
c++进阶
来自视频课程学习笔记资料整理,有做删改,记性不好记录查询使用,仅做参考
c++进阶
一、类的访问权限
-
类的成员有三种访问权限:public、private和protected,分别表示公有的、私有的和受保护的。
-
在类的内部(类的成员函数中),无论成员被声明为 public还是private,都可以访问。
-
在类的外部(定义类的代码之外),只能访问public成员,不能访问 private、protected成员。
-
在一个类体的定义中,private 和 public 可以出现多次。
-
结构体的成员缺省为public,类的成员缺省为private。
-
private的意义在于隐藏类的数据和实现,把需要向外暴露的成员声明为public。
二、简单使用类
-
编程思想和方法的改变,披着C++外衣的C程序员。
-
类的成员函数可以直接访问该类其它的成员函数(可以递归)。
-
类的成员函数可以重载,可以使用默认参数。
-
类指针的用法与结构体指针用法相同。
-
类的成员可以是任意数据类型(类中枚举)。
-
可以为类的成员指定缺省值(C++11标准)。
-
类可以创建对象数组,就像结构体数组一样。
-
对象可以作为实参传递给函数,一般传引用。
-
可以用new动态创建对象,用delete释放对象。
-
在类的外部,一般不直接访问(读和写)对象的成员,而是用成员函数。数据隐藏是面向对象编程的思想之一。
-
对象一般不用memset()清空成员变量,可以写一个专用于清空成员变量的成员函数。
-
对类和对象用sizeof运算意义不大,一般不用。
-
用结构体描述纯粹的数据,用类描述对象。
-
在类的声明中定义的函数都将自动成为内联函数;在类的声明之外定义的函数如果使用了inline限定符,也是内联函数。
-
为了区分类的成员变量和成员函数的形参,把成员变量名加m_前缀或_后缀,如m_name或name_。
-
类的分文件编写。
三、构造函数和析构函数
-
构造函数:在创建对象时,自动的进行初始化工作。
-
析构函数:在销毁对象前,自动的完成清理工作。
构造函数
语法:类名(){......}
- 访问权限必须是public。
- 函数名必须与类名相同。
- 没有返回值,不写void。
- 可以有参数,可以重载,可以有默认参数。
- 创建对象时只会自动调用一次,不能手工调用。
析构函数
语法:~类名(){......}
- 访问权限必须是public。
- 函数名必须在类名前加~。
- 没有返回值,也不写void。
- 没有参数,不能重载。
- 销毁对象前只会自动调用一次,但是可以手工调用。
注意:
- 如果没有提供构造/析构函数,编译器将提供空实现的构造/析构函数。
- 如果提供了构造/析构函数,编译器将不提供空实现的构造/析构函数。
- 创建对象的时候,如果重载了构造函数,编译器根据实参匹配相应的构造函数。没有参数的构造函数也叫默认构造函数。
- 创建对象的时候不要在对象名后面加空的圆括号,编译器误认为是声明函数。(如果没有构造函数、构造函数没有参数、构造函数的参数都有默认参数)
- 在构造函数名后面加括号和参数不是调用构造函数,是创建匿名对象。
- 接受一个参数的构造函数允许使用赋值语法将对象初始化为一个值(可能会导致问题,不推荐)。
CGirl girl =10;
以下两行代码有本质的区别:
CGirl girl = CGirl("西施"20); // 显式创建对象。
CGirl girl; // 创建对象。
girl = CGirl("西施"20); // 创建匿名对象,然后给现有的对象赋值。
- 用new/delete创建/销毁对象时,也会调用构造/析构函数。
- 不建议在构造/析构函数中写太多的代码,可以调用成员函数。
- 除了初始化,不建议让构造函数做太多工作(只能成功不会失败)。
- C++11支持使用统一初始化列表。
CGirl girl = {"西施"20};
CGirl girl {"西施"20};
CGirl* girl = new CGirl{ "西施"20 };
- 如果类的成员也是类,创建对象的时候,先构造成员类;销毁对象的时候,先析构成员类。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
public:
string m_name; // 姓名属性。
int m_age; // 年龄属性。
char m_memo[301]; // 备注。
CGirl() // 没有参数的构造函数。
{
initdata();
cout << "调用了CGirl()构造函数。\n";
}
CGirl(string name) // 一个参数(姓名)的构造函数。
{
initdata();
cout << "调用了CGirl(name)构造函数。\n";
m_name = name;
}
CGirl(int age) // 一个参数(年龄)的构造函数。
{
initdata();
cout << "调用了CGirl(age)构造函数。\n";
m_age = age;
}
CGirl(string name, int age) // 两个参数的构造函数。
{
initdata();
cout << "调用了CGirl(name,age)构造函数。\n";
m_name = name; m_age = age;
}
void initdata()
{
m_name.clear(); m_age = 0; memset(m_memo, 0, sizeof(m_memo));
}
~CGirl() // 析构函数。
{
cout << "调用了~CGirl()\n";
}
void show() // 超女自我介绍的方法。
{ cout << "姓名:" << m_name << ",年龄:" << m_age << ",备注:" << m_memo<< endl; }
};
int main()
{
// CGirl girl; // 创建超女对象,不设置任何初始值。
// CGirl girl("西施"); // 创建超女对象,为成员姓名设置初始值。
// CGirl girl("西施",8); // 创建超女对象,为成员姓名和年龄设置初始值。
// CGirl girl=CGirl(); // 创建超女对象,不设置任何初始值。
// CGirl girl=CGirl("西施"); // 创建超女对象,为成员姓名设置初始值。
// CGirl girl=CGirl("西施",8); // 创建超女对象,为成员姓名和年龄设置初始值。
// CGirl girl = 8; // 使用赋值语法初始化对象。
// CGirl *girl=new CGirl; // 创建超女对象,不设置任何初始值。
// CGirl *girl=new CGirl("西施"); // 创建超女对象,为成员姓名设置初始值。
CGirl *girl=new CGirl("西施",8); // 创建超女对象,为成员姓名和年龄设置初始值。
girl->show(); // 显示超女的自我介绍。
delete girl;
}
四、拷贝构造函数
-
用一个已存在的对象创建新的对象,不会调用(普通)构造函数,而是调用拷贝构造函数。
-
如果类中没有定义拷贝构造函数,编译器将提供一个拷贝构造函数,它的功能是把已存在对象的成员变量赋值给新对象的成员变量。
用一个已存在的对象创建新的对象语法
-
类名 新对象名(已存在的对象名);
-
类名 新对象名=已存在的对象名;
-
拷贝构造函数的语法:
-
类名(const 类名& 对象名)
注意:
-
访问权限必须是public。
-
函数名必须与类名相同。
-
没有返回值,不写void。
-
如果类中定义了拷贝构造函数,编译器将不提供默认的拷贝构造函数。
-
以值传递的方式调用函数时,如果实参为对象,会调用拷贝构造函数。
-
函数以值的方式返回对象时,可能会调用拷贝构造函数(VS会调用,Linux不会,g++编译器做了优化)。
-
拷贝构造函数可以重载,可以有默认参数。
-
类名(......,const 类名& 对象名,......)
-
如果类中重载了拷贝构造函数却没有定义默认的拷贝构造函数,编译器也会提供默认的拷贝构造函数。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
public:
string m_name; // 姓名属性。
int m_age; // 年龄属性。
// 没有参数的普通构造函数。
CGirl() { m_name.clear(); m_age = 0; cout << "调用了CGirl()构造函数。\n"; }
// 没有重载的拷贝构造函数(默认拷贝构造函数)。
CGirl(const CGirl &gg) { m_name="漂亮的"+gg.m_name; m_age = gg.m_age-1; cout << "调用了CGirl(const CGirl &gg)拷贝构造函数。\n"; }
// 重载的拷贝构造函数。
CGirl(const CGirl& gg,int ii) { m_name = "漂亮的" + gg.m_name; m_age = gg.m_age - ii; cout << "调用了CGirl(const CGirl &gg,int ii)拷贝构造函数。\n"; }
// 析构函数。
~CGirl() { cout << "调用了~CGirl()\n"; }
// 超女自我介绍的方法,显示姓名和年龄。
void show() { cout << "姓名:" << m_name << ",年龄:" << m_age << endl; }
};
int main()
{
CGirl g1;
g1.m_name = "西施"; g1.m_age = 23;
CGirl g2(g1,3);
g2.show();
}
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
public:
string m_name; // 姓名属性。
int m_age; // 年龄属性。
int* m_ptr; // 指针成员,计划使用堆内存。
// 没有参数的普通构造函数。
CGirl() { m_name.clear(); m_age = 0; m_ptr = nullptr; cout << "调用了CGirl()构造函数。\n"; }
// 没有重载的拷贝构造函数(默认拷贝构造函数)。
CGirl(const CGirl& gg)
{
m_name = gg.m_name; m_age = gg.m_age;
m_ptr = new int; // 分配内存。
// *m_ptr = *gg.m_ptr; // 拷贝数据。
memcpy(m_ptr, gg.m_ptr, sizeof(int)); // 拷贝数据。
cout << "调用了CGirl(const CGirl &gg)拷贝构造函数。\n";
}
// 析构函数。
~CGirl() { delete m_ptr; m_ptr = nullptr; cout << "调用了~CGirl()\n"; }
// 超女自我介绍的方法,显示姓名和年龄。
void show() { cout << "姓名:" << m_name << ",年龄:" << m_age << ",m_ptr="<< m_ptr<<",*m_ptr="<<*m_ptr<<endl; }
};
int main()
{
CGirl g1;
g1.m_name = "西施"; g1.m_age = 23; g1.m_ptr = new int(3);
g1.show();
CGirl g2(g1); *g2.m_ptr = 8;
g1.show();
g2.show();
}
五、初始化列表
-
构造函数的执行可以分成两个阶段:初始化阶段和计算阶段(初始化阶段先于计算阶段)。
-
初始化阶段:全部的成员都会在初始化阶段初始化。
-
计算阶段:一般是指用于执行构造函数体内的赋值操作。
-
构造函数除了参数列表和函数体之外,还可以有初始化列表。
初始化列表的语法
-
类名(形参列表):成员一(值一), 成员二(值二),..., 成员n(值n)
注意:
-
如果成员已经在初始化列表中,则不应该在构造函数中再次赋值。
-
初始化列表的括号中可以是具体的值,也可以是构造函数的形参名,还可以是表达式。
-
初始化列表与赋值有本质的区别,如果成员是类,使用初始化列表调用的是成员类的拷贝构造函数,而赋值则是先创建成员类的对象(将调用成员类的普通构造函数),然后再赋值。
-
如果成员是类,初始化列表对性能略有提升。
-
如果成员是常量和引用,必须使用初始列表,因为常量和引用只能在定义的时候初始化。
-
如果成员是没有默认构造函数的类,则必须使用初始化列表。
-
拷贝构造函数也可以有初始化列表。
-
类的成员变量可以不出现在初始化列表中。
-
构造函数的形参先于成员变量初始化。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CBoy // 男朋友类。
{
public:
string m_xm; // 男朋友的姓名。
CBoy() // 没有参数的普通构造函数,默认构造函数。
{ m_xm.clear(); cout << "调用了CBoy()构造函数。\n"; }
CBoy(string xm) // 有一个参数的普通构造函数。
{ m_xm = xm; cout << "调用了CBoy(string xm)构造函数。\n"; }
CBoy(const CBoy& bb) // 默认拷贝构造函数。
{ m_xm = bb.m_xm; cout << "调用了CBoy(const CBoy &bb)拷贝构造函数。\n"; }
};
class CGirl // 超女类CGirl。
{
public:
string m_name; // 姓名属性。
const int m_age; // 年龄属性。
CBoy& m_boy; // 男朋友的信息。
//CGirl() // 没有参数的普通构造函数,默认构造函数。
//{
// cout << "调用了CGirl()构造函数。\n";
//}
//CGirl(string name, int age,CBoy &boy) // 三个参数的普通构造函数。
//{
// m_name = name; m_age = age; m_boy.m_xm = boy.m_xm;
// cout << "调用了CGirl(name,age,boy)构造函数。\n";
//}
CGirl(string name, int age, CBoy& boy) :m_name(name), m_age(age),m_boy(boy) // 三个参数的普通构造函数。
{
cout << "调用了CGirl(name,age,boy)构造函数。\n";
}
// 超女自我介绍的方法,显示姓名、年龄、男朋友。
void show() { cout << "姓名:" << m_name << ",年龄:" << m_age << ",男朋友:" << m_boy.m_xm << endl; }
};
int main()
{
CBoy boy("子都");
CGirl g1("冰冰",18,boy);
g1.show();
}
六、const修饰成员函数
- 在类的成员函数后面加const关键字,表示在成员函数中保证不会修改调用对象的成员变量。
注意:
-
mutable可以突破const的限制,被mutable修饰的成员变量,将永远处于可变的状态,在const修饰的函数中,mutable成员也可以被修改。
-
非const成员函数可以调用const成员函数和非const成员函数。
-
const成员函数不能调用非const成员函数。
-
非const对象可以调用const修饰的成员函数和非const修饰的成员函数。
-
const对象只能调用const修饰的成员函数,不能调用非cosnt修饰的成员函数。
这里出现了令人纠结的三个问题:
1、为什么要保护类的成员变量不被修改?
2、为什么用const保护了成员变量,还要再定义一个mutable关键字来突破const的封锁线?
3、到底有没有必要使用const和mutable这两个关键字?
- 保护类的成员变量不在成员函数中被修改,是为了保证模型的逻辑正确,通过用const关键字来避免在函数中错误的修改了类对象的状态。并且在所有使用该成员函数的地方都可以更准确的预测到使用该成员函数的带来的影响。而mutable则是为了能突破const的封锁线,让类的一些次要的或者是辅助性的成员变量随时可以被更改。没有使用const和mutable关键字当然没有错,const和mutable 关键字只是给了建模工具更多的设计约束和设计灵活性,而且程序员也可以把更多的逻辑检查问题交给编译器和建模工具去做,从而减轻程序员的负担。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
public:
mutable string m_name; // 姓名属性。
int m_age; // 年龄属性。
// 两个参数的普通构造函数。
CGirl(const string &name, int age)
{ m_name = name; m_age = age; cout << "调用了CGirl(name,age)构造函数。\n"; }
// 超女自我介绍的方法,显示姓名、年龄。
void show1() const
{
m_name="西施show1";
cout << "姓名:" << m_name << ",年龄:" << m_age << endl;
}
void show2() const
{
m_name = "西施show2";
cout << "姓名:" << m_name << ",年龄:" << m_age << endl;
}
void show3()
{
m_name = "西施show3";
cout << "姓名:" << m_name << ",年龄:" << m_age << endl;
}
void show4()
{
m_name = "西施show4";
cout << "姓名:" << m_name << ",年龄:" << m_age << endl;
}
};
int main()
{
const CGirl g1("冰冰",18);
g1.show1();
}
六点五、this指针
-
如果类的成员函数中涉及多个对象,在这种情况下需要使用this指针。
-
this指针存放了对象的地址,它被作为隐藏参数传递给了成员函数,指向调用成员函数的对象(调用者对象)。
-
每个成员函数(包括构造函数和析构函数)都有一个this指针,可以用它访问调用者对象的成员。(可以解决成员变量名与函数形参名相同的问题)
*this可以表示对象
如果在成员函数的括号后面使用const,那么将不能通过this指针修改成员变量。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
public:
string m_name; // 姓名属性。
int m_yz; // 颜值:1-沉鱼落雁;2-漂亮;3-一般;4-歪瓜裂枣。
// 两个参数的普通构造函数。
CGirl(const string &name, int yz) { m_name = name; m_yz = yz; }
// 超女自我介绍的方法。
void show() const { cout << "我是:" << m_name << ",最漂亮的超女。"<< endl; }
// 超女颜值pk的方法。
const CGirl& pk(const CGirl& g) const
{
if (g.m_yz < m_yz) return g;
return *this;
}
};
int main()
{
// 比较五个超女的颜值,然后由更漂亮的超女作自我介绍。
CGirl g1("西施",5), g2("西瓜",3), g3("冰冰", 4), g4("幂幂", 5), g5("金莲", 2);
const CGirl& g = g1.pk(g2).pk(g3).pk(g4).pk(g5);
g.show();
}
七、静态成员
-
类的静态成员包括静态成员变量和静态成员函数。
-
用静态成员可以变量实现多个对象之间的数据共享,比全局变量更安全性。
-
用 static 关键字把类的成员变量声明为静态,表示它在程序中(不仅是对象)是共享的。
-
静态成员变量不会在创建对象的时候初始化,必须在程序的全局区用代码清晰的初始化(用范围解析运算符 ::)。
-
静态成员使用类名加范围解析运算符 :: 就可以访问,不需要创建对象。
-
如果把类的成员声明为静态的,就可以把它与类的对象独立开来(静态成员不属于对象)。
-
静态成员变量在程序中只有一份(生命周期与程序运行期相同,存放在静态存储区的),不论是否创建了类的对象,也不论创建了多少个类的对象。
-
在静态成员函数中,只能访问静态成员,不能访问非静态成员。
-
静态成员函数中没有this指针。
-
在非静态成员函数中,可以访问静态成员。
-
私有静态成员在类外无法访问。
-
const静态成员变量可以在定义类的时候初始化。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
static int m_age; // 年龄属性。
public:
string m_name; // 姓名属性。
// 两个参数的普通构造函数。
CGirl(const string& name, int age) { m_name = name; m_age = age; }
// 显示超女的姓名。
void showname() { cout << "姓名:" << m_name << endl; }
// 显示超女的年龄。
static void showage() { cout << "年龄:" << m_age << endl; }
};
int CGirl::m_age=8; // 初始化类的静态成员变量。
int main()
{
CGirl g1("西施1", 21), g2("西施2", 22), g3("西施3", 23);
g1.showname(); g1.showage();
g2.showname(); g2.showage();
g3.showname(); g3.showage();
CGirl::showage();
// cout << "CGirl::m_age=" << CGirl::m_age << endl;
}
八、简单对象模型
-
在C语言中,数据和处理数据的操作(函数)是分开的。也就是说,C语言本身没有支持数据和函数之间的关联性。
-
C++用类描述抽象数据类型(abstract data type,ADT),在类中定义了数据和函数,把数据和函数关联起来。
-
对象中维护了多个指针表,表中放了成员与地址的对应关系。
class CGirl // 超女类CGirl。
{
public:
char m_name[10]; // 姓名属性。
int m_age; // 年龄属性。
// 默认构造函数和析构函数。
CGirl() { memset(m_name, 0, sizeof(m_name)); m_age = 0; }
~CGirl() { }
// 显示超女的姓名。
void showname() { cout << "姓名:" << m_name << endl; }
// 显示超女的年龄。
void showage() { cout << "年龄:" << m_age << endl; }
};
C++类中有两种数据成员:nonstatic、static,三种函数成员:nonstatic、static、virtual。
- 对象内存的大小包括:
- 所有非静态数据成员的大小;
- 由内存对齐而填补的内存大小;
- 为了支持virtual成员而产生的额外负担。
- 静态成员变量属于类,不计算在对象的大小之内。
- 成员函数是分开存储的,不论对象是否存在都占用存储空间,在内存中只有一个副本,也不计算在对象大小之内。
- 用空指针可以调用没有用到this指针的非静态成员函数。
- 对象的地址是第一个非静态成员变量的地址,如果类中没有非静态成员变量,编译器会隐含的增加一个1字节的占位成员。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
public:
char m_name[3]; // 姓名属性。
int m_bh; // 编号属性。
static int m_age; // 年龄属性。
// 默认构造函数和析构函数。
CGirl() { memset(m_name, 0, sizeof(m_name)); m_age = 0; }
~CGirl() { }
// 显示超女的姓名。
void showname() { if (this == nullptr) return; cout << "姓名:" << this->m_name << endl; }
// 显示超女的年龄。
void showage() { cout << "年龄:" << m_age << endl; }
};
int CGirl::m_age;
int aaa;
void func() {}
int main()
{
CGirl g;
cout << "对象g占用的内存大小是:" << sizeof(g) << endl;
cout << "对象g的地址是:" << (void*)&g << endl;
cout << "成员变量m_bh的地址是:" << (void*)&g.m_bh << endl;
cout << "成员变量m_name的地址是:" << (void*)&g.m_name << endl;
cout << "成员变量m_age的地址是:" << (void *)&g.m_age << endl;
cout << "全局变量aaa的地址是:" << (void*)&aaa << endl;
printf("成员函数showname的地址是:%p\n", &CGirl::showname);
printf("成员函数showage的地址是:%p\n", &CGirl::showage);
printf("函数func()的地址是:%p\n", func);
CGirl* g1 = nullptr;
g1->showname();
}
九、友元
-
如果要访问类的私有成员变量,调用类的公有成员函数是唯一的办法,而类的私有成员函数则无法访问。
-
友元提供了另一访问类的私有成员的方案。友元有三种:
-
友元全局函数。
-
友元类。
-
友元成员函数。
友元全局函数 -
在友元全局函数中,可以访问另一个类的所有成员。
友元类
- 在友元类所有成员函数中,都可以访问另一个类的所有成员。
友元类的注意事项:
- 友元关系不能被继承。
- 友元关系是单向的,不具备交换性。
- 若类B是类A的友元,类A不一定是类B的友元。B是类A的友元,类C是B的友元,类C不一定是类A的友元,要看类中是否有相应的声明。
友元成员函数
-
在友元成员函数中,可以访问另一个类的所有成员。
-
如果要把男朋友类CBoy的某成员函数声明为超女类CGirl的友元,声明和定义的顺序如下:
class CGirl; // 前置声明。
class CBoy { ...... }; // CBoy的定义。
class CGirl { ...... }; // CGirl的定义。
// 友元成员函数的定义。
void CBoy::func(CGirl &g) { ...... }
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
friend int main();
friend void func();
public:
string m_name; // 姓名。
// 默认构造函数。
CGirl() { m_name = "西施"; m_xw = 87; }
// 显示姓名的成员函数。
void showname() { cout << "姓名:" << m_name << endl; }
private:
int m_xw; // 胸围。
// 显示胸围的成员函数。
void showxw() { cout << "胸围:" << m_xw << endl; }
};
void func()
{
CGirl g;
g.showname();
g.showxw();
}
int main()
{
func();
}
///////////////////////////////////////////////////////////////////////////////////////
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
friend class CBoy;
public:
string m_name; // 姓名。
// 默认构造函数。
CGirl() { m_name = "西施"; m_xw = 87; }
// 显示姓名的成员函数。
void showname() { cout << "姓名:" << m_name << endl; }
private:
int m_xw; // 胸围。
// 显示胸围的成员函数。
void showxw() const { cout << "胸围:" << m_xw << endl; }
};
class CBoy // 超女的男朋友类
{
public:
void func(const CGirl& g)
{
cout << "我女朋友的姓名是:" << g.m_name << endl;
cout << "我女朋友的胸围是:" << g.m_xw << endl;
g.showxw();
}
};
int main()
{
CGirl g;
CBoy b;
b.func(g);
}
///////////////////////////////////////////////////////////////////////////////////////
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl; // 把超女类的声明前置
class CBoy // 超女的男朋友类
{
public:
void func1(const CGirl& g);
void func2(const CGirl& g);
};
class CGirl // 超女类CGirl。
{
friend void CBoy::func1(const CGirl& g);
// friend void CBoy::func2(const CGirl& g);
public:
string m_name; // 姓名。
// 默认构造函数。
CGirl() { m_name = "西施"; m_xw = 87; }
// 显示姓名的成员函数。
void showname() { cout << "姓名:" << m_name << endl; }
private:
int m_xw; // 胸围。
// 显示胸围的成员函数。
void showxw() const { cout << "胸围:" << m_xw << endl; }
};
void CBoy::func1(const CGirl& g) { cout << "func1()我女朋友的胸围是:" << g.m_xw << endl; }
void CBoy::func2(const CGirl& g) { cout << "func2()我女朋友的姓名是:" << g.m_name << endl; }
int main()
{
CGirl g;
CBoy b;
b.func2(g);
b.func1(g);
}
十、运算符重载基础
-
C++将运算符重载扩展到自定义的数据类型,它可以让对象操作更美观。
-
例如字符串string用加号(+)拼接、cout用两个左尖括号(<<)输出。
-
运算符重载函数的语法:返回值 operator运算符(参数列表);
-
运算符重载函数的返回值类型要与运算符本身的含义一致。
-
非成员函数版本的重载运算符函数:形参个数与运算符的操作数个数相同;
-
成员函数版本的重载运算符函数:形参个数比运算符的操作数个数少一个,其中的一个操作数隐式传递了调用对象。
-
如果同时重载了非成员函数和成员函数版本,会出现二义性。
注意:
-
返回自定义数据类型的引用可以让多个运算符表达式串联起来。(不要返回局部变量的引用)
-
重载函数参数列表中的顺序决定了操作数的位置。
-
重载函数的参数列表中至少有一个是用户自定义的类型,防止程序员为内置数据类型重载运算符。
-
如果运算符重载既可以是成员函数也可以是全局函数,应该优先考虑成员函数,这样更符合运算符重载的初衷。
-
重载函数不能违背运算符原来的含义和优先级。
-
不能创建新的运算符。
以下运算符不可重载:
-
sizeof sizeof运算符
-
. 成员运算符
-
.* 成员指针运算符
-
:: 作用域解析运算符
-
?: 条件运算符
-
typeid 一个RTTI运算符
-
const_cast 强制类型转换运算符
-
dynamic_cast 强制类型转换运算符
-
reinterpret_cast 强制类型转换运算符
-
static_cast 强制类型转换运算符
以下运算符只能通过成员函数进行重载: -
= 赋值运算符
-
() 函数调用运算符
-
[] 下标运算符
-
-> 通过指针访问类成员的运算符
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
friend CGirl &operator+(CGirl& g, int score);
friend CGirl& operator+(int score, CGirl& g);
friend CGirl& operator+(CGirl& g1, CGirl& g2);
private:
int m_xw; // 胸围。
int m_score; // 分数。
public:
string m_name; // 姓名。
// 默认构造函数。
CGirl() { m_name = "西施"; m_xw = 87; m_score = 30; }
// 自我介绍的方法。
void show() { cout << "姓名:" << m_name << ",胸围:" << m_xw << ",评分:" << m_score << endl; }
//CGirl& operator-(int score) // 给超女减分的函数。
//{
// m_score = m_score - score;
// return *this;
//}
};
CGirl& operator+(CGirl& g, int score) // 给超女加分的函数。
{
g.m_score = g.m_score + score;
return g;
}
CGirl& operator+(int score,CGirl& g) // 给超女加分的函数。
{
g.m_score = g.m_score + score;
return g;
}
CGirl& operator+(CGirl& g1, CGirl& g2) // 给超女加分的函数。
{
g1.m_score = g1.m_score + g2.m_score;
return g1;
}
int main()
{
// 导演的要求:每轮表演之后,给超女加上她的得分。
CGirl g;
g = g+g;
g.show();
}
第十一、重载关系运算符
-
重载关系运算符(==、!=、>、>=、<、<=)用于比较两个自定义数据类型的大小。
-
可以使用非成员函数和成员函数两种版本,建议采用成员函数版本。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
string m_name; // 姓名。
int m_yz; // 颜值:1-千年美人;2-百年美人;3-绝代美人;4-极漂亮;5-漂亮;6-一般;7-歪瓜裂枣。
int m_sc; // 身材:1-火辣;2-...;3-...;4-...;5-...;6-...;7-膘肥体壮。
int m_acting; // 演技:1-完美;2-...;3-...;4-...;5-...;6-...;7-四不像。
public:
// 四个参数的构造函数。
CGirl(string name, int yz, int sc, int acting) { m_name = name; m_yz = yz; m_sc = sc; m_acting = acting; }
// 比较两个超女的商业价值。
bool operator==(const CGirl& g1) // 相等==
{
if ((m_yz + m_sc + m_acting) == (g1.m_yz + g1.m_sc + g1.m_acting)) return true;
return false;
}
bool operator>(const CGirl& g1) // 大于>
{
if ((m_yz + m_sc + m_acting) < (g1.m_yz + g1.m_sc + g1.m_acting)) return true;
return false;
}
bool operator<(const CGirl& g1) // 小于<
{
if ((m_yz + m_sc + m_acting) > (g1.m_yz + g1.m_sc + g1.m_acting)) return true;
return false;
}
};
int main()
{
CGirl g1("西施", 1, 2, 2), g2("冰冰", 1, 1, 1);
if (g1==g2)
cout << "西施和冰冰的商业价值相同。\n";
else
if (g1>g2)
cout << "西施商业价值相同比冰冰大。\n";
else
cout << "冰冰商业价值相同比西施大。\n";
}
十二、重载左移运算符
-
重载左移运算符(<<)用于输出自定义对象的成员变量,在实际开发中很有价值(调试和日志)。
-
只能使用非成员函数版本。
-
如果要输出对象的私有成员,可以配合友元一起使用。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
friend ostream& operator<<(ostream& cout, const CGirl& g);
string m_name; // 姓名。
int m_xw; // 胸围。
int m_score; // 评分。
public:
// 默认构造函数。
CGirl() { m_name = "西施"; m_xw = 87; m_score = 30; }
// 自我介绍的方法。
void show() { cout << "姓名:" << m_name << ",胸围:" << m_xw << ",评分:" << m_score << endl; }
};
ostream& operator<<(ostream& cout, const CGirl& g)
{
cout << "姓名:" << g.m_name << ",胸围:" << g.m_xw << ",评分:" << g.m_score;
return cout;
}
int main()
{
CGirl g;
cout << g << endl;
}
十三、重载下标运算符
-
如果对象中有数组,重载下标运算符[],操作对象中的数组将像操作普通数组一样方便。
-
下标运算符必须以成员函数的形式进行重载。
下标运算符重载函数的语法:
-
或者:
-
使用第一种声明方式,[]不仅可以访问数组元素,还可以修改数组元素。
-
使用第二种声明方式,[]只能访问而不能修改数组元素。
-
在实际开发中,我们应该同时提供以上两种形式,这样做是为了适应const对象,因为通过const 对象只能调用const成员函数,如果不提供第二种形式,那么将无法访问const对象的任何数组元素。
-
在重载函数中,可以对下标做合法性检查,防止数组越界。
例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
private:
string m_boys[3]; // 超女的男朋友
public:
string m_name; // 姓名。
// 默认构造函数。
CGirl() { m_boys[0] = "子都"; m_boys[1] = "潘安"; m_boys[2] = "宋玉"; }
// 显示全部男朋友的姓名。
void show() { cout << m_boys[0] << "、" << m_boys[1] << "、" << m_boys[2] << endl; }
string& operator[](int ii)
{
return m_boys[ii];
}
const string& operator[](int ii) const
{
return m_boys[ii];
}
};
int main()
{
CGirl g; // 创建超女对象。
g[1] = "王麻子";
cout << "第1任男朋友:" << g[1] << endl;
g.show();
const CGirl g1 = g;
cout << "第1任男朋友:" << g1[1] << endl;
}
十四、重载赋值运算符
C++编译器可能会给类添加四个函数:
-
默认构造函数,空实现。
