线程池-进程池-协程-io模型
一、线程池与进程池
什么是池?简单的说就是一个容器,一个范围
在保证计算机硬件安全的情况下最大限度的充分利用计算机,
池其实是降低了程序的运行效率,但是保证了计算机硬件的安全,也是实现了一个并发的效果,现如今硬件的发展跟不上软件的更新速度
进程池与线程池
开进程开线程都需要消耗资源,只不过两者比较的情况线程消耗的资源比较少
创建进程池:multiprocess.Pool模块
导入的写法:from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
Pool([numprocess [,initializer [, initargs]]]):创建进程池
1 numprocess:要创建的进程数,如果省略,将默认使用cpu_count()的值
2 initializer:是每个工作进程启动时要执行的可调用对象,默认为None
3 initargs:是要传给initializer的参数组
方法有:p.apply() p.apply_async() p.colse() p.join()
内置函数 pool =ProcessPoolExecutor() # 创建进程池,不写默认为当前计算机cpu的个数
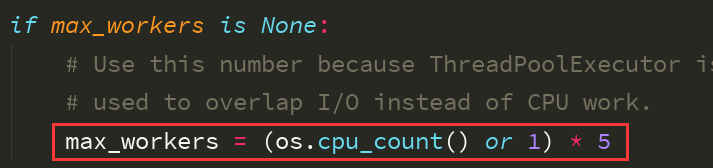
1、进程池的用法:
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import time import os """ 池子中创建的进程/线程创建一次就不会再创建了 开始到结尾都是那么几个,最初定义的 这样的话节省了反复开辟进程/线程的资源 """ #进程池的用法: pool =ProcessPoolExecutor() # 创建进程池,不写默认为当前计算机cpu的个数 def task(n): print(n,os.getpid()) # 查看当前的进程号 time.sleep(2) return n**2 def call_back(n): print("异步提交任务的返回结果:",n.result()) "异步回调机制:当异步提交的任务有返回结果之后,会自动触发回调函数的执行" if __name__ == '__main__': l_list = [] for i in range(20): res = pool.submit(task,i).add_done_callback(call_back) # 异步回调 "提交任务的时候 绑定一个回调函数 一旦该任务有结果 立刻执行对于的回调函数" l_list.append(res)
>>>>
0 16128
1 41700
2 24856
3 9876
4 41128
5 40068
6 19288
7 40080
8 16128
异步提交任务的返回结果: 0
9 41700
异步提交任务的返回结果: 1
10 24856
异步提交任务的返回结果: 4
11 9876

进程池的回调机制
2、创建线程池:
线程池的用法 from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import time import os pool =ThreadPoolExecutor(5) # 括号内可以传参数指定线程池内的线程个数 # 也可以不传,不传就默认为当前所在技算机的cpu个数乘以5 def task(n): print(n,os.getpid()) time.sleep(2) return n **2 t_list=[] for i in range(20): res=pool.submit(task,i) # 往线程池中提交任务 异步提交 # print(res.result()) # 原地等待任务的返回结果 异步 t_list.append(res) pool.shutdown() # 关闭池子 等待池子中所有的任务执行完毕之后 才会往下运行代码 for p in t_list: print(">>>>:",p.result())
>>>:
18 32864
19 32864
>>>>: 0
>>>>: 1
>>>>: 4
>>>>: 9
>>>>: 16
>>>>: 25
>>>>: 36
二、协程
(是程序员想象出来的,就是单线程实现并发的情况下可以称为协程)
1、单线程实现并发 在应用程序里控制多个任务的 切换+保存 的状态
优点:应用程序级别速度要远远高于操作系统的切换
缺点:多任务一旦有一个阻塞没有切,整个线程都阻塞在原地,该线程内的其他任务都不能执行了
进程:资源单位
线程:执行单位
协程:单线程下实现并发
并发的条件:多道技术:空间上的应用,时间上的复用 (切换+保存)
2、协程序的目的:
想要在单线程下实现并发
并发指的是多个任务看起来是同时运行的
并发=切换+保存状态
#串行执行 import time def func1(): for i in range(10000000): i+1 def func2(): for i in range(10000000): i+1 start = time.time() func1() func2() stop = time.time() #1.094691514968872 print(stop - start) #基于yield并发执行 有yield在函数内,加括号调用时变成生成器 import time def func1(): while True: yield def func2(): g=func1() for i in range(10000000):
i+1 next(g) start=time.time() func2() stop=time.time() # 1.3715009689331055 print(stop-start)
:第一种情况的切换。在任务一遇到io情况下,切到任务二去执行,这样就可以利用任务一阻塞的时间完成任务二的计算,
(在运行和就绪态来回切换,等待阻塞的事件很短)效率的提升就在于此。
一旦遇到IO自己通过代码切换
给操作系统的感觉是你这个线程没有任何的IO
ps:欺骗操作系统 让它误认为你这个程序一直没有IO
从而保证程序在运行态和就绪态来回切换
提升代码的运行效率
3、实现了切换+保存的状态就一定能够提升效率吗?
