Go-fi-else-for循环-数组-切片
函数的高级应用
闭包函数:定义在函数内部,对外部作用有引用;
内层函数:定义在函数内部的函数。
简单的举例子:
//函数高级 package main import "fmt" //闭包函数:定义在函数内部,对外部作用有引用 //内层函数:定义在函数内部的函数 //go中函数内部定义的函数是不能有名的,需要定义匿名函数:没有名字 func test(a int) { func() { fmt.Println("我是内层函数") }() } //闭包函数 func test(a int) (func()) { //var c int =100 b:=func() { fmt.Println(a) fmt.Println("我是闭包函数") } return b } // 定义一个函数,传入函数,返回函数 func test(a func()) func() { b:= func() { fmt.Println("我先执行") a() fmt.Println("函数执行完了") } return b } func test2() { fmt.Println("xxxx") }
给类型命别名
格式:type 函数名 类型
//给类型命别名 type MyFunc func(a int,b int) func() type MyInt int func test() (MyFunc) { c:= func(a int,b int) func(){ return func() { } } return c } func main() { //a:=test(3) //a() //a:=test2 //a=test(a) //a() var a MyInt=10 var b int =90 a=MyInt(b) fmt.Println(a) }
类型转换:取别名的的int要对应Myint
var a MyInt=10 var b int =90 a=MyInt(b) fmt.Println(a)
if-else语句
格式有点类似javascrapy的格式,注意的小点是if后面的{}不能换行,应为没有结束符";"分号。
在 Go 语言规则中,它指定在 } 之后插入一个分号,如果这是该行的最终标记。因此,在if语句后面的 } 会自动插入一个分号。
package main import ( "fmt" ) func main() { num := 10 if num % 2 == 0 { //checks if number is even fmt.Println("the number is even") } else { fmt.Println("the number is odd") } }
完整的if-else语句,else必须紧跟在if后面的{}后面,不能空格,不然编译器报错。
package main import ( "fmt" ) func main() { num := 99 if num <= 50 { fmt.Println("number is less than or equal to 50") } else if num >= 51 && num <= 100 { fmt.Println("number is between 51 and 100") } else { fmt.Println("number is greater than 100") } }
if-else语句特殊的点:在条件中可以定义变量。
//if -else package main import "fmt" func main() { //a := 90 //if 条件{} 大括号和条件之间不能换行 //if a == 90{ // fmt.Println("a 是90"); //} //if a >90{ // fmt.Println("a 大于90") //}else if a<90{ // fmt.Println("a 小于90") //}else { // fmt.Println("a 等于90") //} //在条件中可以定义变量,但是它的作用于范围只在if判断内部使用 if a :=90;a>90{ fmt.Println("大于") }else if a==90{ fmt.Println(a) } //fmt.Println(a) }
包的使用
什么是包,为什么要使用包?
到目前为止,我们看到的 Go 程序都只有一个文件,文件里包含一个 main 函数和几个其他的函数。在实际中,这种把所有源代码编写在一个文件的方法并不好用。以这种方式编写,代码的重用和维护都会很困难。而包(Package)解决了这样的问题。
包用于组织 Go 源代码,提供了更好的可重用性与可读性。由于包提供了代码的封装,因此使得 Go 应用程序易于维护。
