线程
一、进程间的通信
队列:先进先出,堆栈:先进后出
Queue([maxsize]):创建共享的进程队列,参数maxsizez是队列中允许的最大项数,如果省略此参数,则无大小限制
方法:
q.get 获取对列中的数
q.get_nowait():同q.get(False)方法 取值,没有值时直接报错,不等待
q.put():往队列里放数
print(q.empty()) # 判断队列中的数据是否取完
q.qsize():返回队列中目前的正确数量
q.full(): 判断队列是否满了,如果q已满,返回为True
q.close()关闭对列,防止对列中加入更多的数据
1:进程间的通信
from multiprocessing import Queue q = Queue(5) # 括号内可以传参数 表示的是这个队列的最大存储数 # 往队列中添加数据 q.put(1) q.put(2) # print(q.full()) # 判断队列是否满了 q.put(3) q.put(4) q.put(5) # print(q.full()) # q.put(6) # 当队列满了之后 再放入数据 不会报错 会原地等待 直到队列中有数据被取走(阻塞态) print(q.get()) print(q.get()) print(q.get()) print(q.empty()) # 判断队列中的数据是否取完 print(q.get()) print(q.get()) print(q.empty()) # print(q.get_nowait()) # 取值 没有值不等待直接报错

""" full get_nowait empty 都不适用于多进程的情况,因为多队列情况下,当你取完队列中的值时,另一个正好在往队列里放入值,不好判断 ,得出的结果是不可靠的 """
2:进程间通信的IPC机制
from multiprocessing import Process,Queue import time def prdoucer(q): q.put('往队列中放数') def consumer(q): print(q.get()) # 获取数据 if __name__ == '__main__': q = Queue() # 创建对列 p = Process(target=prdoucer,args=(q,)) # 创建进程 c = Process(target=consumer,args=(q,)) p.start() c.start() """ 子进程放数据,主进程获取数据 两个子进程相互放取数据 """ >> 往队列中放数
3:生产者与消费者模型
在并发编程中使用生产者和消费者模式能够解决大多数并发问题,该模式通过平衡生产线与消费线程的工作能力来提高程序的整体处理数据的速度
生产者消费者模式是通过一个容器(队列)来解决生产者和消费者的强耦合问题,生产者消费者之间不能直接通信,而是通过阻塞队列来进行通讯的
# from multiprocessing import process,Queue,JoinableQueue 关键字"JoinableQueue"
方法:
q=JoinableQueue(): 实例化一个进程队列
q.task_done(): 表示告诉队列已经从中获取了一个数据,而且已经处理完了
q.join(): 等到队列中数据全部取出
生产者:生产/制造数据的
消费者:消费/处理数据的
例子:做包子(生产者)和买包子(消费者)
1:做包子远比买包子的多 2:做包子的远比买包子的少 出现 供不应求,供大于求等供需不平衡的问题


from multiprocessing import Process,Queue,JoinableQueue import time import random def producer(name,food,q): for i in range(10): data = '%s生产了%s%s'%(name,food,i) time.sleep(random.random()) q.put(data) # 往队列中添加数 print(data) def consumer(name,q): while True: data = q.get() # 获取队列中的数 if data == None:break print('%s吃了%s'%(name,data)) time.sleep(random.random()) q.task_done() # 告诉对列已经从中取出了一个数,并且已经处理完了 if __name__ == '__main__': q=JoinableQueue() p = Process(target=producer,args=('大厨师Jack','黄焖鸡',q) ) p1= Process(target=producer,args=('小老弟Mo','鸡腿',q)) c = Process(target=consumer,args=('rose',q)) c1 = Process(target=consumer,args=('出货kevin',q)) p.start() # 告诉子进程创建 p1.start() c.daemon = True # 将c c1 设置为守护进程 c1.daemon = True c.start() c1.start() p.join() p1.join() # c.start() # c1.start() q.join() # 等待队列中数据全部取出 q.put(None) # 加两个None 后让队列取值后直接结束退出,不需要在原地等待 q.put(None)

