Django数据库查询优化-事务-图书管理系统的搭建
数据库查询优化
优化:虽然减轻了数据库的压力,但查询速度大大的减慢
ORM内所有的语句操作,默认都是惰性查询,只有你在真正的需要数据的时候才会走数据,
如果你只是写ORM语句时,是不会走数据库的,这样的原理设计,主要是在于减轻数据库的压力。
例如:

查询优化的关键字方法:select_related、only、prefentch_related、defer
Django数据库优化操作之only方法
加only参数是从查询结果中只取某个字段,封装做成对象的形式,不再频繁的走数据库,从而减轻数据库的压力

上述r.title在查询时,即使循环也只是走了一次数据库查询,而r.price,没有的字段时,会循环的频繁走数据库
Django数据库优化操作之defer方法
与only刚好相反,会将不是括号内的所有字段信息查询出来;如果点的是括号内的字段会频繁的走数据库查询;
如果不是字段内的反而点一次只查询一次,也是为了排除在外,然后起到优化的作用

Django数据库优化操作之select_related主动联表查询
例子如:
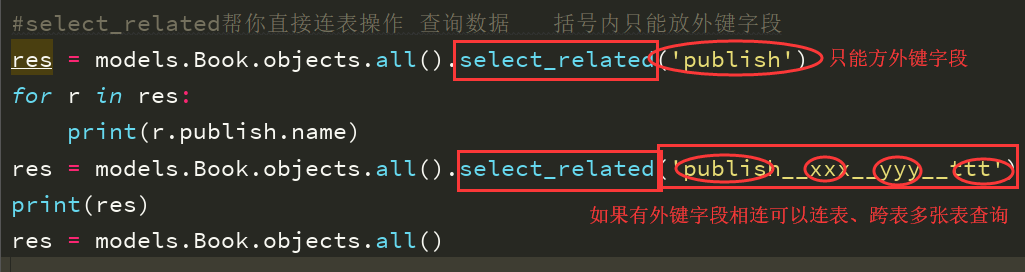
如果不用select_related时。查询all()执行的结果中显示多条MySQL语句,
而select_related会一致性的做连表操作,一句MySQL语句即可,大大的减轻数据库的压力
all()查询的结果显示:
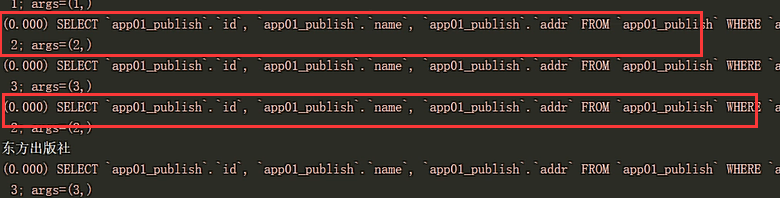
而select_relate的查询方法是一致性的连表操作

结论:
""" select_related:会将括号内外键字段所关联的那张表 直接全部拿过来(可以一次性拿多张表)跟当前表拼接操作 从而降低你跨表查询 数据库的压力 注意select_related括号只能放外键字段(一对一和一对多) res = models.Book.objects.all().select_related('外键字段1__外键字段2__外键字段3__外键字段4') """
Django数据库优化操作之perfetch_related非主动联表查询
不直接连表,但是会以第一次查询的结果之上再次查询了另一张表操作,看似查询两次
""" 不主动连表操作(但是内部给你的感觉像是连表操作了),而是将book表中的publish全部拿出来,在取publish表中将id对应的所有的数据取出 res = models.Book.objects.prefetch_related('publish') 括号内有几个外键字段 就会走几次数据库查询操作 """