-
默认析构函数,空实现。
-
默认拷贝构造函数,对成员变量进行浅拷贝。
-
默认赋值函数, 对成员变量进行浅拷贝。
-
对象的赋值运算是用一个已经存在的对象,给另一个已经存在的对象赋值。
-
如果类的定义中没有重载赋值函数,编译器就会提供一个默认赋值函数。
-
如果类中重载了赋值函数,编译器将不提供默认赋值函数。
-
重载赋值函数的语法:类名 & operator=(const 类名 & 源对象);
注意:
- 编译器提供的默认赋值函数,是浅拷贝。
- 如果对象中不存在堆区内存空间,默认赋值函数可以满足需求,否则需要深拷贝。
- 赋值运算和拷贝构造不同:拷贝构造是指原来的对象不存在,用已存在的对象进行构造;赋值运算是指已经存在了两个对象,把其中一个对象的成员变量的值赋给另一个对象的成员变量。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
public:
int m_bh; // 编号。
string m_name; // 姓名。
int* m_ptr; // 计划使用堆区内存。
CGirl() { m_ptr = nullptr; }
~CGirl() { if (m_ptr) delete m_ptr; }
// 显示全部成员变量。
void show() { cout << "编号:" << m_bh << ",姓名:" << m_name << ",m_ptr=" << m_ptr <</* ",*m_ptr=" << *m_ptr<< */endl; }
CGirl& operator=(const CGirl& g)
{
if (this == &g) return *this; // 如果是自己给自己赋值。
if (g.m_ptr == nullptr) // 如果源对象的指针为空,则清空目标对象的内存和指针。
{
if (m_ptr != nullptr) { delete m_ptr; m_ptr = nullptr; }
}
else // 如果源对象的指针不为空。
{
// 如果目标对象的指针为空,先分配内存。
if (m_ptr == nullptr) m_ptr = new int;
// 然后,把源对象内存中的数据复制到目标对象的内存中。
memcpy(m_ptr, g.m_ptr, sizeof(int));
}
m_bh = g.m_bh; m_name = g.m_name;
cout << "调用了重载赋值函数。\n" << endl;
return *this;
}
};
int main()
{
CGirl g1, g2; // 创建超女对象。
g1.m_bh = 8; g1.m_name = "西施"; g1.m_ptr = new int(3);
g1.show();
g2.show();
g2 = g1;
g2.show();
cout << "*g1.m_ptr=" << *g1.m_ptr << ",*g2.m_ptr=" << *g2.m_ptr << endl;
}
十五、重载new&delete运算符
-
重载new和delete运算符的目是为了自定义内存分配的细节。(内存池:快速分配和归还,无碎片)
-
建议先学习C语言的内存管理函数malloc()和free()。
在C++中,使用new时,编译器做了两件事情:
-
调用标准库函数operator new()分配内存;
-
调用构造函数初始化内存;
使用delete时,也做了两件事情:
-
调用析构函数;
-
调用标准库函数operator delete()释放内存。
-
构造函数和析构函数由编译器调用,我们无法控制。
-
但是,可以重载内存分配函数operator new()和释放函数operator delete()。
重载内存分配函数的语法:void* operator new(size_t size);
-
参数必须是size_t,返回值必须是void*。
-
重载内存释放函数的语法:void operator delete(void* ptr)
-
参数必须是void *(指向由operator new()分配的内存),返回值必须是void。
-
重载的new和delete可以是全局函数,也可以是类的成员函数。
-
为一个类重载new和delete时,尽管不必显式地使用static,但实际上仍在创建static成员函数。
-
编译器看到使用new创建自定义的类的对象时,它选择成员版本的operator new()而不是全局版本的new()。
-
new[]和delete[]也可以重载。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
void* operator new(size_t size) // 参数必须是size_t(unsigned long long),返回值必须是void*。
{
cout << "调用了全局重载的new:" << size << "字节。\n";
void* ptr = malloc(size); // 申请内存。
cout << "申请到的内存的地址是:" << ptr << endl;
return ptr;
}
void operator delete(void* ptr) // 参数必须是void *,返回值必须是void。
{
cout << "调用了全局重载的delete。\n";
if (ptr == 0) return; // 对空指针delete是安全的。
free(ptr); // 释放内存。
}
class CGirl // 超女类CGirl。
{
public:
int m_bh; // 编号。
int m_xw; // 胸围。
CGirl(int bh, int xw) { m_bh = bh, m_xw = xw; cout << "调用了构造函数CGirl()\n"; }
~CGirl() { cout << "调用了析构函数~CGirl()\n"; }
void* operator new(size_t size) // 参数必须是size_t(unsigned long long),返回值必须是void*。
{
cout << "调用了类的重载的new:" << size << "字节。\n";
void* ptr = malloc(size); // 申请内存。
cout << "申请到的内存的地址是:" << ptr << endl;
return ptr;
}
void operator delete(void* ptr) // 参数必须是void *,返回值必须是void。
{
cout << "调用了类的重载的delete。\n";
if (ptr == 0) return; // 对空指针delete是安全的。
free(ptr); // 释放内存。
}
};
int main()
{
int* p1 = new int(3);
cout << "p1=" << (void *)p1 <<",*p1=" <<*p1<< endl;
delete p1;
CGirl* p2 = new CGirl(3, 8);
cout << "p2的地址是:" << p2 << "编号:" << p2->m_bh << ",胸围:" << p2->m_xw << endl;
delete p2;
}
内存池示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
public:
int m_bh; // 编号。
int m_xw; // 胸围。
static char* m_pool; // 内存池的起始地址。
static bool initpool() // 个初始化内存池的函数。
{
m_pool = (char*)malloc(18); // 向系统申请18字节的内存。
if (m_pool == 0) return false; // 如果申请内存失败,返回false。
memset(m_pool, 0, 18); // 把内存池中的内容初始化为0。
cout << "内存池的起始地址是:" << (void*)m_pool << endl;
return true;
}
static void freepool() // 释放内存池。
{
if (m_pool == 0) return; // 如果内存池为空,不需要释放,直接返回。
free(m_pool); // 把内存池归还给系统。
cout << "内存池已释放。\n";
}
CGirl(int bh, int xw) { m_bh = bh, m_xw = xw; cout << "调用了构造函数CGirl()\n"; }
~CGirl() { cout << "调用了析构函数~CGirl()\n"; }
void* operator new(size_t size) // 参数必须是size_t(unsigned long long),返回值必须是void*。
{
if (m_pool[0] == 0) // 判断第一个位置是否空闲。
{
cout << "分配了第一块内存:" << (void*)(m_pool + 1) << endl;
m_pool[0] = 1; // 把第一个位置标记为已分配。
return m_pool + 1; // 返回第一个用于存放对象的址。
}
if (m_pool[9] == 0) // 判断第二个位置是否空闲。
{
cout << "分配了第二块内存:" << (void*)(m_pool + 9) << endl;
m_pool[9] = 1; // 把第二个位置标记为已分配。
return m_pool + 9; // 返回第二个用于存放对象的址。
}
// 如果以上两个位置都不可用,那就直接系统申请内存。
void* ptr = malloc(size); // 申请内存。
cout << "申请到的内存的地址是:" << ptr << endl;
return ptr;
}
void operator delete(void* ptr) // 参数必须是void *,返回值必须是void。
{
if (ptr == 0) return; // 如果传进来的地址为空,直接返回。
if (ptr == m_pool + 1) // 如果传进来的地址是内存池的第一个位置。
{
cout << "释放了第一块内存。\n";
m_pool[0] = 0; // 把第一个位置标记为空闲。
return;
}
if (ptr == m_pool + 9) // 如果传进来的地址是内存池的第二个位置。
{
cout << "释放了第二块内存。\n";
m_pool[9] = 0; // 把第二个位置标记为空闲。
return;
}
// 如果传进来的地址不属于内存池,把它归还给系统。
free(ptr); // 释放内存。
}
};
char* CGirl::m_pool = 0; // 初始化内存池的指针。
int main()
{
// 初始化内存池。
if (CGirl::initpool()==false) { cout << "初始化内存池失败。\n"; return -1; }
CGirl* p1 = new CGirl(3, 8); // 将使用内存池的第一个位置。
cout << "p1的地址是:" << p1 << ",编号:" << p1->m_bh << ",胸围:" << p1->m_xw << endl;
CGirl* p2 = new CGirl(4, 7); // 将使用内存池的第二个位置。
cout << "p2的地址是:" << p2 << ",编号:" << p2->m_bh << ",胸围:" << p2->m_xw << endl;
CGirl* p3 = new CGirl(6, 9); // 将使用系统的内存。
cout << "p3的地址是:" << p3 << ",编号:" << p3->m_bh << ",胸围:" << p3->m_xw << endl;
delete p1; // 将释放内存池的第一个位置。
CGirl* p4 = new CGirl(5, 3); // 将使用内存池的第一个位置。
cout << "p4的地址是:" << p4 << ",编号:" << p4->m_bh << ",胸围:" << p4->m_xw << endl;
delete p2; // 将释放内存池的第二个位置。
delete p3; // 将释放系统的内存。
delete p4; // 将释放内存池的第一个位置。
CGirl::freepool(); // 释放内存池。
}
十六、重载括号运算符
- 括号运算符()也可以重载,对象名可以当成函数来使用(函数对象、仿函数)。
括号运算符重载函数的语法:
返回值类型 operator()(参数列表);
注意:
- 括号运算符必须以成员函数的形式进行重载。
- 括号运算符重载函数具备普通函数全部的特征。
- 如果函数对象与全局函数同名,按作用域规则选择调用的函数。
- 函数对象的用途:
-
表面像函数,部分场景中可以代替函数,在STL中得到广泛的应用;
-
函数对象本质是类,可以用成员变量存放更多的信息;
-
函数对象有自己的数据类型;
-
可以提供继承体系。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
void show(string str) // 向超女表白的函数。
{
cout << "普通函数:" << str << endl;
}
class CGirl // 超女类。
{
public:
void operator()(string str) // 向超女表白的函数。
{
cout << "重载函数:" << str << endl;
}
};
int main()
{
CGirl show;
::show("我是一只傻傻鸟。");
show("我是一只傻傻鸟。");
}
十七、重载一元运算符
可重载的一元运算符。
1)++ 自增 2)-- 自减 3)! 逻辑非 4)& 取地址
5)~ 二进制反码 6)* 解引用 7)+ 一元加 8) - 一元求反
一元运算符通常出现在它们所操作的对象的左边。
但是,自增运算符++和自减运算符--有前置和后置之分。
-
C++ 规定,重载++或--时,如果重载函数有一个int形参,编译器处理后置表达式时将调用这个重载函数。
-
成员函数版:CGirl &operator++(); // ++前置
-
成员函数版:CGirl operator++(int); // 后置++
-
非成员函数版:CGirl &operator++(CGirl &); // ++前置
-
非成员函数版:CGirl operator++(CGirl &,int); // 后置++
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
public:
string m_name; // 姓名。
int m_ranking; // 排名。
// 默认构造函数。
CGirl() { m_name = "西施"; m_ranking = 5; }
// 自我介绍的方法。
void show() const { cout << "姓名:" << m_name << ",排名:" << m_ranking << endl; }
CGirl & operator++() // ++前置的重载函数。
{
m_ranking++; return *this;
}
CGirl operator++(int) // ++后置的重载函数。
{
CGirl tmp = *this;
m_ranking++;
return tmp;
}
};
int main()
{
CGirl g1,g2; // 创建超女对象。
int ii=5 , jj=5;
int xx = ++(++(++ii)); cout << "xx=" << xx << ",ii=" << ii << endl;
int yy = jj++; cout << "yy=" << yy << ",jj=" << jj << endl;
CGirl g3 = ++(++(++g1)); cout << "g3.m_ranking=" << g3.m_ranking << ",g1.m_ranking=" << g1.m_ranking << endl;
CGirl g4 = g2++; cout << "g4.m_ranking=" << g4.m_ranking << ",g2.m_ranking=" << g2.m_ranking << endl;
// g2.show();
}
十八、自动类型转换
- 对于内置类型,如果两种数据类型是兼容的,C++可以自动转换,如果从更大的数转换为更小的数,可能会被截断或损失精度。
long count = 8; // int转换为long
double time = 11; // int转换为double
int side = 3.33 // double转换为int的3
C++不自动转换不兼容的类型,下面语句是非法的:
int* ptr = 8;
不能自动转换时,可以使用强制类型转换:
int* p = (int*)8;
如果某种类型与类相关,从某种类型转换为类类型是有意义的。
string str = "我是一只傻傻鸟。";
在C++中,将一个参数的构造函数用作自动类型转换函数,它是自动进行的,不需要显式的转换。
CGirl g1(8); // 常规的写法。
CGirl g1 = CGirl(8); // 显式转换。
CGirl g1 = 8; // 隐式转换。
CGirl g1; // 创建对象。
g1 = 8; // 隐式转换,用CGirl(8)创建临时对象,再赋值给g。
注意:
-
一个类可以有多个转换函数。
-
多个参数的构造函数,除第一个参数外,如果其它参数都有缺省值,也可以作为转换函数。
-
CGirl(int)的隐式转换的场景:
- 将CGirl对象初始化为int值时。 CGirl g1 = 8;
- 将int值赋给CGirl对象时。 CGirl g1; g1 = 8;
- 将int值传递给接受CGirl参数的函数时。
- 返回值被声明为CGirl的函数试图返回int值时。
- 在上述任意一种情况下,使用可转换为int类型的内置类型时。
- 如果自动类型转换有二义性,编译将报错。
-
将构造函数用作自动类型转换函数似乎是一项不错的特性,但有时候会导致意外的类型转换。explicit关键字用于关闭这种自动特性,但仍允许显式转换。
-
explicit CGirl(int bh);
-
CGirl g=8; // 错误。
-
CGirl g=CGirl(8); // 显式转换,可以。
-
CGirl g=(CGirl)8; // 显式转换,可以。
-
在实际开发中,如果强调的是构造,建议使用explicit,如果强调的是类型转换,则不使用explicit。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
public:
int m_bh; // 编号。
string m_name; // 姓名。
double m_weight; // 体重,单位:kg。
// 默认构造函数。
CGirl() { m_bh = 0; m_name.clear(); m_weight = 0; cout << "调用了CGirl()\n"; }
// 自我介绍的方法。
void show() { cout << "bh=" << m_bh << ",name=" << m_name << ",weight=" << m_weight << endl; }
explicit CGirl(int bh) { m_bh = bh; m_name.clear(); m_weight = 0; cout << "调用了CGirl(int bh)\n"; }
//CGirl(double weight) { m_bh = 0; m_name.clear(); m_weight = weight; cout << "调用了CGirl(double weight)\n"; }
};
int main()
{
//CGirl g1(8); // 常规的写法。
//CGirl g1 = CGirl(8); // 显式转换。
//CGirl g1 = 8; // 隐式转换。
CGirl g1; // 创建对象。
g1 = (CGirl)8; // 隐式转换,用CGirl(8)创建临时对象,再赋值给g。
//CGirl g1 = 8.7; // 隐式转换。
//g1.show();
}
十九、转换函数
- 构造函数只用于从某种类型到类类型的转换,如果要进行相反的转换,可以使用特殊的运算符函数-转换函数。
语法:operator 数据类型();
注意:转换函数必须是类的成员函数;不能指定返回值类型;不能有参数。
-
可以让编译器决定选择转换函数(隐式转换),可以像使用强制类型转换那样使用它们(显式转换)。
-
int ii=girl; // 隐式转换。
-
int ii=(int) girl; // 显式转换。
-
int ii=int(girl); // 显式转换。
-
如果隐式转换存在二义性,编译器将报错。
-
在C++98中,关键字explicit不能用于转换函数,但C++11消除了这种限制,可以将转换函数声明为显式的。
-
还有一种方法是:用一个功能相同的普通成员函数代替转换函数,普通成员函数只有被调用时才会执行。
-
int ii=girl.to_int();
-
警告:应谨慎的使用隐式转换函数。通常,最好选择仅在被显式地调用时才会执行的成员函数。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类CGirl。
{
public:
int m_bh; // 编号。
string m_name; // 姓名。
double m_weight; // 体重,单位:kg。
// 默认构造函数。
CGirl() { m_bh = 8; m_name="西施"; m_weight = 50.7; }
explicit operator int() { return m_bh; }
int to_int() { return m_bh; }
operator string() { return m_name; }
explicit operator double() { return m_weight; }
};
int main()
{
string name = "西施"; // char * 转换成 string
const char* ptr = name; // string 转换成 char *,错误
const char* ptr = name.c_str(); // 返回char *,正确
CGirl g;
int a = g.to_int(); cout << "a的值是:" << a << endl;
string b = string(g); cout << "b的值是:" << b << endl;
double c = double(g); cout << "c的值是:" << c << endl;
short d = (int)g;
}
二十、继承的基本概念
- 继承可以理解为一个类从另一个类获取成员变量和成员函数的过程。
语法:
-
class 派生类名:[继承方式]基类名
-
{
-
派生类新增加的成员
-
};
-
被继承的类称为基类或父类,继承的类称为派生类或子类。
-
继承和派生是一个概念,只是站的角度不同。
-
派生类除了拥有基类的成员,还可以定义新的成员,以增强其功能。
使用继承的场景:
-
如果新创建的类与现有的类相似,只是多出若干成员变量或成员函数时,可以使用继承。
-
当需要创建多个类时,如果它们拥有很多相似的成员变量或成员函数,可以将这些类共同的成员提取出来,定义为基类,然后从基类继承。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CAllComers // 海选报名者类
{
public:
string m_name; // 姓名
string m_tel; // 联系电话
// 构造函数。
CAllComers() { m_name = "某女"; m_tel = "不详"; }
// 报名时需要唱一首歌。
void sing() { cout << "我是一只小小鸟。\n"; }
// 设置姓名。
void setname(const string& name) { m_name = name; }
// 设置电话号码。
void settel(const string& tel) { m_tel = tel; }
};
class CGirl :public CAllComers // 超女类
{
public:
int m_bh; // 编号。
CGirl() { m_bh = 8; }
void show() { cout << "编号:" << m_bh << ",姓名:" << m_name << ",联系电话:" << m_tel << endl; }
};
int main()
{
CGirl g;
g.setname("西施");
g.show();
}
二十一、继承方式
-
类成员的访问权限由高到低依次为:public --> protected --> private,public成员在类外可以访问,private成员只能在类的成员函数中访问。
-
如果不考虑继承关系,protected成员和private成员一样,类外不能访问。但是,当存在继承关系时,protected和private就不一样了。基类中的protected成员可以在派生类中访问,而基类中的 private成员不能在派生类中访问。
-
继承方式有三种:public(公有的)、protected(受保护的)和private(私有的)。它是可选的,如果不写,那么默认为private。不同的继承方式决定了在派生类中成员函数中访问基类成员的权限。
-
基类成员在派生类中的访问权限不得高于继承方式中指定的权限。例如,当继承方式为protected时,那么基类成员在派生类中的访问权限最高也为protected,高于protected的会降级为protected,但低于protected不会升级。再如,当继承方式为public时,那么基类成员在派生类中的访问权限将保持不变。
-
也就是说,继承方式中的public、protected、private是用来指明基类成员在派生类中的最高访问权限的。
-
不管继承方式如何,基类中的private成员在派生类中始终不能使用(不能在派生类的成员函数中访问或调用)。
-
如果希望基类的成员能够被派生类继承并且毫无障碍地使用,那么这些成员只能声明为public 或protected;只有那些不希望在派生类中使用的成员才声明为private。
-
如果希望基类的成员既不向外暴露(不能通过对象访问),还能在派生类中使用,那么只能声明为 protected。
-
由于private和protected继承方式会改变基类成员在派生类中的访问权限,导致继承关系复杂,所以,在实际开发中,一般使用public。
-
在派生类中,可以通过基类的公有成员函数间接访问基类的私有成员。
-
使用 using 关键字可以改变基类成员在派生类中的访问权限。
- 注意:using只能改变基类中public和protected成员的访问权限,不能改变private成员的访问权限,因为基类中的private成员在派生类中是不可见的,根本不能使用。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class A { // 基类
public:
int m_a=10;
protected:
int m_b=20;
private:
int m_c = 30;
};
class B :public A // 派生类
{
public:
using A::m_b; // 把m_b的权限修改为公有的。
private:
using A::m_a; // 把m_a的权限修改为私有的。
};
int main()
{
B b;
// b.m_a = 11;
b.m_b = 21;
//b.m_c = 21;
}
二十二、继承的对象模型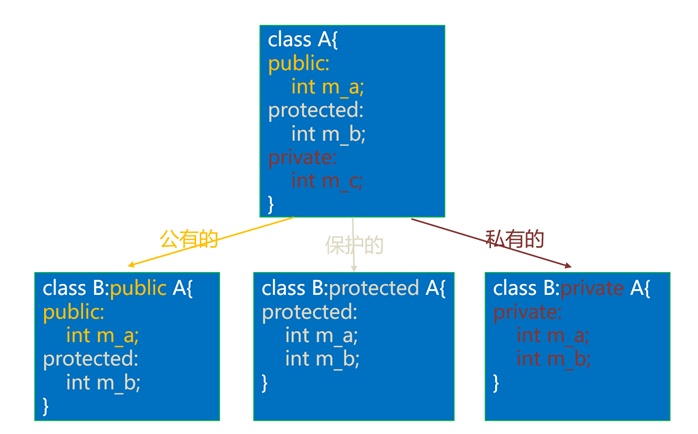
-
创建派生类对象时,先调用基类的构造函数,再调用派生类的构造函数。
-
销毁派生类对象时,先调用派生类的析构函数,再调用基类的析构函数。如果手工调用派生类的析构函数,也会调用基类的析构函数。
-
创建派生类对象时只会申请一次内存,派生类对象包含了基类对象的内存空间,this指针相同的。
-
创建派生类对象时,先初始化基类对象,再初始化派生类对象。
-
在VS中,用cl.exe可以查看类的内存模型。
-
对派生类对象用sizeof得到的是基类所有成员(包括私有成员)+派生类对象所有成员的大小。
-
在C++中,不同继承方式的访问权限只是语法上的处理。
-
对派生类对象用memset()会清空基类私有成员。
-
用指针可以访问到基类中的私有成员(内存对齐)。
查看对象内存布局的方法:
-
cl 源文件名 /d1 reportSingleClassLayout类名
-
注意:类名不要太短,否则屏幕会显示一大堆东西,找起来很麻烦。
-
例如,查看BBB类,源代码文件是demo01.cpp:
-
cl demo01.cpp /d1 reportSingleClassLayoutBBB
cl命令环境变量:
1)在PATH环境变量中增加cl.exe的目录
C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.30.30705\bin\Hostx64\x64
2)增加INCLUDE环境变量,内容如下:
C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.30.30705\include
C:\Program Files (x86)\Windows Kits\10\Include\10.0.19041.0\shared
C:\Program Files (x86)\Windows Kits\10\Include\10.0.19041.0\ucrt
C:\Program Files (x86)\Windows Kits\10\Include\10.0.19041.0\um
C:\Program Files (x86)\Windows Kits\10\Include\10.0.19041.0\winrt
3)增加LIB环境变量,内容如下:
C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.30.30705\lib\x64
C:\Program Files (x86)\Windows Kits\10\Lib\10.0.19041.0\um\x64
C:\Program Files (x86)\Windows Kits\10\Lib\10.0.19041.0\ucrt\x64
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
void* operator new(size_t size) // 重载new运算符。
{
void* ptr = malloc(size); // 申请内存。
cout << "申请到的内存的地址是:" << ptr << ",大小是:" << size << endl;
return ptr;
}
void operator delete(void* ptr) // 重载delete运算符。
{
if (ptr == 0) return; // 对空指针delete是安全的。
free(ptr); // 释放内存。
cout << "释放了内存。\n";
}
class A { // 基类
public:
int m_a = 10;
protected:
int m_b = 20;
private:
int m_c = 30;
public:
A() {
cout << "A中this指针是: " << this << endl;
cout << "A中m_a的地址是:" << &m_a << endl;
cout << "A中m_b的地址是:" << &m_b << endl;
cout << "A中m_c的地址是:" << &m_c << endl;
}
void func() { cout << "m_a=" << m_a << ",m_b=" << m_b << ",m_c=" << m_c << endl; }
};
class B :public A // 派生类
{
public:
int m_d = 40;
B() {
cout << "B中this指针是: " << this << endl;
cout << "B中m_a的地址是:" << &m_a << endl;
cout << "B中m_b的地址是:" << &m_b << endl;
//cout << "B中m_c的地址是:" << &m_c << endl;
cout << "B中m_d的地址是:" << &m_d << endl;
}
void func1() { cout << "m_d=" << m_d << endl; }
};
int main()
{
cout << "基类占用内存的大小是:" << sizeof(A) << endl;
cout << "派生类占用内存的大小是:" << sizeof(B) << endl;
B *p=new B;
p->func(); p->func1();
// memset(p, 0, sizeof(B));
*((int*)p + 2) = 31; // 把基类私有成员m_c的值修改成31。
p->func(); p->func1();
delete p;
}
二十三、如何构造基类
派生类构造函数的要点如下:
-
创建派生类对象时,程序首先调用基类构造函数,然后再调用派生类构造函数。
-
如果没以指定基类构造函数,将使用基类的默认构造函数。
-
可以用初始化列表指明要使用的基类构造函数。
-
基类构造函数负责初始化被继承的数据成员;派生类构造函数主要用于初始化新增的数据成员。
-
派生类的构造函数总是调用一个基类构造函数,包括拷贝构造函数。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class A { // 基类
public:
int m_a;
private:
int m_b;
public:
A() : m_a(0) , m_b(0) // 基类的默认构造函数。
{
cout << "调用了基类的默认构造函数A()。\n";
}
A(int a,int b) : m_a(a) , m_b(b) // 基类有两个参数的构造函数。
{
cout << "调用了基类的构造函数A(int a,int b)。\n";
}
A(const A &a) : m_a(a.m_a+1) , m_b(a.m_b+1) // 基类的拷贝构造函数。
{
cout << "调用了基类的拷贝构造函数A(const A &a)。\n";
}
// 显示基类A全部的成员。
void showA() { cout << "m_a=" << m_a << ",m_b=" << m_b << endl; }
};
class B :public A // 派生类
{
public:
int m_c;
B() : m_c(0) , A() // 派生类的默认构造函数,指明用基类的默认构造函数(不指明也无所谓)。
{
cout << "调用了派生类的默认构造函数B()。\n";
}
B(int a, int b, int c) : A(a, b), m_c(c) // 指明用基类的有两个参数的构造函数。
{
cout << "调用了派生类的构造函数B(int a,int b,int c)。\n";
}
B(const A& a, int c) :A(a), m_c(c) // 指明用基类的拷贝构造函数。
{
cout << "调用了派生类的构造函数B(const A &a,int c) 。\n";
}
// 显示派生类B全部的成员。
void showB() { cout << "m_c=" << m_c << endl << endl; }
};
int main()
{
B b1; // 将调用基类默认的构造函数。
b1.showA(); b1.showB();
B b2(1, 2, 3); // 将调用基类有两个参数的构造函数。
b2.showA(); b2.showB();
A a(10, 20); // 创建基类对象。
B b3(a, 30); // 将调用基类的拷贝造函数。
b3.showA(); b3.showB();
}
二十四、名字遮蔽与类作用域
- 如果派生类中的成员(包括成员变量和成员函数)和基类中的成员重名,通过派生类对象或者在派生类的成员函数中使用该成员时,将使用派生类新增的成员,而不是基类的。
注意:基类的成员函数和派生类的成员函数不会构成重载,如果派生类有同名函数,那么就会遮蔽基类中的所有同名函数。
-
类是一种作用域,每个类都有它自己的作用域,在这个作用域之内定义成员。
-
在类的作用域之外,普通的成员只能通过对象(可以是对象本身,也可以是对象指针或对象引用)来访问,静态成员可以通过对象访问,也可以通过类访问。
-
在成员名前面加类名和域解析符可以访问对象的成员。
-
如果不存在继承关系,类名和域解析符可以省略不写。
-
当存在继承关系时,基类的作用域嵌套在派生类的作用域中。如果成员在派生类的作用域中已经找到,就不会在基类作用域中继续查找;如果没有找到,则继续在基类作用域中查找。
-
如果在成员的前面加上类名和域解析符,就可以直接使用该作用域的成员。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class A { // 基类
public:
int m_a=10;
void func() { cout << "调用了A的func()函数。\n"; }
};
class B :public A { // 子类
public:
int m_a = 20;
void func() { cout << "调用了B的func()函数。\n"; }
};
class C :public B { // 孙类
public:
int m_a = 30;
void func() { cout << "调用了C的func()函数。\n"; }
void show() {
cout << "C::m_a的值是:" << C::m_a << endl;
cout << "B::m_a的值是:" << B::m_a << endl;
cout << "A::m_a的值是:" << B::A::m_a << endl;
}
};
int main()
{
C c;
cout << "C::m_a的值是:" << c.C::m_a << endl;
cout << "B::m_a的值是:" << c.B::m_a << endl;
cout << "A::m_a的值是:" << c.B::A::m_a << endl;
c.C::func();
c.B::func();
c.B::A::func();
}
二十五、继承的特殊关系
-
派生类和基类之间有一些特殊关系。
-
如果继承方式是公有的,派生类对象可以使用基类成员。
-
可以把派生类对象赋值给基类对象(包括私有成员),但是,会舍弃非基类的成员。
-
基类指针可以在不进行显式转换的情况下指向派生类对象。
-
基类引用可以在不进行显式转换的情况下引用派生类对象。
注意:
-
基类指针或引用只能调用基类的方法,不能调用派生类的方法。
-
可以用派生类构造基类。
-
如果函数的形参是基类,实参可以用派生类。
-
C++要求指针和引用类型与赋给的类型匹配,这一规则对继承来说是例外。但是,这种例外只是单向的,不可以将基类对象和地址赋给派生类引用和指针(没有价值,没有讨论的必要)。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class A { // 基类
public:
int m_a=0;
private:
int m_b=0;
public:
// 显示基类A全部的成员。
void show() { cout << "A::show() m_a=" << m_a << ",m_b=" << m_b << endl; }
// 设置成员m_b的值。
void setb(int b) { m_b = b; }
};
class B :public A // 派生类
{
public:
int m_c=0;
// 显示派生类B全部的成员。
void show() { cout << "B::show() m_a=" << m_a << "m_c=" << m_c << endl; }
};
int main()
{
B b;
A* a = &b;
b.m_a = 10;
b.setb(20); // 设置成员m_b的值。
b.m_c = 30;
b.show(); // 调用的是B类的show()函数。
a->m_a = 11;
a->setb(22); // 设置成员m_b的值。
// a->m_c = 30;
a->show(); // 调用的是A类的show()函数。
}
二十六、多继承与虚继承
多继承的语法:
-
class 派生类名 : [继承方式1] 基类名1, [继承方式2] 基类名2,......
-
{
-
派生类新增加的成员
-
};
菱形继承
-
虚继承可以解决菱形继承的二义性和数据冗余的问题。
-
有了多继承,就存在菱形继承,有了菱形继承就有虚继承,增加了复杂性。
-
不提倡使用多继承,只有在比较简单和不出现二义性的情况时才使用多继承,能用单一继承解决的问题就不要使用多继承。
-
如果继承的层次很多、关系很复杂,程序的编写、调试和维护工作都会变得更加困难,由于这个原因,C++之后的很多面向对象的编程语言,例如 Java、C#、PHP 等,都不支持多继承。
多继承示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class A1 { // 基类一
public:
int m_a = 10;
};
class A2 { // 基类二
public:
int m_a = 20;
};
class B :public A1, public A2 { // 派生类
public:
int m_a = 30;
};
int main()
{
B b;
cout << " B::m_a的值是:" << b.m_a << endl;
cout << "A1::m_a的值是:" << b.A1::m_a << endl;
cout << "A2::m_a的值是:" << b.A2::m_a << endl;
}
菱形继承示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class A {
public:
int m_a = 10;
};
class B : virtual public A { };
class C : virtual public A { };
class DD : public B, public C {};
int main()
{
DD d;
// d.B::m_a = 30;
// d.C::m_a = 80;
d.m_a = 80;
cout << "B::m_a的地址是:" << &d.B::m_a << ",值是:" << d.B::m_a << endl;
cout << "C::m_a的地址是:" << &d.C::m_a << ",值是:" << d.C::m_a << endl;
}
二十七、多态的基本概念
-
基类指针只能调用基类的成员函数,不能调用派生类的成员函数。
-
如果在基类的成员函数前加virtual 关键字,把它声明为虚函数,基类指针就可以调用派生类中同名的成员函数,通过派生类中同名的成员函数,就可以访问派生对象的成员变量。
-
有了虚函数,基类指针指向基类对象时就使用基类的成员函数和数据,指向派生类对象时就使用派生类的成员函数和数据,基类指针表现出了多种形式,这种现象称为多态。
-
基类引用也可以使用多态。
注意:
-
只需要在基类的函数声明中加上virtual关键字,函数定义时不能加。
-
在派生类中重定义虚函数时,函数特征要相同。
-
当在基类中定义了虚函数时,如果派生类没有重定义该函数,那么将使用基类的虚函数。
-
在派生类中重定义了虚函数的情况下,如果想使用基类的虚函数,可以加类名和域解析符。
-
如果要在派生类中重新定义基类的函数,则将它设置为虚函数;否则,不要设置为虚函数,有两方面的好处:首先效率更高;其次,指出不要重新定义该函数。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CAllComers { // 报名者类
public:
int m_bh = 0; // 编号。
virtual void show() { cout << "CAllComers::show():我是" << m_bh << "号。 " << endl; }
virtual void show(int a) { cout << "CAllComers::show(int a):我是" << m_bh << "号。 " << endl; }
};
class CGirl :public CAllComers { // 超女类
public:
int m_age = 0; // 年龄。
void show() { cout << "CGirl::show():我是" << m_bh << "号, " << m_age << "岁。" << endl; }
void show(int a) { cout << "CGirl::show(int a):我是" << m_bh << "号, " << m_age << "岁。" << endl; }
};
int main()
{
CAllComers a; a.m_bh = 3; // 创建基类对象并对成员赋值。
CGirl g; g.m_bh = 8; g.m_age = 23; // 创建派生类对象并对成员赋值。
CAllComers* p; // 声明基类指针。
//p = &a; p->show(); // 让基类指针指向基类对象,并调用虚函数。
p = &g; p->show(); // 让基类指针指向派生类对象,并调用虚函数。
p->show(5);
p->CAllComers::show(5);
}
二十八、多态的应用场景
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class Hero // 英雄基类
{
public:
int viability; // 生存能力。
int attack; // 攻击伤害。
virtual void skill1() { cout << "英雄释放了一技能。\n"; }
virtual void skill2() { cout << "英雄释放了二技能。\n"; }
virtual void uskill() { cout << "英雄释放了大绝招。\n"; }
};
class XS :public Hero // 西施派生类
{
public:
void skill1() { cout << "西施释放了一技能。\n"; }
void skill2() { cout << "西施释放了二技能。\n"; }
void uskill() { cout << "西施释放了大招。\n"; }
};
class HX :public Hero // 韩信派生类
{
public:
void skill1() { cout << "韩信释放了一技能。\n"; }
void skill2() { cout << "韩信释放了二技能。\n"; }
void uskill() { cout << "韩信释放了大招。\n"; }
};
class LB :public Hero // 李白派生类
{
public:
void skill1() { cout << "李白释放了一技能。\n"; }
void skill2() { cout << "李白释放了二技能。\n"; }
void uskill() { cout << "李白释放了大招。\n"; }
};
int main()
{
// 根据用户选择的英雄,施展一技能、二技能和大招。
int id = 0; // 英雄的id。
cout << "请输入英雄(1-西施;2-韩信;3-李白。):";
cin >> id;
// 创建基类指针,让它指向派生类对象,用基类指针调用派生类的成员函数。
Hero* ptr = nullptr;
if (id == 1) { // 1-西施
ptr=new XS;
}
else if (id == 2) { // 2-韩信
ptr = new HX;
}
else if (id == 3) { // 3-李白
ptr = new LB;
}
if (ptr != nullptr) {
ptr->skill1();
ptr->skill2();
ptr->uskill();
delete ptr;
}
}
二十九、多态的对象模型
-
类的普通成员函数的地址是静态的,在编译阶段已指定。
-
如果基类中有虚函数,对象的内存模型中有一个虚函数表,表中存放了基类的函数名和地址。
-
如果派生类中重定义了基类的虚函数,创建派生类对象时,将用派生类的函数取代虚函数表中基类的函数。
-
C++中的多态分为两种:静态多态与动态多态。
静态多态:也成为编译时的多态;在编译时期就已经确定要执行了的函数地址了;主要有函数重载和函数模板。
动态多态:即动态绑定,在运行时才去确定对象类型和正确选择需要调用的函数,一般用于解决基类指针或引用派生类对象调用类中重写的方法(函数)时出现的问题。
三十、如何析构派生类
-
构造函数不能继承,创建派生类对象时,先执行基类构造函数,再执行派生类构造函数。
-
析构函数不能继承,而销毁派生类对象时,先执行派生类析构函数,再执行基类析构函数。
-
派生类的析构函数在执行完后,会自动执行基类的析构函数。
-
如果手工的调用派生类的析构函数,也会自动调用基类的析构函数。
析构派生类的要点如下:
-
析构派生类对象时,会自动调用基类的析构函数。与构造函数不同的是,在派生类的析构函数中不用显式地调用基类的析构函数,因为每个类只有一个析构函数,编译器知道如何选择,无需程序员干涉。
-
析构函数可以手工调用,如果对象中有堆内存,析构函数中以下代码是必要的:
-
delete ptr;
-
ptr=nulllptr;
-
用基类指针指向派生类对象时,delete基类指针调用的是基类的析构函数,不是派生类的,如果希望调用派生类的析构函数,就要把基类的析构函数设置为虚函数。
-
C++编译器对虚析构函数做了特别的处理。
-
对于基类,即使它不需要析构函数,也应该提供一个空虚析构函数。
-
赋值运算符函数不能继承,派生类继承的函数的特征标与基类完全相同,但赋值运算符函数的特征标随类而异,它包含了一个类型为其所属类的形参。
-
友元函数不是类成员,不能继承。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class AA { // 基类
public:
AA() { cout << "调用了基类的构造函数AA()。\n"; }
virtual void func() { cout << "调用了基类的func()。\n"; }
// virtual ~AA() { cout << "调用了基类的析构函数~AA()。\n"; }
virtual ~AA() {}
};
class BB:public AA { // 派生类
public:
BB() { cout << "调用了派生类的构造函数BB()。\n"; }
void func() { cout << "调用了派生类的func()。\n"; }
~BB() { cout << "调用了派生类的析构函数~BB()。\n"; }
};
int main()
{
AA *a=new BB;
delete a;
}
三十一、纯虚函数和抽象类
-
纯虚函数是一种特殊的虚函数,在某些情况下,基类中不能对虚函数给出有意义的实现,把它声明为纯虚函数。
-
纯虚函数只有函数名、参数和返回值类型,没有函数体,具体实现留给该派生类去做。
语法:virtual 返回值类型 函数名 (参数列表)=0;
-
纯虚函数在基类中为派生类保留一个函数的名字,以便派生类它进行重定义。如果在基类中没有保留函数名字,则无法支持多态性。
-
含有纯虚函数的类被称为抽象类,不能实例化对象,可以创建指针和引用。
-
派生类必须重定义抽象类中的纯虚函数,否则也属于抽象类。
-
基类中的纯虚析构函数也需要实现。
-
有时候,想使一个类成为抽象类,但刚好又没有任何纯虚函数,怎么办?
-
方法很简单:在想要成为抽象类的类中声明一个纯虚析构函数。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class AA { // 基类
public:
AA() { cout << "调用了基类的构造函数AA()。\n"; }
virtual void func() = 0 { cout << "调用了基类的func()。\n"; }
virtual ~AA() = 0 { cout << "调用了基类的析构函数~AA()。\n"; }
};
class BB :public AA { // 派生类
public:
BB() { cout << "调用了派生类的构造函数BB()。\n"; }
void func() { cout << "调用了派生类的func()。\n"; }
~BB() { cout << "调用了派生类的析构函数~BB()。\n"; }
};
int main()
{
BB b;
AA &r = b;
r.func();
}
三十二、运行阶段类型识别dynamic_cast
-
运行阶段类型识别(RTTI RunTime Type Identification)为程序在运行阶段确定对象的类型,只适用于包含虚函数的类。
-
基类指针可以指向派生类对象,如何知道基类指针指向的是哪种派生类的对象呢?(想调用派生类中的非虚函数)。
-
dynamic_cast运算符用指向基类的指针来生成派生类的指针,它不能回答“指针指向的是什么类的对象”的问题,但能回答“是否可以安全的将对象的地址赋给特定类的指针”的问题。
语法:派生类指针 = dynamic_cast<派生类类型 *>(基类指针);
- 如果转换成功,dynamic_cast返回对象的地址,如果失败,返回nullptr。
注意:
-
dynamic_cast只适用于包含虚函数的类。
-
dynamic_cast可以将派生类指针转换为基类指针,这种画蛇添足的做法没有意义。
-
dynamic_cast可以用于引用,但是,没有与空指针对应的引用值,如果转换请求不正确,会出现bad_cast异常。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class Hero // 英雄基类
{
public:
int viability; // 生存能力。
int attack; // 攻击伤害。
virtual void skill1() { cout << "英雄释放了一技能。\n"; }
virtual void skill2() { cout << "英雄释放了二技能。\n"; }
virtual void uskill() { cout << "英雄释放了大绝招。\n"; }
};
class XS :public Hero // 西施派生类
{
public:
void skill1() { cout << "西施释放了一技能。\n"; }
void skill2() { cout << "西施释放了二技能。\n"; }
void uskill() { cout << "西施释放了大招。\n"; }
void show() { cout << "我是天下第一美女。\n"; }
};
class HX :public Hero // 韩信派生类
{
public:
void skill1() { cout << "韩信释放了一技能。\n"; }
void skill2() { cout << "韩信释放了二技能。\n"; }
void uskill() { cout << "韩信释放了大招。\n"; }
};
class LB :public Hero // 李白派生类
{
public:
void skill1() { cout << "李白释放了一技能。\n"; }
void skill2() { cout << "李白释放了二技能。\n"; }
void uskill() { cout << "李白释放了大招。\n"; }
};
int main()
{
// 根据用户选择的英雄,施展一技能、二技能和大招。
int id = 0; // 英雄的id。
cout << "请输入英雄(1-西施;2-韩信;3-李白。):";
cin >> id;
// 创建基类指针,让它指向派生类对象,用基类指针调用派生类的成员函数。
Hero* ptr = nullptr;
if (id == 1) { // 1-西施
ptr = new XS;
}
else if (id == 2) { // 2-韩信
ptr = new HX;
}
else if (id == 3) { // 3-李白
ptr = new LB;
}
if (ptr != nullptr) {
ptr->skill1();
ptr->skill2();
ptr->uskill();
// 如果基类指针指向的对象是西施,那么就调用西施的show()函数。
//if (id == 1) {
// XS* pxs = (XS *)ptr; // C风格强制转换的方法,程序员必须保证目标类型正确。
// pxs->show();
//}
XS* xsptr = dynamic_cast<XS*>(ptr); // 把基类指针转换为派生类。
if (xsptr != nullptr) xsptr->show(); // 如果转换成功,调用派生类西施的非虚函数。
delete ptr;
}
// 以下代码演示把基类引用转换为派生类引用时发生异常的情况。
/*HX hx;
Hero& rh = hx;
try{
XS & rxs= dynamic_cast<XS &>(rh);
}
catch (bad_cast) {
cout << "出现了bad_cast异常。\n";
}*/
}
三十三、typeid运算符和type_info类
typeid运算符用于获取数据类型的信息。
语法一:typeid(数据类型);
语法二:typeid(变量名或表达式);
-
typeid运算符返回type_info类(在头文件
中定义)的对象的引用。 -
type_info类的实现随编译器而异,但至少有name()成员函数,该函数返回一个字符串,通常是类名。
-
type_info重载了==和!=运算符,用于对类型进行比较。
注意:
-
type_info类的构造函数是private属性,也没有拷贝构造函数,所以不能直接实例化,只能由编译器在内部实例化。
-
不建议用name()成员函数返回的字符串作为判断数据类型的依据。(编译器可能会转换类型名)
-
typeid运算符可以用于多态的场景,在运行阶段识别对象的数据类型。
-
假设有表达式typeid(*ptr),当ptr是空指针时,如果ptr是多态的类型,将引发bad_typeid异常。
示例:
#include <iostream>
#include <string>
using namespace std;
class AA { // 定义一个类。
public:
AA() {}
};
int main()
{
// typeid用于自定义的数据类型。
AA aa;
AA* paa = &aa;
AA& raa = aa;
cout << "typeid(AA)=" << typeid(AA).name() << endl;
cout << "typeid(aa)=" << typeid(aa).name() << endl;
cout << "typeid(AA *)=" << typeid(AA*).name() << endl;
cout << "typeid(paa)=" << typeid(paa).name() << endl;
cout << "typeid(AA &)=" << typeid(AA&).name() << endl;
cout << "typeid(raa)=" << typeid(raa).name() << endl;
// type_info重载了==和!=运算符,用于对类型进行比较。
if (typeid(AA) == typeid(aa)) cout << "ok1\n";
if (typeid(AA) == typeid(*paa)) cout << "ok2\n";
if (typeid(AA) == typeid(raa)) cout << "ok3\n";
if (typeid(AA*) == typeid(paa)) cout << "ok4\n";
return 0;
}
三十四、自动推导类型auto
-
在C语言和C++98中,auto关键字用于修饰变量(自动存储的局部变量)。
-
在C++11中,赋予了auto全新的含义,不再用于修饰变量,而是作为一个类型指示符,指示编译器在编译时推导auto声明的变量的数据类型。
语法:auto 变量名 = 初始值;
- 在Linux平台下,编译需要加-std=c++11参数。
注意:
-
auto声明的变量必须在定义时初始化。
-
初始化的右值可以是具体的数值,也可以是表达式和函数的返回值等。
-
auto不能作为函数的形参类型。
-
auto不能直接声明数组。
-
auto不能定义类的非静态成员变量。
不要滥用auto,auto在编程时真正的用途如下:
-
代替冗长复杂的变量声明。
-
在模板中,用于声明依赖模板参数的变量。
-
函数模板依赖模板参数的返回值。
-
用于lambda表达式中。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
double func(double b, const char* c, float d, short e, long f)
{
cout << ",b=" << b << ",c=" << c << ",d=" << d << ",e=" << e << ",f=" << f << endl;
return 5.5;
}
int main()
{
double (*pf)( double , const char* , float , short , long ); // 声明函数指针pf。
pf = func;
pf( 2, "西施", 3, 4, 5);
auto pf1 = func;
pf1(2, "西施", 3, 4, 5);
}
三十五、函数模板的基本概念
-
函数模板是通用的函数描述,使用任意类型(泛型)来描述函数。
-
编译的时候,编译器推导实参的数据类型,根据实参的数据类型和函数模板,生成该类型的函数定义。
-
生成函数定义的过程被称为实例化。
-
创建交换两个变量的函数模板:
template <typename T>
void Swap(T &a, T &b)
{
T tmp = a;
a = b;
b = tmp;
}
-
在C++98添加关键字typename之前,C++使用关键字class来创建模板。
-
如果考虑向后兼容,函数模板应使用typename,而不是class。
-
函数模板实例化可以让编译器自动推导,也可以在调用的代码中显式的指定。
三十六、函数模板的注意事项
-
可以为类的成员函数创建模板,但不能是虚函数和析构函数。
-
使用函数模板时,必须明确数据类型,确保实参与函数模板能匹配上。
-
使用函数模板时,推导的数据类型必须适应函数模板中的代码。
-
使用函数模板时,如果是自动类型推导,不会发生隐式类型转换,如果显式指定了函数模板的数据类型,可以发生隐式类型转换。
-
函数模板支持多个通用数据类型的参数。
-
函数模板支持重载,可以有非通用数据类型的参数。
三十七、函数模板的具体化
可以提供一个具体化的函数定义,当编译器找到与函数调用匹配的具体化定义时,将使用该定义,不再寻找模板。
-
具体化(特例化、特化)的语法:
-
template<> void 函数模板名<数据类型>(参数列表)
-
template<> void 函数模板名 (参数列表)
-
{
-
// 函数体。
-
}
-
对于给定的函数名,可以有普通函数、函数模板和具体化的函数模板,以及它们的重载版本。
编译器使用各种函数的规则:
-
具体化优先于常规模板,普通函数优先于具体化和常规模板。
-
如果希望使用函数模板,可以用空模板参数强制使用函数模板。
-
如果函数模板能产生更好的匹配,将优先于普通函数。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class CGirl // 超女类。
{
public:
int m_bh; // 编号。
string m_name; // 姓名。
int m_rank; // 排名。
};
template <typename T>
void Swap(T& a, T& b); // 交换两个变量的值函数模板。
template<>
void Swap<CGirl>(CGirl& g1, CGirl& g2); // 交换两个超女对象的排名。
// template<>
// void Swap(CGirl& g1, CGirl& g2); // 交换两个超女对象的排名。
int main()
{
int a = 10, b = 20;
Swap(a, b); // 使用了函数模板。
cout << "a=" << a << ",b=" << b << endl;
CGirl g1, g2;
g1.m_rank = 1; g2.m_rank = 2;
Swap(g1, g2); // 使用了超女类的具体化函数。
cout << "g1.m_rank=" << g1.m_rank << ",g2.m_rank=" << g2.m_rank << endl;
}
template <typename T>
void Swap(T& a, T& b) // 交换两个变量的值函数模板。
{
T tmp = a;
a = b;
b = tmp;
cout << "调用了Swap(T& a, T& b)\n";
}
template<>
void Swap<CGirl>(CGirl& g1, CGirl& g2) // 交换两个超女对象的排名。
// template<>
// void Swap(CGirl& g1, CGirl& g2) // 交换两个超女对象的排名。
{
int tmp = g1.m_rank;
g1.m_rank = g2.m_rank;
g2.m_rank = tmp;
cout << "调用了Swap(CGirl& g1, CGirl& g2)\n";
}
//////////////////////////////////////////////////////
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
void Swap(int a, int b) // 普通函数。
{
cout << "使用了普通函数。\n";
}
template <typename T>
void Swap(T a, T b) // 函数模板。
{
cout << "使用了函数模板。\n";
}
template <>
void Swap(int a, int b) // 函数模板的具体化版本。
{
cout << "使用了具体化的函数模板。\n";
}
int main()
{
Swap('c', 'd');
}
三十八、函数模板分文件编写
-
函数模板只是函数的描述,没有实体,创建函数模板的代码放在头文件中。
-
函数模板的具体化有实体,编译的原理和普通函数一样,所以,声明放在头文件中,定义放在源文件中。
示例:
/////////////////////////////////////////////////////////////////
// public.h
#pragma once
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
void Swap(int a, int b); // 普通函数。
template <typename T>
void Swap(T a, T b) // 函数模板。
{
cout << "使用了函数模板。\n";
}
template <>
void Swap(int a, int b); // 函数模板的具体化版本。
/////////////////////////////////////////////////////////////////
/////////////////////////////////////////////////////////////////
// public.cpp
#include "public.h"
void Swap(int a, int b) // 普通函数。
{
cout << "使用了普通函数。\n";
}
template <>
void Swap(int a, int b) // 函数模板的具体化版本。
{
cout << "使用了具体化的函数模板。\n";
}
/////////////////////////////////////////////////////////////////
/////////////////////////////////////////////////////////////////
// demo01.cpp
#include "public.h"
int main()
{
Swap(1,2); // 将使用普通函数。
Swap(1.3, 3.5); // 将使用具体化的函数模板。
Swap('c', 'd'); // 将使用函数模板。
}
/////////////////////////////////////////////////////////////////
三十九、函数模板高级
decltype关键字
在C++11中,dec- ltype操作符,用于查询表达式的数据类型。
语法:decltype(expression) var;
-
decltype分析表达式并得到它的类型,不会计算执行表达式。函数调用也一种表达式,因此不必担心在使用decltype时执行了函数。
-
decltype推导规则(按步骤):
-
如果expression是一个没有用括号括起来的标识符,则var的类型与该标识符的类型相同,包括const等限定符。
-
如果expression是一个函数调用,则var的类型与函数的返回值类型相同(函数不能返回void,但可以返回void *)。
-
者用括号括起来的标识符,那么var的类型是expression的引用。
-
如果上面的条件都不满足,则var的类型与expression的类型相同。
-
如果需要多次使用decltype,可以结合typedef和using。
-
函数后置返回类型
-
int func(int x,double y);
等同:
-
auto func(int x,double y) -> int;
-
将返回类型移到了函数声明的后面。
-
auto是一个占位符(C++11给auto新增的角色), 为函数返回值占了一个位置。
-
这种语法也可以用于函数定义:
-
auto func(int x,double y) -> int
-
{
-
// 函数体。
-
}
- C++14的auto关键字
C++14标准对函数返回类型推导规则做了优化,函数的返回值可以用auto,不必尾随返回类型。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
template <typename T1, typename T2>
auto func(T1 x, T2 y) -> decltype(x + y)
{
// 其它的代码。
decltype(x+y) tmp = x + y;
cout << "tmp=" << tmp << endl;
return tmp;
}
int main()
{
func(3, 5.8);
}
四十、模板类的基本概念
-
类模板是通用类的描述,使用任意类型(泛型)来描述类的定义。
-
使用类模板的时候,指定具体的数据类型,让编译器生成该类型的类定义。
语法:
template
class 类模板名
{
类的定义;
};
函数模板建议用typename描述通用数据类型,类模板建议用class。
注意:
-
在创建对象的时候,必须指明具体的数据类型。
-
使用类模板时,数据类型必须适应类模板中的代码。
-
类模板可以为通用数据类型指定缺省的数据类型(C++11标准的函数模板也可以)。
-
模板类的成员函数可以在类外实现。
-
可以用new创建模板类对象。
-
在程序中,模板类的成员函数使用了才会创建。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
template <class T1, class T2=string>
class AA
{
public:
T1 m_a; // 通用类型用于成员变量。
T2 m_b; // 通用类型用于成员变量。
AA() { } // 默认构造函数是空的。
// 通用类型用于成员函数的参数。
AA(T1 a,T2 b):m_a(a),m_b(b) { }
// 通用类型用于成员函数的返回值。
T1 geta() // 获取成员m_a的值。
{
T1 a = 2; // 通用类型用于成员函数的代码中。
return m_a + a;
}
T2 getb(); // 获取成员m_b的值。
};
template <class T1, class T2>
T2 AA<T1,T2>::getb() // 获取成员m_b的值。
{
return m_b;
}
int main()
{
AA<int, string>* a = new AA<int, string>(3, "西施"); // 用模板类AA创建对象a。
cout << "a->geta()=" << a->geta() << endl;
cout << "a->getb()=" << a->getb() << endl;
delete a;
}
四十一、模板类的示例-栈
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
// typedef string DataType; // 定义栈元素的数据类型。
template <class DataType>
class Stack // 栈类
{
private:
DataType* items; // 栈数组。
int stacksize; // 栈实际的大小。
int top; // 栈顶指针。
public:
// 构造函数:1)分配栈数组内存;2)把栈顶指针初始化为0。
Stack(int size) :stacksize(size), top(0) {
items = new DataType[stacksize];
}
~Stack() {
delete [] items; items = nullptr;
}
bool isempty() const { // 判断栈是否为空。
return top == 0;
}
bool isfull() const { // 判断栈是否已满。
return top == stacksize;
}
bool push(const DataType& item) { // 元素入栈。
if (top < stacksize) { items[top++] = item; return true; }
return false;
}
bool pop(DataType& item) { // 元素出栈。
if (top > 0) { item = items[--top]; return true; }
return false;
}
};
int main()
{
Stack<string> ss(5); // 创建栈对象,大小是5。
// 元素入栈。
// ss.push(1); ss.push(2); ss.push(3); ss.push(4); ss.push(5);
ss.push("西施"); ss.push("冰冰"); ss.push("幂幂"); ss.push("金莲");
// 元素出栈。
string item;
while (ss.isempty() == false)
{
ss.pop(item); cout << "item = " << item << endl;
}
}
四十二、模板类的示例-数组
类模板可以有非通用类型参数:1)通常是整型(C++20标准可以用其它的类型);2)实例化模板时必须用常量表达式;3)模板中不能修改参数的值;4)可以为非通用类型参数提供默认值。
优点:在栈上分配内存,易维护,执行速度快,合适小型数组。
缺点:在程序中,不同的非通用类型参数将导致编译器生成不同的类。
构造函数的方法更通用,因为数据的大小是类的成员(而不是硬编码),可以创建数组大小可变的类。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
template <class T,int len=10>
class Array
{
private:
T items[len]; // 数组元素。
public:
Array() {} // 默认构造函数。
~Array() {} // 析构函数
T& operator[](int ii) { return items[ii]; } // 重载操作符[],可以修改数组中的元素。
const T& operator[](int ii) const { return items[ii]; } // 重载操作符[],不能修改数组中的元素。
};
template <class T>
class Vector
{
private:
int len; // 数组元素的个数。
T* items; // 数组元素。
public:
// 默认构造函数,分配内存。
Vector(int size=10):len(size) {
items = new T[len];
}
~Vector() { // 析构函数
delete[] items; items = nullptr;
}
void resize(int size) { // 护展数组的内存空间。
if (size <= len) return; // 只能往更大扩展。
T* tmp = new T[size]; // 分配更大的内存空间。
for (int ii = 0; ii < len; ii++) tmp[ii] = items[ii]; // 把原来数组中的元素复制到新数组。
delete[] items; // 释放原来的数组。
items = tmp; // 让数组指针指向新数组。
len = size; // 扩展后的数组长度。
}
int size() const { return len; } // 获取数组长度。
T& operator[](int ii) { // 重载操作符[],可以修改数组中的元素。
if (ii >= len) resize(ii + 1); // 扩展数组。
return items[ii];
}
const T& operator[](int ii) const { return items[ii]; } // 重载操作符[],不能修改数组中的元素。
};
int main()
{
// Array<string,10> aa; // 创建模板类Array的对象。
Vector<int> aa(1); // 创建模板类Vector的对象。
aa[0] = 5; aa[1] = 8; aa[2] = 3; aa[3] = 2; aa[4] = 7;
// aa[0] = "西施"; aa[1] = "冰冰"; aa[2] = "幂幂"; aa[3] = "金莲"; aa[4] = "小乔";
for (int ii=0; ii<5;ii++) cout << "aa[" << ii << "]=" << aa[ii] << endl;
}
四十三、嵌套和递归使用模板类
在C++11之前,嵌套使用模板类的时候,> >之间要加空格。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
template <class DataType>
class Stack // 栈类
{
private:
DataType* items; // 栈数组。
int stacksize; // 栈实际的大小。
int top; // 栈顶指针。
public:
// 构造函数:1)分配栈数组内存;2)把栈顶指针初始化为0。
Stack(int size = 3) :stacksize(size), top(0) {
items = new DataType[stacksize];
}
~Stack() {
delete[] items; items = nullptr;
}
Stack& operator=(const Stack& v) // 重载赋值运算符函数,实现深拷贝。
{
delete[] items; // 释放原内存。
stacksize = v.stacksize; // 栈实际的大小。
items = new DataType[stacksize]; // 重新分配数组。
for (int ii = 0; ii < stacksize; ii++) items[ii] = v.items[ii]; // 复制数组中的元素。
top = v.top; // 栈顶指针。
return *this;
}
bool isempty() const { // 判断栈是否为空。
return top == 0;
}
bool isfull() const { // 判断栈是否已满。
return top == stacksize;
}
bool push(const DataType& item) { // 元素入栈。
if (top < stacksize) { items[top++] = item; return true; }
return false;
}
bool pop(DataType& item) { // 元素出栈。
if (top > 0) { item = items[--top]; return true; }
return false;
}
};
template <class T>
class Vector // 动态数组。
{
private:
int len; // 数组元素的个数。
T* items; // 数组元素。
public:
// 默认构造函数,分配内存。
Vector(int size = 2) :len(size) {
items = new T[len];
}
~Vector() { // 析构函数
delete[] items; items = nullptr;
}
Vector& operator=(const Vector& v) // 重载赋值运算符函数,实现深拷贝。
{
delete[] items; // 释放原内存。
len = v.len; // 数组实际的大小。
items = new T[len]; // 重新分配数组。
for (int ii = 0; ii < len; ii++) items[ii] = v.items[ii]; // 复制数组中的元素。
return *this;
}
void resize(int size) { // 护展数组的内存空间。
if (size <= len) return; // 只能往更大扩展。
T* tmp = new T[size]; // 分配更大的内存空间。
for (int ii = 0; ii < len; ii++) tmp[ii] = items[ii]; // 把原来数组中的元素复制到新数组。
delete[] items; // 释放原来的数组。
items = tmp; // 让数组指针指向新数组。
len = size; // 扩展后的数组长度。
}
int size() const { return len; } // 获取数组长度。
T& operator[](int ii) { // 重载操作符[],可以修改数组中的元素。
if (ii >= len) resize(ii + 1); // 扩展数组。
return items[ii];
}
const T& operator[](int ii) const { return items[ii]; } // 重载操作符[],不能修改数组中的元素。
};
int main()
{
// Vector容器的大小缺省值是2,Stack容器的大小缺省值是3。
// 创建Vector容器,容器中的元素用Stack<string>。
Vector<Stack<string>> vs; // C++11之前,>>之间要加空格。
// 手工的往容器中插入数据。
vs[0].push("西施1"); vs[0].push("西施2"); vs[0].push("西施3"); // vs容器中的第0个栈。
vs[1].push("西瓜1"); vs[1].push("西瓜2"); vs[1].push("西瓜3"); // vs容器中的第1个栈。
vs[2].push("冰冰"); vs[2].push("幂幂"); // vs容器中的第2个栈。
// 用嵌套的循环,把vs容器中的数据显示出来。
for (int ii = 0; ii < vs.size(); ii++) // 遍历Vector容器。
{
while (vs[ii].isempty() == false) // 遍历Stack容器。
{
string item; vs[ii].pop(item); cout << "item = " << item << endl;
}
}
// 创建Stack容器,容器中的元素用Vector<string>。
Stack<Vector<string>> sv;
Vector<string> tmp; // 栈的元素,临时Vector<string>容器。
// 第一个入栈的元素。
tmp[0] = "西施1"; tmp[1] = "西施2"; sv.push(tmp);
// 第二个入栈的元素。
tmp[0] = "西瓜1"; tmp[1] = "西瓜2"; sv.push(tmp);
// 第三个入栈的元素。
tmp[0] = "冰冰1"; tmp[1] = "冰冰2"; tmp[2] = "冰冰3"; tmp[3] = "冰冰4"; sv.push(tmp);
// 用嵌套的循环,把sv容器中的数据显示出来。
while (sv.isempty() == false)
{
sv.pop(tmp); // 出栈一个元素,放在临时容器中。
for (int ii = 0; ii < tmp.size(); ii++) // 遍历临时Vector<string>容器,显示容器中每个元素的值。
cout << " vs[" << ii << "] = " << tmp[ii] << endl;
}
// 创建Vector容器,容器中的元素用Vector<string>。
Vector<Vector<string>> vv; // 递归使用模板类。
vv[0][0] = "西施1"; vv[0][1] = "西施2"; vv[0][2] = "西施3";
vv[1][0] = "西瓜1"; vv[1][1] = "西瓜2";
vv[2][0] = "冰冰1"; vv[2][1] = "冰冰2"; vv[2][2] = "冰冰3"; vv[2][3] = "冰冰4";
// 用嵌套的循环,把vv容器中的数据显示出来。
for (int ii = 0; ii < vv.size(); ii++)
{
for (int jj = 0; jj < vv[ii].size(); jj++)
// cout << " vv[" << ii << "][" << jj << "] = " << vv[ii][jj] << endl;
cout << vv[ii][jj] << " ";
cout << endl;
}
}
四十四、模板类具体化
-
模板类具体化(特化、特例化)有两种:完全具体化和部分具体化。
-
语法请见示例程序。
-
具体化程度高的类优先于具体化程度低的类,具体化的类优先于没有具体化的类。
-
具体化的模板类,成员函数类外实现的代码应该放在源文件中。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
// 类模板
template<class T1, class T2>
class AA { // 类模板。
public:
T1 m_x;
T2 m_y;
AA(const T1 x, const T2 y) :m_x(x), m_y(y) { cout << "类模板:构造函数。\n"; }
void show() const;
};
template<class T1, class T2>
void AA<T1, T2>::show() const { // 成员函数类外实现。
cout << "类模板:x = " << m_x << ", y = " << m_y << endl;
}
