Go-并发和并行-协程-信道-缓冲信道-select-mutex-读写文件-beego框架
并发
Go 是并发式语言,而不是并行式语言。在讨论 Go 如何处理并发之前,我们必须理解何为并发,以及并发与并行的区别。
并发是什么?
并发是指立即处理多个任务的能力。一个CPU的情况下<意指看上去像是同时运行,其中有io的阻塞态等待的时间慢而已。
例子1:
我们可以想象一个人正在跑步。假如在他晨跑时,鞋带突然松了。于是他停下来,系一下鞋带,接下来继续跑。这个例子就是典型的并发。这个人能够一下搞定跑步和系鞋带两件事,即立即处理多个任务。
例子2:
并发:你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
并行:你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并
理解:
解释一:并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔发生。
解释二:并行是在不同实体上的多个事件,并发是在同一实体上的多个事件。
解释三:在一台处理器上“同时”处理多个任务,在多台处理器上同时处理多个任务。如hadoop分布式集群
并行是什么?并行和并发有何区别?
并行是指同时处理多个任务。这听起来和并发差不多,但其实完全不同。
我们同样用这个跑步的例子来帮助理解。假如这个人在慢跑时,还在用他的 iPod 听着音乐。在这里,他是在跑步的同时听音乐,也就是同时处理多个任务。这称之为并行。
Go 对并发的支持
Go 编程语言原生支持并发。Go 使用 Go 协程(Goroutine) 和信道(Channel)来处理并发。在接下来的教程里,我们还会详细介绍它们。
Go 协程是什么?
Go 协程是与其他函数或方法一起并发运行的函数或方法。Go 协程可以看作是轻量级线程。与线程相比,创建一个 Go 协程的成本很小。因此在 Go 应用中,常常会看到有数以千计的 Go 协程并发地运行。
Go 协程相比于线程的优势
- 相比线程而言,Go 协程的成本极低。堆栈大小只有若干 kb,并且可以根据应用的需求进行增减。而线程必须指定堆栈的大小,其堆栈是固定不变的。
- Go 协程会复用(Multiplex)数量更少的 OS 线程。即使程序有数以千计的 Go 协程,也可能只有一个线程。如果该线程中的某一 Go 协程发生了阻塞(比如说等待用户输入),那么系统会再创建一个 OS 线程,并把其余 Go 协程都移动到这个新的 OS 线程。所有这一切都在运行时进行,作为程序员,我们没有直接面临这些复杂的细节,而是有一个简洁的 API 来处理并发。
- Go 协程使用信道(Channel)来进行通信。信道用于防止多个协程访问共享内存时发生竞态条件(Race Condition)。信道可以看作是 Go 协程之间通信的管道。我们会在下一教程详细讨论信道。
如何启动一个 Go 协程?
调用函数或者方法时,在前面加上关键字 go,可以让一个新的 Go 协程并发地运行。
例子:
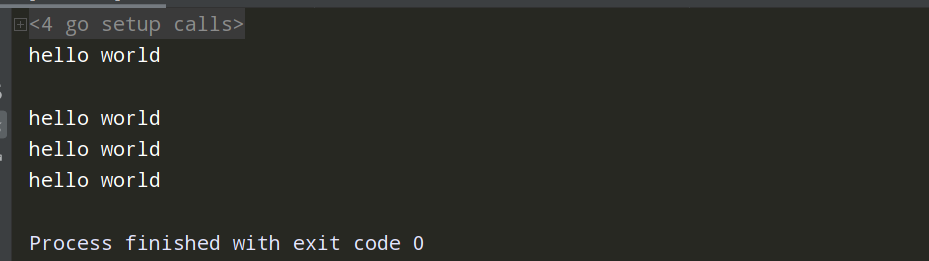
package main import ( "fmt" "time" ) // go协程 func index() { fmt.Println("hello world") } func main() { go index() go index() go index() go index() fmt.Println("") time.Sleep(time.Second*3) }
协程的书写直接在函数前加关键字“go”即可开启协程,运行是从上至下,遇到io阻塞态时等待自行的切换处理。各个协程之间做数据的通信,开多个协程就是这么简单的实现。
time模块的时间传参,点击second查看源码:

总结:
- 启动一个新的协程时,协程的调用会立即返回。与函数不同,程序控制不会去等待 Go 协程执行完毕。在调用 Go 协程之后,程序控制会立即返回到代码的下一行,忽略该协程的任何返回值。
- 如果希望运行其他 Go 协程,Go 主协程必须继续运行着。如果 Go 主协程终止,则程序终止,于是其他 Go 协程也不会继续运行。
信道(channel)
什么是信道?
