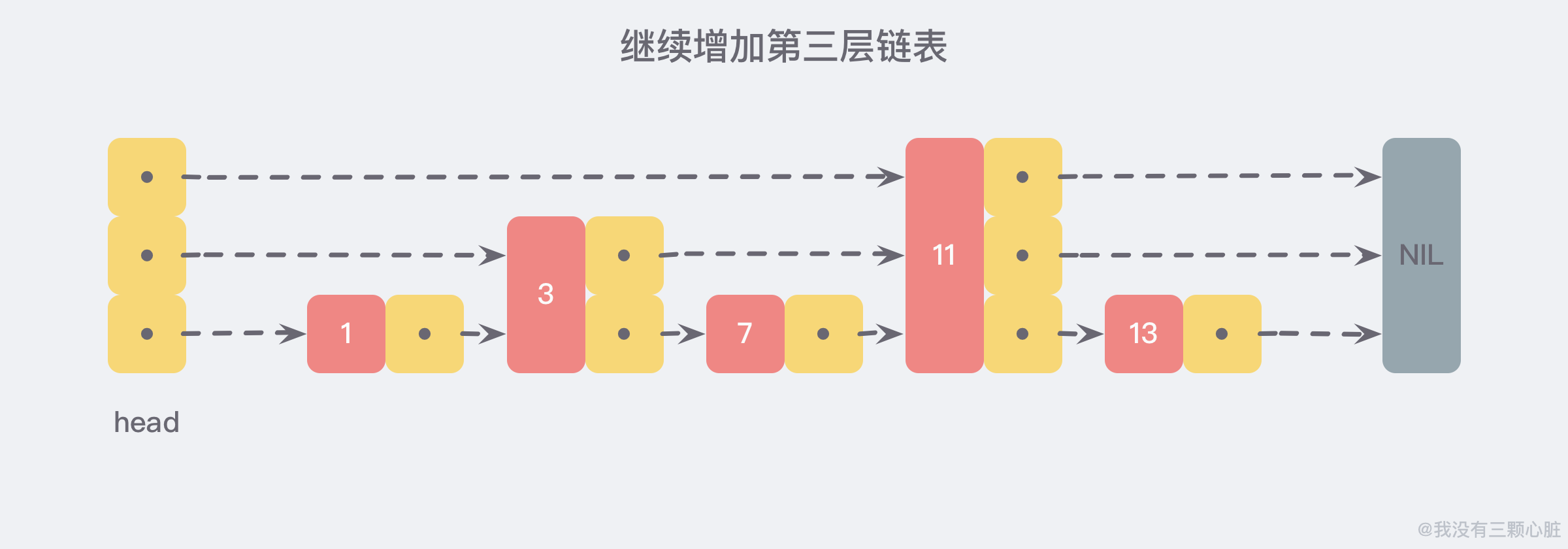
在这个新的三层链表结构中,我们试着 查找 13,那么沿着最上层链表首先比较的是 11,发现 11 比 13 小,于是我们就知道只需要到 11 后面继续查找,从而一下子跳过了 11 前面的所有节点。
可以想象,当链表足够长,这样的多层链表结构可以帮助我们跳过很多下层节点,从而加快查找的效率。
更进一步的跳跃表
跳跃表 skiplist 就是受到这种多层链表结构的启发而设计出来的。按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到 O(logn)。
但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的 2:1 的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点 (也包括新插入的节点) 重新进行调整,这会让时间复杂度重新蜕化成 O(n)。删除数据也有同样的问题。
skiplist 为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是 为每个节点随机出一个层数(level)。比如,一个节点随机出的层数是 3,那么就把它链入到第 1 层到第 3 层这三层链表中。为了表达清楚,下图展示了如何通过一步步的插入操作从而形成一个 skiplist 的过程:
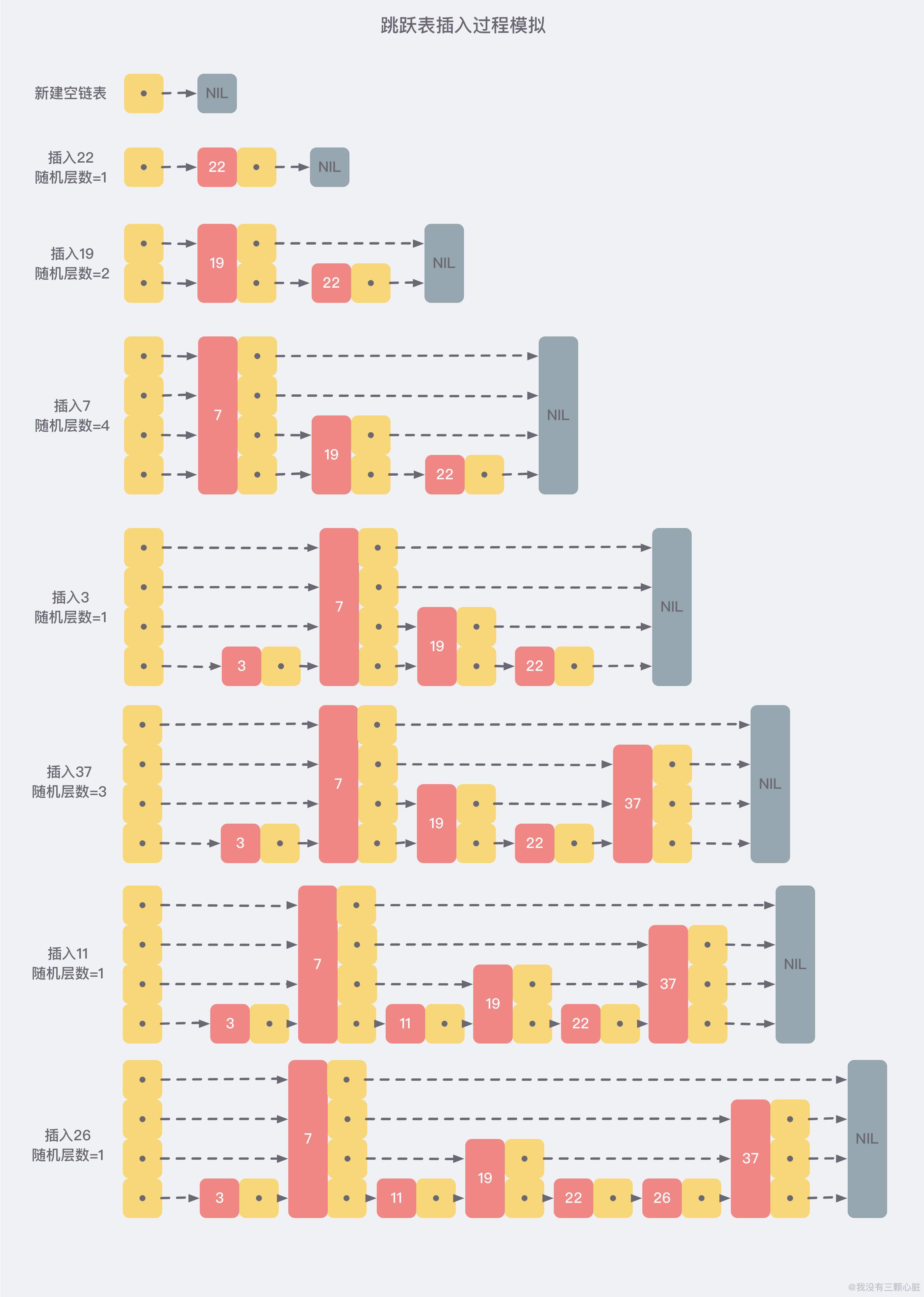