执行效率最好,更节省资源的应该是:多进程下开多线程,多线程下再开协程
4、用yeild 只能够保持切换的状态(yield 保存上一次的结果),需要找到一个能识别io的工具 从而引入了 gevent 模块
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。
swpn( ) 用于监测I/O 操作 实现切换+保存的状态 在单线程下实现并发的效果
swpn() 内置封装 自带return 有返回值
from gevent import monkey;monkey.patch_all() # 由于该模快经常被使用,建议这么写 from gevent import spawn import time #注意gevent模块没办法自动识别time.sleep等io情况 # 需要你手动再配置一个参数 def heng(): print("天时地利") time.sleep(2) print("只前东风") def hei(): print("登高望楼") time.sleep(2) print("独坐西楼") def haha(): print('who are you ') time.sleep(2) print('why') start = time.time() g1= spawn(heng) # spawn会检测所有的任务 g2 = spawn(hei) g3 = spawn(haha) g1.join() g2.join() g3.join() print(time.time()-start)
用spawn 检测掠过io 快速的切换+保存的状态 让系统误认为没有一个io的操作,提升执行的效率
5、利用单线程形式实现ftp的并发效果
利用genvent模块下的spawn() 自动检测io操作的功能实现
FTP客户端:
import socket from threading import Thread,current_thread def client(): # 写成函数版 client = socket.socket() client.connect(('127.0.0.1',8080)) n = 0 while True: data = '%s %s'%(current_thread().name,n) client.send(data.encode('utf-8')) res = client.recv(1024) print(res.decode('utf-8')) n += 1 for i in range(400): t = Thread(target=client) t.start()
FTP服务端:
from gevent import monkey;monkey.patch_all() import socket from gevent import spawn server = socket.socket() server.bind(('127.0.0.1',8080)) server.listen(5) def talk(conn): while True: try: data = conn.recv(1024) if len(data) == 0:break print(data.decode('utf-8')) conn.send(data.upper()) except ConnectionResetError as e: print(e) break conn.close() def server1(): while True: conn, addr = server.accept() spawn(talk,conn) # 自定检测io操作,在通讯和接受之间,快速实现切换+保存的状态,时间间隔很短,看起来就像是在并发 if __name__ == '__main__': g1 = spawn(server1) g1.join()
三、IO模型
为了更好地了解IO模型,我们需要事先回顾下:同步、异步、阻塞、非阻塞
Stevens在文章中一共比较了五种IO Model:
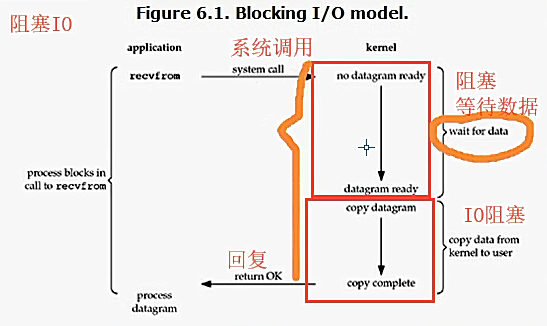
* blocking IO 阻塞IO
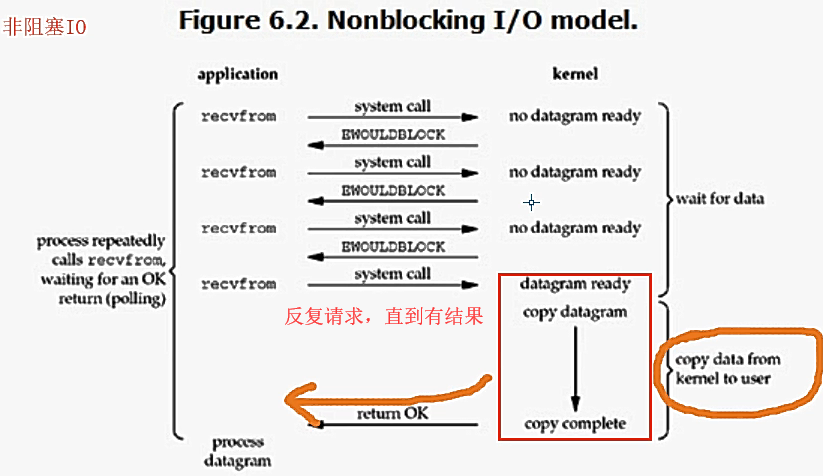
* nonblocking IO 非阻塞IO
* IO multiplexing IO多路复用
* signal driven IO 信号驱动IO
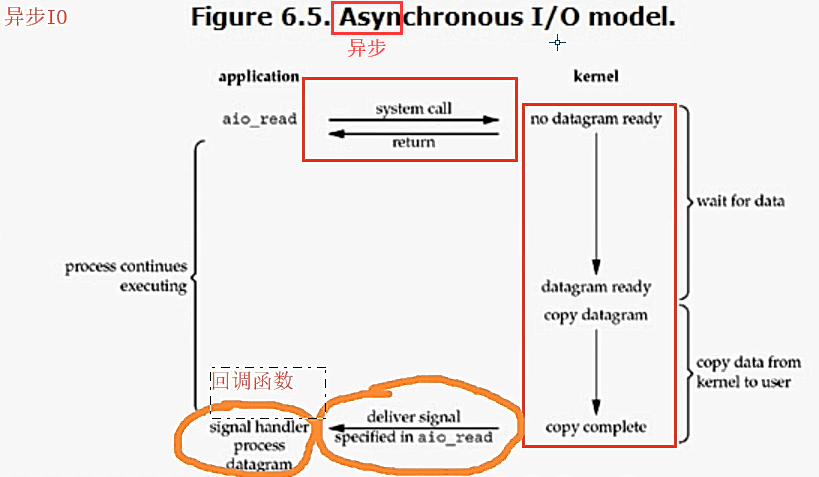
* asynchronous IO 异步IO
同步异步:指的是运行的任务的提交方式:
同步:提交的任务之后原地等待任务的返回结果,期间不做任何事
异步:提交任务后立刻执行下一行代码,不等待任务的返回结果,采用异步回调机制
阻塞与非阻塞:指的是程序的运行状态
阻塞:阻塞等待的状态
非阻塞:就绪态或者运行态

本文来自博客园,作者:游走De提莫,转载请注明原文链接:https://www.cnblogs.com/Gaimo/p/11359121.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号