GCC使用具体教程以及例子
编译第一个C程序
#include <stdio.h> int main(void) { printf("hello world!\n"); return 0; }
使用gcc命令将hello.c编译成可执行程序 a.out,并运行:
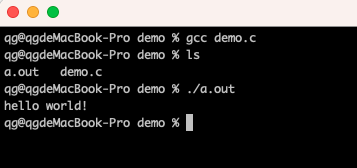
将源文件hello.c编译为一个指定名称的可执行文件:hello,可以通过gcc -o参数来完成
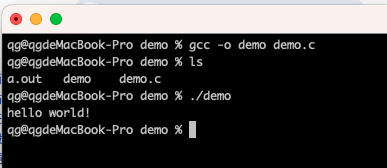
GCC 编译过程分析
以demo.c为例:从一个C语言源文件,到生成最后的可执行文件,GCC编译过程的基本流程如下:
- C 源文件: 编写一个简单的hello world程序
- 预处理:生成预处理后的C源文件 hello.i
- 编译:将C源文件翻译成汇编文件 hello.s
- 汇编:将汇编文件汇编成目标文件 hello.o
- 链接:将目标文件链接成可执行文件
gcc命令是GCC编译器里的一个前端程序,用来控制整个编译过程:分别调用预处理器、编译器和汇编器,完成编译的每一个过程,最后调用链接器,生成可执行文件:a.out
默认情况下,gcc命令会自动完成上述的整个编译过程。当然,gcc还提供了一系列参数,使用这个参数,可以让用户精准控制每一个编译过程。
- -E :只做预处理,不编译
- -S :只编译,将C程序编译为汇编文件
- -c :只汇编,不链接。
- -o :指定输出的文件名
GCC -E 参数
如果只对一段C语言程序做预处理操作,而不进行编译,可以通过gcc -E 参数来完成。如下面的一段程序,在程序中分别使用#include包含头文件,使用#define定义宏,使用#ifdef条件编译。
#include <stdio.h> #define PI 3.14 int main(void) { printf("hello world!\n"); printf("PI = %f\n", PI); #ifdef DEBUG printf("debug mode\n"); #else printf("release mode\n"); #endif return 0; }
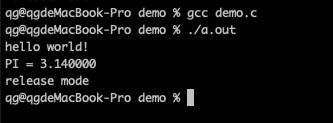
上面的C源程序使用gcc -E进行预处理,就可以生成原汁原味的C程序

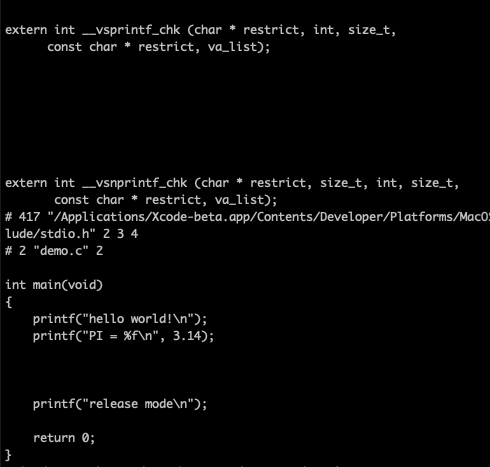
通过预处理后的C程序,使用#include包含的的头文件就地展开,我们可以看到stdio.h头文件中printf函数的声明。程序中使用#define定义的宏PI,也会在实际使用的地方展开为实际的值。使用#ifdef定义的条件编译,会根据条件判断,选择实际要编译的代码分支。
GCC -S 参数
如果只对C源程序做编译处理,不汇编,可以使用gcc -S 参数:会gcc会将C源程序做预处理、编译操作,生成对应的汇编文件,不再做进一步的汇编和链接操作。
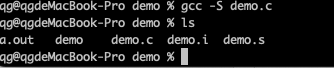
也可以 利用上次的
gcc -S demo.i
GCC -c 参数
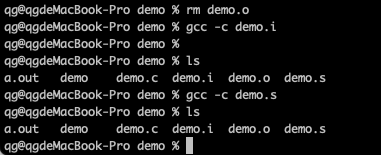
如果只想对一个C程序做汇编操作,不进行链接,可以使用gcc -c 来完成:

gcc只对源文件做预处理、编译和汇编操作,不会做链接操作。在当前目录下,我们可以看到demo.c经过汇编编译,生成的对应的demo.o目标文件。
当然,gcc -c 选项,也可以对上几节生成的 demo.i、demo.s文件直接汇编,生成对应的目标文件
默认情况下,gcc会将demo.c生成对应的demo.o目标文件。当然,我们也可以通过 -o 输出选项,生成指定的目标文件:

GCC 静态链接库
我们也可以通过gcc命令,将自己实现的一些函数封装成库,提供给其他开发者使用。
制作静态链接库
假如现在有add.c和sub.c 源文件,分别实现了加法函数add()和减法函数sub():
// add.c int add(int a, int b) { return a + b; } // sub.c int sub(int a, int b) { return a - b; }
