布隆过滤器、哈希一致性
一、布隆过滤器
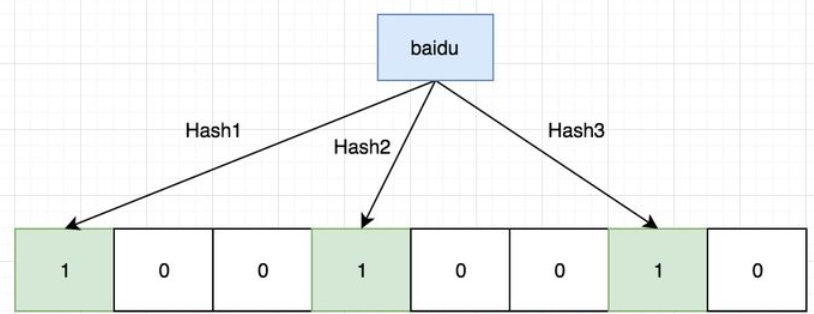
使用大的bitMap,存储哈希函数计算后的结果。
请求: 文件中有大量的key,此时请求一个key,判断是否在文件中。(如果允许失误率,使用布隆过滤器)
步骤:1. 使用k个hash函数计算key的hash值,再%m(bitMap的位数),将k个计算出的位置都填1。
2.下次查询是否存在key时,经过k个hash函数计算出的k个值,查看bitMap中对应位置,如果都为1,则存在过,反之不存在。
但是有失误率P,
问题:不存在文件中的key,也会被误认为存在于文件。
(如果K值不合适,或者m值过小,则失误率就会上涨。)
下图为各个参数计算公式。

二、哈希一致性
该算法的原理用一句话将就是:
将服务器节点分布到一个环上,必要时需要增加虚拟节点(映射到真实节点),查找的时候根据Hash算法定位到环上的某个点,然后再顺时针找到最近的一个可用的服务器节点。
解决问题
在使用分布式对数据进行存储时,经常会碰到需要新增节点来满足业务快速增长的需求。然而在新增节点时,如果处理不善会导致所有的数据重新分片,这对于某些系统来说可能是灾难性的。
作用:在新增或者减少服务器的时候,减小影响的范围。
原理
一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:
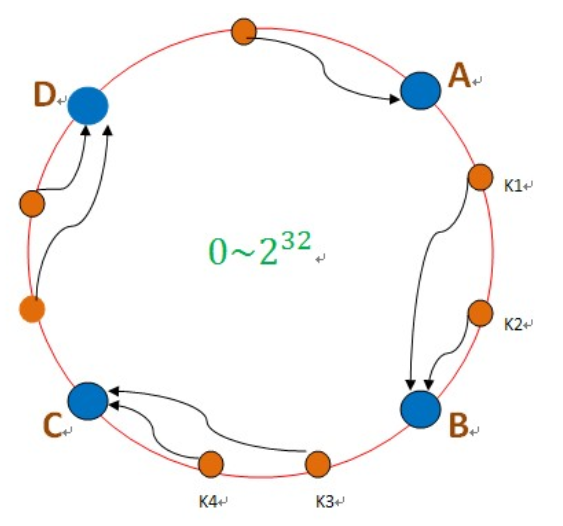
- 首先求出memcached服务器(节点)的哈希值,并将其配置圆(continuum)上。
- 然后采用同样的方法求出存储数据的键的哈希值,并映射到相同的圆上。
- 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。
但此时有问题
- 机器节点不一定分配均匀
- 增加或减少机器,负载就不均衡了
因此产生了虚拟节点技术来解决问题
虚拟节点
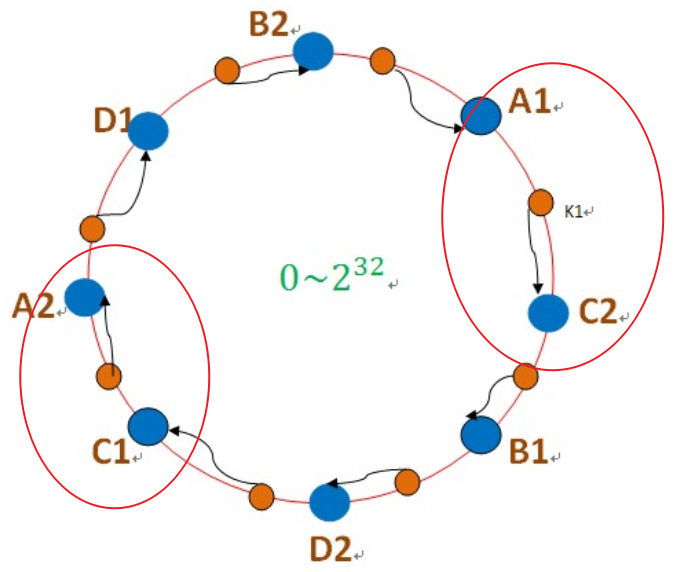
为机器分配字符串,此时不再用机器来抢环上的数据归属,而是使用字符串(机器的代表点)来抢占
如机器A:a1,a2,a3,.......a1000
B: b1,b2,b3,......b1000
C: c1,c2,c3,........c1000
此时使用字符串(机器的代表点)来计算hash值来抢环
因为虚拟节点很多,所以在环上的任意区域,相当于均分了数据。如下图,任意区域都均分了虚拟节点,
此时如果增加机器,就给新增的节点D也分配很多字符串用来抢数据,最后一个区域就均分4个机器的虚拟节点了。
此时就解决了机器节点不均匀分配和增加减少机器负载不均衡的问题了。
而且还额外的增添了一个功能,就是可以管理负载,如果A机器性能良好,就可以分配2000个虚拟节点,而D机器不好,就可以少分配一些节点,从而达到管理负载的效果。
性质
平衡性(Balance)
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
单调性(Monotonicity)
如果原本有一些服务器被分配了数据,此时有新的服务器加入,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的服务器中去,,而不会被映射到旧的服务器中。
平滑性(Smoothness)
平滑性是指缓存服务器的数目平滑改变和缓存对象的平滑改变是一致的。
分散性(Spread)
在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。
导致了相同内容被存储到不同缓冲中去,降低了系统存储的效率。
分散性的定义就是上述情况发生的严重程度。
好的哈希算法应能够尽量避免不一致
负载(Load)
负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