例如,假如我们正在开发一个 Go 图像处理程序,它提供了图像的裁剪、锐化、模糊和彩色增强等功能。一种组织程序的方式就是根据不同的特性,把代码放到不同的包中。比如裁剪可以是一个单独的包,而锐化是另一个包。这种方式的优点是,由于彩色增强可能需要一些锐化的功能,因此彩色增强的代码只需要简单地导入(我们会在随后讨论)锐化功能的包,就可以使用锐化的功能了。这样的方式使得代码易于重用。
我们会逐步构建一个计算矩形的面积和对角线的应用程序。
通过这个程序,我们会更好地理解包。
注意事项:
goland导包查找规则:默认在GOPATH路径下和GOROOT下查找加载。
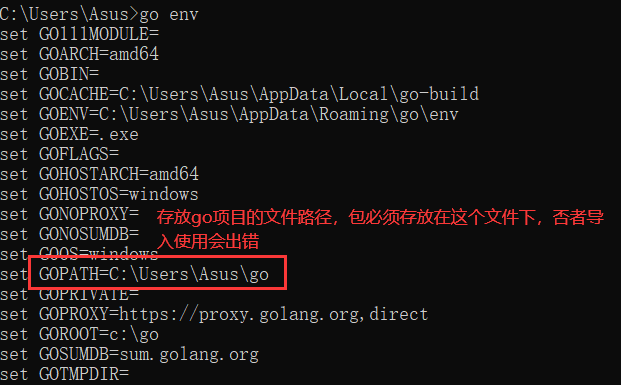
一般流程:
-包 -新建一个文件夹,内部写很多go文件,但是包名必须一致 -如果想在外部包使用,首字母必须大写 -在其他包中使用 -import "mypackage" -mypackage.Test1() -下载第三方包 go get github.com/astaxie/beego beego、gin 框架
例子:
自定义包的导入使用
先在GOPATH下的src文件下,自定义一个包下面有两个函数:
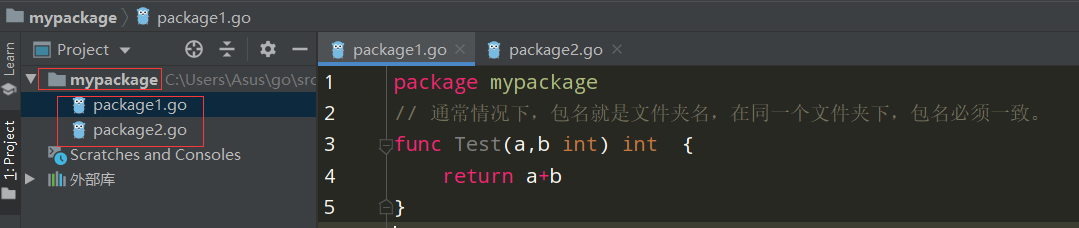
mypackage包下的package1,如果想要让外部导入使用,函数名必须首字母大写。
package mypackage // 通常情况下,包名就是文件夹名,在同一个文件夹下,包名必须一致。 func Test(a,b int) int { return a+b }
mypackage包下的package2
package mypackage import "fmt" //在同一个包下,变量,函数,都不能重复定义 func Test1() { fmt.Println("包的使用") }
导入使用:
//包的使用 package main import ( "fmt" "mypackage" ) func main() { //想使用mypackage包下的test函数和test1函数 mypackage.Test1() mypackage.Test(1,2) fmt.Println("xxx") }
for 循环
循环语句是用来重复执行某一段代码。
for 是 Go 语言唯一的循环语句。Go 语言中并没有其他语言比如 C 语言中的 while 和 do while 循环。
基本语法结构:

简单完整的for语法结构
//for 循环 package main import ( "fmt" ) func main() { for i := 1; i <= 10; i++ { fmt.Printf(" %d",i) } }
for语法的其他写法,三部分可以省略
//for循环 package main import "fmt" func main(){ //三部分,都可以省略 //先省略第一部分 //i :=0 //for ;i<10;i++{ // fmt.Println(i) //} //省略第三部分 //i :=0 //for ;i<10;{ // i++ // fmt.Println(i) //} //省略第二部分 //for ;;{ // fmt.Println("xxxx") //} //死循环 //for { // fmt.Println("xxxx") //} //只写条件 for 条件{} 等同于while循环 for { fmt.Println("just do it") } }
结合break和countnue的使用和其他语言的语法结构一致的;
break 语句用于在完成正常执行之前突然终止 for 循环,之后程序将会在 for 循环下一行代码开始执行。
continue 语句用来跳出 for 循环中当前循环。在 continue 语句后的所有的 for 循环语句都不会在本次循环中执行。循环体会在一下次循环中继续执行。
//for 循环 package main import "fmt" func main(){ //break和continue跟其他任何语言都一样 for i:=0;i<10;i++{ if i==5{ break } fmt.Println(i) } for i:=0;i<10;i++{ if i==5{ continue } fmt.Println(i) }
switch 语句
switch 是一个条件语句,用于将表达式的值与可能匹配的选项列表进行比较,并根据匹配情况执行相应的代码块。
它可以被认为是替代多个 if else 子句的常用方式。
简单的理解,即使用switch替代if else条件语句
基本用法:
package main import ( "fmt" ) func main() { finger := 4 switch finger { case 1: fmt.Println("a") case 2: fmt.Println("b") case 3: fmt.Println("c") case 4: fmt.Println("d") case 5: fmt.Println("e") } }
默认情况(Default Case)
