爬虫-中
requests模块其他用法
响应Response
1、response属性
import requests respone=requests.get('http://www.jianshu.com') # respone属性 print(respone.text) # 获取响应的数据的文本 print(respone.content) # 二进制数据 print(respone.status_code) # 获取响应状态你码 print(respone.headers) print(respone.cookies) print(respone.cookies.get_dict()) #cookies的value以字典形式获取 print(respone.cookies.items()) print(respone.url) print(respone.history) print(respone.encoding) #关闭:response.close() from contextlib import closing
with closing(requests.get('xxx',stream=True)) as response: for line in response.iter_content(): pass
2、编码问题
#编码问题 import requests response=requests.get('http://www.autohome.com/news') # response.encoding='gbk' #汽车之家网站返回的页面内容为gb2312编码的,而requests的默认编码为ISO-8859-1,如果不设置成gbk则中文乱码 print(response.text)
3、获取二进制数
#stream参数:一点一点的取,比如下载视频时,如果视频100G,用response.content然后一下子写到文件中是不合理的 import requests response=requests.get('https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo
-transcode/1767502_56ec685f9c7ec542eeaf6eac93a65dc7_6fe25cd1347c_3.mp4', stream=True) with open('b.mp4','wb') as f: for line in response.iter_content(): f.write(line)
4、解析json
两种写法,用json序列化,或直接.json().
#解析json import requests response=requests.get('http://httpbin.org/get') import json res1=json.loads(response.text) #太麻烦 res2=response.json() #直接获取json数据 print(res1 == res2) #True
高级用法
1、SSL Cert Verificationg
即现在的http协议加上证书认证变成https协议,访问请求资源时需要携带证书认证才能通过。
# 参数:verify=False,即不带证书认证。
介绍
#证书验证(大部分网站都是https) import requests respone=requests.get('https://www.12306.cn') #如果是ssl请求,首先检查证书是否合法,不合法则报错,程序终端 #改进1:去掉报错,但是会报警告 import requests respone=requests.get('https://www.12306.cn',verify=False) #不验证证书,报警告,返回200 print(respone.status_code) #改进2:去掉报错,并且去掉警报信息 import requests from requests.packages import urllib3 urllib3.disable_warnings() #关闭警告 respone=requests.get('https://www.12306.cn',verify=False) print(respone.status_code) #打印状态码 #改进3:加上证书
#很多网站都是https,但是不用证书也可以访问,大多数情况都是可以携带也可以不携带证书 #知乎\百度等都是可带可不带 #有硬性要求的,则必须带,比如对于定向的用户,拿到证书后才有权限访问某个特定网站 import requests respone=requests.get('https://www.12306.cn', cert=('/path/server.crt', '/path/key')) print(respone.status_code)