从上面的创建和插入的过程中可以看出,每一个节点的层数(level)是随机出来的,而且新插入一个节点并不会影响到其他节点的层数,因此,插入操作只需要修改节点前后的指针,而不需要对多个节点都进行调整,这就降低了插入操作的复杂度。
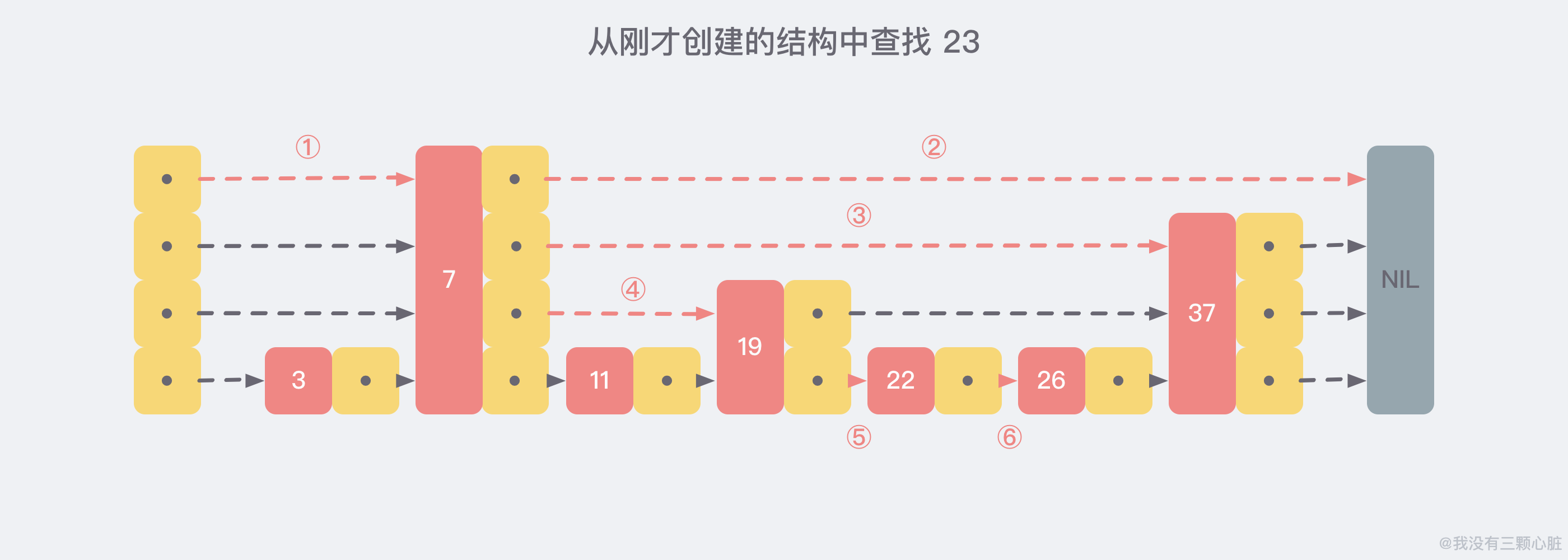
现在我们假设从我们刚才创建的这个结构中查找 23 这个不存在的数,那么查找路径会如下图:
二、跳跃表的实现
Redis 中的跳跃表由 server.h/zskiplistNode 和 server.h/zskiplist 两个结构定义,前者为跳跃表节点,后者则保存了跳跃节点的相关信息,同之前的 集合 list 结构类似,其实只有 zskiplistNode 就可以实现了,但是引入后者是为了更加方便的操作:
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
// value
sds ele;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
// 跳跃表头指针
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;
正如文章开头画出来的那张标准的跳跃表那样。
随机层数
对于每一个新插入的节点,都需要调用一个随机算法给它分配一个合理的层数,源码在 t_zset.c/zslRandomLevel(void) 中被定义:
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
直观上期望的目标是 50% 的概率被分配到 Level 1,25% 的概率被分配到 Level 2,12.5% 的概率被分配到 Level 3,以此类推…有 2-63 的概率被分配到最顶层,因为这里每一层的晋升率都是 50%。