/////////////////////////////////////////////////////////////////////////////////////////
// 类模板完全具体化
template<>
class AA<int, string> {
public:
int m_x;
string m_y;
AA(const int x, const string y) :m_x(x), m_y(y) { cout << "完全具体化:构造函数。\n"; }
void show() const;
};
void AA<int, string>::show() const { // 成员函数类外实现。
cout << "完全具体化:x = " << m_x << ", y = " << m_y << endl;
}
/////////////////////////////////////////////////////////////////////////////////////////
// 类模板部分具体化
template<class T1>
class AA<T1, string> {
public:
T1 m_x;
string m_y;
AA(const T1 x, const string y) :m_x(x), m_y(y) { cout << "部分具体化:构造函数。\n"; }
void show() const;
};
template<class T1>
void AA<T1, string>::show() const { // 成员函数类外实现。
cout << "部分具体化:x = " << m_x << ", y = " << m_y << endl;
}
/////////////////////////////////////////////////////////////////////////////////////////
int main()
{
// 具体化程度高的类优先于具体化程度低的类,具体化的类优先于没有具体化的类。
AA<int, string> aa1(8, "我是一只傻傻鸟。"); // 将使用完全具体化的类。
AA<char, string> aa2(8, "我是一只傻傻鸟。"); // 将使用部分具体化的类。
AA<int, double> aa3(8, 999999); // 将使用模板类。
}
四十五、模板类与继承
-
模板类继承普通类(常见)。
-
普通类继承模板类的实例化版本。
-
普通类继承模板类。(常见)
-
模板类继承模板类。
-
模板类继承模板参数给出的基类(不能是模板类)。
示例:
1)模板类继承普通类
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class AA // 普通类AA。
{
public:
int m_a;
AA(int a) :m_a(a) { cout << "调用了AA的构造函数。\n"; }
void func1() { cout << "调用了func1()函数:m_a=" << m_a << endl;; }
};
template<class T1, class T2>
class BB:public AA // 模板类BB。
{
public:
T1 m_x;
T2 m_y;
BB(const T1 x, const T2 y,int a) : AA(a) , m_x(x), m_y(y) { cout << "调用了BB的构造函数。\n"; }
void func2() const { cout << "调用了func2()函数:x = " << m_x << ", y = " << m_y << endl; }
};
int main()
{
BB<int, string> bb(8, "我是一只傻傻鸟。",3);
bb.func2();
bb.func1();
}
2)普通类继承模板类的实例化版本
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
template<class T1, class T2>
class BB // 模板类BB。
{
public:
T1 m_x;
T2 m_y;
BB(const T1 x, const T2 y) : m_x(x), m_y(y) { cout << "调用了BB的构造函数。\n"; }
void func2() const { cout << "调用了func2()函数:x = " << m_x << ", y = " << m_y << endl; }
};
class AA:public BB<int,string> // 普通类AA。
{
public:
int m_a;
AA(int a,int x,string y) : BB(x,y),m_a(a) { cout << "调用了AA的构造函数。\n"; }
void func1() { cout << "调用了func1()函数:m_a=" << m_a << endl;; }
};
int main()
{
AA aa(3,8, "我是一只傻傻鸟。");
aa.func1();
aa.func2();
}
3)普通类继承模板类。
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
template<class T1, class T2>
class BB // 模板类BB。
{
public:
T1 m_x;
T2 m_y;
BB(const T1 x, const T2 y) : m_x(x), m_y(y) { cout << "调用了BB的构造函数。\n"; }
void func2() const { cout << "调用了func2()函数:x = " << m_x << ", y = " << m_y << endl; }
};
template<class T1, class T2>
class AA:public BB<T1,T2> // 普通类AA变成了模板类,才能继承模板类。
{
public:
int m_a;
AA(int a, const T1 x, const T2 y) : BB<T1,T2>(x,y),m_a(a) { cout << "调用了AA的构造函数。\n"; }
void func1() { cout << "调用了func1()函数:m_a=" << m_a << endl;; }
};
int main()
{
AA<int,string> aa(3,8, "我是一只傻傻鸟。");
aa.func1();
aa.func2();
}
4)模板类继承模板类。
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
template<class T1, class T2>
class BB // 模板类BB。
{
public:
T1 m_x;
T2 m_y;
BB(const T1 x, const T2 y) : m_x(x), m_y(y) { cout << "调用了BB的构造函数。\n"; }
void func2() const { cout << "调用了func2()函数:x = " << m_x << ", y = " << m_y << endl; }
};
template<class T1, class T2>
class AA:public BB<T1,T2> // 普通类AA变成了模板类,才能继承模板类。
{
public:
int m_a;
AA(int a, const T1 x, const T2 y) : BB<T1,T2>(x,y),m_a(a) { cout << "调用了AA的构造函数。\n"; }
void func1() { cout << "调用了func1()函数:m_a=" << m_a << endl;; }
};
template<class T, class T1, class T2>
class CC :public BB<T1, T2> // 模板类继承模板类。
{
public:
T m_a;
CC(const T a, const T1 x, const T2 y) : BB<T1, T2>(x, y), m_a(a) { cout << "调用了CC的构造函数。\n"; }
void func3() { cout << "调用了func3()函数:m_a=" << m_a << endl;; }
};
int main()
{
CC<int,int,string> cc(3,8, "我是一只傻傻鸟。");
cc.func3();
cc.func2();
}
5)模板类继承模板参数给出的基类
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
class AA {
public:
AA() { cout << "调用了AA的构造函数AA()。\n"; }
AA(int a) { cout << "调用了AA的构造函数AA(int a)。\n"; }
};
class BB {
public:
BB() { cout << "调用了BB的构造函数BB()。\n"; }
BB(int a) { cout << "调用了BB的构造函数BB(int a)。\n"; }
};
class CC {
public:
CC() { cout << "调用了CC的构造函数CC()。\n"; }
CC(int a) { cout << "调用了CC的构造函数CC(int a)。\n"; }
};
template<class T>
class DD {
public:
DD() { cout << "调用了DD的构造函数DD()。\n"; }
DD(int a) { cout << "调用了DD的构造函数DD(int a)。\n"; }
};
template<class T>
class EE : public T { // 模板类继承模板参数给出的基类。
public:
EE() :T() { cout << "调用了EE的构造函数EE()。\n"; }
EE(int a) :T(a) { cout << "调用了EE的构造函数EE(int a)。\n"; }
};
int main()
{
EE<AA> ea1; // AA作为基类。
EE<BB> eb1; // BB作为基类。
EE<CC> ec1; // CC作为基类。
EE<DD<int>> ed1; // EE<int>作为基类。
// EE<DD> ed1; // DD作为基类,错误。
}
157、模板类与函数
模板类可以用于函数的参数和返回值,有三种形式:
-
普通函数,参数和返回值是模板类的实例化版本。
-
函数模板,参数和返回值是某种的模板类。
-
函数模板,参数和返回值是任意类型(支持普通类和模板类和其它类型)。
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
template<class T1, class T2>
class AA // 模板类AA。
{
public:
T1 m_x;
T2 m_y;
AA(const T1 x, const T2 y) : m_x(x), m_y(y) { }
void show() const { cout << "show() x = " << m_x << ", y = " << m_y << endl; }
};
// 采用普通函数,参数和返回值是模板类AA的实例化版本。
AA<int, string> func(AA<int, string>& aa)
{
aa.show();
cout << "调用了func(AA<int, string> &aa)函数。\n";
return aa;
}
// 函数模板,参数和返回值是的模板类AA。
template <typename T1,typename T2>
AA<T1, T2> func(AA<T1, T2>& aa)
{
aa.show();
cout << "调用了func(AA<T1, T2> &aa)函数。\n";
return aa;
}
// 函数模板,参数和返回值是任意类型。
template <typename T>
T func(T &aa)
{
aa.show();
cout << "调用了func(AA<T> &aa)函数。\n";
return aa;
}
int main()
{
AA<int, string> aa(3, "我是一只傻傻鸟。");
func(aa);
}
四十六、模板类与友元
模板类的友元函数有三类:
-
非模板友元:友元函数不是模板函数,而是利用模板类参数生成的函数。
-
约束模板友元:模板类实例化时,每个实例化的类对应一个友元函数。
-
非约束模板友元:模板类实例化时,如果实例化了n个类,也会实例化n个友元函数,每个实例化的类都拥有n个友元函数。
非模板友元示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
template<class T1, class T2>
class AA
{
T1 m_x;
T2 m_y;
public:
AA(const T1 x, const T2 y) : m_x(x), m_y(y) { }
// 非模板友元:友元函数不是模板函数,而是利用模板类参数生成的函数,只能在类内实现。
friend void show(const AA<T1, T2>& a)
{
cout << "x = " << a.m_x << ", y = " << a.m_y << endl;
}
/* friend void show(const AA<int, string>& a);
friend void show(const AA<char, string>& a);*/
};
//void show(const AA<int, string>& a)
//{
// cout << "x = " << a.m_x << ", y = " << a.m_y << endl;
//}
//
//void show(const AA<char, string>& a)
//{
// cout << "x = " << a.m_x << ", y = " << a.m_y << endl;
//}
int main()
{
AA<int, string> a(88, "我是一只傻傻鸟。");
show(a);
AA<char, string> b(88, "我是一只傻傻鸟。");
show(b);
}
2)约束模板友元示例
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
// 约束模板友元:模板类实例化时,每个实例化的类对应一个友元函数。
template <typename T>
void show(T& a); // 第一步:在模板类的定义前面,声明友元函数模板。
template<class T1, class T2>
class AA // 模板类AA。
{
friend void show<>(AA<T1, T2>& a); // 第二步:在模板类中,再次声明友元函数模板。
T1 m_x;
T2 m_y;
public:
AA(const T1 x, const T2 y) : m_x(x), m_y(y) { }
};
template<class T1, class T2>
class BB // 模板类BB。
{
friend void show<>(BB<T1, T2>& a); // 第二步:在模板类中,再次声明友元函数模板。
T1 m_x;
T2 m_y;
public:
BB(const T1 x, const T2 y) : m_x(x), m_y(y) { }
};
template <typename T> // 第三步:友元函数模板的定义。
void show(T& a)
{
cout << "通用:x = " << a.m_x << ", y = " << a.m_y << endl;
}
template <> // 第三步:具体化版本。
void show(AA<int, string>& a)
{
cout << "具体AA<int, string>:x = " << a.m_x << ", y = " << a.m_y << endl;
}
template <> // 第三步:具体化版本。
void show(BB<int, string>& a)
{
cout << "具体BB<int, string>:x = " << a.m_x << ", y = " << a.m_y << endl;
}
int main()
{
AA<int, string> a1(88, "我是一只傻傻鸟。");
show(a1); // 将使用具体化的版本。
AA<char, string> a2(88, "我是一只傻傻鸟。");
show(a2); // 将使用通用的版本。
BB<int, string> b1(88, "我是一只傻傻鸟。");
show(b1); // 将使用具体化的版本。
BB<char, string> b2(88, "我是一只傻傻鸟。");
show(b2); // 将使用通用的版本。
}
3)非约束模板友元
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
// 非类模板约束的友元函数,实例化后,每个函数都是每个每个类的友元。
template<class T1, class T2>
class AA
{
template <typename T> friend void show(T& a); // 把函数模板设置为友元。
T1 m_x;
T2 m_y;
public:
AA(const T1 x, const T2 y) : m_x(x), m_y(y) { }
};
template <typename T> void show(T& a) // 通用的函数模板。
{
cout << "通用:x = " << a.m_x << ", y = " << a.m_y << endl;
}
template <>void show(AA<int, string>& a) // 函数模板的具体版本。
{
cout << "具体<int, string>:x = " << a.m_x << ", y = " << a.m_y << endl;
}
int main()
{
AA<int, string> a(88, "我是一只傻傻鸟。");
show(a); // 将使用具体化的版本。
AA<char, string> b(88, "我是一只傻傻鸟。");
show(b); // 将使用通用的版本。
}
四十七、成员模板类
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
template<class T1, class T2>
class AA // 类模板AA。
{
public:
T1 m_x;
T2 m_y;
AA(const T1 x, const T2 y) : m_x(x), m_y(y) {}
void show() { cout << "m_x=" << m_x << ",m_y=" << m_y << endl; }
template<class T>
class BB
{
public:
T m_a;
T1 m_b;
BB() {}
void show();
};
BB<string> m_bb;
template<typename T>
void show(T tt);
};
template<class T1, class T2>
template<class T>
void AA<T1,T2>::BB<T>::show() {
cout << "m_a=" << m_a << ",m_b=" << m_b << endl;
}
template<class T1, class T2>
template<typename T>
void AA<T1,T2>::show(T tt) {
cout << "tt=" << tt << endl;
cout << "m_x=" << m_x << ",m_y=" << m_y << endl;
m_bb.show();
}
int main()
{
AA<int, string> a(88, "我是一只傻傻鸟。");
a.show();
a.m_bb.m_a = "我有一只小小鸟。";
a.m_bb.show();
a.show("你是一只什么鸟?");
}
四十八、将模板类用作参数
示例:
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
template <class T, int len>
class LinkList // 链表类模板。
{
public:
T* m_head; // 链表头结点。
int m_len = len; // 表长。
void insert() { cout << "向链表中插入了一条记录。\n"; }
void ddelete() { cout << "向链表中删除了一条记录。\n"; }
void update() { cout << "向链表中更新了一条记录。\n"; }
};
template <class T, int len>
class Array // 数组类模板。
{
public:
T* m_data; // 数组指针。
int m_len = len; // 表长。
void insert() { cout << "向数组中插入了一条记录。\n"; }
void ddelete() { cout << "向数组中删除了一条记录。\n"; }
void update() { cout << "向数组中更新了一条记录。\n"; }
};
// 线性表模板类:tabletype-线性表类型,datatype-线性表的数据类型。
template<template<class, int >class tabletype, class datatype, int len>
class LinearList
{
public:
tabletype<datatype, len> m_table; // 创建线性表对象。
void insert() { m_table.insert(); } // 线性表插入操作。
void ddelete() { m_table.ddelete(); } // 线性表删除操作。
void update() { m_table.update(); } // 线性表更新操作。
void oper() // 按业务要求操作线性表。
{
cout << "len=" << m_table.m_len << endl;
m_table.insert();
m_table.update();
}
};
int main()
{
// 创建线性表对象,容器类型为链表,链表的数据类型为int,表长为20。
LinearList<LinkList, int, 20> a;
a.insert();
a.ddelete();
a.update();
// 创建线性表对象,容器类型为数组,数组的数据类型为string,表长为20。
LinearList<Array, string, 20> b;
b.insert();
b.ddelete();
b.update();
}
四十九、编译预处理
C++程序编译的过程:预处理 -> 编译(优化、汇编)-> 链接
预处理指令主要有以下三种:
- 包含头文件:#include
- 宏定义:#define(定义宏)、#undef(删除宏)。
- 条件编译:#ifdef、#ifndef。
包含头文件
- #include 包含头文件有两种方式:
- #include <文件名>:直接从编译器自带的函数库目录中寻找文件。
- #include "文件名":先从自定义的目录中寻找文件,如果找不到,再从编译器自带的函数库目录中寻找。
- #include也包含其它的文件,如:*.h、*.cpp或其它的文件。
C++98标准后的头文件:
- C的标准库:老版本的有.h后缀;新版本没有.h的后缀,增加了字符c的前缀。例如:老版本是<stdio.h>,新版本是
,新老版本库中的内容是一样的。在程序中,不指定std命名空间也能使用库中的内容。 - C++的标准库:老版本的有.h后缀;新版本没有.h的后缀。例如:老版本是<iostream.h>,新版本是
,老版本已弃用,只能用新版本。在程序中,必须指定std命名空间才能使用库中的内容。
注意:用户自定义的头文件还是用.h为后缀。
宏定义指令
-
无参数的宏:#define 宏名 宏内容
-
有参数的宏:#define MAX(x,y) ((x)>(y) ? (x) : (y)) MAX(3,5) ((3)>(5) ? (3) : (5))
-
编译的时候,编译器把程序中的宏名用宏内容替换,是为宏展开(宏替换)。
-
宏可以只有宏名,没有宏内容。
-
在C++中,内联函数可代替有参数的宏,效果更好。
C++中常用的宏:
当前源代码文件名:FILE
当前源代码函数名:FUNCTION
当前源代码行号:LINE
编译的日期:DATE
编译的时间:TIME
编译的时间戳:TIMESTAMP
当用C++编译程序时,宏__cplusplus就会被定义。
条件编译
最常用的两种:#ifdef、#ifndef if #define if not #define
#ifdef 宏名
程序段一
#else
程序段二
#endif
含义:如果#ifdef后面的宏名已存在,则使用程序段一,否则使用程序段二。
#ifndef 宏名
程序段一
#else
程序段二
#endif
含义:如果#ifndef后面的宏名不存在,则使用程序段一,否则使用序段二。
**解决头文件中代码重复包含的问题**
在C/C++中,在使用预编译指令#include的时候,为了防止头文件被重复包含,有两种方式。
第一种:用#ifndef指令。
#ifndef _GIRL_
#define _GIRL_
//代码内容。
#endif
第二种:把#pragma once指令放在文件的开头。
#ifndef方式受C/C++语言标准的支持,不受编译器的任何限制;而#pragma once方式有些编译器不支持。
#ifndef可以针对文件中的部分代码;而#pragma once只能针对整个文件。
#ifndef更加灵活,兼容性好;#pragma once操作简单,效率高。
五十、编译和链接
一、源代码的组织
头文件(*.h):#include头文件、函数的声明、结构体的声明、类的声明、模板的声明、内联函数、#define和const定义的常量等。
源文件(*.cpp):函数的定义、类的定义、模板具体化的定义。
主程序(main函数所在的程序):主程序负责实现框架和核心流程,把需要用到的头文件用#include包含进来。
二、编译预处理
预处理的包括以下方面:
-
处理#include头文件包含指令。
-
处理#ifdef #else #endif、#ifndef #else #endif条件编译指令。
-
处理#define宏定义。
-
为代码添加行号、文件名和函数名。
-
删除注释。
-
保留部分#pragma编译指令(编译的时候会用到)。
三、编译
将预处理生成的文件,经过词法分析、语法分析、语义分析以及优化和汇编后,编译成若干个目标文件(二进制文件)。
四、链接
将编译后的目标文件,以及它们所需要的库文件链接在一起,形成一个体整。
五、更多细节
-
分开编译的好处:每次只编译修改过的源文件,然后再链接,效率最高。
-
编译单个*.cpp文件的时候,必须要让编译器知道名称的存在,否则会出现找不到标识符的错误。(直接和间接包含头文件都可以)
-
编译单个*.cpp文件的时候,编译器只需要知道名称的存在,不会把它们的定义一起编译。
-
如果函数和类的定义不存在,编译不会报错,但链接会出现无法解析的外部命令。
-
链接的时候,变量、函数和类的定义只能有一个,否则会出现重定义的错误。(如果把变量、函数和类的定义放在.h文件中,.h会被多次包含,链接前可能存在多个副本;如果放在.cpp文件中,.cpp文件不会被包含,只会被编译一次,链接前只存在一个版本)
-
把变量、函数和类的定义放在.h中是不规范的做法,如果.h被多个*.cpp包含,会出现重定义。
-
用#include包含*.cpp也是不规范的做法,原理同上。
-
尽可能不使用全局变量,如果一定要用,要在.h文件中声明(需要加extern关键字),在.cpp文件中定义。
-
全局的const常量在头文件中定义(const常量仅在单个文件内有效)。
-
h文件重复包含的处理方法只对单个的*.cpp文件有效,不是整个项目。
-
函数模板和类模板的声明和定义可以分开书写,但它们的定义并不是真实的定义,只能放在.h文件中;函数模板和类模板的具体化版本的代码是真实的定义,所以放在.cpp文件中。
-
Linux下C++编译和链接的原理与VS一样。
五十一、命名空间
-
在实际开发中,较大型的项目会使用大量的全局名字,如类、函数、模板、变量等,很容易出现名字冲突的情况。
-
命名空间分割了全局空间,每个命名空间是一个作用域,防止名字冲突。
一、语法
创建命名空间:
namespace 命名空间的名字
{
// 类、函数、模板、变量的声明和定义。
}
创建命名空间的别名:
namespace 别名=原名;
二、使用命名空间
在同一命名空间内的名字可以直接访问,该命名空间之外的代码则必须明确指出命名空间。
- 运算符::
语法:命名空间::名字
- 简单明了,且不会造成任何冲突,但使用起来比较繁琐。
- u1sing声明
语法:using 命名空间::名字
-
用using声明名后,就可以进行直接使用名称。
-
如果该声明区域有相同的名字,则会报错。
- using编译指令
语法:using namespace命名空间
- using编译指令将使整个命名空间中的名字可用。如果声明区域有相同的名字,局部版本将隐藏命名空间中的名字,不过,可以使用域名解析符使用命名空间中的名称。
四、注意事项
-
命名空间是全局的,可以分布在多个文件中。
-
命名空间可以嵌套。
-
在命名空间中声明全局变量,而不是使用外部全局变量和静态变量。
-
对于using声明,首选将其作用域设置为局部而不是全局。
-
不要在头文件中使用using编译指令,如果非要使用,应将它放在所有的#include之后。
-
匿名的命名空间,从创建的位置到文件结束有效。
示例:
// demo01.cpp ///////////////////////////////////////
#include <iostream> // 包含头文件。
#include "public1.h"
#include "public2.h"
using namespace std; // 指定缺省的命名空间。
int main()
{
using namespace aa;
using namespace bb;
using bb::ab;
cout << "aa::ab=" << aa::ab << endl;
aa::func1();
aa::A1 a;
a.show();
cout << "bb::ab=" << bb::ab << endl;
}
///////////////////////////////////////////////////////////
// public2.cpp ///////////////////////////////////////
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
#include "public2.h"
namespace aa
{
int ab = 1; // 全局变量。
}
namespace bb
{
int ab = 2; // 全局变量。
void func1() { // 全局函数的定义。
cout << "调用了bb::func1()函数。\n";
}
void A1::show() { // 类成员函数的类外实现。
cout << "调用了bb::A1::show()函数。\n";
}
}
///////////////////////////////////////////////////////////
// public1.cpp ///////////////////////////////////////
#include <iostream> // 包含头文件。
using namespace std; // 指定缺省的命名空间。
#include "public1.h"
namespace aa
{
void func1() { // 全局函数的定义。
cout << "调用了aa::func1()函数。\n";
}
void A1::show() { // 类成员函数的类外实现。
cout << "调用了aa::A1::show()函数。\n";
}
}
///////////////////////////////////////////////////////////
// public2.h ///////////////////////////////////////
#pragma once
namespace aa
{
extern int ab; // 全局变量。
}
namespace bb
{
extern int ab ; // 全局变量。
void func1(); // 全局函数的声明。
class A1 // 类。
{
public:
void show(); // 类的成员函数。
};
}
///////////////////////////////////////////////////////////
// public1.h ///////////////////////////////////////
#pragma once
namespace aa
{
void func1(); // 全局函数的声明。
class A1 // 类。
{
public:
void show(); // 类的成员函数。
};
}
///////////////////////////////////////////////////////////
五十二、C++强制类型转换
-
C风格的强制类型转换很容易理解,不管什么类型都可以直接进行转换,使用格式如下:
-
目标类型 b = (目标类型) a;
-
C++也是支持C风格的强制类型转换,但是C风格的强制类型转换可能会带来一些隐患,出现一些难以察觉的问题,所以C++又推出了四种新的强制类型转换来替代C风格的强制类型转换,降低使用风险。
-
在C++中,新增了四个关键字static_cast、const_cast、reinterpret_cast和dynamic_cast,用于支持C++风格的强制类型转换。
-
C++风格的强制类型转换能更清晰的表明它们要干什么,程序员只要看一眼这样的代码,立即能知道强制转换的目的,并且,在多态场景也只能使用C++风格的强制类型转换。
一、static_cast
- static_cast是最常用的C++风格的强制类型转换,主要是为了执行那些较为合理的强制类型转换,使用格式如下:
static_cast<目标类型>(表达式);
- 用于基本内置数据类型之间的转换
C风格:编译器可能会提示警告信息。
static_cast:不会提示警告信息。
#include <iostream>
using namespace std;
int main(int argc, char* argv[])
{
char cc = 'X';
float ff = cc; // 隐式转换,不会告警。
float ffc = static_cast<float>(cc); // 显式地使用static_cast进行强制类型转换,不会告警。
double dd = 3.38;
long ll = dd; // 隐式转换,会告警。
long llc = static_cast<long>(dd); // 显式地使用static_cast进行强制类型转换,不会告警。
}
- 用于指针之间的转换
C风格:可用于各种类型指针之间的转换。
static_cast:各种类型指针之间的不允许转换,必须借助void*类型作为中间介质。
#include <iostream>
int main(int argc, char* argv[])
{
int type_int = 10;
float* float_ptr1 = (float *) & type_int; // int* -> float* 隐式转换无效
// float* float_ptr2 = static_cast<float*>(&type_int); // int* -> float* 使用static_cast转换无效
char* char_ptr1 = (char *) & type_int; // int* -> char* 隐式转换无效
// char* char_ptr2 = static_cast<char*>(&type_int); // int* -> char* 使用static_cast转换无效
void* void_ptr = &type_int; // 任何指针都可以隐式转换为void*
float* float_ptr3 = (float *)void_ptr; // void* -> float* 隐式转换无效
float* float_ptr4 = static_cast<float*>(void_ptr); // void* -> float* 使用static_cast转换成功
char* char_ptr3 = (char *)void_ptr; // void* -> char* 隐式转换无效
char* char_ptr4 = static_cast<char*>(void_ptr); // void* -> char* 使用static_cast转换成功
}
3)不能转换掉expression的const或volitale属性
#include <iostream>
int main(int argc, char* argv[])
{
int temp = 10;
const int* a_const_ptr = &temp;
int* b_const_ptr = static_cast<int*>(a_const_ptr); // const int* -> int* 无效
const int a_const_ref = 10;
int& b_const_ref = static_cast<int&>(a_const_ref); // const int& -> int& 无效
volatile int* a_vol_ptr = &temp;
int* b_vol_ptr = static_cast<int*>(a_vol_ptr); // volatile int* -> int* 无效
volatile int a_vol_ref = 10;
int& b_vol_ref = static_cast<int&>(a_vol_ref); // volatile int& -> int& 无效
**
**
}
五十三、C++类型转换-static_cast
C风格的类型转换很容易理解:
语法:(目标类型)表达式或目标类型(表达式);
-
C++认为C风格的类型转换过于松散,可能会带来隐患,不够安全。
-
C++推出了新的类型转换来替代C风格的类型转换,采用更严格的语法检查,降低使用风险。
-
C++新增了四个关键字static_cast、const_cast、reinterpret_cast和dynamic_cast,用于支持C++风格的类型转换。
-
C++的类型转换只是语法上的解释,本质上与C风格的类型转换没什么不同,C语言做不到事情的C++也做不到。
语法:
static_cast<目标类型>(表达式);
const_cast<目标类型>(表达式);
reinterpret_cast<目标类型>(表达式);
dynamic_cast<目标类型>(表达式);
一、static_cast
- 用于内置数据类型之间的转换
除了语法不同,C和C++没有区别。
#include <iostream>
using namespace std;
int main(int argc, char* argv[])
{
int ii = 3;
long ll = ii; // 绝对安全,可以隐式转换,不会出现警告。
double dd = 1.23;
long ll1 = dd; // 可以隐式转换,但是,会出现可能丢失数据的警告。
long ll2 = (long)dd; // C风格:显式转换,不会出现警告。
long ll3 = static_cast<long>(dd); // C++风格:显式转换,不会出现警告。
cout << "ll1=" << ll1 << ",ll2=" << ll2 << ",ll3=" << ll3 << endl;
}
2.用于指针之间的转换
C风格可以把不同类型的指针进行转换。
C++不可以,需要借助void *。
**
#include <iostream>
using namespace std;
void func(void* ptr) { // 其它类型指针 -> void *指针 -> 其它类型指针
double* pp = static_cast<double*>(ptr);
}
int main(int argc, char* argv[])
{
int ii = 10;
//double* pd1 = ⅈ // 错误,不能隐式转换。
double* pd2 = (double*) ⅈ // C风格,强制转换。
//double* pd3 = static_cast<double*>(&ii); // 错误,static_cast不支持不同类型指针的转换。
void* pv = ⅈ // 任何类型的指针都可以隐式转换成void*。
double* pd4 = static_cast<double*>(pv); // static_cast可以把void *转换成其它类型的指针。
func(&ii);
}
二、const_cast
static_cast不能丢掉指针(引用)的const和volitale属性,const_cast可以。
示例:
#include <iostream>
using namespace std;
void func(int *ii)
{}
int main(int argc, char* argv[])
{
const int *aa=nullptr;
int *bb = (int *)aa; // C风格,强制转换,丢掉const限定符。
int* cc = const_cast<int*>(aa); // C++风格,强制转换,丢掉const限定符。
func(const_cast<int *>(aa));
}
三、reinterpret_cast
static_cast不能用于转换不同类型的指针(引用)(不考虑有继承关系的情况),reinterpret_cast可以。
reinterpret_cast的意思是重新解释,能够将一种对象类型转换为另一种,不管它们是否有关系。
语法:reinterpret_cast<目标类型>(表达式);
<目标类型>和(表达式)中必须有一个是指针(引用)类型。
reinterpret_cast不能丢掉(表达式)的const或volitale属性。
应用场景:
1)reinterpret_cast的第一种用途是改变指针(引用)的类型。
2)reinterpret_cast的第二种用途是将指针(引用)转换成整型变量。整型与指针占用的字节数必须一致,否则会出现警告,转换可能损失精度。
3)reinterpret_cast的第三种用途是将一个整型变量转换成指针(引用)。
示例:
#include <iostream>
using namespace std;
void func(void* ptr) {
long long ii = reinterpret_cast<long long>(ptr);
cout << "ii=" << ii << endl;
}
int main(int argc, char* argv[])
{
long long ii = 10;
func(reinterpret_cast<void *>(ii));
}
五十四、string容器
string是字符容器,内部维护了一个动态的字符数组。
与普通的字符数组相比,string容器有三个优点:
1)使用的时候,不必考虑内存分配和释放的问题;
2)动态管理内存(可扩展);
3)提供了大量操作容器的API。缺点是效率略有降低,占用的资源也更多。
string类是std::basic_string类模板的一个具体化版本的别名。
using std::string=std::basic_string<char, std::char_traits
一、构造和析构
静态常量成员string::npos为字符数组的最大长度(通常为unsigned int的最大值);
NBTS(null-terminated string):C风格的字符串(以空字符0结束的字符串)。
string类有七个构造函数(C++11新增了两个):
1)string(); // 创建一个长度为0的string对象(默认构造函数)。
2)string(const char *s); // 将string对象初始化为s指向的NBTS(转换函数)。
3)string(const string &str); // 将string对象初始化为str(拷贝构造函数)。
4)string(const char *s,size_t n); // 将string对象初始化为s指向的地址后n字节的内容。
5)string(const string &str,size_t pos=0,size_t n=npos); // 将sring对象初始化为str从位置pos开始到结尾的字符(或从位置pos开始的n个字符)。
6)template
7)string(size_t n,char c); // 创建一个由n个字符c组成的string对象。
析构函数~string()释放内存空间。
C++11新增的构造函数:
1)string(string && str) noexcept:它将一个string对象初始化为string对象str,并可能修改str(移动构造函数)。
2)string(initializer_list
例如:string ss = { 'h','e','l','l','o' };
示例:
#include <iostream>
using namespace std;
int main()
{
// 1)string():创建一个长度为0的string对象(默认构造函数)。
string s1; // 创建一个长度为0的string对象
cout << "s1=" << s1 << endl; // 将输出s1=
cout << "s1.capacity()=" << s1.capacity() << endl; // 返回当前容量,可以存放字符的总数。
cout << "s1.size()=" << s1.size() << endl; // 返回容器中数据的大小。
cout << "容器动态数组的首地址=" << (void *)s1.c_str() << endl;
s1 = "xxxxxxxxxxxxxxxxxxxx";
cout << "s1.capacity()=" << s1.capacity() << endl; // 返回当前容量,可以存放字符的总数。
cout << "s1.size()=" << s1.size() << endl; // 返回容器中数据的大小。
cout << "容器动态数组的首地址=" << (void *)s1.c_str() << endl;
// 2)string(const char *s):将string对象初始化为s指向的NBTS(转换函数)。
string s2("hello world");
cout << "s2=" << s2 << endl; // 将输出s2=hello world
string s3 = "hello world";
cout << "s3=" << s3 << endl; // 将输出s3=hello world