Django orm中事务操作
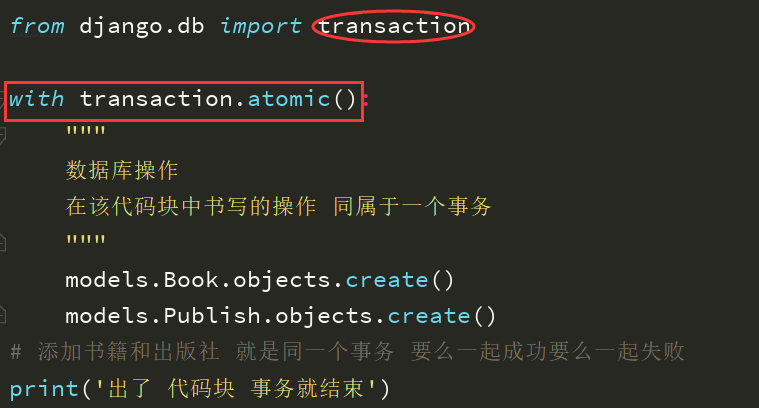
事务的定义:将多个sql语句操作变成原子性操作,要么同时成功,有一个失败则里面回滚到原来的状态;
保证数据的完整性和一致性(NoSQL数据库对于事务则是部分支持)
联想数据库MySQL中的事务有以下特点
事务的ACID特性:原子性、一致性、隔离性、持久性
直接导入模块使用事务:开启事务,事务回滚(自动)
图书管理系统的搭建
首先先建立号数据库,在进行逻辑操作:
1、修改Django指定的数据库配置步骤:用可视化工具Navicat手动新建数据库,库名:day56
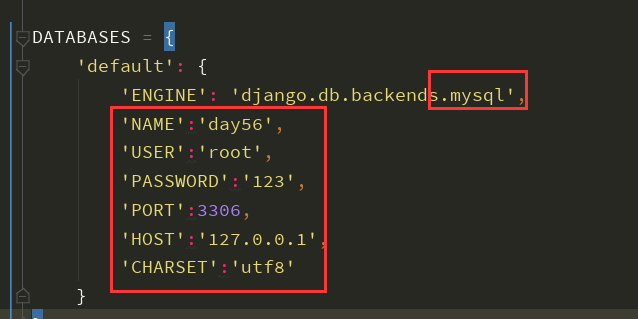
2、在Django的settings.py文件中修改环境配置
3、在app01__init__中指定修改默认的数据库,把Sqlite修改为常用的MySQL数据库
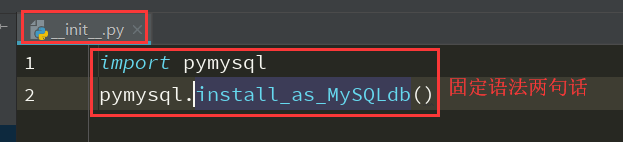
常用的数据库:
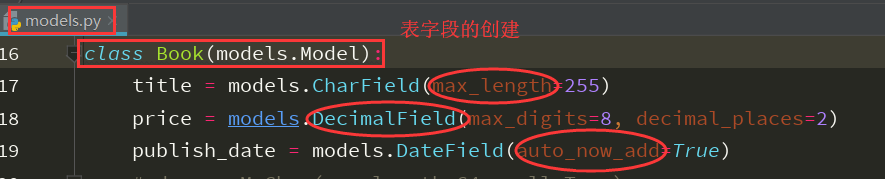
3、在modles.py中建立表模型,进行创建表的字段,属性,ID等操作
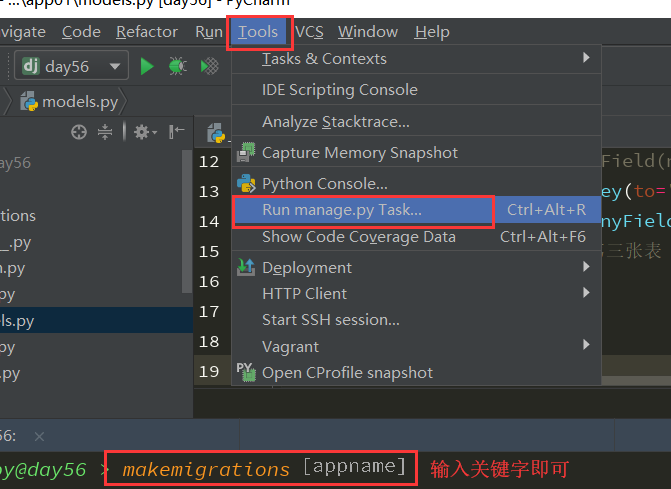
4、创建好表结构之后,必须执行数据库的迁移命令操作,把数据同步到库day56中,有两个命令
(1)、在小本本上(migrations文件夹)记录数据库的修改