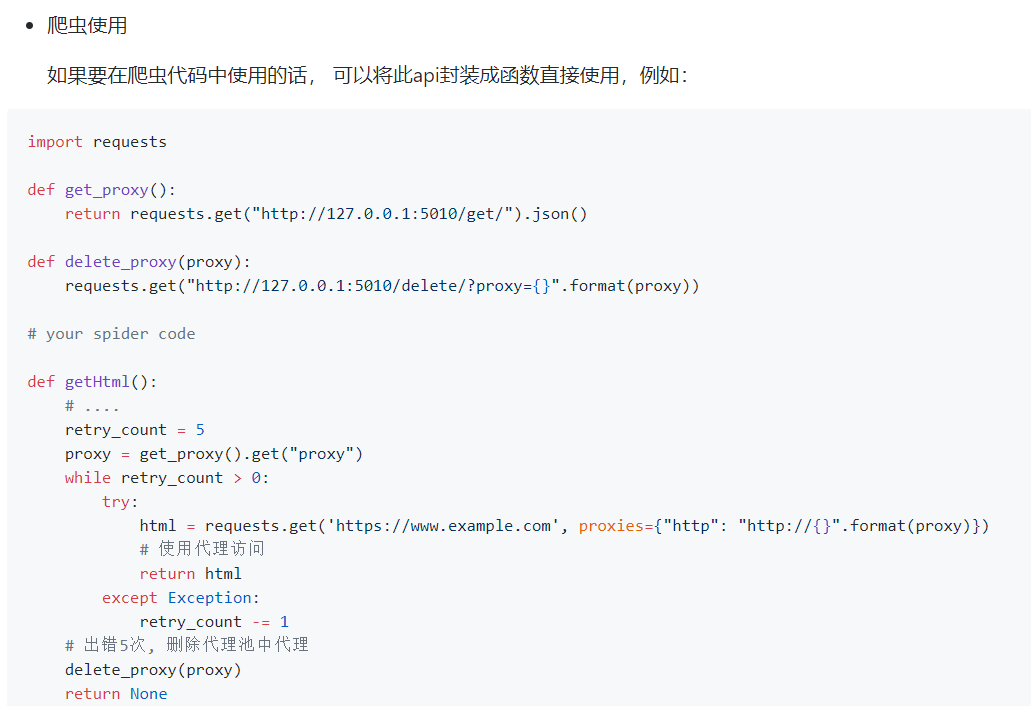
2、使用代理
目的是为了防反爬,把ip给禁掉不能发起请求。
#官网链接: http://docs.python-requests.org/en/master/user/advanced/#proxies #代理设置:先发送请求给代理,然后由代理帮忙发送(封ip是常见的事情) import requests proxies={ 'http':'http://egon:123@localhost:9743',#带用户名密码的代理,@符号前是用户名与密码 'http':'http://localhost:9743', 'https':'https://localhost:9743', } respone=requests.get('https://www.12306.cn', proxies=proxies) #在这填写代理的地址即可 print(respone.status_code) #支持socks代理,安装:pip install requests[socks] import requests proxies = { 'http': 'socks5://user:pass@host:port', 'https': 'socks5://user:pass@host:port' } respone=requests.get('https://www.12306.cn', proxies=proxies) print(respone.status_code)
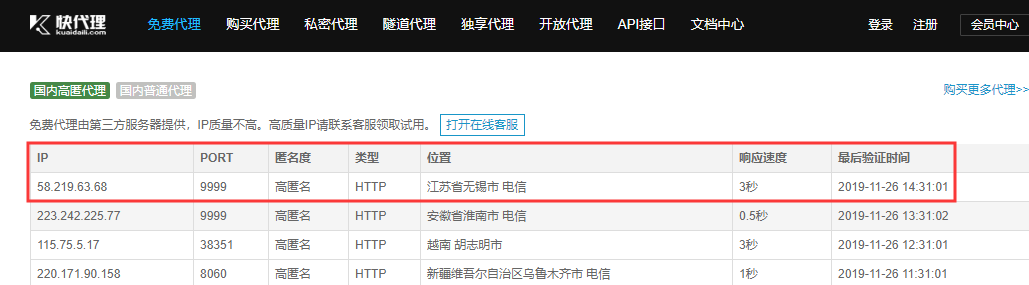
爬虫代理池,GitHub开源项目,是作者爬取其他免费代理的网站来做收费提供使用
3、超时设置
#超时设置 #两种超时:float or tuple #timeout=0.1 #代表接收数据的超时时间 #timeout=(0.1,0.2)#0.1代表链接超时 0.2代表接收数据的超时时间 import requests respone=requests.get('https://www.baidu.com', timeout=0.0001)
4、认证设置
#官网链接:http://docs.python-requests.org/en/master/user/authentication/ #认证设置:登陆网站是,弹出一个框,要求你输入用户名密码(与alter很类似),此时是无法获取html的 # 但本质原理是拼接成请求头发送 # r.headers['Authorization'] = _basic_auth_str(self.username, self.password) # 一般的网站都不用默认的加密方式,都是自己写 # 那么我们就需要按照网站的加密方式,自己写一个类似于_basic_auth_str的方法 # 得到加密字符串后添加到请求头 # r.headers['Authorization'] =func('.....') #看一看默认的加密方式吧,通常网站都不会用默认的加密设置 import requests from requests.auth import HTTPBasicAuth r=requests.get('xxx',auth=HTTPBasicAuth('user','password')) print(r.status_code) #HTTPBasicAuth可以简写为如下格式 import requests r=requests.get('xxx',auth=('user','password')) print(r.status_code)
5、异常处理
#异常处理 import requests from requests.exceptions import * #可以查看requests.exceptions获取异常类型 try: r=requests.get('http://www.baidu.com',timeout=0.00001) except ReadTimeout: print('===:') # except ConnectionError: #网络不通 # print('-----') # except Timeout: # print('aaaaa') except RequestException: print('Error')
接口的压力测试工具
# jmter 压力测试工具
6、上传文件
import requests files={'file':open('a.jpg','rb')} respone=requests.post('http://httpbin.org/post',files=files) print(respone.status_code)
beautisoup 4简单使用
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.