// 3)string(const string & str):将string对象初始化为str(拷贝构造函数)。
string s4(s3); // s3 = "hello world";
cout << "s4=" << s4 << endl; // 将输出s4=hello world
string s5 = s3;
cout << "s5=" << s5 << endl; // 将输出s5=hello world
// 4)string(const char* s, size_t n):将string对象初始化为s指向的NBTS的前n个字符,即使超过了NBTS结尾。
string s6("hello world", 5);
cout << "s6=" << s6 << endl; // 将输出s6=hello
cout << "s6.capacity()=" << s6.capacity() << endl; // 返回当前容量,可以存放字符的总数。
cout << "s6.size()=" << s6.size() << endl; // 返回容器中数据的大小。
string s7("hello world", 50);
cout << "s7=" << s7 << endl; // 将输出s7=hello未知内容
cout << "s7.capacity()=" << s7.capacity() << endl; // 返回当前容量,可以存放字符的总数。
cout << "s7.size()=" << s7.size() << endl; // 返回容器中数据的大小。
// 5)string(const string & str, size_t pos = 0, size_t n = npos):
// 将string对象初始化为str从位置pos开始到结尾的字符,或从位置pos开始的n个字符。
string s8(s3, 3, 5); // s3 = "hello world";
cout << "s8=" << s8 << endl; // 将输出s8=lo wo
string s9(s3, 3);
cout << "s9=" << s9 << endl; // 将输出s9=lo world
cout << "s9.capacity()=" << s9.capacity() << endl; // 返回当前容量,可以存放字符的总数。
cout << "s9.size()=" << s9.size() << endl; // 返回容器中数据的大小。
string s10("hello world", 3, 5);
cout << "s10=" << s10 << endl; // 将输出s10=lo wo
string s11("hello world", 3); // 注意:不会用构造函数5),而是用构造函数4)
cout << "s11=" << s11 << endl; // 将输出s11=hel
// 6)template<class T> string(T begin, T end):将string对象初始化为区间[begin, end]内的字符,
// 其中begin和end的行为就像指针,用于指定位置,范围包括begin在内,但不包括end。
// 7)string(size_t n, char c):创建一个由n个字符c组成的string对象。
string s12(8, 'x');
cout << "s12=" << s12 << endl; // 将输出s12=xxxxxxxx
cout << "s12.capacity()=" << s12.capacity() << endl; // s12.capacity()=15
cout << "s12.size()=" << s12.size() << endl; // s12.size()=8
string s13(30, 0);
cout << "s13=" << s13 << endl; // 将输出s13=
cout << "s13.capacity()=" << s13.capacity() << endl; // s13.capacity()=31
cout << "s13.size()=" << s13.size() << endl; // s12.size()=30
}
示例2:
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
int main()
{
char cc[8]; // 在栈上分配8字节的内存空间。
// 把cc的内存空间用于字符串。
strcpy(cc, "hello");
cout << "cc=" << cc << endl << endl;
// 把cc的内存空间用于int型整数。
int* a, * b;
a = (int *)cc; // 前4个字节的空间用于整数a。
b = (int *)cc + 4; // 后4个字节的空间用于整数b。
*a = 12345;
*b = 54321;
cout << "*a=" << *a << endl;
cout << "*b=" << *b << endl << endl;
// 把cc的内存空间用于double。
double* d = (double*)cc;
*d = 12345.7;
cout << "*d=" << *d << endl << endl;
// 把cc的内存空间用于结构体。
struct stt
{
int a;
char b[4];
}*st;
st = (struct stt*)cc;
st->a = 38;
strcpy(st->b, "abc");
cout << "st->a=" << st->a << endl;
cout << "st->b=" << st->b << endl << endl;
// void* malloc(size_t size);
//char* cc1 = (char*)malloc(8);
//int* cc1 = (int*)malloc(8);
}
示例3:
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
int main()
{
struct st_girl { // 超女结构体。
int bh;
char name[30];
bool yz;
double weight;
string memo;
} girl;
cout << "超女结构体的大小:" << sizeof(struct st_girl) << endl;
string buffer; // 创建一个空的string容器buffer。
// 生成10名超女的信息,存入buffer中。
for (int ii = 1; ii <= 10; ii++)
{
// 对超女结构体成员赋值。
memset(&girl, 0, sizeof(struct st_girl));
girl.bh = ii;
sprintf(girl.name, "西施%02d", ii);
girl.yz = true;
girl.weight = 48.5 + ii;
girl.memo = "中国历史第一美女。";
// 把超女结构追加到buffer中。
buffer.append((char*)&girl, sizeof(struct st_girl));
}
cout << "buffer.capacity()=" << buffer.capacity() << endl; // 显示容量。
cout << "buffer.size()=" << buffer.size() << endl; // 显示实际大小。
// 用一个循环,把buffer容器中全部的数据取出来。
for (int ii = 0; ii < buffer.size() / sizeof(struct st_girl); ii++)
{
memset(&girl, 0, sizeof(struct st_girl)); // 初始化超女结构体。
// 把容器中的数据复制到超女结构体。
memcpy(&girl , buffer.data() + ii * sizeof(struct st_girl), sizeof(struct st_girl));
// buffer.copy((char*)&girl, sizeof(struct st_girl), ii * sizeof(struct st_girl));
// 显示超女结构体成员的值。
cout << "bh=" << girl.bh << ",name=" << girl.name << ",yz=" << girl.yz << ",weight="
<< girl.weight << ",memo=" << girl.memo << endl;
}
}
二、特性操作
size_t max_size() const; // 返回string对象的最大长度string::npos,此函数意义不大。
size_t capacity() const; // 返回当前容量,可以存放字符的总数。
size_t length() const; // 返回容器中数据的大小(字符串语义)。
size_t size() const; // 返回容器中数据的大小(容器语义)。
bool empty() const; // 判断容器是否为空。
void clear(); // 清空容器,清空后,size()将返回0。
void shrink_to_fit(); // 将容器的容量降到实际大小(需要重新分配内存)。
void reserve( size_t size=0); // 将容器的容量设置为至少size。
void resize(size_t len,char c=0); // 把容器的实际大小置为len,如果len<实际大小,会截断多出的部分;如果len>实际大小,就用字符c填充。resize()后,length()和size()将返回len。
三、字符操作
char &operator[](size_t n);
const char &operator[](size_t n) const; // 只读。
char &at(size_t n);
const char &at(size_t n) const; // 只读。
operator[]和at()返回容器中的第n个元素,但at函数提供范围检查,当越界时会抛出out_of_range异常,operator[]不提供范围检查。
const char *c_str() const; // 返回容器中动态数组的首地址,语义:寻找以null结尾的字符串。
const char *data() const; // 返回容器中动态数组的首地址,语义:只关心容器中的数据。
int copy(char *s, int n, int pos = 0) const; // 把当前容器中的内容,从pos开始的n个字节拷贝到s中,返回实际拷贝的数目。
四、赋值操作
给已存在的容器赋值,将覆盖容器中原有的内容。
1)string &operator=(const string &str); // 把容器str赋值给当前容器。
2)string &assign(const char *s); // 将string对象赋值为s指向的NBTS。
3)string &assign(const string &str); // 将string对象赋值为str。
4)string &assign(const char *s,size_t n); // 将string对象赋值为s指向的地址后n字节的内容。
5)string &assign(const string &str,size_t pos=0,size_t n=npos); // 将sring对象赋值为str从位置pos开始到结尾的字符(或从位置pos开始的n个字符)。
6)template<class T> string &assign(T begin,T end); // 将string对象赋值为区间[begin,end]内的字符。
7)string &assign(size_t n,char c); // 将string对象赋值为由n个字符c。
五、连接操作
把内容追加到已存在容器的后面。
1)string &operator+=(const string &str); //把容器str连接到当前容器。
2)string &append(const char *s); // 把指向s的NBTS连接到当前容器。
3)string &append(const string &str); // 把容器str连接到当前容器。
4)string &append(const char *s,size_t n); // 将s指向的地址后n字节的内容连接到当前容器。
5)string &append(const string &str,size_t pos=0,size_t n=npos); // 将str从位置pos开始到结尾的字符(或从位置pos开始的n个字符)连接到当前容器。
6)template<class T> string &append (T begin,T end); // 将区间[begin,end]内的字符连接到容器。
7)string &append(size_t n,char c); // 将n个字符c连接到当前容器。
六、交换操作
void swap(string &str); // 把当前容器与str交换。
如果数据量很小,交换的是动态数组中的内容,如果数据量比较大,交换的是动态数组的地址。
七、截取操作
string substr(size_t pos = 0,size_t n = npos) const; // 返回pos开始的n个字节组成的子容器
八、比较操作
bool operator==(const string &str1,const string &str2) const; // 比较两个字符串是否相等。
int compare(const string &str) const; // 比较当前字符串和str1的大小。
int compare(size_t pos, size_t n,const string &str) const; // 比较当前字符串从pos开始的n个字符组成的字符串与str的大小。
int compare(size_t pos, size_t n,const string &str,size_t pos2,size_t n2)const; // 比较当前字符串从pos开始的n个字符组成的字符串与str中pos2开始的n2个字符组成的字符串的大小。
以下几个函数用于和C风格字符串比较。
int compare(const char *s) const;
int compare(size_t pos, size_t n,const char *s) const;
int compare(size_t pos, size_t n,const char *s, size_t pos2) const;
compre()函数有异常,慎用
九、查找操作
size_t find(const string& str, size_t pos = 0) const;
size_t find(const char* s, size_t pos = 0) const;
size_t find(const char* s, size_t pos, size_t n) const;
size_t find(char c, size_t pos = 0) const;
size_t rfind(const string& str, size_t pos = npos) const;
size_t rfind(const char* s, size_t pos = npos) const;
size_t rfind(const char* s, size_t pos, size_t n) const;
size_t rfind(char c, size_t pos = npos) const;
size_t find_first_of(const string& str, size_t pos = 0) const;
size_t find_first_of(const char* s, size_t pos = 0) const;
size_t find_first_of(const char* s, size_t pos, size_t n) const;
size_t find_first_of(char c, size_t pos = 0) const;
size_t find_last_of(const string& str, size_t pos = npos) const;
size_t find_last_of(const char* s, size_t pos = npos) const;
size_t find_last_of(const char* s, size_t pos, size_t n) const;
size_t find_last_of(char c, size_t pos = npos) const;
size_t find_first_not_of(const string& str, size_t pos = 0) const;
size_t find_first_not_of(const char* s, size_t pos = 0) const;
size_t find_first_not_of(const char* s, size_t pos, size_t n) const;
size_t find_first_not_of(char c, size_t pos = 0) const;
size_t find_last_not_of(const string& str, size_t pos = npos) const;
size_t find_last_not_of(const char* s, size_t pos = npos) const;
size_t find_last_not_of(const char* s, size_t pos, size_t n) const;
size_t find_last_not_of(char c, size_t pos = npos) const;
十、替换操作
string& replace(size_t pos, size_t len, const string& str);
string& replace(size_t pos, size_t len, const string& str, size_t subpos, size_t sublen = npos);
string& replace(size_t pos, size_t len, const char* s);
string& replace(size_t pos, size_t len, const char* s, size_t n);
string& replace(size_t pos, size_t len, size_t n, char c);
以下函数意义不大。
string& replace(iterator i1, iterator i2, const string& str);
string& replace(iterator i1, iterator i2, const char* s);
string& replace(iterator i1, iterator i2, const char* s, size_t n);
string& replace(iterator i1, iterator i2, size_t n, char c);
template <class InputIterator>
string& replace(iterator i1, iterator i2, InputIterator first, InputIterator last);
十一、插入操作
string& insert(size_t pos, const string& str);
string& insert(size_t pos, const string& str, size_t subpos, size_t sublen = npos);
string& insert(size_t pos, const char* s);
string& insert(size_t pos, const char* s, size_t n);
string& insert(size_t pos, size_t n, char c);
以下函数意义不大。
iterator insert(iterator p, size_t n, char c);
iterator insert(iterator p, char c);
template <class InputIterator>
iterator insert(iterator p, InputIterator first, InputIterator last);
十二、删除操作
string &erase(size_t pos = 0, size_t n = npos); // 删除pos开始的n个字符。
以下函数意义不大。
iterator erase(iterator it); // 删除it指向的字符,返回删除后迭代器的位置。
iterator erase(iterator first, iterator last); / /删除[first,last)之间的所有字符,返回删除后迭代器的位置。
五十四、vector容器
vector容器封装了动态数组。
包含头文件: #include
vector类模板的声明:
template<class T, class Alloc = allocator<T>>
class vector{
private:
T *start_;
T *finish_;
T *end_;
……
}
分配器
各种STL容器模板都接受一个可选的模板参数,该参数指定使用哪个分配器对象来管理内存
如果省略该模板参数的值,将默认使用allocator
一、构造函数
1)vector(); // 创建一个空的vector容器。
2)vector(initializer_list<T> il); // 使用统一初始化列表。
3)vector(const vector<T>& v); // 拷贝构造函数。
4)vector(Iterator first, Iterator last); // 用迭代器创建vector容器。
5)vector(vector<T>&& v); // 移动构造函数(C++11标准)。
6)explicit vector(const size_t n); // 创建vector容器,元素个数为n(容量和实际大小都是n)。
7)vector(const size_t n, const T& value); // 创建vector容器,元素个数为n,值均为value。
析构函数~vector()释放内存空间。
二、特性操作
size_t max_size() const; // 返回容器的最大长度,此函数意义不大。
size_t capacity() const; // 返回容器的容量。
size_t size() const; // 返回容器的实际大小(已使用的空间)。
bool empty() const; // 判断容器是否为空。
void clear(); // 清空容器。
void reserve(size_t size); // 将容器的容量设置为至少size。
void shrink_to_fit(); // 将容器的容量降到实际大小(需要重新分配内存)。
void resize(size_t size); // 把容器的实际大小置为size。
void resize(size_t size,const T &value); // 把容器的实际大小置为size,如果size<实际大小,会截断多出的部分;如果size>实际大小,就用value填充。
三、元素操作
T &operator[](size_t n);
const T &operator[](size_t n) const; // 只读。
T &at(size_t n);
const T &at(size_t n) const; // 只读。
T *data(); // 返回容器中动态数组的首地址。
const T *data() const; // 返回容器中动态数组的首地址。
T &front(); // 第一个元素。
const T &front(); // 第一个元素,只读。
const T &back(); // 最后一个元素,只读。
T &back(); // 最后一个元素。
四、赋值操作
给已存在的容器赋值,将覆盖容器中原有的内容。
1)vector &operator=(const vector<T> &v); // 把容器v赋值给当前容器。
2)vector &operator=(initializer_list<T> il); // 用统一初始化列表给当前容器赋值。
3)void assign(initializer_list<T> il); // 使用统一初始化列表赋值。
4)void assign(Iterator first, Iterator last); // 用迭代器赋值。
5)void assign(const size_t n, const T& value); // 把n个value给容器赋值。
示例:
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> v1;
v1 = { 1,2,3,4,5 }; // 使用统一初始化列表赋值。
for (int ii = 0; ii < v1.size(); ii++) cout << v1[ii] << " ";
cout << endl;
vector<int> v2;
v2 = v1; // 把容器v1赋值给当前容器。
for (int ii = 0; ii < v2.size(); ii++) cout << v2[ii] << " ";
cout << endl;
vector<int> v3;
v3.assign({ 1,2,3,4,5 }); // 用assign()函数给当前容器赋值,参数是统一初始化列表。
for (int ii = 0; ii < v3.size(); ii++) cout << v3[ii] << " ";
cout << endl;
}
五、交换操作
void swap(vector
交换的是动态数组的地址。
六、比较操作
bool operator == (const vector<T> & v) const;
bool operator != (const vector<T> & v) const;
七、插入和删除
1)void push_back(const T& value); // 在容器的尾部追加一个元素。
2)void emplace_back(…); // 在容器的尾部追加一个元素,…用于构造元素。C++11
3)iterator insert(iterator pos, const T& value); // 在指定位置插入一个元素,返回指向插入元素的迭代器。
4)iterator emplace (iterator pos, …); // 在指定位置插入一个元素,…用于构造元素,返回指向插入元素的迭代器。C++11
5)iterator insert(iterator pos, iterator first, iterator last); // 在指定位置插入一个区间的元素,返回指向第一个插入元素的迭代器。
6)void pop_back(); // 从容器尾部删除一个元素。
7)iterator erase(iterator pos); // 删除指定位置的元素,返回下一个有效的迭代器。
8)iterator erase(iterator first, iterator last); // 删除指定区间的元素,返回下一个有效的迭代器。
示例:
#include <iostream>
#include <vector>
using namespace std;
class AA
{
public:
int m_bh; // 编号。
string m_name; // 姓名。
AA() // 默认构造函数。
{
//cout << "默认构造函数AA()。\n";
}
AA(const int &bh,const string& name) : m_bh(bh),m_name(name) // 有两个参数的构造函数。
{
//cout << "构造函数,name=" << m_name << "。\n";
}
AA(const AA& g) :m_bh(g.m_bh), m_name(g.m_name) // 拷贝构造函数。
{
//cout << "拷贝构造函数,name=" << m_name << "。\n";
}
//~AA() { cout << "析构函数。\n"; }
};
int main()
{
vector<AA> v(10);
cout << v.size() << v.data() << endl;
//AA a(18,"西施");
//v.push_back(a);
//v.emplace_back(a);
v.emplace_back(18,"西施");
cout << "bh=" << v[0].m_bh << ",name=" << v[0].m_name << endl;
}
八、vector的嵌套
vector容器可以嵌套使用。
示例:
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<vector<int>> vv; // 创建一个vector容器vv,元素的数据类型是vector<int>。
vector<int> v; // 创建一个容器v,它将作为容器vv的元素。
v = { 1,2,3,4,5 }; // 用统一初始化列表给v赋值。
vv.push_back(v); // 把容器v作为元素追加到vv中。
v = { 11,12,13,14,15,16,17 }; // 用统一初始化列表给v赋值。
vv.push_back(v); // 把容器v作为元素追加到vv中。
v = { 21,22,23 }; // 用统一初始化列表给v赋值。
vv.push_back(v); // 把容器v作为元素追加到vv中。
// 用嵌套的循环,把vv容器中的数据显示出来。
for (int ii = 0; ii < vv.size(); ii++)
{
for (int jj = 0; jj < vv[ii].size(); jj++)
cout << vv[ii][jj] << " "; // 像二维数组一样使用容器vv。
cout << endl;
}
}
九、注意事项
1)迭代器失效的问题
resize()、reserve()、assign()、push_back()、pop_back()、insert()、erase()等函数会引起vector容器的动态数组发生变化,可能导致vector迭代器失效。
五十五、迭代器
迭代器是访问容器中元素的通用方法。
如果使用迭代器,不同的容器,访问元素的方法是相同的。
迭代器支持的基本操作:赋值(=)、解引用(*)、比较(==和!=)、从左向右遍历(++)。
一般情况下,迭代器是指针和移动指针的方法。
迭代器有五种分类:
1)正向迭代器
只能使用++运算符从左向右遍历容器,每次沿容器向右移动一个元素。
容器名<元素类型>::iterator 迭代器名; // 正向迭代器。
容器名<元素类型>::const_iterator 迭代器名; // 常正向迭代器。
相关的成员函数:
iterator begin();
const_iterator begin();
const_iterator cbegin(); // 配合auto使用。
iterator end();
const_iterator end();
const_iterator cend();
2)双向迭代器
具备正向迭代器的功能,还可以反向(从右到左)遍历容器(也是用++),不管是正向还是反向遍历,都可以用--让迭代器后退一个元素。
容器名<元素类型>:: reverse_iterator 迭代器名; // 反向迭代器。
容器名<元素类型>:: const_reverse_iterator 迭代器名; // 常反向迭代器。
相关的成员函数:
reverse_iterator rbegin();
const_reverse_iterator crbegin();
reverse_iterator rend();
const_reverse_iterator crend();
3)随机访问迭代器
具备双向迭代器的功能,还支持以下操作:
用于比较两个迭代器相对位置的关系运算(<、<=、>、>=)。
迭代器和一个整数值的加减法运算(+、+=、-、-=)。
支持下标运算(iter[n])。
数组的指针是纯天然的随机访问迭代器。
4)输入和输出迭代器
这两种迭代器比较特殊,它们不是把容器当做操作对象,而是把输入/输出流作为操作对象。
示例:
#include <iostream>
#include <vector>
#include <list>
using namespace std;
struct Node // 单链表的结点。
{
int item;
Node* next;
};
int* find_(int* arr, int n, const int& val) // 在整型数组arr中查找值为val的元素。
{
for (int ii = 0; ii < n; ii++) // 遍历数组。
if (arr[ii] == val) return &arr[ii]; // 如果找到了,返回数组中元素的地址。
return nullptr;
}
int* find_(int* begin, int* end, const int& val) // 在整型数组的区间中查找值为val的元素。
{
for (int* iter = begin; iter != end; iter++) // 遍历查找区间。
if (*iter == val) return iter; // 如果找到了元素,返回区间中的位置。
return nullptr;
}
Node* find_(Node* begin, Node* end, const Node& val) // 在单链表中查找值为val的元素。
{
for (Node * iter = begin; iter != end; iter = iter->next) // 遍历链表。
if (iter->item == val.item) return iter; // 如果找到了,返回链表中结点的地址。
return nullptr;
}
// 查找元素的算法。
template<typename T1, typename T2>
// begin-查找区间开始的位置;end-查找区间结束的位置;val-待查找的值。
T1 find_(T1 begin, T1 end, const T2 &val)
{
for (T1 iter = begin; iter != end; iter++) // 遍历查找区间。
if (*iter == val) return iter; // 如果找到了元素,返回区间中的位置。
return end;
}
int main()
{
// 在vector容器中查找元素。
vector<int> vv = { 1,2,3,4,5 }; // 初始化vector容器。
vector<int>::iterator it2 = find_(vv.begin(), vv.end(), 3);
if (it2 != vv.end()) cout << "查找成功。\n";
else cout << "查找失败。\n";
// 在list容器中查找元素。
list<int> ll = {1,2,3,4,5}; // 初始化vector容器。
list<int>::iterator it3 = find_(ll.begin(), ll.end(), 3);
if (it3 != ll.end()) cout << "查找成功。\n";
else cout << "查找失败。\n";
}
五十五、基于范围的for循环
对于一个有范围的集合来说,在程序代码中指定循环的范围有时候是多余的,还可能犯错误。
C++11中引入了基于范围的for循环。
语法:
for (迭代的变量 : 迭代的范围)
{
// 循环体。
}
注意:
1)迭代的范围可以是数组名、容器名、初始化列表或者可迭代的对象(支持begin()、end()、++、==)。
2)数组名传入函数后,已退化成指针,不能作为容器名。
3)如果容器中的元素是结构体和类,迭代器变量应该申明为引用,加const约束表示只读。
4)注意迭代器失效的问题
示例:
#include <iostream>
#include <vector>
using namespace std;
class AA
{
public:
string m_name;
AA() { cout << "默认构造函数AA()。\n"; }
AA(const string& name) : m_name(name) { cout << "构造函数,name=" << m_name << "。\n"; }
AA(const AA& a) : m_name(a.m_name) { cout << "拷贝构造函数,name=" << m_name << "。\n"; }
AA& operator=(const AA& a) { m_name = a.m_name; cout << "赋值函数,name=" << m_name << "。\n"; return *this; }
~AA() { cout << "析构函数,name=" << m_name<<"。\n"; }
};
int main()
{
vector<int> vv = { 1,2,3,4,5,6,7,8,9,10 };
//for (auto it = vv.begin(); it != vv.end(); it++) // 用迭代器遍历容器vv。
//{
// cout << *it << " ";
//}
//cout << endl;
for (auto val : vv) // 用基于范围的for循环遍历数组vv。
{
cout << val << " ";
vv.push_back(10);
}
cout << endl;
/*vector<AA> v;
cout << "1111,v.capacity()=" << v.capacity() << "\n";
v.emplace_back("西施");
cout << "2222,v.capacity()=" << v.capacity() << "\n";
v.emplace_back("冰冰");
cout << "3333,v.capacity()=" << v.capacity() << "\n";
v.emplace_back("幂幂");
cout << "4444,v.capacity()=" << v.capacity() << "\n";
for (const auto &a : v)
cout << a.m_name << " ";
cout << endl;*/
}
五十六、list容器
list容器封装了双链表。
包含头文件: #include
list类模板的声明:
template<class T, class Alloc = allocator<T>>
class list{
private:
iterator head;
iterator tail;
……
}
构造函数
1)list(); // 创建一个空的list容器。
2)list(initializer_list<T> il); // 使用统一初始化列表。
3)list(const list<T>& l); // 拷贝构造函数。
4)list(Iterator first, Iterator last); // 用迭代器创建list容器。
5)list(list<T>&& l); // 移动构造函数(C++11标准)。
6)explicit list(const size_t n); // 创建list容器,元素个数为n。
7)list(const size_t n, const T& value); // 创建list容器,元素个数为n,值均为value。
析构函数~list()释放内存空间。
示例:
#include <iostream>
#include <vector>
#include <list>
using namespace std;
int main()
{
// 1)list(); // 创建一个空的list容器。
list<int> l1;
// cout << "li.capacity()=" << l1.capacity() << endl; // 链表没有容量说法。
cout << "li.size()=" << l1.size() << endl;
// 2)list(initializer_list<T> il); // 使用统一初始化列表。
list<int> l2({ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 });
// list<int> l2={ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
// list<int> l2 { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
for (int value : l2) // 用基于范围的for循环遍历容器。
cout << value << " ";
cout << endl;
// 3)list(const list<T>& l); // 拷贝构造函数。
list<int> l3(l2);
// list<int> l3=l2;
for (int value : l3)
cout << value << " ";
cout << endl;
// 4)list(Iterator first, Iterator last); // 用迭代器创建list容器。
list<int> l4(l3.begin(), l3.end()); // 用list容器的迭代器。
for (int value : l4)
cout << value << " ";
cout << endl;
vector<int> v1 = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; // 创建vector容器。
list<int> l5(v1.begin() + 2, v1.end() - 3); // 用vector容器的迭代器创建list容器。
for (int value : l5)
cout << value << " ";
cout << endl;
int a1[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; // 创建数组。
list<int> l6(a1 + 2, a1 + 10 - 3); // 用数组的指针作为迭代器创建list容器。
for (int value : l6)
cout << value << " ";
cout << endl;
char str[] = "hello world"; // 定义C风格字符串。
string s1(str + 1, str + 7); // 用C风格字符串创建string容器。
for (auto value : s1) // 遍历string容器。
cout << value << " ";
cout << endl;
cout << s1 << endl; // 以字符串的方式显示string容器。
vector<int> v2(l3.begin(), l3.end()); // 用list迭代器创建vector容器。
for (auto value : v2) // 遍历vector容器。
cout << value << " ";
cout << endl;
}
特性操作
size_t max_size() const; // 返回容器的最大长度,此函数意义不大。
size_t size() const; // 返回容器的实际大小(已使用的空间)。
bool empty() const; // 判断容器是否为空。
void clear(); // 清空容器。
void resize(size_t size); // 把容器的实际大小置为size。
void resize(size_t size,const T &value); // 把容器的实际大小置为size,如果size<实际大小,会截断多出的部分;如果size>实际大小,就用value填充。
三、元素操作
T &front(); // 第一个元素。
const T &front(); // 第一个元素,只读。
const T &back(); // 最后一个元素,只读。
T &back(); // 最后一个元素。
四、赋值操作
给已存在的容器赋值,将覆盖容器中原有的内容。
1)list &operator=(const list<T> &l); // 把容器l赋值给当前容器。
2)list &operator=(initializer_list<T> il); // 用统一初始化列表给当前容器赋值。
3)list assign(initializer_list<T> il); // 使用统一初始化列表赋值。
4)list assign(Iterator first, Iterator last); // 用迭代器赋值。
5)void assign(const size_t n, const T& value); // 把n个value给容器赋值。
五、交换、反转、排序、归并
void swap(list<T> &l); // 把当前容器与l交换,交换的是链表结点的地址。
void reverse(); // 反转链表。
void sort(); // 对容器中的元素进行升序排序。
void sort(_Pr2 _Pred); // 对容器中的元素进行排序,排序的方法由_Pred决定(二元函数)。
void merge(list<T> &l); // 采用归并法合并两个已排序的list容器,合并后的list容器仍是有序的。
示例:
#include <iostream>
#include <vector>
#include <list>
using namespace std;
int main()
{
list<int> la = { 8,2,6,4,5 };
for (auto &val : la)
cout << val << " ";
cout << endl;
la.reverse(); // 反转链表。
for (auto& val : la)
cout << val << " ";
cout << endl;
la.sort(); // 链表排序。
for (auto& val : la)
cout << val << " ";
cout << endl;
list<int> lb = { 3,7,9,10,1 };
lb.sort(); // 链表排序。
la.merge(lb); // 归并链表。
for (auto& val : la)
cout << val << " ";
cout << endl;
}
六、比较操作
bool operator == (const vector<T> & l) const;
bool operator != (const vector<T> & l) const;
七、插入和删除
1)void push_back(const T& value); // 在链表的尾部追加一个元素。
2)void emplace_back(…); // 在链表的尾部追加一个元素,…用于构造元素。C++11
3)iterator insert(iterator pos, const T& value); // 在指定位置插入一个元素,返回指向插入元素的迭代器。
4)iterator emplace (iterator pos, …); // 在指定位置插入一个元素,…用于构造元素,返回指向插入元素的迭代器。C++11