当其他情况都不匹配时,将运行默认情况,类似if-else if -else
package main import ( "fmt" ) func main() { switch finger := 8; finger { case 1: fmt.Println("Thumb") case 2: fmt.Println("Index") case 3: fmt.Println("Middle") case 4: fmt.Println("Ring") case 5: fmt.Println("Pinky") default: // 默认情况 fmt.Println("incorrect finger number") } }
多表达式判断
通过用逗号分隔,可以在一个 case 中包含多个表达式。
package main import ( "fmt" ) func main() { letter := "i" switch letter { case "a", "e", "i", "o", "u": // 一个选项多个表达式 fmt.Println("vowel") default: fmt.Println("not a vowel") } }
在 case "a","e","i","o","u": 这一行中,列举了所有的元音。只要匹配该项,则将输出 vowel。
无表达式的 switch
在 switch 语句中,表达式是可选的,可以被省略。如果省略表达式,则表示这个 switch 语句等同于 switch true,并且每个 case 表达式都被认定为有效,相应的代码块也会被执行。
package main import ( "fmt" ) func main() { num := 75 switch { // 表达式被省略了 case num >= 0 && num <= 50: fmt.Println("num is greater than 0 and less than 50") case num >= 51 && num <= 100: fmt.Println("num is greater than 51 and less than 100") case num >= 101: fmt.Println("num is greater than 100") } }
在上述代码中,switch 中缺少表达式,因此默认它为 true,true 值会和每一个 case 的求值结果进行匹配。case num >= 51 && <= 100: 为 true,
所以程序输出 num is greater than 51 and less than 100。这种类型的 switch 语句可以替代多个 if else 子句。
Fallthrough 语句
简单的理解:就是当语句中由Fallthrough 这个关键字,就无条件的执行它后面的语句。
package main import "fmt" func main(){ a:=10 switch a { case 1: fmt.Println("1") fmt.Println("xxxx") case 2: fmt.Println("2") case 10: fmt.Println("10") //穿透,无条件执行下一个case的内容 fallthrough case 11: fmt.Println("11") test5() fallthrough case 12: fmt.Println("12") } } func test5() { fmt.Println("xxxxxx") } }
fallthrough 语句应该是 case 子句的最后一个语句。如果它出现在了 case 语句的中间,编译器将会报错:fallthrough statement out of place。
数组和切片
数组
数组是同一类型元素的集合。
例如,整数集合 5,8,9,79,76 形成一个数组。Go 语言中不允许混合不同类型的元素,例如包含字符串和整数的数组。
(译者注:当然,如果是 interface{} 类型数组,可以包含任意类型)
数组的声明
一个数组的表示形式为 [n]T。n 表示数组中元素的数量,T 代表每个元素的类型。元素的数量 n 也是该类型的一部分
简单例子
package main //数组 在定义阶段,长度和类型就固定了,以后不能更改 import "fmt" func main() { var a [3]int a[1]=20 a[2]=100 fmt.Println(a) }
结果:

数组的其他情况