Redis 跳跃表默认允许最大的层数是 32,被源码中 ZSKIPLIST_MAXLEVEL 定义,当 Level[0] 有 264 个元素时,才能达到 32 层,所以定义 32 完全够用了。
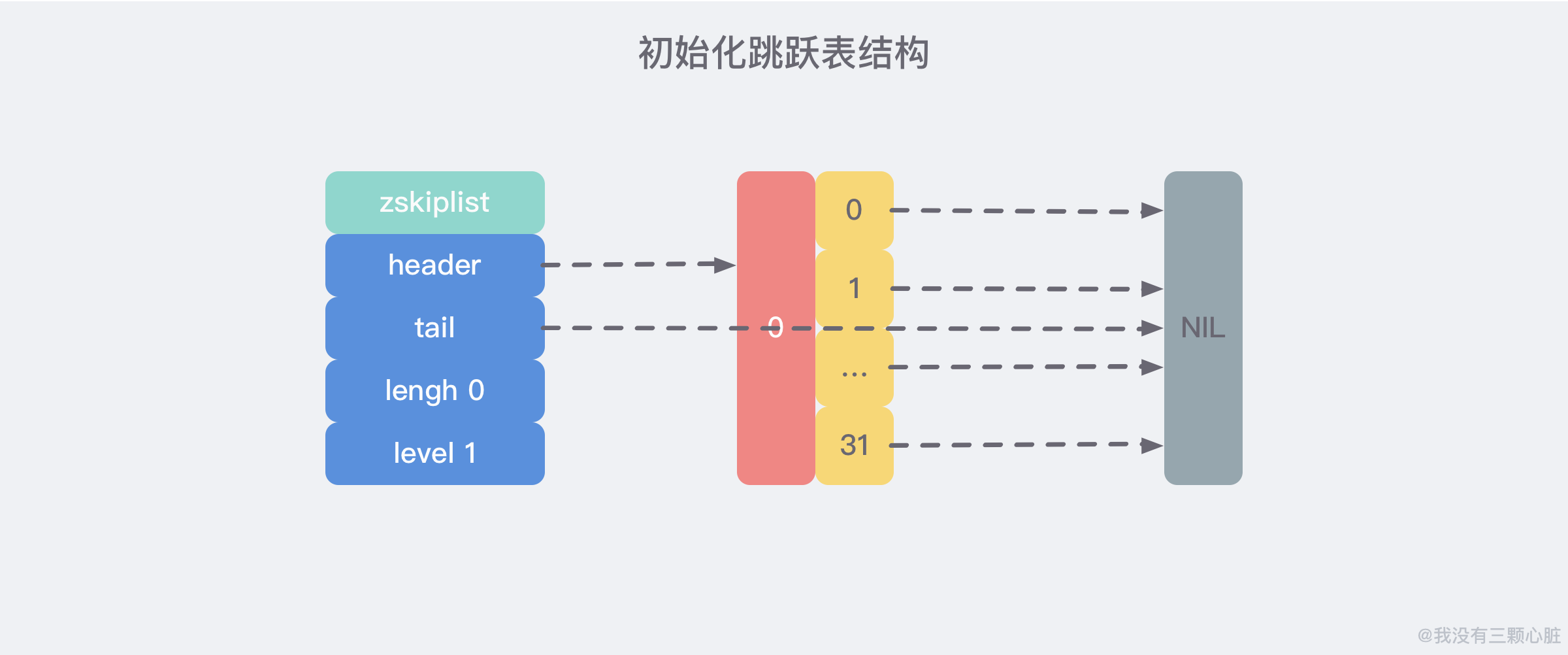
创建跳跃表
这个过程比较简单,在源码中的 t_zset.c/zslCreate 中被定义:
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
// 申请内存空间
zsl = zmalloc(sizeof(*zsl));
// 初始化层数为 1
zsl->level = 1;
// 初始化长度为 0
zsl->length = 0;
// 创建一个层数为 32,分数为 0,没有 value 值的跳跃表头节点
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
// 跳跃表头节点初始化
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
// 将跳跃表头节点的所有前进指针 forward 设置为 NULL
zsl->header->level[j].forward = NULL;
// 将跳跃表头节点的所有跨度 span 设置为 0
zsl->header->level[j].span = 0;
}
// 跳跃表头节点的后退指针 backward 置为 NULL
zsl->header->backward = NULL;
// 表头指向跳跃表尾节点的指针置为 NULL
zsl->tail = NULL;
return zsl;
}
即执行完之后创建了如下结构的初始化跳跃表:
插入节点实现
这几乎是最重要的一段代码了,但总体思路也比较清晰简单,如果理解了上面所说的跳跃表的原理,那么很容易理清楚插入节点时发生的几个动作 (几乎跟链表类似):
- 找到当前我需要插入的位置 (其中包括相同 score 时的处理);
- 创建新节点,调整前后的指针指向,完成插入;
为了方便阅读,我把源码 t_zset.c/zslInsert 定义的插入函数拆成了几个部分
第一部分:声明需要存储的变量
// 存储搜索路径
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
// 存储经过的节点跨度
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
第二部分:搜索当前节点插入位置
serverAssert(!isnan(score));
x = zsl->header;
// 逐步降级寻找目标节点,得到 "搜索路径"
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
// 如果 score 相等,还需要比较 value 值
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
// 记录 "搜索路径"
update[i] = x;
}
讨论: 有一种极端的情况,就是跳跃表中的所有 score 值都是一样,zset 的查找性能会不会退化为 O(n) 呢?