5)iterator insert(iterator pos, iterator first, iterator last); // 在指定位置插入一个区间的元素,返回指向第一个插入元素的迭代器。
6)void pop_back(); // 从链表尾部删除一个元素。
7)iterator erase(iterator pos); // 删除指定位置的元素,返回下一个有效的迭代器。
8)iterator erase(iterator first, iterator last); // 删除指定区间的元素,返回下一个有效的迭代器。
9)push_front(const T& value); // 在链表的头部插入一个元素。
10)emplace_front(…); // 在链表的头部插入一个元素,…用于构造元素。C++11
11)splice(iterator pos, const vector<T> & l); // 把另一个链表连接到当前链表。
12)splice(iterator pos, const vector<T> & l, iterator first, iterator last); // 把另一个链表指定的区间连接到当前链表。
13)splice(iterator pos, const vector<T> & l, iterator first); // 把另一个链表从first开始的结点连接到当前链表。
14)void remove(const T& value); // 删除链表中所有值等于value的元素。
15)void remove_if(_Pr1 _Pred); // 删除链表中满足条件的元素,参数_Pred是一元函数。
16)void unique(); // 删除链表中相邻的重复元素,只保留一个。
17)void pop_front(); // 从链表头部删除一个元素。
示例:
#include <iostream>
#include <vector>
#include <list>
using namespace std;
int main()
{
list<int> la = { 8,2,6,4,5 };
for (auto& val : la) cout << val << " ";
cout << endl;
list<int> lb = { 3,7,9,10,1 };
for (auto& val : lb) cout << val << " ";
cout << endl;
auto first = lb.begin();
first++;
auto last = lb.end();
last--;
la.splice(la.begin(), lb, first, last);
for (auto& val : la) cout << val << " ";
cout << endl;
cout << "lb.size()=" << lb.size() << endl;
for (auto& val : lb) cout << val << " ";
cout << endl;
}
八、list容器的简单实现
以下demo程序简单的实现了list容器。
示例:
#include<iostream>
using namespace std;
namespace
{
template<class _Ty> class List;
template<class _Ty> class ListIterator;
// 节点类。
template<class _Ty>
class ListNode
{
friend class List<_Ty>;
friend class ListIterator<_Ty>;
public:
ListNode() :_Value(_Ty()), _Next(nullptr), _Prev(nullptr) {}
ListNode(_Ty V, ListNode* next = nullptr, ListNode* prev = nullptr) :_Value(V), _Next(next), _Prev(prev) {}
private:
_Ty _Value;
ListNode* _Next;
ListNode* _Prev;
};
// 迭代器。
template<class _Ty>
class ListIterator
{
typedef ListIterator<_Ty> _It;
public:
ListIterator() :_Ptr(nullptr) {}
ListIterator(ListNode<_Ty>* _P) :_Ptr(_P) {}
public:
_It& operator++()
{
_Ptr = _Ptr->_Next;
return *this;
}
_It& operator--()
{
_Ptr = _Ptr->Prev;
return *this;
}
_Ty& operator*()
{
return (_Ptr->_Value);
}
bool operator!=(const _It& it)
{
return _Ptr != it._Ptr;
}
bool operator==(const _It& it)
{
return _Ptr == it._Ptr;
}
ListNode<_Ty>* _Mynode()
{
return _Ptr;
}
private:
ListNode<_Ty>* _Ptr;
};
// 链表类。
template<class _Ty>
class List
{
public:
typedef ListNode<_Ty>* _Nodeptr;
typedef ListIterator<_Ty> iterator;
public:
List() :_Size(0)
{
CreateHead();
}
List(size_t n, const _Ty& x = _Ty()) :_Size(0)
{
CreateHead(),
insert(begin(), n, x);
}
List(const _Ty* first, const _Ty* last) :_Size(0)
{
CreateHead();
while (first != last)
push_back(*first++);
}
List(iterator first, iterator last)
{
CreateHead();
while (first != last)
{
push_back(*first);
++first;
}
}
List(List<_Ty>& lt) :_Size(0)
{
CreateHead();
List<_Ty>tmp(lt.begin(), lt.end());
this->swap(tmp);
}
~List()
{
clear();
delete _Head;
_Size = 0;
}
public:
void push_back(const _Ty& x)
{
insert(end(), x);
}
void pop_back()
{
erase(--end());
}
void push_front(const _Ty& x)
{
insert(begin(), x);
}
void pop_front()
{
erase(begin());
}
_Ty& front()
{
return *begin();
}
const _Ty& front()const
{
return *begin();
}
_Ty& back()
{
return *--end();
}
const _Ty& back()const
{
return *--end();
}
public:
size_t size()const
{
return _Size;
}
bool empty()const
{
return (size() == 0);
}
public:
iterator begin()
{
return iterator(_Head->_Next);
}
iterator end()
{
return iterator(_Head);
}
void clear()
{
erase(begin(), end());
}
public:
//在_P位置前插入值为x的节点
iterator insert(iterator _P, const _Ty& x)
{
_Nodeptr cur = _P._Mynode();
_Nodeptr _S = new ListNode<_Ty>(x);
_S->_Next = cur;
_S->_Prev = cur->_Prev;
_S->_Prev->_Next = _S;
_S->_Next->_Prev = _S;
_Size++;
return iterator(_S);
}
void insert(iterator _P, size_t n, const _Ty& x = _Ty())
{
while (n--)
insert(_P, x);
}
//删除_P位置的节点,返回该节点的下一个节点位置
iterator erase(iterator _P)
{
_Nodeptr cur = _P._Mynode();
_Nodeptr next_node = cur->_Next;
cur->_Prev->_Next = cur->_Next;
cur->_Next->_Prev = cur->_Prev;
delete cur;
_Size--;
return iterator(next_node);
}
iterator erase(iterator first, iterator last)
{
while (first != last)
{
first = erase(first);
}
return first;
}
void swap(List<_Ty>& lt)
{
std::swap(_Head, lt._Head);
std::swap(_Size, lt._Size);
}
protected:
void CreateHead()
{
_Head = new ListNode<_Ty>;
_Head->_Prev = _Head->_Next = _Head;
}
private:
_Nodeptr _Head;
size_t _Size;
};
};
int main()
{
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
List<int>la(arr+2, arr + 10);
List<int>lb(la);
for (auto elem:la)
cout << elem << " ";
cout << endl;
for (auto elem : lb)
cout << elem << " ";
cout << endl;
}
五十七、pair键值对
pair是类模板,一般用于表示key/value数据,其实现是结构体。
pair结构模板的定义如下:
template <class T1, class T2>
struct pair
{
T1 first; // 第一个成员,一般表示key。
T2 second; // 第二个成员,一般表示value。
pair(); // 默认构造函数。
pair(const T1 &val1,const T2 &val2); // 有两个参数的构造函数。
pair(const pair<T1,T2> &p); // 拷贝构造函数。
void swap(pair<T1,T2> &p); // 交换两个pair。
};
make_pair函数模板的定义如下:
template <class T1, class T2>
make_pair(const T1 &first,const T2 &second)
{
return pair<T1,T2>(first, second);
}
示例:
#include <iostream>
using namespace std;
template <class T1, class T2>
struct Pair
{
T1 first; // 第一个成员,一般表示key。
T2 second; // 第二个成员,一般表示value。
Pair() {
cout << "调用了有默认的构造函数。\n";
}
Pair(const T1& val1, const T2& val2) :first(val1), second(val2) {
cout << "调用了有两个参数的构造函数。\n";
}
Pair(const Pair<T1, T2>& p) : first(p.first),second(p.second) {
cout << "调用了拷贝构造函数。\n";
}
};
template <class T1, class T2>
Pair<T1, T2> make_Pair(const T1& first, const T2& second)
{
// Pair<T1, T2> p(first, second);
// return p; // 返回局部对象。
return Pair<T1, T2>(first, second); // 返回临时对象。
}
int main()
{
//pair<int, string> p0;
//cout << "p0 first=" << p0.first << ",second=" << p0.second << endl;
//pair<int, string> p1(1, "西施1"); // 两个参数的构造函数。
//cout << "p1 first=" << p1.first << ",second=" << p1.second << endl;
//pair<int, string> p2 = p1; // 拷贝构造。
//cout << "p2 first=" << p2.first << ",second=" << p2.second << endl;
//pair<int, string> p3 = { 3, "西施3" }; // 两个参数的构造函数。
//// pair<int, string> p3 { 3, "西施3" }; // 两个参数的构造函数,省略了等于号。
//cout << "p3 first=" << p3.first << ",second=" << p3.second << endl;
auto p4 = Pair<int, string>(4, "西施4"); // 匿名对象(显式调用构造函数)。
cout << "p4 first=" << p4.first << ",second=" << p4.second << endl;
auto p5 = make_Pair<int, string>(5, "西施5"); // make_pair()返回的临时对象。
cout << "p5 first=" << p5.first << ",second=" << p5.second << endl;
//pair<int, string> p6 = make_pair(6, "西施6"); // 慎用,让make_pair()函数自动推导,再调用拷贝构造,再隐式转换。
//cout << "p6 first=" << p6.first << ",second=" << p6.second << endl;
//auto p7 = make_pair(7, "西施7"); // 慎用,让make_pair()函数自动推导,再调用拷贝构造。
//cout << "p7 first=" << p7.first << ",second=" << p7.second << endl;
//p5.swap(p4); // 交换两个pair。
//cout << "p4 first=" << p4.first << ",second=" << p4.second << endl;
//cout << "p5 first=" << p5.first << ",second=" << p5.second << endl;
//struct st_girl
//{
// string name;
// int age;
// double height;
//};
//// 用pair存放结构体数据。
//pair<int, st_girl> p = { 3,{"西施",23,48.6} };
//cout << "p first=" << p.first << endl;
//cout << "p second.name=" << p.second.name << endl;
//cout << "p second.age=" << p.second.age << endl;
//cout << "p second.height=" << p.second.height << endl;
}
五十八、map容器
map 容器封装了红黑树(平衡二叉排序树),用于查找。
包含头文件: #include
map容器的元素是pair键值对。
map类模板的声明:
template <class K, class V, class P = less<K>, class _Alloc = allocator<pair<const K, V >>>
class map : public _Tree<_Tmap_traits< K, V, P, _Alloc, false>>
{
…
}
第一个模板参数K:key的数据类型(pair.first)。
第二个模板参数V:value的数据类型(pair.second)。
第三个模板参数P:排序方法,缺省按key升序。
第四个模板参数_Alloc:分配器,缺省用new和delete。
map提供了双向迭代器。
二叉链表:
struct BTNode
{
pair<K,V> p; // 键值对。
BTNode *parent; // 父节点。
BTNode *lchirld; // 左子树。
BTNode *rchild; // 右子树。
};
一、构造函数
1)map(); // 创建一个空的map容器。
2)map(initializer_list<pair<K,V>> il); // 使用统一初始化列表。
3)map(const map<K,V>& m); // 拷贝构造函数。
4)map(Iterator first, Iterator last); // 用迭代器创建map容器。
5)map(map<K,V>&& m); // 移动构造函数(C++11标准)。
示例:
#include <iostream>
#include <map>
using namespace std;
int main()
{
// 1)map(); // 创建一个空的map容器。
map<int, string> m1;
// 2)map(initializer_list<pair<K, V>> il); // 使用统一初始化列表。
map<int, string> m2( { { 8,"冰冰" }, { 3,"西施" }, { 1,"幂幂" }, { 7,"金莲" }, { 5,"西瓜" } } );
// map<int, string> m2={ { 8,"冰冰" }, { 3,"西施" }, { 1,"幂幂" }, { 7,"金莲" }, { 5,"西瓜" } };
// map<int, string> m2 { { 8,"冰冰" }, { 3,"西施" }, { 1,"幂幂" }, { 7,"金莲" }, { 5,"西瓜" } };
for (auto& val : m2)
cout << val.first << "," << val.second << " ";
cout << endl;
// 3)map(const map<K, V>&m); // 拷贝构造函数。
map<int, string> m3 = m2;
for (auto& val : m3)
cout << val.first << "," << val.second << " ";
cout << endl;
// 4)map(Iterator first, Iterator last); // 用迭代器创建map容器。
auto first = m3.begin(); first++;
auto last = m3.end(); last--;
map<int, string> m4(first,last);
for (auto& val : m4)
cout << val.first << "," << val.second << " ";
cout << endl;
// 5)map(map<K, V> && m); // 移动构造函数(C++11标准)。
}
二、特性操作
size_t size() const; // 返回容器的实际大小(已使用的空间)。
bool empty() const; // 判断容器是否为空。
void clear(); // 清空容器。
三、元素操作
V &operator[](K key); // 用给定的key访问元素。
const V &operator[](K key) const; // 用给定的key访问元素,只读。
V &at(K key); // 用给定的key访问元素。
const V &at(K key) const; // 用给定的key访问元素,只读。
注意:
1)[ ]运算符:如果指定键不存在,会向容器中添加新的键值对;如果指定键不存在,则读取或修改容器中指定键的值。
2)at()成员函数:如果指定键不存在,不会向容器中添加新的键值对,而是直接抛出out_of_range 异常。
**示例
#include <iostream>
#include <map>
using namespace std;
int main()
{
map<string, string> m( { { "08","冰冰" }, { "03","西施" }, { "01","幂幂" }, { "07","金莲" }, { "05","西瓜" } } );
cout << "m[08]=" << m["08"] << endl; // 显示key为08的元素的value。
cout << "m[09]=" << m["09"] << endl; // 显示key为09的元素的value。key为09的元素不存在,将添加新的键值对。
m["07"] = "花花"; // 把key为07的元素的value修改为花花。
m["12"] = "小乔"; // 将添加新的键值对。
for (auto& val : m)
cout << val.first << "," << val.second << " ";
cout << endl;
}
四、赋值操作
给已存在的容器赋值,将覆盖容器中原有的内容。
1)map<K,V> &operator=(const map<K,V>& m); // 把容器m赋值给当前容器。
2)map<K,V> &operator=(initializer_list<pair<K,V>> il); // 用统一初始化列表给当前容器赋值。
五、交换操作
void swap(map<K,V>& m); // 把当前容器与m交换。
交换的是树的根结点。
六、比较操作
bool operator == (const map<K,V>& m) const;
bool operator != (const map<K,V>& m) const;
七、查找操作
1)查找键值为key的键值对
在map容器中查找键值为key的键值对,如果成功找到,则返回指向该键值对的迭代器;失败返回end()。
iterator find(const K &key);
const_iterator find(const K &key) const; // 只读。
2)查找键值>=key的键值对
在map容器中查找第一个键值>=key的键值对,成功返回迭代器;失败返回end()。
iterator lower_bound(const K &key);
const_iterator lower_bound(const K &key) const; // 只读。
3)查找键>key的键值对
在map容器中查找第一个键值>key的键值对,成功返回迭代器;失败返回end()。
iterator upper_bound(const K &key);
const_iterator upper_bound(const K &key) const; // 只读。
4)统计键值对的个数
统计map容器中键值为key的键值对的个数。
size_t count(const K &key) const;
示例:
#include <iostream>
#include <map>
using namespace std;
int main()
{
map<string, string> m( { { "08","冰冰" }, { "03","西施" }, { "01","幂幂" }, { "07","金莲" }, { "05","西瓜" } } );
for (auto& val : m)
cout << val.first << "," << val.second << " ";
cout << endl;
// 在map容器中查找键值为key的键值对,如果成功找到,则返回指向该键值对的迭代器;失败返回end()。
auto it1 = m.find("05");
if (it1 != m.end())
cout << "查找成功:" << it1->first << "," << it1->second << endl;
else
cout << "查找失败。\n";
// 在map容器中查找第一个键值 >= key的键值对,成功返回迭代器;失败返回end()。
auto it2 = m.lower_bound("05");
if (it2 != m.end())
cout << "查找成功:" << it2->first << "," << it2->second << endl;
else
cout << "查找失败。\n";
// 在map容器中查找第一个键值 > key的键值对,成功返回迭代器;失败返回end()。
auto it3 = m.upper_bound("05");
if (it3 != m.end())
cout << "查找成功:" << it3->first << "," << it3->second << endl;
else
cout << "查找失败。\n";
// 统计map容器中键值为key的键值对的个数。
cout << "count(05)=" << m.count("05") << endl; // 返回1。
cout << "count(06)=" << m.count("06") << endl; // 返回0。
}
八、插入和删除
1)void insert(initializer_list<pair<K,V>> il); // 用统一初始化列表在容器中插入多个元素。
2)pair<iterator,bool> insert(const pair<K,V> &value); // 在容器中插入一个元素,返回值pair:first是已插入元素的迭代器,second是插入结果。
3)void insert(iterator first,iterator last); // 用迭代器插入一个区间的元素。
4)pair<iterator,bool> emplace (...); // 将创建新键值对所需的数据作为参数直接传入,map容器将直接构造元素。返回值pair:first是已插入元素的迭代器,second是插入结果。
例:mm.emplace(piecewise_construct, forward_as_tuple(8), forward_as_tuple("冰冰", 18));
5)iterator emplace_hint (const_iterator pos,...); // 功能与第4)个函数相同,第一个参数提示插入位置,该参数只有参考意义,如果提示的位置是正确的,对性能有提升,如果提示的位置不正确,性能反而略有下降,但是,插入是否成功与该参数元关。该参数常用end()和begin()。成功返回新插入元素的迭代器;如果元素已经存在,则插入失败,返回现有元素的迭代器。
6)size_t erase(const K & key); // 从容器中删除指定key的元素,返回已删除元素的个数。
7)iterator erase(iterator pos); // 用迭代器删除元素,返回下一个有效的迭代器。
8)iterator erase(iterator first,iterator last); // 用迭代器删除一个区间的元素,返回下一个有效的迭代器。
示例
#include <iostream>
#include <map>
using namespace std;
class CGirl // 超女类。
{
public:
string m_name; // 超女姓名。
int m_age; // 超女年龄。
/*CGirl() : m_age(0) {
cout << "默认构造函数。\n";
}*/
CGirl(const string name, const int age) : m_name(name), m_age(age) {
cout << "两个参数的构造函数。\n";
}
CGirl(const CGirl & g) : m_name(g.m_name), m_age(g.m_age) {
cout << "拷贝构造函数。\n";
}
};
int main()
{
//map<int, CGirl> mm;
//mm.insert (pair<int, CGirl>(8, CGirl("冰冰", 18))); // 一次构造函数,两次拷贝构造函数。
//mm.insert (make_pair<int, CGirl>(8, CGirl("冰冰", 18))); // 一次构造函数,两次拷贝构造函数。
//mm.emplace(pair<int, CGirl>(8, CGirl("冰冰", 18))); // 一次构造函数,两次拷贝构造函数。
//mm.emplace(make_pair<int, CGirl>(8, CGirl("冰冰", 18))); // 一次构造函数,两次拷贝构造函数。
//mm.emplace(8, CGirl("冰冰", 18)); // 一次构造函数,一次拷贝构造函数。
//mm.emplace(8, "冰冰", 18); // 错误。
//mm.emplace(piecewise_construct, forward_as_tuple(8), forward_as_tuple("冰冰", 18)); // 一次构造函数。
//for (const auto& val : mm)
// cout << val.first << "," << val.second.m_name << "," << val.second.m_name << " ";
//cout << endl;
//return 0;
map<int, string> m;
// 1)void insert(initializer_list<pair<K,V>> il); // 用统一初始化列表在容器中插入多个元素。
m.insert({ { 8,"冰冰" }, { 3,"西施" }});
m.insert({ pair<int,string>(1,"幂幂"), make_pair<int,string>(7,"金莲"), {5,"西瓜"}});
m.insert({ { 18,"冰冰" }, { 3,"西施" } });
// 2)pair<iterator,bool> insert(const pair<K,V> &value);
// 在容器中插入一个元素,返回值pair:first是已插入元素的迭代器,second是插入结果。
auto ret = m.insert(pair<int, string>(18, "花花"));
if (ret.second == true) cout << "插入成功:" << ret.first->first << "," << ret.first->second << endl;
else cout << "插入失败。\n";
// 3)void insert(iterator first, iterator last); // 用迭代器插入一个区间的元素。
// 4)pair<iterator, bool> emplace(...);
// 将创建新键值对所需的数据作为参数直接传入,map容器将直接构造元素。
// 返回值pair:first是已插入元素的迭代器,second是插入结果。
auto ret1 = m.emplace(20, "花花");
if (ret1.second == true) cout << "插入成功:" << ret1.first->first << "," << ret1.first->second << endl;
else cout << "插入失败。\n";
// 5)iterator emplace_hint(const_iterator pos, ...);
// 功能与第4)个函数相同,第一个参数提示插入位置,该参数只有参考意义,如果提示的位置是正确的,
// 对性能有提升,如果提示的位置不正确,性能反而略有下降,但是,插入是否成功与该参数元关。
// 该参数常用end()和begin()。成功返回新插入元素的迭代器;如果元素已经存在,则插入失败,返回现
// 有元素的迭代器。
m.emplace_hint(m.begin(), piecewise_construct, forward_as_tuple(23), forward_as_tuple("冰棒"));
for (auto& val : m)
cout << val.first << "," << val.second << " ";
cout << endl;
}
五十九、unordered_map容器
unordered_map容器封装了哈希表,查找、插入和删除元素时,只需要比较几次key的值。
包含头文件: #include<unordered_map>
unordered_map容器的元素是pair键值对。
unordered_map类模板的声明:
template <class K, class V, class _Hasher = hash<K>, class _Keyeq = equal_to<K>,
class _Alloc = allocator<pair<const K, V>>>
class unordered_map : public _Hash<_Umap_traits<K, V, _Uhash_compare<K, _Hasher, _Keyeq>, _Alloc, false>>
{
…
}
第一个模板参数K:key的数据类型(pair.first)。
第二个模板参数V:value的数据类型(pair.second)。
第三个模板参数_Hasher:哈希函数,默认值为std::hash
第四个模板参数_Keyeq:比较函数,用于判断两个key是否相等,默认值是std::equal_to
第五个模板参数_Alloc:分配器,缺省用new和delete。
创建std::unordered_map类模板的别名
template<class K,class V>
using umap = std::unordered_map<K, V>;
一、构造函数
1)umap(); // 创建一个空的umap容器。
2)umap(size_t bucket); // 创建一个空的umap容器,指定了桶的个数,下同。
3)umap(initializer_list<pair<K,V>> il); // 使用统一初始化列表。
4)umap(initializer_list<pair<K,V>> il, size_t bucket); // 使用统一初始化列表。
5)umap(Iterator first, Iterator last); // 用迭代器创建umap容器。
6)umap(Iterator first, Iterator last, size_t bucket); // 用迭代器创建umap容器。
7)umap(const umap<K,V>& m); // 拷贝构造函数。
8)umap(umap<K,V>&& m); // 移动构造函数(C++11标准)。
示例:
#include <iostream>
#include <unordered_map>
using namespace std;
template<class K, class V>
using umap = std::unordered_map<K, V>;
int main()
{
// 1)umap(); // 创建一个空的map容器。
umap<int, string> m1;
// 2)umap(initializer_list<pair<K, V>> il); // 使用统一初始化列表。
umap<int, string> m2({ { 8,"冰冰" }, { 3,"西施" }, { 1,"幂幂" }, { 7,"金莲" }, { 5,"西瓜" } });
// umap<int, string> m2={ { 8,"冰冰" }, { 3,"西施" }, { 1,"幂幂" }, { 7,"金莲" }, { 5,"西瓜" } };
// umap<int, string> m2 { { 8,"冰冰" }, { 3,"西施" }, { 1,"幂幂" }, { 7,"金莲" }, { 5,"西瓜" } };
for (auto& val : m2)
cout << val.first << "," << val.second << " ";
cout << endl;
// 3)umap(const map<K, V>&m); // 拷贝构造函数。
umap<int, string> m3 = m2;
for (auto& val : m3)
cout << val.first << "," << val.second << " ";
cout << endl;
// 4)umap(Iterator first, Iterator last); // 用迭代器创建map容器。
auto first = m3.begin(); first++;
auto last = m3.end(); last--;
umap<int, string> m4(first, last);
for (auto& val : m4)
cout << val.first << "," << val.second << " ";
cout << endl;
// 5)umap(map<K, V> && m); // 移动构造函数(C++11标准)。
}
二、特性操作
1)size_t size() const; // 返回容器中元素的个数。
2)bool empty() const; // 判断容器是否为空。
3)void clear(); // 清空容器。
4)size_t max_bucket_count(); // 返回容器底层最多可以使用多少桶,无意义。
5)size_t bucket_count(); // 返回容器桶的数量,空容器有8个桶。
6)float load_factor(); // 返回容器当前的装填因子,load_factor() = size() / bucket_count()。
7)float max_load_factor(); // 返回容器的最大装填因子,达到该值后,容器将扩充,缺省为1。
8)void max_load_factor (float z ); // 设置容器的最大装填因子。
9)iterator begin(size_t n); // 返回第n个桶中第一个元素的迭代器。
10)iterator end(size_t n); // 返回第n个桶中最后一个元素尾后的迭代器。
11)void reserve(size_t n); // 将容器设置为至少n个桶。
12)void rehash(size_t n); // 将桶的数量调整为>=n。如果n大于当前容器的桶数,该方法会将容器重新哈希;如果n的值小于当前容器的桶数,该方法可能没有任何作用。
13)size_t bucket_size(size_t n); // 返回第n个桶中元素的个数,0 <= n < bucket_count()。
14)size_t bucket(K &key); // 返回值为key的元素对应的桶的编号。
三、元素操作
V &operator[](K key); // 用给定的key访问元素。
const V &operator[](K key) const; // 用给定的key访问元素,只读。
V &at(K key); // 用给定的key访问元素。
const V &at(K key) const; // 用给定的key访问元素,只读。
注意:
1)[ ]运算符:如果指定键不存在,会向容器中添加新的键值对;如果指定键不存在,则读取或修改容器中指定键的值。
2)at()成员函数:如果指定键不存在,不会向容器中添加新的键值对,而是直接抛出out_of_range 异常。
示例:
#include <iostream>
#include <unordered_map>
using namespace std;
template<class K, class V>
using umap = std::unordered_map<K, V>;
int main()
{
umap<string, string> m( { { "08","冰冰" }, { "03","西施" }, { "01","幂幂" }, { "07","金莲" }, { "05","西瓜" } } );
cout << "m[08]=" << m["08"] << endl; // 显示key为08的元素的value。
cout << "m[09]=" << m["09"] << endl; // 显示key为09的元素的value。key为09的元素不存在,将添加新的键值对。
m["07"] = "花花"; // 把key为07的元素的value修改为花花。
m["12"] = "小乔"; // 将添加新的键值对。
for (auto& val : m)
cout << val.first << "," << val.second << " ";
cout << endl;
}
四、赋值操作
给已存在的容器赋值,将覆盖容器中原有的内容。
1)umap<K,V> &operator=(const umap<K,V>& m); // 把容器m赋值给当前容器。
2)umap<K,V> &operator=(initializer_list<pair<K,V>> il); // 用统一初始化列表给容器赋值。
五、交换操作
void swap(umap<K,V>& m); // 把当前容器与m交换。
交换的是树的根结点。
六、比较操作
bool operator == (const umap<K,V>& m) const;
bool operator != (const umap<K,V>& m) const;
七、查找操作
1)查找键值为key的键值对
在umap容器中查找键值为key的键值对,如果成功找到,则返回指向该键值对的迭代器;失败返回end()。
iterator find(const K &key);
const_iterator find(const K &key) const; // 只读。
2)统计键值对的个数
统计umap容器中键值为key的键值对的个数。
size_t count(const K &key) const;
示例:
八、插入和删除
1)void insert(initializer_list<pair<K,V>> il); // 用统一初始化列表在容器中插入多个元素。
2)pair<iterator,bool> insert(const pair<K,V> &value); // 在容器中插入一个元素,返回值pair:first是已插入元素的迭代器,second是插入结果。
3)void insert(iterator first,iterator last); // 用迭代器插入一个区间的元素。
4)pair<iterator,bool> emplace (...); // 将创建新键值对所需的数据作为参数直接传入,map容器将直接构造元素。返回值pair:first是已插入元素的迭代器,second是插入结果。
例:mm.emplace(piecewise_construct, forward_as_tuple(8), forward_as_tuple("冰冰", 18));
5)iterator emplace_hint (const_iterator pos,...); // 功能与第4)个函数相同,第一个参数提示插入位置,该参数只有参考意义。对哈希容器来说,此函数意义不大。
6)size_t erase(const K & key); // 从容器中删除指定key的元素,返回已删除元素的个数。
7)iterator erase(iterator pos); // 用迭代器删除元素,返回下一个有效的迭代器。
8)iterator erase(iterator first,iterator last); // 用迭代器删除一个区间的元素,返回下一个有效的迭代器。
示例
#include <iostream>
#include <unordered_map>
using namespace std;
template<class K, class V>
using umap = std::unordered_map<K, V>;
class CGirl // 超女类。
{
public:
string m_name; // 超女姓名。
int m_age; // 超女年龄。
/*CGirl() : m_age(0) {
cout << "默认构造函数。\n";
}*/
CGirl(const string name, const int age) : m_name(name), m_age(age) {
cout << "两个参数的构造函数。\n";
}
CGirl(const CGirl& g) : m_name(g.m_name), m_age(g.m_age) {
cout << "拷贝构造函数。\n";
}
};
int main()
{
//umap<int, CGirl> mm;
////mm.insert (pair<int, CGirl>(8, CGirl("冰冰", 18))); // 一次构造函数,两次拷贝构造函数。
////mm.insert (make_pair<int, CGirl>(8, CGirl("冰冰", 18))); // 一次构造函数,两次拷贝构造函数。
////mm.emplace(pair<int, CGirl>(8, CGirl("冰冰", 18))); // 一次构造函数,两次拷贝构造函数。
////mm.emplace(make_pair<int, CGirl>(8, CGirl("冰冰", 18))); // 一次构造函数,两次拷贝构造函数。
////mm.emplace(8, CGirl("冰冰", 18)); // 一次构造函数,一次拷贝构造函数。
////// mm.emplace(8, "冰冰", 18); // 错误。
//mm.emplace(piecewise_construct, forward_as_tuple(8), forward_as_tuple("冰冰", 18)); // 一次构造函数。
//for (const auto& val : mm)
// cout << val.first << "," << val.second.m_name << "," << val.second.m_name << " ";
//cout << endl;
//return 0;
umap<int, string> m;
// 1)void insert(initializer_list<pair<K,V>> il); // 用统一初始化列表在容器中插入多个元素。
m.insert({ { 8,"冰冰" }, { 3,"西施" } });
m.insert({ pair<int,string>(1,"幂幂"), make_pair<int,string>(7,"金莲"), {5,"西瓜"} });