将它们编译生成一个静态库libmath.a,供其他程序调用:
# gcc -c add.c # gcc -c sub.c # ls add.c add.o sub.c sub.o # ar rcs libmath.a add.o sub.o # ls add.c add.o libmath.a sub.c sub.o
生成的libmath.a就是一个静态库,里面包含了我们实现的add()函数和sub()函数:
# ar t libmath.a add.o sub.o # nm libmath.a add.o: 0000000000000000 T add sub.o: 0000000000000000 T sub
使用静态链接库
接下来,我们就可以编写一个main()函数,然后在main函数里调用它们。
int add(int a, int b); int sub(int a, int b); int main(void) { add(1, 2); sub(4, 3); return 0; }
在编译mainc源文件时,因为调用了libmath.a库中的add和sub函数,编译时要使用gcc -l指定库的名字,使用-L指定库的路径:
# ls libmath.a main.c # gcc main.c -L./ -lmath # ls a.out libmath.a main.c
GCC -I 参数
按照C语言的传统,调用函数之前,要先声明,然后才能使用。对add和sub函数的声明,可以放到C源文件里声明,也可以单独放到一个头文件里声明,任何使用add和sub函数的源文件,直接包含这个头文件就可以了。
# tree . ├── inc │ ├── add.h │ └── sub.h ├── libmath.a └── main.c # cat inc/add.h int add(int a, int b); # cat inc/sub.h int sub(int a, int b); # cat main.c #include "add.h" #include "sub.h" int main(void) { add(1, 2); sub(4, 3); return 0; }
因为头文件 add.h 和 sub.h 统一放到了inc目录下,编译器在预处理时,要告诉编译器这个路径,否则编译器就会找不到这些头文件报错。通过 gcc -I参数可以告诉编译器,这些头文件的所在路径:
# ls inc libmath.a main.c # gcc main.c -L./ -lmath -I inc/ # ls a.out inc libmath.a main.c
GCC 动态链接库
静态库里实现的函数,可能被多个应用程序调用,那么在链接时,被调用的这个函数可能就会多次链接到不同的应用程序中。
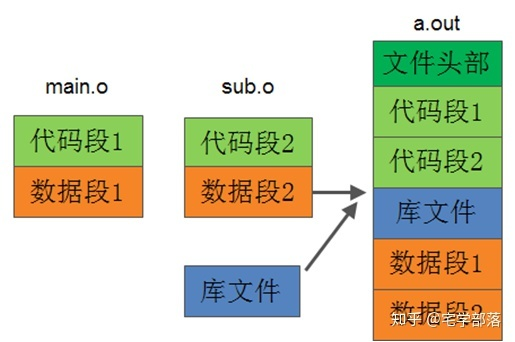
比如C标准库的printf函数,可能被一个应用程序调用多次,被不同的应用程序调用,当这些应用程序加载到内存运行时,内存中也就存在多个printf函数代码的副本,太浪费了内存空间。而且,对于应用程序来说,每一个调用的库函数都被链接进来,自身的文件体积也会大增。是可忍孰不可忍,动态链接此时就粉墨登场了。
动态链接跟静态链接相比,具有以下优势
- 库的代码不会链接到应用程序里
- 同一份代码(如printf代码)可以被多个应用程序共享使用
- 大大节省了内存空间
但动态库也有缺点,发布软件时,动态库需要和应用程序一起发布,否则你编译的应用程序到了一个新的平台可能就无法运行。
制作一个动态库
gcc -shared -fPIC -o libmymath.dylib add.c sub.c

其中的参数说明:
- -shared :动态库编译,链接动态库
- -fPIC(或fpic) :生成使用相对地址无关的目标代码
- -Ldir :在动态库的搜索路径中增加dir目录
- -lname :链接静态库(libname.a)或动态库(libname.so)的库
使用动态链接
将动态链接库拷贝到main.c的同一目录下
# tree
.