信道可以想像成 Go 协程之间通信的管道。如同管道中的水会从一端流到另一端,通过使用信道,数据也可以从一端发送,在另一端接收。
信道的声明
所有信道都关联了一个类型。信道只能运输这种类型的数据,而运输其他类型的数据都是非法的。
chan T 表示 T 类型的信道。信道是一个值类型,可以作为参数传递。
信道的零值为 nil。信道的零值没有什么用,应该像对 map 和切片所做的那样,用 make 来定义信道。
下面编写代码,声明一个信道。
package main import ( "fmt" "time" ) //信道、管道 通道 channel // func main() { // //信道也是个变量 // //信道运输的类型是int类型 // //空值 是nil 引用类型 // var a chan int // fmt.Println(a) // //初始化 var a chan int =make(chan int) fmt.Println(a) // //重点 :放值和取值 // //箭头向信道变量,就是往信道中放值 a <-1 // //箭头向外,表示从信道中取值 <-a // //信道默认情况下,取值和赋值都是阻塞的 ******重要**** // }
简短声明通常也是一种定义信道的简洁有效的方法。
a := make(chan int)
这一行代码同样定义了一个 int 类型的信道 a,类型可以是其他数据结构bool string int...

通过信道进行发送和接收
如下所示,该语法通过信道发送和接收数据。
data := <- a // 读取信道 a a <- data // 写入信道 a
信道旁的箭头方向指定了是发送数据还是接收数据。
在第一行,箭头对于 a 来说是向外指的,因此我们读取了信道 a 的值,并把该值存储到变量 data。
在第二行,箭头指向了 a,因此我们在把数据写入信道 a。
package main import ( "fmt" "time" ) // 信道,管道,通道 channel func main() { // 定义信道 // 信道也是个变量 // 控制nil 引用的类型时int //var a chan int //fmt.Println(a) // 初始化 var a chan int =make(chan int ) fmt.Println(a) // 重点:放值和取值 // 箭头向通道变量 就是往信道中值 a<-1 // 阻塞态 不在往下运行 等待取值 // 箭头向外,表示信道中取值 b:=<-a fmt.Println(b) time.Sleep(time.Second*1) //信道默认情况下,取值和赋值都是阻塞的 ******重要**** }
信道默认情况下,取值和赋值都是阻塞的,存和取都需要通过信道之间的通信进行传递参数,不然会造成死锁现象。
发送与接收默认是阻塞的
发送与接收默认是阻塞的。这是什么意思?当把数据发送到信道时,程序控制会在发送数据的语句处发生阻塞,直到有其它 Go 协程从信道读取到数据,才会解除阻塞。与此类似,当读取信道的数据时,如果没有其它的协程把数据写入到这个信道,那么读取过程就会一直阻塞着。
信道的这种特性能够帮助 Go 协程之间进行高效的通信,不需要用到其他编程语言常见的显式锁或条件变量。
信道的代码示例
接下来写点代码,看看协程之间通过信道是怎么通信的吧。
package main import ( "fmt" "time" ) // go协程 信道之间的通信传递 func index1(a chan bool) { fmt.Println("hello go") // 一旦执行完毕,往信道中存放一个值 time.Sleep(time.Second*3) a<-true fmt.Println("Just do IT") } func main() { // 必须初始化 var a chan bool = make(chan bool) go index1(a) // 从信道中取值 <-a //b:=<-a //fmt.Println(b) time.Sleep(time.Second*3) }
加入time.sleep模拟IO阻塞态,来更好的理解go协程中使用信道通信的传递。
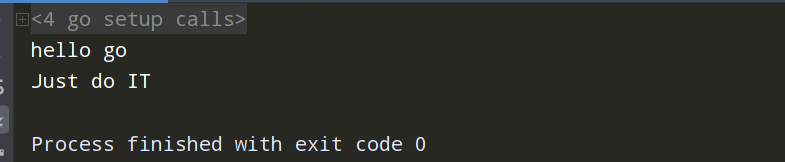
信道的代码示例:
我们再编写一个程序来更好地理解信道。该程序会计算一个数中每一位的平方和与立方和,然后把平方和与立方和相加并打印出来。
例如,如果输出是 123,该程序会如下计算输出:
squares = (1 * 1) + (2 * 2) + (3 * 3) cubes = (1 * 1 * 1) + (2 * 2 * 2) + (3 * 3 * 3) output = squares + cubes = 50
我们会这样去构建程序:在一个单独的 Go 协程计算平方和,而在另一个协程计算立方和,最后在 Go 主协程把平方和与立方和相加。
package main import "fmt" // 例子 //number =456 func calcSquares(number int, squareop chan int) { sum := 0 for number != 0 { digit := number % 10 sum += digit * digit number /= 10 } squareop <- sum } func calcCubes(number int, a chan int) { sum := 0 for number != 0 { digit := number % 10 sum += digit * digit*digit number /= 10 } a <- sum } func main() { //运输平方和 var a chan int=make(chan int) //运输立方和 var b chan int=make(chan int) number:=123