//数组 在定义阶段,长度和类型就固定了,以后不能更改 package main import "fmt" func main() { //var a [5]int //定义了一个长度为5的int类型数组 //a[1]=100 //把2个位置放上100 //fmt.Println(a) //定义并赋初值 //var a [6]int=[6]int{1,2,3,4,5,6} //var a =[6]int{1,2,3} //a :=[6]int{1,2,3} //a[5]=100 //fmt.Println(a) //第99个位置设为99 //a :=[100]int{1,2,98:99,87:88} ////a[-9]=19 不支持 //fmt.Println(a) //数组是值类型 //所有的函数传参都是copy传递 //a:=[4]int{1,2,3} //test6(a) //fmt.Println(a) //数组的长度 内置函数len //a:=[4]int{1,2,3} //fmt.Println(len(a)) //数组大小是类型一部分 //var a [4]int=[4]int{1,2,} //var b [5]int=[5]int{4,5,} //a=b //fmt.Println(a) //与或非 //&& || ! //a:=10 //if !(a>9||a<6){ // //} //数组迭代 //var a [4]int=[4]int{1,2,} //for i:=0;i<len(a);i++{ // fmt.Println(a[i]) //} //通过range迭代 //for i,v:=range a { ////for i:=range a { // fmt.Println("------",i) // fmt.Println(v) //} }
多维数组
package main import "fmt" func main(){ //多维数组 var a [7][2]int // 7组2个元素的元组 a[0][1]=100 fmt.Println(a) } func test6(b [4]int) { b[3]=100 fmt.Println(b) } }

切片
切片是由数组建立的一种方便、灵活且功能强大的包装(Wrapper)。切片本身不拥有任何数据。它们只是对现有数组的引用。
创建一个切片
带有 T 类型元素的切片由 []T 表示
package main import ( "fmt" ) func main() { a := [5]int{76, 77, 78, 79, 80} var b []int = a[1:4] // creates a slice from a[1] to a[3] fmt.Println(b) }
值为[77 78 79]
使用语法 a[start:end] 创建一个从 a 数组索引 start 开始到 end - 1 结束的切片。因此,在上述程序的第 9 行中, a[1:4] 从索引 1 到 3 创建了 a 数组的一个切片表示。因此, 切片 b 的值为 [77 78 79]。
切片的修改
切片自己不拥有任何数据。它只是底层数组的一种表示。对切片所做的任何修改都会反映在底层数组中。
比如定义一个8[int]的数字:
package main import "fmt" func main() { //切片的定义的第一种方式,由数组切出来的 var a [8]int=[8]int{1,2,3,4,5,6,7,8} /// 只是对数组的引用 var b []int=a[2:6] fmt.Println(b) a[2]=30 b[1]=40 fmt.Println(a) }
区分数组的长度和容量的概念,底层数组的修改会影响切片,切片的修改也会影响底层数组,切片中不存在步长。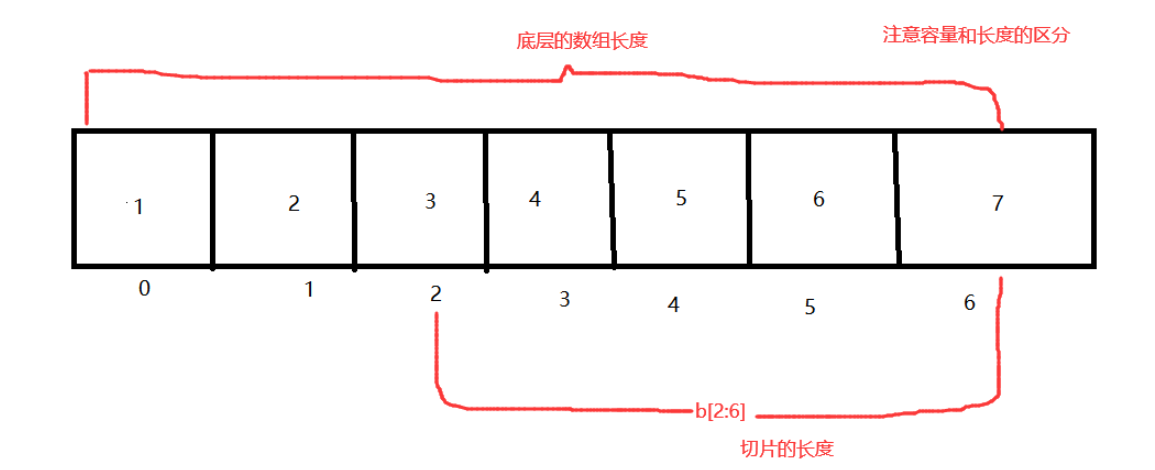
切片的修改
切片自己不拥有任何数据。它只是底层数组的一种表示。对切片所做的任何修改都会反映在底层数组中。
package main import ( "fmt" ) func main() { darr := [...]int{57, 89, 90, 82, 100, 78, 67, 69, 59} dslice := darr[2:5] fmt.Println("array before", darr) for i := range dslice { dslice[i]++ } fmt.Println("array after", darr) }
在上述程序的第 9 行,我们根据数组索引 2,3,4 创建一个切片 dslice。for 循环将这些索引中的值逐个递增。当我们使用 for 循环打印数组时,我们可以看到对切片的更改反映在数组中。该程序的输出是
array before [57 89 90 82 100 78 67 69 59]
array after [57 89 91 83 101 78 67 69 59]
其他用法
package main import "fmt" func main() {
//切片定义的第一种方式,由数组切出来 //var a [8]int=[8]int{1,2,3,4,5,6,7,8} ////只是对数组的引用 var b []int=a[2:6] fmt.Println(b) a[2]=30 修改 fmt.Println(b) b[1]=40 fmt.Println(b) fmt.Println(a) ////底层数组的修改会影响切片 ////切片的修改也会影响底层数组