├── inc
│ ├── add.h
│ └── sub.h
├── libmymath.so
└── main.c
在编译main.c,链接动态库libmymath.so的时候,直接指定当前目录下的libmymath.dylib文件:
# gcc main.c ./libmymath.dylib -I inc/ # ls a.out inc libmymath.dylib main.c
在当前目录下运行生成的可执行文件a.out,可以正常运行。将a.out拷贝到其他目录,比如/opt目录下 会报错
我们需要将对应的libmymath.dylib文件拷贝到a.out的同一目录下,然后a.out才能正常运行。
Linux的动态链接库一般都放在/lib官方默认目录下。如果想让a.out放在任何路径下都可以运行,我们可以把libmymath.dylib动态库拷贝到/lib下,然后在编译应用程序时,通过-L参数指定动态链接库的搜索路径。编译生成的a.out在运行时,就会到指定的/lib目录下去加载动态库libmyamth.dylib:
GCC -std标准
同样一段C程序,使用GCC的不同标准去编译,编译的结果可能不相同。使用gcc -std参数可以指定GCC编译时的标准,常用的标准如下:
- c89
- c99
- c11
- gnu89、gnu90、gnu99、gnu11
gnu89和c89标准的区别是:gnu89除了支持和兼容c89标准外,在c89的基础上进行了语法扩展。
同样一段C程序,使用GCC不同的C标准去编译,结果可能就不一样:
# cat hello.c #include <stdio.h> int main(void) { int a[10]; for(int i = 0; i < 10; i++) a[i] = i; return 0; }
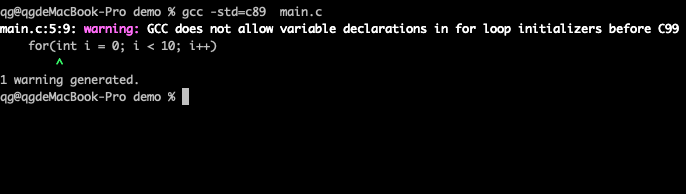
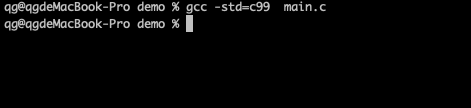
如果根据提示,使用C99、C11、gnu99等标准编译,就不会报错,可以正常编译:
GCC -Wall 参数
GCC编译器的-Wall参数用于显示所有的警告信息。大家在编写程序时,不要以为编译通过,程序可以运行就万事大吉了,任何一个隐藏的警告信息都可以对软件的稳定运行带来隐患。因此,我们不要放过任何一个警告信息,使用GCC编译器的-Wall参数,可以开启警告信息,显示所有的警告信息。
GCC -g 参数
程序的编译一般分为两种模式:debug模式和release模式。
软件在开发阶段,需要不断地调试,甚至源码级单步调试,此时建议使用debug模式编译,生成的可执行文件中包含了大量的调试信息,可以方便我们使用gdb等调试器进行源码级地调试:比如单步、在源码中设置断点等。
使用调试模式生成的可执行文件因为包含大量的调试信息,所以文件体系会比release模式大。等开发结束,发布软件时,建议使用release模式,生成的可执行文件体积就比较小了。
使用gcc -g 选项,可以生成一个debug模式的可执行文件
使用debug模式生成的可执行文件里,会有一些单独的section保存各种符号及调试信息,这些信息包含了二进制代码和源码之间的一一对应关系。通过这种对应关系,我们就可以实现源码级的单步调试和设置断点。
对比一下,release模式的可执行文件,你会发现:debug模式的可执行文件里有35个section,而release模式的可执行文件里只有30个section:

