递归-匿名函数-常用的内置方法
一、递归定义
如果函数中包含了对其自身的调用,该函数就是递归的;
递归(Recursion),在数学与计算机科学中,是指在函数的定义中使用函数自身的方法;
# 非递归实现阶乘 def factorial(n): res = 1 for i in range(2, n+1): res *= i return res print(factorial(5)) # 24 # 递归实现阶乘 def factorial(n): if n == 0 or n == 1: return 1 else: return (n * factorial(n - 1)) print(factorial(5)) # 120 """ factorial(5) # 第 1 次调用使用 5 5 * factorial(4) # 第 2 次调用使用 4 5 * (4 * factorial(3)) # 第 3 次调用使用 3 5 * (4 * (3 * factorial(2))) # 第 4 次调用使用 2 5 * (4 * (3 * (2 * factorial(1)))) # 第 5 次调用使用 1 5 * (4 * (3 * (2 * 1))) # 从第 5 次调用返回 5 * (4 * (3 * 2)) # 从第 4 次调用返回 5 * (4 * 6) # 从第 3次调用返回 5 * 24 # 从第 2 次调用返回 120 """
一、递归函数的定义: 在函数体内再调用函数本身(简单的说就是多次甚至无限的循环)
# 简单的递归 def func(index) print('form index') return login() def func(login) print(''form login') return index() login() ##嵌套调用,进入多次循环,直到递归深度上限
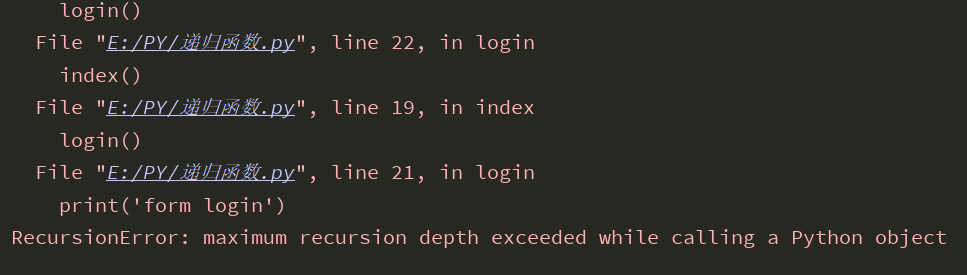
>>>:提示超过了内置的递归深度
1:递归的最大深度——997
如果在函数体内使用递归函数那么程序就不停的运行着,这会导致数据的存储量过大,内存会溢出,Python为了杜绝这类现象的发生,定义了一个强制的将递归层数控制在了997。
查看函数最大递归深度:
import sys print(sys.getrecursionlimit()) # 查看最大的递归深度范围 print(sys.setrecursionlimit(2000)) # 修改递归深度的范围值
2:递归函数的实现过程:
1:回溯:就是一次次重复的过程,重复的过程必须在逐渐的降低问题的复查程度,直到找到一个最终的结束条件
2:递归:就是拿到条件后 ,一次次往回推导的过程
def age(n): if n==1: # 第一个开始回溯的人 return 18 # 结束的条件 else: return age(n-1)+2 #递推的规律 res=age(10) print(res)
二、算法之二分法:所谓的算法就是提高效率的方法, 二分法:就是容器内必须有一定的大小顺序,以中间数为基准寻找规律,分段比较左右对比
l=[1,4,8,9,14,25,48,58,124,236,485,489,520,1234,4526,7852] def func(l,aim): mid=(len(1)-1)//2 # 先取列表的中间值 if l: if aim>l[mid]: func(1[mid+1:],aim) # 按索引的方式取值 elif aim<l[mid]: func(1[:mid],aim) elif aim==l[mid]: print('bingo',mid) else: print('找不到') func(1,124) # 124是要找的数 func(1,8) # 8是分段寻找 前后取出在对比
三、三元表达式:
三元表达式固定表达式
值1 if 条件 else 值2
条件成立 值1
条件不成立 值2
当表达式例有一个条件使得结果不执行这个,就执行另一个时,常采用三元表达式更简单。
def my_max(x,y): if x>y: return x else: return y res=my_max(1,9) print(res)
上述表达式等价于 res = x if x > y else y 如果if后面的条件成立返回if前面的值,否则返回else后面的值
=555 y=3313 res=x if x>y else y print(res) >>3313
四、列表的生成式:往列表里添加或修改内容
l=['tank','nick','oscar','topa','kevin','jamse'] k=[] for name in l: k .append('%s_boy'%name) # k.append(name+'boy')但不推荐使用,pycharm里效率极低 print(k) 运行的结果 >>['tank_boy', 'nick_boy', 'oscar_boy', 'topa_boy', 'kevin_boy', 'jamse_boy']
等价于:
res = [ '%s_boy' %name for name in l ]
print(res)
res = [name for name in l if name.endswith('_sb') # 关键字.endswith
l=['tank','nick','oscar','topa','kevin','jamse'] res=['%s_boy'%name for name in l] print(res) 结果: >> >>['tank_boy', 'nick_boy', 'oscar_boy', 'topa_boy', 'kevin_boy', 'jamse_boy']
先 for 循环依次取出列表里面的每一个元素,然后先交给 if 判断 条件成立才会交给 for前面的代码
五、字典生成式
内部都是基于 for 循环 以 key:vlaue 键值对的形式生成列表 list,关键字 enumerate
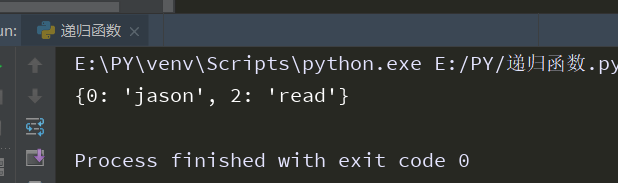
ser=['kevin', '1213',read] d={i=j for i ,j in enumerate(l1)} if j!=‘123’ print(d)
六、匿名函数:
定义的规范: 函数名 = lambda 参数 :返回值
就是没有函数的名字,在调用阶段只是暂时的命名,用完就不起作用了。

一般不会单独使用,常与内置函数搭配使用
#这段代码 def calc(n): return n**n print(calc(10)) #换成匿名函数 calc = lambda n:n**n print(calc(10))
七、常用的内置
|
内置函数 | ||||
|---|---|---|---|---|
|
|
常用的一些内置函数:
map(映射) zip(拉链) filter(过滤) sorted(排序) reduce(叠加) 大部分都是基于for循环
map:
l=[1,12,45,54,65,78] print(list(map(lambda x:x+5,l))) # 映射相当于for循环 对列表里赋值 >>>[6, 17, 50, 59, 70, 83] 对应的都+5
zip:
l1 = [1,2,3,4,5] l2 = ['jason','egon','tank'] # 按位置对称以元祖的形式返回,多的没有对应的就不返回: print(list(zip(l1,l2))) >>>>[(1, 'jason'), (2, 'egon'), (3, 'tank')]
filter:执行的条件是:当返回的值为True时才执行,为Flase 直接过滤掉( x:x != 3)
l = [1,2,3,4,5,6] print(list(filter(lambda x:x != 3,l))) # 过滤掉不等于3的数 返回 >>>[1, 2, 4, 5, 6]
文件操作相关:
open() 打开一个文件,返回一个文件操作符(文件句柄)
操作文件的模式有r,w,a,r+,w+,a+ 共6种,每一种方式都可以用二进制的形式操作(rb,wb,ab,rb+,wb+,ab+)
可以用encoding指定编码.
数字——数据类型相关:bool,int,float,complex
数字——进制转换相关:bin,oct,hex
数字——数学运算:abs,divmod,min,max,sum,round,pow
作用域相关的:
基于字典的形式获取局部变量和全局变量
globals()——获取全局变量的字典
locals()——获取执行本方法所在命名空间内的局部变量的字典
d = { # 'egon':30000, # 'jason':88888888888, # 'nick':3000, # 'tank':1000 # } # def index(name): # return d[name] # print(max(d,key=lambda name:d[name])) # # 比较薪资 返回人名 # print(min(d,key=lambda name:d[name])) # 通过key取值调用数字给d,然后在做比较
其他内置函数方法:
abs(x)-
返回一个数的绝对值。 参数可以是整数、浮点数或任何实现了
__abs__()的对象。 如果参数是一个复数,则返回它的模。
all(iterable)-
如果 iterable 的所有元素均为真值(或可迭代对象为空)则返回
True。 等价于:def all(iterable): for element in iterable: if not element: return False return True
any(iterable)-
如果 iterable 的任一元素为真值则返回
True。 如果可迭代对象为空,返回False。 等价于:def any(iterable): for element in iterable: if element: return True return False
ascii(object)-
与
repr()类似,返回一个包含对象的可打印表示形式的字符串,但是使用\x、\u和\U对repr()返回的字符串中非 ASCII 编码的字符进行转义。 生成的字符串和 Python 2 的repr()返回的结果相似。
bin(x)-
将一个整数转变为一个前缀为“0b”的二进制字符串。结果是一个合法的 Python 表达式。如果 x 不是 Python 的
int对象,那它需要定义__index__()方法返回一个整数。一些例子:>>> bin(3) '0b11' >>> bin(-10) '-0b1010'如果不一定需要前缀“0b”,还可以使用如下的方法。
>>> format(14, '#b'), format(14, 'b') ('0b1110', '1110') >>> f'{14:#b}', f'{14:b}' ('0b1110', '1110')另见
format()获取更多信息。
@classmethod
把一个方法封装成类方法。
一个类方法把类自己作为第一个实参,就像一个实例方法把实例自己作为第一个实参。请用以下习惯来声明类方法:
class C:
@classmethod
def f(cls, arg1, arg2, ...): ...
@classmethod 这样的形式称为函数的 decorator -- 详情参阅 函数定义。
类方法的调用可以在类上进行 (例如 C.f()) 也可以在实例上进行 (例如 C().f())。 其所属类以外的类实例会被忽略。 如果类方法在其所属类的派生类上调用,则该派生类对象会被作为隐含的第一个参数被传入。
类方法与 C++ 或 Java 中的静态方法不同。 如果你需要后者,请参阅本节中的 staticmethod()。 有关类方法的更多信息,请参阅 标准类型层级结构。
在 3.9 版更改: 类方法现在可以包装其他 描述器 例如 property()。
enumerate(iterable, start=0)
返回一个枚举对象。iterable 必须是一个序列,或 iterator,或其他支持迭代的对象。 enumerate() 返回的迭代器的 __next__() 方法返回一个元组,里面包含一个计数值(从 start 开始,默认为 0)和通过迭代 iterable 获得的值。
>>> seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1))
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
等价于:
def enumerate(sequence, start=0):
n = start
for elem in sequence:
yield n, elem
n += 1
filter(function, iterable)
用 iterable 中函数 function 返回真的那些元素,构建一个新的迭代器。iterable 可以是一个序列,一个支持迭代的容器,或一个迭代器。
如果 function 是 None ,则会假设它是一个身份函数,即 iterable 中所有返回假的元素会被移除。
getattr(object, name[, default])-
返回对象命名属性的值。name 必须是字符串。如果该字符串是对象的属性之一,则返回该属性的值。例如,
getattr(x, 'foobar')等同于x.foobar。如果指定的属性不存在,且提供了 default 值,则返回它,否则触发AttributeError。
globals()-
返回表示当前全局符号表的字典。这总是当前模块的字典(在函数或方法中,不是调用它的模块,而是定义它的模块)。
hasattr(object, name)-
该实参是一个对象和一个字符串。如果字符串是对象的属性之一的名称,则返回
True,否则返回False。(此功能是通过调用getattr(object, name)看是否有AttributeError异常来实现的。)
hash(object)-
返回该对象的哈希值(如果它有的话)。哈希值是整数。它们在字典查找元素时用来快速比较字典的键。相同大小的数字变量有相同的哈希值(即使它们类型不同,如 1 和 1.0)。
注解
如果对象实现了自己的
__hash__()方法,请注意,hash()根据机器的字长来截断返回值。另请参阅__hash__()。
help([object])-
启动内置的帮助系统(此函数主要在交互式中使用)。如果没有实参,解释器控制台里会启动交互式帮助系统。如果实参是一个字符串,则在模块、函数、类、方法、关键字或文档主题中搜索该字符串,并在控制台上打印帮助信息。如果实参是其他任意对象,则会生成该对象的帮助页。
本文来自博客园,作者:游走De提莫,转载请注明原文链接:https://www.cnblogs.com/Gaimo/p/11176371.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号