(2)、执行所谓真正意义上的迁移数据操作

也可以快捷创建使用:
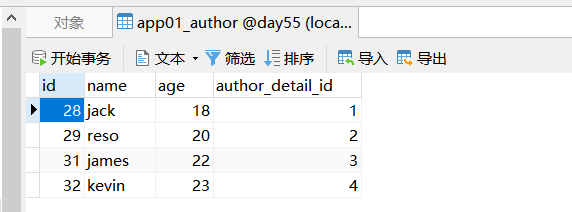
5、在数据库中手录入数据信息
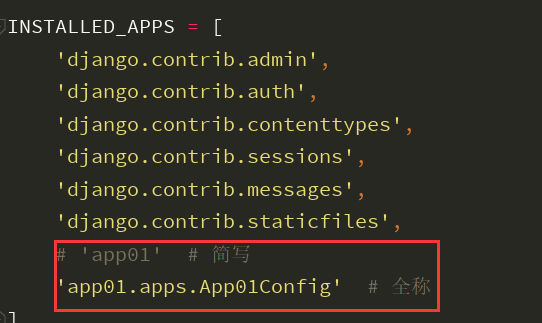
6、新创建的app一定要先去settings.py注册
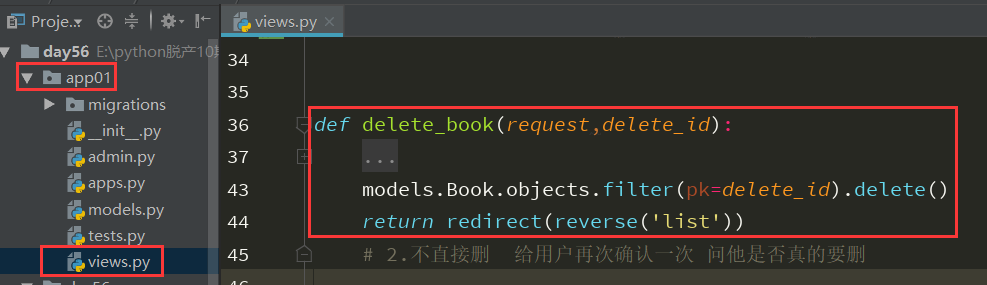
7、在app01的views.py中书写逻辑代码块
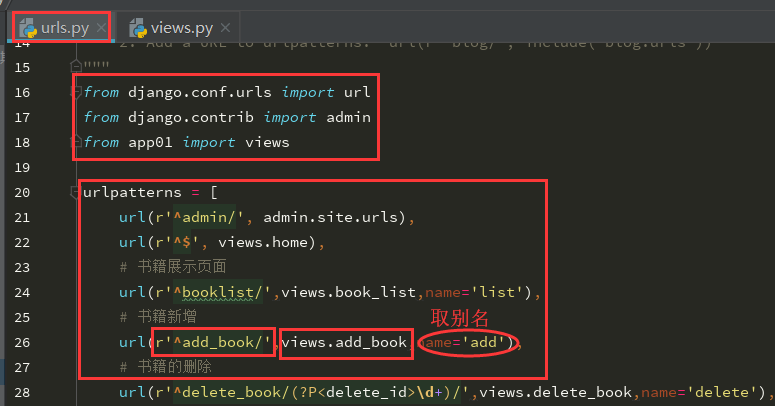
8、在项目文件下的url.py书写url匹配规则,相对应的方法
9、书写前端功能搭建的代码固定建立在templates文件夹下

前端内容的书写:
利用模板的继承,模板的导入,使用前端模板框架Bootstsrap复杂模板,修改搭建
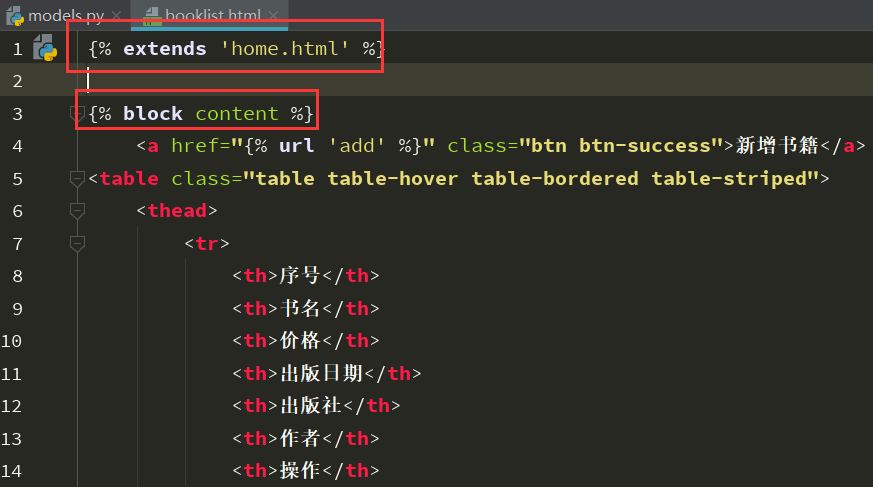
模板继承:
本文来自博客园,作者:游走De提莫,转载请注明原文链接:https://www.cnblogs.com/Gaimo/p/11563157.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号