m.insert({ { 18,"冰冰" }, { 3,"西施" } });
// 2)pair<iterator,bool> insert(const pair<K,V> &value);
// 在容器中插入一个元素,返回值pair:first是已插入元素的迭代器,second是插入结果。
auto ret = m.insert(pair<int, string>(18, "花花"));
if (ret.second == true) cout << "插入成功:" << ret.first->first << "," << ret.first->second << endl;
else cout << "插入失败。\n";
// 3)void insert(iterator first, iterator last); // 用迭代器插入一个区间的元素。
// 4)pair<iterator, bool> emplace(...);
// 将创建新键值对所需的数据作为参数直接传入,umap容器将直接构造元素。
// 返回值pair:first是已插入元素的迭代器,second是插入结果。
auto ret1 = m.emplace(20, "花花");
if (ret1.second == true) cout << "插入成功:" << ret1.first->first << "," << ret1.first->second << endl;
else cout << "插入失败。\n";
// 5)iterator emplace_hint(const_iterator pos, ...);
m.emplace_hint(m.begin(), piecewise_construct, forward_as_tuple(23), forward_as_tuple("冰棒"));
for (auto& val : m)
cout << val.first << "," << val.second << " ";
cout << endl;
}
五十九、queue容器
queue容器的逻辑结构是队列,物理结构可以是数组或链表,主要用于多线程之间的数据共享。
包含头文件: #include
queue类模板的声明:
template <class T, class _Container = deque
class queue{
……
}
第一个模板参数T:元素的数据类型。
第二个模板参数_Container:底层容器的类型,缺省是std::deque,可以用std::list,还可以用自定义的类模板。
queue容器不支持迭代器。
一、构造函数
1)queue(); // 创建一个空的队列。
2)queue(const queue<T>& q); // 拷贝构造函数。
3)queue(queue<T>&& q); // 移动构造函数(C++11标准)。
**析构函数~queue()释放内存空间。·
二、常用操作
1)void push(const T& value); // 元素入队。
2)void emplace(…); // 元素入队,…用于构造元素。C++11
3)size_t size() const; // 返回队列中元素的个数。
4)bool empty() const; // 判断队列是否为空。
5)T &front(); // 返回队头元素。
6)const T &front(); // 返回队头元素,只读。
7)T &back(); // 返回队尾元素。
8)const T &back(); // 返回队头元素,只读。
9)void pop(); // 出队,删除队头的元素。
示例:
#include <iostream>
#include <queue>
#include <deque>
#include <list>
using namespace std;
class girl // 超女类。
{
public:
int m_bh; // 编号。
string m_name; // 姓名。
girl(const int& bh, const string& name) : m_bh(bh), m_name(name) {}
};
int main()
{
// template <class T, class _Container = deque<T>>
// class queue {
// ……
// }
// 第一个模板参数T:元素的数据类型。
// 第二个模板参数_Container:底层容器的类型,缺省是std::deque,可以用std::list,还可以用自定义的类模板。
queue<girl, list<girl>> q; // 物理结构为链表。
//queue<girl, deque<girl>> q; // 物理结构为数组。
//queue<girl> q; // 物理结构为数组。
//queue<girl, vector<girl>> q; // 物理结构为vector,不可以。
q.push(girl(3, "西施")); // 效率不高。
q.emplace(8, "冰冰"); // 效率更高。
q.push(girl(5, "幂幂"));
q.push(girl(2, "西瓜"));
while (q.empty() == false)
{
cout << "编号:" << q.front().m_bh << ",姓名:" << q.front().m_name << endl;
q.pop();
}
}
三、其它操作
1)queue &operator=(const queue<T> &q); // 赋值。
2)void swap(queue<T> &q); // 交换。
3)bool operator == (const queue<T> & q) const; // 重载==操作符。
4)bool operator != (const queue<T> & q) const; // 重载!=操作符。
六十、STL其它容器
一、array(静态数组)
1)物理结构
在栈上分配内存,创建数组的时候,数组长度必须是常量,创建后的数组大小不可变。
template<class T, size_t size>
class array{
private:
T elems_[size]
};
2)迭代器
随机访问迭代器。
3)特点
部分场景中,比常规数组更方便(能用于模板),可以代替常规数组。
4)各种操作
1)void fill(const T & val); // 给数组填充值(清零)。
2)size_t size(); // 返回数组的大小。
3)bool empty() const; // 无意义。
4)T &operator[](size_t n);
5)const T &operator[](size_t n) const; // 只读。
6)T &at(size_t n);
7)const T &at(size_t n) const; // 只读。
8)T *data(); // 返回数组的首地址。
9)const T *data() const; // 返回数组的首地址。
10)T &front(); // 第一个元素。
11)const T &front(); // 第一个元素,只读。
12)const T &back(); // 最后一个元素,只读。
13)T &back(); // 最后一个元素。
示例:
#include <iostream>
#include <array>
using namespace std;
////void func(int arr[][6],int len)
//void func(int (* arr)[6], int len)
//{
// for (int ii = 0; ii < len; ii++)
// {
// for (int jj = 0; jj < 6; jj++)
// cout << arr[ii][jj] << " ";
// cout << endl;
// }
//}
//void func(const array < array<int, 5>, 10 >& arr)
//{
// for (int ii = 0; ii < arr.size(); ii++)
// {
// for (int jj = 0; jj < arr[ii].size(); jj++)
// cout << arr[ii][jj] << " ";
// cout << endl;
// }
//}
template <typename T>
void func(const T& arr)
{
for (int ii = 0; ii < arr.size(); ii++)
{
for (int jj = 0; jj < arr[ii].size(); jj++)
cout << arr[ii][jj] << " ";
cout << endl;
}
}
int main()
{
//int aa[11] = {1,2,3,4,5,6,7,8,9,10,11}; // 一维数组。
//array<int, 10> aa = { 1,2,3,4,5,6,7,8,9,10 }; // 一维数组。
//for (int ii = 0; ii < 10; ii++) // 传统的方法。
// cout << aa[ii] << " ";
//cout << endl;
//
//for (int ii = 0; ii < aa.size(); ii++) // 利用array的size()方法。
// cout << aa[ii] << " ";
//cout << endl;
//
//for (auto it= aa.begin(); it < aa.end(); it++) // 使用迭代器。
// cout << *it << " ";
//cout << endl;
//for (auto val : aa) // 基于范围的for循环。
// cout << val << " ";
//cout << endl;
//int bb[10][6];
//for (int ii = 0; ii < 10; ii++) // 对二维数组赋值。
//{
// for (int jj = 0; jj < 6; jj++)
// bb[ii][jj] = jj * 10 + ii;
//}
//func(bb,10); // 把二维数组传给函数。
array< array<int, 5>, 10 > bb; // 二维数组,相当于int bb[10][5]。
for (int ii = 0; ii < bb.size(); ii++) // 对二维数组赋值。
{
for (int jj = 0; jj < bb[ii].size(); jj++)
bb[ii][jj] = jj * 10 + ii;
}
func(bb); // 把二维数组传给函数。
}
二、deque(双端队列)
1)物理结构
deque容器存储数据的空间是多段等长的连续空间构成,各段空间之间并不一定是连续的。
为了管理这些连续空间的分段,deque容器用一个数组存放着各分段的首地址。
通过建立数组,deque容器的分段的连续空间能实现整体连续的效果。
当deque容器在头部或尾部增加元素时,会申请一段新的连续空间,同时在数组中添加指向该空间的指针。
2)迭代器
随机访问迭代器。
3)特点
提高了在两端插入和删除元素的效率,扩展空间的时候,不需要拷贝以前的元素。
在中间插入和删除元素的效率比vector更糟糕。
随机访问的效率比vector容器略低。
4)各种操作
与vector容器相同。
三、forward_list(单链表)
1)物理结构
单链表。
2)迭代器
正向迭代器。
3)特点
比双链表少了一个指针,可节省一丢丢内存,减少了两次对指针的赋值操作。
如果单链表能满足业务需求,建议使用单链表而不是双链表。
4)各种操作
与list容器相同。
四、multimap
底层是红黑树。
multimap和map的区别在:multimap允许关键字重复,而map不允许重复。
各种操作与map容器相同。
五、set&multiset
底层是红黑树。
set和map的区别在:map中存储的是键值对,而set只保存关键字。
multiset和set的区别在:multiset允许关键字重复,而set不允许重复。
各种操作与map容器相同。
六、unordered_multimap
底层是哈希表。
unordered_multimap和unordered_map的区别在:unordered_multimap允许关键字重复,而unordered_map不允许重复。
各种操作与unordered_map容器相同。
七、unordered_set&unordered_multiset
底层是哈希表。
unordered_set和unordered_map的区别在:unordered_map中存储的是键值对,而unordered_set只保存关键字。
unordered_multiset和unordered_set的区别在:unordered_multiset允许关键字重复,而unordered_set不允许重复。
各种操作与unordered_map容器相同。
八、priority_queue(优先队列)
优先级队列相当于一个有权值的单向队列queue,在这个队列中,所有元素是按照优先级排列的。
底层容器可以用deque和list。
各种操作与queue容器相同。
九、stack(栈)
底层容器可以用deque和list。
六十一、STL算法
STL提供了很多处理容器的函数模板,它们的设计是相同的,有以下特点:
1)用迭代器表示需要处理数据的区间。
2)返回迭代器放置处理数据的结果(如果有结果)。
3)接受一个函数对象参数(结构体模板),用于处理数据(如果需要)。
一、函数对象
很多STL算法都使用函数对象,也叫函数符(functor),包括函数名、函数指针和仿函数。
函数符的概念:
1)生成器(generator):不用参数就可以调用的函数符。
2)一元函数(unary function):用一个参数可以调用的函数符。
3)二元函数(binary function):用两个参数可以调用的函数符。
改进的概念:
1)一元谓词(predicate):返回bool值的一元函数。
2)二元谓词(binary predicate):返回bool值的二元函数。
二、预定义的函数对象
STL定义了多个基本的函数符,用于支持STL的算法函数。
包含头文件:#include
三、算法函数
STL将算法函数分成四组:
1)非修改式序列操作:对区间中的每个元素进行操作,这些操作不修改容器的内容。
2)修改式序列操作:对区间中的每个元素进行操作,这些操作可以容器的内容(可以修改值,也可以修改排列顺序)。
3)排序和相关操作:包括多个排序函数和其它各种函数,如集合操作。
4)通用数字运算:包括将区间的内容累积、计算两个容器的内部乘积、计算小计、计算相邻对象差的函数。通常,这些都是数组的操作特性,因此vector是最有可能使用这些操作的容器。
前三组在头文件#include
详见《C++ Primer plus》,第六版,从886页开始。
四、学习要领
1)如果容器有成员函数,则使用成员函数,如果没有才考虑用STL的算法函数。
2)把全部的STL算法函数过一遍,知道大概有些什么东西。
3)如果打算采用某算法函数,一定要搞清楚它的原理,关注它的效率。
4)不要太看重这些算法函数,自己写一个也就那么回事。
5)不是因为简单,而是因为不常用。
五、常用函数
1)for_each()遍历
2)find()遍历
3)find_if()遍历
4)find_not_if()遍历
5)sort()排序
STL的sort算法,数据量大时采用QuickSort(快速排序),分段归并排序。一旦分段后的数据量小于某个门槛(16),为避免QuickSort的递归调用带来过大的额外负荷,就改用InsertSort(插入排序)。如果递归层次过深,还会改用HeapSort(堆排序)。
适用于数组容器vector、string、deque(list容器有sort成员函数,红黑树和哈希表没有排序的说法)。
6)二分查找
示例(foreach):
#include <iostream>
#include <vector>
#include <list>
#include <algorithm>
using namespace std;
template<typename T>
void zsshow(const T& no) // 张三的个性化表白函数。
{
cout << "亲爱的" << no << "号:我是一只傻傻鸟。\n";
}
template<typename T>
class czs // 张三的个性化表白仿函数。
{
public:
void operator()(const T& no) {
cout << "亲爱的" << no << "号:我是一只傻傻鸟。\n";
}
};
template<typename T1, typename T2>
void foreach(const T1 first, const T1 last, T2 pfun)
{
for (auto it = first; it != last; it++)
pfun(*it); // 以超女编号为实参调用类的operator()函数。
}
int main()
{
vector<int> bh = { 5,8,2,6,9,3,1,7 }; // 存放超女编号的容器。
//list<string> bh = { "05","08","02","06","09","03","01","07" }; // 存放超女编号的容器。
// 写一个函数,在函数中遍历容器,向超女表白,表白的方法可自定义。
foreach(bh.begin(), bh.end(), zsshow<int>); // 第三个参数是模板函数。
foreach(bh.begin(), bh.end(), czs<int>()); // 第三个参数是仿函数。
}
示例(findif)
#include <iostream>
#include <vector>
#include <list>
#include <algorithm>
using namespace std;
template<typename T>
bool zsshow(const T& no,const T & in_no) // 张三的个性化表白函数。
{
if (no != in_no) return false;
cout << "亲爱的" << no << "号:我是一只傻傻鸟。\n";
return true;
}
template<typename T>
class czs // 张三的个性化表白仿函数。
{
public:
bool operator()(const T& no, const T& in_no) {
if (no != in_no) return false;
cout << "亲爱的" << no << "号:我是一只傻傻鸟。\n";
return true;
}
};
template<typename T1, typename T2, typename T3>
T1 findif(const T1 first, const T1 last, T2 pfun,T3 in_no)
{
for (auto it = first; it != last; it++)
if (pfun(*it, in_no) ==true) return it; // 用迭代器调用函数对象。
return last;
}
int main()
{
vector<int> bh = { 5,8,2,6,9,33,1,7 }; // 存放超女编号的容器。
//list<string> bh = { "05","08","02","06","09","03","01","07" }; // 存放超女编号的容器。
auto it1=findif(bh.begin(), bh.end(), zsshow<int>,2); // 第三个参数是模板函数。
if (it1 == bh.end()) cout << "查找失败。\n";
else cout << "查找成功:" << *it1 << endl;
auto it2=findif(bh.begin(), bh.end(), czs<int>(),33); // 第三个参数是仿函数。
if (it2 == bh.end()) cout << "查找失败。\n";
else cout << "查找成功:" << *it2 << endl;
**}
示例(findif仿函数)**
#include <iostream>
#include <vector>
#include <list>
#include <algorithm> // STL算法函数头文件。
using namespace std;
template<typename T>
bool zsshow(const T& no) // 张三的个性化表白函数。
{
if (no != 3) return false;
cout << "亲爱的" << no << "号:我是一只傻傻鸟。\n";
return true;
}
template<typename T>
class czs // 张三的个性化表白仿函数。
{
public:
T m_no; // 存放张三喜欢的超女编号。
czs(const T& no) : m_no(no) {} // 构造函数的参数是张三喜欢的超女编号。
bool operator()(const T& no) {
if (no != m_no) return false;
cout << "亲爱的" << no << "号:我是一只傻傻鸟。\n";
return true;
}
};
template<typename T1, typename T2>
T1 findif(const T1 first, const T1 last, T2 pfun)
{
for (auto it = first; it != last; it++)
if (pfun(*it) ==true) return it; // 用迭代器调用函数对象。
return last;
}
int main()
{
vector<int> bh = { 5,8,2,6,9,33,1,7 }; // 存放超女编号的容器。
//list<string> bh = { "05","08","02","06","09","03","01","07" }; // 存放超女编号的容器。
auto it1=find_if(bh.begin(), bh.end(), zsshow<int>); // 第三个参数是模板函数。
if (it1 == bh.end()) cout << "查找失败。\n";
else cout << "查找成功:" << *it1 << endl;
auto it2=find_if(bh.begin(), bh.end(), czs<int>(8)); // 第三个参数是仿函数。
if (it2 == bh.end()) cout << "查找失败。\n";
else cout << "查找成功:" << *it2 << endl;
}
示例(bsort)
#include <iostream>
#include <vector>
#include <list>
#include <algorithm> // STL算法函数。
#include <functional> // STL仿函数。
using namespace std;
template<typename T>
bool compasc(const T& left, const T& right) { // 普通函数,用于升序。
return left < right;
}
template<typename T>
struct _less
{
bool operator()(const T& left, const T& right) { // 仿函数,用于升序。
return left < right;
}
};
template<typename T>
bool compdesc(const T& left, const T& right) { // 普通函数,用于降序。
return left > right;
}
template<typename T>
class _greater
{
public:
bool operator()(const T& left, const T& right) { // 仿函数,用于降序。
return left > right;
}
};
template<typename T, typename compare>
void bsort(const T first, const T last, compare comp) // 冒泡排序。
{
while(true)
{
bool bswap = false; // 本轮遍历已交换过元素的标识,true-交换过,false-未交换过。
for (auto it = first; ; )
{
auto left = it; // 左边的元素。
it++;
auto right = it; // 右边的元素。
if (right == last) break; // 表示it1已经是最后一个元素了。
//if (*left > *right) // 如果左边的元素比右边大,交换它们的值。
//if (*left < *right) // 如果左边的元素比右边小,交换它们的值。
// 排序规则:如果comp()返回true,left排在前面(升序),否则right排在前面(降序)。
if (comp(*left, *right) == true) continue;
// 交换两个元素的值。
auto tmp = *right;
*right = *left;
*left = tmp;
bswap = true; // 一轮遍历已交换过元素的标识。
}
if (bswap == false) break; // 如果在for循环中不曾交换过元素,说明全部的元素已有序。
}
}
int main()
{
vector<int> bh = { 5,8,2,6,9,33,1,7 }; // 存放超女编号的容器。
//list<string> bh = { "05","08","02","06","09","03","01","07" }; // 存放超女编号的容器。
//bsort(bh.begin(), bh.end(),compasc<int>); // 普通函数(升序)。
//bsort(bh.begin(), bh.end(), compdesc<int>); // 普通函数(降序)。
//bsort(bh.begin(), bh.end(),_less<int>()); // 仿函数(升序)。
//bsort(bh.begin(), bh.end(), _greater<int>()); // 仿函数(降序)。
//bsort(bh.begin(), bh.end(), less<int>()); // STL提供的仿函数(升序)。
//bsort(bh.begin(), bh.end(), greater<int>()); // STL提供的仿函数(降序)。
//sort(bh.begin(), bh.end(),_less<int>()); // 仿函数(升序)。
sort(bh.begin(), bh.end(), _greater<int>()); // 仿函数(降序)。
for (auto val : bh)
cout << val << " ";
cout << endl;
}
示例(for_each):
#include <iostream>
#include <vector>
#include <list>
#include <algorithm>
using namespace std;
template<typename T>
struct girl {
T m_yz; // 统计的颜值。
int m_count; // 符合条件的元素个数。
girl(const T yz) : m_yz(yz), m_count(0) {}
void operator()(const T& yz) {
if (yz==m_yz) m_count++;
}
};
int main()
{
vector<int> vv = { 1,3,2,4,1,2,3,1,4,3 }; // 1-极漂亮;2-漂亮;3-普通;4-歪瓜裂枣
girl<int> g=for_each(vv.begin(), vv.end(), girl<int>(1)); // 按颜值统计超女人数。
cout << "g.m_count=" << g.m_count << endl;
}
智能指针unique_ptr
unique_ptr独享它指向的对象,也就是说,同时只有一个unique_ptr指向同一个对象,当这个unique_ptr被销毁时,指向的对象也随即被销毁。
包含头文件:#include <memory>
template <typename T, typename D = default_delete<T>>
class unique_ptr
{
public:
explicit unique_ptr(pointer p) noexcept; // 不可用于转换函数。
~unique_ptr() noexcept;
T& operator*() const; // 重载*操作符。
T* operator->() const noexcept; // 重载->操作符。
unique_ptr(const unique_ptr &) = delete; // 禁用拷贝构造函数。
unique_ptr& operator=(const unique_ptr &) = delete; // 禁用赋值函数。
unique_ptr(unique_ptr &&) noexcept; // 右值引用。
unique_ptr& operator=(unique_ptr &&) noexcept; // 右值引用。
// ...
private:
pointer ptr; // 内置的指针。
};
第一个模板参数T:指针指向的数据类型。
第二个模板参数D:指定删除器,缺省用delete释放资源。
测试类AA的定义:
class AA
{
public:
string m_name;
AA() { cout << m_name << "调用构造函数AA()。\n"; }
AA(const string & name) : m_name(name) { cout << "调用构造函数AA("<< m_name << ")。\n"; }
~AA() { cout << m_name << "调用了析构函数~AA(" << m_name << ")。\n"; }
};
一、基本用法
1)初始化
方法:
unique_ptr<AA> p0(new AA("西施")); // 分配内存并初始化。
方法二:
unique_ptr<AA> p0 = make_unique<AA>("西施"); // C++14标准。
unique_ptr<int> pp1=make_unique<int>(); // 数据类型为int。
unique_ptr<AA> pp2 = make_unique<AA>(); // 数据类型为AA,默认构造函数。
unique_ptr<AA> pp3 = make_unique<AA>("西施"); // 数据类型为AA,一个参数的构造函数。
unique_ptr<AA> pp4 = make_unique<AA>("西施",8); // 数据类型为AA,两个参数的构造函数。
方法三(不推荐):
AA* p = new AA("西施");
unique_ptr<AA> p0(p); // 用已存在的地址初始化。
2)使用方法
智能指针重载了*和->操作符,可以像使用指针一样使用unique_ptr。
不支持普通的拷贝和赋值。
AA* p = new AA("西施");
unique_ptr<AA> pu2 = p; // 错误,不能把普通指针直接赋给智能指针。
unique_ptr<AA> pu3 = new AA("西施"); // 错误,不能把普通指针直接赋给智能指针。
unique_ptr<AA> pu2 = pu1; // 错误,不能用其它unique_ptr拷贝构造。
unique_ptr<AA> pu3;
pu3 = pu1; // 错误,不能用=对unique_ptr进行赋值。
不要用同一个裸指针初始化多个unique_ptr对象。
get()方法返回裸指针。
不要用unique_ptr管理不是new分配的内存。
3)用于函数的参数
传引用(不能传值,因为unique_ptr没有拷贝构造函数)。
裸指针。
4)不支持指针的运算(+、-、++、--)
二、更多技巧
1)将一个unique_ptr赋给另一个时,如果源unique_ptr是一个临时右值,编译器允许这样做;如果源unique_ptr将存在一段时间,编译器禁止这样做。一般用于函数的返回值。
unique_ptr<AA> p0;
p0 = uniq```ue_ptr<AA>(new AA ("西瓜"));
2)用nullptr给unique_ptr赋值将释放对象,空的unique_ptr==nullptr。
3)release()释放对原始指针的控制权,将unique_ptr置为空,返回裸指针。(可用于把unique_ptr传递给子函数,子函数将负责释放对象)
4)std::move()可以转移对原始指针的控制权。(可用于把unique_ptr传递给子函数,子函数形参也是unique_ptr)
5)reset()释放对象。
void reset(T * _ptr= (T *) nullptr);
pp.reset(); // 释放pp对象指向的资源对象。
pp.reset(nullptr); // 释放pp对象指向的资源对象
pp.reset(new AA("bbb")); // 释放pp指向的资源对象,同时指向新的对象。
6)swap()交换两个unique_ptr的控制权。
void swap(unique_ptr<T> &_Right);
7)unique_ptr也可象普通指针那样,当指向一个类继承体系的基类对象时,也具有多态性质,如同使用裸指针管理基类对象和派生类对象那样。
8)unique_ptr不是绝对安全,如果程序中调用exit()退出,全局的unique_ptr可以自动释放,但局部的unique_ptr无法释放。
9)unique_ptr提供了支持数组的具体化版本。
数组版本的unique_ptr,重载了操作符[],操作符[]返回的是引用,可以作为左值使用。
// unique_ptr<int[]> parr1(new int[3]); // 不指定初始值。
unique_ptr<int[]> parr1(new int[3]{ 33,22,11 }); // 指定初始值。
cout << "parr1[0]=" << parr1[0] << endl;
cout << "parr1[1]=" << parr1[1] << endl;
cout << "parr1[2]=" << parr1[2] << endl;
unique_ptr<AA[]> parr2(new AA[3]{string("西施"), string("冰冰"), string("幂幂")});
cout << "parr2[0].m_name=" << parr2[0].m_name << endl;
cout << "parr2[1].m_name=" << parr2[1].m_name << endl;
cout << "parr2[2].m_name=" << parr2[2].m_name << endl;
示例1
#include <iostream>
#include <memory>
using namespace std;
class AA
{
public:
string m_name;
AA() { cout << m_name << "调用构造函数AA()。\n"; }
AA(const string & name) : m_name(name) { cout << "调用构造函数AA("<< m_name << ")。\n"; }
~AA() { cout << "调用了析构函数~AA(" << m_name << ")。\n"; }
};
// 函数func1()需要一个指针,但不对这个指针负责。
void func1(const AA* a) {
cout << a->m_name << endl;
}
// 函数func2()需要一个指针,并且会对这个指针负责。
void func2(AA* a) {
cout << a->m_name << endl;
delete a;
}
// 函数func3()需要一个unique_ptr,不会对这个unique_ptr负责。
void func3(const unique_ptr<AA> &a) {
cout << a->m_name << endl;
}
// 函数func4()需要一个unique_ptr,并且会对这个unique_ptr负责。
void func4(unique_ptr<AA> a) {
cout << a->m_name << endl;
}
int main()
{
unique_ptr<AA> pu(new AA("西施"));
cout << "开始调用函数。\n";
//func1(pu.get()); // 函数func1()需要一个指针,但不对这个指针负责。
//func2(pu.release()); // 函数func2()需要一个指针,并且会对这个指针负责。
//func3(pu); // 函数func3()需要一个unique_ptr,不会对这个unique_ptr负责。
func4(move(pu)); // 函数func4()需要一个unique_ptr,并且会对这个unique_ptr负责。
cout << "调用函数完成。\n";
if (pu == nullptr) cout << "pu是空指针。\n";
}
示例2:
#include <iostream>
#include <memory>
using namespace std;
class AA
{
public:
string m_name;
AA() { cout << m_name << "调用构造函数AA()。\n"; }
AA(const string & name) : m_name(name) { cout << "调用构造函数AA("<< m_name << ")。\n"; }
~AA() { cout << "调用了析构函数~AA(" << m_name << ")。\n"; }
};
int main()
{
//AA* parr1 = new AA[2]; // 普通指针数组。
////AA* parr1 = new AA[2]{ string("西施"), string("冰冰") };
//parr1[0].m_name = "西施1";
//cout << "parr1[0].m_name=" << parr1[0].m_name << endl;
//parr1[1].m_name = "西施2";
//cout << "parr1[1].m_name=" << parr1[1].m_name << endl;
//delete [] parr1;
unique_ptr<AA[]> parr2(new AA[2]); // unique_ptr数组。
//unique_ptr<AA[]> parr2(new AA[2]{ string("西施"), string("冰冰") });
parr2[0].m_name = "西施1";
cout << "parr2[0].m_name=" << parr2[0].m_name << endl;
parr2[1].m_name = "西施2";
cout << "parr2[1].m_name=" << parr2[1].m_name << endl;
}
智能指针shared_ptr
shared_ptr共享它指向的对象,多个shared_ptr可以指向(关联)相同的对象,在内部采用计数机制来实现。
当新的shared_ptr与对象关联时,引用计数增加1。
当shared_ptr超出作用域时,引用计数减1。当引用计数变为0时,则表示没有任何shared_ptr与对象关联,则释放该对象。
一、基本用法
shared_ptr的构造函数也是explicit,但是,没有删除拷贝构造函数和赋值函数。
1)初始化
方法一:
shared_ptr
方法二:
shared_ptr<AA> p0 = make_shared<AA>("西施"); // C++11标准,效率更高。
shared_ptr<int> pp1=make_shared<int>(); // 数据类型为int。
shared_ptr<AA> pp2 = make_shared<AA>(); // 数据类型为AA,默认构造函数。
shared_ptr<AA> pp3 = make_shared<AA>("西施"); // 数据类型为AA,一个参数的构造函数。
shared_ptr<AA> pp4 = make_shared<AA>("西施",8); // 数据类型为AA,两个参数的构造函数。
方法三:
AA* p = new AA("西施");
shared_ptr<AA> p0(p); // 用已存在的地址初始化。
方法四:
shared_ptr<AA> p0(new AA("西施"));
shared_ptr<AA> p1(p0); // 用已存在的shared_ptr初始化,计数加1。
shared_ptr<AA> p1=p0; // 用已存在的shared_ptr初始化,计数加1。
2)使用方法
智能指针重载了*和->操作符,可以像使用指针一样使用shared_ptr。
use_count()方法返回引用计数器的值。
unique()方法,如果use_count()为1,返回true,否则返回false。
shared_ptr支持赋值,左值的shared_ptr的计数器将减1,右值shared_ptr的计算器将加1。
get()方法返回裸指针。
不要用同一个裸指针初始化多个shared_ptr。
不要用shared_ptr管理不是new分配的内存。
3)用于函数的参数
与unique_ptr的原理相同。
4)不支持指针的运算(+、-、++、--)
二、更多细节
1)将一个unique_ptr赋给另一个时,如果源unique_ptr是一个临时右值,编译器允许这样做;如果源unique_ptr将存在一段时间,编译器禁止这样做。一般用于函数的返回值。
2)用nullptr给shared_ptr赋值将把计数减1,如果计数为0,将释放对象,空的shared_ptr==nullptr。
3)release()释放对原始指针的控制权,将unique_ptr置为空,返回裸指针。
4)std::move()可以转移对原始指针的控制权。还可以将unique_ptr转移成shared_ptr。
5)reset()改变与资源的关联关系。
pp.reset(); // 解除与资源的关系,资源的引用计数减1。
pp. reset(new AA("bbb")); // 解除与资源的关系,资源的引用计数减1。关联新资源。
6)swap()交换两个shared_ptr的控制权。
void swap(shared_ptr
7)shared_ptr也可象普通指针那样,当指向一个类继承体系的基类对象时,也具有多态性质,如同使用裸指针管理基类对象和派生类对象那样。
8)shared_ptr不是绝对安全,如果程序中调用exit()退出,全局的shared_ptr可以自动释放,但局部的shared_ptr无法释放。
9)shared_ptr提供了支持数组的具体化版本。
数组版本的shared_ptr,重载了操作符[],操作符[]返回的是引用,可以作为左值使用。
10)shared_ptr的线程安全性:
shared_ptr的引用计数本身是线程安全(引用计数是原子操作)。
多个线程同时读同一个shared_ptr对象是线程安全的。
如果是多个线程对同一个shared_ptr对象进行读和写,则需要加锁。
多线程读写shared_ptr所指向的同一个对象,不管是相同的shared_ptr对象,还是不同的shared_ptr对象,也需要加锁保护。
11)如果unique_ptr能解决问题,就不要用shared_ptr。unique_ptr的效率更高,占用的资源更少。
示例1:
#include <iostream>
#include <memory>
using namespace std;
class AA
{
public:
string m_name;
AA() { cout << m_name << "调用构造函数AA()。\n"; }
AA(const string & name) : m_name(name) { cout << "调用构造函数AA("<< m_name << ")。\n"; }
~AA() { cout << "调用了析构函数~AA(" << m_name << ")。\n"; }
};
int main()
{
shared_ptr<AA> pa0(new AA("西施a")); // 初始化资源西施a。
shared_ptr<AA> pa1 = pa0; // 用已存在的shared_ptr拷贝构造,计数加1。
shared_ptr<AA> pa2 = pa0; // 用已存在的shared_ptr拷贝构造,计数加1。
cout << "pa0.use_count()=" << pa0.use_count() << endl; // 值为3。
shared_ptr<AA> pb0(new AA("西施b")); // 初始化资源西施b。
shared_ptr<AA> pb1 = pb0; // 用已存在的shared_ptr拷贝构造,计数加1。
cout << "pb0.use_count()=" << pb0.use_count() << endl; // 值为2。
pb1 = pa1; // 资源西施a的引用加1,资源西施b的引用减1。
pb0 = pa1; // 资源西施a的引用加1,资源西施b的引用成了0,将被释放。
cout << "pa0.use_count()=" << pa0.use_count() << endl; // 值为5。
cout << "pb0.use_count()=" << pb0.use_count() << endl; // 值为5。
}
智能指针的删除器
在默认情况下,智能指针过期的时候,用delete原始指针; 释放它管理的资源。
程序员可以自定义删除器,改变智能指针释放资源的行为。
删除器可以是全局函数、仿函数和Lambda表达式,形参为原始指针。
示例:
#include <iostream>
#include <memory>
using namespace std;
class AA
{
public:
string m_name;
AA() { cout << m_name << "调用构造函数AA()。\n"; }
AA(const string & name) : m_name(name) { cout << "调用构造函数AA("<< m_name << ")。\n"; }
~AA() { cout << "调用了析构函数~AA(" << m_name << ")。\n"; }
};
void deletefunc(AA* a) { // 删除器,普通函数。
cout << "自定义删除器(全局函数)。\n";
delete a;
}
struct deleteclass // 删除器,仿函数。
{
void operator()(AA* a) {
cout << "自定义删除器(仿函数)。\n";
delete a;
}
};
auto deleterlamb = [](AA* a) { // 删除器,Lambda表达式。
cout << "自定义删除器(Lambda)。\n";
delete a;
};
int main()
{
shared_ptr<AA> pa1(new AA("西施a"), deletefunc);
//shared_ptr<AA> pa2(new AA("西施b"), deleteclass());