二、线程:
什么是线程?
进程线程其实都是虚拟单位,都是用来帮助我们形象的描述某种事物
进程:资源单位
线程:执行单位
将内存比例成工厂,那么进程就相当于是工厂里面的车间,而线程就相当于是车间里面的流水线
PS: 每一个进程都自带一个线程,线程才是真正的执行单位,进程只是在线程运行过程中提供代码运行所需要的资源
为什么要用线程?有什么优缺点?
进程和线程的关系:每创建一个进程将开辟一块新的内存空间,浪费资源,为了高效的利用资源可以用线程,因为一个进程里可以包含多个线程,并且线程与线程之间数据是共共享的
PS:就占系统资源的角度来讲,开启线程的开销要远远小于开启进程的开销
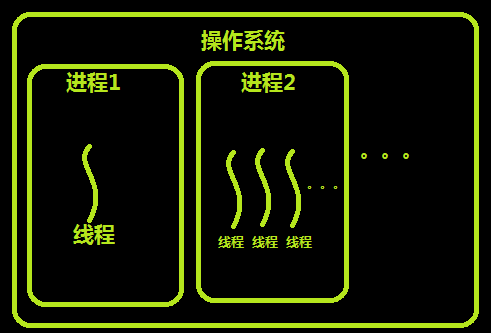
在线程中可以说没有主线程与子线程之分,因为他们处于同一个进程中
2:创建线程的两种方式:
和创建进程的方式类似
模块:Threading.Thread
(1):直接创建.调用模块.实例化
from threading import Thread import time def task(name): print('%s in running ' %name) time.sleep(2) print("%s in over "%name) t = Thread(target=task,args=('james',)) t.start() print("主线程")
>>:james in running
主线程
james in over # 小的代码执行完,线程就已经开启了,速度比较快
小区别:可以不创建在 if __name__ == '__main__': 下面, 但习惯性还是要写
(2):继承类,内置方法调用
from threading import Thread import time class MyThread(Thread): # 继承类 创建线程 def __init__(self,name): super().__init__() self.name = name def run (self): print("%s is running "%self.name) time.sleep(3) print('%s is over' %self.name) t=MyThread("GAI") t.start() print("主线程") >> GAI is running 主线程 GAI is over
三、线程及其他方法:与进程的其他方法有同样的一些方法
Thread实例化对象的方法
isAlive(): 判断线程是否活动的
getName():返回线程名
setName():设置线程名
threading.currentTheread(): 返回当前的线程变量
threading.enumerate(): 返回一个包含正在运行的线程list
threading.activeCount(): 返回正在运行的线程数量
from threading import Thread,current_thread,active_count import time import os def task(name,i): print("%s is running "%name) time.sleep(i) print("%s is over"%name ) t = Thread(target=task,args=('get.mo',1)) t1 = Thread(target=task,args=('kill',2)) t.start() t1.start() t1.join() print('当前正在活跃的线程数,',active_count()) print("主线程") print("主current_Thread",current_thread().name) print("主",os.getpid()) t.isAlive() t.isDaemon() t.getName() t.join() t.is_alive() # t.setDaemon() >>: get.mo is running kill is running get.mo is over kill is over 当前正在活跃的线程数, 1 主线程 主current_Thread MainThread 主 33668
四、守护进程
无论是进程还是线程,都遵循:守护XX会等待主XX运行完毕后被销毁,需要注意的是:运行完毕并非终止运行
1:对主进程来说,运行完毕指的主进程代码运行完毕
2:对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕
from threading import Thread,current_thread import time def task(i): print(current_thread().name) time.sleep(i) print('GG') # for i in range(3): # t = Thread(target=task,args=(i,)) # t.start() t = Thread(target=task,args=(1,)) t.daemon = True t.start() print('主') # 主线程运行结束之后需要等待子线程结束才能结束呢? """ 主线程的结束也就意味着进程的结束 主线程必须等待其他非守护线程的结束才能结束 (意味子线程在运行的时候需要使用进程中的资源,而主线程一旦结束了资源也就销毁了) """
五、线程之间的数据是共享的
from threading import Thread money =1000 def task(): global money money =66666 t = Thread(target=task) t.start() t.join() print(money) >> 66666
六、互斥锁
当多个线程或进程操作同一份数据时数据混乱这时必须考虑到加锁(LOCK)
from threading import Thread,Lock import time n = 100 def task(mutex): global n mutex.acquire() # 抢锁 只要有人抢到了锁其他人必须等待该人释放锁 tmp = n time.sleep(0.1) n = tmp-1 mutex.release() # 释放锁 t_list = [] mutex = Lock() for i in range(100): t = Thread(target=task,args=(mutex,)) t.start() t_list.append(t) for t in t_list: t.join() print(n) >> 0
七、迷惑人的守护线程的小例子
from threading import Thread from multiprocessing import Process import time def foo(): print(123) time.sleep(1) print("end123") def run(): print(456) time.sleep(3) print("end456") if __name__ == '__main__': t= Thread(target=foo) t2=Thread(target=run) t.daemon=True t.start() t2.start() print("主线程") >> 123 456 main------- end123 end456
守护进程是指等待子进程完全结束程序才会完全结束,上述第2个time.sleep(3)等待3秒时,第一个1秒早就完全可以运行完了
本文来自博客园,作者:游走De提莫,转载请注明原文链接:https://www.cnblogs.com/Gaimo/p/11342263.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号