//开启两个go协程 go calcSquares(number,a) go calcCubes(number,b) sum1:=<-a sum2:=<-b // 开两个协程分别进行,最后计算总和即可,速度很快 fmt.Println(sum1+sum2) }
协程分任务执行,速度很快。

死锁
使用信道需要考虑的一个重要的是死锁,当GO协程给一个信道发送数据时,照理说会有其他G协程来接收数据,
如果没有的话,程序会在运行时触发panic,形成死锁现象。
同理,当有 Go 协程等着从一个信道接收数据时,我们期望其他的 Go 协程会向该信道写入数据,要不然程序就会触发 panic。
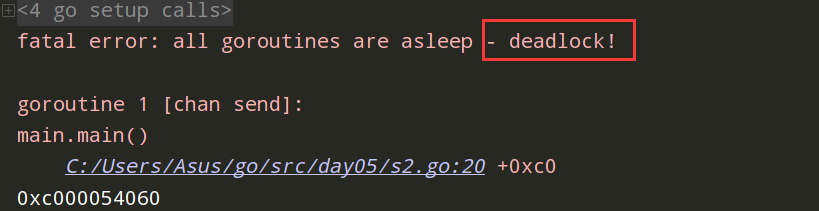
package main func main() { ch := make(chan int) ch <- 5 }
没有接收信道的值会报错:

单向信道
我们目前讨论的信道都是双向信道,即通过信道既能发送数据,又能接收数据。其实也可以创建单向信道,这种信道只能发送或者接收数据。
package main import "fmt" //单向信道 只能放或者只能取 func sendData(sendch chan<- int) { sendch <- 10 } func main() { // 只写信道 sendch := make(chan int) go sendData(sendch) fmt.Println(<-sendch) }
...>>> 10
关闭信道和使用 for range 遍历信道
数据发送方可以关闭信道,通知接收方这个信道不再有数据发送过来
当从信道接收数据时,接收方可以多用一个变量来检查信道是否已经关闭。
v, ok := <- ch
上面的语句里,如果成功接收信道所发送的数据,那么 ok 等于 true。而如果 ok 等于 false,说明我们试图读取一个关闭的通道。从关闭的信道读取到的值会是该信道类型的零值。例如,当信道是一个 int 类型的信道时,那么从关闭的信道读取的值将会是 0。
package main import "fmt" //关闭信道和使用 for range 遍历信道 func producer(chnl chan int) { for i := 0; i < 10; i++ { chnl <- i } close(chnl) } func main() { ch := make(chan int) go producer(ch) for { v, ok := <-ch // 如果信道关闭,ok就是false //如果没关闭,就是true if ok == false { break } fmt.Println("Received ", v, ok) } }
主函数用的是for循环,会打印出0-9,然后关闭通道,使用变量 ok,检查信道是否已经关闭。如果 ok 等于 false,说明信道已经关闭,于是退出 for 循环。如果 ok 等于 true,会打印出接收到的值和 ok 的值。

用range来循环读取数据,range会自动判断,取完值后直接关闭,比for更好一些
package main import ( "fmt" ) func producer(chnl chan int) { for i := 0; i < 10; i++ { chnl <- i } close(chnl) } func main() { ch := make(chan int) go producer(ch) for v := range ch { fmt.Println("Received ",v) } }
for range 循环从信道 ch 接收数据,直到该信道关闭。一旦关闭了 ch,循环会自动结束。该程序会输出:
Received 0 Received 1 Received 2 Received 3 Received 4 Received 5 Received 6 Received 7 Received 8 Received 9
用for-range优化上述计算平和的例子:
package main import "fmt" //优化例子 //number=456 func digits(number int, dchnl chan int) { for number != 0 { digit := number % 10 dchnl <- digit number /= 10 } close(dchnl) } func calcSquares1(number int, squareop chan int) { sum := 0 dch := make(chan int) go digits(number, dch) for digit := range dch { sum += digit * digit } squareop <- sum } func calcCubes1(number int, cubeop chan int) { sum := 0 dch := make(chan int) go digits(number, dch) for digit := range dch { sum += digit * digit * digit } cubeop <- sum } func main() { number := 123 sqrch := make(chan int) cubech := make(chan int) go calcSquares1(number, sqrch) go calcCubes1(number, cubech) squares:= <-sqrch cubes :=<-cubech fmt.Println("Final output", squares+cubes) }
缓冲信道和工作池
什么是缓冲信道?
无缓冲信道的发送和接收过程是阻塞的。
我们还可以创建一个有缓冲(Buffer)的信道。只在缓冲已满的情况,才会阻塞向缓冲信道(Buffered Channel)发送数据。同样,只有在缓冲为空的时候,才会阻塞从缓冲信道接收数据。
package main import "fmt" //缓冲信道 func main() { //定义了一个缓冲大小为3的信道,可以放三个值 var a chan int=make(chan int,3) // 放三个值 a<-1 a<-2 a<-3 // 也可以去三个字,有缓冲,不会造成阻塞态 <-a <-a b:=<-a fmt.Println("Hello go") fmt.Println(b) }
类似管道,水的流通从上到下,有缓冲时,不会阻塞,多取才会报错死锁。

例子:
package main import "fmt" //例子 func write(ch chan int) { for i := 0; i < 5; i++ { ch <- i fmt.Println("successfully wrote", i, "to ch") } close(ch) } func main() { ch := make(chan int, 2) go write(ch) time.Sleep(2 * time.Second) for v := range ch { fmt.Println("read value", v,"from ch") time.Sleep(2 * time.Second) }
其中有一个并发的 Go 协程来向信道写入数据,而 Go 主协程负责读取数据。该示例帮助我们进一步理解,在向缓冲信道写入数据时,什么时候会发生阻塞。
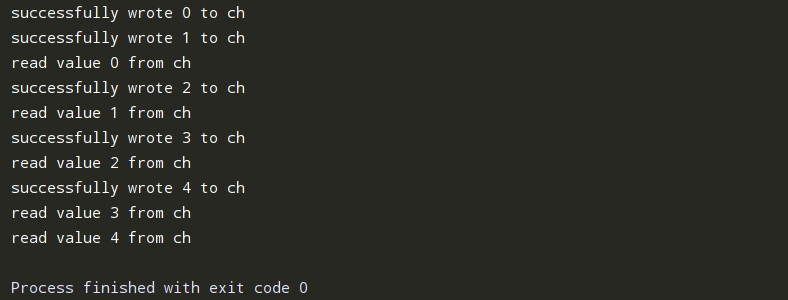
该过程会一直进行,放一个取一个,直到信道读取完所有的值,并在 write 协程中关闭信道。
长度 vs 容量
缓冲信道的容量是指信道可以存储的值的数量。我们在使用 make 函数创建缓冲信道的时候会指定容量大小。
缓冲信道的长度是指信道中当前排队的元素个数。
//长度 vs 容量 //长度是目前里面有几个值 //容量是最多能放多少值 func main() { var a =make(chan int ,4) a<-1 a<-2 fmt.Println(len(a)) fmt.Println(cap(a)) <-a fmt.Println(len(a)) fmt.Println(cap(a)) }
WaitGroup
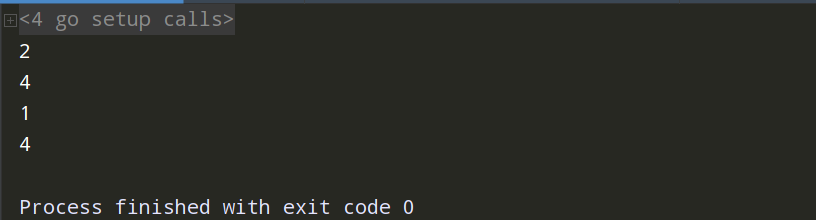
WaitGroup 用于等待一批 Go 协程执行结束。程序控制会一直阻塞,直到这些协程全部执行完毕。假设我们有 3 个并发执行的 Go 协程(由 Go 主协程生成)。Go 主协程需要等待这 3 个协程执行结束后,才会终止。这就可以用 WaitGroup 来实现。
package main import ( "fmt" "sync" "time" ) //WaitGroup:等待所有go协程执行完成 func test6(wg *sync.WaitGroup,i int) { time.Sleep(time.Second*2) fmt.Println(i) wg.Done() } func main() { //sync包下的WaitGroup,是个结构体的值类型,当参传递,需要取地址 var wg sync.WaitGroup for i:=0;i<5;i++{ //wg.Add表示标志了起了一个goroutine wg.Add(1) go test6(&wg,i) } //等待所有协程执行完成 wg.Wait() fmt.Println("都执行完了") }
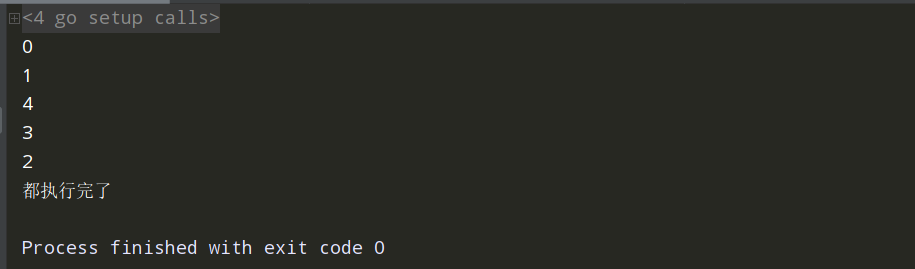
通过信道来实现工作池waitgroup
//通过信道实现 func main() { var a =make(chan bool) for i:=0;i<5;i++{ go test6(a,i) } for i:=0;i<5;i++{ <-a } fmt.Println("都执行完了") } func test6(a chan bool,i int) { time.Sleep(time.Second*2) fmt.Println(i) a<-true }
由于 Go 协程的执行顺序不一定,每次的执行的结果不一样:
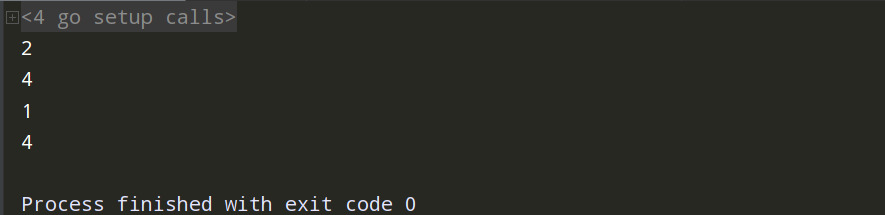
Select
什么是 select?
select 语句用于在多个发送/接收信道操作中进行选择。select 语句会一直阻塞,直到发送/接收操作准备就绪。如果有多个信道操作准备完毕,select 会随机地选取其中之一执行。该语法与 switch 类似,所不同的是,这里的每个 case 语句都是信道操作。我们好好看一些代码来加深理解吧。
package main import ( "fmt" //"time" ) //select func test5(a chan int) { //time.Sleep(time.Second * 2) a <- 1 } func test7(b chan int) { //time.Sleep(time.Second * 3) b <- 1 } func main() { a := make(chan int) b := make(chan int) go test5(a) go test7(b) for { select { case <-a: fmt.Println("test5执行完成了") return case <-b: fmt.Println("test7执行完成了") return default: fmt.Println("谁也没回来") //time.Sleep(time.Second*1) } } }
例子二:
默认情况
在没有 case 准备就绪时,可以执行 select 语句中的默认情况(Default Case)。这通常用于防止 select 语句一直阻塞。
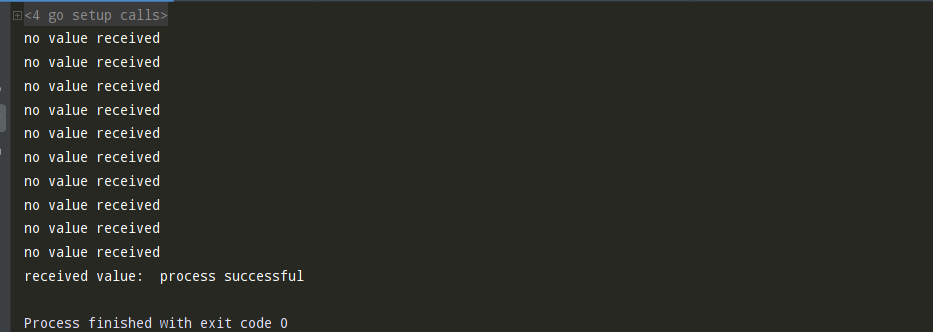
package main import ( "fmt" "time" ) func process(ch chan string) { time.Sleep(10500 * time.Millisecond) ch <- "process successful" } func main() { ch := make(chan string) go process(ch) for { time.Sleep(1000 * time.Millisecond) select { case v := <-ch: fmt.Println("received value: ", v) return default: fmt.Println("no value received") } } }
上述程序中,第 8 行的 process 函数休眠了 10500 毫秒(10.5 秒),接着把 process successful 写入 ch 信道。在程序中的第 15 行,并发地调用了这个函数。
在并发地调用了 process 协程之后,主协程启动了一个无限循环。这个无限循环在每一次迭代开始时,都会先休眠 1000 毫秒(1 秒),然后执行一个 select 操作。在最开始的 10500 毫秒中,由于 process 协程在 10500 毫秒后才会向 ch 信道写入数据,因此 select 语句的第一个 case(即 case v := <-ch:)并未就绪。所以在这期间,程序会执行默认情况,该程序会打印 10 次 no value received。
在 10.5 秒之后,process 协程会在第 10 行向 ch 写入 process successful。现在,就可以执行 select 语句的第一个 case 了,程序会打印 received value: process successful,然后程序终止。该程序会输出:
死锁与默认情况
package main func main() { ch := make(chan string) select { case <-ch: } }
由于没有 Go 协程向该信道写入数据,因此 select 语句会一直阻塞,导致死锁。该程序会触发运行时 panic,报错信息如下:
fatal error: all goroutines are asleep - deadlock! goroutine 1 [chan receive]: main.main() /tmp/sandbox416567824/main.go:6 +0x80
随机选取
当 select 由多个 case 准备就绪时,将会随机地选取其中之一去执行。
package main import ( "fmt" "time" ) func server1(ch chan string) { ch<-"from servser1" } func server2(ch chan string) { ch<-"from servser2" } func main() { Output1 :=make(chan string) Output2 :=make(chan string) go server1(Output1) go server1(Output2) time.Sleep(time.Second*2) select{ case s1 :=<-Output1: fmt.Println(s1) case s2 :=<-Output2: fmt.Println(s2) } }
Mutex
临界区
在学习 Mutex 之前,我们需要理解并发编程中临界区(Critical Section)的概念。当程序并发地运行时,多个 [Go 协程]不应该同时访问那些修改共享资源的代码。这些修改共享资源的代码称为临界区。例如,假设我们有一段代码,将一个变量 x 自增 1。
x = x + 1
多个协程同时操作同一个数据,会导致并发数据不安全,需加锁处理。
Mutex
Mutex 用于提供一种加锁机制(Locking Mechanism),可确保在某时刻只有一个协程在临界区运行,以防止出现竞态条件。
Mutex 可以在 [sync] 包内找到。[Mutex] 定义了两个方法:[Lock]和 [Unlock](。所有在 Lock 和 Unlock 之间的代码,都只能由一个 Go 协程执行,于是就可以避免竞态条件。
mutex.Lock() x = x + 1 mutex.Unlock()
在上面的代码中,x = x + 1 只能由一个 Go 协程执行,因此避免了竞态条件。
如果有一个 Go 协程已经持有了锁(Lock),当其他协程试图获得该锁时,这些协程会被阻塞,直到 Mutex 解除锁定为止。
package main import ( "fmt" "sync" ) //通过锁实现 var x = 0 func increment(wg *sync.WaitGroup,m *sync.Mutex) { m.Lock() x = x + 1 m.Unlock() wg.Done() } func main() { var w sync.WaitGroup var m sync.Mutex //值类型,传递地址 for i := 0; i < 1000; i++ { w.Add(1) go increment(&w,&m) } w.Wait() fmt.Println("final value of x", x) }
>>>final value of x 1000
使用信道处理竞态条件
package main import ( "fmt" "sync" ) var x = 0 func increment(wg *sync.WaitGroup, ch chan bool) { ch <- true x = x + 1 <- ch wg.Done() } func main() { var w sync.WaitGroup ch := make(chan bool, 1) for i := 0; i < 1000; i++ { w.Add(1) go increment(&w, ch) } w.Wait() fmt.Println("final value of x", x) }
Mutex vs 信道
通过使用 Mutex 和信道,我们已经解决了竞态条件的问题。那么我们该选择使用哪一个?答案取决于你想要解决的问题。如果你想要解决的问题更适用于 Mutex,那么就用 Mutex。如果需要使用 Mutex,无须犹豫。而如果该问题更适用于信道,那就使用信道。:)
由于信道是 Go 语言很酷的特性,大多数 Go 新手处理每个并发问题时,使用的都是信道。这是不对的。Go 给了你选择 Mutex 和信道的余地,选择其中之一都可以是正确的。
总体说来,当 Go 协程需要与其他协程通信时,可以使用信道。而当只允许一个协程访问临界区时,可以使用 Mutex。
就我们上面解决的问题而言,我更倾向于使用 Mutex,因为该问题并不需要协程间的通信。所以 Mutex 是很自然的选择。
我的建议是去选择针对问题的工具,而别让问题去将就工具。
结构体取代类
Go 支持面向对象吗?