简介:简单的理解就是专门解析文档的模块
使用:
#安装 Beautiful Soup pip install beautifulsoup4
#安装解析器 Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml .根据操作系统不同,可以选择下列方法来安装lxml: $ apt-get install Python-lxml $ easy_install lxml $ pip install lxml
下表列出了主要的解析器,以及它们的优缺点,官网推荐使用lxml作为解析器,因为效率更高.
在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib,
因为那些Python版本的标准库中内置的HTML解析方法不够稳定.
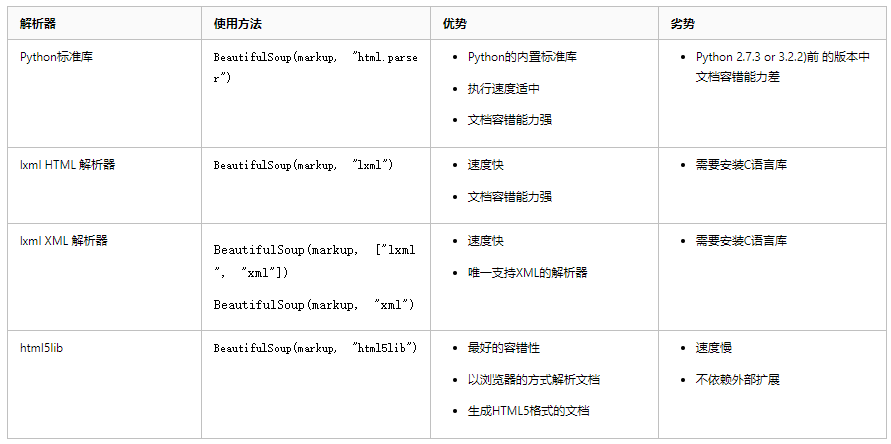
常用的解析格式:
BeautifulSoup(markup, "lxml")
举例子简单的使用
# soup=BeautifulSoup(res.text,'lxml') # find # find_all
爬取汽车之家的新闻专栏
#爬取的地址 #https://www.autohome.com.cn/news/1/#liststart import requests from bs4 import BeautifulSoup url='https://www.autohome.com.cn/news/1/#liststart' res=requests.get(url) # print(res.text) #生成一个bs4对象 soup=BeautifulSoup(res.text,'lxml') div=soup.find(id='auto-channel-lazyload-article') #div 是个对象 # print(type(div)) ul=div.find(name='ul') #只找第一个ul标签 # ul_list=div.find_all(class_="article") #找出下面所有类名为article的标签 # print(len(ul_list)) li_list=ul.find_all(name='li') # print(len(li_list)) for li in li_list: h3=li.find(name='h3') if h3: title=h3.text #把h3标签的text取出来 print(title) a=li.find(name='a') if a: article_url=a.get('href') #取出a标签的href属性 print(article_url) img=li.find(name='img') if img: img_url=img.get('src') print(img_url) p=li.find(name='p') if p: content=p.text print(content) # def test(a:str): # print(a)
''' find: -name="标签名" 标签 -id,class_,="" 把这个标签拿出来 -标签.text 取标签的内容 -标签.get(属性名) 取标签属性的内容 find_all '''
分析网站,得出结论,获取重要参数


beautisoup 4其他详细使用
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ #基本使用:容错处理,文档的容错能力指的是在html代码不完整的情况下,使用该模块可以识别该错误。使用BeautifulSoup解析上述代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出 from bs4 import BeautifulSoup soup=BeautifulSoup(html_doc,'lxml') #具有容错功能 res=soup.prettify() #处理好缩进,结构化显示 print(res)
遍历文档树
#遍历文档树:即直接通过标签名字选择,特点是选择速度快,但如果存在多个相同的标签则只返回第一个 #1、用法 #2、获取标签的名称 #3、获取标签的属性 #4、获取标签的内容 #5、嵌套选择 #6、子节点、子孙节点 #7、父节点、祖先节点 #8、兄弟节点
举例
#1、用法 from bs4 import BeautifulSoup soup=BeautifulSoup(html_doc,'lxml')
# ress=soup.prettify() #美化一下 # soup=BeautifulSoup(open('a.html'),'lxml') print(soup.p) #存在多个相同的标签则只返回第一个 获取标签 print(soup.a) #存在多个相同的标签则只返回第一个 #2、获取标签的名称 print(soup.p.name) #3、获取标签的属性 print(soup.p.attrs) #4、获取标签的内容 print(soup.p.string) # p下的文本只有一个时,取到,否则为None print(soup.p.strings) #拿到一个生成器对象, 取到p下所有的文本内容 print(soup.p.text) #取到p下所有的文本内容 for line in soup.stripped_strings: #去掉空白 print(line) #5、嵌套选择 print(soup.head.title.string) print(soup.body.a.string) #6、子节点、子孙节点 print(soup.p.contents) #p下所有子节点 print(soup.p.children) #得到一个迭代器,包含p下所有子节点 for i,child in enumerate(soup.p.children): print(i,child) print(soup.p.descendants) #获取子孙节点,p下所有的标签都会选择出来 for i,child in enumerate(soup.p.descendants): print(i,child) #7、父节点、祖先节点 print(soup.a.parent) #获取a标签的父节点 print(soup.a.parents) #找到a标签所有的祖先节点,父亲的父亲,父亲的父亲的父亲... #8、兄弟节点 print('=====>') print(soup.a.next_sibling) #下一个兄弟 print(soup.a.previous_sibling) #上一个兄弟 print(list(soup.a.next_siblings)) #下面的兄弟们=>生成器对象 print(soup.a.previous_siblings) #上面的兄弟们=>生成器对象
搜索文档树
1、五种过滤器
#1、五种过滤器: 字符串、正则表达式、列表、True、方法
#搜索文档树:BeautifulSoup定义了很多搜索方法,这里着重介绍2个: find() 和 find_all() .其它方法的参数和用法类似 html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p id="my p" class="title"><b id="bbb" class="boldest">The Dormouse's story</b> </p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup=BeautifulSoup(html_doc,'lxml') #1、五种过滤器: 字符串、正则表达式、列表、True、方法 #1.1、字符串:即标签名 print(soup.find_all('b')) #1.2、正则表达式 import re print(soup.find_all(re.compile('^b'))) #找出b开头的标签,结果有body和b标签 #1.3、列表:如果传入列表参数,Beautiful Soup会将与列表中任一元素匹配的内容返回.下面代码找到文档中所有<a>标签和<b>标签: print(soup.find_all(['a','b'])) #1.4、True:可以匹配任何值,下面代码查找到所有的tag,但是不会返回字符串节点 print(soup.find_all(True)) for tag in soup.find_all(True): print(tag.name) #1.5、方法:如果没有合适过滤器,那么还可以定义一个方法,方法只接受一个元素参数 ,如果这个方法返回 True 表示当前元素匹配并且被找到,如果不是则反回 False def has_class_but_no_id(tag): return tag.has_attr('class') and not tag.has_attr('id') print(soup.find_all(has_class_but_no_id))
2、find_all( name , attrs , recursive , text , **kwargs )


#2、find_all( name , attrs , recursive , text , **kwargs ) #2.1、name: 搜索name参数的值可以使任一类型的 过滤器 ,字符窜,正则表达式,列表,方法或是 True . print(soup.find_all(name=re.compile('^t'))) #2.2、keyword: key=value的形式,value可以是过滤器:字符串 , 正则表达式 , 列表, True . print(soup.find_all(id=re.compile('my'))) print(soup.find_all(href=re.compile('lacie'),id=re.compile('\d'))) #注意类要用class_ print(soup.find_all(id=True)) #查找有id属性的标签 # 有些tag属性在搜索不能使用,比如HTML5中的 data-* 属性: data_soup = BeautifulSoup('<div data-foo="value">foo!</div>','lxml') # data_soup.find_all(data-foo="value") #报错:SyntaxError: keyword can't be an expression # 但是可以通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的tag: print(data_soup.find_all(attrs={"data-foo": "value"})) # [<div data-foo="value">foo!</div>] #2.3、按照类名查找,注意关键字是class_,class_=value,value可以是五种选择器之一 print(soup.find_all('a',class_='sister')) #查找类为sister的a标签 print(soup.find_all('a',class_='sister ssss')) #查找类为sister和sss的a标签,顺序错误也匹配不成功 print(soup.find_all(class_=re.compile('^sis'))) #查找类为sister的所有标签 #2.4、attrs print(soup.find_all('p',attrs={'class':'story'})) #2.5、text: 值可以是:字符,列表,True,正则 print(soup.find_all(text='Elsie')) print(soup.find_all('a',text='Elsie')) #2.6、limit参数:如果文档树很大那么搜索会很慢.如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量.效果与SQL中的limit关键字类似,当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果 print(soup.find_all('a',limit=2)) #2.7、recursive:调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False . print(soup.html.find_all('a')) print(soup.html.find_all('a',recursive=False)) ''' 像调用 find_all() 一样调用tag find_all() 几乎是Beautiful Soup中最常用的搜索方法,所以我们定义了它的简写方法. BeautifulSoup 对象和 tag 对象可以被当作一个方法来使用,这个方法的执行结果与调用这个对象的 find_all() 方法相同,下面两行代码是等价的: soup.find_all("a") soup("a") 这两行代码也是等价的: soup.title.find_all(text=True) soup.title(text=True) ''' 复制代码 3、find( name , attrs , recursive , text , **kwargs ) 复制代码 #3、find( name , attrs , recursive , text , **kwargs ) find_all() 方法将返回文档中符合条件的所有tag,尽管有时候我们只想得到一个结果.比如文档中只有一个<body>标签,那么使用 find_all() 方法来查找<body>标签就不太合适, 使用 find_all 方法并设置 limit=1 参数不如直接使用 find() 方法.下面两行代码是等价的: soup.find_all('title', limit=1) # [<title>The Dormouse's story</title>] soup.find('title') # <title>The Dormouse's story</title> 唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果. find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None . print(soup.find("nosuchtag")) # None soup.head.title 是 tag的名字 方法的简写.这个简写的原理就是多次调用当前tag的 find() 方法: soup.head.title # <title>The Dormouse's story</title> soup.find("head").find("title") # <title>The Dormouse's story</title>
View Code
3、find( name , attrs , recursive , text , **kwargs )
#3、find( name , attrs , recursive , text , **kwargs ) find_all() 方法将返回文档中符合条件的所有tag,尽管有时候我们只想得到一个结果.比如文档中只有一个<body>标签,那么使用 find_all() 方法来查找<body>标签就不太合适, 使用 find_all 方法并设置 limit=1 参数不如直接使用 find() 方法.下面两行代码是等价的: soup.find_all('title', limit=1) # [<title>The Dormouse's story</title>] soup.find('title') # <title>The Dormouse's story</title> 唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果. find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None . print(soup.find("nosuchtag")) # None soup.head.title 是 tag的名字 方法的简写.这个简写的原理就是多次调用当前tag的 find() 方法: soup.head.title # <title>The Dormouse's story</title> soup.find("head").find("title") # <title>The Dormouse's story</title>
5、CSS选择器
#该模块提供了select方法来支持css,详见官
网:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id37
from bs4 import BeautifulSoup soup=BeautifulSoup(html_doc,'lxml') #1、CSS选择器 print(soup.p.select('.sister')) print(soup.select('.sister span')) print(soup.select('#link1')) print(soup.select('#link1 span')) print(soup.select('#list-2 .element.xxx')) print(soup.select('#list-2')[0].select('.element')) #可以一直select,但其实没必要,一条select就可以了 # 2、获取属性 print(soup.select('#list-2 h1')[0].attrs) # 3、获取内容 print(soup.select('#list-2 h1')[0].get_text())
修改文档树
# 官网 https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id40

总结
# 总结: #1、推荐使用lxml解析库 #2、讲了三种选择器:标签选择器,find与find_all,css选择器 1、标签选择器筛选功能弱,但是速度快 2、建议使用find,find_all查询匹配单个结果或者多个结果 3、如果对css选择器非常熟悉建议使用select
#3、记住常用的获取属性attrs和文本值get_text()的方法
爬虫请求库之selenium
简介:
# 官网:http://selenium-python.readthedocs.io
通过驱动浏览器,完成自动化操作。
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器 from selenium import webdriver
# 支持的浏览器 browser=webdriver.Chrome() # 谷歌 browser=webdriver.Firefox() browser=webdriver.PhantomJS() browser=webdriver.Safari() browser=webdriver.Edge()
安装
驱动器需要下载安装,并放入指定的文件目录下,放在项目的根目录下也可以。
1、有界面浏览器
#安装:selenium+chromedriver pip3 install selenium
下载chromdriver.exe放到python安装路径的scripts目录中即可,注意最新版本是2.38,并非2.9 国内镜像网站地址:http://npm.taobao.org/mirrors/chromedriver/2.38/ 最新的版本去官网找:https://sites.google.com/a/chromium.org/chromedriver/downloads #验证安装 C:\Users\Administrator>python3 Python 3.6.1 (v3.6.1:69c0db5, Mar 21 2017, 18:41:36) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> from selenium import webdriver >>> driver=webdriver.Chrome() #弹出浏览器 >>> driver.get('https://www.baidu.com') >>> driver.page_source #注意: selenium3默认支持的webdriver是Firfox,而Firefox需要安装geckodriver 下载链接:https://github.com/mozilla/geckodriver/releases
注意:需要指定浏览器的版本号和驱动的版本号对应关系

例子:实现自动在百度搜索框中输入信息,完成页面的跳转搜索。

from selenium import webdriver from selenium.webdriver.common.keys import Keys import time # bro=webdriver.Chrome(chrome_options=chrome_options) bro=webdriver.Chrome() bro.get('https://www.baidu.com') # print(bro.page_source) # time.sleep(3) time.sleep(1) #取到输入框 inp=bro.find_element_by_id('kw') #往框里写字 inp.send_keys("腾讯NBA") inp.send_keys(Keys.ENTER) #输入回车 #另一种方式,取出按钮,点击su time.sleep(6) bro.close()
谷歌浏览器:

2、无界面浏览器
比较流行的PhantomJS不再更新。
#安装:selenium+phantomjs pip3 install selenium 下载phantomjs,解压后把phantomjs.exe所在的bin目录放到环境变量 下载链接:http://phantomjs.org/download.html #验证安装 C:\Users\Administrator>phantomjs phantomjs> console.log('egon gaga') egon gaga undefined phantomjs> ^C C:\Users\Administrator>python3 Python 3.6.1 (v3.6.1:69c0db5, Mar 21 2017, 18:41:36) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> from selenium import webdriver >>> driver=webdriver.PhantomJS() #无界面浏览器 >>> driver.get('https://www.baidu.com') >>> driver.page_source
在 PhantomJS 年久失修, 后继无人的节骨眼 Chrome 出来救场, 再次成为了反爬虫 Team 的噩梦 自Google 发布 chrome 59 / 60 正式版 开始便支持Headless mode 这意味着在无 GUI 环境下, PhantomJS 不再是唯一选择
#selenium:3.12.0 #webdriver:2.38 #chrome.exe: 65.0.3325.181(正式版本) (32 位) from selenium import webdriver from selenium.webdriver.chrome.options import Options chrome_options = Options()
# 可以隐藏浏览器的参数 chrome_options.add_argument('window-size=1920x3000') #指定浏览器分辨率 chrome_options.add_argument('--disable-gpu') #谷歌文档提到需要加上这个属性来规避bug chrome_options.add_argument('--hide-scrollbars') #隐藏滚动条, 应对一些特殊页面 chrome_options.add_argument('blink-settings=imagesEnabled=false') #不加载图片, 提升速度 chrome_options.add_argument('--headless') #浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败 chrome_options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" #手动指定使用的浏览器位置 driver=webdriver.Chrome(chrome_options=chrome_options) driver.get('https://www.baidu.com') print('hao123' in driver.page_source) driver.close() #切记关闭浏览器,回收资源
3、基本使用
from selenium import webdriver from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR from selenium.webdriver.common.keys import Keys #键盘按键操作 from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 browser=webdriver.Chrome() try: browser.get('https://www.baidu.com') ``` input_tag=browser.find_element_by_id('kw') input_tag.send_keys('美女') #python2中输入中文错误,字符串前加个u input_tag.send_keys(Keys.ENTER) #输入回车 ``` wait=WebDriverWait(browser,10) wait.until(EC.presence_of_element_located((By.ID,'content_left'))) #等到id为content_left的元素加载完毕,最多等10秒 ``` print(browser.page_source) print(browser.current_url) print(browser.get_cookies()) ``` finally: browser.close()
本文来自博客园,作者:游走De提莫,转载请注明原文链接:https://www.cnblogs.com/Gaimo/p/11935909.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号