//a[1]=20 //fmt.Println(b) //更多用法,没有步长 //var a [8]int=[8]int{1,2,3,4,5,6,7,8} //b:=a[:4] //fmt.Println(b)
//第二种方式,直接定义 //切片空值是?nil类型 var a []int if a==nil{ fmt.Println("我是空的") } a[0]=10 fmt.Println(a)
//定义并初始化,第一个数字是切片的长度,第二个数字是底层数组长度,也就是切片的容量 var a []int=make([]int,3) fmt.Println(a) }
例子:
package main import "fmt" func main() { //切片的定义的第一种方式,由数组切出来的 var a [8]int=[8]int{1,2,3,4,5,6,7,8} /// 只是对数组的引用 var b []int=a[2:6] fmt.Println(b) a[2]=30 fmt.Println(b) b[1]=40 fmt.Println(b) fmt.Println(a) // 底层数组的修改会影响切片 // 切片的修改也会影响底层的数组 a[1]=20 fmt.Println(b) }
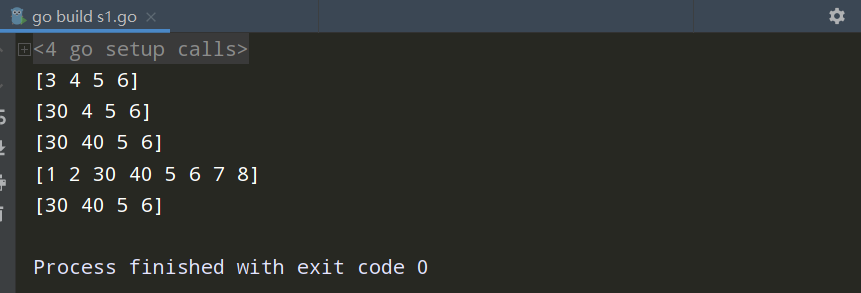
切片的长度和容量
切片的长度是切片中的元素数。切片的容量是从创建切片索引开始的底层数组中元素数。
让我们写一段代码来更好地理解这点。
package main import "fmt" func main() { //切片的长度和容量(len cap:容量) var a [8]int=[8]int{1,2,3,4,5,6,7,8} var b []int=a[1:6] fmt.Println(len(b)) fmt.Println(cap(b)) }
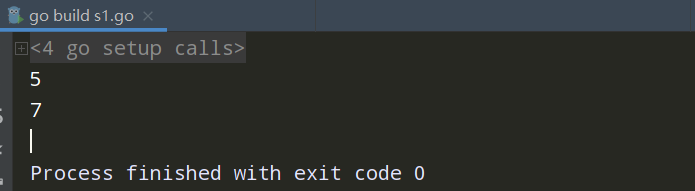
理解:b是在从a数组中[1:6]创建出来的,所以len长度为5,a的长度为7,b的容量是从a的索引1开始的{1,2,3,4,5,6,7}为7。
使用 make 创建一个切片
func make([]T,len,cap)[]T 通过传递类型,长度和容量来创建切片。容量是可选参数, 默认值为切片长度。
make 函数创建一个数组,并返回引用该数组的切片。
package main import ( "fmt" ) func main() { i := make([]int, 5, 5) fmt.Println(i) }
使用 make 创建切片时默认情况下这些值为零。上述程序的输出为 [0 0 0 0 0]。
追加切片元素
正如我们已经知道数组的长度是固定的,它的长度不能增加。 切片是动态的,使用 append 可以将新元素追加到切片上。append 函数的定义是 func append(s[]T,x ... T)[]T。
x ... T 在函数定义中表示该函数接受参数 x 的个数是可变的。这些类型的函数被称为[可变函数]。
package main import "fmt" func main(){ //切片追加值 var a [8]int=[8]int{1,2,3,4,5,6,7,8} var b []int =a[2:6] fmt.Println(len(b)) fmt.Println(cap(b)) fmt.Println(b) //内置函数append b=append(b,555) b=append(b,666) fmt.Println(b) fmt.Println(len(b)) fmt.Println(cap(b)) // 修改值最加值,capy赋值了一个数组的容量,内存的优化机制 b[0]=666 fmt.Println(a) b=append(b,88) fmt.Println(b) fmt.Println(len(b)) fmt.Println(cap(b)) //var b =make([]int,3,4) //fmt.Println(b) b=append(b,4) fmt.Println(b) fmt.Println(len(b)) fmt.Println(cap(b)) b=append(b,5) fmt.Println(len(b)) fmt.Println(cap(b)) }
打印的结果:

切片的修改
package main import ( "fmt" ) func main() { // 切片的修改 //var b = make([]int,3,4) //b[0]=999 //fmt.Println(b) var b =make([]int,4,4) fmt.Println(len(b)) fmt.Println(cap(b)) }
切片的函数传递