Go 并不是完全面向对象的编程语言。Go 官网回答了 Go 是否是面向对象语言,摘录如下。
可以说是,也可以说不是。虽然 Go 有类型和方法,支持面向对象的编程风格,但却没有类型的层次结构。Go 中的“接口”概念提供了一种不同的方法,我们认为它易于使用,也更为普遍。Go 也可以将结构体嵌套使用,这与子类化(Subclassing)类似,但并不完全相同。此外,Go 提供的特性比 C++ 或 Java 更为通用:子类可以由任何类型的数据来定义,甚至是内建类型(如简单的“未装箱的”整型)。这在结构体(类)中没有受到限制。
在接下来的教程里,我们会讨论如何使用 Go 来实现面向对象编程概念。与其它面向对象语言(如 Java)相比,Go 有很多完全不同的特性。
文件的读取
package main import ( "flag" "fmt" "io/ioutil" ) func main() { fptr := flag.String("fpath", "test.txt", "file path to read from") flag.Parse() data, err := ioutil.ReadFile(*fptr) if err != nil { fmt.Println("File reading error", err) return } fmt.Println("Contents of file:", string(data)) }
beego搭建web框架
根据官方文档按步骤操作:

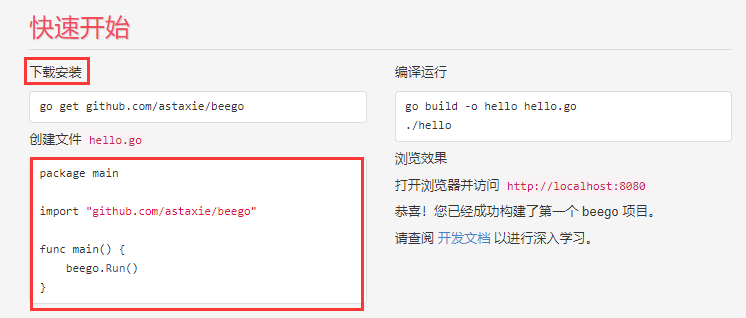
快速入门
参考地址:
https://github.com/beego/beedoc/blob/master/zh-CN/quickstart.md
安装
beego 包含一些示例应用程序以帮您学习并使用 beego 应用框架。
您需要安装 Go 1.1+ 以确保所有功能的正常使用。
你需要安装或者升级 Beego 和 Bee 的开发工具:
$ go get -u github.com/astaxie/beego
$ go get -u github.com/beego/bee
为了更加方便的操作,请将 $GOPATH/bin 加入到你的 $PATH 变量中。请确保在此之前您已经添加了 $GOPATH 变量。
# 如果您还没添加 $GOPATH 变量
$ echo 'export GOPATH="$HOME/go"' >> ~/.profile # 或者 ~/.zshrc, ~/.cshrc, 您所使用的sh对应的配置文件
# 如果您已经添加了 $GOPATH 变量
$ echo 'export PATH="$GOPATH/bin:$PATH"' >> ~/.profile # 或者 ~/.zshrc, ~/.cshrc, 您所使用的sh对应的配置文件
$ exec $SHELL
想要快速建立一个应用来检测安装?
$ cd $GOPATH/src
$ bee new hello
$ cd hello
$ bee run
Windows 平台下输入:
>cd %GOPATH%/src
>bee new hello
>cd hello
>bee run
这些指令帮助您:
- 安装 beego 到您的 $GOPATH 中。
- 在您的计算机上安装 Bee 工具。
- 创建一个名为 “hello” 的应用程序。
- 启动热编译。
一旦程序开始运行,您就可以在浏览器中打开 http://localhost:8080/ 进行访问。
简单示例
下面这个示例程序将会在浏览器中打印 “Hello world”,以此说明使用 beego 构建 Web 应用程序是多么的简单!
package main import ( "github.com/astaxie/beego" ) type MainController struct { beego.Controller } func (this *MainController) Get() { this.Ctx.WriteString("hello world") } func main() { beego.Router("/", &MainController{}) beego.Run() }
把上面的代码保存为 hello.go,然后通过命令行进行编译并执行:
$ go build -o hello hello.go
$ ./hello
这个时候你可以打开你的浏览器,通过这个地址浏览 http://127.0.0.1:8080 返回 “hello world”。

在终端检测beego是否安装成功:

已经启动了一个简易的server服务端,点击地址即可访问。
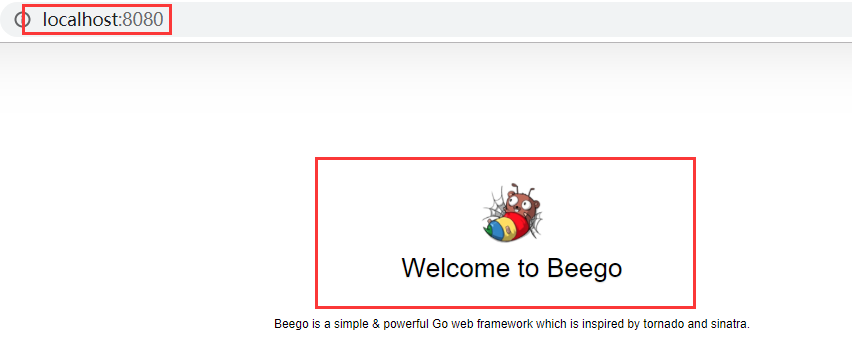
那么上面的代码到底做了些什么呢?
