卷积神经网络CNN全面解析
2016-03-31 21:39 GarfieldEr007 阅读(21427) 评论(3) 收藏 举报最近仔细学习了一下卷积神经网络(CNN,Convolutional Neural Network),发现各处资料都不是很全面,经过艰苦努力终于弄清楚了。为了以后备查,以及传播知识,决定记录下来。本文将极力避免废话,重点聚焦在推导过程上,为打算从零开始的孩纸说清楚“为什么”。
另外,因本人才疏学浅(是真的才疏学浅,不是谦虚),肯定会有很多谬误,欢迎大家指出!
卷积神经网络(CNN)概述
- 由来:神经元网络的直接升级版
- 相关:Yann LeCun和他的LeNet
- 影响:在图像、语音领域不断突破,复兴了神经元网络并进入“深度学习”时代
卷积神经网络沿用了普通的神经元网络即多层感知器的结构,是一个前馈网络。以应用于图像领域的CNN为例,大体结构如图1。
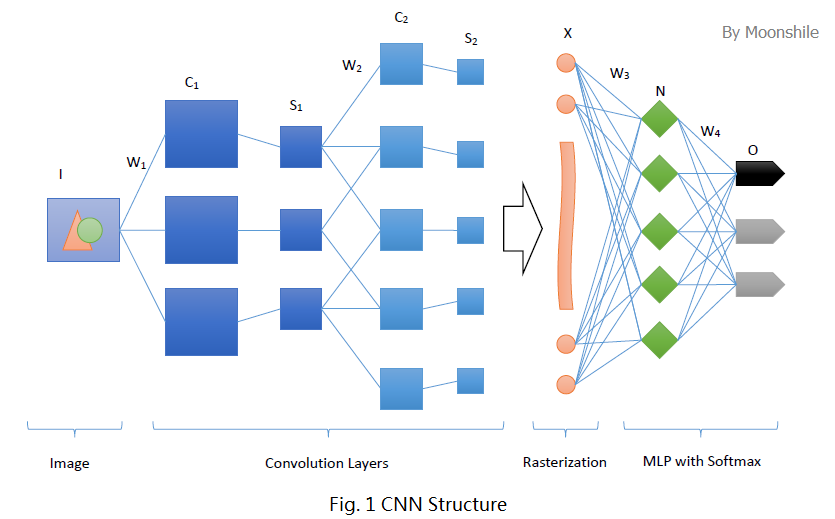
很明显,这个典型的结构分为四个大层次
- 输入图像I。为了减小复杂度,一般使用灰度图像。当然,也可以使用RGB彩色图像,此时输入图像有三张,分别为RGB分量。输入图像一般需要归一化,如果使用sigmoid激活函数,则归一化到[0, 1],如果使用tanh激活函数,则归一化到[-1, 1]。
- 多个卷积(C)-下采样(S)层。将上一层的输出与本层权重W做卷积得到各个C层,然后下采样得到各个S层。怎么做以及为什么,下面会具体分析。这些层的输出称为Feature Map。
- 光栅化(X)。是为了与传统的多层感知器全连接。即将上一层的所有Feature Map的每个像素依次展开,排成一列。
- 传统的多层感知器(N&O)。最后的分类器一般使用Softmax,如果是二分类,当然也可以使用LR。
接下来,就开始深入探索这个结构吧!
从多层感知器(MLP)说起
卷积神经网络来源于普通的神经元网络。要了解个中渊源,就要先了解神经元网络的机制以及缺点。典型的神经元网络就是多层感知器。
摘要:本节主要内容为多层感知器(MLP,Multi-Layer Perceptron)的原理、权重更新公式的推导。熟悉这一部分的童鞋可以直接跳过了~但是,一定一定要注意,本节难度比较大,所以不熟悉的童鞋一定一定要认真看看!如果对推导过程没兴趣,可直接在本节最后看结论。
感知器
感知器(Perceptron)是建立模型
其中激活函数 act 可以使用{sign, sigmoid, tanh}之一。
- 激活函数使用符号函数 sign ,可求解损失函数最小化问题,通过梯度下降确定参数
- 激活函数使用 sigmoid (或者 tanh ),则分类器事实上成为Logistic Regression(个人理解,请指正),可通过梯度上升极大化似然函数,或者梯度下降极小化损失函数,来确定参数
- 如果需要多分类,则事实上成为Softmax Regression
- 如要需要分离超平面恰好位于正例和负例的正中央,则成为支持向量机(SVM)。
感知器比较简单,资料也比较多,就不再详述。
多层感知器
感知器存在的问题是,对线性可分数据工作良好,如果设定迭代次数上限,则也能一定程度上处理近似线性可分数据。但是对于非线性可分的数据,比如最简单的异或问题,感知器就无能为力了。这时候就需要引入多层感知器这个大杀器。
多层感知器的思路是,尽管原始数据是非线性可分的,但是可以通过某种方法将其映射到一个线性可分的高维空间中,从而使用线性分类器完成分类。图1中,从X到O这几层,正展示了多层感知器的一个典型结构,即输入层-隐层-输出层。
输入层-隐层
是一个全连接的网络,即每个输入节点都连接到所有的隐层节点上。更详细地说,可以把输入层视为一个向量 xx ,而隐层节点 jj 有一个权值向量 θjθj 以及偏置 bjbj ,激活函数使用 sigmoid 或 tanh ,那么这个隐层节点的输出应该是
也就是每个隐层节点都相当于一个感知器。每个隐层节点产生一个输出,那么隐层所有节点的输出就成为一个向量,即
若输入层有 mm 个节点,隐层有 nn 个节点,那么 Θ=[θT]Θ=[θT] 为 n×mn×m 的矩阵,xx 为长为 mm 的向量,bb 为长为 nn 的向量,激活函数作用在向量的每个分量上, f(x)f(x) 返回一个向量。
隐层-输出层
可以视为级联在隐层上的一个感知器。若为二分类,则常用Logistic Regression;若为多分类,则常用Softmax Regression。
Back Propagation
搞清楚了模型的结构,接下来就需要通过某种方法来估计参数了。对于一般的问题,可以通过求解损失函数极小化问题来进行参数估计。但是对于多层感知器中的隐层,因为无法直接得到其输出值,当然不能够直接使用到其损失了。这时,就需要将损失从顶层反向传播(Back Propagate)到隐层,来完成参数估计的目标。
首先,约定标量为普通小写字母,向量为加粗小写字母,矩阵为加粗大写字母;再约定以下记号:
- 输入样本为 xx,其标签为 tt
- 对某个层 QQ ,其输出为 oQoQ ,其第 jj 个节点的输出为 o(j)QoQ(j) ,其每个节点的输入均为上一层 PP 的输出 oPoP ;层 QQ 的权重为矩阵 ΘQΘQ ,连接层 PP 的第 ii 个节点与层 QQ 的第 jj 个节点的权重为 θ(ji)QθQ(ji)
- 对输出层 YY ,设其输出为 oYoY, 其第 yy 个节点的输出为 o(y)YoY(y)
现在可以定义损失函数
其中, ϕϕ 为激活函数。我们依旧通过极小化损失函数的方法,尝试进行推导。则
上边两个式子的等号右边部有三个导数比较容易确定
然后再看剩下的比较复杂的一个偏导数。考虑层 QQ 的下一层 RR ,其节点 kk 的输入为层 QQ 中每个节点的输出,也就是为 o(j)QoQ(j) 的函数,考虑逆函数,可视 o(j)QoQ(j) 为 o(k)RoR(k) 的函数,也为 n(k)RnR(k) 的函数。则对每个隐层