//shared_ptr<AA> pa3(new AA("西施c"), deleterlamb);
//unique_ptr<AA,decltype(deletefunc)*> pu1(new AA("西施1"), deletefunc);
// unique_ptr<AA, void (*)(AA*)> pu0(new AA("西施1"), deletefunc);
//unique_ptr<AA, deleteclass> pu2(new AA("西施2"), deleteclass());
//unique_ptr<AA, decltype(deleterlamb)> pu3(new AA("西施3"), deleterlamb);
}
智能指针weak_ptr
一、shared_ptr存在的问题
shared_ptr内部维护了一个共享的引用计数器,多个shared_ptr可以指向同一个资源。
如果出现了循环引用的情况,引用计数永远无法归0,资源不会被释放。
示例:
#include <iostream>
#include <memory>
using namespace std;
class BB;
class AA
{
public:
string m_name;
AA() { cout << m_name << "调用构造函数AA()。\n"; }
AA(const string & name) : m_name(name) { cout << "调用构造函数AA("<< m_name << ")。\n"; }
~AA() { cout << "调用了析构函数~AA(" << m_name << ")。\n"; }
shared_ptr<BB> m_p;
};
class BB
{
public:
string m_name;
BB() { cout << m_name << "调用构造函数BB()。\n"; }
BB(const string& name) : m_name(name) { cout << "调用构造函数BB(" << m_name << ")。\n"; }
~BB() { cout << "调用了析构函数~BB(" << m_name << ")。\n"; }
shared_ptr<AA> m_p;
};
int main()
{
shared_ptr<AA> pa = make_shared<AA>("西施a");
shared_ptr<BB> pb = make_shared<BB>("西施b");
pa-> m_p = pb;
pb->m_p = pa;
}
二、weak_ptr是什么
weak_ptr 是为了配合shared_ptr而引入的,它指向一个由shared_ptr管理的资源但不影响资源的生命周期。也就是说,将一个weak_ptr绑定到一个shared_ptr不会改变shared_ptr的引用计数。
不论是否有weak_ptr指向,如果最后一个指向资源的shared_ptr被销毁,资源就会被释放。
weak_ptr更像是shared_ptr的助手而不是智能指针。
示例:
#include <iostream>
#include <memory>
using namespace std;
class BB;
class AA
{
public:
string m_name;
AA() { cout << m_name << "调用构造函数AA()。\n"; }
AA(const string & name) : m_name(name) { cout << "调用构造函数AA("<< m_name << ")。\n"; }
~AA() { cout << "调用了析构函数~AA(" << m_name << ")。\n"; }
weak_ptr<BB> m_p;
};
class BB
{
public:
string m_name;
BB() { cout << m_name << "调用构造函数BB()。\n"; }
BB(const string& name) : m_name(name) { cout << "调用构造函数BB(" << m_name << ")。\n"; }
~BB() { cout << "调用了析构函数~BB(" << m_name << ")。\n"; }
weak_ptr<AA> m_p;
};
int main()
{
shared_ptr<AA> pa = make_shared<AA>("西施a");
shared_ptr<BB> pb = make_shared<BB>("西施b");
cout << "pa.use_count()=" << pa.use_count() << endl;
cout << "pb.use_count()=" << pb.use_count() << endl;
pa->m_p = pb;
pb->m_p = pa;
cout << "pa.use_count()=" << pa.use_count() << endl;
cout << "pb.use_count()=" << pb.use_count() << endl;
}
三、如何使用weak_ptr
weak_ptr没有重载 ->和 *操作符,不能直接访问资源。
有以下成员函数:
1)operator=(); // 把shared_ptr或weak_ptr赋值给weak_ptr。
2)expired(); // 判断它指资源是否已过期(已经被销毁)。
3)lock(); // 返回shared_ptr,如果资源已过期,返回空的shared_ptr。
4)reset(); // 将当前weak_ptr指针置为空。
5)swap(); // 交换。
weak_ptr不控制对象的生命周期,但是,它知道对象是否还活着。
用lock()函数把它可以提升为shared_ptr,如果对象还活着,返回有效的shared_ptr,如果对象已经死了,提升会失败,返回一个空的shared_ptr。
提升的行为(lock())是线程安全的。
示例:
#include <iostream>
#include <memory>
using namespace std;
class BB;
class AA
{
public:
string m_name;
AA() { cout << m_name << "调用构造函数AA()。\n"; }
AA(const string& name) : m_name(name) { cout << "调用构造函数AA(" << m_name << ")。\n"; }
~AA() { cout << "调用了析构函数~AA(" << m_name << ")。\n"; }
weak_ptr<BB> m_p;
};
class BB
{
public:
string m_name;
BB() { cout << m_name << "调用构造函数BB()。\n"; }
BB(const string& name) : m_name(name) { cout << "调用构造函数BB(" << m_name << ")。\n"; }
~BB() { cout << "调用了析构函数~BB(" << m_name << ")。\n"; }
weak_ptr<AA> m_p;
};
int main()
{
shared_ptr<AA> pa = make_shared<AA>("西施a");
{
shared_ptr<BB> pb = make_shared<BB>("西施b");
pa->m_p = pb;
pb->m_p = pa;
shared_ptr<BB> pp = pa->m_p.lock(); // 把weak_ptr提升为shared_ptr。
if (pp == nullptr)
cout << "语句块内部:pa->m_p已过期。\n";
else
cout << "语句块内部:pp->m_name=" << pp->m_name << endl;
}
shared_ptr<BB> pp = pa->m_p.lock(); // 把weak_ptr提升为shared_ptr。
if (pp == nullptr)
cout << "语句块外部:pa->m_p已过期。\n";
else
cout << "语句块外部:pp->m_name=" << pp->m_name << endl;
}
文件操作-写入文本文件
文本文件一般以行的形式组织数据。
包含头文件:#include
类:ofstream(output file stream)
ofstream打开文件的模式(方式):
对于ofstream,不管用哪种模式打开文件,如果文件不存在,都会创建文件。
ios::out 缺省值:会截断文件内容。
ios::trunc 截断文件内容。(truncate)
ios::app 不截断文件内容,只在文件未尾追加文件。(append)
示例:
#include <iostream>
#include <fstream> // ofstream类需要包含的头文件。
using namespace std;
int main()
{
// 文件名一般用全路径,书写的方法如下:
// 1)"D:\data\txt\test.txt" // 错误。
// 2)R"(D:\data\txt\test.txt)" // 原始字面量,C++11标准。
// 3)"D:\\data\\txt\\test.txt" // 转义字符。
// 4)"D:/tata/txt/test.txt" // 把斜线反着写。
// 5)"/data/txt/test.txt" // Linux系统采用的方法。
string filename = R"(D:\data\txt\test.txt)";
//char filename[] = R"(D:\data\txt\test.txt)";
// 创建文件输出流对象,打开文件,如果文件不存在,则创建它。
// ios::out 缺省值:会截断文件内容。
// ios::trunc 截断文件内容。(truncate)
// ios::app 不截断文件内容,只在文件未尾追加文件。(append)
//ofstream fout(filename);
//ofstream fout(filename, ios::out);
//ofstream fout(filename, ios::trunc);
//ofstream fout(filename, ios::app);
ofstream fout;
fout.open(filename,ios::app);
// 判断打开文件是否成功。
// 失败的原因主要有:1)目录不存在;2)磁盘空间已满;3)没有权限,Linux平台下很常见。
if (fout.is_open() == false)
{
cout << "打开文件" << filename << "失败。\n"; return 0;
}
// 向文件中写入数据。
fout << "西施|19|极漂亮\n";
fout << "冰冰|22|漂亮\n";
fout << "幂幂|25|一般\n";
fout.close(); // 关闭文件,fout对象失效前会自动调用close()。
cout << "操作文件完成。\n";
}
文件操作-读取文本文件
包含头文件:#include
类:ifstream
ifstream打开文件的模式(方式):
对于ifstream,如果文件不存在,则打开文件失败。
ios::in 缺省值。
示例:
#include <iostream>
#include <fstream> // ifstream类需要包含的头文件。
#include <string> // getline()函数需要包含的头文件。
using namespace std;
int main()
{
// 文件名一般用全路径,书写的方法如下:
// 1)"D:\data\txt\test.txt" // 错误。
// 2)R"(D:\data\txt\test.txt)" // 原始字面量,C++11标准。
// 3)"D:\\data\\txt\\test.txt" // 转义字符。
// 4)"D:/tata/txt/test.txt" // 把斜线反着写。
// 5)"/data/txt/test.txt" // Linux系统采用的方法。
string filename = R"(D:\data\txt\test.txt)";
//char filename[] = R"(D:\data\txt\test.txt)";
// 创建文件输入流对象,打开文件,如果文件不存在,则打开文件失败。。
// ios::in 缺省值。
//ifstream fin(filename);
//ifstream fin(filename, ios::in);
ifstream fin;
fin.open(filename,ios::in);
// 判断打开文件是否成功。
// 失败的原因主要有:1)目录不存在;2)文件不存在;3)没有权限,Linux平台下很常见。
if (fin.is_open() == false)
{
cout << "打开文件" << filename << "失败。\n"; return 0;
}
//// 第一种方法。
//string buffer; // 用于存放从文件中读取的内容。
//// 文本文件一般以行的方式组织数据。
//while (getline(fin, buffer))
//{
// cout << buffer << endl;
//}
//// 第二种方法。
//char buffer[16]; // 存放从文件中读取的内容。
//// 注意:如果采用ifstream.getline(),一定要保证缓冲区足够大。
//while (fin.getline(buffer, 15))
//{
// cout << buffer << endl;
//}
// 第三种方法。
string buffer;
while (fin >> buffer)
{
cout << buffer << endl;
}
fin.close(); // 关闭文件,fin对象失效前会自动调用close()。
cout << "操作文件完成。\n";
}
文件操作-写入二进制文件
二进制文件以数据块的形式组织数据,把内存中的数据直接写入文件。
包含头文件:#include
类:ofstream(output file stream)
ofstream打开文件的模式(方式):
对于ofstream,不管用哪种模式打开文件,如果文件不存在,都会创建文件。
ios::out 缺省值:会截断文件内容。
ios::trunc 截断文件内容。(truncate)
ios::app 不截断文件内容,只在文件未尾追加文件。(append)
ios::binary 以二进制方式打开文件。
**
操作文本文件和二进制文件的一些细节:**
1)在windows平台下,文本文件的换行标志是"\r\n"。
2)在linux平台下,文本文件的换行标志是"\n"。
3)在windows平台下,如果以文本方式打开文件,写入数据的时候,系统会将"\n"转换成"\r\n";读取数据的时候,系统会将"\r\n"转换成"\n"。 如果以二进制方式打开文件,写和读都不会进行转换。
4)在Linux平台下,以文本或二进制方式打开文件,系统不会做任何转换。
5)以文本方式读取文件的时候,遇到换行符停止,读入的内容中没有换行符;以二制方式读取文件的时候,遇到换行符不会停止,读入的内容中会包含换行符(换行符被视为数据)。
6)在实际开发中,从兼容和语义考虑,一般:a)以文本模式打开文本文件,用行的方法操作它;b)以二进制模式打开二进制文件,用数据块的方法操作它;c)以二进制模式打开文本文件和二进制文件,用数据块的方法操作它,这种情况表示不关心数据的内容。(例如复制文件和传输文件)d)不要以文本模式打开二进制文件,也不要用行的方法操作二进制文件,可能会破坏二进制数据文件的格式,也没有必要。(因为二进制文件中的某字节的取值可能是换行符,但它的意义并不是换行,可能是整数n个字节中的某个字节)
示例:
#include <iostream>
#include <fstream> // ofstream类需要包含的头文件。
using namespace std;
int main()
{
// 文件名一般用全路径,书写的方法如下:
// 1)"D:\data\bin\test.dat" // 错误。
// 2)R"(D:\data\bin\test.dat)" // 原始字面量,C++11标准。
// 3)"D:\\data\\bin\\test.dat" // 转义字符。
// 4)"D:/tata/bin/test.dat" // 把斜线反着写。
// 5)"/data/bin/test.dat" // Linux系统采用的方法。
string filename = R"(D:\data\bin\test.dat)";
//char filename[] = R"(D:\data\bin\test.dat)";
// 创建文件输出流对象,打开文件,如果文件不存在,则创建它。
// ios::out 缺省值:会截断文件内容。
// ios::trunc 截断文件内容。(truncate)
// ios::app 不截断文件内容,只在文件未尾追加文件。(append)
// ios::binary 以二进制方式打开文件。
//ofstream fout(filename, ios::binary);
//ofstream fout(filename, ios::out | ios::binary);
//ofstream fout(filename, ios::trunc | ios::binary);
//ofstream fout(filename, ios::app | ios::binary);
ofstream fout;
fout.open(filename, ios::app | ios::binary);
// 判断打开文件是否成功。
// 失败的原因主要有:1)目录不存在;2)磁盘空间已满;3)没有权限,Linux平台下很常见。
if (fout.is_open() == false)
{
cout << "打开文件" << filename << "失败。\n"; return 0;
}
// 向文件中写入数据。
struct st_girl { // 超女结构体。
char name[31]; // 姓名。
int no; // 编号。
char memo[301]; // 备注。
double weight; // 体重。
}girl;
girl = { "西施",3,"中国历史第一美女。" ,45.8 };
fout.write((const char *)& girl, sizeof(st_girl)); // 写入第一块数据。
girl = { "冰冰",8,"也是个大美女哦。",55.2};
fout.write((const char*)&girl, sizeof(st_girl)); // 写入第二块数据。
fout.close(); // 关闭文件,fout对象失效前会自动调用close()。
cout << "操作文件完成。\n";
}
文件操作-读取二进制文件
包含头文件:#include
类:ifstream
ifstream打开文件的模式(方式):
对于ifstream,如果文件不存在,则打开文件失败。
ios::in 缺省值。
ios::binary 以二进制方式打开文件。
示例:
#include <iostream>
#include <fstream> // ifstream类需要包含的头文件。
using namespace std;
int main()
{
// 文件名一般用全路径,书写的方法如下:
// 1)"D:\data\bin\test.dat" // 错误。
// 2)R"(D:\data\bin\test.dat)" // 原始字面量,C++11标准。
// 3)"D:\\data\\bin\\test.dat" // 转义字符。
// 4)"D:/tata/bin/test.dat" // 把斜线反着写。
// 5)"/data/bin/test.dat" // Linux系统采用的方法。
string filename = R"(D:\data\bin\test.dat)";
//char filename[] = R"(D:\data\bin\test.dat)";
// 创建文件输入流对象,打开文件,如果文件不存在,则打开文件失败。。
// ios::in 缺省值。
// ios::binary 以二进制方式打开文件。
//ifstream fin(filename , ios::binary);
//ifstream fin(filename , ios::in | ios::binary);
ifstream fin;
fin.open(filename, ios::in | ios::binary);
// 判断打开文件是否成功。
// 失败的原因主要有:1)目录不存在;2)文件不存在;3)没有权限,Linux平台下很常见。
if (fin.is_open() == false)
{
cout << "打开文件" << filename << "失败。\n"; return 0;
}
// 二进制文件以数据块(数据类型)的形式组织数据。
struct st_girl { // 超女结构体。
char name[31]; // 姓名。
int no; // 编号。
char memo[301]; // 备注。
double weight; // 体重。
}girl;
while (fin.read((char*)&girl, sizeof(girl)))
{
cout << "name=" << girl.name << ",no=" << girl.no <<
",memo=" << girl.memo << ",weight=" << girl.weight << endl;
}
fin.close(); // 关闭文件,fin对象失效前会自动调用close()。
cout << "操作文件完成。\n";
}
文件操作-随机存取
一、fstream类
fstream类既可以读文本/二进制文件,也可以写文本/二进制文件。
fstream类的缺省模式是ios::in | ios::out,如果文件不存在,则创建文件;但是,不会清空文件原有的内容。
普遍的做法是:
1)如果只想写入数据,用ofstream;如果只想读取数据,用ifstream;如果想写和读数据,用fstream,这种情况不多见。不同的类体现不同的语义。
2)在Linux平台下,文件的写和读有严格的权限控制。(需要的权限越少越好)
二、文件的位置指针
对文件进行读/写操作时,文件的位置指针指向当前文件读/写的位置。
很多资料用“文件读指针的位置”和“文件写指针的位置”,容易误导人。不管用哪个类操作文件,文件的位置指针只有一个。
1)获取文件位置指针
ofstream类的成员函数是tellp();ifstream类的成员函数是tellg();fstream类两个都有,效果相同。
std::streampos tellp();
std::streampos tellg();
2)移动文件位置指针
ofstream类的函数是seekp();ifstream类的函数是seekg();fstream类两个都有,效果相同。
方法一:
std::istream & seekg(std::streampos _Pos);
fin.seekg(128); // 把文件指针移到第128字节。
fin.seekp(128); // 把文件指针移到第128字节。
fin.seekg(ios::beg) // 把文件指针移动文件的开始。
fin.ios::end) // 把文件指针移动文件的结尾。
方法二:
std::istream & seekg(std::streamoff _Off,std::ios::seekdir _Way);
在ios中定义的枚举类型:
enum seek_dir {beg, cur, end}; // beg-文件的起始位置;cur-文件的当前位置;end-文件的结尾位置。
fin.seekg(30, ios::beg); // 从文件开始的位置往后移30字节。
fin.seekg(-5, ios::cur); // 从当前位置往前移5字节。
fin.seekg( 8, ios::cur); // 从当前位置往后移8字节。
fin.seekg(-10, ios::end); // 从文件结尾的位置往前移10字节。
三、随机存取
随机存取是指直接移动文件的位置指针,在指定位置读取/写入数据。
示例:
#include <iostream>
#include <fstream> // fstream类需要包含的头文件。
using namespace std;
int main()
{
string filename = R"(D:\data\txt\test.txt)";
fstream fs;
fs.open(filename, ios::in | ios::out);
if (fs.is_open() == false)
{
cout << "打开文件" << filename << "失败。\n"; return 0;
}
fs.seekg(26); // 把文件位置指针移动到第26字节处。
fs << "我是一只傻傻的小菜鸟。\n";
/*string buffer;
while (fs >> buffer)
{
cout << buffer << endl;
}*/
fs.close(); // 关闭文件,fs对象失效前会自动调用close()。
cout << "操作文件完成。\n";
}
文件操作-打开文件的模式(方式)
一、写文件
如果文件不存在,各种模式都会创建文件。
ios::out 1)会截断文件;2)可以用seekp()移动文件指针。
ios:trunc 1)会截断文件;2)可以用seekp()移动文件指针。
ios::app 1)不会截断文件;2)文件指针始终在文件未尾,不能用seekp()移动文件指针。
ios::ate 打开文件时文件指针指向文件末尾,但是,可以在文件中的任何地方写数据。
ios::in 打开文件进行读操作,即读取文件中的数据。
ios::binary 打开文件为二进制文件,否则为文本文件。
注:ate是at end的缩写,trunc是truncate(截断)的缩写,app是append(追加)的缩写。
文件操作-缓冲区及流状态
一、文件缓冲区
文件缓冲区(缓存)是系统预留的内存空间,用于存放输入或输出的数据。
根据输出和输入流,分为输出缓冲区和输入缓冲区。
注意,在C++中,每打开一个文件,系统就会为它分配缓冲区。不同的流,缓冲区是独立的。
程序员不用关心输入缓冲区,只关心输出缓冲区就行了。
在缺省模式下,输出缓冲区中的数据满了才把数据写入磁盘,但是,这种模式不一定能满足业务的需求。
输出缓冲区的操作:
1)flush()成员函数
刷新缓冲区,把缓冲区中的内容写入磁盘文件。
2)endl
换行,然后刷新缓冲区。
3)unitbuf
fout << unitbuf;
设置fout输出流,在每次操作之后自动刷新缓冲区。
4)nounitbuf
fout << nounitbuf;
设置fout输出流,让fout回到缺省的缓冲方式。
二、流状态
流状态有三个:eofbit、badbit和failbit,取值:1-设置;或0-清除。
当三个流状成都为0时,表示一切顺利,good()成员函数返回true。
1)eofbit
当输入流操作到达文件未尾时,将设置eofbit。
eof()成员函数检查流是否设置了eofbit。
2)badbit
无法诊断的失败破坏流时,将设置badbit。(例如:对输入流进行写入;磁盘没有剩余空间)。
bad()成员函数检查流是否设置了badbit。
3)failbit
当输入流操作未能读取预期的字符时,将设置failbit(非致命错误,可挽回,一般是软件错误,例如:想读取一个整数,但内容是一个字符串;文件到了未尾)I/O失败也可能设置failbit。
fail()成员函数检查流是否设置了failbit。
4)clear()成员函数清理流状态。
5)setstate()成员函数重置流状态。
示例1:
#include <iostream>
#include <fstream> // ofstream类需要包含的头文件。
#include <unistd.h>
using namespace std;
int main()
{
ofstream fout("/oracle/tmp/bbb.txt"); // 打开文件。
fout << unitbuf;
for (int ii = 0; ii < 1000; ii++) // 循环1000次。
{
fout << "ii=" << ii << ",我是一只傻傻傻傻傻傻傻傻傻傻傻傻傻傻的鸟。\n";
//fout.flush(); // 刷新缓冲区。
usleep(100000); // 睡眠十分之一秒。
}
fout.close(); // 关闭文件。
}
示例2
#include <iostream>
#include <fstream> // ifstream类需要包含的头文件。
#include <string> // getline()函数需要包含的头文件。
using namespace std;
int main()
{
ifstream fin(R"(D:\data\txt\test.txt)", ios::in);
if (fin.is_open() == false) {
cout << "打开文件" << R"(D:\data\txt\test.txt)" << "失败。\n"; return 0;
}
string buffer;
/*while (fin >> buffer) {
cout << buffer << endl;
}*/
while (true) {
fin >> buffer;
cout << "eof()=" << fin.eof() << ",good() = " << fin.good() << ", bad() = " << fin.bad() << ", fail() = " << fin.fail() << endl;
if (fin.eof() == true) break;
cout << buffer << endl;
}
fin.close(); // 关闭文件,fin对象失效前会自动调用close()。
}
C++异常
一、异常的语法
1)捕获全部的异常
try
{
// 可能抛出异常的代码。
// throw 异常对象;
}
catch (...)
{
// 不管什么异常,都在这里统一处理。
}
2)捕获指定的异常
try
{
// 可能抛出异常的代码。
// throw 异常对象;
}
catch (exception1 e)
{
// 发生exception1异常时的处理代码。
}
catch (exception2 e)
{
// 发生exception2异常时的处理代码。
}
在try语句块中,如果没有发生异常,执行完try语句块中的代码后,将继续执行try语句块之后的代码;如果发生了异常,用throw抛出异常对象,异常对象的类型决定了应该匹配到哪个catch语句块,如果没有匹配到catch语句块,程序将调用abort()函数中止。
如果try语句块中用throw抛出异常对象,并且匹配到了catch语句块,执行完catch语句块中的代码后,将继续执行catch语句块之后的代码,不会回到try语句块中。
如果程序中的异常没有被捕获,程序将异常中止。
示例:
#include <iostream>
using namespace std;
int main(int argc, char* argv[])
{
try
{
// 可能抛出异常的代码。
int ii = 0;
cout << "你是一只什么鸟?(1-傻傻鸟;2-小小鸟)";
cin >> ii;
if (ii==1) throw "不好,有人说我是一只傻傻鸟。"; // throw抛出const char *类型的异常。
if (ii==2) throw ii; // throw抛出int类型的异常。
if (ii==3) throw string("不好,有人说我是一只傻傻鸟。"); // throw抛出string类型的异常。
cout << "我不是一只傻傻鸟,哦耶。\n";
}
catch (int ii)
{
cout << "异常的类型是int=" << ii << endl;
}
catch (const char* ss)
{
cout << "异常的类型是const char *=" << ss << endl;
}
catch (string str)
{
cout << "异常的类型是string=" << str << endl;
}
//catch (...) // 不管什么异常,都在这里处理。
//{
// cout << "捕获到异常,具体没管是什么异常。\n";
//}
cout << "程序继续运行......\n"; // 执行完try ... catch ...后,将继续执行程序中其它的代码。
}
二、栈解旋
异常被抛出后,从进入try语句块开始,到异常被抛出之前,这期间在栈上构造的所有对象,都会被自动析构。析构的顺序与构造的顺序相反。这一过程称为栈的解旋。
也就是在执行throw前,在try执行期间构造的所有对象被自动析构后,才会进入catch匹配。
在堆上构造的对象肿么办?
三、异常规范
C++98标准提出了异常规范,目的是为了让使用者知道函数可能会引发哪些异常。
void func1() throw(A, B, C); // 表示该函数可能会抛出A、B、C类型的异常。
void func2() throw(); // 表示该函数不会抛出异常。
void func3(); // 该函数不符合C++98的异常规范。
C++11标准弃用了异常规范,使用新增的关键字noexcept指出函数不会引发异常。
void func4() noexcept; // 该函数不会抛出异常。
在实际开发中,大部分程序员懒得在函数后面加noexcept,弃用异常已是共识,没必要多此一举。
关键字noexcept也可以用作运算符,判断表达试(操作数)是否可能引发异常;如果表达式可能引发异常,则返回false,否则返回true。
四、C++标准库异常
五、重点关注的异常
1)std::bad_alloc
如果内存不足,调用new会产生异常,导致程序中止;如果在new关键字后面加(std::nothrow)选项,则返回nullptr,不会产生异常。
示例:
#include <iostream>
using namespace std;
int main()
{
try {
// 如果分配内存失败,会抛出异常。
//double* ptr = new double[100000000000];
// 如果分配内存失败,将返回nullptr,会抛出异常。
double* ptr = new (std::nothrow) double[100000000000];
if (ptr == nullptr) cout << "ptr is null.\n";
}
catch (bad_alloc& e)
{
cout << "catch bad_alloc.\n";
}
}
2)std::bad_cast
dynamic_cast可以用于引用,但是,C++没有与空指针对应的引用值,如果转换请求不正确,会出现std::bad_cast异常。
3)std::bad_typeid
假设有表达式typeid(*ptr),当ptr是空指针时,如果ptr是多态的类型,将引发std::bad_typeid异常。
六、逻辑错误异常
程序的逻辑错误产生的异常std::logic_error,通过合理的编程可以避免。
1)std::out_of_range
Defines a type of object to be thrown as exception. It reports errors that are consequence of attempt to access elements out of defined range.
It may be thrown by the member functions of std::bitset and std::basic_string, by std::stoi and std::stod families of functions, and by the bounds-checked member access functions (e.g. std::vector::at and std::map::at).
2)std::length_error
Defines a type of object to be thrown as exception. It reports errors that result from attempts to exceed implementation defined length limits for some object.
This exception is thrown by member functions of std::basic_string and std::vector::reserve.
3)std::domain_error
Defines a type of object to be thrown as exception. It may be used by the implementation to report domain errors, that is, situations where the inputs are outside of the domain on which an operation is defined.
The standard library components do not throw this exception (mathematical functions report domain errors as specified in math_errhandling). Third-party libraries, however, use this. For example, boost.math throws std::domain_error if boost::math::policies::throw_on_error is enabled (the default setting).
4)std::invalid_argument
Defines a type of object to be thrown as exception. It reports errors that arise because an argument value has not been accepted.
This exception is thrown by std::bitset::bitset, and the std::stoi and std::stof families of functions.
示例1:
#include <iostream>
#include <vector>
using namespace std;
int main()
{
try{
vector<int> vv = { 1,2,3 }; // 容器vv中只有三个元素。
vv.at(3) = 5; // 将引发out_of_range异常。
}
catch (out_of_range) {
cout << "出现了out_of_range异常。\n";
}
}
示例2:
#include <stdexcept>
#include <iostream>
#include <string>
using namespace std;
int main()
{
string str = "123"; // 不会抛出异常。
//string str = ""; // 将抛出Invalid_argument异常。
//string str = "253647586946334221002101"; // 将抛出out_of_range异常。
try {
int x = stoi(str); // 把string字符串转换为整数。
cout << "x=" << x << endl;
}
catch (invalid_argument&) {
cout << " invalid_argument. \n";
}
catch (out_of_range&) {
cout << " out of range. \n";
}
catch (...) {
cout << " something else…" << endl;
}
}
七、其它异常
1)std::range_error
Defines a type of object to be thrown as exception. It can be used to report range errors (that is, situations where a result of a computation cannot be represented by the destination type).
The only standard library components that throw this exception are std::wstring_convert::from_bytes and std::wstring_convert::to_bytes.
The mathematical functions in the standard library components do not throw this exception (mathematical functions report range errors as specified in math_errhandling).
2)std::overflow_error
Defines a type of object to be thrown as exception. It can be used to report arithmetic overflow errors (that is, situations where a result of a computation is too large for the destination type)
The only standard library components that throw this exception are std::bitset::to_ulong and std::bitset::to_ullong.
The mathematical functions of the standard library components do not throw this exception (mathematical functions report overflow errors as specified in math_errhandling). Third-party libraries, however, use this. For example, boost.math throws std::overflow_error if boost::math::policies::throw_on_error is enabled (the default setting).
3)std::underflow_error
Defines a type of object to be thrown as exception. It may be used to report arithmetic underflow errors (that is, situations where the result of a computation is a subnormal floating-point value)
The standard library components do not throw this exception (mathematical functions report underflow errors as specified in math_errhandling). Third-party libraries, however, use this. For example, boost.math throws std::underflow_error if boost::math::policies::throw_on_error is enabled (the default setting
4)ios_base::failure
这个异常,程序员不主动找它就没事。
示例:
#include <iostream>
#include <fstream>
int main()
{
using namespace std;
fstream file;
file.exceptions(ios::failbit); // 设置如果出现ios::failbit,就引发异常。
try
{
file.open("rm.txt", ios_base::in); // 如果打开的文件不存在,就会引发异常。
}
catch (ios_base::failure f)
{
cout << caught an exception: " << f.what() << endl;
}
}
5)std::bad_exception
This is a special type of exception specifically designed to be listed in the dynamic-exception-specifier of a function (i.e., in its throw specifier).
If a function with bad_exception listed in its dynamic-exception-specifier throws an exception not listed in it and unexpected rethrows it (or throws any other exception also not in the dynamic-exception-specifier), a bad_exception is automatically thrown.
C++断言
一、断言
断言(assertion)是一种常用的编程手段,用于排除程序中不应该出现的逻辑错误。
使用断言需要包含头文件
语法:assert(表达式);
断言就是判断(表达式)的值,如果为0(false),程序将调用abort()函数中止,如果为非0(true),程序继续执行。
断言可以提高程序的可读性,帮助程序员定位违反了某些前提条件的错误。
注意:
断言用于处理程序中不应该发生的错误,而非逻辑上可能会发生的错误。
不要把需要执行的代码放到断言的表达式中。
断言的代码一般放在函数/成员函数的第一行,表达式多为函数的形参。
示例:
#include <iostream>
#include <cassert> // 断言assert宏需要包含的头文件。
using namespace std;
void copydata(void *ptr1,void *ptr2) // 把ptr2中的数据复制到ptr1中。
{
assert(ptr1&&ptr2); // 断言ptr1和ptr2都不会为空。
cout << "继续执行复制数据的代码......\n";
}
int main()
{
int ii=0,jj=0;
copydata(&ii, &jj); // 把ptr2中的数据复制到ptr1中。
}
二、C++11静态断言
assert宏是运行时断言,在程序运行的时候才能起作用。
C++11新增了静态断言static_assert,用于在编译时检查源代码。
使用静态断言不需要包含头文件。
语法:static_assert(常量表达式,提示信息);
注意:static_assert的第一个参数是常量表达式。而assert的表达式既可以是常量,也可以是变量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号