rabbitMQ消息队列
消息队列的前提
1、什么叫星轨?
2、使用消息队列
什么是消息中间件?
星轨
# 一星轨表示一个一线明星出轨所带来的流量,微博的服务器现在能同时扛8星轨。
也就是说:8个一线明星同一时间爆出出轨的新闻,微博都能扛得住!
微博的流量波动是很难预测的,指不定什么时候出来一个热点话题,微博的流量就会垂直上升,这也是微博和其他网站最大的区别。
如:淘宝、百度地图、京东这些应用平时的流量是很稳定的,不会出现短时间的暴增,也不会出现急剧下滑的现象。
在特殊的时间点,如双十一、618、节假日等情况下,工程师们会提前增加N倍的服务器进行应对,来解决高并发量带来的服务器瘫痪等异常,而微博的特殊情况属于不可预知的。
他们采取的方式都是在流量高峰到来之前扩充更多的服务器(不少企业都是租用亚马逊、阿里云等云服务提供商的服务器),用完之后就释放,这样能节约不少成本
而微博就很无奈了,因为它无法预测流量高峰,谁也不知道明星们啥时候就搞个出轨或是其他新闻出来,流量短时间暴增,微博的服务器就扛不住了。
下图是邓超2015年12月20日刷屏的微博,那一天他的刷屏就把微博服务器给搞挂了不少!
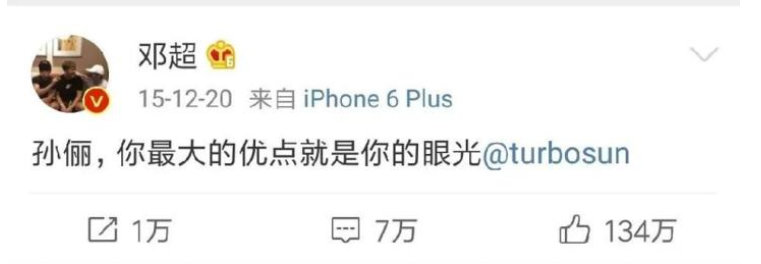
鉴于以上的特殊情况,微博应对的解决方法就是引入了消息队列
如何使用““消息队列”来应对大流量高并发下用户提交内容的入库问题。
什么是消息中间件?
简单的理解如下图示:先应用消息队列来接收一系列的访问,再进行分发进行,减缓对服务器同时的访问量。
当用户发送请求之后(评论操作或者消息请求操作),中转设备就把流量分摊到集群中的各个物理节点上,比如使用Nginx做代理以及负载均衡;
消息队列可以把消息分类,分别下发,比如点赞、评论和转发,各自走各自的通道。 消息队列可以暂存消息。当用户的请求到达消息队列以后,消息队列就给用户发出响应,显示评论成功,即使这时候该评论还没写入数据库,
可是用户是不感知的。当流量暴增的时候,生产者生成的消息大于消费者的处理能力,消息就会先被暂存在消息队列里,然后消费者全力去处理,
这样就避免了服务器压力过大。消息队列并不是全部存储在内存中,也是可以写入硬盘的,所以能存储很大量的消息。
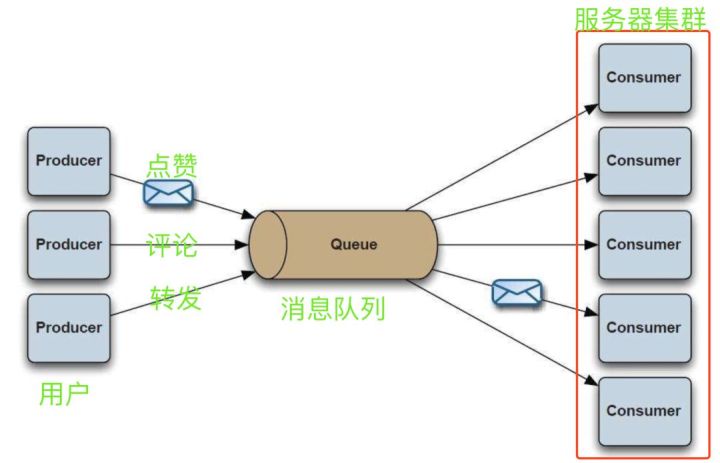
在简单的举个例子:

由此可以看出,引入消息队列后,用户的响应时间就等于写入数据库的时间+写入消息队列的时间(可以忽略不计),
引入消息队列后处理后,响应时间是串行的3倍,是并行的2倍。
队列、生产者、消费者
队列是RabbitMQ的内部对象,用于存储消息。生产者(下图中的P)生产消息并投递到队列中,消费者(下图中的C)可以从队列中获取消息并消费。

# 多个消费者可以订阅同一个队列,这时队列中的消息会被平均分摊给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理。

rabbitMQ
其是一个软件,需要安装,启动服务端才能使用

安装后启动服务:
进入官网查看相关的信息
介绍
RabbitMQ是消息代理:它接受并转发消息。您可以将其视为邮局:将要发布的邮件放在邮箱中时,可以确保Mailperson先生或女士最终将邮件传递给收件人。
以此类推,RabbitMQ是一个邮箱,一个邮局和一个邮递员。
RabbitMQ与邮局之间的主要区别在于,它不处理纸张,而是接收,存储和转发数据消息的二进制斑点。
RabbitMQ和一般的消息传递使用一些术语。
根据官方文档实现消息队列简单的输出“hello world”
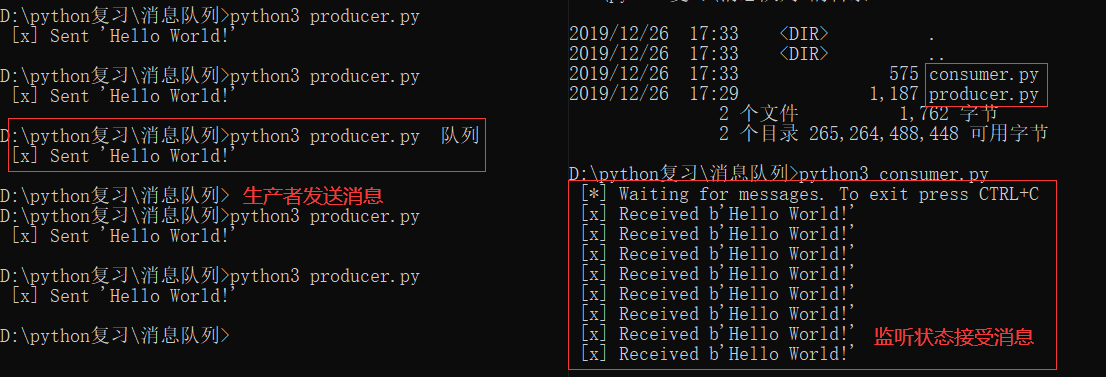
生产者
向消息中间件rabbitMQ发送消息
# #!/usr/bin/env python import pika #先建立连接 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 向rabbitMQ发送消息 channel.queue_declare(queue="hello") channel.basic_publish(exchange='', routing_key='hello', body='Hello World!') print(" [x] Sent 'Hello World!'") connection.close()
消费者
接收消息中间件的传的信息
# !/usr/bin/env python import pika connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.queue_declare(queue='hello') # 回调函数 def callback(ch, method, properties, body): print(" [x] Received %r" % body) # 从消息队列中取出值 channel.basic_consume(queue='hello', auto_ack=True, on_message_callback=callback) print(' [*] Waiting for messages. To exit press CTRL+C') # 开始进行消费 channel.start_consuming()
切换到CMD终端分别运行两个py文件,效果如下:
本文来自博客园,作者:游走De提莫,转载请注明原文链接:https://www.cnblogs.com/Gaimo/p/12103979.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号