我们可以认为,切片在内部可由一个结构体类型表示。这是它的表现形式,
package main import "fmt" func main() { //切片的函数传递 var b =make([]int,3,4) //test(b) //fmt.Println(b) //切片的数据结构表示 type slice struct { Length int Capacity int ZerothElement *byte } func test(b []int) { b[0]=999 fmt.Println(b) }
切片包含长度、容量和指向数组第零个元素的指针。当切片传递给函数时,即使它通过值传递,指针变量也将引用相同的底层数组。
因此,当切片作为参数传递给函数时,函数内所做的更改也会在函数外可见。
多维切片
类似于数组,切片可以有多个维度。
package main import "fmt" func main(){ //多维切片 var a [][]string=make([][]string,2,3) fmt.Println(a[0]) a[0]=make([]string,2,3) if a[0]==nil{ fmt.Println("xxxx") } //切片初始化的方法 //var a []int=[]int{1,2,3} //fmt.Println(a) //fmt.Println(len(a)) //fmt.Println(cap(a)) //多维切片初始化 var a [][]string=[][]string{{"1","2"},{"3","4"}} fmt.Println(a) fmt.Println(len(a)) fmt.Println(cap(a)) a[0][1]="999" fmt.Println(a) //a[1][0]="999" //var a []int=[]int{1,2} //fmt.Println(a) //a=append(a,3) fmt.Println(len(a)) fmt.Println(cap(a)) a[2]=99 a[3]=888 fmt.Println(a) }

多维的初始化定义,类型必须统一,书写的格式也要统一。
capy函数
capy即内存的优化:
切片持有对底层数组的引用。只要切片在内存中,数组就不能被垃圾回收。在内存管理方面,这是需要注意的。让我们假设我们有一个非常大的数组,我们只想处理它的一小部分。然后,我们由这个数组创建一个切片,并开始处理切片。这里需要重点注意的是,在切片引用时数组仍然存在内存中。
一种解决方法是使用 [copy] 函数 func copy(dst,src[]T)int 来生成一个切片的副本。这样我们可以使用新的切片,原始数组可以被垃圾回收。
package main import "fmt" func main() { //copy函数 var a =make([]int,3,10000) a[1]=99 a[2]=888 fmt.Println(a) //var b =make([]int,4,4) var b =make([]int,2,4) fmt.Println(b) copy(b,a) fmt.Println(b) }
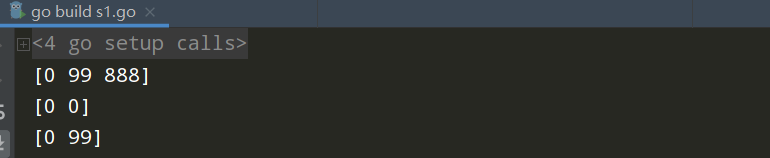
capy源码:

注意位置的传参,copy(b,a),a复制b,当复制的数量大于原有的时候,会被覆盖收回,不再被引用,小的时候只引用复制的部分即可。
补充知识点
可变长参数和循环多维数组的使用:
package main //可变长参数 import "fmt" //可变长参数 func main() { //var a =[]int{1,2,4,} //test1(1,2,3,4) //相当于打散了 //test1(a...) //veggies := []string{"potatoes", "tomatoes", "brinjal"} //fruits := []string{"oranges", "apples"} //food := append(veggies, fruits...) //fmt.Println("food:",food) //循环多维切片 pls := [][]string { {"C", "C++"}, {"JavaScript"}, {"Go", "Rust"}, } fmt.Println(pls) for _,v:=range pls { for _,v1:=range v{ fmt.Println(v1) } } } func test1(a ...int) { fmt.Println(a) fmt.Printf("%T",a) }
本文来自博客园,作者:游走De提莫,转载请注明原文链接:https://www.cnblogs.com/Gaimo/articles/12019251.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号