- 首先我们导入了包
github.com/astaxie/beego。我们知道 Go 语言里面被导入的包会按照深度优先的顺序去执行导入包的初始化(变量和 init 函数,更多详情),beego 包中会初始化一个 BeeAPP 的应用和一些参数。 - 定义 Controller,这里我们定义了一个 struct 为
MainController,充分利用了 Go 语言的组合的概念,匿名包含了beego.Controller,这样我们的MainController就拥有了beego.Controller的所有方法。 - 定义 RESTful 方法,通过匿名组合之后,其实目前的
MainController已经拥有了Get、Post、Delete、Put等方法,这些方法是分别用来对应用户请求的 Method 函数,如果用户发起的是 POST 请求,那么就执行Post函数。所以这里我们定义了MainController的Get方法用来重写继承的Get函数,这样当用户发起 GET 请求的时候就会执行该函数。 - 定义 main 函数,所有的 Go 应用程序和 C 语言一样都是 main 函数作为入口,所以我们这里定义了我们应用的入口。
- Router 注册路由,路由就是告诉 beego,当用户来请求的时候,该如何去调用相应的 Controller,这里我们注册了请求
/的时候,请求到MainController。这里我们需要知道,Router 函数的两个参数函数,第一个是路径,第二个是 Controller 的指针。 - Run 应用,最后一步就是把在步骤 1 中初始化的 BeeApp 开启起来,其实就是内部监听了 8080 端口:Go 默认情况会监听你本机所有的 IP 上面的 8080 端口。
停止服务的话,请按 Ctrl+c。
下面为 windows 下的快捷操作批处理文件:
在 %GOPATH%/src 目录下分别创建文件 step1.install-bee.bat 和 step2.new-beego-app.bat。
step1.install-bee.bat 文件内容:
set GOPATH=%~dp0..
go build github.com\beego\bee
copy bee.exe %GOPATH%\bin\bee.exe
del bee.exe
pause
step2.new-beego-app.bat 文件内容:
@echo 设置 App 的值为您的应用文件夹名称
set APP=coscms.com
set GOPATH=%~dp0..
set BEE=%GOPATH%\bin\bee
%BEE% new %APP%
cd %APP%
echo %BEE% run %APP%.exe > run.bat
echo pause >> run.bat
start run.bat
pause
start http://127.0.0.1:8080
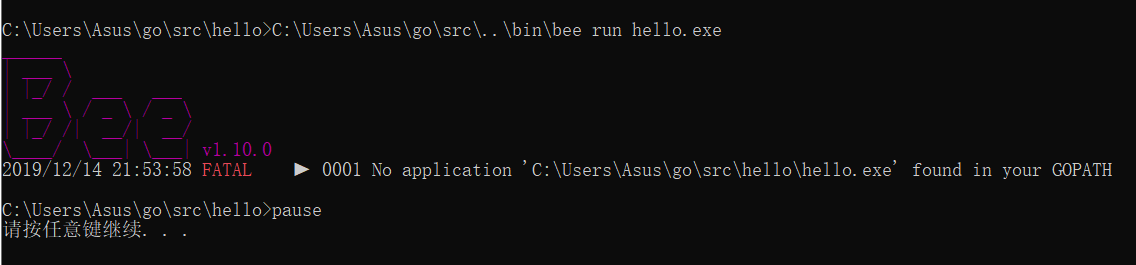
依次点击上面创建的两个文件即可快速开启 beego 之旅。 以后只需要到您的应用目录下点击 run.bat 即可。

创建好配置文件之后,点击在应用中会自动生成run.bat文件,点击即可运行.go文件。

运行后的效果:
gin web框架
本文来自博客园,作者:游走De提莫,转载请注明原文链接:https://www.cnblogs.com/Gaimo/p/12037018.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号