从上面的源码中我们可以发现 zset 的排序元素不只是看 score 值,也会比较 value 值 (字符串比较)
第三部分:生成插入节点
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel();
// 如果随机生成的 level 超过了当前最大 level 需要更新跳跃表的信息
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
// 创建新节点
x = zslCreateNode(level,score,ele);
第四部分:重排前向指针
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
第五部分:重排后向指针并返回
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
节点删除实现
删除过程由源码中的 t_zset.c/zslDeleteNode 定义,和插入过程类似,都需要先把这个 “搜索路径” 找出来,然后对于每个层的相关节点重排一下前向后向指针,同时还要注意更新一下最高层数 maxLevel,直接放源码 (如果理解了插入这里还是很容易理解的):
/* Internal function used by zslDelete, zslDeleteByScore and zslDeleteByRank */
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {
update[i]->level[i].span -= 1;
}
}
if (x->level[0].forward) {
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
}
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
zsl->length--;
}
/* Delete an element with matching score/element from the skiplist.
* The function returns 1 if the node was found and deleted, otherwise
* 0 is returned.
*
* If 'node' is NULL the deleted node is freed by zslFreeNode(), otherwise
* it is not freed (but just unlinked) and *node is set to the node pointer,
* so that it is possible for the caller to reuse the node (including the
* referenced SDS string at node->ele). */
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x;
}
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
zslDeleteNode(zsl, x, update);
if (!node)
zslFreeNode(x);
else
*node = x;
return 1;
}
return 0; /* not found */
}
节点更新实现
当我们调用 ZADD 方法时,如果对应的 value 不存在,那就是插入过程,如果这个 value 已经存在,只是调整一下 score 的值,那就需要走一个更新流程。
假设这个新的 score 值并不会带来排序上的变化,那么就不需要调整位置,直接修改元素的 score 值就可以了,但是如果排序位置改变了,那就需要调整位置,该如何调整呢?
从源码 t_zset.c/zsetAdd 函数 1350 行左右可以看到,Redis 采用了一个非常简单的策略:
/* Remove and re-insert when score changed. */
if (score != curscore) {
zobj->ptr = zzlDelete(zobj->ptr,eptr);
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
*flags |= ZADD_UPDATED;
}
把这个元素删除再插入这个,需要经过两次路径搜索,从这一点上来看,Redis 的 ZADD 代码似乎还有进一步优化的空间。
元素排名的实现
跳跃表本身是有序的,Redis 在 skiplist 的 forward 指针上进行了优化,给每一个 forward 指针都增加了 span 属性,用来 表示从前一个节点沿着当前层的 forward 指针跳到当前这个节点中间会跳过多少个节点。在上面的源码中我们也可以看到 Redis 在插入、删除操作时都会小心翼翼地更新 span 值的大小。
所以,沿着 “搜索路径”,把所有经过节点的跨度 span 值进行累加就可以算出当前元素的最终 rank 值了:
/* Find the rank for an element by both score and key.
* Returns 0 when the element cannot be found, rank otherwise.
* Note that the rank is 1-based due to the span of zsl->header to the
* first element. */
unsigned long zslGetRank(zskiplist *zsl, double score, sds ele) {
zskiplistNode *x;
unsigned long rank = 0;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) <= 0))) {
// span 累加
rank += x->level[i].span;
x = x->level[i].forward;
}
/* x might be equal to zsl->header, so test if obj is non-NULL */
if (x->ele && sdscmp(x->ele,ele) == 0) {
return rank;
}
}
return 0;
}
扩展阅读
- 跳跃表 Skip List 的原理和实现(Java) - https://blog.csdn.net/DERRANTCM/article/details/79063312
- 【算法导论33】跳跃表(Skip list)原理与java实现 - https://blog.csdn.net/brillianteagle/article/details/52206261

 浙公网安备 33010602011771号
浙公网安备 33010602011771号